CnSTD+CnOCR的联合使用
复杂背景的OCR,使用CnSTD定位图像中的文本区域,然后CnOCR对每一个区域内的文字进行识别。
安装
有一个注意点:如果直接pip安装就会安装最新版的CnSTD和CnOCR,需要使用v5版本的模型,然而我在项目的官网并没有下载到v5版本的模型,甚至在CSDN上花了几十元买了模型也不能使用,我手里的模型是v4版本的,所以不能直接安装最新版否则会出错:
![]() 会提示找不到v5版本的模型。
会提示找不到v5版本的模型。
解决办法:安装旧版的。
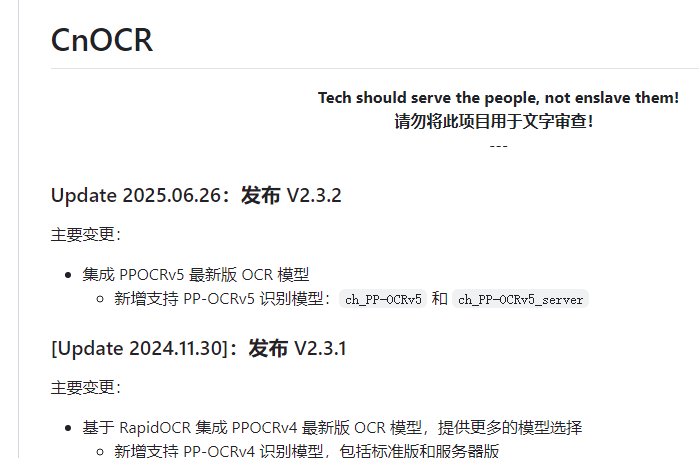
支持v4模型的最新版本:
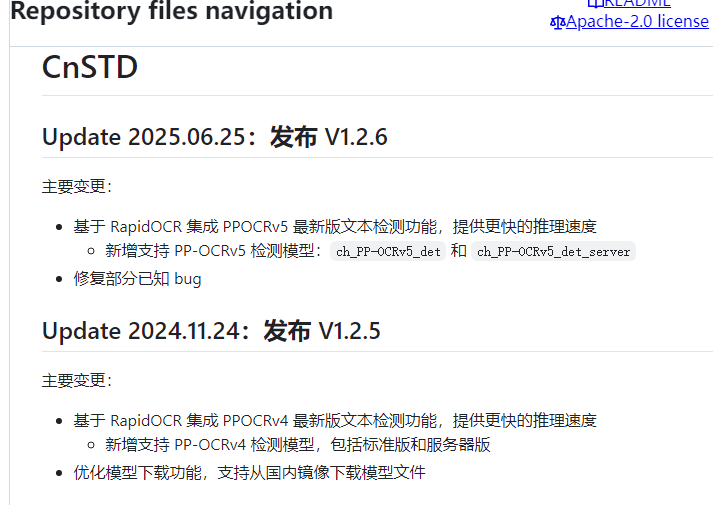
pip install cnstd==1.2.5
pip install cnocr==2.3.1基本的使用

from cnstd import CnStd
from cnocr import CnOcrstd = CnStd()
ocr = CnOcr()box_infos = std.detect('test.jpg', resized_shape=(768, 1024))print(len(box_infos['detected_texts']))
for box_info in box_infos['detected_texts']:cropped_img = box_info['cropped_img']ocr_res = ocr.ocr_for_single_line(cropped_img)print('ocr result: %s' % str(ocr_res))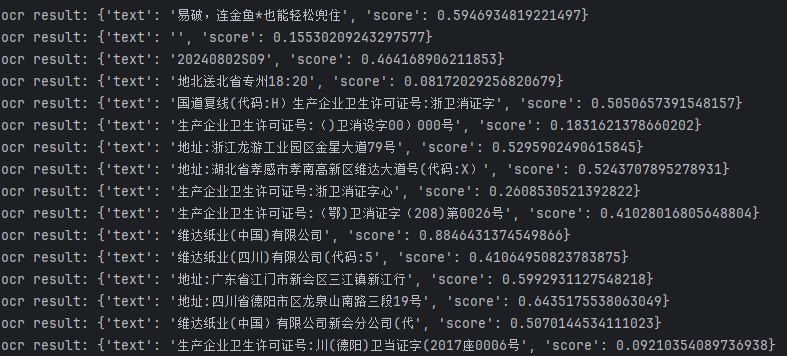
艾玛,识别效果还是令人满意的。