Odoo AI 智能查询系统
🤖 Odoo AI 智能查询系统 - 基于 Streamlit 和阿里云 DashScope 的企业级数据查询解决方案
📖 项目概述
这是一个基于 Streamlit 和 阿里云 DashScope 开发的智能 Odoo ERP 数据查询系统。该系统通过自然语言处理技术,让用户能够用中文自然语言查询 Odoo 系统中的各种业务数据,大大降低了数据查询的技术门槛。
🎯 核心特性
1. 智能自然语言查询
- 中文自然语言处理:支持中文查询,如"查找所有员工"、“查询销售订单及产品信息”
- AI 智能解析:基于阿里云 DashScope 的 qwen-turbo 模型进行查询意图识别
- 多模型支持:支持人力资源、销售、采购、库存、财务等多个业务模块
2. 双模式工作界面
- 🔍 数据查询模式:专注于数据检索和分析
- 💬 智能聊天模式:提供 Odoo 系统使用指导和业务咨询
3. 灵活的网络模式
- 🏠 本地模式:仅使用本地 Odoo 服务,适合内网环境
- 🌍 在线模式:优先使用在线 AI 服务
- 🤖 智能模式:自动选择最佳服务
🏗️ 技术架构
核心技术栈
- 前端框架:Streamlit - 快速构建数据应用
- AI 服务:阿里云 DashScope (qwen-turbo 模型)
- ERP 系统:Odoo XML-RPC API
- 数据处理:Pandas DataFrame
- 模板引擎:Jinja2
📊 功能模块详解
1. 人力资源模块
支持查询员工信息、部门结构、职位管理等:
# 员工信息查询示例
"查找所有员工" → hr.employee 模型
"员工及部门信息" → 跨表查询员工和部门信息
2. 销售管理模块
支持销售订单查询、客户信息、产品详情等:
# 销售订单查询示例
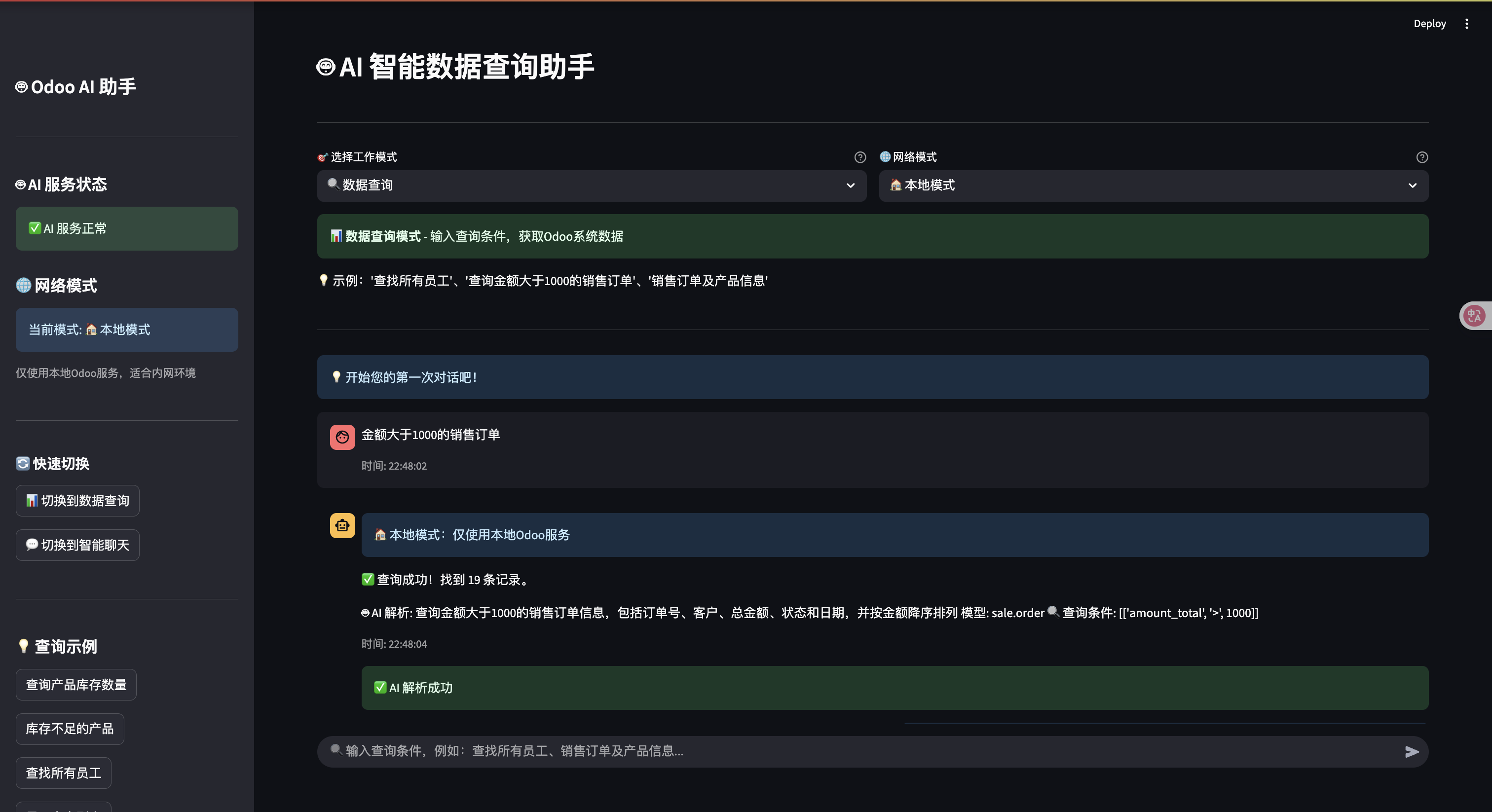
"查询销售订单" → sale.order 模型
"销售订单及产品信息" → 跨表查询订单和产品详情
3. 库存管理模块
支持库存数量查询、产品信息、库位管理等:
# 库存查询示例
"查询产品库存数量" → stock.quant 模型
"产品及库存信息" → 跨表查询产品和库存
4. 采购管理模块
支持采购订单、供应商信息查询:
# 采购查询示例
"查询采购订单" → purchase.order 模型
"采购订单及供应商产品" → 跨表查询采购和供应商信息
5. 财务管理模块
支持会计凭证、发票、账单查询:
# 财务查询示例
"查询财务凭证" → account.move 模型
"大额发票" → 条件查询大额财务记录
🚀 核心代码解析
AI 查询解析器
def parse_query_with_ai(self, query: str) -> Dict[str, Any]:"""使用 AI 解析自然语言查询"""try:# 构建系统提示词system_prompt = self.system_prompt_template.render(models_info=json.dumps(self.models_info, ensure_ascii=False, indent=2))# 调用 AI 服务response = self.openai_client.chat.completions.create(model="qwen-turbo",messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": f"请解析以下查询并返回 JSON 格式:{query}"}],temperature=0.1,max_tokens=1000)# 解析 AI 返回的 JSONai_response = response.choices[0].message.content.strip()parsed = json.loads(ai_response)return {"success": True,"parsed": parsed,"explanation": parsed.get("explanation", "")}except Exception as e:return self._fallback_parsing(query)
跨表查询处理
def search_records(self, model: str, domain: List = None, fields: List = None, limit: int = 10, order: str = None) -> Dict[str, Any]:"""搜索记录 - 支持跨表查询"""try:# 处理跨表查询字段processed_fields = []related_queries = {}need_order_lines = Falsefor field in fields:if field == "order_line" or field.startswith("order_line."):need_order_lines = Trueif "order_line" not in processed_fields:processed_fields.append("order_line")elif '.' in field:# 处理关联字段,如 partner_id.nameparts = field.split('.')relation_field = parts[0]related_field = parts[1]if relation_field not in processed_fields:processed_fields.append(relation_field)if relation_field not in related_queries:related_queries[relation_field] = []related_queries[relation_field].append(related_field)else:processed_fields.append(field)# 执行主查询result = self.proxy.execute_kw(self.database, self.uid, self.password,model, "search_read", [domain],{"fields": processed_fields, "limit": limit, "order": order})# 处理关联数据if (related_queries or need_order_lines) and result:enhanced_result = []for record in result:enhanced_record = record.copy()# 处理订单行查询if need_order_lines and "order_line" in record:order_line_result = self.proxy.execute_kw(self.database, self.uid, self.password,"sale.order.line" if model == "sale.order" else "purchase.order.line","search_read", [[("order_id", "=", record["id"])]],{"fields": ["product_id", "name", "product_uom_qty", "price_unit", "price_subtotal"]})if order_line_result:enhanced_record["order_lines"] = order_line_resultenhanced_result.append(enhanced_record)result = enhanced_resultreturn {"success": True, "data": result, "count": len(result)}except Exception as e:return {"success": False, "error": str(e), "data": [], "count": 0}
🎨 用户界面设计
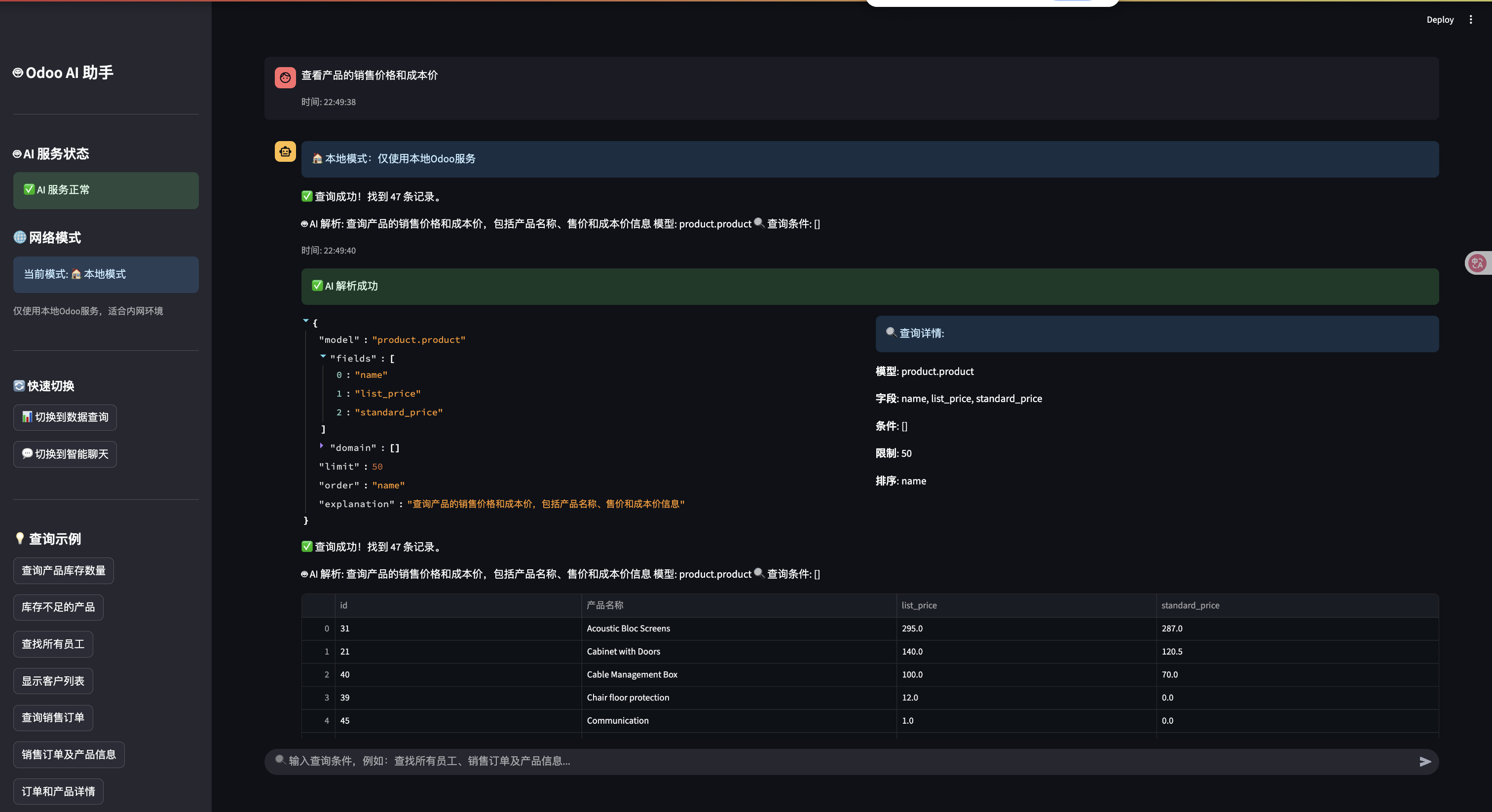
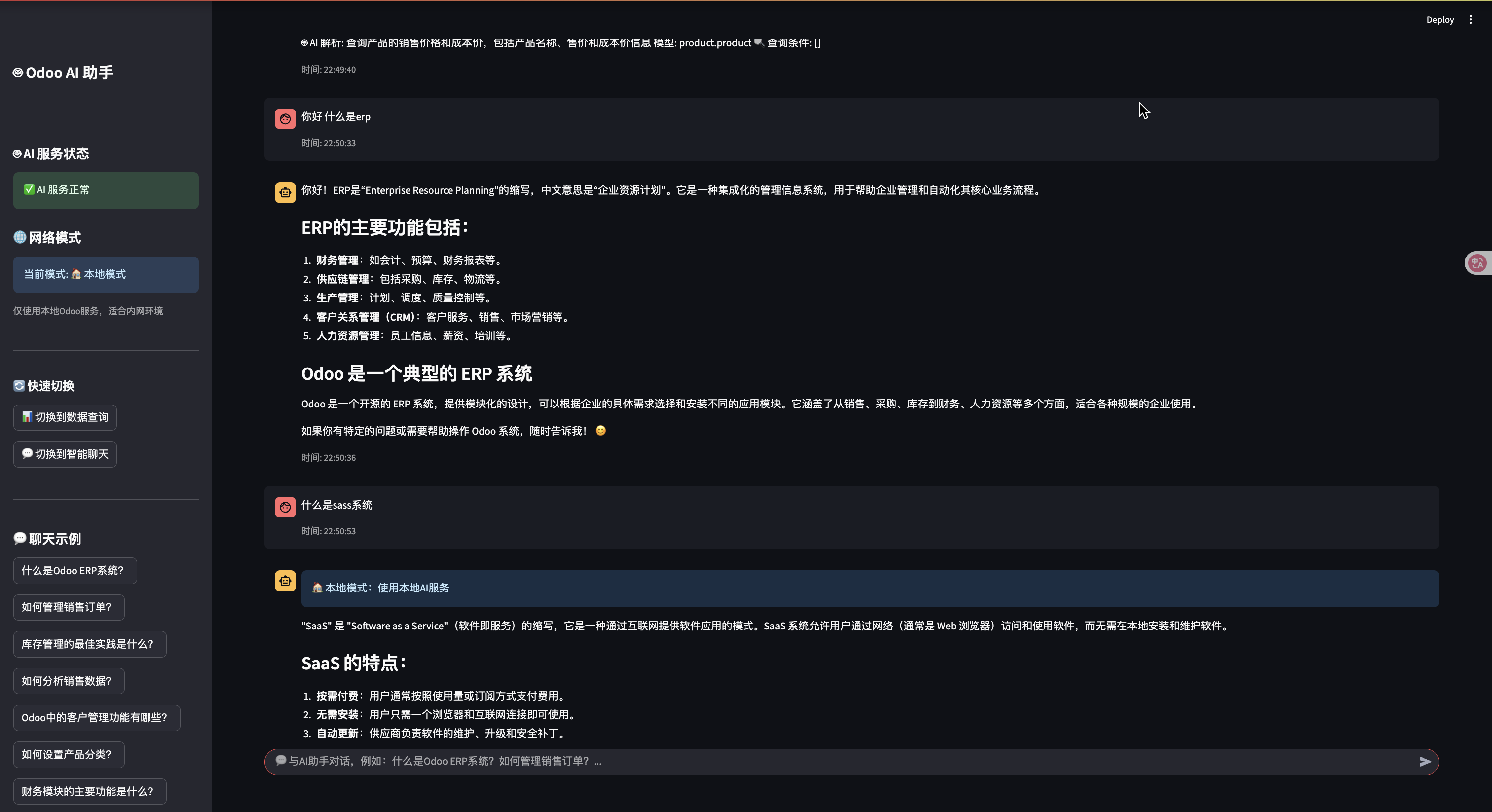
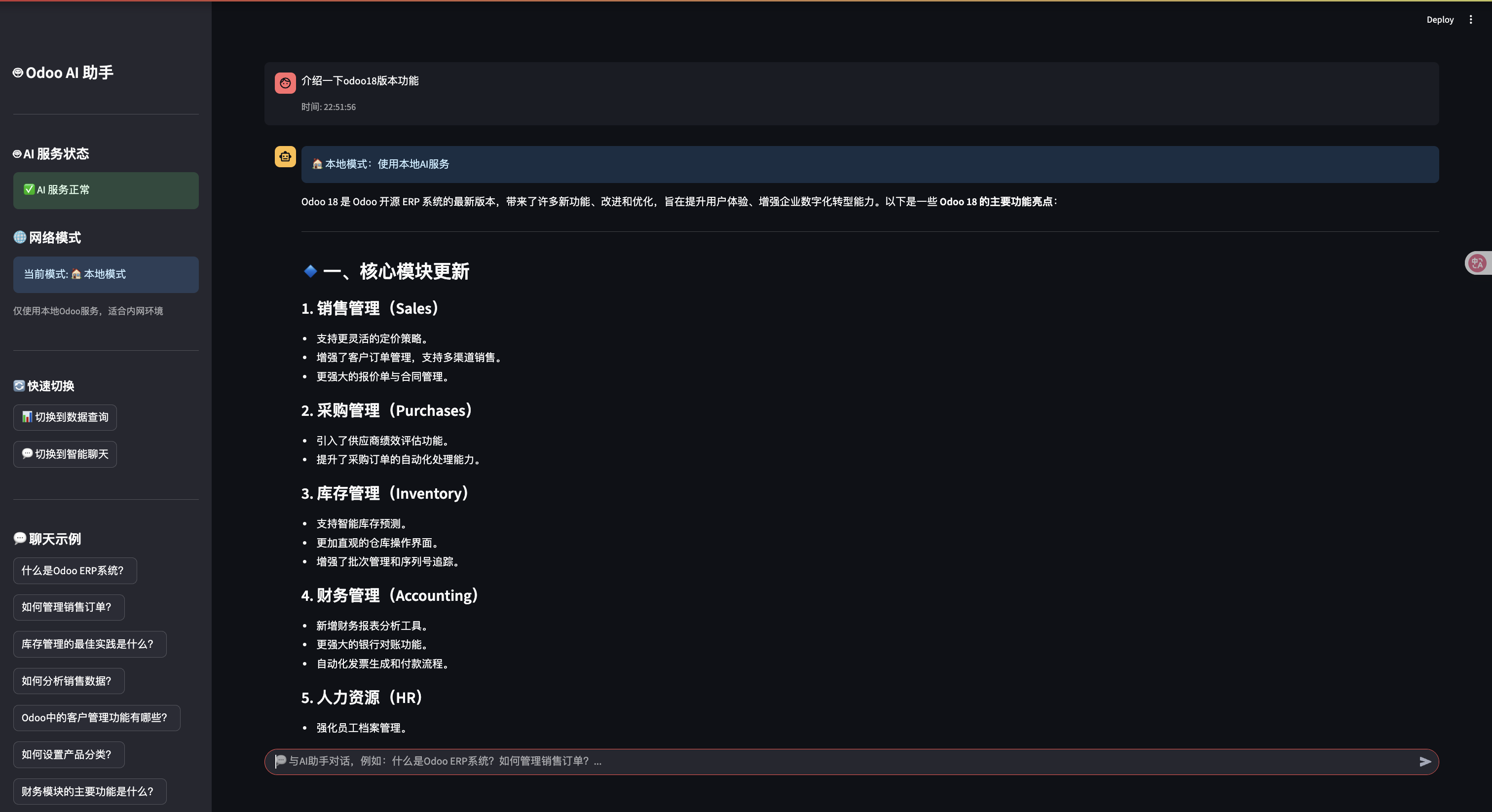
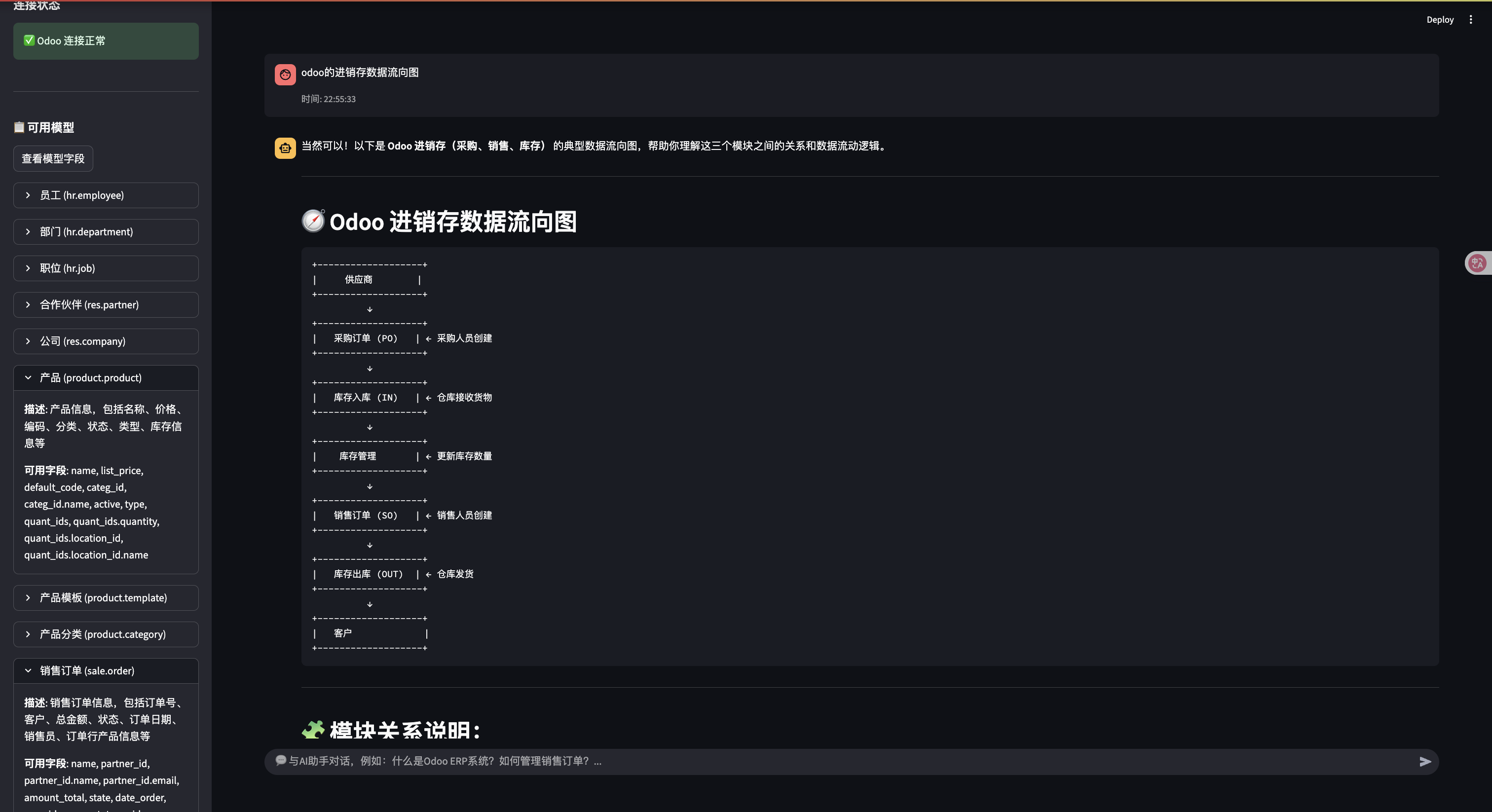
主界面布局
系统采用现代化的界面设计,包含:
- 顶部导航:模式选择和网络模式切换
- 侧边栏:快速示例、连接状态、模型信息
- 主内容区:聊天界面和数据展示
- 响应式设计:适配不同屏幕尺寸
数据展示优化
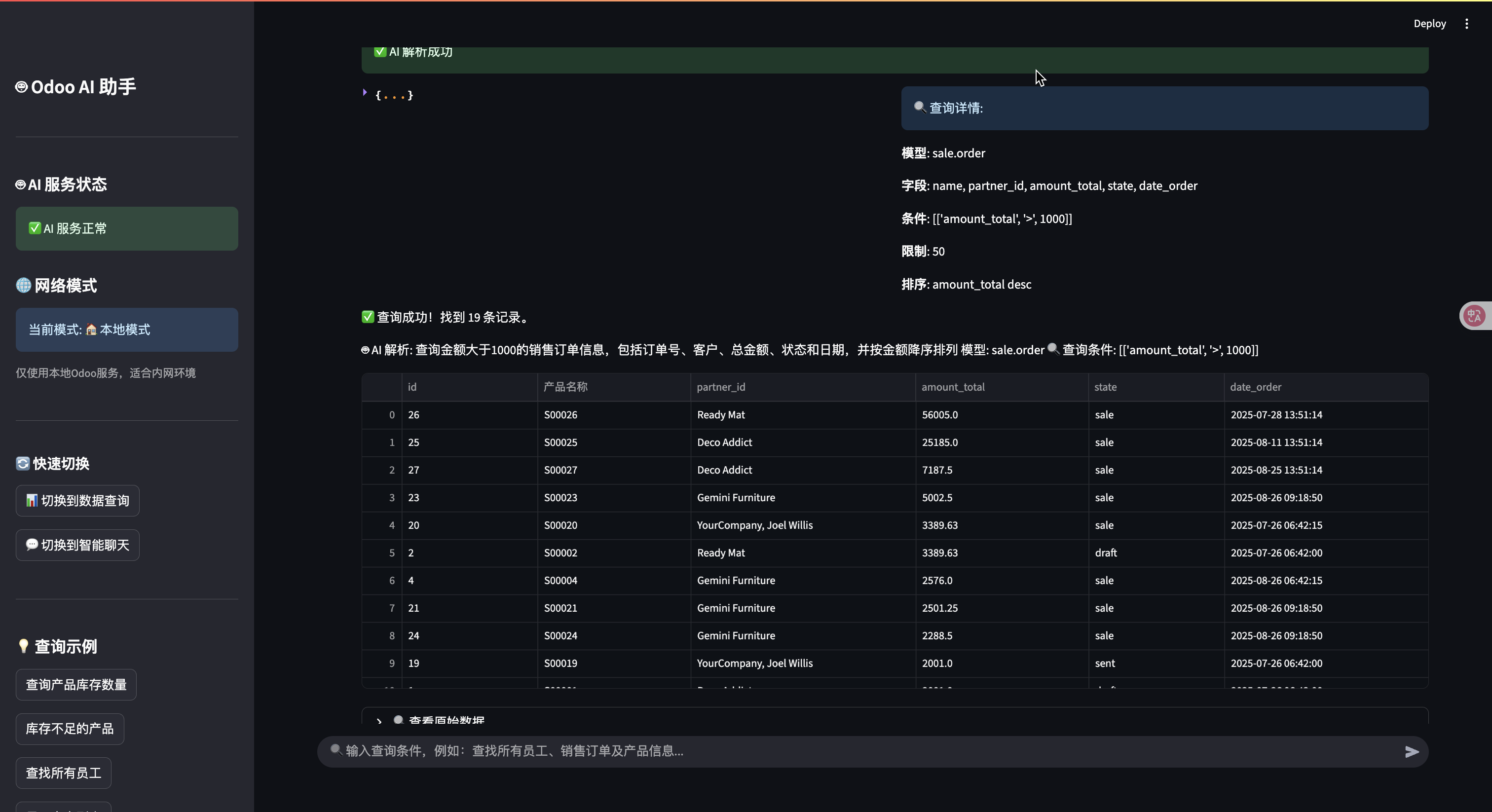
- 智能表格:自动处理复杂数据类型
- 跨表数据:订单和产品信息的分离展示
- 数据统计:实时计算和展示关键指标
- 导出功能:支持 CSV 格式数据导出
🔧 安装和配置
环境要求
Python 3.8+
Streamlit
pandas
openai
jinja2
xmlrpc
requests
配置步骤
- 安装依赖
pip install streamlit pandas openai jinja2 requests
- 配置 Odoo 连接
# 修改连接参数
self.odoo_url = "http://your-odoo-server:8069"
self.database = "your-database-name"
- 配置 AI 服务
# 配置阿里云 DashScope API
self.openai_client = OpenAI(api_key='your-dashscope-api-key',base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
- 启动应用
streamlit run streamlit_odoo_dashscope_ai.py
💡 使用示例
基础查询示例
用户输入: "查找所有员工"
AI 解析: {"model": "hr.employee", "fields": ["name", "employee_id", "department_id", "work_email"]}
结果: 显示员工列表,包含姓名、工号、部门、邮箱
复杂查询示例
用户输入: "销售订单及产品信息"
AI 解析: {"model": "sale.order", "fields": ["name", "partner_id.name", "amount_total", "order_line"]}
结果: 显示订单概览 + 产品详情表格
条件查询示例
用户输入: "库存不足的产品"
AI 解析: {"model": "stock.quant", "domain": [["quantity", "<", 10]]}
结果: 显示库存少于10个的产品
🎯 应用场景
1. 企业管理层
- 实时数据监控:快速了解业务状况
- 决策支持:基于数据的决策分析
- 报表生成:自动生成各类业务报表
2. 业务人员
- 日常查询:快速查询客户、订单、库存信息
- 数据分析:分析销售趋势、库存状况
- 客户服务:快速响应客户查询需求
3. 技术人员
- 系统集成:作为 Odoo 系统的智能查询接口
- 数据导出:批量导出数据用于进一步分析
- API 开发:基于此系统开发更多应用
🔮 未来发展方向
1. 功能扩展
- 语音查询:支持语音输入和语音播报
- 图表可视化:集成更多图表类型
- 移动端适配:优化移动设备体验
2. AI 能力增强
- 多语言支持:支持英文等其他语言
- 智能推荐:基于历史查询推荐相关问题
- 预测分析:基于历史数据进行趋势预测
3. 系统集成
- 第三方系统:集成更多 ERP 和 CRM 系统
- API 开放:提供 RESTful API 接口
- 插件生态:支持自定义插件开发
📈 性能优化
1. 查询优化
- 缓存机制:缓存常用查询结果
- 分页加载:大数据量分页显示
- 异步处理:长时间查询异步执行
2. AI 服务优化
- 批量处理:批量处理多个查询
- 模型缓存:缓存 AI 模型响应
- 降级策略:AI 服务异常时的降级处理
🛡️ 安全考虑
1. 数据安全
- 用户认证:Odoo 用户认证机制
- 权限控制:基于用户权限的数据访问控制
- 数据加密:敏感数据传输加密
2. API 安全
- API 密钥管理:安全的 API 密钥存储
- 请求限流:防止 API 滥用
- 日志审计:完整的操作日志记录
📞 技术支持
联系方式
- 微信:H13655699934
常见问题
- 连接失败:检查 Odoo 服务状态和网络连接
- AI 服务异常:检查 DashScope API 密钥和配额
- 查询无结果:检查用户权限和查询条件
🎉 总结
这个 Odoo AI 智能查询系统通过结合现代 AI 技术和传统 ERP 系统,为企业提供了一个强大而易用的数据查询解决方案。它不仅降低了数据查询的技术门槛,还提供了智能化的用户体验,是现代企业数字化转型的重要工具。
通过自然语言处理技术,用户可以用日常语言查询复杂的业务数据,大大提高了工作效率。同时,系统的模块化设计和扩展性为未来的功能增强提供了良好的基础。
本文档介绍了基于 Streamlit 和阿里云 DashScope 的 Odoo AI 智能查询系统的完整功能和技术实现。该系统为企业提供了一个现代化、智能化的数据查询解决方案。