腾讯wxg后台开发面经
文章目录
- 1、C++ 编译器是如何解析 decltype 和 auto 关键字的?
- auto 关键字的解析
- a.普通变量:
- b. 指针和引用:
- c.数组和 auto:
- d.const 修饰符:
- e.模板中的 auto:
- decltype 关键字的解析
- a.普通变量:
- b.表达式的类型:
- c.引用的处理:
- d. decltype(auto)用法:
- 2、vector的resize和reserve有什么区别?
- resize:调整容器的大小(元素数量)
- reserve:预留容量(内存空间)
- 二者关键区别
- 3. vector是分配在堆还是栈,sizeof(vector)返回什么值?
- vector是分配在堆还是栈?
- sizeof(vector)返回什么值?
- 4. unorderedmap中插入一个元素,它原来的iterater还有效吗?
- 具体原因解释
- 示例代码
- 5. map中插入一个元素,它原来的iterater还有效吗?
- 详细解释
- 示例代码
- 注意事项
- 规律
- 6. shared_ptr是不是线程安全的,为什么?
- 原因
- 7. 把uniqueptr move到sharedptr会发生什么? (高频)
- 示例代码
- 注意事项
- 8. weak_ptr的作用是什么?它与shared_ptr的区别是什么?
- std::weak_ptr 的作用
- 使用 std::weak_ptr 防止循环引用
- 使用 std::weak_ptr 解决循环引用
- std::weak_ptr 的 lock() 方法
- 9、HTTP/2和HTTP/1.1的主要区别是什么?
- HTTP 基本概念
- HTTP/2 的关键改进
- 示例:HTTP/1.1 vs HTTP/2 传输过程
- HTTP/1.1:
- HTTP/2:
- 10. 使用 std::function 和 std::bind 绑定一个类成员函数,并调用它。
- 代码示例
- 面试中的可能追问和应对
- 1. “为什么用 std::bind 而不用 lambda?”
- 11. 如何重载[]操作符? 写一个例子
- 实现方式
- 示例代码
- 面试官也可能问到的要点
- 12. 假设你要实现一个线程安全的队列,其中 push 和 pop 需要支持多个线程并发访问,如何设计?请实现该数据结构
- 13. 代码实现:给定一个数组,找出数组中重复的数。
- 14. 代码实现:反转链表
- 解题思路
- 代码实现
- 15. 代码实现:实现一个线程安全的单例模式
- 最优解——使用C++11标准的局部静态变量
1、C++ 编译器是如何解析 decltype 和 auto 关键字的?
在 C++ 中,decltype 和 auto 关键字用于类型推导,但它们的解析方式不同
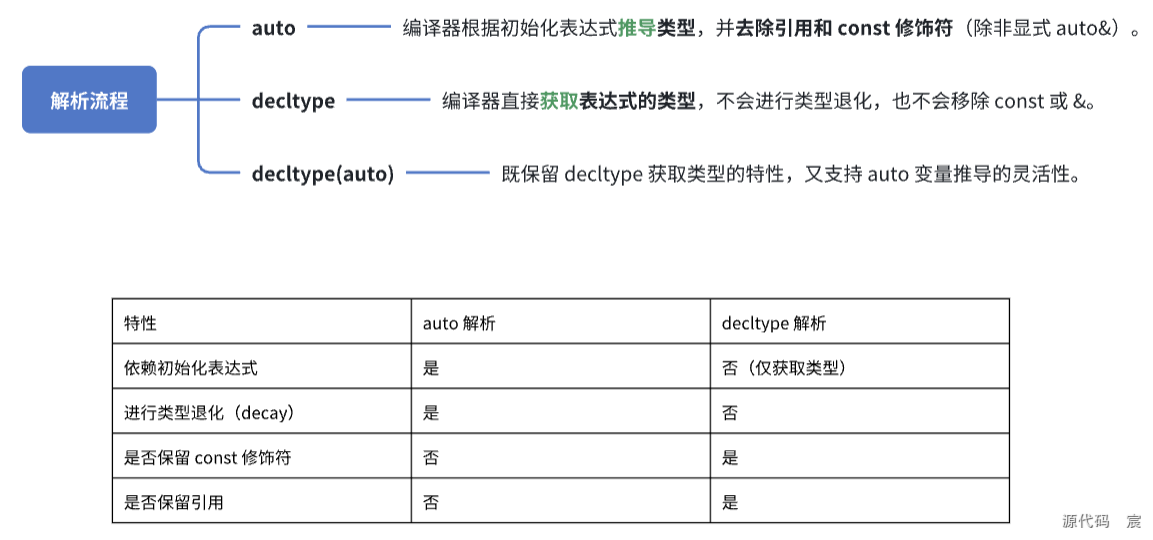
auto 关键字的解析
auto 在编译期会进行类型推导,通常基于初始化表达式的类型进行推导。auto 也是编译期类型推导的关键字,但它的行为更像是一个“占位符”,由初始化表达式来决定类型
a.普通变量:
int x = 10;
auto y = x; // y 的类型为 int
b. 指针和引用:
int a = 10;
int& ra = a;
auto b = ra; // b 的类型是 int(不会保留引用)
注意:auto 不会保留引用,需要显式加上 auto&:
auto& c = ra; // c 的类型是 int&
c.数组和 auto:
int arr[3] = {1, 2, 3};
auto p = arr; // p 的类型是 int*,不是 int[3]
d.const 修饰符:
const int x = 42;
auto y = x; // y 的类型是 int(丢失 const)
auto& z = x; // z 的类型是 const int&
e.模板中的 auto:
template <typename T>
void func(T val) { } // 传值时会发生类型退化(decay)int x = 42;
func(x); // T 被推导为 int
decltype 关键字的解析
decltype 主要用于获取表达式的类型,但不会对其进行类型退化(decay)
a.普通变量:
int x = 10;
decltype(x) y; // y 的类型是 int
b.表达式的类型:
int a = 10, b = 20;
decltype(a + b) c; // c 的类型是 int
c.引用的处理:
int x = 10;
int& ref = x;
decltype(ref) y = x; // y 的类型是 int&
d. decltype(auto)用法:
decltype(auto) 结合 decltype 和 auto 的特点,保留所有修饰符:
int x = 10;
int& ref = x;
decltype(auto) z = ref; // z 的类型是 int&
2、vector的resize和reserve有什么区别?
resize:调整容器的大小(元素数量)

#include <iostream>
#include <vector>using namespace std;
int main() {std::vector<int> v = {1, 2, 3};v.resize(5); // 扩展到5个元素,默认填充 0(int 默认构造值)for (int i : v) std::cout << i << " "; // 输出: 1 2 3 0 0 cout << endl;v.resize(2); // 缩小到 2 个元素for (int i : v) std::cout << i << " "; // 输出: 1 2cout << endl;v.resize(4, 9); // 扩展到 4 个元素,新元素填充 9for (int i : v) std::cout << i << " "; // 输出: 1 2 9 9 cout << endl;return 0;
}

reserve:预留容量(内存空间)

#include <iostream>
#include <vector>int main() {std::vector<int> v;v.reserve(5); // 预分配容量为 5std::cout << "Capacity: " << v.capacity() << ", Size: " << v.size() << std::endl;// 输出: Capacity: 5, Size: 0v.push_back(10);std::cout << "Capacity: " << v.capacity() << ", Size: " << v.size() << std::endl;// 输出: Capacity: 5, Size: 1return 0;
}
二者关键区别

3. vector是分配在堆还是栈,sizeof(vector)返回什么值?
vector是分配在堆还是栈?
std::vector 本身是一个类模板,它的对象(即vector实例)通常分配在栈上,但它管理的元素数据是动态分配在堆上的。
具体来说:
- vector对象本身:当你声明一个std::vector变量(比如std::vector v;),这个对象通常是在栈上创建的。它包含一些内部成员(如指向数据的指针、容量大小、元素个数等),这些成员占用固定大小的内存,存储在栈上。
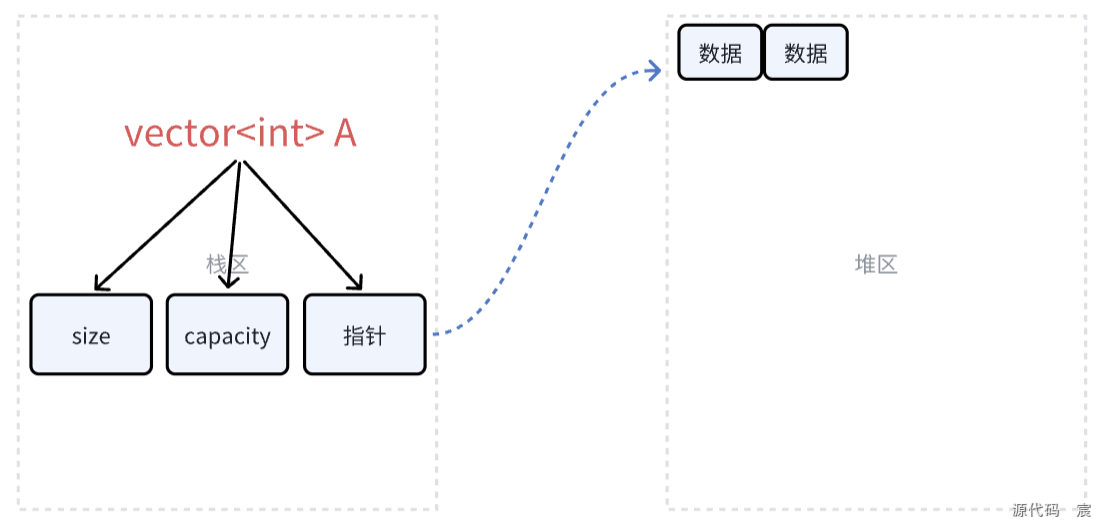
- 元素数据:vector通过动态内存分配(通常使用new或分配器)在堆上存储实际的元素。当你调用push_back或resize等操作时,vector会在堆上分配或重新分配内存来存储这些元素。
一句话:vector对象在栈上,但它管理的元素在堆上。
sizeof(vector)返回什么值?



4. unorderedmap中插入一个元素,它原来的iterater还有效吗?
在 std::unordered_map 中插入一个元素后,原有的迭代器通常仍然有效,但有一个重要的例外:如果插入导致哈希表重新分配内存(rehash),那么所有已有迭代器都会失效。
具体原因解释

示例代码
#include <iostream>
#include <unordered_map>int main() {std::unordered_map<int, std::string> umap;umap[1] = "one"; // 插入第一个元素auto it = umap.find(1); // 获取迭代器std::cout << "Before insert: " << it->second << "\n"; // 输出 "one"umap[2] = "two"; // 插入第二个元素// 检查迭代器是否仍然有效std::cout << "After insert: " << it->second << "\n"; // 通常仍输出 "one"// 假设大量插入导致 rehashfor (int i = 3; i < 60000000; ++i) {umap[i] = std::to_string(i);}// 此时 it 可能已失效,使用它会导致未定义行为// 不要这样做!// std::cout << it->second << "\n"; // 检查迭代器是否仍然有效if (it != umap.end()) {std::cout << it->second << "\n"; // 此时 it 可能已失效,检查是否有效} else {std::cout << "Iterator is invalid after rehash.\n"; // 输出迭代器失效的提示}return 0;
}

5. map中插入一个元素,它原来的iterater还有效吗?
在 std::map 中插入一个元素后,原有的迭代器始终保持有效。
详细解释

示例代码
#include <iostream>
#include <map>
int main() {std::map<int, std::string> myMap;myMap[1] = "one"; // 插入键 1auto it = myMap.find(1); // 获取键 1 的迭代器std::cout << "Before insert: " << it->second << "\n"; // 输出 "one"myMap[2] = "two"; // 插入键 2std::cout << "After insert: " << it->second << "\n"; // 仍然输出 "one",迭代器有效// 插入更多元素myMap[3] = "three";myMap[0] = "zero";std::cout << "After more inserts: " << it->second << "\n"; // 仍然有效,输出 "one"return 0;
}

注意事项
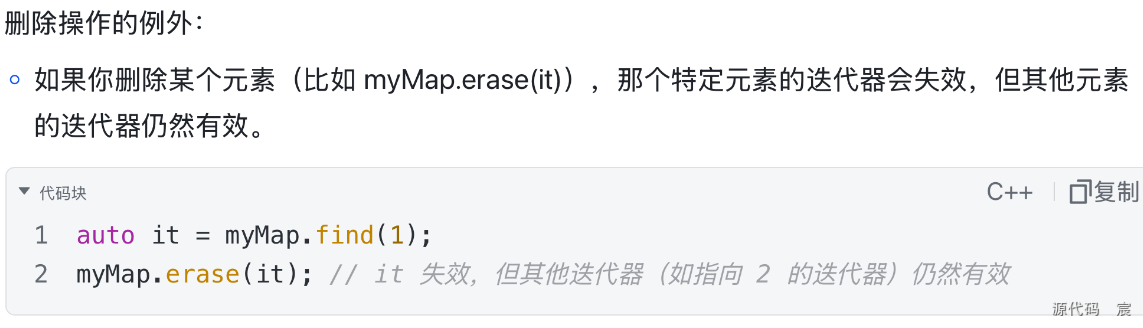
规律

6. shared_ptr是不是线程安全的,为什么?

原因


#include <memory>
#include <thread>//函数
void threadFunc(std::shared_ptr<int> sp) {// 拷贝 sp,增加引用计数std::shared_ptr<int> local = sp;// local 离开作用域,减少引用计数
}int main() {auto sp = std::make_shared<int>(42);std::thread t1(threadFunc, sp);std::thread t2(threadFunc, sp);t1.join();t2.join();// sp 的引用计数安全更新,最终销毁return 0;
}
这里两个线程同时拷贝和销毁 sp,引用计数的变化是线程安全的,最终对象在引用计数为 0 时正确销毁。

#include <memory>
#include <thread>
void threadFunc(std::shared_ptr<int>& sp) {sp = std::make_shared<int>(10); // 修改 sp
}
int main() {auto sp = std::make_shared<int>(42);std::thread t1(threadFunc, std::ref(sp));std::thread t2(threadFunc, std::ref(sp));t1.join();t2.join();// 未定义行为:两个线程同时修改 spreturn 0;
}
这里两个线程同时对 sp 赋值,会导致数据竞争,结果不可预测。
修改后
#include <memory>
#include <thread>
#include <mutex>std::mutex mtx;void threadFunc(std::shared_ptr<int>& sp) {std::lock_guard<std::mutex> lock(mtx); // 确保在修改 sp 时加锁sp = std::make_shared<int>(10); // 修改 sp
}int main() {auto sp = std::make_shared<int>(42);std::thread t1(threadFunc, std::ref(sp));std::thread t2(threadFunc, std::ref(sp));t1.join();t2.join();return 0;
}
7. 把uniqueptr move到sharedptr会发生什么? (高频)
将 std::unique_ptr 移动到 std::shared_ptr 是安全的,且 std::shared_ptr 会接管资源的生命周期,而原 std::unique_ptr 变为空。

示例代码
#include <iostream>
#include <memory>int main() {std::unique_ptr<int> uptr = std::make_unique<int>(10);std::shared_ptr<int> sptr = std::move(uptr); // 资源转移std::cout << "uptr is " << (uptr ? "not empty" : "empty") << std::endl;std::cout << "sptr use count: " << sptr.use_count() << std::endl;return 0;
}

注意事项

8. weak_ptr的作用是什么?它与shared_ptr的区别是什么?
std::weak_ptr 的作用

使用 std::weak_ptr 防止循环引用
如果两个对象相互持有 std::shared_ptr,则引用计数不会归零,导致内存泄漏。使用 std::weak_ptr 可以解决这个问题。
#include <iostream>
#include <memory>struct B;struct A {std::shared_ptr<B> ptr;~A() { std::cout << "A destroyed\n"; }
};struct B {std::shared_ptr<A> ptr;~B() { std::cout << "B destroyed\n"; }
};int main() {auto a = std::make_shared<A>();auto b = std::make_shared<B>();a->ptr = b; // A 拥有 Bb->ptr = a; // B 拥有 A(循环引用)//问题是:a 和 b 互相持有 shared_ptr,//即使 main() 结束,它们的 use_count 仍大于 0,导致内存泄漏。return 0; // 资源无法释放,导致内存泄漏
}
使用 std::weak_ptr 解决循环引用
#include <iostream>
#include <memory>struct B;
struct A {std::weak_ptr<B> ptr; // 改为 weak_ptr,避免循环引用~A() { std::cout << "A destroyed\n"; }
};
struct B {std::shared_ptr<A> ptr;~B() { std::cout << "B destroyed\n"; }
};int main() {auto a = std::make_shared<A>();auto b = std::make_shared<B>();a->ptr = b; // A 持有 B(弱引用,不增加计数)b->ptr = a; // B 持有 A(共享所有权)return 0; // 资源正常释放,不会内存泄漏
}
在 main() 函数的结尾,a 和 b 都超出了作用域,shared_ptr 的引用计数会被减少。
由于 A 中的 ptr 是 std::weak_ptr,它不会增加 B 的引用计数,所以 B 可以正常销毁。
当 B 被销毁时,A 也可以被销毁,因为 B 不再持有 A 的共享所有权。

std::weak_ptr 的 lock() 方法
由于 weak_ptr 不能直接访问对象,如果想访问对象,需要使用 .lock() 方法将其转换为 shared_ptr:
std::weak_ptr<int> wptr = sptr; // sptr 是一个 std::shared_ptr<int>
if (auto spt = wptr.lock()) { // 获取 std::shared_ptr<int>std::cout << "Value: " << *spt << std::endl;
} else {std::cout << "Object has been destroyed" << std::endl;
}
9、HTTP/2和HTTP/1.1的主要区别是什么?
HTTP 基本概念
HTTP 是超文本传输协议,也就是HyperText Transfer Protocol。
HTTP 是一种在计算机世界里专门在 两点 之间 传输 文字、图片、音频、视频等 超文本 数据的 约定和规范。
HTTP/2 vs HTTP/1.1 的主要区别
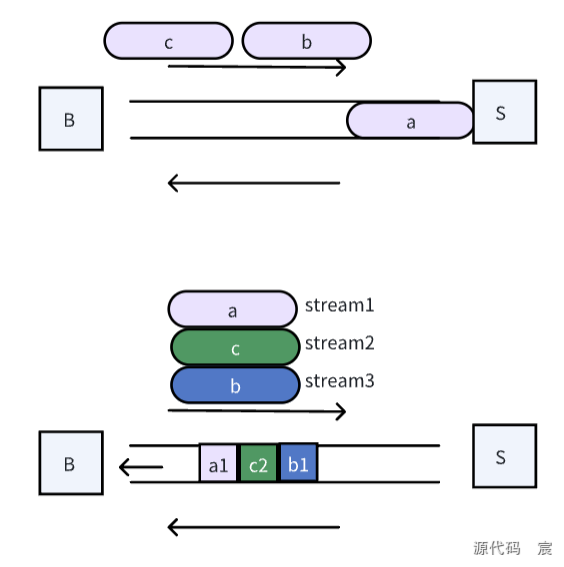


并发传输, HTTP/2 就很⽜逼了,引出了 Stream 概念,多个 Stream 复⽤在⼀条 TCP 连接。
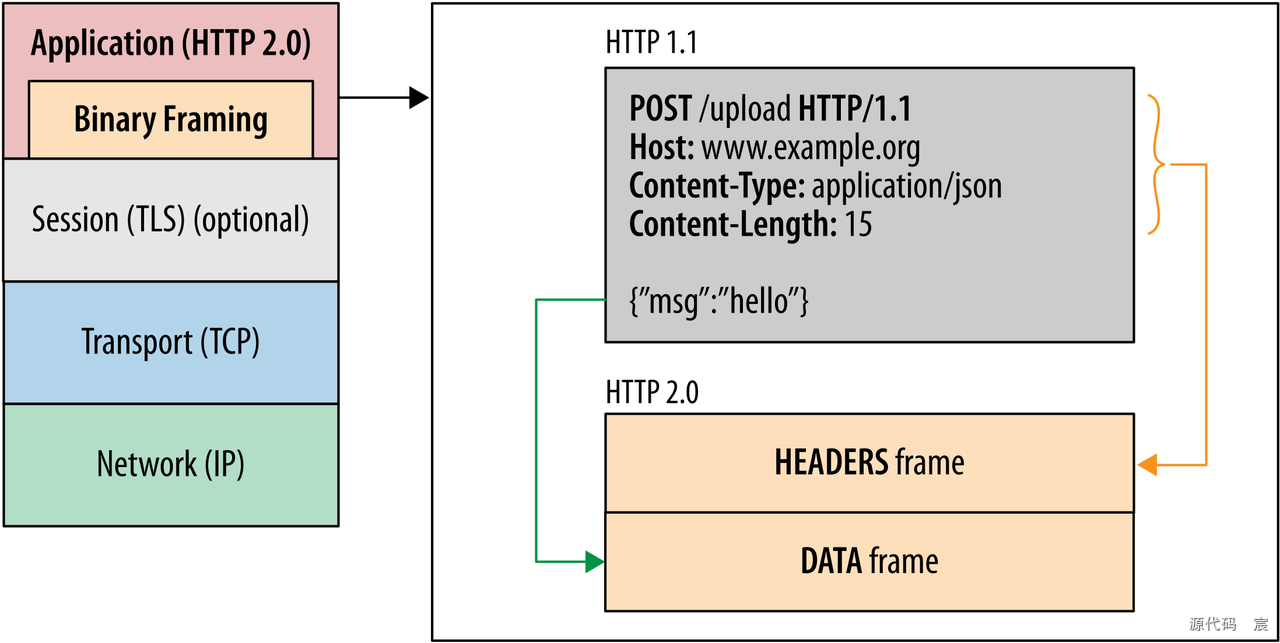
从上图可以看到,1 个 TCP 连接包含多个 Stream,Stream ⾥可以包含 1 个或多个
Message,Message 对应 HTTP/1 中的请求或响应,由 HTTP 头部和包体构成。Message ⾥包含⼀条或者多个 Frame,Frame 是 HTTP/2 最⼩单位,以⼆进制压缩格式存放 HTTP/1 中的内容(头部和包体)。


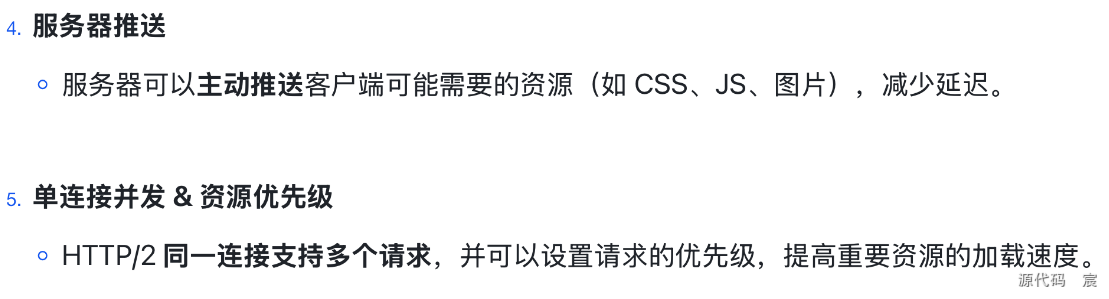
HTTP/2 的关键改进

示例:HTTP/1.1 vs HTTP/2 传输过程
HTTP/1.1:
客户端:请求 index.html
服务器:返回 index.html
客户端:请求 style.css
服务器:返回 style.css
客户端:请求 script.js
服务器:返回 script.js
每个请求是串行的,导致阻塞。
HTTP/2:
客户端:请求 index.html、style.css、script.js(同时)
服务器:返回 index.html、style.css、script.js(同时)
多个请求并行进行,减少延迟。
10. 使用 std::function 和 std::bind 绑定一个类成员函数,并调用它。

代码示例
#include <iostream>
#include <functional> // 包含 std::function 和 std::bindclass MyClass {
public:// 一个成员函数,接受两个参数void print(int x, const std::string& s) {std::cout << "x = " << x << ", s = " << s << std::endl;}
};int main() {MyClass obj; // 创建一个 MyClass 对象// 使用 std::function 声明一个函数对象std::function<void(int, const std::string&)> func;// 使用 std::bind 绑定 MyClass 的成员函数 print// std::placeholders::_1 和 _2 分别表示第一个和第二个参数的占位符/*&MyClass::print:表示要绑定的成员函数。&MyClass::print 是指向 MyClass 类成员函数 print 的指针。&obj:表示 print 函数的第一个参数(this 指针),即 obj 是调用 print 成员函数的对象。因此,&obj 是 print 函数的隐式 this 指针。std::placeholders::_1 和 std::placeholders::_2:占位符用于表示待绑定的参数。这些占位符将被调用时的实际参数替代。_1 对应第一个参数,_2 对应第二个参数。*/func = std::bind(&MyClass::print, &obj, std::placeholders::_1, std::placeholders::_2);// 调用绑定的函数func(42, "Hello, World!"); // 预期输出: x = 42, s = Hello, World!return 0;
}


面试中的可能追问和应对
1. “为什么用 std::bind 而不用 lambda?”
- 回答:
- std::bind 和 lambda 都可以实现类似功能,但 std::bind 是 C++11 引入的工具,专门为绑定函数和参数设计,语法更简洁,尤其在需要占位符时。
- 用 lambda 也可以,比如:
std::function<void(int, const std::string&)> func = [&obj](int x, const std::string& s) {obj.print(x, s);
};
- 但 lambda 更灵活,适合复杂逻辑,std::bind 更适合简单绑定。


11. 如何重载[]操作符? 写一个例子
重载 [] 操作符,就是说可以让你自定义类对象使用方括号访问数据(例如 obj[index])。
实现方式

示例代码
#include <iostream>
#include <stdexcept>
using namespace std;
class MyArray {
private:int* data; // 动态分配的数组int size; // 数组大小
public:// 构造函数MyArray(int s) : size(s) {data = new int[size];for (int i = 0; i < size; i++) {data[i] = 0; // 初始化}}// 非 const 版本:支持读写int& operator[](int index) {if (index < 0 || index >= size) {throw out_of_range("Index out of bounds");}return data[index];}// const 版本:仅支持读取const int& operator[](int index) const {if (index < 0 || index >= size) {throw out_of_range("Index out of bounds");}return data[index];}// 析构函数~MyArray() {delete[] data;}
};
int main() {MyArray arr(3);// 测试读写arr[1] = 10; // 使用非 const 版本cout << arr[1] << endl; // 输出 10// 测试 const 对象const MyArray constArr(3);cout << constArr[1] << endl; // 使用 const 版本,输出 0// 测试越界try {arr[5] = 100;} catch (const out_of_range& e) {// e.what() 是 std::exception 类(out_of_range 是从 std::exception 继承的)中的一个成员函数,用来返回异常的描述信息。cout << e.what() << endl; // 输出 "Index out of bounds"}return 0;
}

面试官也可能问到的要点


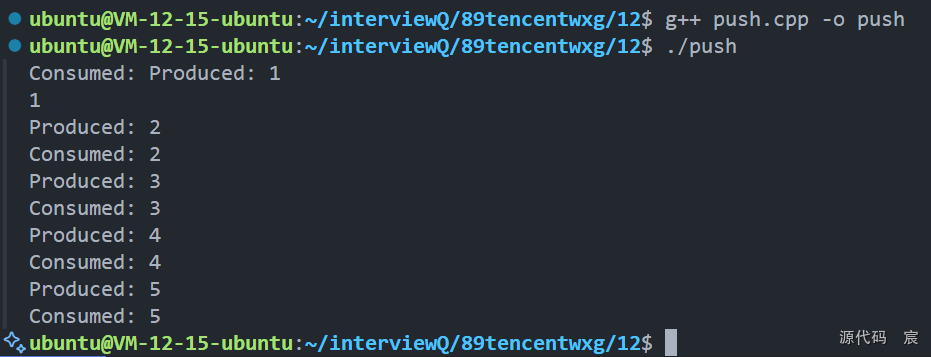
12. 假设你要实现一个线程安全的队列,其中 push 和 pop 需要支持多个线程并发访问,如何设计?请实现该数据结构
基于 mutex 和 condition_variable 的线程安全队列
#include <iostream>
#include <queue>
#include <mutex>
#include <condition_variable>
#include <thread>//模版
template <typename T>
class ThreadSafeQueue {
private:std::queue<T> queue;std::mutex mtx; //锁std::condition_variable cv; //条件变量public:void push(T value) {std::lock_guard<std::mutex> lock(mtx);queue.push(value);cv.notify_one(); // 通知等待的线程}T pop() {std::unique_lock<std::mutex> lock(mtx);cv.wait(lock, [this] { return !queue.empty(); }); // 等待直到队列非空T value = queue.front();queue.pop();return value;}
};//生产者
void producer(ThreadSafeQueue<int>& tsq) {for (int i = 1; i <= 5; ++i) {tsq.push(i);std::cout << "Produced: " << i << "\n";std::this_thread::sleep_for(std::chrono::milliseconds(100));}
}//消费者
void consumer(ThreadSafeQueue<int>& tsq) {for (int i = 1; i <= 5; ++i) {int value = tsq.pop();std::cout << "Consumed: " << value << "\n";}
}int main() {ThreadSafeQueue<int> tsq;std::thread t1(producer, std::ref(tsq));std::thread t2(consumer, std::ref(tsq));t1.join();t2.join();return 0;
}

13. 代码实现:给定一个数组,找出数组中重复的数。
使用 unordered_set 存储已经访问过的元素,如果遇到重复元素,则直接返回。
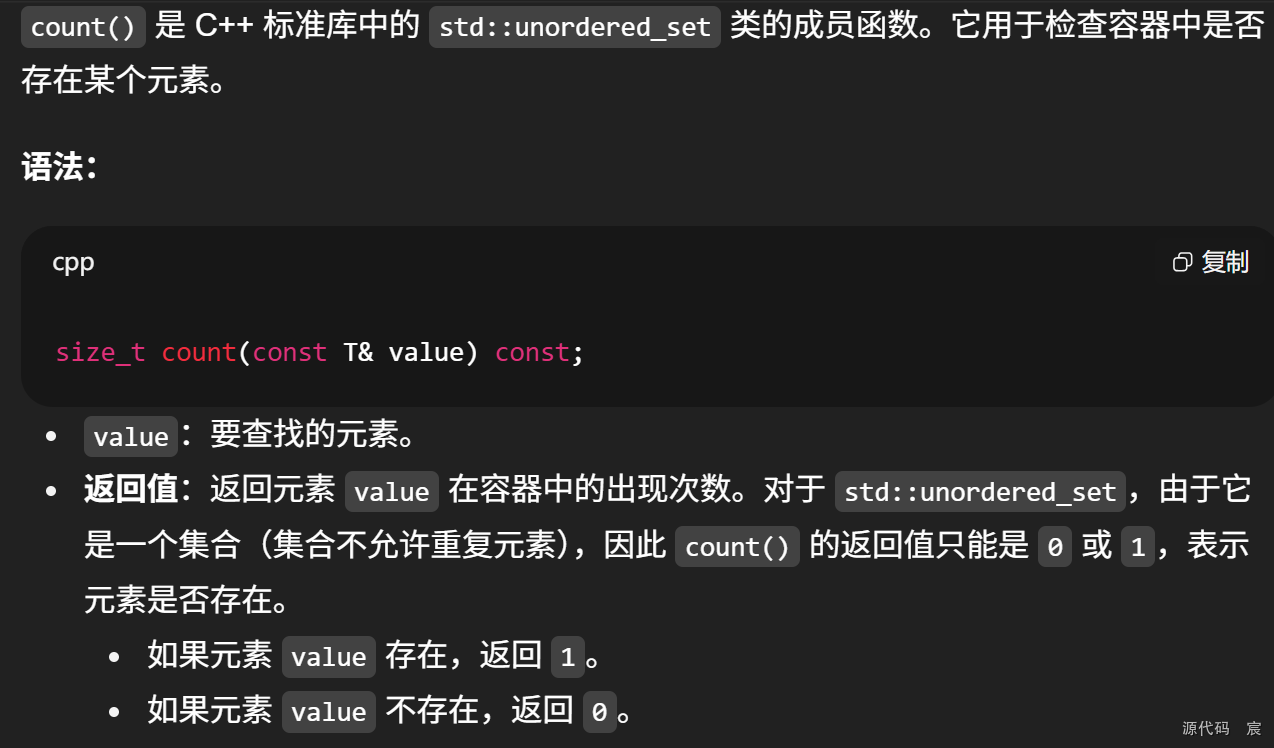
count() 是 C++ 标准库中的 std::unordered_set 类的成员函数。它用于检查容器中是否存在某个元素。
#include <iostream>
#include <vector>
#include <unordered_set>void findDuplicates(const std::vector<int>& nums) {std::unordered_set<int> st;for(const int& num: nums) {if(st.count(num)) {std::cout << "重复的数: " << num << std::endl;} else {st.insert(num);}}
}int main() {std::vector<int> nums = {4, 3, 2, 7, 8, 2, 3, 1};findDuplicates(nums);return 0;
}

优点:
- 线性时间复杂度 O(n),适用于大规模数据。
- 使用 unordered_set 提高查找效率。
14. 代码实现:反转链表
就是Leetcode—206.反转链表【简单】,我的博客提供了一题多解
给定一个单链表的头节点,反转整个链表并返回新的头节点。
示例:输入 1->2->3->4->5->NULL,输出 5->4->3->2->1->NULL。
解题思路
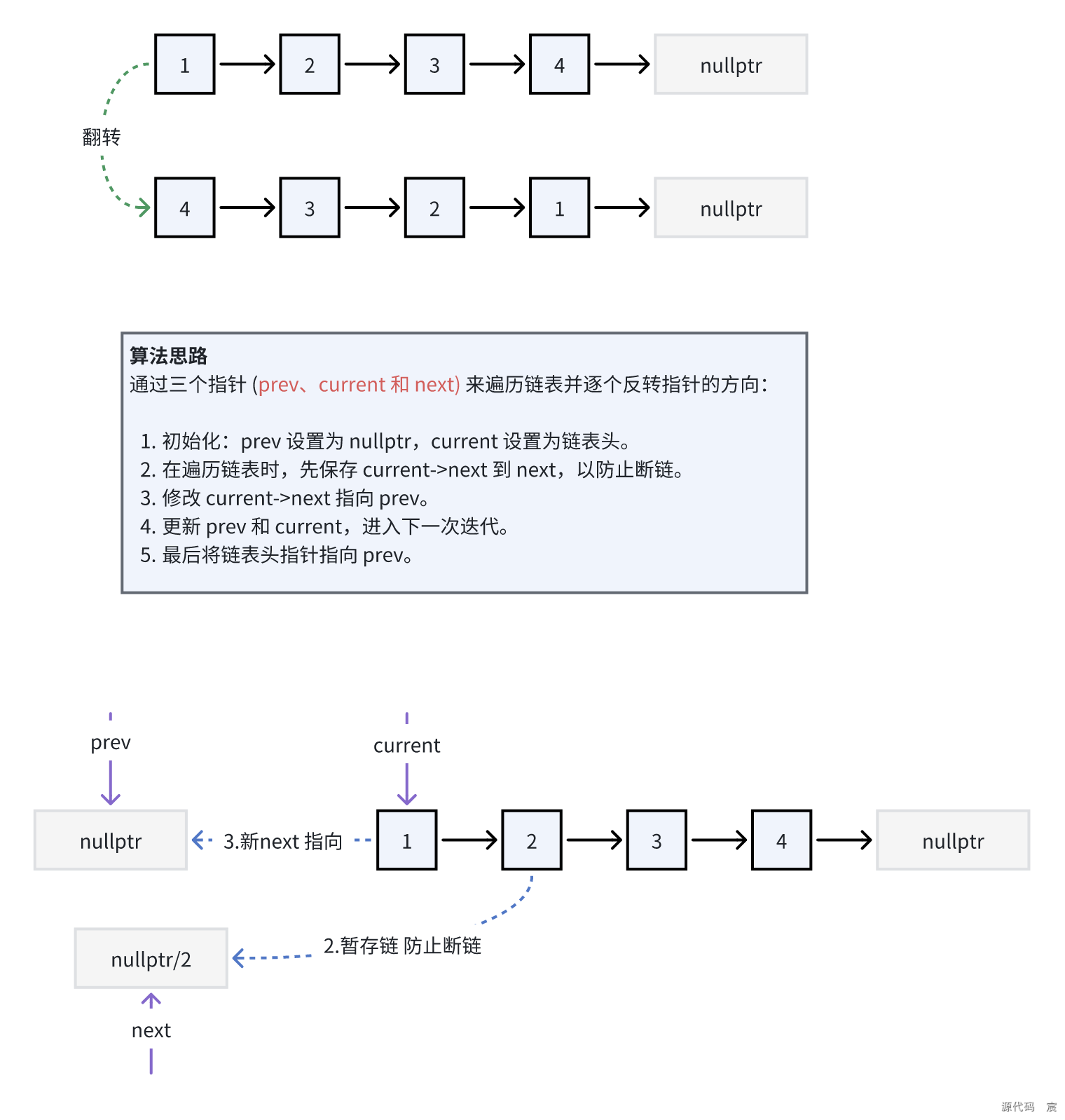
代码实现
#include <iostream>
struct ListNode {int val;ListNode* next;ListNode(int x) : val(x), next(nullptr) {}
};
ListNode* reverseList(ListNode* head) {ListNode* prev = nullptr;ListNode* curr = head;while (curr != nullptr) {ListNode* nextTemp = curr->next; // 保存下一个节点curr->next = prev; // 反转指针prev = curr; // 前进curr = nextTemp;}return prev; // 新的头节点
}
// 测试代码
int main() {ListNode* head = new ListNode(1);head->next = new ListNode(2);head->next->next = new ListNode(3);head->next->next->next = new ListNode(4);ListNode* newHead = reverseList(head);ListNode* curr = newHead;while (curr) {std::cout << curr->val << " ";curr = curr->next;}return 0;
}
说明:
- 时间复杂度:O(n),n 是链表长度。
- 空间复杂度:O(1),只用了几个指针。
15. 代码实现:实现一个线程安全的单例模式
#include <iostream>
#include <mutex>
class Singleton {
private:static Singleton* instance;static std::mutex mtx;Singleton() { std::cout << "Singleton created\n"; } // 私有构造函数
public:Singleton(const Singleton&) = delete; // 禁止拷贝Singleton& operator=(const Singleton&) = delete; // 禁止赋值static Singleton* getInstance() {std::lock_guard<std::mutex> lock(mtx); // 线程安全if (instance == nullptr) {instance = new Singleton();}return instance;}
};
// 静态成员初始化
Singleton* Singleton::instance = nullptr;
std::mutex Singleton::mtx;
// 测试代码
int main() {Singleton* s1 = Singleton::getInstance();Singleton* s2 = Singleton::getInstance();std::cout << "s1: " << s1 << ", s2: " << s2 << std::endl; // 地址相同return 0;
}
说明:
- 使用 std::mutex 和 std::lock_guard 确保线程安全。
- C++11 后可以用 static 局部变量实现更简洁的线程安全单例(Meyers’ Singleton),但这里展示传统方式。
最优解——使用C++11标准的局部静态变量
#include <iostream>
#include <mutex>class Singleton {
private:Singleton() { std::cout << "Singleton created\n"; } // 私有构造函数public:// 禁止拷贝Singleton(const Singleton&) = delete;// 禁止赋值Singleton& operator=(const Singleton&) = delete;// 静态局部变量,线程安全static Singleton& getInstance() {static Singleton instance;return instance;}
};int main() {Singleton& s1 = Singleton::getInstance();Singleton& s2 = Singleton::getInstance();std::cout << "s1: " << &s1 << ", s2: " << &s2 << std::endl; // 地址相同return 0;
}

之后我会持续更新,如果喜欢我的文章,请记得一键三连哦,点赞关注收藏,你的每一个赞每一份关注每一次收藏都将是我前进路上的无限动力 !!!↖(▔▽▔)↗感谢支持!