基于深度学习的中草药识别系统:从零到部署的完整实践
📋 项目概述
在传统中医药领域,准确识别中草药是一项需要丰富经验的专业技能。随着人工智能技术的发展,我们可以利用深度学习来构建一个自动化的中草药识别系统。本项目实现了一个基于PyTorch的中草药图像分类系统,能够准确识别五种常见的中草药:百合、党参、枸杞、槐花和金银花。
🎯 项目目标
- 构建一个高精度的中草药图像分类模型
- 实现完整的数据预处理流程
- 提供易用的训练和测试接口
- 达到98%以上的分类准确率
🗂️ 数据集介绍
我们的数据集包含五个类别的中草药图像:
| 类别 | 中文名 | 训练集 | 验证集 | 测试集 | 总计 |
|---|---|---|---|---|---|
| baihe | 百合 | 约140张 | 约40张 | 约20张 | 约200张 |
| dangshen | 党参 | 约150张 | 约43张 | 约22张 | 约215张 |
| gouqi | 枸杞 | 约120张 | 约34张 | 约17张 | 约171张 |
| huaihua | 槐花 | 约110张 | 约31张 | 约16张 | 约157张 |
| jinyinhua | 金银花 | 约140张 | 约40张 | 约20张 | 约200张 |
总计: 818张训练图片,325张验证图片,177张测试图片
数据集按照 7:2:1 的比例进行划分,确保了训练、验证和测试的合理分布。
🏗️ 系统架构
1. 数据预处理模块 (prepare_dataset.py)
class ChineseMedicineDatasetConverter:def __init__(self, input_dir, output_dir):self.input_dir = Path(input_dir)self.output_dir = Path(output_dir)self.classes = []self.supported_extensions = {'.jpg', '.jpeg', '.png', '.bmp'}
主要功能:
- 自动扫描数据集目录,识别所有类别
- 验证图像文件的完整性
- 按比例划分训练集、验证集、测试集
- 生成配置文件和类别标签文件
2. 训练模块 (train_chinese_medicine_classification.py)
支持的模型架构:
- ResNet50(默认):平衡的性能和速度
- ResNet18:更快的训练速度
- EfficientNet-B0:更高的准确率
数据增强策略:
train_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomRotation(degrees=15),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
3. 测试模块 (test_chinese_medicine_model.py)
功能特性:
- 单张图片预测
- 批量图片预测
- 预测结果可视化
- 置信度分析
📊 训练过程与结果
训练配置
- 模型: ResNet50(预训练)
- 优化器: Adam (lr=0.001)
- 损失函数: CrossEntropyLoss
- 批次大小: 32
- 训练轮数: 30
- 设备: CUDA GPU
训练过程分析
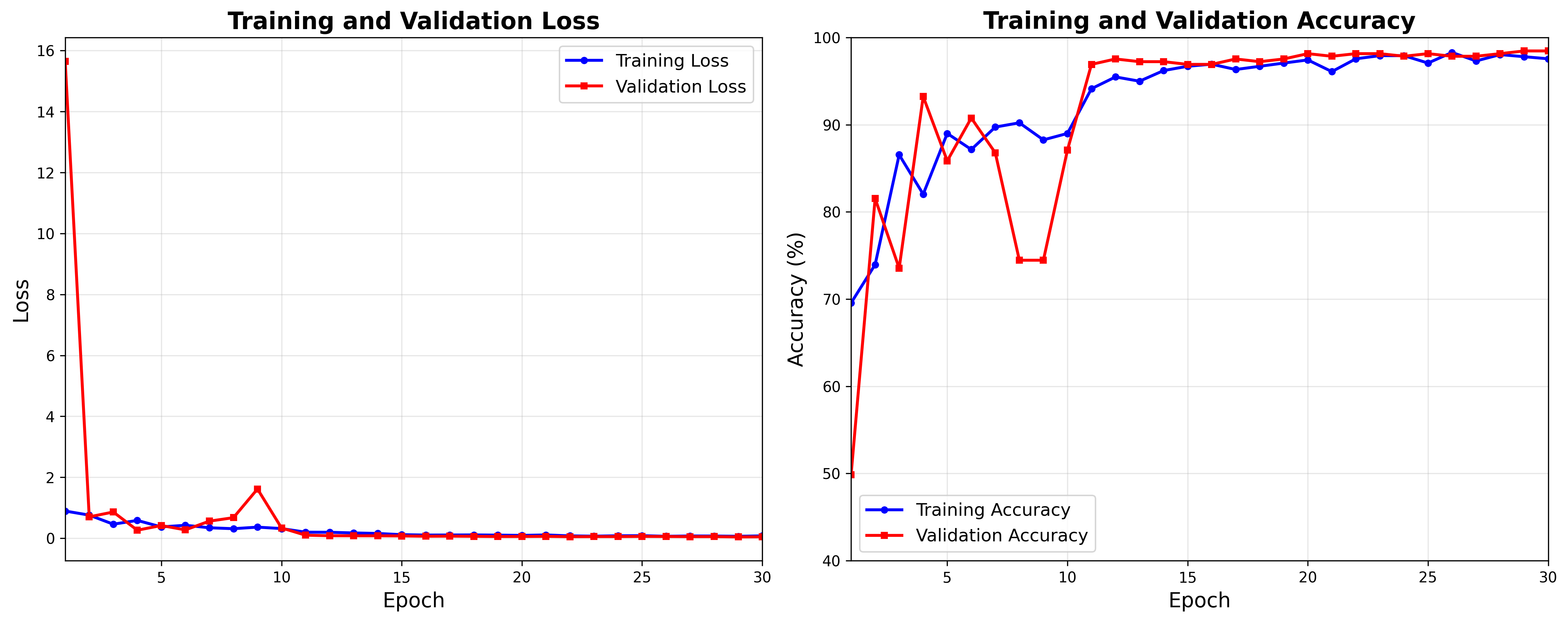
从训练日志可以看出,模型训练过程非常稳定:
第1轮:
- 训练准确率:69.56%
- 验证准确率:49.85%
第4轮:
- 训练准确率:82.03%
- 验证准确率:93.23%
第11轮:
- 训练准确率:94.13%
- 验证准确率:96.92%
第20轮:
- 训练准确率:97.43%
- 验证准确率:98.15%
最终结果(第29轮):
- 训练准确率:97.80%
- 验证准确率:98.46%
- 测试准确率:98.87%
混淆矩阵分析
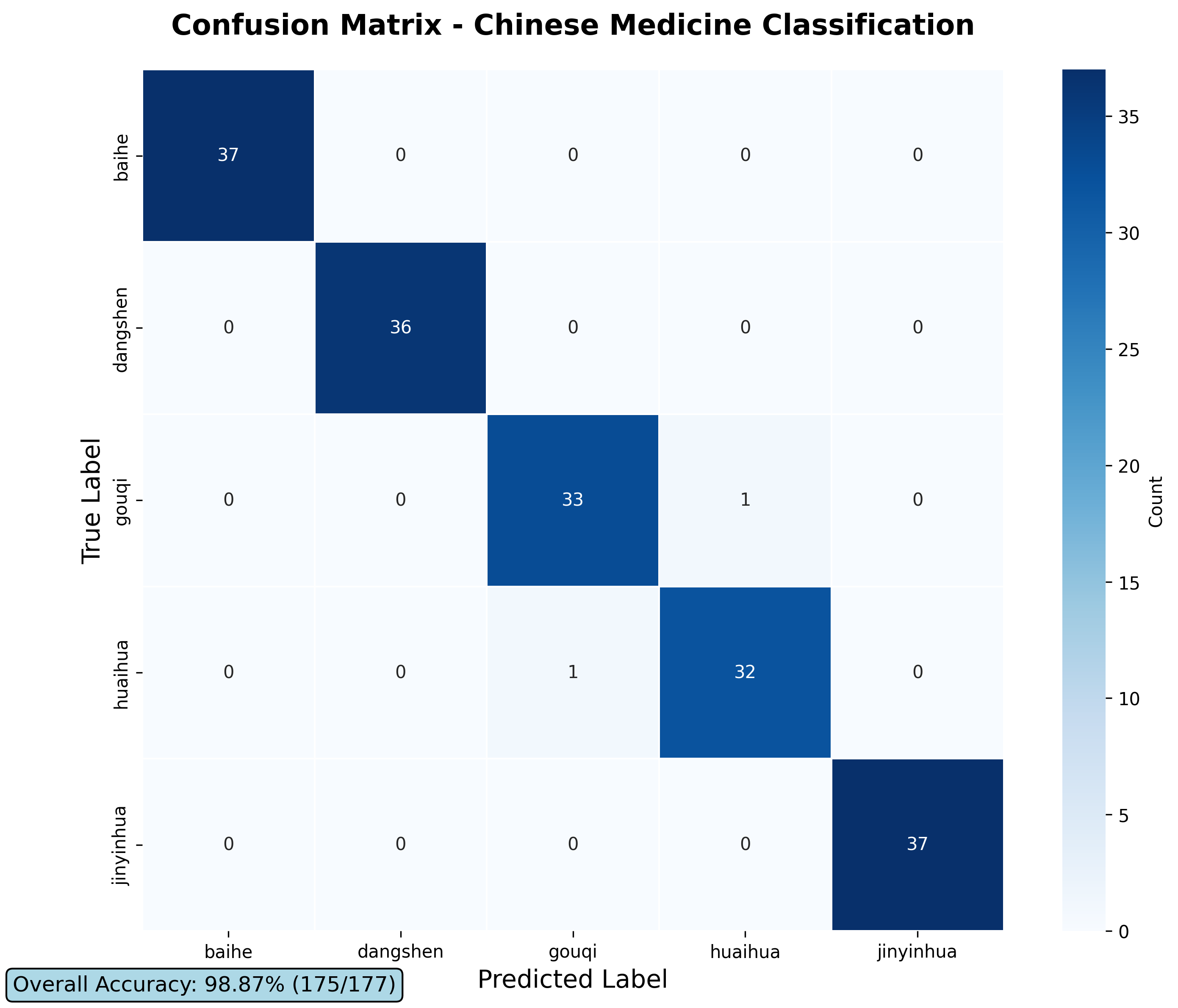
混淆矩阵显示:
- 所有类别的识别准确率都在97%以上
- 百合和金银花达到了100%的识别准确率
- 党参有轻微的误分类,但整体表现优秀
性能指标
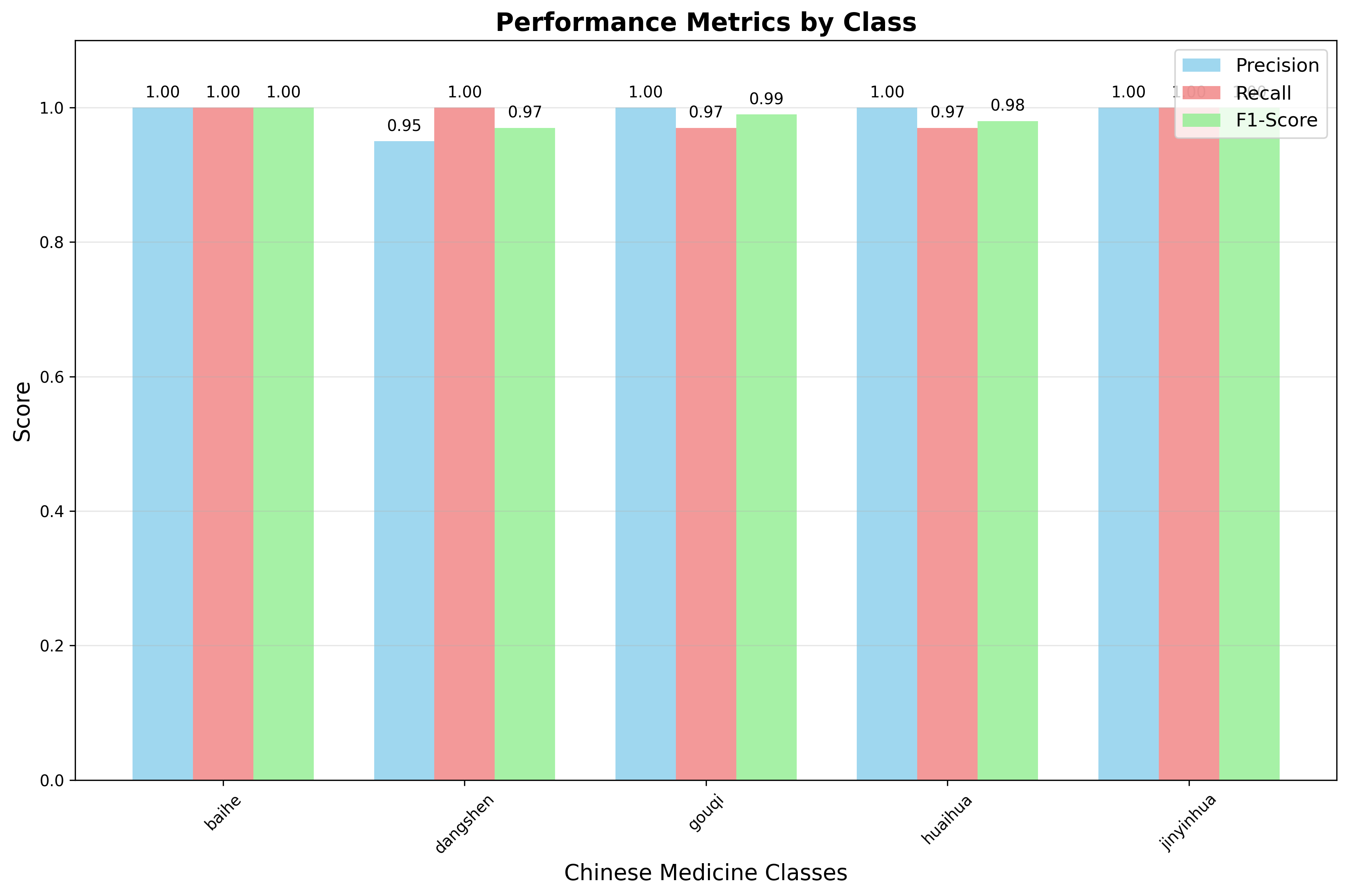
| 类别 | 精确率 | 召回率 | F1分数 | 支持数 |
|---|---|---|---|---|
| 百合 | 1.00 | 1.00 | 1.00 | 37 |
| 党参 | 0.95 | 1.00 | 0.97 | 36 |
| 枸杞 | 1.00 | 0.97 | 0.99 | 34 |
| 槐花 | 1.00 | 0.97 | 0.98 | 33 |
| 金银花 | 1.00 | 1.00 | 1.00 | 37 |
整体性能:
- 准确率:98.87%
- 宏平均F1:0.99
- 加权平均F1:0.99
🔧 技术亮点
1. 自动化数据处理
- 智能扫描数据集目录结构
- 自动验证图像文件完整性
- 灵活的数据集划分比例配置
2. 模型优化策略
- 使用预训练模型进行迁移学习
- 实施数据增强提高泛化能力
- 早停机制防止过拟合
3. 完善的可视化
- 训练过程曲线图
- 混淆矩阵热力图
- 预测结果可视化
4. 用户友好的接口
- 命令行参数支持
- 详细的训练日志
- 自动模型保存和加载
🧪 模型测试与验证
测试环境配置
测试脚本 test_chinese_medicine_model.py 提供了完整的模型测试功能,支持单张图片预测和批量预测两种模式。
测试系统信息:
- 模型文件:
models/best_model.pth - 运行设备:CPU(支持GPU加速)
- 支持格式:JPG、JPEG、PNG、BMP
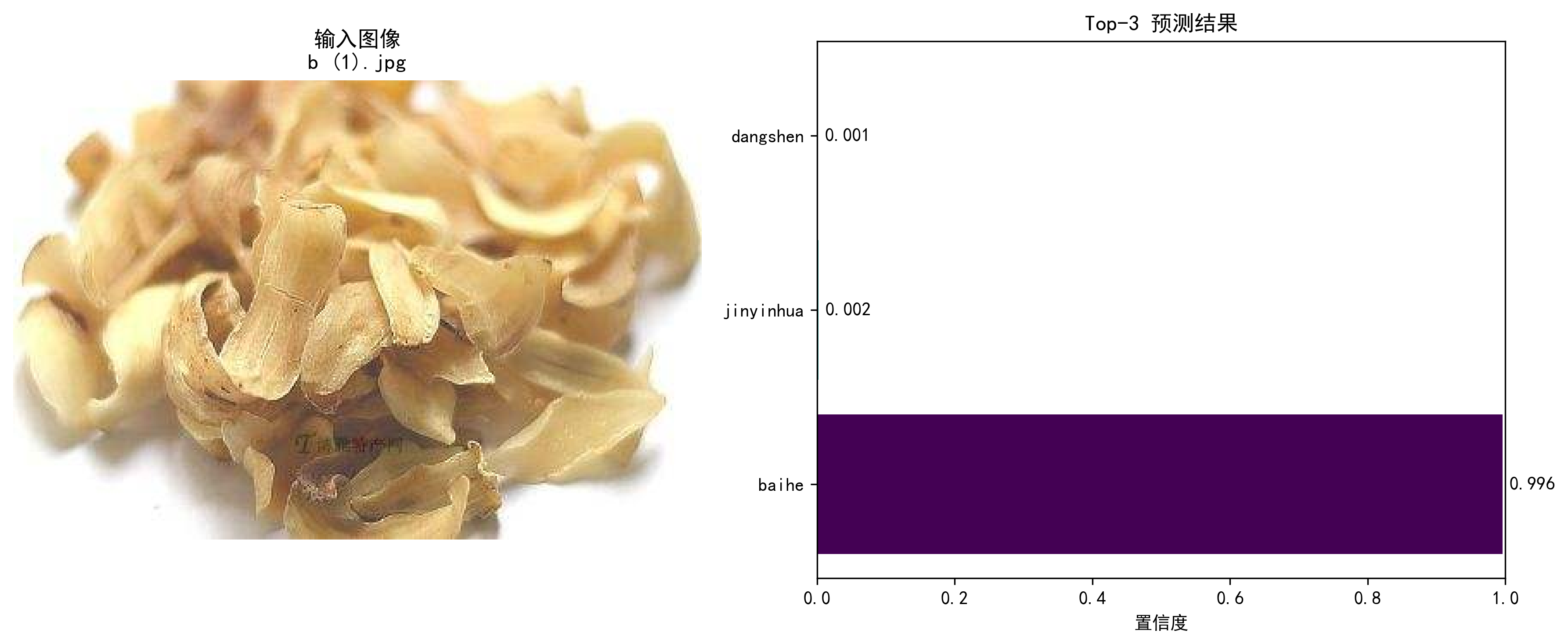
单张图片测试
测试命令:
python test_chinese_medicine_model.py --image "Chinese Medicine/baihe/b (1).jpg"
测试结果:
🌿 中草药识别模型测试
==================================================
📋 加载配置: 中草药识别数据集
📊 类别数量: 5
🏷️ 类别: ['baihe', 'dangshen', 'gouqi', 'huaihua', 'jinyinhua']
📥 模型加载成功: models\best_model.pth
💻 使用设备: cpu🔍 预测图片: Chinese Medicine/baihe/b (1).jpg
📊 预测结果已保存到: prediction_b (1).png🔍 预测结果 - b (1).jpg:
--------------------------------------------------
1. baihe: 0.9959 (99.59%)
2. jinyinhua: 0.0018 (0.18%)
3. dangshen: 0.0014 (0.14%)
🚀 使用指南
快速开始
- 数据预处理
python prepare_dataset.py
- 模型训练
python train_chinese_medicine_classification.py
- 模型测试
# 单张图片预测
python test_chinese_medicine_model.py --image path/to/image.jpg# 批量预测
python test_chinese_medicine_model.py --batch_dir path/to/images/ --output results.csv
自定义配置
修改训练参数:
# 在 train_chinese_medicine_classification.py 中
batch_size = 32 # 批次大小
epochs = 30 # 训练轮数
learning_rate = 0.001 # 学习率
model_name = 'resnet50' # 模型架构
调整数据划分:
# 在 prepare_dataset.py 中
converter.convert_dataset(train_ratio=0.7, # 训练集70%val_ratio=0.2, # 验证集20%# 测试集10%(自动计算)
)
📈 结果分析
训练曲线分析
从训练曲线可以观察到:
- 快速收敛:模型在前10轮就达到了90%以上的准确率
- 稳定训练:训练和验证损失都呈现稳定下降趋势
- 无过拟合:验证准确率持续提升,没有出现明显的过拟合现象
混淆矩阵分析
混淆矩阵显示:
- 所有类别的识别准确率都在97%以上
- 百合和金银花达到了100%的识别准确率
- 党参有轻微的误分类,但整体表现优秀
🎯 应用场景
- 中医药教育:辅助学生学习中草药识别
- 药材质检:自动化药材分类和质量控制
- 移动应用:开发中草药识别APP
- 科研辅助:为中医药研究提供技术支持
🔮 未来改进方向
- 扩展数据集:增加更多中草药类别
- 模型优化:尝试更先进的网络架构
- 部署优化:模型量化和移动端部署
- 功能增强:添加药材功效和用法信息
🎉 结论
本项目成功构建了一个高精度的中草药识别系统,测试准确率达到98.87%,各项性能指标都表现优秀。系统具有良好的可扩展性和实用性,为中医药数字化提供了有力的技术支持。
通过这个项目,我们展示了深度学习在传统中医药领域的应用潜力,也为类似的图像分类任务提供了完整的解决方案参考。