现代数据采集系列(四):数据采集的安全红线-审计、血缘与合规
在前文中,我们构建了数据采集的“预防性”安全体系——通过凭证、传输和访问控制(SSO/RBAC)来“严守大门”。然而,安全闭环的终点不是预防,而是问责(Accountability)。当预防措施被(合法或非法)绕过时,一个无法回答“谁、在何时、做了什么”的系统,在合规性上等同于零。
本文将深入探讨“检测性”安全。我们将论证,Web原生(B/S)架构的“集中管控”特性,不仅是运维的福音,更是实现“不可抵赖”审计的唯一架构。我们将拆解一个完备审计体系的三大支柱:操作审计(谁动了配置)、运行时审计(任务跑得如何)和数据血缘(数据的“前世今生”),并阐述它们如何共同构筑起满足现代数据合规(Data Compliance)的基石。

1. 为什么“审计”是B/S架构的灵魂?
在(一)中我们批判了C/S架构的“手工作坊”模式。其在审计上的缺陷是与生俱来的:
日志分散: 操作日志存储在开发者本地电脑,可以被随意篡改或删除。
身份模糊: 多个开发者可能共享一个高权限的
db_admin账户进行ETL开发,出事后无法定责到“自然人”。“黑盒”执行: 脚本(如
.ktr文件)在服务器上执行,但其日志与“谁触发了它”之间的关联是脱钩的。
Web原生(B/S)架构从根本上解决了这个问题。
它的核心是“集中化”与“身份先行”。如前文所述,一个现代平台必须集成SSO。这意味着,任何操作的发起者,不再是模糊的IP或共享账户,而是通过企业身份认证的、唯一的“自然人”(如zhangsan@company.com)。
B/S平台作为所有“设计时”配置和“运行时”任务的唯一强制网关,使其天然成为了一个“中央审计中心”。它具备了记录所有行为并将其精确归因到人的能力。这种“不可抵赖性”是C/S架构永远无法实现的,也是现代数据合规(如《数据安全法》、GDPR、SOX法案)的最低要求。
2. 审计支柱一:“操作审计” (谁动了“配置”?)
“检测性”安全的第一层,是审计“设计时”(Design-Time)的行为。
风险场景: 一个拥有合法权限的内部开发者(dev_zhangsan),在深夜11点修改了“生产环境-客户主数据”的采集任务。他没有偷凭证,只是在该任务的“目标端”增加了一个新的目标:他自己在公有云上的个人S3存储桶。
这个操作是“合法的”(通过了RBAC),但却是“恶意的”。“预防性”安全(RBAC)在此刻失效了。
解决方案:不可篡改的“4W”操作日志
此时,“检测性”审计必须登场。平台必须记录下所有对“元数据”(即连接、任务、调度等配置)的**CRUD(增删改查)**操作。一个合格的审计日志必须包含“4W”:
Who(谁): 必须是SSO登录后的自然人ID(
zhangsan@company.com),而非admin。When(何时): 精确到毫秒的UTC时间戳。
Where(何地): 登录的源IP地址。
What(做了什么): 这是最关键的。
(差的日志):“用户
zhangsan更新了任务Task-101”。—— (毫无意义)(好的日志):“用户
zhangsan更新了任务Task-101。[Diff]:targets字段新增{"type": "S3", "bucket": "zhangsan-personal-bucket", ...}”。
一个现代Web平台,必须能够提供配置的“Diff”日志,清晰地显示“改了什么”。
安全闭环: 仅有日志还不够,必须确保其“不可篡改”。平台管理员(Admin)理论上可以登录数据库删除自己的操作日志。因此,这些审计日志必须**实时流式(Streaming)地发送到企业独立的、WORM(Write-Once, Read-Many)**的日志中心或SIEM平台(如Splunk, ELK)。这样,即使平台自身被攻破,其“犯罪记录”也已在外部存证。
3. 审计支柱二:“运行时审计” (任务“跑得”如何?)
“检测性”安全的第二层,是审计“运行时”的行为。
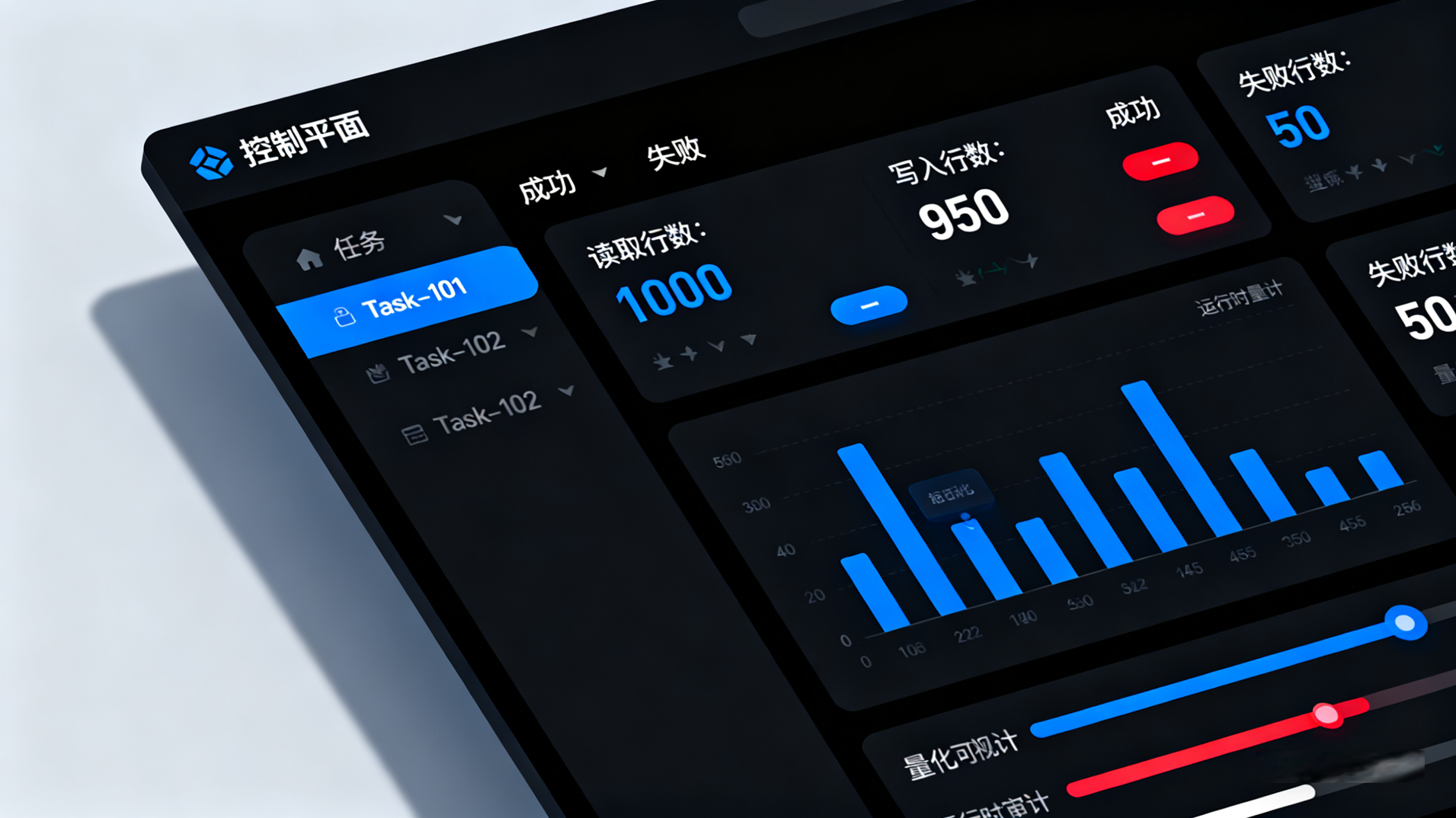
风险场景: 一个数据采集任务(如同步订单数据)在凌晨3点运行。
场景A(失败): 任务因源数据库密码错误而失败。
场景B(部分成功): 任务读取了1000行,但因数据格式错误,只写入了950行,50行被丢弃。
场景C(空跑): 任务成功运行,但源API返回了0条数据,导致下游报表“开天窗”。
解决方案:集中的、量化的运行日志
(二)中提到的“控制面-数据面”分离架构在此处发挥了关键作用。“控制面”(Web平台)必须作为“中央监控塔”,自动从所有Worker(数据面)收集运行时日志。
运维人员不应该(也不需要)SSH登录到N台Worker上去grep日志。他们应该在Web UI上看到所有任务的统一视图:
宏观指标:
任务ID,开始时间,结束时间,运行时长,状态(成功/失败/部分成功)。量化指标:
读取行数,写入行数,失败/丢弃行数,处理字节数。详细日志: Worker上报的
stdout/stderr。如果失败,必须能一键查到根本原因(Root Cause),如Error: Authentication failed for user 'prod_user'或API returned 403 Forbidden。
这种集中的“运行时审计”,将数据采集从“黑盒脚本”转变为“白盒服务”。它为数据质量(Data Quality)和SLA(服务等级协议)提供了最基础的度量衡。
4. 审计支柱三:“数据血缘” (数据的“前世今生”)
这是“审计”的最高形态,也是“合规”的终极答案。操作审计(Pillar 1)和运行时审计(Pillar 2)回答了“平台发生了什么”,而“数据血缘”(Data Lineage)回答的是“数据发生了什么”。
场景需求(合规): 监管机构(或内部法务)前来审查一份BI报表(如“欧洲区客户画像”),并提出质询:
“这份报表的数据源自哪里?”
“它是否包含了GDPR定义的个人身份信息(PII)?例如
email或address?”“如果包含,这些PII在采集过程中是否进行了(合规要求的)‘假名化’或‘脱敏’处理?”
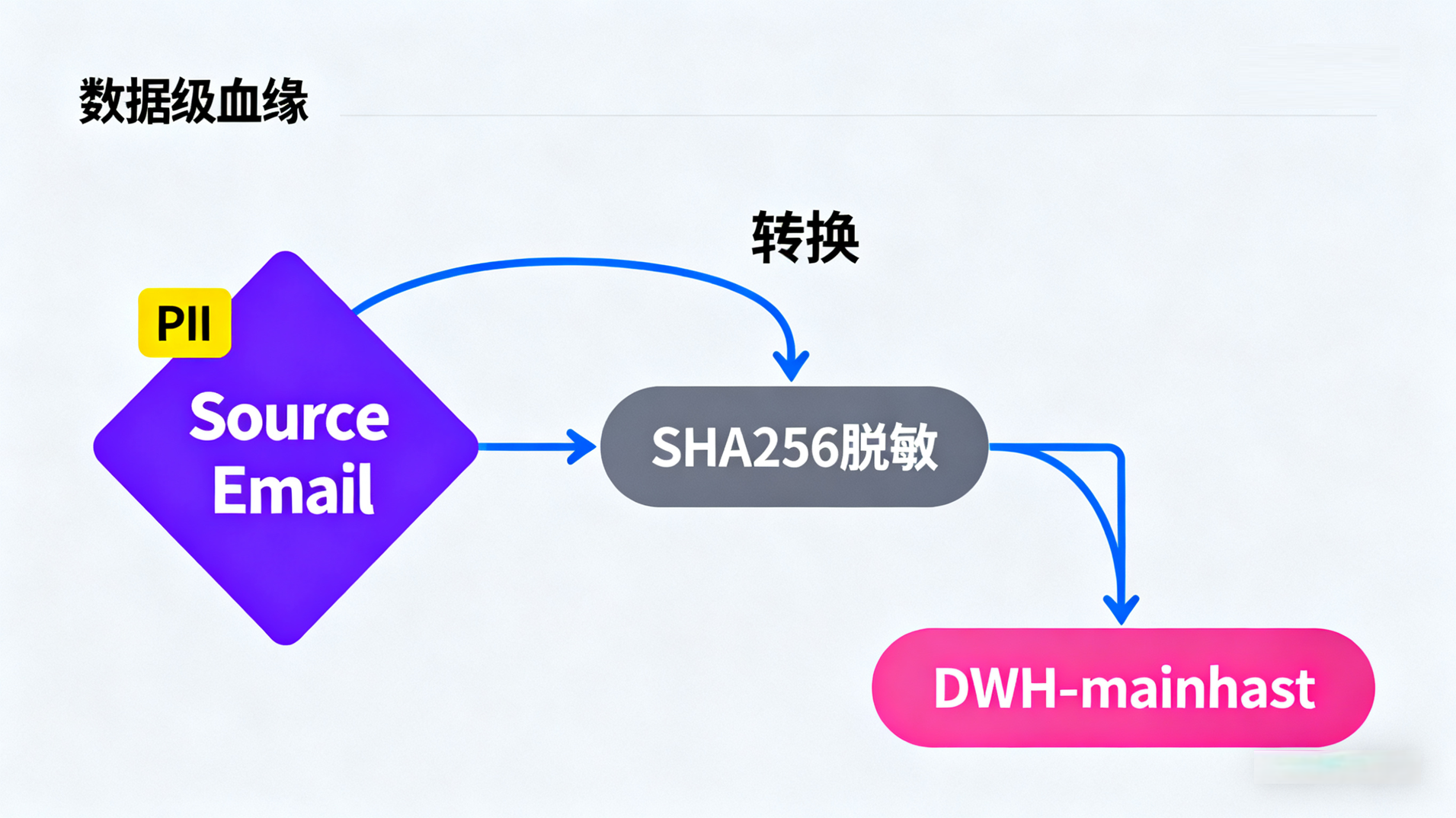
解决方案:平台自动生成的“血缘图谱”
“血缘”是Web采集平台这种“集中化”架构的必然产物。因为平台是唯一“知道”数据流转全貌的角色,它“被迫”掌握了血缘:
它知道Source:
Salesforce.Account.Email它知道Transform:
Mask(Email, 'SHA256')它知道Target:
DWH.ods_customer.email_hash
一个现代采集平台,必须能够自动生成并可视化这种血缘关系:
表级血缘(Table-Level):
[SaaS: Account]->[Task: Sync-SFDC-Customer]->[DB: ods_customer]。价值: 宏观上回答“数据从哪来,到哪去”。
字段级血缘(Field-Level):
Account.Email->[T: SHA256]->ods_customer.email_hash。价值: 精确回答“这个字段是如何演变而来的”。这对于PII追踪、合规审查至关重要。
血缘的价值:
(对合规):提供“PII追溯”的黄金路径,是满足GDPR、数据安全法“可追溯性”要求的唯一解法。
(对IT):提供“影响分析”(Impact Analysis)。当源API(
Salesforce.Account)要变更时,IT可以通过血缘图马上知道“下游的哪5个采集任务和3个数据仓库表会受影响”。(对业务):提供“根本原因分析”(Root Cause Analysis)。当BI报表数据错误时,业务可以沿着血缘图反向追溯,快速定位到是哪个采集任务在哪个环节(如
Task: Sync-SFDC-Customer)出了问题。
5. 结论:
一个现代数据采集平台,早已不是一个简单的“数据搬运工”。它必须是一个集成的“数据治理平台”。
它的Web原生(B/S)架构,其意义远不止于“界面友好”或“运维便捷”。这种“集中化”的架构,是当今企业实现**数据安全(Security)、可观测性(Observability)和可追溯性(Traceability)**的唯一技术底座。
它将数据采集这项工作,从过去那种分散的、不可控的、高风险的“黑盒脚本”,转变为一种透明的、可审计的、安全的、符合合规的企业级“数据服务”。