R语言基础(包含资料)
目录
前言-高效编写代码
在RStudio中新建项目
在项目中新建脚本
数据类型
数据结构
前言
向量(vector)
创建
操作-有个小重点
对两个向量进行的操作
当两个向量长度不一致-循环补齐
向量筛选(取子集)
修改向量
简单向量作图
补充:有重点
数据框(data.frame)
新建和读取数据框
操作
数据框取子集
按条件逻辑值
数据框修改
两个数据框的连接
高效使用函数处理数据框
矩阵(matrix)
列表(list)
函数(了解)
R包安装
文件读写
字符串
条件及循环
隐式循环-有重点-对于数据框和向量
前言-高效编写代码
在RStudio中新建项目
方式:RStudio中,菜单栏File→NewProject→NewDirectory→NewProject→DirectoryName
该方式通过新建一个目录的方式来新建一个项目,创建一个R的项目文件(Rproj):
- 将所有与该项目相关的数据、脚本、文件等都存放在该项目文件夹下,每次通过运行Rproj文件启动项目,自动关联相关文件,便于统一管理和调试。
- 该项目的工作目录即为新建该项目创建的目录。即后续创建的脚本文件默认保存位置均为该目录。
- 项目目录移动后,项目中的文件、脚本仍然可以通过项目文件(Rproj)关联使用。
在项目中新建脚本
方式:Rstudio菜单栏,File→NewFile→RScript
保存:
- R脚本保存的文件后缀为.R
- 保存的默认位置为当前的工作目录(working directory)
Tips: 脚本中点击Run或快捷键ctrl+Enter,执行光标所在行的代码,光标会移动到下一行 脚本中选中多行,点击Run,执行所选的代码 使用#为脚本添加注释。让自己和其他协作者了解代码的用途。R不会执行#后面的内容。
数据类型
- 数值型(numeric) 1 2
- 字符型(character) “a” “nn”
- 逻辑型(logical) TRUE(T) FALSE(F) NA
NA:为缺失值,表示存在但未知。NULL:为空,表示没有这个值(不存在)。TRUE(T) FALSE(F)在脚本中可以缩写成T、F
- 逻辑型数据 <,>, >=, <=, ==(判断是否相等), !=(判断是否不等)
多个逻辑条件的连接
- & 表示和/与
- | 表示或
- !表示非
数据结构
前言
R语言中主要有4种数据结构:向量、数据框、矩阵、列表
一个向量只能是同一种数据类型,可以有重复值。
数据框约等于“表格”。数据框要求每一列只能是同一种数据类型,
数据框单独拿出来的一列是一个向量,视为一个整体。一个向量可以出自数据框的一列,也可以用代码生成。
向量(vector)
创建
(1)用 c() 结合到一起
c(2,5,6,2,9) # 2 5 6 2 9
c("a","f","md","b") # "a" "f" "md" "b"
(2)连续的数字用冒号“:”
1:5 # 1 2 3 4 5(3)有重复的用rep(),有规律的序列用seq(),随机数用rnorm()
rep("x",times = 3) # "x" "x" "x"
seq(from = 3,to = 21,by = 3) # 3 6 9 12 15 18 21
rnorm(n = 3) # 0.7800798 -0.7946923 0.2169629(4)通过组合,产生更为复杂的向量。
paste(rep("x",times = 3),1:3) # "x 1" "x 2" "x 3"
#与paste一样不过没有默认空格间隔
paste0(rep("x",times = 3),1:3) # x1,x2,x3
操作-有个小重点
(1)赋值+输出一起实现
x <- c(1,3,5,1);x
(x <- c(1,3,5,1))
# 1 3 5 1在这里 “ <- ” 与 “=” 作用相同,但在与负数做小于比较时需要注意要加空格隔开,“ < -1”
(2)简单数学计算
# x 是 1 3 5 1
x+1 # 2 4 6 2
log(x) # 默认是以自然对数e为底,都是对向量中每一个值
sqrt(x) # 开方
(3)根据某条件进行判断,生成逻辑型向量
# x 是 1 3 5 1
x>3 # FALSE FALSE TRUE FALSE
x==3 # FALSE TRUE FALSE FALSE对两个向量进行的操作
x = c(1,3,5,1)
y = c(3,2,5,6)
#(1)比较运算,生成等长的逻辑向量
x == y # FALSE FALSE TRUE FALSE
y == x
#(2)数学计算
x + y # 4 5 10 7
#(3)连接
paste(x,y,sep=",") # "1,3" "3,2" "5,5" "1,6"#(4)交集、并集、差集
x = c(1,3,5,6,2)
y = c(3,2,5)
intersect(x,y) # 3 5 2
union(x,y) # 1 3 5 6 2
setdiff(x,y) # 1 6
setdiff(y,x) # 无
unique(x) # 去重
# x的每个元素在y中是否存在
x %in% y # FALSE TRUE TRUE FALSE TRUE
# y的每个元素在x中是否存在
y %in% x # TRUE TRUE TRUE当两个向量长度不一致-循环补齐
#循环补齐 次数会选向量个数最多的来
#当两个向量长度不一致
x = c(1,3,5,6,2)
y = c(3,2,5)
x == y # 啊!warning!
# FALSE FALSE TRUE FALSE TRUE# 原理
# x 1 3 5 6 2
# y 3 2 5 y 3 2
# F F T F T向量筛选(取子集)
x <- 8:12 # 8 9 10 11 12
#根据逻辑值取子集
x[x == 10] # 10
x[x < 12] # 8 9 10 11
x[x %in% c(9,13)] # 9
#根据位置取子集 # 下标从1开始
x[4] # 11
x[2:4] # 9 10 11
x[c(1,5)]
x[-4] # 8 9 10 12
x[-(2:4)] # 8 12-(减号)表示除了该位置的其他元素都取出来
修改向量
取子集+赋值
x <- 8:12 # 8 9 10 11 12
#改一个元素
x[4] <- 40
x # 8 9 10 40 12
#改多个元素
x[c(1,5)] <- c(80,20)
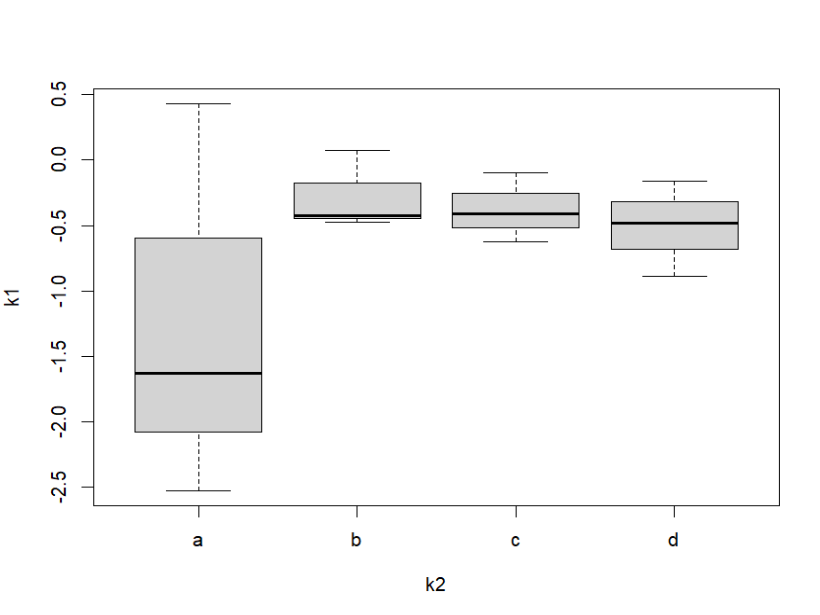
x # 80 9 10 40 20简单向量作图
k1 = rnorm(12);k1
# [1] -2.52322600 -1.62527192 0.42735119 -0.47192010 0.07189914
# [6] -0.42492975 -0.41367238 -0.09782699 -0.62340866 -0.15760400
# [11] -0.48121769 -0.88449818k2 = rep(c("a","b","c","d"),each = 3);k2
# "a" "a" "a" "b" "b" "b" "c" "c" "c" "d" "d" "d"plot(k1) # 点图
boxplot(k1~k2) # 箱线图 k1 纵坐标 k2作为横坐标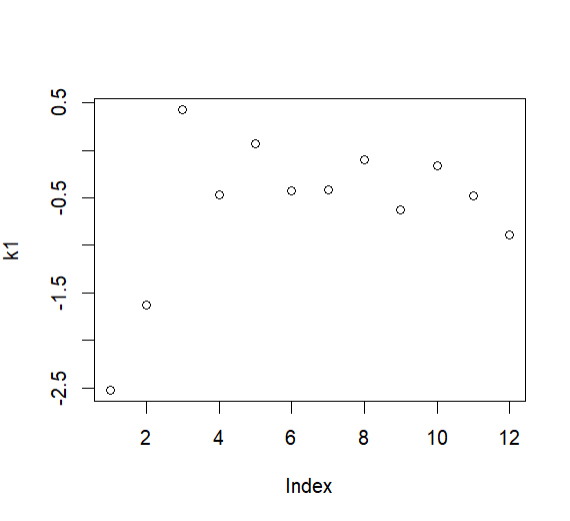
补充:有重点
可以加上类似列名的东西
scores = c(100,59,73,95,45)
scores
# 100 59 73 95 45 names(scores) = c("jimmy","nicker","Damon","Sophie","tony")
scores
# jimmy nicker Damon Sophie tony
# 100 59 73 95 45 scores["jimmy"]
# jimmy
# 100
scores[c("jimmy","nicker")]
# jimmy nicker
# 100 59 names(scores)[scores>60]
# "jimmy" "Damon" "Sophie"一些函数
x # 1 3 5 1
max(x) #最大值
min(x) #最小值
mean(x) #均值
median(x) #中位数
var(x) #方差
sd(x) #标准差
sum(x) #总和length(x) #长度
unique(x) #去重复
duplicated(x) #对应元素是否重复
table(x) #重复值统计
sort(x) # 默认升序
sort(x,decreasing = F) # 升序
sort(x,decreasing = T) # 降序 5 3 1 1杂项
x = rnorm(n=10,mean=0,sd=18) # 18标准差越大,正态分布越扁
save(g,s,file = "gands.Rdata") # 保存环境
rm(list = ls()) # 清空环境
数据框(data.frame)
可以由用代码新建、由已有数据转换或处理得到、读取表格文件、R语言内置数据
# R语言内置数据
letters # 小写字母
LETTERS
iris
volcanoclass(letters)
# [1] "character"
class(LETTERS)
# "character"
class(iris)
# "data.frame"
class(volcano)
# "matrix" "array" heatmap(volcano)新建和读取数据框
df1 <- data.frame(gene = paste0("gene",1:4),change = rep(c("up","down"),each = 2),score = c(5,3,-2,-4))
df1df2 <- read.csv("gene.csv")
df2# gene change score
# 1 gene1 up 5
# 2 gene2 up 3
# 3 gene3 down -2
# 4 gene4 down -4操作
# gene change score
# 1 gene1 up 5
# 2 gene2 up 3
# 3 gene3 down -2
# 4 gene4 down -4# 提取数据框属性# 行数 列数
dim(df1) # 4 3
# 行数
nrow(df1) # 4
# 列数
ncol(df1) #3数据框取子集
# gene change score
# 1 gene1 up 5
# 2 gene2 up 3
# 3 gene3 down -2
# 4 gene4 down -4# 按列名
# tab键可以补齐df1$gene # "gene1" "gene2" "gene3" "gene4"
df1$change # "up" "up" "down" "down"$在数据框不能一行的取,矩阵不支持$取东西
# gene change score
# 1 gene1 up 5
# 2 gene2 up 3
# 3 gene3 down -2
# 4 gene4 down -4# 按坐标
df1[2,2]
"up"df1[2,]gene change score
2 gene2 up 3df1[,2]
"up" "up" "down" "down"df1[c(1,3),1:2]gene change
1 gene1 up
3 gene3 down## 按名字
df1[,"gene"]
"gene1" "gene2" "gene3" "gene4"df1[,c('gene','change')]gene change
1 gene1 up
2 gene2 up
3 gene3 down
4 gene4 down
按条件逻辑值
需一一对应
df1 <- data.frame(gene = paste0("gene",1:4),change = rep(c("up","down"),each = 2),score = c(5,3,-2,-4))
# gene change score
# 1 gene1 up 5
# 2 gene2 up 3
# 3 gene3 down -2
# 4 gene4 down -4k = df1$score>0;k # k=TRUE TRUE FALSE FALSEdf1[k,]
# gene change score
# 1 gene1 up 5
# 2 gene2 up 3数据框修改
#改一个格
df1[3,3] <- 5#改一整列
df1$score <- c(12,23,50,2) # 新增一列
df1$p.value <- c(0.01,0.02,0.07,0.05) #改行名和列名
rownames(df1) <- c("r1","r2","r3","r4")#只修改某一行/列的名
colnames(df1)[2] <- "CHANGE"两个数据框的连接
# 合并
test1 <- data.frame(name = c('jimmy','nicker','Damon','Sophie'), blood_type = c("A","B","O","AB"))test2 <- data.frame(name = c('Damon','jimmy','nicker','tony'),group = c("group1","group1","group2","group2"),vision = c(4.2,4.3,4.9,4.5))test3 <- data.frame(NAME = c('Damon','jimmy','nicker','tony'),weight = c(140,145,110,138))test2name group vision
1 Damon group1 4.2
2 jimmy group1 4.3
3 nicker group2 4.9
4 tony group2 4.5
test1name blood_type
1 jimmy A
2 nicker B
3 Damon O
4 Sophie AB
# 交集
merge(test1,test2,by="name") # 只有一个表有,另一个没有会去掉name blood_type group vision
1 Damon O group1 4.2
2 jimmy A group1 4.3
3 nicker B group2 4.9merge(x= test1,test3,by.x = "name",by.y = "NAME") # 列名不一样时这样用name blood_type weight
1 Damon O 140
2 jimmy A 145
3 nicker B 110test3NAME weight
1 Damon 140
2 jimmy 145
3 nicker 110
4 tony 138# 连接
test1 <- data.frame(name = c('jimmy','nicker','Damon','Sophie'), blood_type = c("A","B","O","AB"))
test1
test2 <- data.frame(name = c('Damon','jimmy','nicker','tony'),group = c("group1","group1","group2","group2"),vision = c(4.2,4.3,4.9,4.5))
test2
library(dplyr)
inner_join(test1,test2,by="name") # 交集
left_join(test1,test2,by="name") # 左连接,右表在左表中没有会去掉,空值填充为na
right_join(test1,test2,by="name")
full_join(test1,test2,by="name") # 全连接,空值填充为na高效使用函数处理数据框
test <- iris[c(1:2,51:52,101:102),]
rownames(test) =NULL # 去掉行名,NULL是“什么都没有”
test# arrange,数据框按照某一列排序library(dplyr)
arrange(test, Sepal.Length) #从小到大
arrange(test, desc(Sepal.Length)) #从大到小# distinct,数据框按照某一列去重复
distinct(test,Species,.keep_all = T)
# unique() 给向量用的# mutate,数据框新增一列
mutate(test, new = Sepal.Length * Sepal.Width)
# test$new = test$Sepal.Length * test$Sepal.Width# 连续的步骤# 1.多次赋值,产生多个中间的变量
x1 = select(iris,-5) # 选择去掉第五列的数据
x2 = as.matrix(x1)
x3 = head(x2,50)
pheatmap::pheatmap(x3)
# heatmap(x1) # 参数必须是矩阵# 2. 嵌套,代码不易读
pheatmap::pheatmap(head(as.matrix(select(iris,-5)),50))# 3.管道符号传递,简洁明了
iris %>% # 将数据传到指向的下一个函数select(-5) %>%as.matrix() %>%head(50) %>% pheatmap::pheatmap()矩阵(matrix)
矩阵不支持$取东西,$在数据框不能一行的取
m <- matrix(1:9, nrow = 3)
# colnames(m) <- c("a","b","c") # 可以加列名
m
# [,1] [,2] [,3]
# [1,] 1 4 7
# [2,] 2 5 8
# [3,] 3 6 9m[2,] # 2 5 8
m[,1] #1 2 3
m[2,3] # 8
m[2:3,1:2]
# [,1] [,2]
# [1,] 2 5
# [2,] 3 6t(m) #转置
# [,1] [,2] [,3]
# [1,] 1 2 3
# [2,] 4 5 6
# [3,] 7 8 9pheatmap::pheatmap(m) # 默认聚类了 # 聚类热图
pheatmap::pheatmap(m,cluster_cols = F,cluster_rows = F) # 取消聚类了class(m) # "matrix" "array"
m = as.data.frame(m)
class(m) # "data.frame"列表(list)
支持用$
x <- list(m1 = matrix(1:9, nrow = 3),m2 = matrix(2:9, nrow = 2))
x
# $m1
# [,1] [,2] [,3]
# [1,] 1 4 7
# [2,] 2 5 8
# [3,] 3 6 9
#
# $m2
# [,1] [,2] [,3] [,4]
# [1,] 2 4 6 8
# [2,] 3 5 7 9x[[1]] #取出的是矩阵。
# [,1] [,2] [,3]
# [1,] 1 4 7
# [2,] 2 5 8
# [3,] 3 6 9
x$m1
# [,1] [,2] [,3]
# [1,] 1 4 7
# [2,] 2 5 8
# [3,] 3 6 9函数(了解)
jimmy <- function(a,b,m = 2){(a+b)^m
}
jimmy(a = 1,b = 2)
jimmy(1,2)
jimmy(3,6)
jimmy(3,6,-2)R包安装
# R包安装# CRAN网站用 install.packages 安装
options("repos"=c(CRAN="http://mirrors.tuna.tsinghua.edu.cn/CRAN/"))
# Biocductor网站安装用 BiocManager::install 安装
options(BioC_mirror="http://mirrors.tuna.tsinghua.edu.cn/bioconductor/")install.packages("tidyr")
install.packages('BiocManager')
BiocManager::install("limma")
install.packages('devtools')
# GitHub 网站安装包
devtools::install_github("jmzeng1314/idmap1") #括号里写作者用户名加包名# 清华镜像
# http://mirrors.tuna.tsinghua.edu.cn/CRAN/
# http://mirrors.tuna.tsinghua.edu.cn/bioconductor/# 中科大镜像
# http://mirrors.ustc.edu.cn/CRAN/
# http://mirrors.ustc.edu.cn/bioc/# 都可以加载包
library(tidyr) # 在加载包时,如果包未安装,它会抛出错误并停止代码执行。
require(tidyr) # 如果包未安装,它会发出警告返回T获F但继续执行代码#或者用过时R包的安装方式
# 取去要下载包的网站下复制旧版本的链接,也可以把包下下来安装
ad = "https://cran.r-project.org/src/contrib/Archive/qlcMatrix/qlcMatrix_0.9.7.tar.gz"
if(!require(qlcMatrix))install.packages(ad,repos = NULL) # 可以换本地电脑的地址# 分情况讨论
# 没安装就下
if(!require(stringr))install.packages("stringr")
#懒惰策略,能不更新就不更新,除非一直报错。
#不想回答:安装命令加参数:update=F,ask=F# 获取帮助
?sd
library(limma)
browseVignettes("limma") #不是每个包都有官方网站
ls("package:limma")# 查看包里有哪些函数文件读写
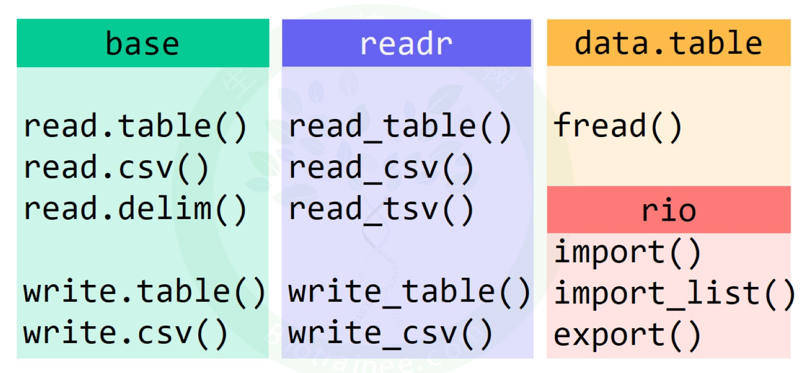
#文件读写部分
# read.delim(sep="\t") # sep 分隔符
# read.table(sep="")
# read.csv(sep=",")
# read.csv2(sep=";")读取各种格式
#1.读取ex1.txt
ex1 <- read.table("ex1.txt")
ex1[2,4]
ex1 <- read.table("ex1.txt",header = T)
#2.读取ex2.csv
ex2 <- read.csv("ex2.csv")
# 源文件自带行名,
# row.names 将第一列成为行名,其中不允许重复名
# 函数会将将特殊符号转为“.”,比如“-” -> “.” check.names 可以更改
ex2 <- read.csv("ex2.csv",row.names = 1,check.names = F)#注意:数据框不允许重复的行名
rod = read.csv("rod.csv",row.names = 1) #报错
rod = read.csv("rod.csv")导出
#数据框导出
write.csv(ex2,file = "example.csv")
write.table(ex2,file = "example.txt")其他更高效的方法
#用data.table来读取
library(data.table)
ex1 = fread("ex1.txt")
class(ex1) # data.table 数据格式无法用数据框的格式读取
ex1 = fread("ex1.txt",data.table = F)
class(ex1)
ex2 = fread("ex2.csv",data.table = F)
#不支持直接设置行名
# 第一种修改
rownames(ex2) = ex2$V1 # 源文件自带行名,
view(ex2[,-1]) # -1 不要第1列
# 第二种修改
library(tibble)
ex2 = column_to_rownames(ex2,"V1")#rio
library(rio)
#一个函数支持读取很多格式,见帮助文档
ex1 = import("ex1.txt")
#一个函数支持导出很多格式,见帮助文档
export(ex1,file = "ex1.xlsx")字符串
rm(list = ls())
if(!require(stringr))install.packages('stringr')
library(stringr)x <- "The birch canoe slid on the smooth planks."
x
### 1.检测字符串长度
str_length(x)
length(x)
### 2.字符串拆分
str_split(x," ")
class(str_split(x," "))
x2 = str_split(x," ")[[1]];x2y = c("jimmy 150","nicker 140","tony 152")
str_split(y," ")
# 切分成矩阵,可以用索引a[,4]
str_split(y," ",simplify = T)### 3.按位置提取字符串
str_sub(x,5,9)
str_sub(x,-4,-1) # 从倒数第四到倒一截取### 4.字符检测
str_detect(x2,"h") # 含有这个字母检测
str_starts(x2,"T")
str_ends(x2,"e")
### 5.字符串替换
x2
str_replace(x2,"o","A") # 每个字符串只会替换第一次匹配到的
str_replace_all(x2,"o","A")### 6.字符删除
x
str_remove(x," ")
str_remove_all(x," ")条件及循环
rm(list = ls())# load("a.Rdata") # 加载环境
# save() 可以保存到.Rdata
# dir.create("export") # 创建文件夹## 条件语句###1.if(){ }#### (1)只有if没有else,那么条件是FALSE时就什么都不做i = -1
if (i<0) print('up')
if (i>0) print('up')#理解下面代码
if(!require(tidyr)) install.packages('tidyr')#### (2)有else
i =1
if (i>0){print('+')
} else {print("-")
}
i = 1
ifelse(i>0,"+","-")x = rnorm(3)
x
ifelse(x>0,"+","-")#ifelse()+str_detect() 按条件匹配
# str_detect函数需要 library(stringr)
samples = c("tumor1","tumor2","tumor3","normal1","normal2","normal3")k1 = str_detect(samples,"tumor");k1 # 返回T,F
# TRUE TRUE TRUE FALSE FALSE FALSE
ifelse(k1,"tumor","normal")k2 = str_detect(samples,"normal");k2
# FALSE FALSE FALSE TRUE TRUE TRUE
ifelse(k2,"normal","tumor")#### (3)多个条件
i = 0
if (i>0){print('+')
} else if (i< 0) {print('-')
} else {print('0')
}library(dplyr)
case_when(i>0 ~ "+",i<O ~ “-”T ~ "0")ifelse(i>0,"+",ifelse(i<0,"-","0"))
循环
## 二、for循环for( i in 1:4){print(i)
}#批量画图
par(mfrow = c(2,2))
for(i in 1:4){plot(iris[,i],col = iris[,5])
}#批量装包
pks = c("tidyr","dplyr","stringr")
for(g in pks){if(!require(g,character.only = T))install.packages(g,ask = F,update = F)
}隐式循环-有重点-对于数据框和向量
rm(list = ls())
## apply()族函数### 1.apply 处理矩阵或数据框#apply(X, MARGIN, FUN, …)
#其中X是数据框/矩阵名;
#MARGIN为1表示行,为2表示列,FUN是函数test<- iris[1:6,1:4]apply(test, 2, mean)
apply(test, 1, sum)### 2.lapply(list, FUN, …)
# 对列表/向量中的每个元素实施相同的操作lapply(1:4,rnorm)