DMFNet代码讲解
utils.py
class TrainSetLoader(Dataset):
初始化代码
def __init__(self, dataset_dir, img_id ,base_size=512,crop_size=480,transform=None,suffix='.png'):super(TrainSetLoader, self).__init__()self.transform = transformself._items = img_idself.masks = dataset_dir+'/'+'masks' # masks 目录路径self.images = dataset_dir+'/'+'images' # images 目录路径self.base_size = base_sizeself.crop_size = crop_sizeself.suffix = suffix_sync_transform图像增强函数:
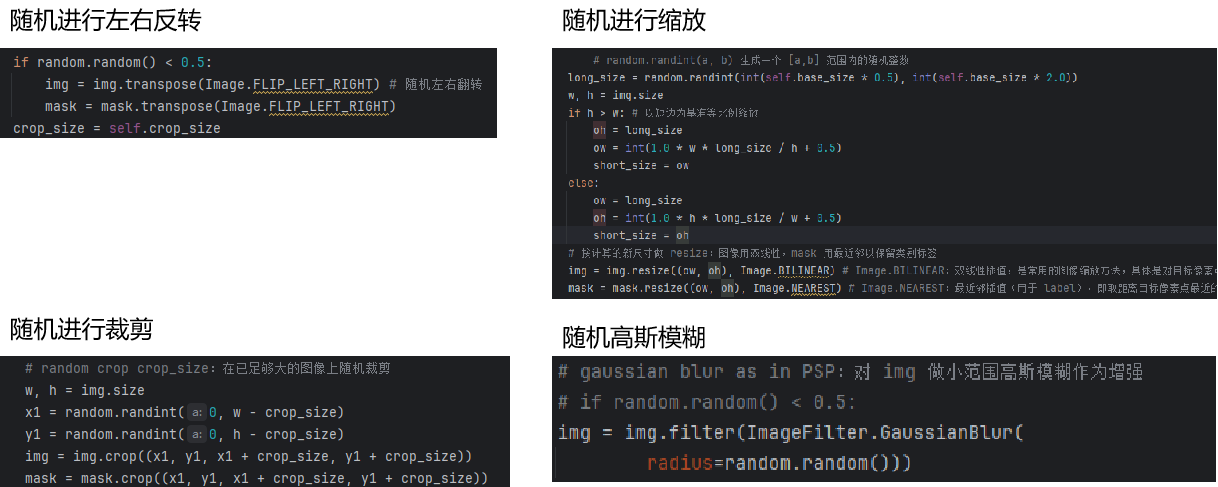
对于函数_sync_transform(self, img, mask):
它可以解决:
1. 解决数据不足问题 现实世界中很难收集所有可能场景的训练数据 通过变换现有数据,创造"新"的训练样本
2. 提升模型泛化能力 让模型学习到:
同一物体在不同位置、尺度、方向的形态
对轻微形变、模糊的鲁棒性
不受光照、颜色变化影响的特征
图片经过这个函数,就相当于:
假设原始训练样本是: 一张清晰的汽车图片 汽车位于图像中央 尺寸固定
经过这个函数,模型会看到:
同一辆汽车在左侧(翻转)
同一辆汽车很小(缩放0.5倍)
同一辆汽车很大(缩放2.0倍)
同一辆汽车在角落(随机裁剪)
同一辆汽车有点模糊(高斯模糊)
各种组合:比如"左侧的小模糊汽车"
效果: 增加了训练数据的多样性 让模型学习不变性特征(无论汽车在哪、多大、多模糊,都能识别) 减少了过拟合风险
__getitem__获取数据:
def __getitem__(self, idx):img_id = self._items[idx] # 从 id 列表取出当前样本 idimg_path = self.images+'/'+img_id+self.suffix # 构造图像文件路径label_path = self.masks +'/'+img_id+self.suffix # 构造 mask 文件路径img = Image.open(img_path).convert('RGB') # 强制转为 3 通道 RGB(兼容单/三通道输入)mask = Image.open(label_path)# synchronized transform:调用上面的增强函数,返回 numpyimg, img_1, mask = self._sync_transform(img, mask)# general resize, normalize and toTensor:若外部传入 transform 则对 img 和 img_1 应用if self.transform is not None:img = self.transform(img)img_1 = self.transform(img_1)# mask 扩展 channel 维度为 (1,H,W),并归一化到 0-1mask = np.expand_dims(mask, axis=0).astype('float32')/ 255.0return img, img_1, torch.from_numpy(mask) # 返回 (img_tensor, img_1_tensor, mask_tensor)class TestSetLoader(Dataset):
_testval_sync_transform
def _testval_sync_transform(self, img, mask):# 验证/测试时的同步 transform:统一缩放到 base_size x base_size(无随机)base_size = self.base_sizeimg = img.resize ((base_size, base_size), Image.BILINEAR)mask = mask.resize((base_size, base_size), Image.NEAREST)# final transform:转为 numpy,mask 为 float32img, mask = np.array(img), np.array(mask, dtype=np.float32) # img: numpy (H,W,3)return img, mask这个函数的目的是为了将数据进行统一,保证获取没有进行随机过的图片,这样可以:
# 所有测试样本在相同条件下处理 # 确保模型性能比较的公正性
# 相同的输入永远产生相同的预处理结果 # 便于调试和结果分析
weights_init_xavier正态初始化:
def weights_init_xavier(m):# 对模块 m 做 Xavier 正态初始化(若类名中包含 Conv2d)classname = m.__class__.__name__if classname.find('Conv2d') != -1:init.xavier_normal_(m.weight.data)这个函数是将所有卷积函数进行正态初始化,目的是为了保持前向传播和反向传播时信号的方差稳定,避免梯度消失或爆炸
# 对于正态分布的Xavier初始化
std = gain × √(2 / (fan_in + fan_out))
权重 ~ N(0, std²)其中:
fan_in:输入通道数 × 卷积核宽 × 卷积核高
fan_out:输出通道数 × 卷积核宽 × 卷积核高
gain:激活函数的增益系数(默认1.0)
如果没有合适的初始化
- 权重太小 → 信号逐渐消失 → 梯度消失
- 权重太大 → 信号指数增长 → 梯度爆炸
metric.py
class ROCMetric():
这个类是针对于ROC曲线的相关工作
ROC曲线:
对于一个模型预测,可以得到一个混淆矩阵:
真实正确 真实错误 预测正确 TP FP 预测错误 FN TN 例如:这个模型要预测一个汉堡是不是真的是汉堡,TP就是一张真正的汉堡照片而模型也将他预测为了汉堡
而ROC曲线在设定不同阈值的情况下,将
作为纵轴,
作为横轴绘制的曲线
init初始化:
def __init__(self, nclass, bins): #bin的意义实际上是确定ROC曲线上的threshold取多少个离散值super(ROCMetric, self).__init__()self.nclass = nclassself.bins = bins# +1 是为了存储0 0.1 0.2 ... 1的11个thresholdself.tp_arr = np.zeros(self.bins+1)self.pos_arr = np.zeros(self.bins+1)self.fp_arr = np.zeros(self.bins+1)self.neg_arr = np.zeros(self.bins+1)self.class_pos=np.zeros(self.bins+1)bins参数就是所取阈值个数,例如bins取10,则阈值就是0,0.1,0.2...0.9,1.0十个值
而下面的复制则是创建出bins+1个零数组(因为实际上由bins+1个值)
update更新:
def update(self, preds, labels):for iBin in range(self.bins+1):score_thresh = (iBin + 0.0) / self.binsd# print(iBin, "-th, score_thresh: ", score_thresh)i_tp, i_pos, i_fp, i_neg,i_class_pos = cal_tp_pos_fp_neg(preds, labels, self.nclass,score_thresh)self.tp_arr[iBin] += i_tpself.pos_arr[iBin] += i_posself.fp_arr[iBin] += i_fpself.neg_arr[iBin] += i_negself.class_pos[iBin]+=i_class_posscore_thresh即本次循环阈值,例如,当iBin=1而bins=10时,score_thresh=0.1本次阈值就为0.1
对于cal_tp_pos_fp_neg函数跳转到:cal_tp_pos_fp_neg获取ROC参数部分查看
get:
def get(self):#注意,在每次计算中,分母加上0.001,以避免除以零的误差。tp_rates = self.tp_arr / (self.pos_arr + 0.001)fp_rates = self.fp_arr / (self.neg_arr + 0.001)recall = self.tp_arr / (self.pos_arr + 0.001)precision = self.tp_arr / (self.class_pos + 0.001)计算的是tp和fp的比率,recall即召回率,precision即精确率
reset:
def reset(self):self.tp_arr = np.zeros([11])self.pos_arr = np.zeros([11])self.fp_arr = np.zeros([11])self.neg_arr = np.zeros([11])self.class_pos= np.zeros([11])重置
class PD_FA():
#基于像素的假阳性率(False Alarm Rate)和假阴性率(Probability of Detection)的计算
init初始化:
def __init__(self, nclass, bins):super(PD_FA, self).__init__()self.nclass = nclassself.bins = binsself.image_area_total = []self.image_area_match = []self.FA = np.zeros(self.bins+1)self.PD = np.zeros(self.bins + 1)self.target= np.zeros(self.bins + 1)update:
for iBin in range(self.bins+1):#将模型的预测结果(preds)和标签(labels)转换为二值图像,并且将它们的维度从一维变为二维。score_thresh = iBin * (255/self.bins)predits = np.array((preds > score_thresh).cpu()).astype('int64')predits = np.reshape (predits, (256,256))labelss = np.array((labels).cpu()).astype('int64') # Plabelss = np.reshape (labelss , (256,256))这段代码就是将所有阈值进行遍历并转为二值图像
二值图像:将照片变为仅有黑色和白色两种颜色的图像,有平均值法,双峰法等
#measure.label函数将分割结果和真实标签进行标记,然后使用measure.regionprops函数获取每个标记区域的属性image = measure.label(predits, connectivity=2)coord_image = measure.regionprops(image)label = measure.label(labelss , connectivity=2)coord_label = measure.regionprops(label)self.target[iBin] += len(coord_label)self.target[iBin] += len(coord_label)self.image_area_total = []# 所有预测区域的面积self.image_area_match = []# 成功匹配的预测区域面积self.distance_match = []# 匹配的距离self.dismatch = []# 未匹配的预测区域面积这一段是将上面获取的图片进行连通,并且采用8连通的方法
1.1 什么是连通组件?
在开始之前,我们首先需要理解什么是连通组件。简单来说,连通组件是图像中相邻像素的集合,这些像素具有相同或相似的特性(如灰度值、颜色等)。
在二值图像中,连通组件通常指的是相邻的前景像素(值为1)组成的区域。例如,在一张包含多个字母的二值图像中,每个字母都可以被视为一个独立的连通组件。
1.2 连通性的定义
连通性定义了像素之间的邻接关系。在2D图像中,我们通常使用两种连通性:
- 4-连通:只考虑像素的上、下、左、右四个方向的邻接像素。
- 8-连通:除了4-连通的四个方向,还考虑对角线方向的邻接像素。
选择哪种连通性取决于具体的应用场景。8-连通通常能提供更精细的结果,但也可能导致不希望的连接。
measure.label 功能:
对二值图像中的连通区域进行标记
为每个连通区域分配唯一的整数标签
背景通常标记为0
measure.regionprops 返回的属性包括:
area: 区域像素数量centroid: 区域质心坐标(y, x)bbox: 边界框(min_row, min_col, max_row, max_col)coords: 区域内所有像素坐标
for K in range(len(coord_image)):area_image = np.array(coord_image[K].area)self.image_area_total.append(area_image)功能:记录所有预测连通区域的面积
示例:
python
# 假设有3个预测区域 coord_image[0].area = 15 # 区域1有15个像素 coord_image[1].area = 8 # 区域2有8个像素 coord_image[2].area = 25 # 区域3有25个像素# 结果: self.image_area_total = [15, 8, 25]
for i in range(len(coord_label)):centroid_label = np.array(list(coord_label[i].centroid))for m in range(len(coord_image)):centroid_image = np.array(list(coord_image[m].centroid))distance = np.linalg.norm(centroid_image - centroid_label)area_image = np.array(coord_image[m].area)if distance < 3:self.distance_match.append(distance)self.image_area_match.append(area_image)del coord_image[m]break外层循环是遍历真实目标,获取质心坐标
质心坐标格式:
coord_label[i].centroid: 返回(y, x)坐标例如:
(125.5, 80.3)表示在第126行、第80列附近
内层循环是遍历预测区域
然后计算欧几里得距离并记录预测区域面积,如果距离小于3,则匹配距离和匹配区域的面积并从预测距离中删除已匹配区域
完整匹配示例
假设有以下情况:
真实目标 (coord_label):
python
目标0: 质心=(50, 50), 面积=20 目标1: 质心=(100, 100), 面积=15预测区域 (coord_image):
python
预测0: 质心=(48, 52), 面积=18, 距离=√(2²+2²)=2.8 ✓ 匹配! 预测1: 质心=(102, 98), 面积=16, 距离=√(2²+2²)=2.8 ✓ 匹配! 预测2: 质心=(200, 200), 面积=25, 距离=√(100²+100²)=141.4 ✗ 不匹配匹配过程:
目标0 匹配 预测0 (距离2.8 < 3)
distance_match = [2.8]
image_area_match = [18]删除预测0
目标1 匹配 预测1 (距离2.8 < 3)
distance_match = [2.8, 2.8]
image_area_match = [18, 16]删除预测1
预测2 未被匹配 → 后续计入误检
self.dismatch = [x for x in self.image_area_total if x not in self.image_area_match]#计算未匹配区域self.FA[iBin]+=np.sum(self.dismatch)#累计误检像素数self.PD[iBin]+=len(self.distance_match)#累计成功检测数1. 计算未匹配区域
列表推导式的作用:
找出所有预测了但未匹配到真实目标的区域面积
self.image_area_total: 所有预测区域的面积self.image_area_match: 成功匹配的预测区域面积完整计算示例
假设一次update处理的情况:
输入数据:
python
# 预测区域面积 self.image_area_total = [20, 15, 8, 30, 5]# 成功匹配的区域面积 self.image_area_match = [20, 30]# 匹配距离 self.distance_match = [2.1, 1.8]
计算过程:
python
# 1. 找出未匹配区域 self.dismatch = [x for x in [20, 15, 8, 30, 5] if x not in [20, 30]]= [15, 8, 5]# 2. 计算误检像素总数 误检像素数 = np.sum([15, 8, 5]) = 28# 3. 计算成功检测数 成功检测数 = len([2.1, 1.8]) = 2# 4. 更新统计 self.FA[iBin] += 28 self.PD[iBin] += 2
指标意义
FA (False Alarm):
定义: 错误检测为目标的像素总数
计算: 所有未匹配预测区域的像素数之和
意义: 值越小越好,表示误检越少
PD (Probability of Detection):
定义: 成功检测到的目标数量
计算: 成功匹配的目标对数
意义: 值越大越好,表示检测能力越强
class mIoU():
这是一个用于计算语义分割任务标准评估指标的类,主要计算像素精度(pixAcc) 和平均交并比(mIoU)
初始化与重置:
def __init__(self, nclass):super(mIoU, self).__init__()self.nclass = nclass # 类别数量self.reset()def reset(self):self.total_inter = 0 # 累计交集self.total_union = 0 # 累计并集 self.total_correct = 0 # 累计正确像素数self.total_label = 0 # 累计标签像素数update:
def update(self, preds, labels):correct, labeled = batch_pix_accuracy(preds, labels)inter, union = batch_intersection_union(preds, labels, self.nclass)self.total_correct += correctself.total_label += labeledself.total_inter += interself.total_union += union有关batch_pix_accuracy和batch_intersection_union函数跳转下方
get:
计算最终指标
def get(self):pixAcc = 1.0 * self.total_correct / (np.spacing(1) + self.total_label) # 是一个极小值,用于避免除数为0的情况。IoU = 1.0 * self.total_inter / (np.spacing(1) + self.total_union)mIoU = IoU.mean()return pixAcc, mIoU像素精度 (Pixel Accuracy)
含义: 所有像素中预测正确的比例
公式:
正确像素数 / 总有效像素数
交并比 (IoU)
含义: 每个类别的预测与真实的重叠程度
公式:
交集 / 并集
3. 平均交并比 (mIoU)
含义: 所有类别IoU的平均值
考虑类别平衡: 对每个类别平等对待
数值稳定性处理
np.spacing(1) # 添加一个极小值避免除零
相当于在分母加一个接近0的值
防止当
total_label=0或total_union=0时出现除零错误
cal_tp_pos_fp_neg获取ROC参数:
def cal_tp_pos_fp_neg(output, target, nclass, score_thresh):# 分别计算tp pos fp neg等一系列指标predict = (torch.sigmoid(output) > score_thresh).float()if len(target.shape) == 3:target = np.expand_dims(target.float(), axis=1)elif len(target.shape) == 4:target = target.float()else:raise ValueError("Unknown target dimension")intersection = predict * ((predict == target).float())tp = intersection.sum()fp = (predict * ((predict != target).float())).sum()tn = ((1 - predict) * ((predict == target).float())).sum()fn = (((predict != target).float()) * (1 - predict)).sum()pos = tp + fnneg = fp + tnclass_pos= tp+fpreturn tp, pos, fp, neg, class_pospredict:对输出结果应用sigmoid得到概率值,并且与阈值进行对比后进行二值化,若概率大于阈值,则为1,若小于则为0。1即模型预测这是所给目标(预测出这是一个汉堡)0则预测不是所给目标。
然后将进行目标张量进行修改,若为3通道则扩展为4通道,若为4通道则不变。
intersection:predict==target即预测正确的区域,即下方绿色区域
真实正确 真实错误 预测正确 TP FP 预测错误 FN TN
而predict * ((predict == target)则是只取正例部分,即下方绿色区域
真实正确 真实错误 预测正确 TP FP 预测错误 FN TN
则tp=intersection.sum()就是获取预测为正例且实际为正例的数量
而fp,tn,fn则分别是表格中其他部分数量
batch_pix_accuracy计算二值分割任务中的正确像素数和标记像素数:
def batch_pix_accuracy(output, target):# 计算一批的像素准确率if len(target.shape) == 3:target = np.expand_dims(target.float(), axis=1)elif len(target.shape) == 4:target = target.float()else:raise ValueError("Unknown target dimension")assert output.shape == target.shape, "Predict and Label Shape Don't Match"predict = (output > 0).float()pixel_labeled = (target > 0).float().sum()pixel_correct = (((predict == target).float())*((target > 0)).float()).sum()统一通道数量同cal_tp_pos_fp_neg函数。
首先检查标签形状和预测输出形状是否一致,然后将预测输出二值化。
计算标记像素数
pixel_labeled = (target > 0).float().sum()
计算过程:
(target > 0).float(): 真实标签中正例区域的掩码.sum(): 统计所有正例像素的数量
结果: 真实标签中所有正例像素的总数
计算正确像素数
pixel_correct = (((predict == target).float()) * ((target > 0)).float()).sum()
分步解析:
(predict == target).float():预测正确的所有区域(包括正例和负例)
正确预测为1,错误预测为0
((target > 0)).float():真实正例区域的掩码
逐元素相乘:
预测正确掩码 × 真实正例掩码
只有在预测正确且真实为正例的位置才为1
其他位置为0
.sum(): 统计真正例(TP)的像素数量
assert pixel_correct <= pixel_labeled, "Correct area should be smaller than Labeled"
确保正确像素数不超过标记像素数
指标意义
pixel_correct (正确像素数)
含义: 真正例(True Positive)的像素数量
计算: 预测为正例且实际为正例的像素数
pixel_labeled (标记像素数)
含义: 真实正例的总像素数量
计算: 真实标签中所有正例像素数
batch_intersection_union计算交区域和并区域:
def batch_intersection_union(output, target, nclass):# 计算交区域和并区域mini = 1maxi = 1nbins = 1predict = (output > 0).float()if len(target.shape) == 3:target = np.expand_dims(target.float(), axis=1)elif len(target.shape) == 4:target = target.float()else:raise ValueError("Unknown target dimension")intersection = predict * ((predict == target).float())"""intersection.cpu()是需要统计的数据,nbins和(mini, maxi)分别为指定的区间数量和数据的取值范围。函数的返回值为一个元组,其中第一个元素为每个区间的计数,第二个元素为每个区间的边界值。由于这里只需要计数值,因此使用了下划线来忽略边界值。最终,计数值被存储在变量area_inter中。"""area_inter, _ = np.histogram(intersection.cpu(), bins=nbins, range=(mini, maxi))area_pred, _ = np.histogram(predict.cpu(), bins=nbins, range=(mini, maxi))area_lab, _ = np.histogram(target.cpu(), bins=nbins, range=(mini, maxi))area_union = area_pred + area_lab - area_interassert (area_inter <= area_union).all(), \"Error: Intersection area should be smaller than Union area"return area_inter, area_union初始化和统一通道数量及intersection变量同cal_tp_pos_fp_neg函数
area_inter: 真正例(TP)的像素数量area_pred: 预测为正例的像素数量(TP+FP)area_lab: 真实为正例的像素数量(TP+FN)
统计量 混淆矩阵对应 计算公式 area_interTP 真正例 area_predTP + FP 预测正例 area_labTP + FN 实际正例 area_unionTP + FP + FN 并集
some_nets.py:
class SELayer:
# SE注意力机制(Squeeze-and-Excitation Networks)在通道维度增加注意力机制
class SELayer(nn.Module):def __init__(self, channel, reduction=16):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)#将任意尺寸的特征图压缩到 1×1 的空间维度# 输入: [B, C, H, W] (任意高度和宽度)# 输出: [B, C, 1, 1] (每个通道一个全局特征值)self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc(y).view(b, c, 1, 1)return x * y.expand_as(x)注意力机制:
为了让机器能够模仿人类人类视觉和认知系统的方法,允许神经网络在处理输入数据时集中注意力于相关的部分。
原理:注意力机制有三个关键的参数分别是Q(question)K(key)V(value)
Q就是“我想找什么信息”,K就是“我有什么信息”,V就是(我能提供的具体内容)
而根号d则是为了防止梯度消失而做的权重归一化
就是通过Q与所有的K相乘获得每个K对Q的关注度,再将关注度转化为权重
SE注意力机制:
Squeeze(压缩):通过全局平均池化将每个通道的特征信息压缩为一个标量,表示该通道的全局信息。这一步骤使得网络能够获得全局感受野,提取出每个通道的重要性信息。
Excitation(激励):使用全连接层对每个通道的重要性进行预测,生成通道注意力权重。这个过程类似于门控机制,通过学习来动态调整每个通道的权重。
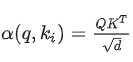
1. 前向传播
输入图片 → 特征提取 → SE模块 → 预测 → 计算损失2. 反向传播
损失梯度 → 告诉网络:"这个预测错了,因为某些特征组合没用好"3. 权重更新
if 某个特征组合帮助正确分类:
增加这个组合的权重
else:
减少这个组合的权重
self.avg_pool = nn.AdaptiveAvgPool2d(1)将全局进行平均池化,捕获全局信息
nn.Linear(channel, channel//reduction) # 压缩 nn.ReLU() # 非线性变换 nn.Linear(channel//reduction, channel) # 恢复
学习过程:
第一层线性层:学习"哪些通道组合在一起时更有意义"
ReLU:过滤掉负相关,保留正相关模式
第二层线性层:学习"基于压缩信息如何重新分配重要性"
forward:
首先获取批大小和通道数b,c然后进行平均池化压缩,压缩后进行重要性权重计算
class AsymBiChaFuse(nn.Module):
init:
self.topdown_1 = nn.Sequential(nn.AdaptiveAvgPool2d(1), # 全局信息压缩nn.Conv2d(channels, bottleneck_channels, 1), # 降维nn.BatchNorm2d(bottleneck_channels),nn.ReLU(),nn.Conv2d(bottleneck_channels, channels, 1), # 恢复维度nn.BatchNorm2d(channels),nn.Sigmoid() # 生成注意力权重
)自上而下的注意力路径
作用: 高层特征指导低层特征应该关注什么
self.bottomup_1 = nn.Sequential(nn.Conv2d(channels, bottleneck_channels, 1), # 降维nn.BatchNorm2d(bottleneck_channels),nn.ReLU(),nn.Conv2d(bottleneck_channels, channels, 1), # 恢复维度 nn.BatchNorm2d(channels),nn.Sigmoid() # 生成注意力权重
)自下而上的注意力路径
作用: 低层特征告诉高层特征应该补充什么细节
forward:
topdown_wei_1 = self.topdown_1(xh) # 高层→低层1的指导权重
topdown_wei_2 = self.topdown_2(xh) # 高层→低层2的指导权重
bottomup_wei_1 = self.bottomup_1(xl_1) # 低层1→高层的补充权重
bottomup_wei_2 = self.bottomup_2(xl_2) # 低层2→高层的补充权重
xs_1 = 2 * torch.mul(xl_1, topdown_wei_1) + 2 * torch.mul(xh, bottomup_wei_1)
xs_2 = 2 * torch.mul(xl_2, topdown_wei_2) + 2 * torch.mul(xh, bottomup_wei_2)
xs = self.post_1(xs_1) + self.post_1(xs_2)xs = self.post(xs)return xs第一部分: 2 * torch.mul(xl_1, topdown_wei_1)
# 高层特征指导低层特征增强 低层特征 × 高层注意力权重
语义引导: 高层特征告诉低层"哪些空间位置对当前语义任务重要"
效果: 增强低层特征中与高层语义相关的细节
第二部分: 2 * torch.mul(xh, bottomup_wei_1)
# 低层特征补充高层特征细节 高层特征 × 低层注意力权重
细节补充: 低层特征告诉高层"哪些语义信息需要更多空间细节"
效果: 为高层特征注入相关的空间细节
融合后处理
实际工作示例
# 输入特征:
xh: 高层特征 - 知道"这是一个人",但边界模糊
xl_1: 低层特征1 - 清晰的边缘信息
xl_2: 低层特征2 - 丰富的纹理信息# 融合过程:
1. topdown_wei_1: 高层告诉边缘特征"人的轮廓边缘更重要"
2. topdown_wei_2: 高层告诉纹理特征"皮肤纹理比背景纹理更重要"
3. bottomup_wei_1: 边缘特征告诉高层"这些位置需要更清晰的边界"
4. bottomup_wei_2: 纹理特征告诉高层"这些区域需要更丰富的细节"# 结果:融合后的特征既有准确的语义,又有清晰的细节