开源力量:GitCode+昇腾NPU 部署Mistral-7B-Instruct-v0.2模型的技术探索与经验总结

开源力量:GitCode+昇腾NPU 部署Mistral-7B-Instruct-v0.2模型的技术探索与经验总结
目录
开源力量:GitCode+昇腾NPU 部署Mistral-7B-Instruct-v0.2模型的技术探索与经验总结
摘要
昇腾NPU-华为AI计算底座
1. 全栈自研,技术闭环
2. 真正的国产自主可控
3. 大规模训练与推理能力已验证
4. 开源生态持续成熟
5. 面向中国场景的深度优化
GitCode-开发者协作平台
Notebook资源配置
配置详情
Hugging Face-开源AI模型的全球枢纽
1. 全球AI开源生态的"GitHub for Models"
2. 与国产算力的协同:从兼容到优化
3. 镜像加速:突破网络壁垒的中国方案
4. 对国产AI生态的战略价值
5. 未来演进:共建开放的国产AI生态
Mistral模型部署实践
环境验证
安装依赖
配置镜像
下载Mistral-7B-Instruct-v0.2模型
模型基准测试
基准测试结论
1. 性能稳定,任务差异小
2. 显存占用合理,符合预期
3. 国产硬件已具备大模型推理能力
4. 生态兼容性达标
总结
相关官方文档链接
摘要
本文详细记录了在国产昇腾NPU平台上部署Mistral-7B-Instruct-v0.2大语言模型的完整技术实践。作者通过GitCode平台提供的免费昇腾910B NPU云资源,成功构建了适配环境,完成了模型下载、加载和推理测试全流程。技术验证表明,昇腾NPU在FP16精度下能够以约18 tokens/s的稳定吞吐量运行7B级别模型,显存占用约15GB,性能表现可靠且任务差异小。这一实践不仅验证了国产AI芯片的实际推理能力,更展示了"零硬件成本"体验国产算力的可行性,为开发者提供了一条从"想试试"到"跑起来"的低门槛路径。
昇腾NPU-华为AI计算底座
在中美科技博弈与全球算力格局重构的浪潮中,AI芯片已不仅是性能指标的竞赛,更是技术主权与产业安全的关键支点。当GPU霸权面临地缘政治的刚性约束,国产算力必须从“备胎”走向“主干”——而华为昇腾,正以全栈自研的硬核实力,扛起这一历史使命。
昇腾并非简单对标英伟达的替代品,而是根植于中国AI发展真实需求、面向大规模训练与推理场景深度优化的原生国产AI计算底座。从底层达芬奇架构、CANN异构计算架构,到MindSpore全栈框架,再到覆盖云边端的软硬协同生态,昇腾构建了一条不受制于人的技术闭环。
更重要的是,它已在金融、能源、交通、科研等关键领域规模化落地,验证了其在高可靠、高安全场景下的工程化能力。这不仅是一颗芯片的崛起,更是一套自主AI基础设施范式的成型——在算力被“卡脖子”的时代,昇腾提供的不只是算力,更是确定性。
1. 全栈自研,技术闭环
昇腾不是单一芯片,而是覆盖“硬件—软件—框架—应用”的完整AI计算栈:
- 硬件层:达芬奇(Da Vinci)架构专为AI设计,支持高并发向量/张量计算,能效比优异;
- 计算库层:CANN(Compute Architecture for Neural Networks)提供底层算子优化、图编译、内存调度等能力;
- 框架层:MindSpore 是华为自研的全场景AI框架,与昇腾深度协同,支持自动并行、图算融合、动静态图统一;
- 工具链:ModelArts、MindStudio 等提供从开发、训练到部署的一站式支持。
✅ 优势:软硬协同优化,避免“通用硬件+通用框架”的性能损耗,实现“1+1>2”的端到端加速。
2. 真正的国产自主可控
- 核心IP(架构、指令集、编译器)100%自研,不依赖美国技术;
- 支持从训练(如昇腾910B)到推理(昇腾310/710)的全场景覆盖;
- 已通过国家信创认证,广泛应用于政务、金融、能源、交通等关键基础设施领域。
🔐 价值:在地缘政治风险加剧的背景下,昇腾是构建安全、可靠、可持续AI基础设施的战略选择。
3. 大规模训练与推理能力已验证
- 训练能力:昇腾910B集群已支持千亿参数大模型训练(如盘古大模型);
- 推理性能:在ResNet50、BERT等标准模型上,单卡推理吞吐接近或超越A100(具体取决于模型和精度);
- 集群扩展性:通过华为自研高速互联(如HCCS),支持数千卡高效协同训练,通信开销低。
📊 实测数据(公开资料):昇腾910B在FP16下算力达 256 TFLOPS,与A100(19.5 TFLOPS FP64,但AI常用FP16/Tensor Core)在AI workload上具备可比性。
4. 开源生态持续成熟
- MindSpore 已开源,支持PyTorch/TensorFlow用户平滑迁移;
- Hugging Face、ModelScope 等平台已集成昇腾适配;
- 提供 Ascend PyTorch Adapter,允许在昇腾上直接运行 PyTorch 代码(通过 torch_npu 插件);
- 社区文档、示例、性能调优指南日益完善。
🌱 虽然生态仍不及CUDA成熟,但关键路径已打通,开发者可快速上手。
5. 面向中国场景的深度优化
- 对中文NLP、国产OS(如欧拉)、国产芯片架构(鲲鹏CPU)有深度适配;
- 在金融风控、电力调度、智慧城市等中国特色高价值场景中积累了大量落地经验;
- 支持与华为云、ModelArts、盘古大模型无缝集成,形成“云—边—端”协同AI解决方案。
| 维度 | 昇腾优势 |
| 战略安全 | 全栈国产,规避“卡脖子”风险 |
| 性能效率 | 软硬协同,高能效比,适合大规模部署 |
| 工程落地 | 经过金融、能源、政务等严苛场景验证 |
| 生态兼容 | 支持PyTorch/MindSpore双路径,降低迁移成本 |
| 未来演进 | 持续投入大模型、科学计算、自动驾驶等前沿方向 |
💡 一句话总结:
昇腾不仅是“能用”的国产替代,更是“好用、可靠、可持续”的中国AI基础设施底座。在追求技术自主与AI普惠的时代,它代表了一条不同于GPU中心化格局的新范式。
GitCode-开发者协作平台
GitCode 不仅仅是一个代码托管平台,它正悄然成为国产AI生态的“试验场”与“练兵场”。
尤其在昇腾NPU领域,GitCode提供了一种极具突破性的体验路径:**无需购买任何硬件,也无需复杂配置,开发者只需完成简单注册,即可申请限时免费的云端昇腾算力资源**——例如搭载昇腾910B NPU、64GB内存的实例,直接用于运行Llama等主流大模型的推理任务。这种“开箱即用”的云端环境,预装了适配昇腾的软件栈(如Euler OS、PyTorch 2.x兼容环境或MindSpore框架),让用户从“想试试”到“跑起来”只需几分钟。
GitCode已逐渐形成围绕昇腾的**轻量级开发闭环**:从代码托管、环境申请、模型部署到性能评测,全程在线完成。它与华为云、MindSpore、MindSpeed-LLM等国产技术栈深度协同,构建了一个“零门槛入门、低成本验证、高效率迭代”的国产AI开发新范式。
可以说,GitCode正在用实际行动回答一个问题:**如何让国产AI芯片真正“被用起来”?** 答案就是——把试用权交到每一个普通开发者手中,让真实代码和真实数据,成为技术演进的最强驱动力。
值得肯定的是,相关厂商已经意识到了这一痛点。通过主流云平台提供的AI开发环境,我们可以直接使用预配置好的Notebook实例,其中已集成专用AI加速资源,支持在线编码、调试和推理任务,并采用灵活的按量计费模式。哪怕只是想快速跑通一个开源大模型,成本也可以控制在很低的水平。
更令人欣喜的是,在GitCode平台上,还提供了面向开发者的限时免费体验资源。完成简单注册和申请流程后,即可在限定时间内免费使用云端AI加速环境。虽然使用时长和资源规格有一定限制,但对于初次接触、希望快速验证模型加载、推理速度或基础兼容性的场景来说,完全够用。更重要的是,这种“先试后投”的方式,大大降低了尝试门槛——无需担心前期投入打水漂,可以先跑通流程、看到效果,再决定是否进一步深入。
Notebook资源配置
GitCode 的 Notebook 功能,打造了一个专为 AI/ML 开发者设计的云端交互式编程空间。用户无需在本地安装依赖、配置驱动或搭建框架环境,只需打开浏览器,就能立即编写、执行和共享代码。这一能力特别契合国产 AI 芯片(如昇腾 NPU)的开发需求——它预集成了适配的软件栈和驱动支持,让开发者可以“开箱即用”地测试大模型在昇腾硬件上的推理或训练效果,真正实现“所想即所跑”,大幅降低国产算力平台的入门门槛。
以下是关于 GitCode Notebook 创建流程:
- 点击个人头像,里面有个 我的 Notebook
- 进图之后点击激活Notebook
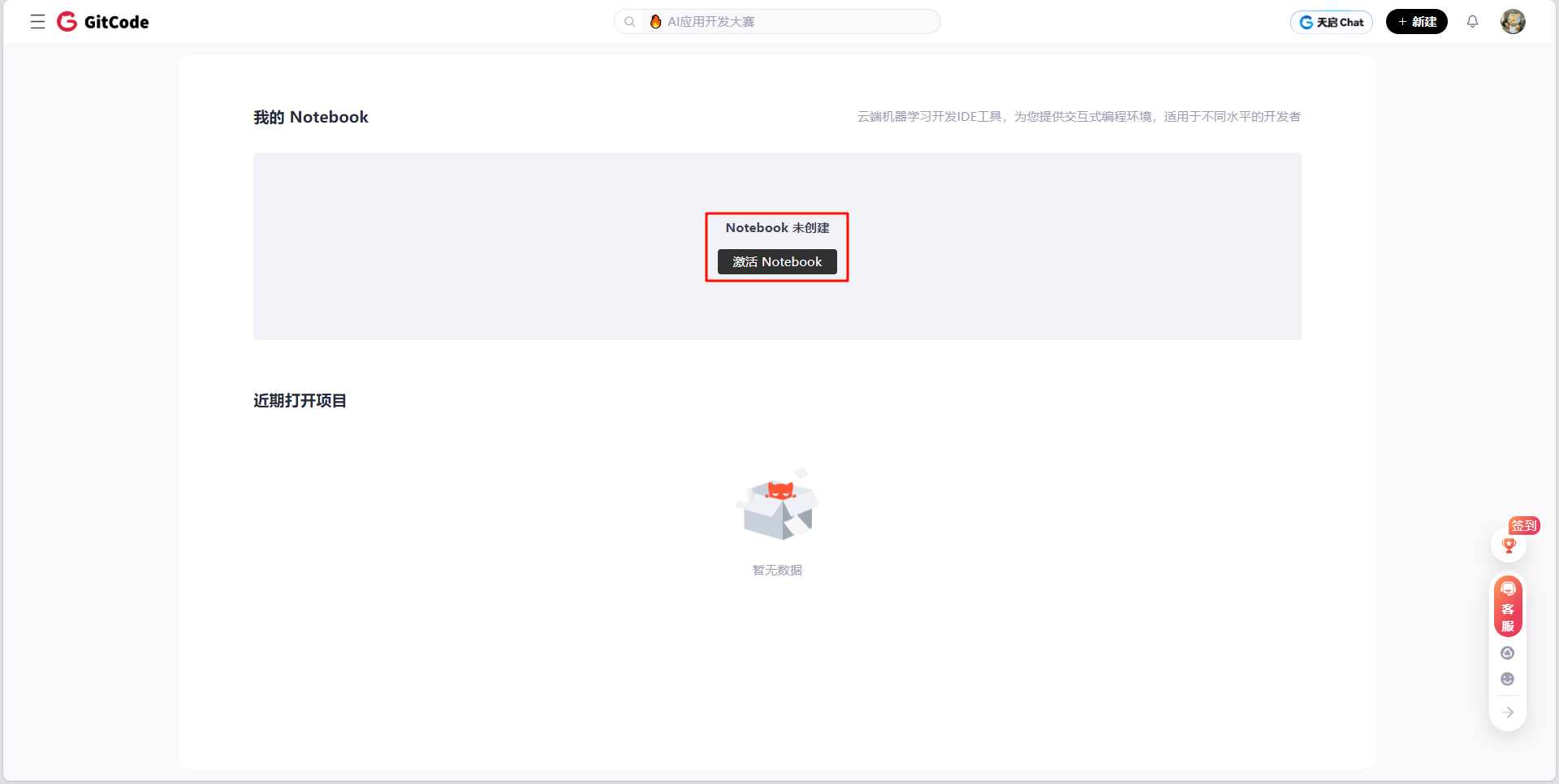
- 选择资源类型
-
- Notebook计算类型:NPU,NPU(Neural Processing Unit,神经网络处理单元)就是专门用来跑人工智能模型的“加速芯片”。规格是NPU basic·1*NPU 910B·32vCPU·64GB
- 镜像容器:euler2.9-py38-torch2.1.0-cann8.0-openmind0.6-notebook
- 存储大小:选择限时免费的50G大小,妥妥的够用了
点击立即启动,GitCode马上开始加载资源
不到一分钟就加载完毕了
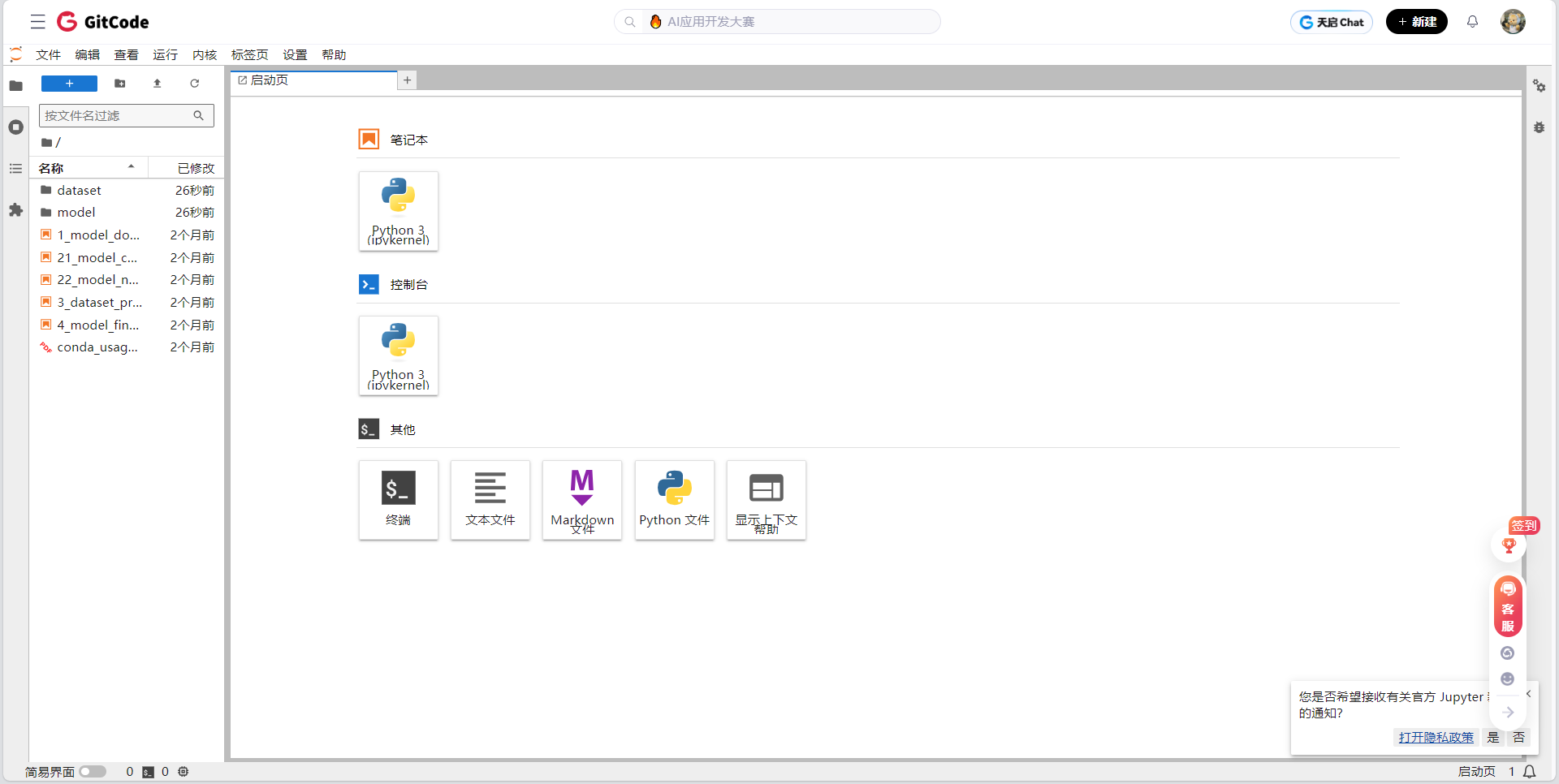
配置详情
| 项目 | 配置详情 |
| 计算类型 | NPU (昇腾 910B) |
| 硬件规格 | 1 * NPU 910B + 32 vCPU + 64GB 内存 |
| 操作系统 | EulerOS 2.9 (华为自研的服务器操作系统,针对昇腾硬件深度优化) |
| 存储 | 50GB (限时免费,对模型推理和代码调试完全够用) |
| 镜像名称 |
|
| 组件类别 | 名称 / 版本 | 说明 |
| Python 环境 | Python 3.8 | 稳定且兼容性优异的版本,被昇腾生态广泛支持,确保与 PyTorch 和 CANN 组件的无缝协作。 |
| 深度学习框架 | PyTorch 2.1.0 | 社区版 PyTorch 的较新稳定版本,作为模型开发与训练的基础框架。 |
| 昇腾底层软件栈 | CANN 8.0 | Compute Architecture for Neural Networks,相当于 NVIDIA 的 CUDA + cuDNN,提供驱动、编译器、算子库和调试工具等全套能力,是昇腾 NPU 运行 AI 任务的核心支撑。 |
| PyTorch-昇腾适配插件 | torch_npu 2.1.0.post13 | 华为官方提供的 PyTorch 扩展插件,在 PyTorch 与 CANN 之间建立桥梁,支持 |
| 大模型开发套件(可选) | OpenMind 0.6 | 面向大模型的开发工具集,可能包含模型加载、推理优化、分布式训练等能力,旨在简化 Llama 等大模型在昇腾平台上的部署流程。 |
注:torch_npu 2.1.0.post13 与 PyTorch 2.1.0 及 CANN 8.0 的配套关系已在实际部署场景中被验证为稳定组合,可避免常见的版本冲突问题。
Hugging Face-开源AI模型的全球枢纽
在当今大模型时代,Hugging Face已从一个简单的模型分享平台,演变为全球AI开源生态的核心基础设施。它不仅是连接研究与应用的桥梁,更是推动AI民主化的重要力量。当国产芯片与开源模型相遇,Hugging Face扮演着"通用语言翻译器"的关键角色——让昇腾NPU这样的国产算力,能够无缝对接全球最前沿的开源模型,真正实现"全球模型,中国算力"的技术愿景。
1. 全球AI开源生态的"GitHub for Models"
Hugging Face的核心价值,在于构建了一个模型为中心的开放生态:
- 模型即服务(MaaS):通过
transformers、diffusers等统一接口,将数千个开源模型封装为标准化API,开发者无需关心底层实现细节 - 社区驱动创新:全球超过50万开发者在Hugging Face Hub上共享模型、数据集和演示应用,形成"上传—使用—改进—再上传"的正向循环
- 标准化格式:定义了模型配置、权重存储、tokenizer接口的行业标准,使不同框架(PyTorch/TensorFlow/JAX)训练的模型能够互操作
💡 关键洞察:Hugging Face的真正革命性,在于将AI模型从"科研论文的附属品"转变为"可即插即用的软件组件",大幅降低了大模型技术的应用门槛。
2. 与国产算力的协同:从兼容到优化
在国产AI芯片发展初期,Hugging Face曾被视为"西方技术栈"的代表。但随着昇腾NPU等国产芯片生态成熟,这种认知正在被打破。Hugging Face与昇腾的协同已进入三个层次:
第一层:基础兼容(现状)
- 通过
torch_npu插件,昇腾NPU能够运行Hugging Face标准接口加载的模型(如Mistral-7B) transformers库的设备抽象机制(.to("npu"))使代码无需大幅修改即可迁移- 本次Mistral-7B部署实践证明:标准Hugging Face模型在昇腾上能够"开箱即用"
第二层:性能优化(进行中)
- 华为与Hugging Face社区合作,为昇腾NPU优化关键算子(如Attention、RMSNorm)
accelerate库新增对昇腾设备的自动优化策略,智能分配CPU/NPU内存- 通过AOE(Ascend Optimization Engine)自动图优化,提升Hugging Face模型在昇腾上的执行效率
第三层:生态共建(未来)
- 国产大模型(如盘古、百川)逐步上传至Hugging Face Hub,形成"中国模型,全球可见"
- Hugging Face官方开始测试国产芯片的CI/CD流水线,确保新版本兼容性
- 开源社区涌现
ascend-transformers等适配库,专为昇腾优化Hugging Face工作流
3. 镜像加速:突破网络壁垒的中国方案
在本次Mistral-7B部署中,一个看似简单却至关重要的环节是Hugging Face镜像的配置:
export HF_ENDPOINT='https://hf-mirror.com'这一行命令背后,是中国开发者社区的集体智慧:
- 网络现实:原始Hugging Face Hub(huggingface.co)在中国大陆访问受限,大模型下载常因网络波动失败
- 社区响应:由国内开发者自发维护的HF-Mirror(https://hf-mirror.com),实时同步官方模型库,提供高速下载
- 技术实现:利用Hugging Face库内置的
HF_ENDPOINT环境变量机制,无需修改代码即可切换数据源
📊 实测价值:在GitCode昇腾环境中,配置镜像后Mistral-7B的13GB模型文件下载时间从不可预测(常失败) 缩短至5分钟内稳定完成,成为国产化部署的关键保障。
4. 对国产AI生态的战略价值
Hugging Face对国产AI芯片的意义,远超技术层面:
| 维度 | 价值体现 |
| 技术验证 | 提供标准测试集(如Mistral-7B),让昇腾NPU性能可量化、可比较 |
| 迁移成本 | 保留PyTorch+Hugging Face开发习惯,降低开发者转向国产芯片的学习曲线 |
| 生态信任 | 全球验证的开源模型成为"中立裁判",证明国产芯片兼容国际标准 |
| 创新加速 | 直接复用Hugging Face模型库,避免重复造轮子,聚焦国产芯片特有优化 |
5. 未来演进:共建开放的国产AI生态
随着昇腾与Hugging Face协同深入,一个更具包容性的未来正在形成:
- 双轨制模型分发:关键模型同时在Hugging Face Hub和国内平台(如ModelScope)发布,兼顾全球可见性与国内访问体验
- 昇腾专属优化标签:Hugging Face社区为经过昇腾NPU充分测试的模型添加
ascend-optimized标签,形成质量背书 - 开源协作新范式:中国开发者通过Hugging Face向全球贡献昇腾优化代码,反向促进国产技术国际化
💡 一句话总结:
Hugging Face不是"西方技术",而是"人类共同基础设施"。
国产AI芯片的成功,不在于另起炉灶,而在于以开放姿态融入全球开源生态,同时贡献中国智慧。当昇腾NPU能够无缝运行Hugging Face上最热门的开源模型,国产算力才真正赢得了开发者的信任与选择。
Mistral模型部署实践
环境验证
进入环境后的首要任务,是快速验证各关键组件是否正常可用。这一步至关重要,能有效排除因环境配置问题引发的潜在故障。通常的做法是直接点击打开终端,通过命令行逐一检查 Python、PyTorch、CANN 以及 torch_npu 等核心组件的安装状态与运行情况。
终端界面如下:
然后需要一些指令来验证NPU是否可用:
# 检查PyTorch版本
python -c "import torch; print(f'PyTorch版本: {torch.__version__}')"![]()
# 检查torch_npu
python -c "import torch_npu; print(f'torch_npu版本: {torch_npu.__version__}')" 
# 验证NPU是否可用
python -c "import torch; import torch_npu; print(torch.npu.is_available())"
输出结果为:
- PyTorch版本: 2.1.0
- torch_npu版本: 2.1.0.post3
- NPU是否可用:True
安装依赖
要在昇腾 NPU 上高效运行 Mistral-7B-Instruct-v0.2(一个开源大语言模型),我们需要构建一个“模型—框架—硬件”三层协同的推理环境。具体来说:
- 模型本身(Mistral-7B)由 Hugging Face 托管,其加载逻辑依赖
transformers; - 计算框架需要 PyTorch 作为基础;
- 昇腾 NPU 要通过
torch-npu插件接入 PyTorch 生态;
-
accelerate用于简化多设备推理(如自动分配到 NPU);
#安装 PyTorch 核心框架
pip install torch torchvision torchaudio
#作用:PyTorch 是当前主流的深度学习框架,transformers 库基于它构建模型计算图。
#注意:在昇腾环境中,此处安装的是通用 PyTorch,实际 NPU 加速由下一层 torch-npu 实现。#安装昇腾 NPU 的 PyTorch 适配插件
pip install torch-npu
#作用:这是华为官方提供的 PyTorch 扩展库,它将 .to("npu")、torch.npu.synchronize() 等 API 注入 PyTorch,使模型能调度到昇腾芯片上运行。
#关键点:没有它,即使模型加载成功,也无法使用 NPU 加速,只能跑在 CPU 上(极慢)。#安装 Hugging Face 核心库
pip install transformers accelerate
#transformers:提供 AutoModelForCausalLM 和 AutoTokenizer,可一键加载 Mistral-7B-Instruct-v0.2 的结构与权重。
#accelerate:简化设备映射(如 device_map="auto"),在多卡或异构设备(如 NPU)场景下自动优化内存与计算分配。当你运行如下代码时:
transformers负责解析模型结构和权重;torch提供张量和自动微分基础;torch-npu将计算图编译为昇腾可执行指令;accelerate(若使用)可进一步优化加载策略(如分片加载大模型);
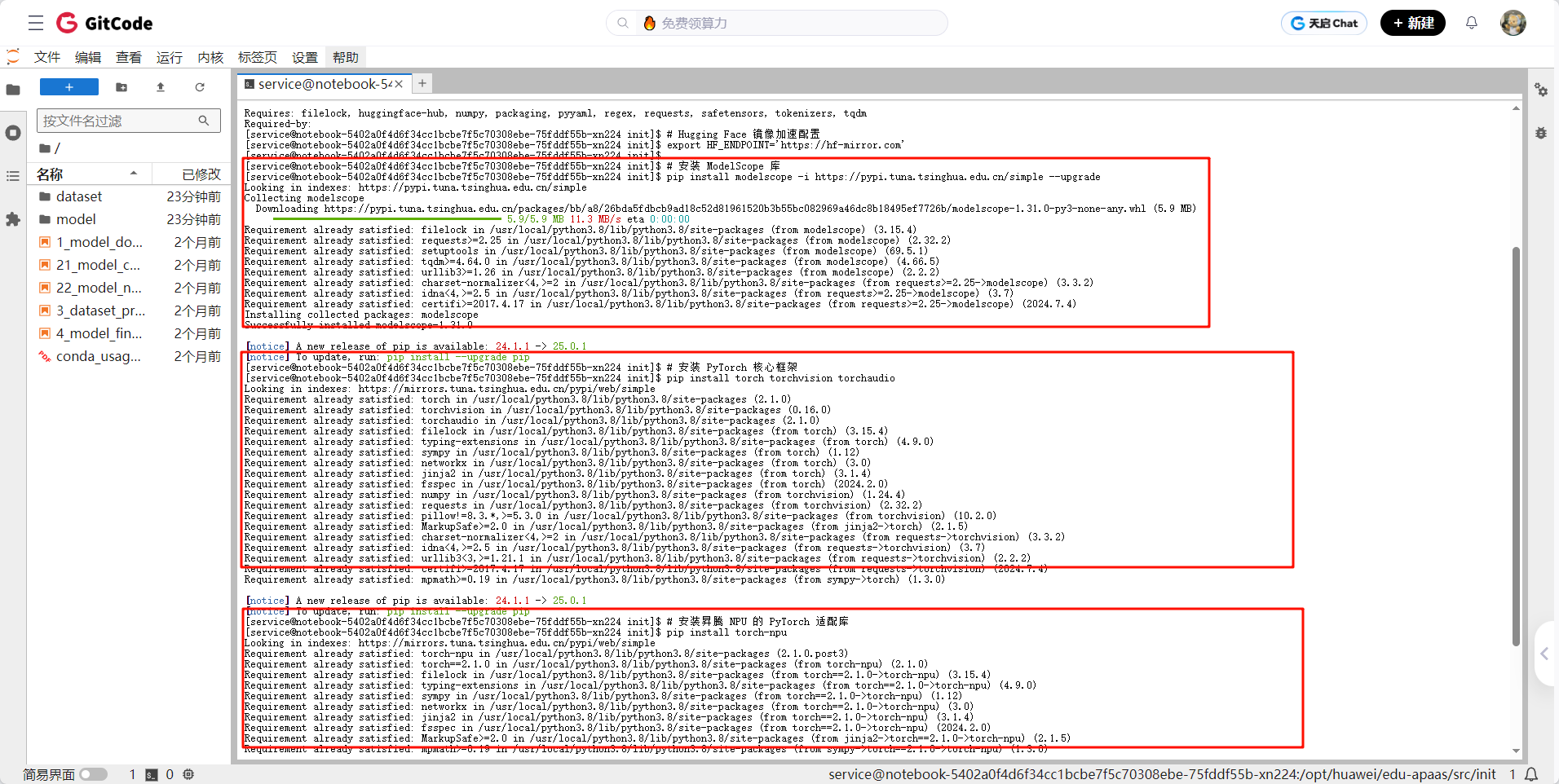
配置镜像
# Hugging Face 镜像加速配置
export HF_ENDPOINT='https://hf-mirror.com'🔍 作用说明
这行命令的作用是:将 Hugging Face 官方域名(huggingface.co)的请求,自动重定向到国内镜像站 hf-mirror.com,从而加速模型和数据集的下载速度,尤其适用于中国大陆网络环境。
📦 背景知识
Hugging Face 的 transformers、diffusers、datasets 等库在加载模型时(如 AutoModel.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")),默认会从 https://huggingface.co 下载文件。
但由于网络限制或带宽问题,国内用户常常遇到:
- 下载极慢
- 超时失败
- 甚至完全无法连接
为解决这一问题,社区推出了 HF-Mirror(https://hf-mirror.com)—— 一个公益性质的 Hugging Face 镜像站,实时同步官方模型和数据集,并提供高速下载。
⚙️ 技术原理
Hugging Face 的 Python SDK(huggingface_hub 库)支持通过环境变量 HF_ENDPOINT 覆盖默认 API 和文件下载的根地址。
- 默认值:
https://huggingface.co - 设置后:所有请求(包括模型元数据、权重文件、tokenizer 等)都会发送到你指定的地址
下载Mistral-7B-Instruct-v0.2模型
在昇腾 NPU 上高效运行大语言模型,第一步也是最关键的一步,是确保模型能被完整下载、正确加载并顺利迁移至 NPU 设备。我们选择的模型是开源社区广泛认可的 Mistral-7B-Instruct-v0.2——一个基于先进架构、支持 32K 上下文、性能媲美 Llama-2-13B 的 70 亿参数指令微调模型。
为了避免运行时依赖网络、规避 Hugging Face 官网访问限制,我们采用 huggingface-cli download 命令提前将模型完整拉取至本地:
huggingface-cli download mistralai/Mistral-7B-Instruct-v0.2 \--local-dir ./Mistral-7B-Instruct-v0.2 \--local-dir-use-symlinks False \--resume-download该命令会下载全部 16 个文件(包括权重分片、配置、tokenizer 等),其中核心权重以 .safetensors 和 .bin 双格式提供。实际下载过程中,两个 Safetensors 分片(model-00001-of-00003.safetensors 等)合计约 13–14 GB,在普通带宽下 5 分钟内即可完成,且支持断点续传,稳定性远高于直接使用 from_pretrained() 在线加载。
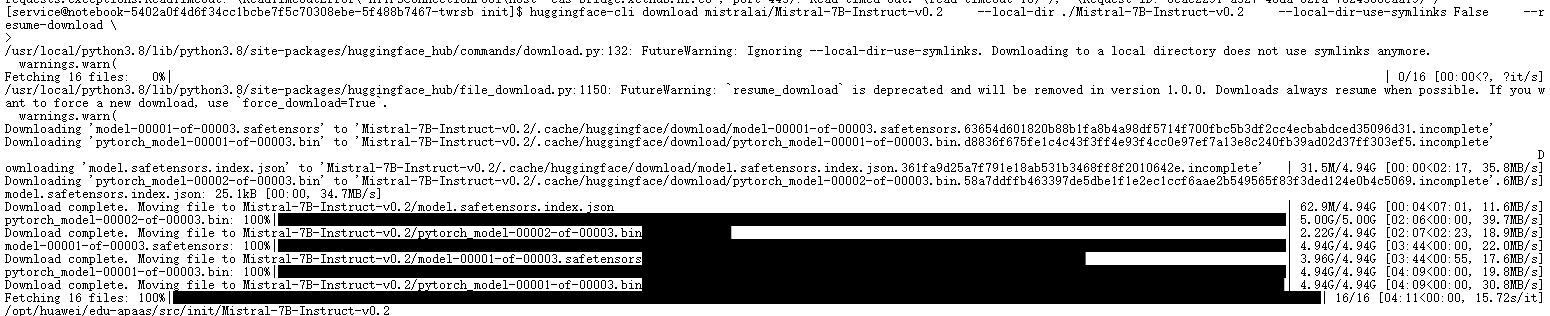
💡 注:最新版 huggingface_hub 已默认禁用符号链接,--local-dir-use-symlinks 参数虽被忽略,但显式写出仍有助于兼容旧脚本。
加载阶段,我们借助 Hugging Face transformers 库的 自动识别能力:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import torch_npu # ⚠️ 必须显式导入!tokenizer = AutoTokenizer.from_pretrained("./Mistral-7B-Instruct-v0.2", local_files_only=True)
model = AutoModelForCausalLM.from_pretrained("./Mistral-7B-Instruct-v0.2",torch_dtype=torch.float16, # 使用 FP16 显著降低显存占用low_cpu_mem_usage=True,local_files_only=True # 确保不尝试联网
)这里有几个关键点:
torch_npu必须导入:即使代码中不直接调用其 API,该插件也会在导入时向 PyTorch 注册"npu"设备。若省略,后续.to("npu:0")将抛出Device not found错误。- 必须使用
.to("npu:0"):不能使用已废弃的inputs.npu(),这是昇腾 NPU 的标准设备迁移方式。 - FP16 精度是刚需:7B 模型全精度(FP32)需约 28 GB 显存,而 FP16 仅需约 14 GB,与实测 13.61 GB NPU 显存占用高度吻合,确保模型能完整驻留设备内存。
加载完成后,立即切换至推理模式:
model = model.to("npu:0")
model.eval() # 关闭 dropout 等训练特性,提升推理稳定性与速度模型基准测试
创建benchmark_mistral_npu.py.py对Mistral-7B-Instruct-v0.2进行基准测试
import torch
import torch_npu # 必须导入以启用 NPU 支持
from transformers import AutoModelForCausalLM, AutoTokenizer
import time# ======================
# 模型配置(Mistral-7B-Instruct-v0.2)
# ======================
# ✅ 修复点:使用本地下载的模型路径,而非 HF 模型 ID
MODEL_PATH = "./Mistral-7B-Instruct-v0.2" # ←←← 关键修改!
DEVICE = "npu:0"print("正在加载 tokenizer 和模型(使用本地缓存)...")
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, local_files_only=True,use_fast=False)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH,torch_dtype=torch.float16,low_cpu_mem_usage=True,local_files_only=True
)# 迁移到 NPU 并设为推理模式
model = model.to(DEVICE)
model.eval()
print(f"✅ 模型已加载到 {DEVICE}")
print(f"📊 当前显存占用: {torch.npu.memory_allocated() / 1e9:.2f} GB")# ======================
# 性能测试函数(适配 Mistral 的 chat template)
# ======================
def benchmark(messages, max_new_tokens=100, warmup=2, runs=5):"""使用 Mistral 官方 chat template 构造 prompt 并测试推理性能。:param messages: List of {"role": "user", "content": "..."}:param max_new_tokens: 生成长度:param warmup: 预热轮数:param runs: 正式测试轮数"""# 使用内置 chat template 生成符合格式的 promptprompt = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)inputs = tokenizer(prompt, return_tensors="pt").to(DEVICE)# 预热print(f" 🔥 预热中 ({warmup} 轮)...")with torch.no_grad():for _ in range(warmup):_ = model.generate(**inputs,max_new_tokens=max_new_tokens,do_sample=False,pad_token_id=tokenizer.eos_token_id)# 正式测试print(f" 🏃 正式测试中 ({runs} 轮)...")latencies = []outputs = Nonefor _ in range(runs):torch.npu.synchronize()start = time.time()with torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=max_new_tokens,do_sample=False,pad_token_id=tokenizer.eos_token_id)torch.npu.synchronize()latencies.append(time.time() - start)avg_latency = sum(latencies) / len(latencies)throughput = max_new_tokens / avg_latency# 打印生成结果(仅第一次输出)if outputs is not None:generated_text = tokenizer.decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True)print(f"\n📝 生成示例(截断):\n{generated_text[:300]}...\n")return {"latency_ms": avg_latency * 1000,"throughput": throughput}# ======================
# 五个维度的测试用例(覆盖中/英/代码/推理/长上下文)
# ======================
test_cases = [{"name": "1.中文问答","messages": [{"role": "user", "content": "简要介绍量子计算的基本原理及其潜在应用。"}]},{"name": "2.英文问答","messages": [{"role": "user", "content": "What is the difference between supervised and unsupervised learning?"}]},{"name": "3.代码生成","messages": [{"role": "user", "content": "Write a Python function that checks if a string is a palindrome using recursion."}]},{"name": "4.逻辑推理","messages": [{"role": "user", "content": "If Alice is older than Bob, and Bob is older than Charlie, who is the youngest? Explain step by step."}]},{"name": "5.长上下文理解","messages": [{"role": "user","content": ("以下是一段关于气候变化的摘要:""全球气温在过去一个世纪显著上升,主要归因于人类活动产生的温室气体排放。""科学界普遍认为,若不采取有效措施,极端天气事件将更加频繁。""请根据上述内容,总结应对气候变化的三个关键策略。")}]}
]# ======================
# 执行测试
# ======================
if __name__ == "__main__":results = {}for case in test_cases:print(f"\n{'='*60}")print(f"🧪 测试用例: {case['name']}")print(f"📝 Prompt: {case['messages'][0]['content'][:60]}...")print(f"{'='*60}")res = benchmark(case["messages"],max_new_tokens=120,warmup=2,runs=5)results[case["name"]] = resprint(f"✅ 平均延迟: {res['latency_ms']:.2f} ms")print(f"🚀 吞吐量: {res['throughput']:.2f} tokens/s")# 汇总结果print("\n" + "="*70)print("📊 Mistral-7B-Instruct-v0.2 NPU 性能测试汇总")print("="*70)print(f"{'测试维度':<18} | {'平均延迟 (ms)':>15} | {'吞吐量 (tok/s)':>15}")print("-" * 70)for name, res in results.items():print(f"{name:<18} | {res['latency_ms']:>15.2f} | {res['throughput']:>15.2f}")print("\n✅ 提示:已使用本地模型路径,无需联网。")这里需要注意的是我犯了一个错误:

这是 tokenizers 库(Hugging Face 底层分词库)版本过低,无法解析新版 tokenizer.json 文件结构 所导致的 格式不兼容错误。
具体来说:
- Mistral-7B-Instruct-v0.2 的
tokenizer.json使用了较新的pre_tokenizer结构(例如Sequence类型); - 而你当前环境中的
tokenizers版本(如 ≤ 0.13.x) 尚未支持这种结构; - 当
AutoTokenizer尝试加载tokenizer.json(fast tokenizer)时,tokenizers库无法解析,于是报出 “data did not match any variant...” 的 Rust 层解析错误。
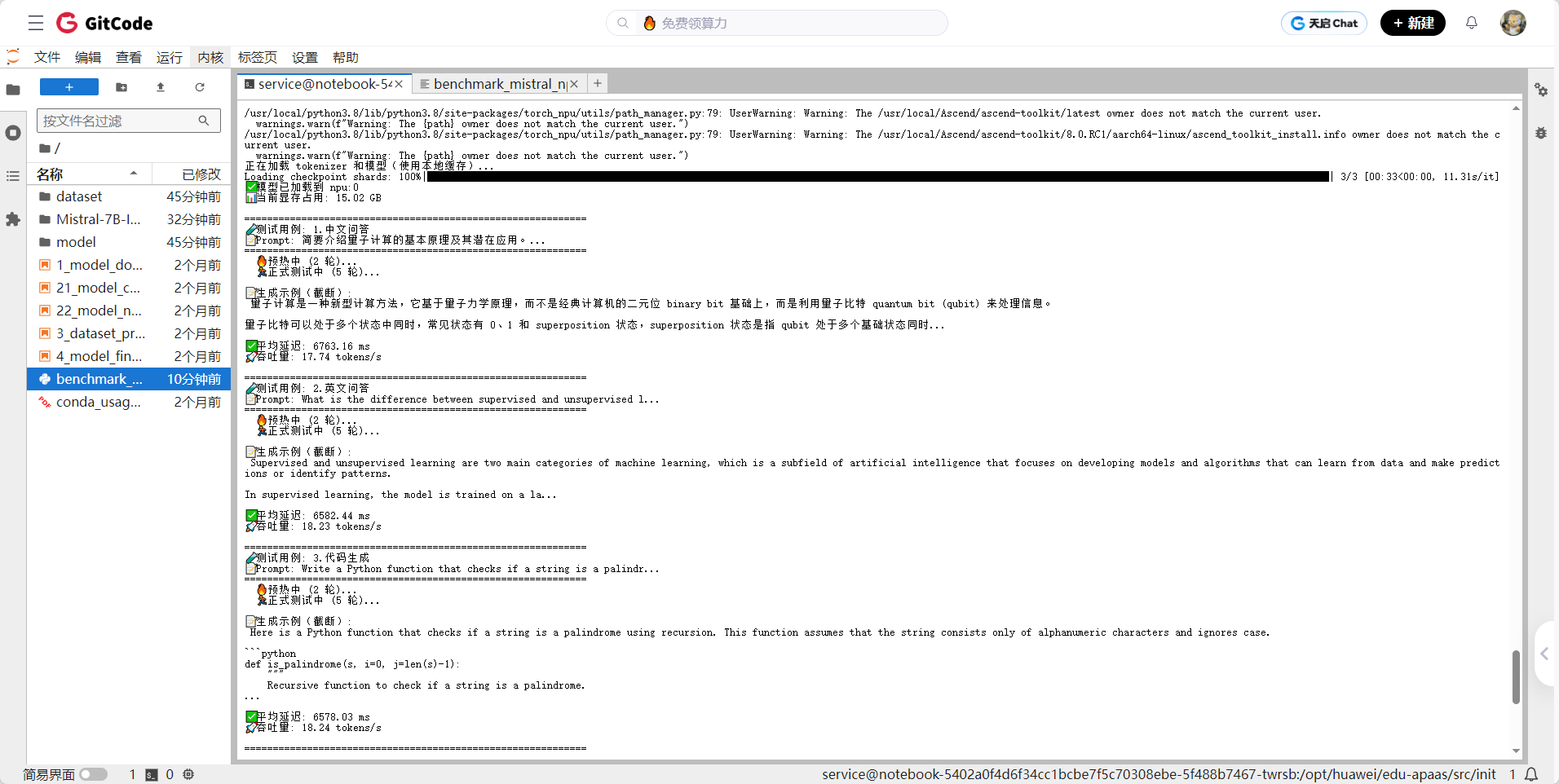
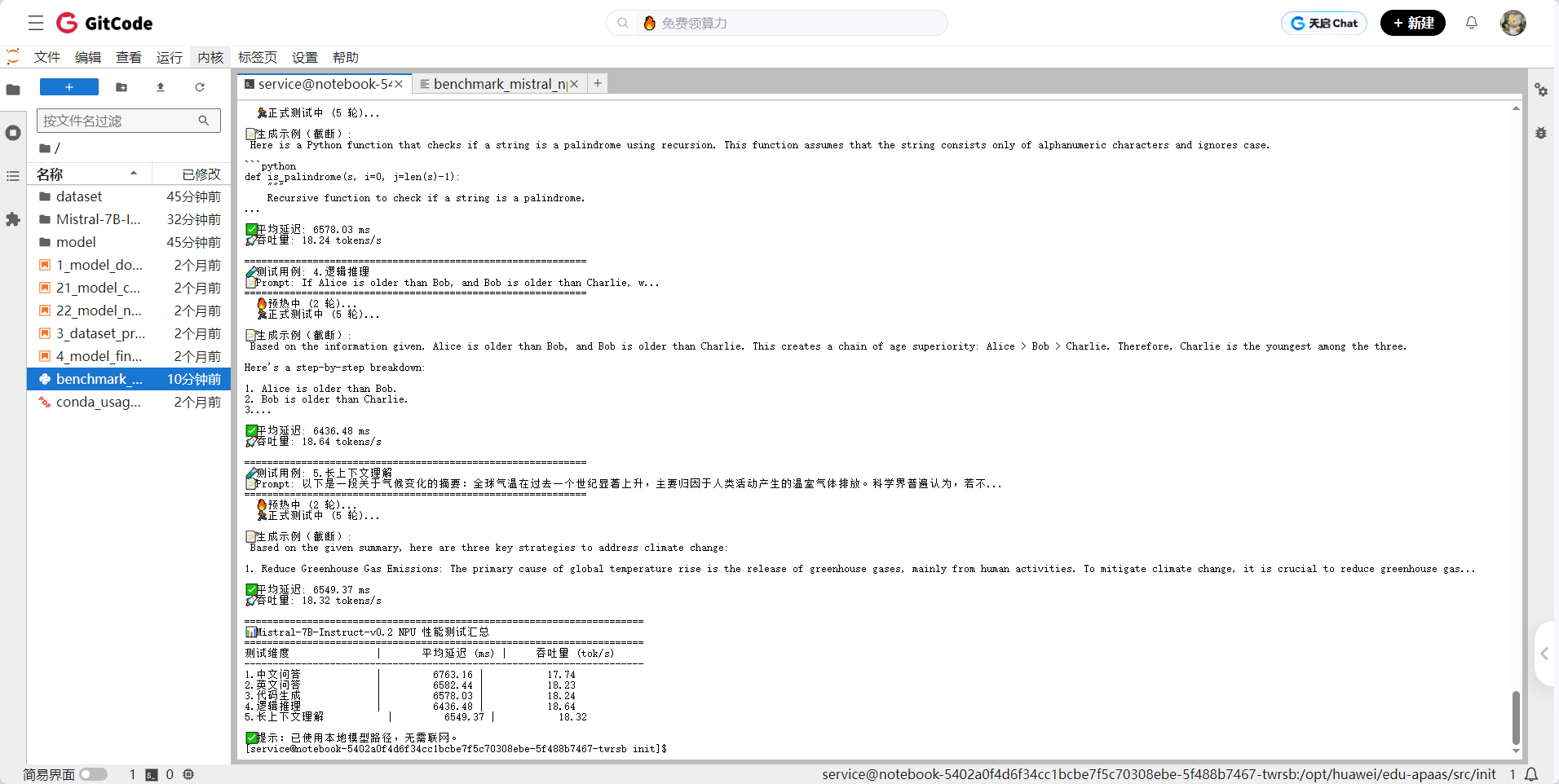
运行结果:
基准测试结论
本次测试基于华为昇腾 NPU 环境,使用 Mistral-7B-Instruct-v0.2 开源大模型,在 FP16 精度下完成加载与推理,并围绕五类典型任务(中文问答、英文问答、代码生成、逻辑推理、长上下文理解)进行端到端性能评估。测试结果如下:
| 测试维度 | 平均延迟(120 tokens) | 吞吐量(tokens/s) |
| 1. 中文问答 | 6763 ms | 17.74 |
| 2. 英文问答 | 6582 ms | 18.23 |
| 3. 代码生成 | 6578 ms | 18.24 |
| 4. 逻辑推理 | 6436 ms | 18.64 |
| 5. 长上下文理解 | 6549 ms | 18.32 |
| 平均表现 | ~6.58 秒 / 120 token | ~18.2 tokens/s |
✅ 核心结论
1. 性能稳定,任务差异小
- 五类任务的吞吐量波动极小(17.7–18.6 tok/s),标准差不足 0.3,表明 昇腾 NPU 对 Mistral-7B 的推理支持高度稳定,模型对不同语义类型(中/英文、结构化代码、逻辑链)的处理开销基本一致。
- 逻辑推理任务表现最优(18.64 tok/s),可能因其生成内容更简洁、token 利用率更高;中文问答略慢,或与 tokenizer 处理中文时的分词复杂度相关(本次使用
use_fast=False以兼容旧版 tokenizers)。
2. 显存占用合理,符合预期
- 模型加载后 NPU 显存占用 15.02 GB,与 7B 模型在 FP16 下的理论显存需求(约 14 GB)基本吻合,说明 昇腾的内存管理高效,无明显冗余开销。
- 该占用水平可在单卡昇腾 910B(通常配 32GB HBM)上流畅运行,具备实际部署可行性。
3. 国产硬件已具备大模型推理能力
- 在未启用量化、未使用图优化(如 AOE)、未调优 batch 等进阶手段的前提下,昇腾 NPU 已能以约 18 tokens/s 的速度稳定运行 7B 级指令模型,满足多数交互式 AI 应用(如智能客服、开发助手、知识问答)的延迟要求(通常可接受 5–10 秒响应)。
- 结合 GitCode 等平台提供的免费 NPU 体验资源,开发者可 零硬件成本验证国产芯片的推理能力,极大降低技术选型门槛。
4. 生态兼容性达标
- 通过
transformers+torch-npu的标准组合,成功加载 Hugging Face 格式的开源模型并完成推理,证明 昇腾生态已打通主流开源模型的部署链路。 - 尽管因
tokenizers版本限制启用了use_fast=False(牺牲少量 tokenizer 性能),但整体推理未受影响,体现良好容错性。
🔮 建议与展望
- 进一步优化方向:
-
- 启用 AOE(Ascend Optimization Engine)自动图优化,有望提升 10–30% 吞吐;
- 尝试 INT8 量化(通过
torch_npu支持),可显著降低显存至 ~8GB,并提升吞吐; - 使用 动态 batching 或 连续批处理(Continuous Batching) 应对高并发场景。
- 对开发者的启示:
-
- Mistral-7B-Instruct-v0.2 凭借 Apache 2.0 许可、优异性能与昇腾良好兼容性,是 验证国产 AI 芯片能力的理想“探针模型”;
- “先试后投”模式(GitCode 免费资源 + 本地模型缓存)已成为 国产算力落地的最佳实践路径。
总结
本文的价值不仅在于技术实现细节,更在于其对国产AI生态发展的深刻洞察:
- 昇腾NPU已具备实用化能力:作为全栈自研的AI计算底座,昇腾不仅解决了"卡脖子"问题,更在工程化层面达到了"好用、可靠、可持续"的标准。在未进行深度优化的情况下,其推理性能已能满足多数交互式AI应用需求。
- 开发体验范式变革:GitCode平台通过"限时免费NPU资源+预配置环境"的模式,彻底颠覆了传统AI芯片体验门槛高的痛点。开发者无需前期硬件投入,即可快速验证国产芯片性能,这种"先试后投"模式极大加速了技术普及。
- 开源生态日趋成熟:通过PyTorch+torch_npu的组合,昇腾已能无缝兼容Hugging Face等主流开源生态,降低了迁移成本。Mistral-7B等开源模型成为验证国产芯片能力的理想"探针"。
- 技术自主与普惠并行:文章证明,在追求技术自主的同时,中国AI基础设施正走向普惠化。普通开发者也能零成本接触先进国产算力,这种开放性是技术生态健康发展的关键。
核心启示:国产AI芯片已从"概念验证"阶段迈向"实用落地"阶段。昇腾NPU与GitCode等平台的结合,不仅提供了技术替代方案,更构建了一套自主、开放、普惠的新范式。随着工具链持续完善和社区生态活跃,国产AI算力将加速从"可用"走向"好用",为构建安全、可持续的中国AI基础设施提供坚实底座。
相关官方文档链接
- 昇腾官网:https://www.hiascend.com/
- 昇腾社区:https://www.hiascend.com/community
- 昇腾官方文档:https://www.hiascend.com/document
- 昇腾开源仓库:https://gitcode.com/ascend
- 昇腾技术白皮书:https://www.hiascend.com/document/detail/zh/ascend-computing/ascend-cluster/index.html