【Agentic RL 专题】四、深入浅出RAG原理与实战项目

🧔 这里是九年义务漏网鲨鱼,研究生在读,主要研究方向是人脸伪造检测,长期致力于研究多模态大模型技术;国家奖学金获得者,国家级大创项目一项,发明专利一篇,多篇论文在投,蓝桥杯国家级奖项、妈妈杯一等奖。
✍ 博客主要内容为大模型技术的学习以及相关面经,本人已得到B站、百度、唯品会等多段多模态大模型的实习offer,为了能够紧跟前沿知识,决定写一个“从零学习 RL”主题的专栏。这个专栏将记录我个人的主观学习过程,因此会存在错误,若有出错,欢迎大家在评论区帮助我指出。除此之外,博客内容也会分享一些我在本科期间的一些知识以及项目经验。
🌎 Github仓库地址:Baby Awesome Reinforcement Learning for LLMs and Agentic AI
📩 有兴趣合作的研究者可以联系我:yirongzzz@163.com
RAG(Retrieval-Augmented Generation)
文章目录
- RAG(Retrieval-Augmented Generation)
- 🦈 前言:记忆 ≠ 检索
- 一、Retrieval-Augmented Generation
- 二、RAG 框架流程图
- 🧩 知识库构建
- 🔍 检索(Retrieval)
- 💡 **为什么语义检索不够?**
- ⚙️ 因此,为什么要加入关键词检索?
- 🧹 去重与过滤
- 🧠 摘要与压缩
- 📚 召回与排序(Re-Ranking)
- 🧩 Prompt 拼接
- 三、项目实战
- 1️⃣ 知识库构建:PDF文本提取
- 2️⃣ 检索结果
- 3️⃣ 拼接prompt
- 4️⃣ 模型部署
- 5️⃣ 界面设计
- 四、项目优化
- 🧩 检索优化
- 原始代码(向量召回),属于单阶段的检索
- 🔍 BM25(关键词召回)
- 🧱 Rerank(重排序)
- 🧩 存储优化
- 原始代码
- 🔍 保存为本地向量库
- 🧠 存储优化
- 五、RAG 的局限性:它永远不会反思
- 六、总结
- 🧩 延伸阅读
🦈 前言:记忆 ≠ 检索
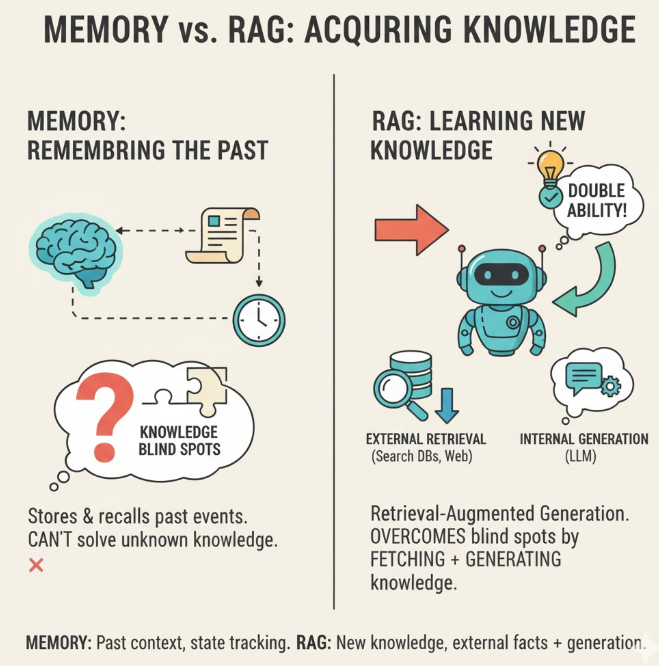
在上一篇文章中,我们探讨了 Memory 模块在多轮会话中的作用,使智能体能够记住历史上下文并进行状态追踪。然而,记忆机制的本质是对已发生事件的存储与复现,它并不能解决知识盲区的问题。在模型训练阶段,我们通常只能接触到有限的数据集;而在实际部署中,智能体往往需要回答来自未知领域的问题。因此,智能体需要的不仅是“记住过去”,更是“学会获取新知识”。RAG(Retrieval-Augmented Generation)正是为此而生的,它让模型具备“外部检索 + 内部生成”的双重能力。
一、Retrieval-Augmented Generation
RAG 是一种“非参数化增强”方法。它不会修改模型的权重,而是改变输入。
在传统 LLM 推理中:
LLM(prompt) → answer
而在 RAG 中:
query → retrieval → context + query → LLM → answer
也就是说,RAG 只是让模型“多看了几页参考资料”,再根据这些资料生成输出。 针对是输出的知识,与原先的prompt进行结合成新的prompt。模型本身的知识并没有“更新”或“记住”任何东西。
🆚 RAG 与 MEMORY 的区别
| 对比项 | RAG(检索增强) | Memory(记忆模块) |
|---|---|---|
| 数据来源 | 外部数据库、文档、知识库 | 模型自身交互的经验 |
| 是否可学习 | ❌ 不可学习(检索规则固定) | ✅ 可学习(RL或策略更新) |
| 存储内容 | 静态文本或嵌入向量 | 动态交互、状态、奖励 |
| 更新机制 | 向量索引更新 | 通过反思与奖励更新 |
| 作用范围 | 提供外部知识 | 提供上下文与长期依赖 |
| 是否有反思能力 | ❌ 无 | ✅ 有 |
| 示例 | LangChain RAG pipeline | MemoryBank / Reflexion / Memory-R1 |
二、RAG 框架流程图
了解完 RAG 的基本概念后,我们更想知道——RAG 到底是怎么工作的?
一个成熟的 RAG(Retrieval-Augmented Generation)系统,不只是“去知识库里搜几段文本”,而是一整套从检索、筛选、压缩到动态拼接 prompt的智能信息管线。一个完整的RAG流程应该是:
知识库构建→检索→去重过滤→摘要压缩→召回排序→拼接prompt
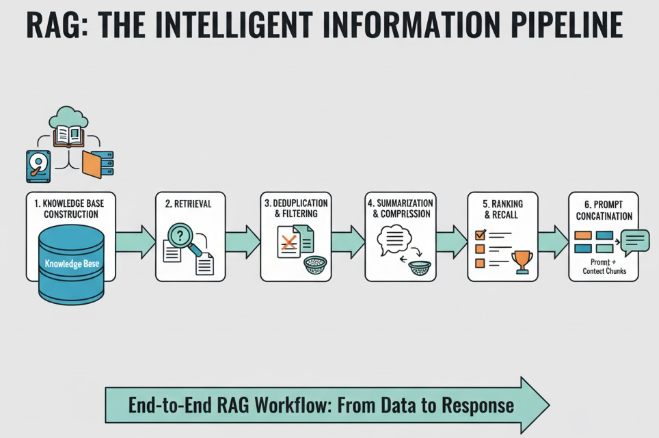
🧩 知识库构建
输入: 原始资料(PDF、网页、数据库、论文、API 文档等)
输出: 向量化的知识库(Vector Store)
🔍 检索(Retrieval)
当用户提出问题时,RAG 的第一步是从知识库中找到最相关的内容。 常用的检索策略包括:
-
语义检索(Semantic Search):通过向量相似度(如 cosine similarity)找到与 query 语义最接近的文档;
-
混合检索(Hybrid Retrieval):结合 BM25(关键词匹配)+ 向量检索;
-
多轮检索(Iterative Retrieval):先粗检,再精检。
例如输入问题:“Transformer 中的 Attention 是怎么计算的?”
检索系统会返回论文《Attention is All You Need》中的若干相关段落。
💡 为什么语义检索不够?
虽然语义检索(embedding-based search)能够理解词语的语义相似性,例如把“注意力机制”和“attention mechanism”识别为同义短语,但它也有三个关键问题:
-
信息漂移(Semantic Drift):
语义检索可能找到“语义相似但主题不同”的文本。
例如用户问“Transformer 的注意力复杂度”,embedding 可能检索到“视觉注意力模型”或“人类注意机制”的文章——它们语义相近,但与问题无关。 -
实体精度不足(Entity Precision):
在专业领域(如医学、法律、编程),一个关键词往往极其重要。
比如问“BERT 中的 NSP 任务”,如果模型没精确匹配到“NSP”,就可能返回一堆讲“MLM”的内容。 -
语义空间饱和(Embedding Saturation):
当知识库非常大时,语义向量在高维空间中趋于稀疏,top-k 检索容易受到噪声影响,特别是当问题短、上下文不足时。
⚙️ 因此,为什么要加入关键词检索?
关键词检索(BM25、TF-IDF)虽然“笨”,但有两个不可替代的优势:
- 精确控制:可以确保关键词出现,例如“Transformer”、“Self-Attention”;
- 补充保障:在 embedding 模型理解失败(例如新概念或缩写)时,仍能找到相关结果。
🧹 去重与过滤
在检索到的多个文档中,可能存在:信息重复;无关内容;过长或语义冲突的段落。
常见做法:
-
计算相似度矩阵,去掉相似度高于阈值(如 0.9)的重复段;
-
使用关键词过滤(仅保留包含核心主题的文本);
-
保留信息密度更高的片段(通过 TF-IDF 或句子长度等指标)。
🧠 摘要与压缩
当检索到的内容太多,直接塞进 LLM prompt 会超出上下文窗口,因此,在得到检索内容后还不能直接进行拼接,还需要对内容进行压缩、摘要处理,保证在上下文窗口限制的同时提供有效信息,常见的摘要压缩方法有:
-
抽取式摘要(Extractive Summary):保留关键句;
-
生成式摘要(Abstractive Summary):用小模型先行压缩;
-
信息融合(Fusion):把多段检索结果合并成一份结构化总结。
这一阶段的目标是“提炼最有用的知识”,而不是“照搬原文”。
📚 召回与排序(Re-Ranking)
压缩后的候选片段需要重新排序,以便模型生成时优先看到重要信息。 常见策略包括:
-
Cross-Encoder 重排序(如 bge-reranker);
-
基于时间或来源的权重(最新信息优先);
-
基于任务类型的动态权重(例如代码问答更注重示例片段)。
🧩 Prompt 拼接
将整理好的知识片段与用户问题拼接成最终输入 prompt,常见结构:
System: 你是一个专业的技术助手。 Context: 1. 文档A摘要:... 2. 文档B摘要:... Question: 用户的问题 Answer:
三、项目实战
本次项目以Deepseek-7B-chat模型为例,实现对本地学生手册PDF数据库的检索增强, 需要达成以下目标:
🟢 开源大模型的本地部署及使用 (以Deepseek为例);
🟢 PDF文本分析 ➕ 相似prompt检索提取 (关键);
🟢 将检索到的信息与原prompt结合作为输入,得到结果;
1️⃣ 知识库构建:PDF文本提取
def extract_text_from_pdf(pdf_path):text = ""with pdfplumber.open(pdf_path) as pdf:for page in pdf.pages:text += page.extract_text()return textdef split_into_paragraphs(text, min_length=3):paragraphs = [p.strip() for p in text.split('\n') if len(p.strip()) >= min_length]return paragraphs# 示例:提取PDF文本并分块
pdf_text = extract_text_from_pdf("mypdf.pdf")
paragraphs = split_into_paragraphs(pdf_text)
2️⃣ 检索结果
from sentence_transformers import SentenceTransformer
import faiss# 编码结果
model = SentenceTransformer("all-MiniLM-L6-v2")
doc_embeddings = model.encode(paragraphs)# 构建FAISS索引
dimension = doc_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(doc_embeddings)def retrieve_docs(query, k=3):"""检索最相关的k个段落"""query_vec = model.encode([query])D, I = index.search(query_vec, k=k) # D是距离,I是索引return [paragraphs[i] for i in I[0]]query = "境外生获得省部级及以上学科竞赛奖项奖励金额可以提高多少?"retrieved = retrieve_docs(query, k=3)
print("\n检索到的相关段落:")
for i, doc in enumerate(retrieved):print(f"[{i+1}] {doc[:100]}...") # 打印前100字符
问题:境外生获得省部级及以上学科竞赛奖项奖励金额可以提高多少?
检索Top3结果:
[参考1] - 8 -(境外生排位第一)获得省部级及以上学科竞赛奖项,奖励金额
[参考2] 1.学校对获得省部级及以上学科竞赛奖项的学生给予奖励,
[参考3] 培训费以及学生奖金等。
🔴 可以发现,这个相似的检索结果中并没有显示我们想要的答案,我们进一步分析生成的paragraphs, 如下所示,可以发现基于pdfplumber库生成的段落都是断断续续的,并不能自成一段。因为pdfplumber库是按行提取的,缺乏对上下文的理解,换行默认为新的一段。
‘- 8 -(境外生排位第一)获得省部级及以上学科竞赛奖项,奖励金额’, ‘可提高 10%。’,
🟢 为此还需要对分段的语句进行处理:
def smart_merge_lines(lines, min_len=30, join_limit=200):paragraphs = []buffer = ""for line in lines:line = line.strip()if not line:continuebuffer += " " + lineif len(buffer) >= min_len and re.search(r"[。!?;:]$", buffer.strip()):paragraphs.append(buffer.strip())buffer = ""elif len(buffer) >= join_limit:paragraphs.append(buffer.strip())buffer = ""if buffer:paragraphs.append(buffer.strip())return paragraphsdef extract_paragraphs_from_pdf(pdf_path):raw_lines = []with pdfplumber.open(pdf_path) as pdf:for page in pdf.pages:text = page.extract_text()if text:raw_lines.extend(text.split('\n'))merged_paragraphs = smart_merge_lines(raw_lines)return merged_paragraphsparagraphs = extract_paragraphs_from_pdf("mypdf.pdf")
print(paragraphs)
- 相似检索结果
请根据以下参考内容回答问题: [参考1] 4.鼓励境外生积极参与学科竞赛活动,境外生个人或团体 - 8 - (境外生排位第一)获得省部级及以上学科竞赛奖项,奖励金额 可提高 10%。 [参考2] 第三章 赛事分类与级别认定 第七条 根据学科竞赛的组织机构、专业度、社会影响和获 - 4 - 奖难度等方面综合考虑,将竞赛分为国家级、省部级、地厅级和 校级赛事。省部级及以上学科竞赛项目原则上需具有下一级别的 竞争性选拔过程。 [参考3] 4.奖金发放:学校归口管理职能部门根据最终确定的奖励情 况,按要求报送相关奖励方案,由财务处发放奖金。
3️⃣ 拼接prompt
messages = [{"role": "user", "content": f"""请根据以下参考内容回答问题:{retrieved}问题:{query}"""}
]
4️⃣ 模型部署
mode_name_or_path = '/root/autodl-tmp/deepseek-ai/deepseek-llm-7b-chat'
# 加载预训练的分词器和模型
tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)
llm = AutoModelForCausalLM.from_pretrained(mode_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16,device_map="auto")
llm.generation_config = GenerationConfig.from_pretrained(mode_name_or_path)
llm.generation_config.pad_token_id = llm.generation_config.eos_token_id
llm.eval() # 设置模型为评估模式input_tensor = tokenizer.apply_chat_template(messages,add_generation_prompt=True, # 添加"Assistant:"提示return_tensors="pt"
)
outputs = llm.generate(input_tensor.to(llm.device), max_new_tokens=200)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print("\n最终回答:", result)
- 最终输出结果:
最终回答: 根据提供的内容,境外生个人或团体获得省部级及以上学科竞赛奖项,奖励金额可以提高10%。
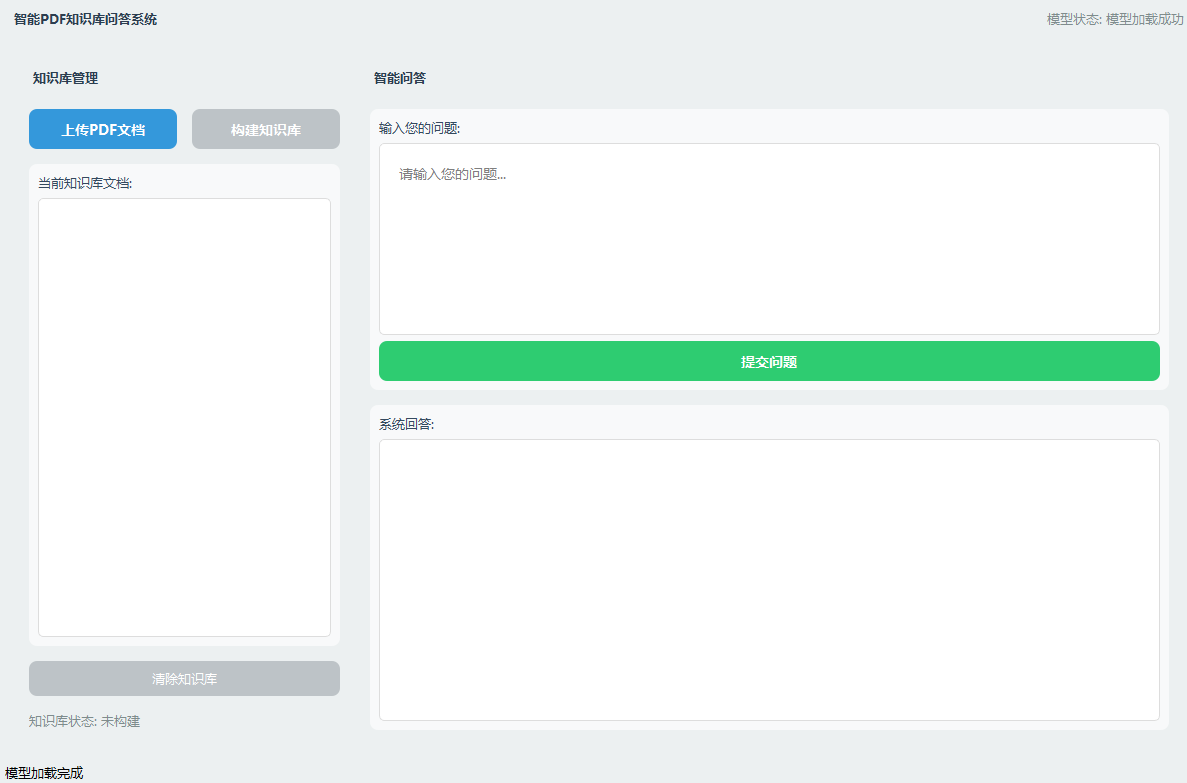
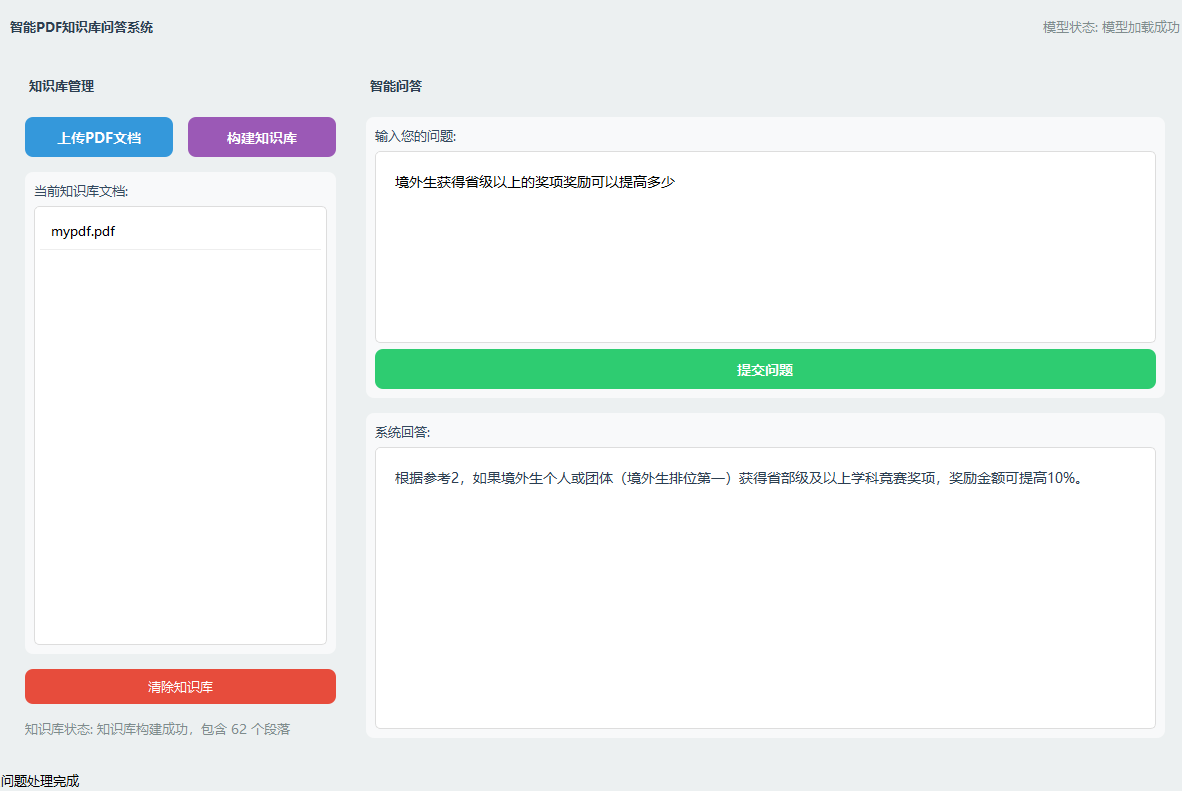
5️⃣ 界面设计
- 编者基于PYQT5模块设计了一个支持知识库搭建的大模型问答系统:
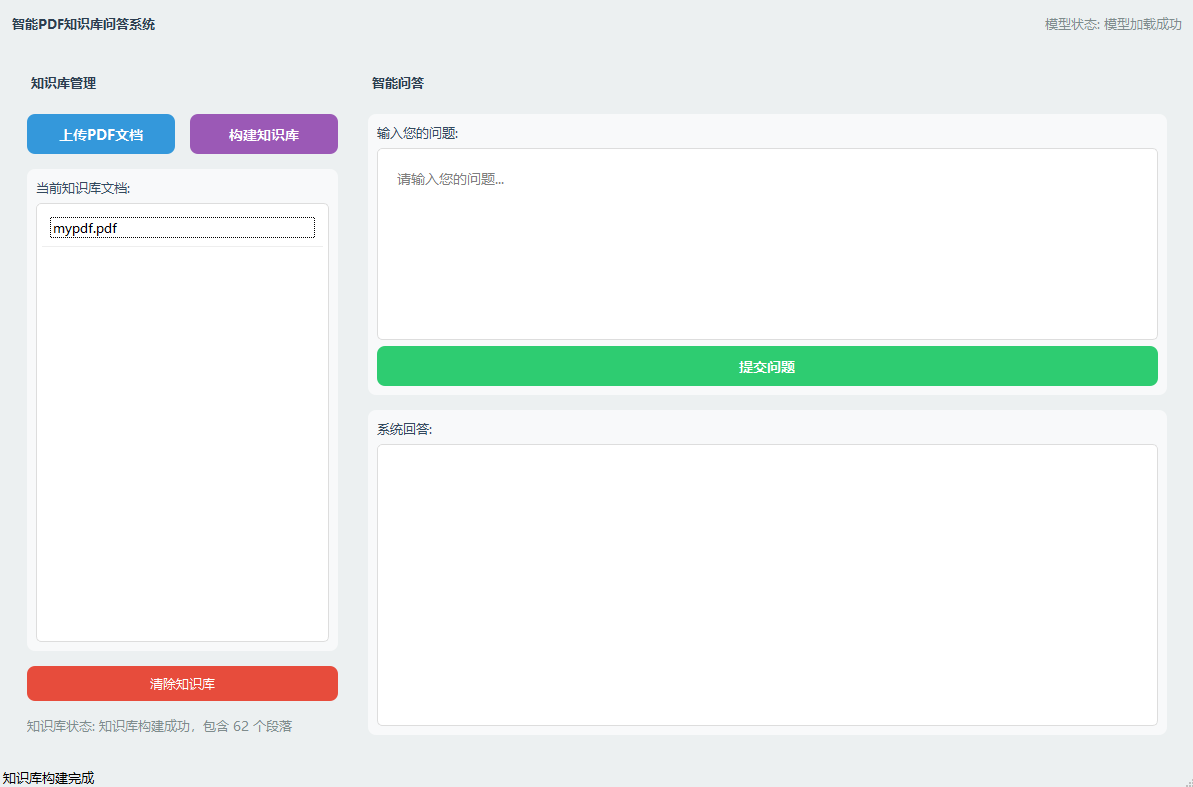
- 搭建知识库后:
- 模型输出:
四、项目优化
🧩 检索优化
原始代码(向量召回),属于单阶段的检索
def retrieve_docs(query, k=3):"""检索最相关的k个段落"""query_vec = model.encode([query])D, I = index.search(query_vec, k=k) # D是距离,I是索引return [paragraphs[i] for i in I[0]]
✅ 能理解语义:能找到与 query 相近含义的段落,即使不含相同词语
❌ 容易忽略语义不相近,但有明显的关键词重合;语义相似≠语用相近,尤其在法律、金融等领域问题突出
因此,向量召回可能遇到以下问题:
| 用户输入 | 单向量召回可能错在哪 |
|---|---|
| “2024年湖北省大学生竞赛奖金是多少?” | 文中提的是“省部级奖励金额”,但向量模型可能找不到这段 |
| “我想了解奖助学金政策” | 向量模型找“奖学金”段落,但“助学金”是关键词 |
| “获得奖项后的政策支持?” | 多个段落提到奖项,但真正写“支持”措施的段落可能被漏掉 |
🔍 BM25(关键词召回)
BM25是一个词项的检索匹配算法,通过对比查询与目标段落之间的词项,相同词项越多越相关,但例如the、a等关键词会频繁出现,因此在关键词出现太多时贡献度也会衰减。是TF-IDF算法的改进版。
- 代码
def retrieve(self, query, k=5, bm25_k=10):bm25_scores = self.bm25.get_scores(query.split())bm25_topk_idx = np.argsort(bm25_scores)[::-1][:bm25_k]
🧱 Rerank(重排序)
目前可以分别从两个召回器(Faiss + BM25)拿到了不同或者相同的段落,从原先的单通道召回变成了多通道召回。但是,还需要分别从两个召回器中判断哪几段是“最适合回答 query 的。这时候引入rerank 模型(如 BGE-Reranker、ColBERT),对多个段落的得分进行重排序,具体实现:
1️⃣ 将 (query, paragraph) 成对送入 BERT/Transformer 分类器
2️⃣ 得到语义相关性分数
3️⃣ 排序并只保留前几条
- 代码
def retrieve(self, query, k=5, bm25_k=10):# 向量召回query_vec = model.encode([query])D, I = index.search(query_vec, k=k) # D是距离,I是索引vec_topk_idx = I[0]# return [paragraphs[i] for i in I[0]]bm25_scores = self.bm25.get_scores(query.split())bm25_topk_idx = np.argsort(bm25_scores)[::-1][:bm25_k]candidate_idxs = list(set(bm25_topk_idx.tolist() + vec_topk_idx.tolist()))candidate_vecs = self.embeddings[candidate_idxs]query_vec = query_vec / np.linalg.norm(query_vec) # 归一化candidate_vecs = candidate_vecs / np.linalg.norm(candidate_vecs, axis=1, keepdims=True)scores = np.dot(candidate_vecs, query_vec.T).squeeze()sorted_idx = np.argsort(scores)[::-1]reranked_idxs = [candidate_idxs[i] for i in sorted_idx[:k]]return [self.paragraphs[i] for i in reranked_idxs]
| 模块 | 能力 |
|---|---|
| Faiss 向量检索 | 找泛义相近文本(Recall 全面) |
| BM25 检索 | 找关键词重合文本(Recall 准确) |
| Reranker | 对 Recall 候选排序,挑出真正语义匹配(Precision) |
🧩 存储优化
原始代码
🔴 每次都要重新 encode → 慢、重复。
doc_embeddings = model.encode(paragraphs)
index.add(doc_embeddings)
🔍 保存为本地向量库
import picklewith open("docs.pkl", "wb") as f:pickle.dump({"paragraphs": paragraphs, "embeddings": doc_embeddings}, f)# 加载
with open("docs.pkl", "rb") as f:cache = pickle.load(f)paragraphs = cache["paragraphs"]doc_embeddings = cache["embeddings"]
index = faiss.IndexFlatL2(dimension)
index.add(doc_embeddings)
🧠 存储优化
当保存的向量超过几千上万条,内存和查询速度都成问题. 为此,需要对存储向量进行压缩.在原来的代码中,我们没有采用任何的向量压缩,采用了最简单和最基础的检索方式IndexFlatL2,通过欧氏距离进行相似度计算,为了加快检索速度, faiss提供了多种压缩方式:
✅ 必须了解底层原理(尤其你是大模型工程师/向量检索方向):
| 算法 | 核心思想 | 应用场景 |
|---|---|---|
| PQ(Product Quantization) | 将向量拆分成多个子向量 → 用 8bit 表示每个子块 | 超大数据量,压缩向量 |
| IVF(Inverted File) | 建立多个“中心点”(聚类),每次只在最近的几个中心中搜索 | 百万级向量库 |
| HNSW(Hierarchical Navigable Small World) | 建图搜索 → 多层邻居结构加速搜索 | 实时性高、近似搜索 |
| OPQ(优化 PQ) | 比 PQ 更强的压缩(旋转+重组) | 更高精度压缩 |
1️⃣ Faiss 的压缩索引(PQ)
- 将向量拆分成多个子向量 → 用 8bit 表示每个子块
index = faiss.IndexPQ(d, M=8, nbits=8)
d: 向量维度(如 384)M: 子向量数量(压缩块)nbits: 每块用几位表示(8bit)
2️⃣ Faiss 的 HNSW/IVF 加速结构: 建图结构用于近似快速检索(不是压缩,但更快),可与压缩同时用
IVF: 建立多个“中心点”(聚类),每次只在最近的几个中心中搜索HNSW: 建图搜索 → 多层邻居结构加速搜索
quantizer = faiss.IndexFlatL2(d)
index = faiss.IndexIVFFlat(quantizer, d, nlist=100)
# index = faiss.IndexIVFPQ(quantizer, dimension, nlist, m, nbits) 压缩 + 近似
index.train(doc_embeddings)
index.add(doc_embeddings)
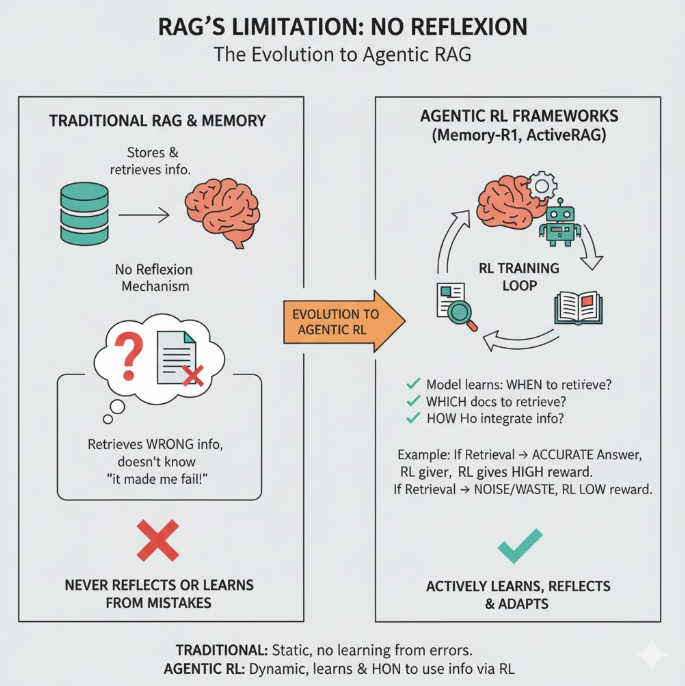
五、RAG 的局限性:它永远不会反思
RAG和Memory模块一样,都不具备反思(Reflexion)机制。即便模型通过 RAG 检索到错误的信息,它也不会知道“这条资料害我犯错了”。在 MemoryBank 到 Memory-R1 的发展中,Agent会主动分析为什么失败,并且主动规避失败的原因。
同样的,在最新的 Agentic RL 框架(如 Memory-R1, ActiveRAG)中, RAG 的 Retriever 和 Reader 都被纳入 RL 训练循环中。
- 模型不只是学“怎么回答”,还学:
- 何时检索
- 检索哪些文档
- 如何融合检索到的信息
举个例子:
智能体在任务中选择是否检索资料,如果检索后回答更准确,RL 就会给更高奖励;
反之,如果盲目检索浪费资源或检索噪声,RL 会降低奖励。
六、总结
本文深入探讨了检索增强生成(RAG)的核心机制,并将其作为智能体“获取新知识”的关键技术,与“记住过去”的 Memory 模块进行了清晰的区分。我们从 RAG 的基本原理(query → retrieval → context + query → LLM)出发,详细拆解了构建一个成熟 RAG 系统所必需的六步工作流:
-
知识库构建:将原始资料向量化。
-
检索:通过语义或混合方式(如 BM25)初步召回。
-
去重过滤:清洗冗余和无关信息。
-
摘要压缩:在不超出上下文窗口的前提下提炼核心知识。
-
召回排序(Re-Ranking):使用更精确的模型(如 Cross-Encoder)排序,提升精度。
-
Prompt 拼接:将整理好的知识注入提示词。
在项目实战中,我们不仅使用 Deepseek、pdfplumber 和 faiss 搭建了一个本地 PDF 问答系统,还特别解决了 PDF 文本切分不佳(smart_merge_lines)这一常见“陷阱”。
更重要的是,我们探讨了 RAG 的两大核心优化路径:
-
检索优化:从单一的向量检索,升级到了 BM25(关键词)+ 向量(语义) 的混合检索模式,并通过 Reranker 提升了召回的最终精度。
-
存储优化:从简单的
IndexFlatL2索引,探讨了如何使用pickle持久化,以及在面对海量数据时如何利用 PQ 和 IVF 等技术进行压缩和加速。
最后,我们必须认识到 RAG 的局限性:它是一个强大的“工具”,但缺乏反思(Reflexion)能力。它不会从检索的“成败经验”中学习。这也为我们指明了 Agentic RL 的前沿方向——智能体不仅要会“用”检索,更要“学会”何时检索、如何检索。
正如文中所强调的:
RAG 让模型更“博学”,但 Memory 让模型更“聪明”。
真正的智能体,不止会查资料,更会从经验中成长。
🧩 延伸阅读
- ActiveRAG: Autonomously Knowledge Assimilation and Accommodation through Retrieval‑Augmented Agents(2024) — [2402.13547] ThinkNote: Enhancing Knowledge Integration and Utilization of Large Language Models via Constructivist Cognition Modeling
- Self‑RAG: Learning to Retrieve, Generate, and Critique through Self‑Reflection(2023) —[2310.11511] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection