对比28种时间序列预测算法在某个数据集上的表现-全套源码
之前在本号列举了一系列时间序列算法和模型。光说不练假把式!本文测试了28个时间序列算法在某个数据集上的表现,本测试仅仅代表在特定数据集上的一次试验表现,并不能说明对应算法的优劣。
数据集
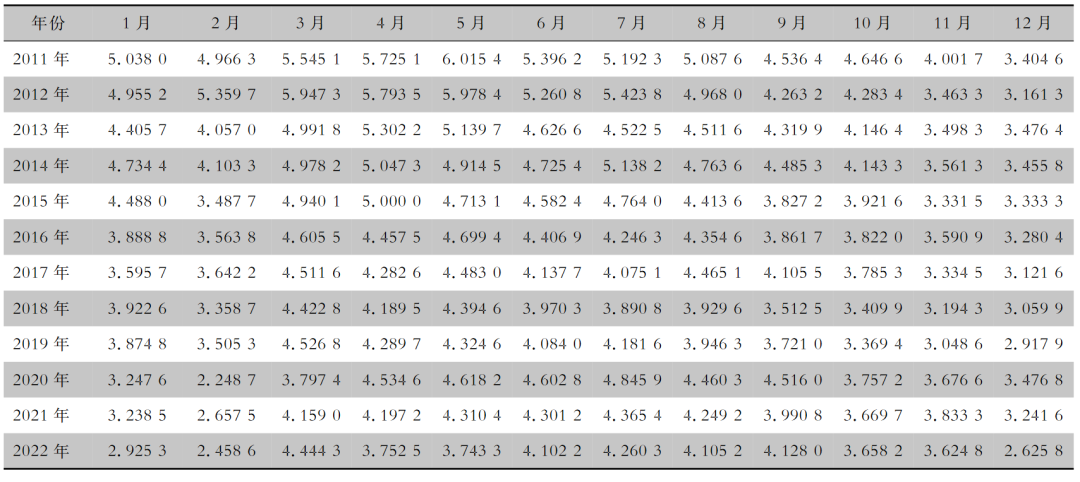
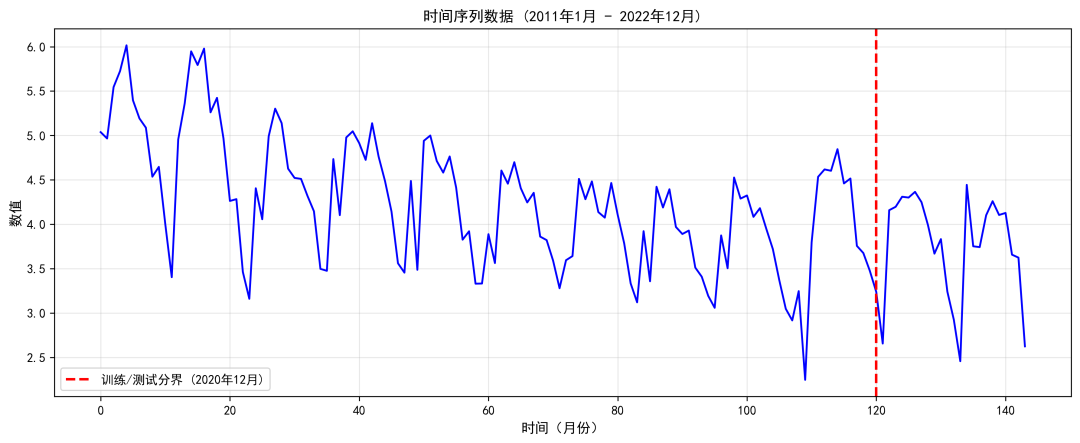
该数据集是浙江省2011年1月-2022年12月12年的月度结核病发病率数据集(/10万)。如有需要可以在评论区留言索取。
本文一共测试了如下28种算法:
1.KNN
2.随机森林
3.GBRT
4.SARIMA
5.BSTS
6.SVR
7.模糊时间序列
8.TCN
9.CNN-LSTM
10.GRU
11.指数平滑
12.ETS
13.DLM
14.马尔可夫链
15.Transformer
16.ARMA
17.VARMA
18.AR
19.VAR
20.MA
21.VECM
22.ARCH
23.ARIMA
24.GARCH
25.Seq2Seq
26.GPR
27.LSTM
28.BiLSTM
本文使用的评价指标如下:
MAE (平均绝对误差): 预测值与真实值之间的平均绝对差异,越小越好
RMSE (均方根误差): 预测误差的平方根,对异常值敏感,越小越好
MAPE (平均绝对百分比误差): 预测误差的百分比表示,越小越好
R² (决定系数): 模型对数据变异性的解释程度,越接近1越好
可视化的预测结果如下:
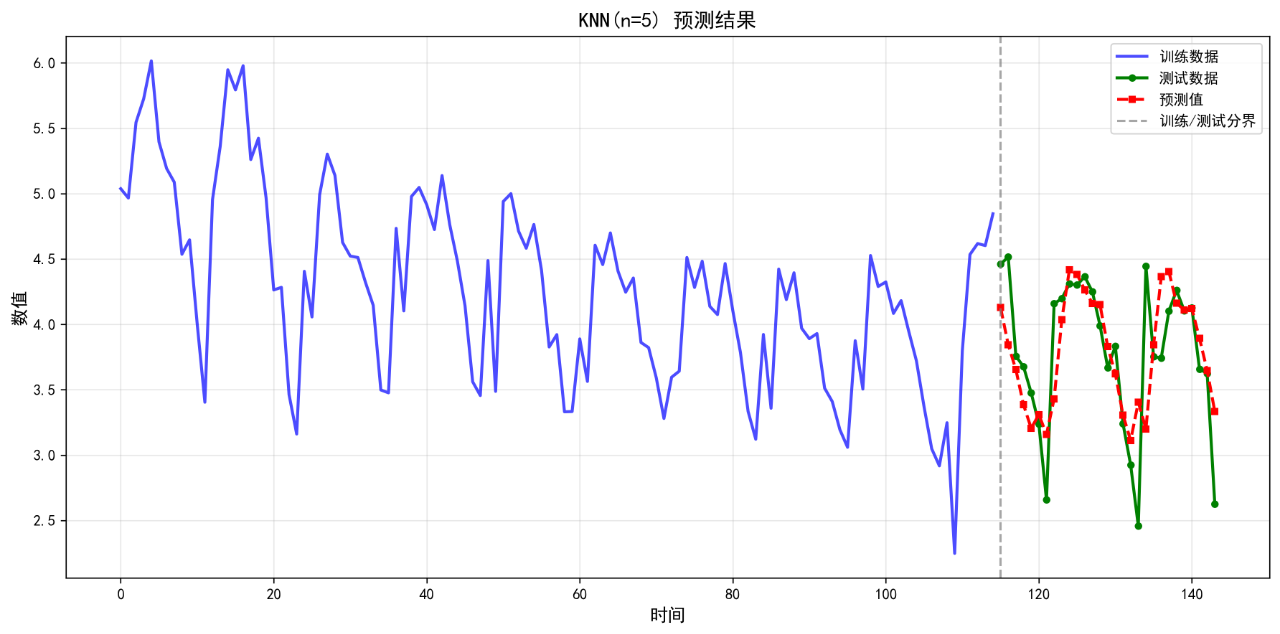
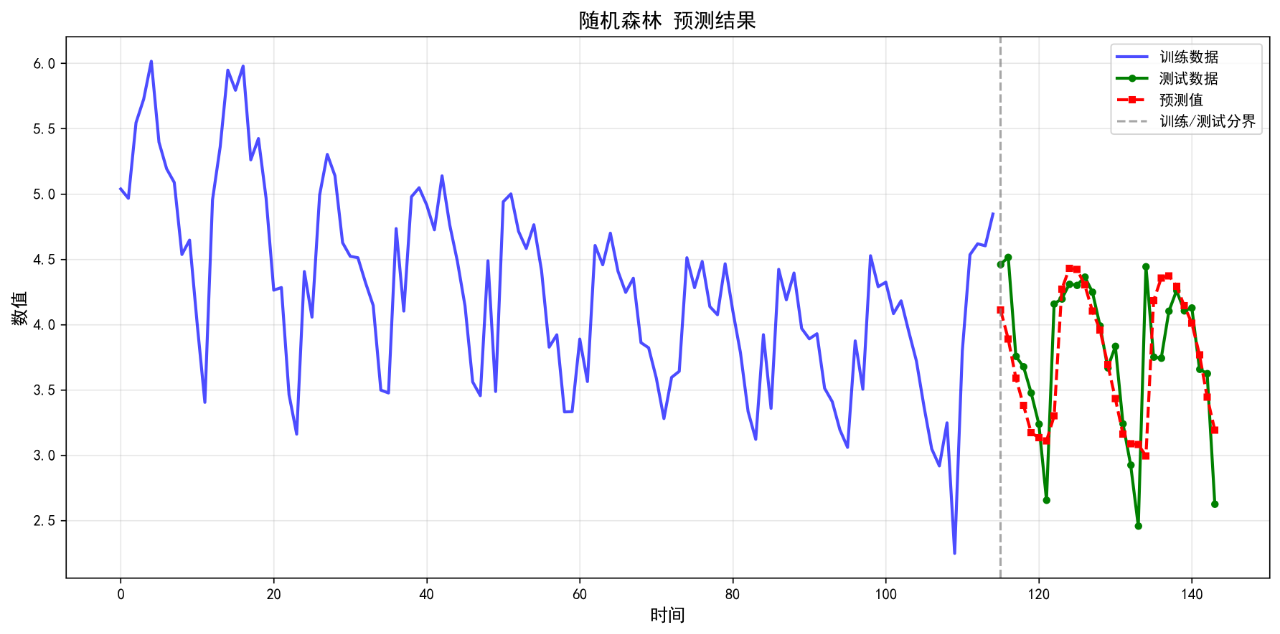
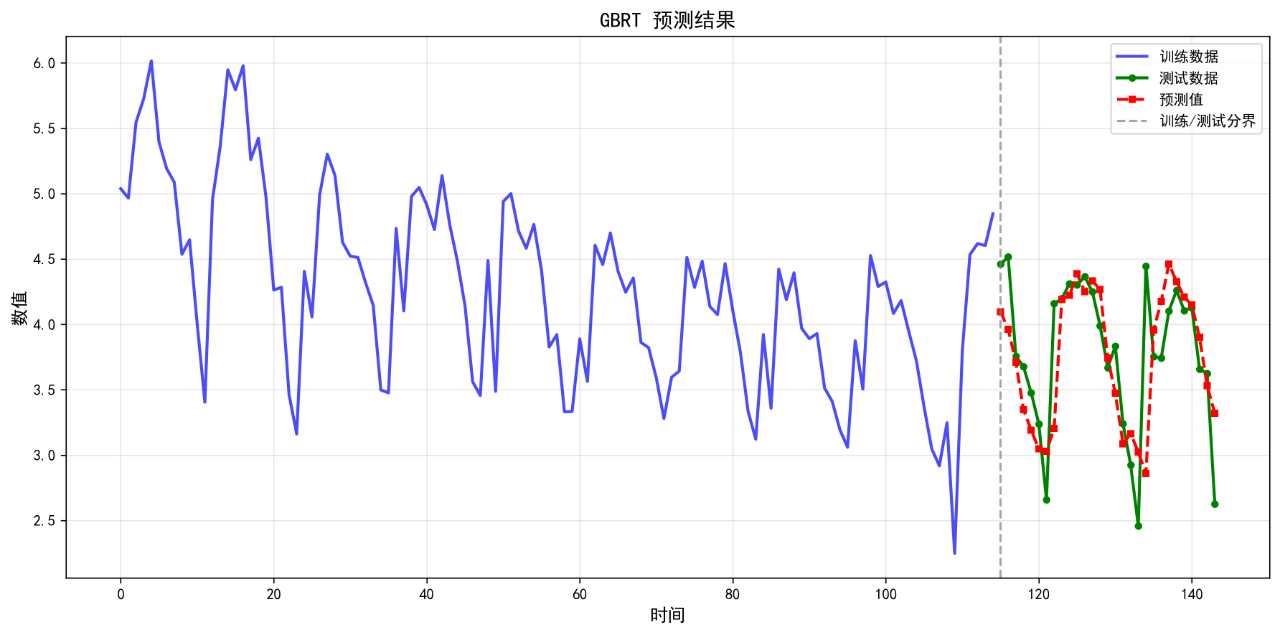
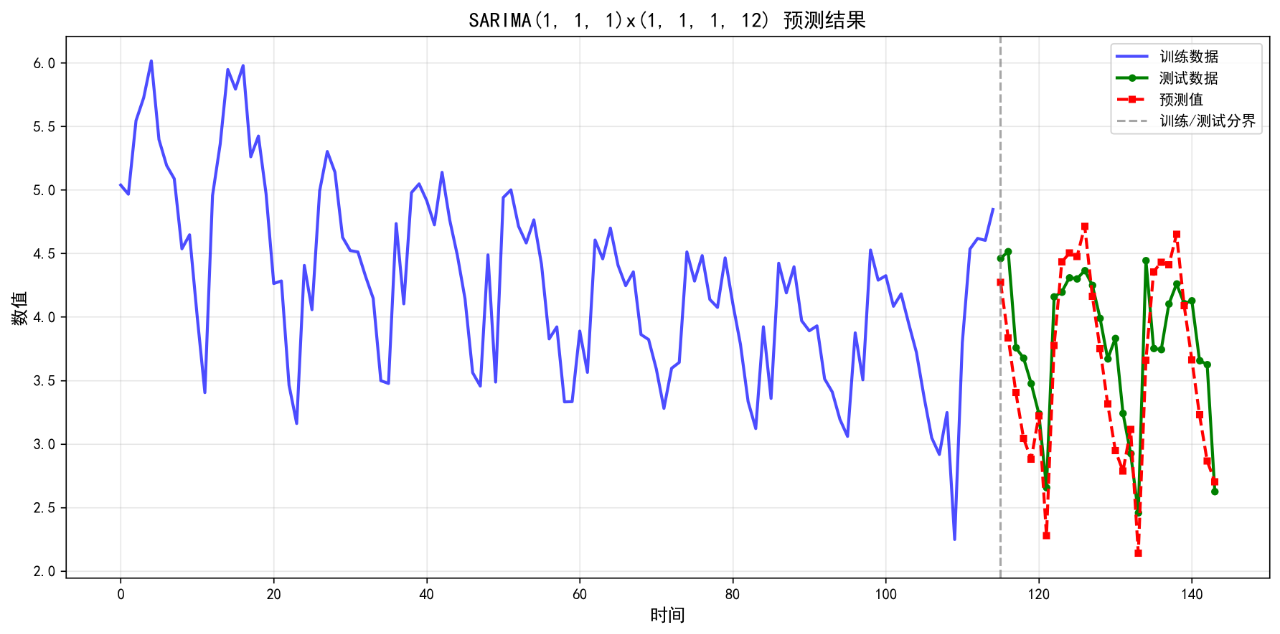
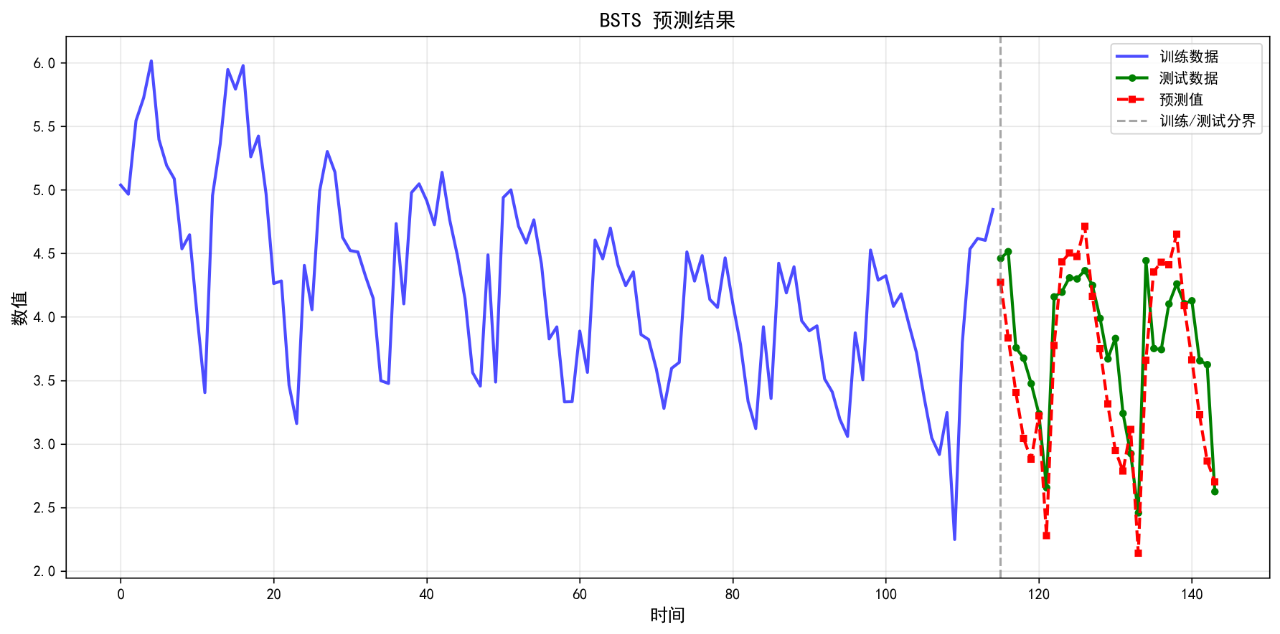
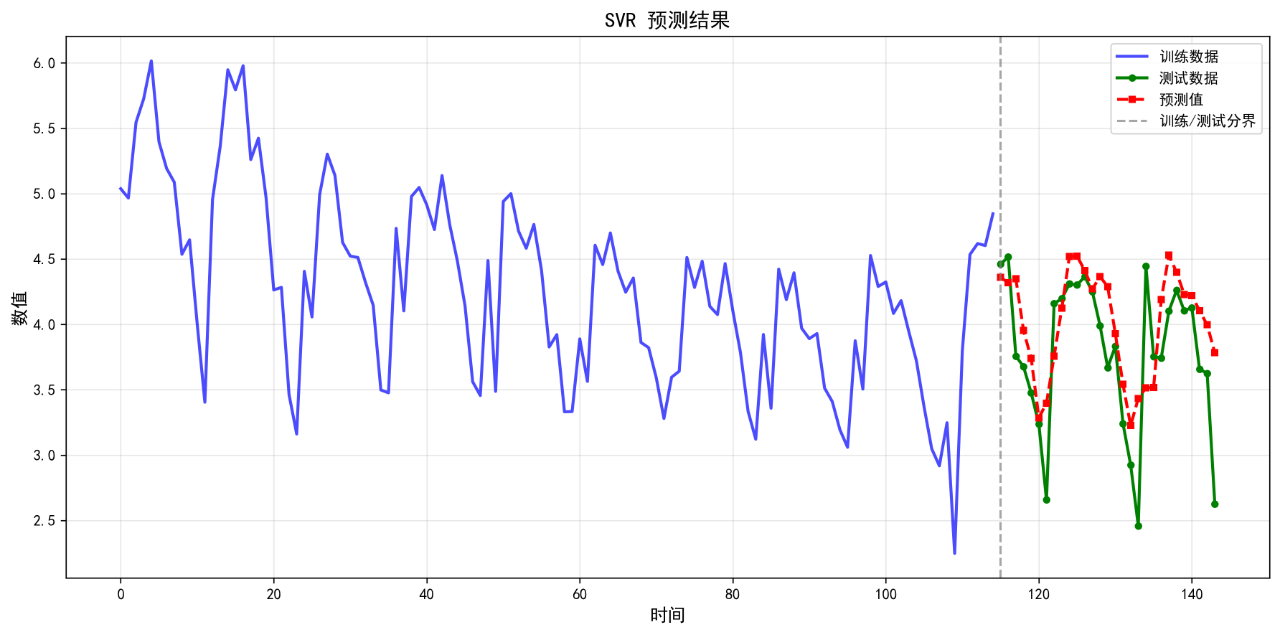
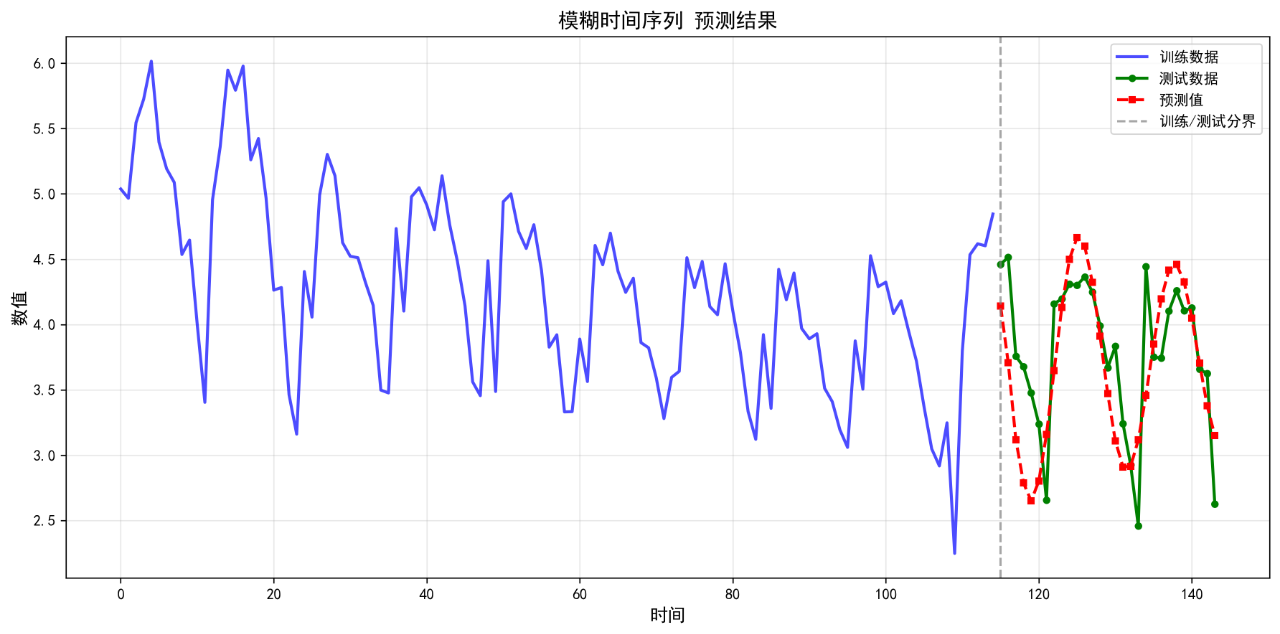
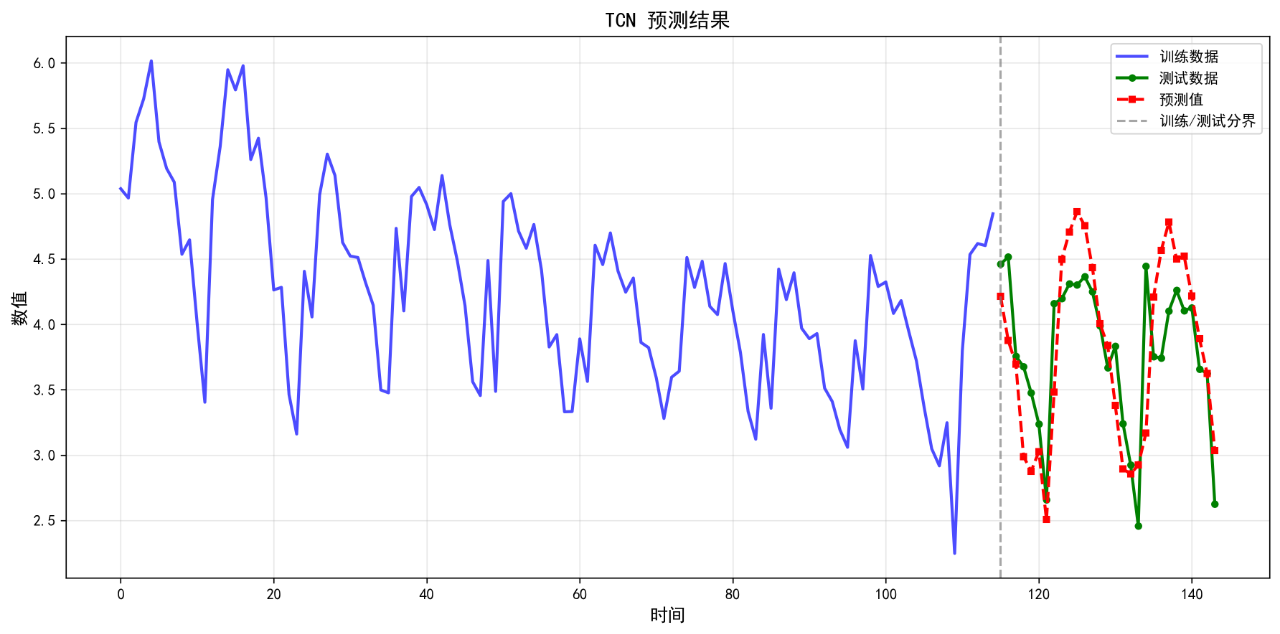
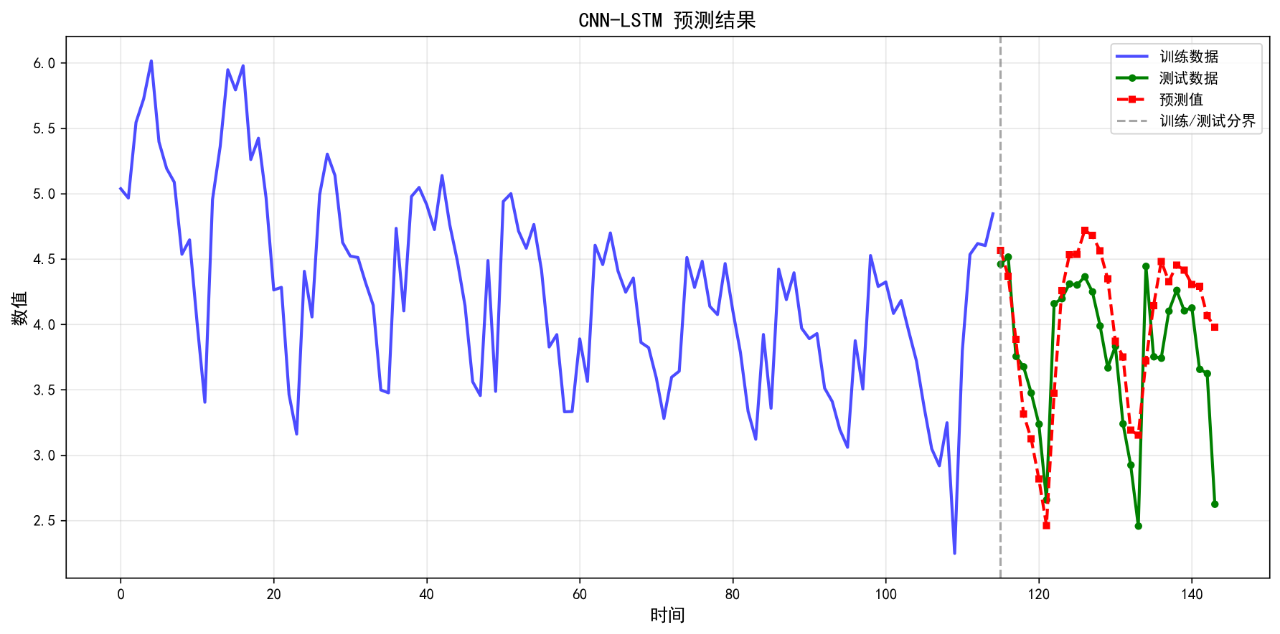
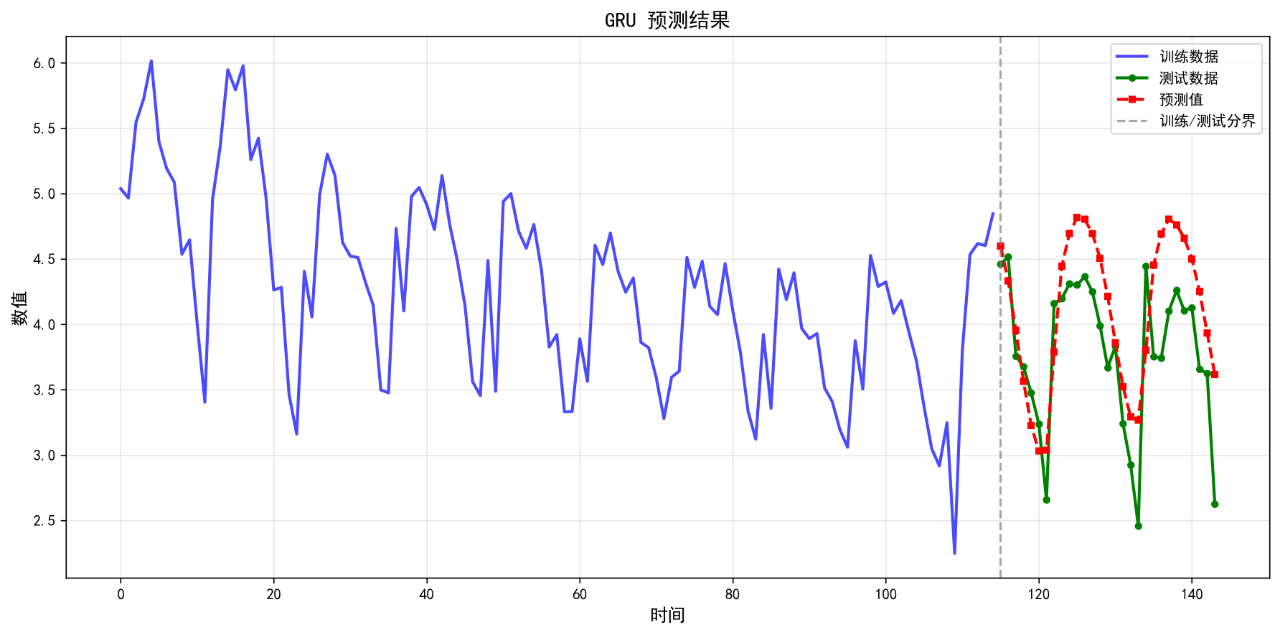
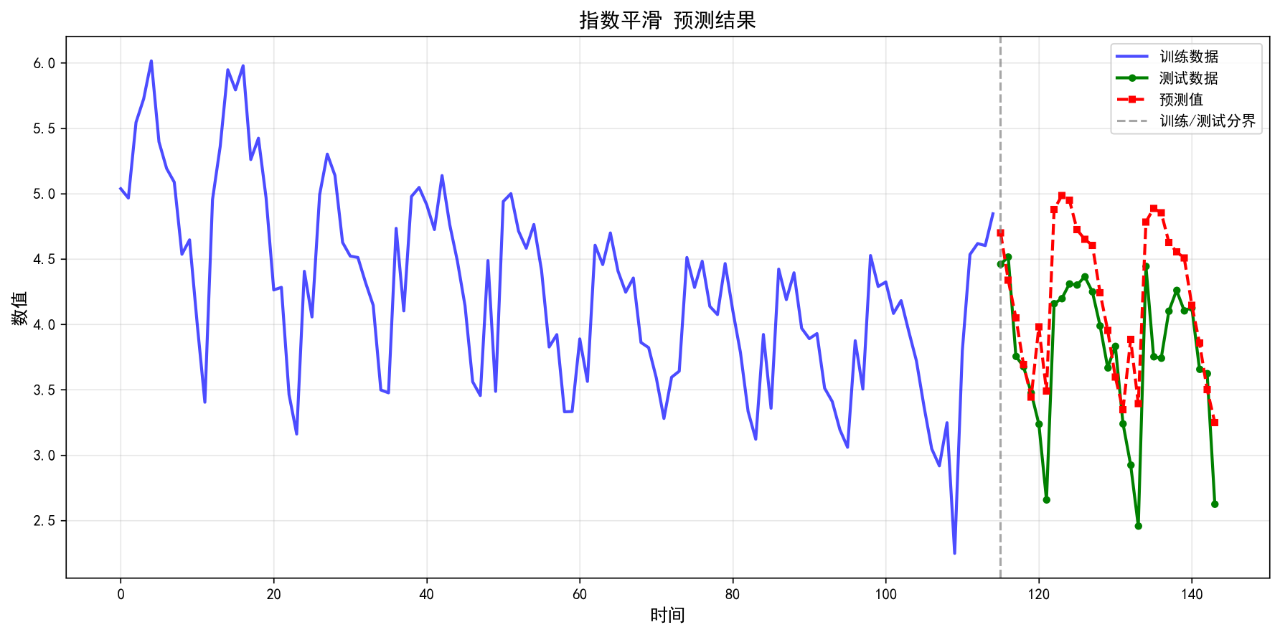
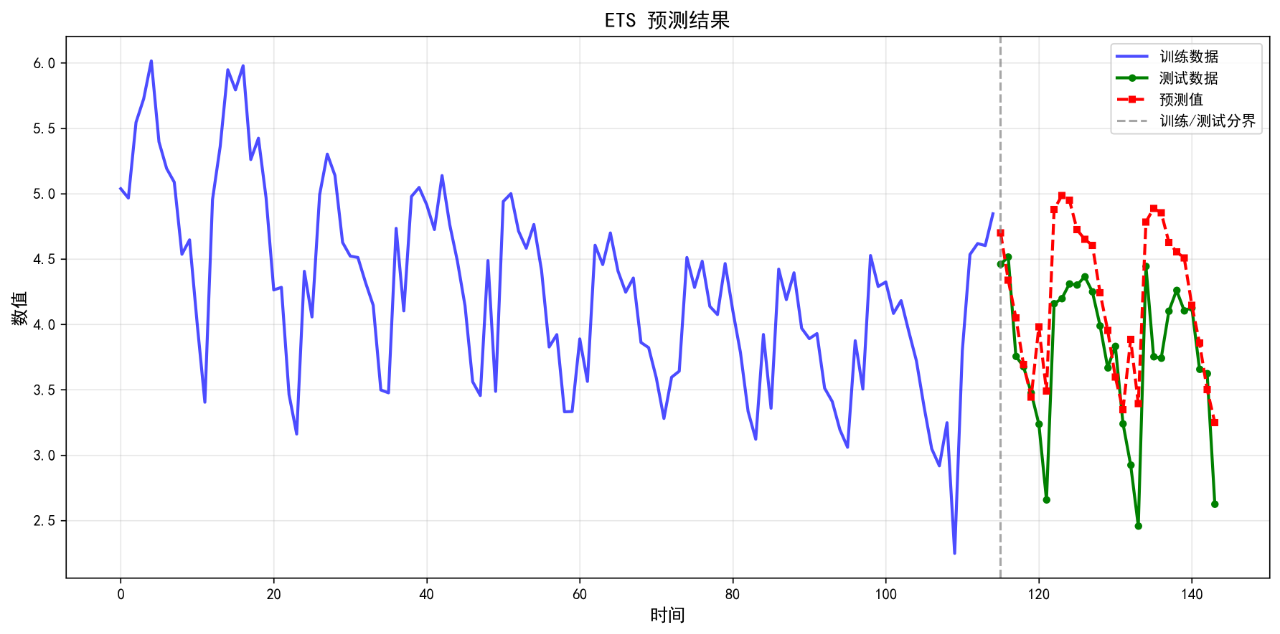
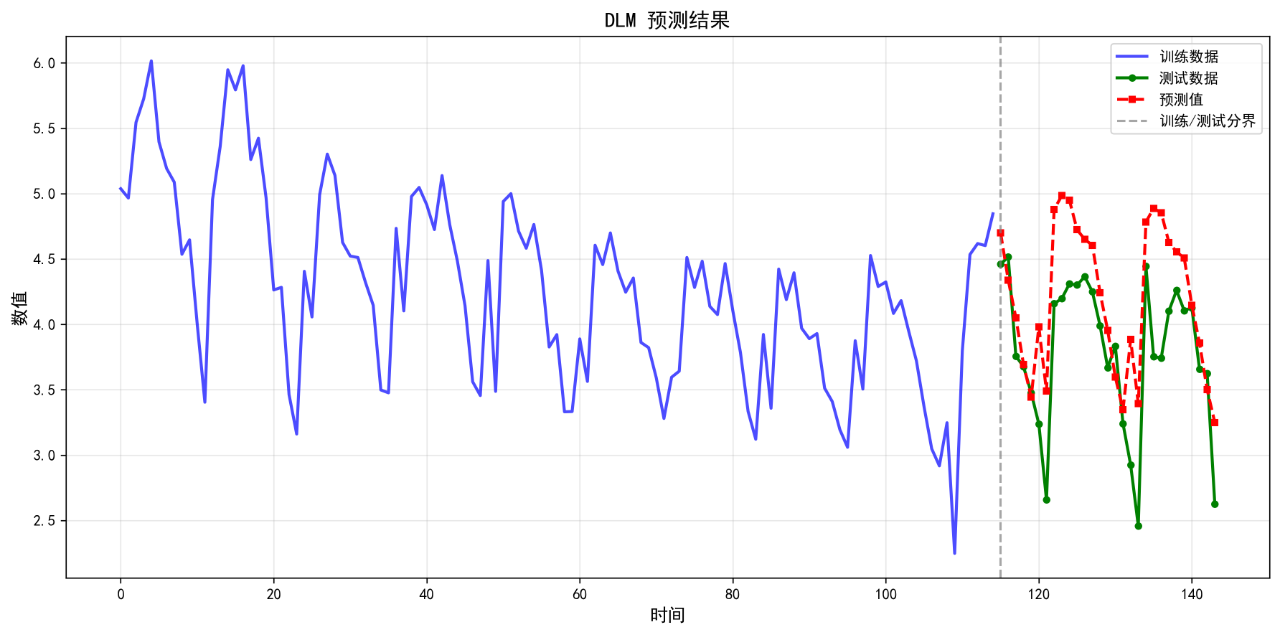
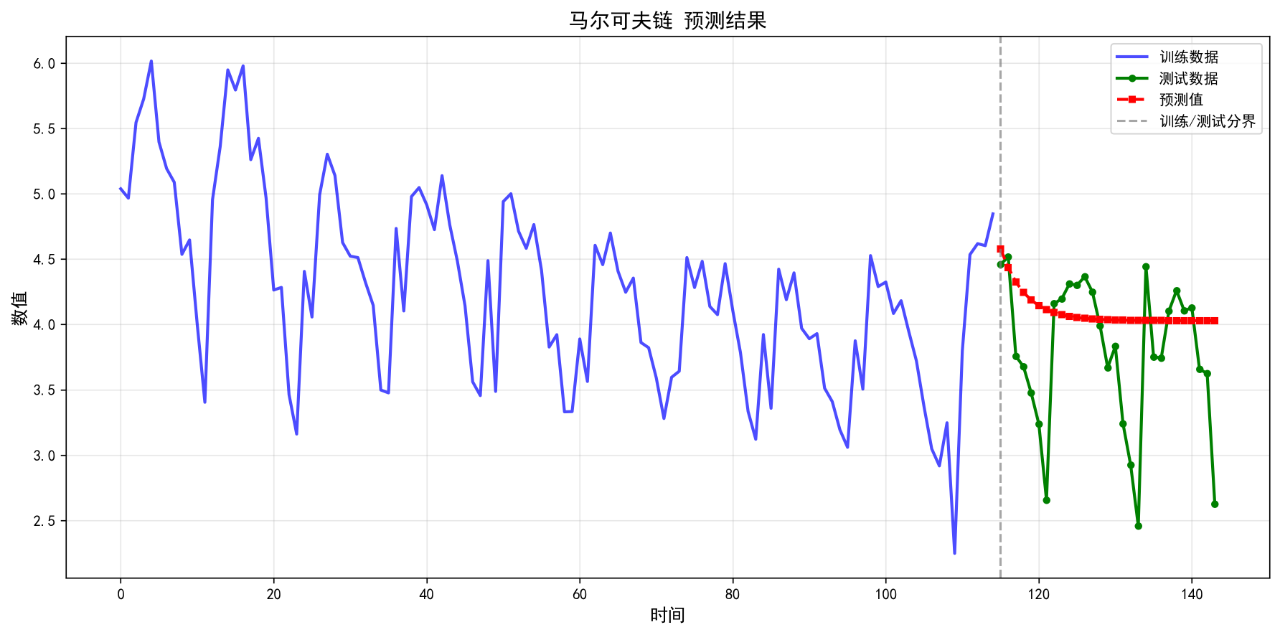
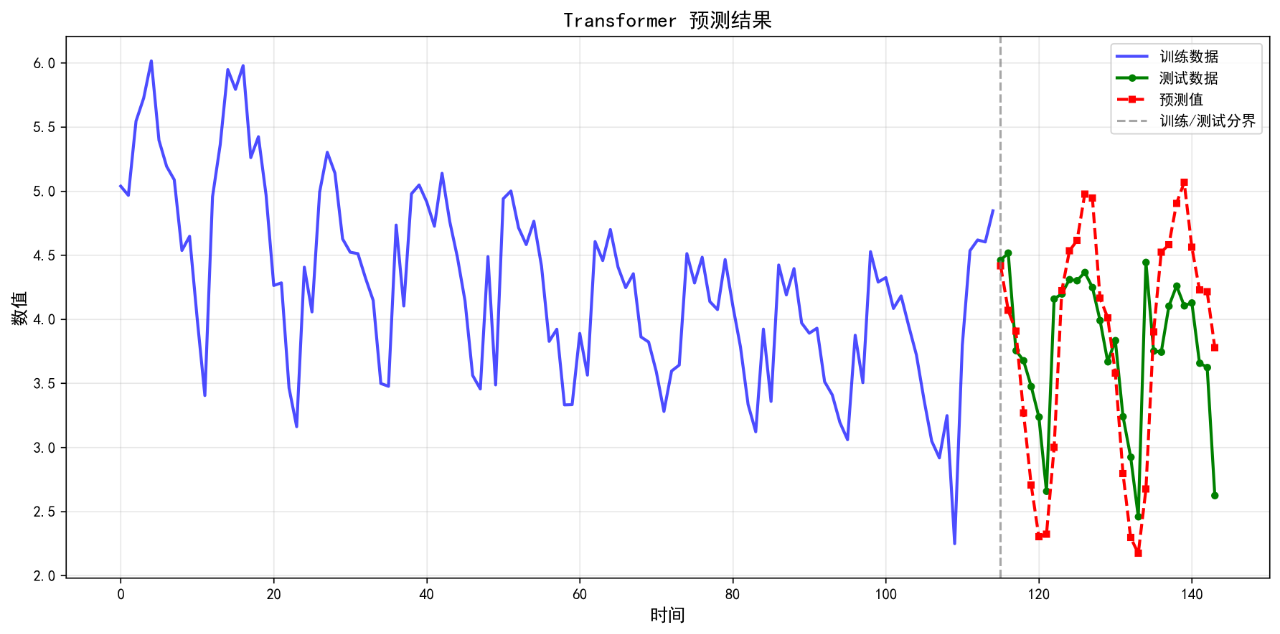
后面的几个算法的基础表现就不再列举了。在不进行任何调参的情况下,算法表现不佳,不足以用来作为预测算法使用。后续将进一步优化参数。下面给出算法评价报告。
=====================
时间序列预测算法对比分析报告
=====================
生成时间: 2025-11-05 14:21:04
数据信息:
总数据量: 144 条
训练集: 115 条 (80%)
测试集: 29 条 (20%)
======================
各算法预测结果对比
======================
算法 MAE RMSE MAPE(%) R²
----------------------------------------------------------------------
AR(5) 0.4935 0.6947 15.71 -0.5060
MA(2) 0.5360 0.7505 17.04 -0.7578
ARMA(2,2) 0.5765 0.6929 17.20 -0.4982
ARIMA(1, 1, 1) 1.0163 1.1635 30.26 -3.2248
SARIMA(1, 1, 1)x(1, 1, 1, 12) 0.3872 0.4515 10.32 0.3639
指数平滑 0.4515 0.5561 12.86 0.0351
ETS 0.4515 0.5561 12.86 0.0351
SVR 0.3527 0.4564 10.43 0.3500
GBRT 0.3084 0.4469 8.49 0.3768
随机森林 0.3039 0.4328 8.36 0.4154
KNN(n=5) 0.2957 0.4238 8.41 0.4396
GPR 3.2559 3.5257 86.82 -37.7907
LSTM 8.3894 18.7696 257.80 -1098.4088
GRU 0.4392 0.4989 12.23 0.2234
BiLSTM 31250151.7945 144472333.4477 1139939852.06 -65135425335662872.0000
TCN 0.3878 0.4768 10.22 0.2907
Transformer 0.5440 0.6626 14.80 -0.3700
Seq2Seq 1.0489 1.2053 31.21 -3.5332
CNN-LSTM 0.4016 0.4868 11.46 0.2605
VAR(5) 0.5309 0.7407 16.85 -0.7123
VARMA(2,2) 0.5765 0.6929 17.20 -0.4982
VECM(1) 1.0086 1.1568 30.05 -3.1760
ARCH(1) 1.0086 1.1568 30.05 -3.1760
GARCH(1,1) 1.0163 1.1635 30.26 -3.2248
DLM 0.4515 0.5561 12.86 0.0351
模糊时间序列 0.3803 0.4701 10.50 0.3103
马尔可夫链 0.4600 0.6317 14.47 -0.2453
BSTS 0.3872 0.4515 10.32 0.3639
=====================
算法性能排名
=====================
按RMSE排序 (越小越好):
1. KNN(n=5) RMSE: 0.4238
2. 随机森林 RMSE: 0.4328
3. GBRT RMSE: 0.4469
4. SARIMA(1, 1, 1)x(1, 1, 1, 12) RMSE: 0.4515
5. BSTS RMSE: 0.4515
6. SVR RMSE: 0.4564
7. 模糊时间序列 RMSE: 0.4701
8. TCN RMSE: 0.4768
9. CNN-LSTM RMSE: 0.4868
10. GRU RMSE: 0.4989
11. 指数平滑 RMSE: 0.5561
12. ETS RMSE: 0.5561
13. DLM RMSE: 0.5561
14. 马尔可夫链 RMSE: 0.6317
15. Transformer RMSE: 0.6626
16. ARMA(2,2) RMSE: 0.6929
17. VARMA(2,2) RMSE: 0.6929
18. AR(5) RMSE: 0.6947
19. VAR(5) RMSE: 0.7407
20. MA(2) RMSE: 0.7505
21. VECM(1) RMSE: 1.1568
22. ARCH(1) RMSE: 1.1568
23. ARIMA(1, 1, 1) RMSE: 1.1635
24. GARCH(1,1) RMSE: 1.1635
25. Seq2Seq RMSE: 1.2053
26. GPR RMSE: 3.5257
27. LSTM RMSE: 18.7696
28. BiLSTM RMSE: 144472333.4477
按MAPE排序 (越小越好):
1. 随机森林 MAPE: 8.36%
2. KNN(n=5) MAPE: 8.41%
3. GBRT MAPE: 8.49%
4. TCN MAPE: 10.22%
5. SARIMA(1, 1, 1)x(1, 1, 1, 12) MAPE: 10.32%
6. BSTS MAPE: 10.32%
7. SVR MAPE: 10.43%
8. 模糊时间序列 MAPE: 10.50%
9. CNN-LSTM MAPE: 11.46%
10. GRU MAPE: 12.23%
11. 指数平滑 MAPE: 12.86%
12. ETS MAPE: 12.86%
13. DLM MAPE: 12.86%
14. 马尔可夫链 MAPE: 14.47%
15. Transformer MAPE: 14.80%
16. AR(5) MAPE: 15.71%
17. VAR(5) MAPE: 16.85%
18. MA(2) MAPE: 17.04%
19. ARMA(2,2) MAPE: 17.20%
20. VARMA(2,2) MAPE: 17.20%
21. VECM(1) MAPE: 30.05%
22. ARCH(1) MAPE: 30.05%
23. ARIMA(1, 1, 1) MAPE: 30.26%
24. GARCH(1,1) MAPE: 30.26%
25. Seq2Seq MAPE: 31.21%
26. GPR MAPE: 86.82%
27. LSTM MAPE: 257.80%
28. BiLSTM MAPE: 1139939852.06%
按R²排序 (越大越好):
1. KNN(n=5) R²: 0.4396
2. 随机森林 R²: 0.4154
3. GBRT R²: 0.3768
4. SARIMA(1, 1, 1)x(1, 1, 1, 12) R²: 0.3639
5. BSTS R²: 0.3639
6. SVR R²: 0.3500
7. 模糊时间序列 R²: 0.3103
8. TCN R²: 0.2907
9. CNN-LSTM R²: 0.2605
10. GRU R²: 0.2234
11. 指数平滑 R²: 0.0351
12. ETS R²: 0.0351
13. DLM R²: 0.0351
14. 马尔可夫链 R²: -0.2453
15. Transformer R²: -0.3700
16. ARMA(2,2) R²: -0.4982
17. VARMA(2,2) R²: -0.4982
18. AR(5) R²: -0.5060
19. VAR(5) R²: -0.7123
20. MA(2) R²: -0.7578
21. VECM(1) R²: -3.1760
22. ARCH(1) R²: -3.1760
23. ARIMA(1, 1, 1) R²: -3.2248
24. GARCH(1,1) R²: -3.2248
25. Seq2Seq R²: -3.5332
26. GPR R²: -37.7907
27. LSTM R²: -1098.4088
28. BiLSTM R²: -65135425335662872.0000
附上源代码:
"""
时间序列预测算法对比分析程序
使用多种算法进行时间序列预测,并生成对比分析报告
"""import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error, mean_squared_error, mean_absolute_percentage_error
import warnings
import os
import sys
from datetime import datetime# 统计模型
from statsmodels.tsa.ar_model import AutoReg
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.tsa.holtwinters import ExponentialSmoothing# LSTM/深度学习相关
try:from tensorflow.keras.models import Sequential, Modelfrom tensorflow.keras.layers import LSTM, Dense, GRU, Bidirectional, Conv1D, MaxPooling1D, Flatten, Dropout, Input, Attention, MultiHeadAttention, LayerNormalizationfrom tensorflow.keras.callbacks import EarlyStoppingTENSORFLOW_AVAILABLE = True
except ImportError:TENSORFLOW_AVAILABLE = Falseprint("警告: TensorFlow未安装,深度学习模型将无法使用")# Prophet
try:from prophet import ProphetPROPHET_AVAILABLE = True
except ImportError:PROPHET_AVAILABLE = False# 机器学习模型
try:from sklearn.svm import SVRfrom sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressorfrom sklearn.neighbors import KNeighborsRegressorfrom sklearn.gaussian_process import GaussianProcessRegressorfrom sklearn.gaussian_process.kernels import RBF, ConstantKernel as CSKLEARN_AVAILABLE = True
except ImportError:SKLEARN_AVAILABLE = False# LightGBM
try:import lightgbm as lgbLIGHTGBM_AVAILABLE = True
except ImportError:LIGHTGBM_AVAILABLE = False# 统计模型
try:from statsmodels.tsa.vector_ar.var_model import VARfrom statsmodels.tsa.statespace.varmax import VARMAXfrom statsmodels.tsa.vector_ar.vecm import VECMfrom statsmodels.tsa.arch.arch_model import ARCHModelfrom statsmodels.tsa.statespace.exponential_smoothing import ExponentialSmoothing as ETSSTATSMODELS_VAR_AVAILABLE = True
except ImportError:STATSMODELS_VAR_AVAILABLE = Falsewarnings.filterwarnings('ignore')# 设置Windows控制台编码为UTF-8
if sys.platform == 'win32':try:sys.stdout.reconfigure(encoding='utf-8')sys.stderr.reconfigure(encoding='utf-8')except:pass# 设置matplotlib支持中文
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = Falseclass TimeSeriesPredictor:"""时间序列预测器基类"""def __init__(self, name):self.name = nameself.model = Noneself.is_fitted = Falsedef fit(self, data):"""训练模型"""raise NotImplementedErrordef predict(self, steps):"""预测"""raise NotImplementedErrordef evaluate(self, y_true, y_pred):"""评估预测结果"""mae = mean_absolute_error(y_true, y_pred)rmse = np.sqrt(mean_squared_error(y_true, y_pred))mape = mean_absolute_percentage_error(y_true, y_pred) * 100# 计算R²ss_res = np.sum((y_true - y_pred) ** 2)ss_tot = np.sum((y_true - np.mean(y_true)) ** 2)r2 = 1 - (ss_res / ss_tot) if ss_tot != 0 else 0return {'MAE': mae,'RMSE': rmse,'MAPE': mape,'R²': r2}class ARPredictor(TimeSeriesPredictor):"""AR (自回归) 模型"""def __init__(self, lags=5):super().__init__(f"AR({lags})")self.lags = lagsdef fit(self, data):try:self.model = AutoReg(data, lags=self.lags).fit()self.is_fitted = Trueexcept Exception as e:print(f"AR模型训练失败: {e}")self.is_fitted = Falsedef predict(self, steps):if not self.is_fitted:raise ValueError("模型尚未训练")try:forecast = self.model.forecast(steps=steps)return forecast.values if hasattr(forecast, 'values') else forecastexcept:# 如果forecast失败,使用predictn = len(self.model.model.endog)predictions = self.model.predict(start=n, end=n+steps-1)return predictions.values if hasattr(predictions, 'values') else predictionsclass MAPredictor(TimeSeriesPredictor):"""MA (移动平均) 模型 - 通过ARIMA(0,0,q)实现"""def __init__(self, q=2):super().__init__(f"MA({q})")self.q = qdef fit(self, data):try:self.model = ARIMA(data, order=(0, 0, self.q)).fit()self.is_fitted = Trueexcept Exception as e:print(f"MA模型训练失败: {e}")self.is_fitted = Falsedef predict(self, steps):if not self.is_fitted:raise ValueError("模型尚未训练")try:forecast = self.model.forecast(steps=steps)return forecast.values if hasattr(forecast, 'values') else forecastexcept:n = len(self.model.model.endog)predictions = self.model.predict(start=n, end=n+steps-1)return predictions.values if hasattr(predictions, 'values') else predictionsclass ARMAPredictor(TimeSeriesPredictor):"""ARMA 模型"""def __init__(self, p=2, q=2):super().__init__(f"ARMA({p},{q})")self.p = pself.q = qdef fit(self, data):try:self.model = ARIMA(data, order=(self.p, 0, self.q)).fit()self.is_fitted = Trueexcept Exception as e:print(f"ARMA模型训练失败: {e}")self.is_fitted = Falsedef predict(self, steps):if not self.is_fitted:raise ValueError("模型尚未训练")try:forecast = self.model.forecast(steps=steps)return forecast.values if hasattr(forecast, 'values') else forecastexcept:n = len(self.model.model.endog)predictions = self.model.predict(start=n, end=n+steps-1)return predictions.values if hasattr(predictions, 'values') else predictionsclass ARIMAPredictor(TimeSeriesPredictor):"""ARIMA 模型"""def __init__(self, order=(1, 1, 1)):super().__init__(f"ARIMA{order}")self.order = orderdef fit(self, data):try:self.model = ARIMA(data, order=self.order).fit()self.is_fitted = Trueexcept Exception as e:print(f"ARIMA模型训练失败: {e}")self.is_fitted = Falsedef predict(self, steps):if not self.is_fitted:raise ValueError("模型尚未训练")try:forecast = self.model.forecast(steps=steps)return forecast.values if hasattr(forecast, 'values') else forecastexcept:n = len(self.model.model.endog)predictions = self.model.predict(start=n, end=n+steps-1)return predictions.values if hasattr(predictions, 'values') else predictionsclass SARIMAPredictor(TimeSeriesPredictor):"""SARIMA 模型"""def __init__(self, order=(1, 1, 1), seasonal_order=(1, 1, 1, 12)):super().__init__(f"SARIMA{order}x{seasonal_order}")self.order = orderself.seasonal_order = seasonal_orderdef fit(self, data):try:self.model = SARIMAX(data, order=self.order, seasonal_order=self.seasonal_order,enforce_stationarity=False,enforce_invertibility=False).fit(disp=False)self.is_fitted = Trueexcept Exception as e:print(f"SARIMA模型训练失败: {e}")self.is_fitted = Falsedef predict(self, steps):if not self.is_fitted:raise ValueError("模型尚未训练")try:forecast = self.model.forecast(steps=steps)return forecast.values if hasattr(forecast, 'values') else forecastexcept:n = len(self.model.model.endog)predictions = self.model.predict(start=n, end=n+steps-1)return predictions.values if hasattr(predictions, 'values') else predictionsclass ExponentialSmoothingPredictor(TimeSeriesPredictor):"""指数平滑模型"""def __init__(self, trend='add', seasonal='add', seasonal_periods=12):super().__init__("指数平滑")self.trend = trendself.seasonal = seasonalself.seasonal_periods = seasonal_periodsdef fit(self, data):try:self.model = ExponentialSmoothing(data, trend=self.trend,seasonal=self.seasonal,seasonal_periods=self.seasonal_periods).fit()self.is_fitted = Trueexcept Exception as e:# 如果带季节性的模型失败,尝试不带季节性的try:self.model = ExponentialSmoothing(data, trend=self.trend).fit()self.is_fitted = Trueexcept:print(f"指数平滑模型训练失败: {e}")self.is_fitted = Falsedef predict(self, steps):if not self.is_fitted:raise ValueError("模型尚未训练")forecast = self.model.forecast(steps=steps)return forecast.values if hasattr(forecast, 'values') else forecastclass LSTMPredictor(TimeSeriesPredictor):"""LSTM 模型"""def __init__(self, lookback=12, units=50):super().__init__("LSTM")self.lookback = lookbackself.units = unitsself.scaler_mean = Noneself.scaler_std = Nonedef _normalize(self, data):"""数据归一化"""self.scaler_mean = np.mean(data)self.scaler_std = np.std(data)return (data - self.scaler_mean) / self.scaler_stddef _denormalize(self, data):"""数据反归一化"""return data * self.scaler_std + self.scaler_meandef _create_sequences(self, data, lookback):"""创建时间序列窗口"""X, y = [], []for i in range(lookback, len(data)):X.append(data[i-lookback:i])y.append(data[i])return np.array(X), np.array(y)def fit(self, data):if not TENSORFLOW_AVAILABLE:print("TensorFlow未安装,跳过LSTM模型")self.is_fitted = Falsereturntry:# 保存原始数据用于后续预测self.train_data = data.copy()# 归一化数据(保存归一化参数)data_norm = self._normalize(data)# 创建序列if len(data_norm) < self.lookback + 1:print(f"数据长度不足,需要至少{self.lookback + 1}个样本")self.is_fitted = FalsereturnX, y = self._create_sequences(data_norm, self.lookback)# 重塑数据为LSTM输入格式 [samples, time steps, features]X = X.reshape((X.shape[0], X.shape[1], 1))# 构建LSTM模型self.model = Sequential([LSTM(self.units, activation='relu', input_shape=(self.lookback, 1)),Dense(1)])self.model.compile(optimizer='adam', loss='mse')# 训练模型early_stop = EarlyStopping(monitor='loss', patience=10, verbose=0)self.model.fit(X, y, epochs=100, batch_size=16, callbacks=[early_stop], verbose=0)self.is_fitted = Trueexcept Exception as e:print(f"LSTM模型训练失败: {e}")self.is_fitted = Falsedef predict(self, steps):if not self.is_fitted:raise ValueError("模型尚未训练")try:# 获取最后lookback个数据点if hasattr(self, 'last_data'):last_data = self.last_dataelse:raise ValueError("需要提供历史数据")predictions = []current_data = last_data.copy()for _ in range(steps):# 准备输入X_input = current_data[-self.lookback:].reshape(1, self.lookback, 1)# 预测pred = self.model.predict(X_input, verbose=0)[0, 0]predictions.append(pred)# 更新数据current_data = np.append(current_data, pred)# 反归一化predictions = self._denormalize(np.array(predictions))return predictionsexcept Exception as e:print(f"LSTM预测失败: {e}")return np.full(steps, np.nan)def set_last_data(self, data):"""设置用于预测的历史数据"""if self.is_fitted:# 使用训练时的归一化参数if self.scaler_mean is not None and self.scaler_std is not None:self.last_data = (data - self.scaler_mean) / self.scaler_stdelse:self.last_data = self._normalize(data)# ==================== 新增预测器类 ====================class ProphetPredictor(TimeSeriesPredictor):"""Prophet模型"""def __init__(self):super().__init__("Prophet")def fit(self, data):if not PROPHET_AVAILABL