论文阅读:《A Universal Model for Human Mobility Prediction》
研究背景
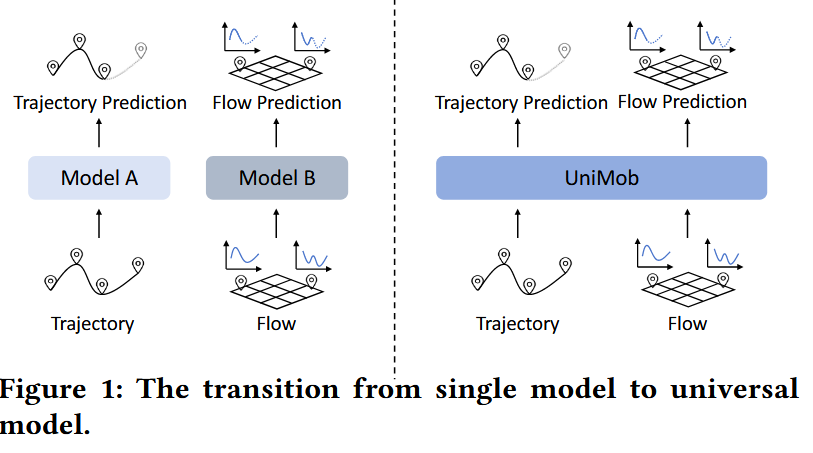
人类移动预测目前主要聚焦于两块:个体轨迹预测和群体流动预测,所有相关研究目前都围绕这两大块中的一块进行,但没有人把这两块合起来一起研究,原因是因为这两类研究的数据格式差别过大,个人轨迹数据主要描述个体某个时间在某个位置,而群体流动数据主要记录某个位置某时间流入流出多少人,因此放在一起研究难度过大。
创新点
但是,这两种数据之间并不是毫无关联的,群体流动正是由个体轨迹聚合体现出来的,而个体行为又会受到群体的影响,因此放在一起研究很有必要。
为此,作者设计了一种新的框架,首次实现个体轨迹与人群流动预测的统一,解决了现有模型仅支持单任务的局限。该模型通过多视角移动令牌化器将两种数据转换为统一时空令牌,结合扩散 Transformer 架构建模时空动态,并设计双向个体 - 集体对齐机制(I2C 损失与 C2I 损失)提取共同时空模式,实现两者预测的相互增强。
问题定义
因为本文有两种输入数据,作者对这两种数据分别进行了阐述:

这段是比较好理解的,因此我就不过多说明了。问题定义就是:在我们知道过去一段时间(t-p到t这段时间)的个体轨迹数据或群体流动数据的情况下,预测未来k步之内的个人轨迹数据或群体流动数据。
模型框架
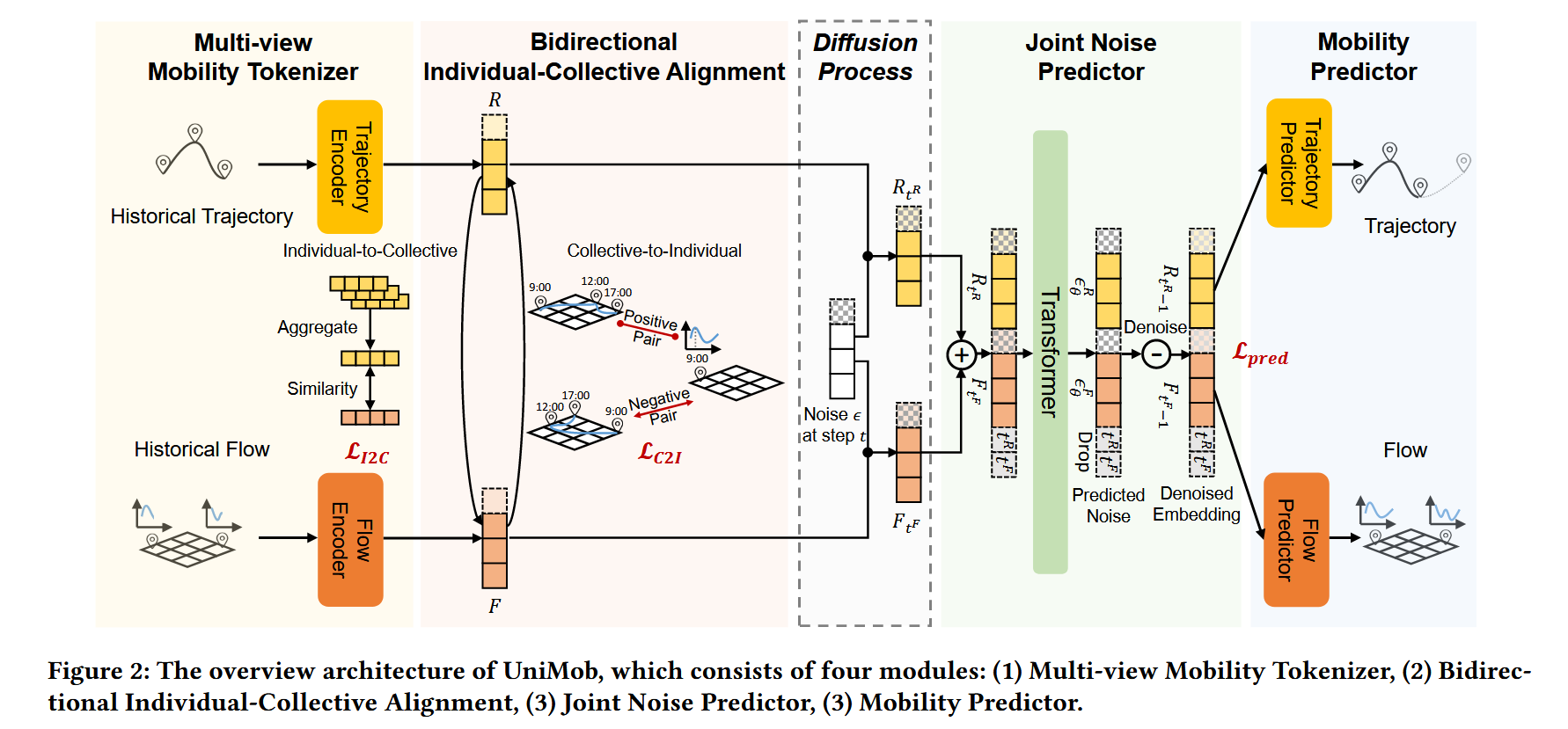
整个模型框架图也是比较清晰明白的。一共有五大块,接下来依次介绍这五大块的作用:
Multi-view Mobility Tokenizer
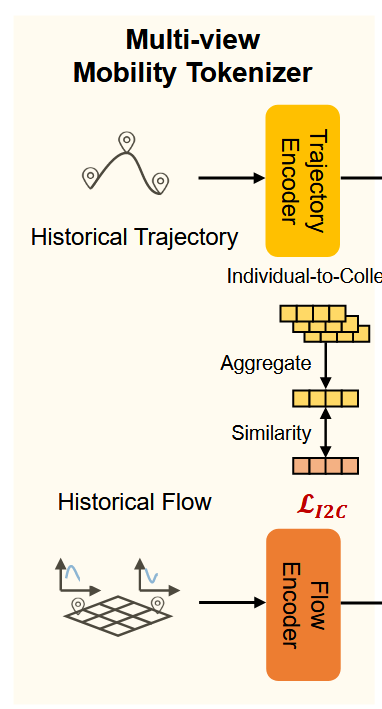
如图中所展示,输入数据有两块:个体轨迹、群体流动,在这个模块,输入数据由于格式不统一、原始数据太长等原因,需要对数据进行统一的切片处理,通过两个编码器(Trajectory Encoder和Flow Encoder)将不同的两种数据切片为长短一致的tokens,方便后续比较的操作。
Bidirectional Individual-Collective Alignment
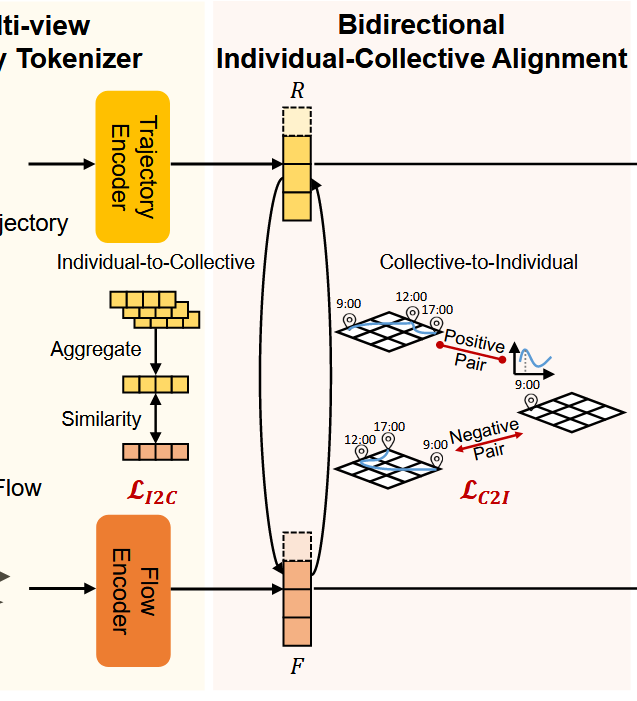
这一步是两种损失的计算,也就是作者在创新点中说到的双向个体 - 集体对齐机制。
对于损失I2C来说,是一个个体轨迹向群体流动对齐的方式,具体实现是个体轨迹数据聚合起来,再通过相似度计算的公式与群体数据进行相似度计算,最终得到损失。
对于损失C2I来说,首先给出某地的群体数据峰值,这一峰值会有一个时间,那么将个体轨迹数据中此时此刻在此地的样本列为正样本,其余当作负样本,以此来计算对比损失使正样本越来越近负样本越来越远。
Diffusion Process
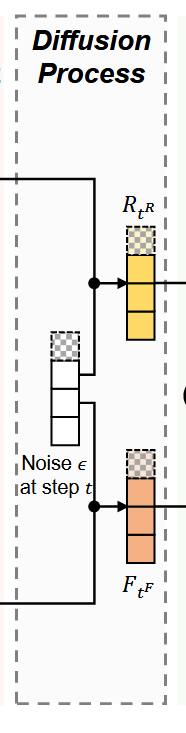
扩散过程用于给数据加噪声,记录下每一步t的噪声值,直到第T步,数据完全模糊。随机采样第t步的噪声与原数据结合,送入下一个环节。
Joint Noise Predictor
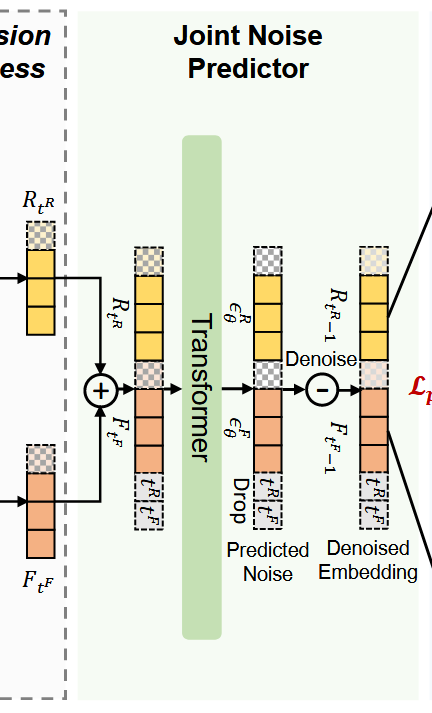
这个模块的输入是已经加了噪声的数据了。将两种数据合并在一起共同送入该模块,经过一个transformer预测出噪声,然后去噪。
Mobility Predictor
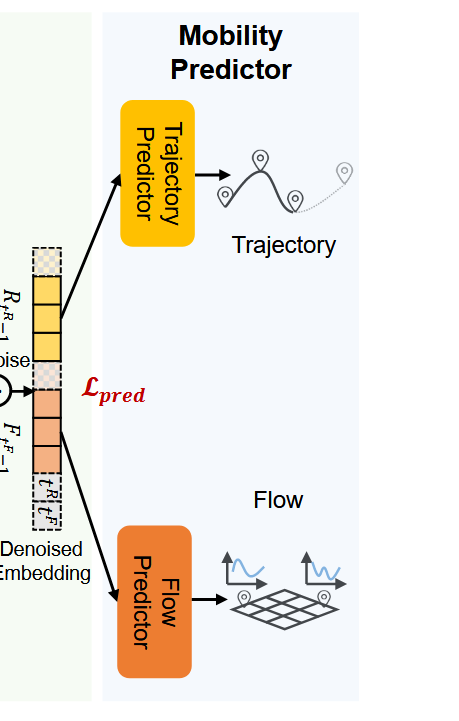
最后再将两种去噪后的数据分开,分别进行预测,得到预测损失L_pred。
损失函数
上述过程中产生了三个损失,将这三个损失按照一定比例相加,就可以得到完整的模型损失了:
