StarRocks技术分享
产品概述
StarRocks作为新一代极速全场景MPP数据库,致力于为用户提供简捷高效的数据分析体验。其核心优势在于:
- 无需复杂预处理即可支持多场景极速分析
- 采用创新的全面向量化引擎与CBO优化器
- 具备卓越的多表关联查询性能
- 支持实时数据分析与高效查询
- 提供现代化物化视图加速机制
- 灵活支持大宽表、星型/雪花模型等多种数据模型
该产品兼容MySQL协议及标准SQL语法,无缝对接主流BI工具(Tableau/Power BI等),具备高可用、易运维特性,且无外部依赖。
竞品对比:StarRocks vs AnalyticDB(ADB)
核心特性对比
| 维度 | StarRocks | ADB |
|---|---|---|
| 架构 | 开源MPP架构 | 云原生数据仓库服务 |
| 版本 | 单一版本 | MySQL/PostgreSQL双版本 |
| 部署 | 多云/私有化灵活部署 | 阿里云全托管 |
| 性能 | 向量化引擎+CBO优化 | 存储计算分离架构 |
优势分析
StarRocks核心优势:
- 极致性能:向量化执行引擎配合智能优化器实现亚秒级响应
- 实时能力:支持秒级数据更新与实时分析
- 并发处理:专为高并发查询场景优化设计
- 成本控制:开源模式显著降低总体拥有成本(TCO)
- 部署灵活:支持混合云、私有云等多种部署方案
ADB突出特点: - 免运维:全托管服务降低管理复杂度
- 弹性扩展:存储计算独立伸缩能力
- 生态整合:深度集成阿里云产品矩阵
- 企业支持:提供商业级服务保障
技术架构
核心组件拓扑
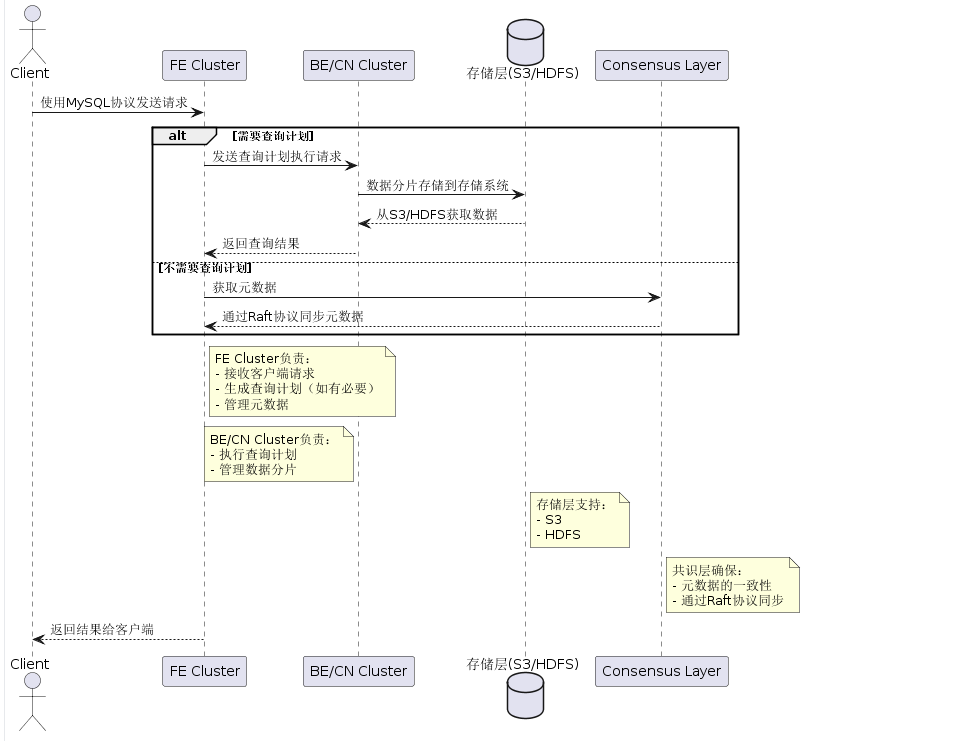
前端节点(FE)架构
核心子系统:
- 查询处理引擎:
- SQL解析器:基于Antlr4实现毫秒级语法树构建
- 优化器:CBO基于统计信息(基数/直方图)生成最优执行计划
- 分布式调度器:采用Push-Based模型分配MPP任务
- 元数据管理:
- 版本化元数据存储(BDB-JE)
- 分布式共识(类Raft协议)
- 元数据缓存分层(内存Snapshot+磁盘Log)
高可用设计:
- 三节点部署模式(Leader/Follower/Observer)
- 故障检测:心跳机制(500ms间隔)
- 选主时间:<3秒(依赖BDB-JE的选举机制)
后端执行引擎(BE/CN)
计算引擎关键技术
| 技术维度 | 实现方案 | 性能优化点 |
|---|---|---|
| 向量化执行 | Columnar Batch Processing | SIMD指令集加速 |
| 并行调度 | Pipeline并行模型 | 自动并行度调节(DOP自适应) |
| 内存管理 | Arena内存池+智能预分配 | 零拷贝序列化/反序列化 |
| 代码生成 | LLVM动态编译 | 消除虚函数调用开销 |
存储引擎对比
# 存算一体(BE) vs 存算分离(CN)
+---------------------+---------------------------+---------------------------+
| 特性 | BE | CN |
+---------------------+---------------------------+---------------------------+
| 数据位置 | 本地SSD/NVMe | 对象存储(S3/HDFS) |
| 缓存机制 | PageCache+BlockCache | 多层缓存(内存/本地SSD) |
| 数据格式 | Segment+Index | 相同格式+智能预取 |
| 扩展性 | 需数据再平衡 | 秒级弹性伸缩 |
+---------------------+---------------------------+---------------------------+
存储格式详解
物理存储结构:
├── Tablet (分区单元)
│ ├── Segment (列存文件)
│ │ ├── DictEncoded Column
│ │ ├── Bitmap Index
│ │ └── ZoneMap
│ └── Persistent Index (主键索引)
核心优化技术:
- 列存编码:
- 字典编码(高基数列)
- 位图编码(低基数列)
- Delta编码(时序数据)
- 索引体系:
- 全局索引:布隆过滤器(Bloom Filter)
- 局部索引:ZoneMap(Min/Max统计)
- 点查优化:Persistent Primary Index
部署StarRocks存算一体模式
下载和解压
wget https://releases.starrocks.io/starrocks/StarRocks-3.2.3.tar.gz
tar -xzf StarRocks-3.2.3.tar.gz -C /mjw/opt
mv /opt/StarRocks-3.2.3 /opt/starrocks
cd /opt/starrocks
目录结构准备
mkdir -p {fe/log,fe/tmp,fe/meta,be/log,be/storage,be/tmp}
FE配置(fe/conf/fe.conf)
JAVA_OPTS = "-Xmx8g -XX:+UseG1GC -XX:G1HeapRegionSize=32m"
http_port = 8030
rpc_port = 9020
query_port = 9030
edit_log_port = 9010
mysql_service_nio_enabled = true
meta_dir = ${STARROCKS_HOME}/meta
log_dir = ${STARROCKS_HOME}/fe/log
frontend_address = 192.168.18.29 # 替换为 FE 的内网 IP
priority_networks = 192.168.18.29/24 # 限定 FE 使用的网段
BE配置(be/conf/be.conf)
JAVA_OPTS = "-Xmx8g -XX:+UseG1GC -XX:G1HeapRegionSize=32m"
be_port = 9060
be_http_port = 8040
heartbeat_service_port = 9050
brpc_port = 8060
starlet_port = 9070
storage_root_path = ${STARROCKS_HOME}/storage
storage_format_version = 2
priority_networks = 192.168.18.29/24 # 限定 BE 使用的网段
标准启动顺序
# 先启动FE,再启动BE
./fe/bin/start_fe.sh --daemon
sleep 30 # 等待 FE 完全启动
./be/bin/start_be.sh --daemon#查看启动日志
tail -1000f fe/log/fe.log
tail -1000f be/log/be.INFO# 停止服务命令
./fe/bin/stop_fe.sh
./be/bin/stop_be.sh
BE 注册逻辑
- 自动注册 BE 启动后,会通过心跳机制(heartbeat_service_port,默认 9050)自动向 FE 注册,无需手动干预。
- SHOW PROC ‘/backends’\G 返回空:表示自动注册失败
- 手动注册(仅在以下情况需要):
- BE 自动注册失败(如网络问题)。
- 需要更换 BE 的 IP 或端口。
- 初始化集群时 FE 未正确识别 BE。
手动注册命令(在 FE 的 MySQL 客户端执行):
# 使用MySQL客户端连接
mysql -h 127.0.0.1 -P 9030 -uroot# 在MySQL客户端中执行
ALTER SYSTEM ADD BACKEND "192.168.18.29:9050";# 检查BE状态
SHOW PROC '/backends'\G
正常应返回类似以下信息:
*************************** 1. row ***************************BackendId: 10001IP: 192.168.18.29HeartbeatPort: 9050BePort: 9060HttpPort: 8040BrpcPort: 8060Alive: true # 关键字段!LastStartTime: 2025-04-17 09:35:47LastHeartbeat: 2025-04-17 10:00:00
访问 Web UI
FE Web UI:http://192.168.18.29:8030/
BE Web UI:http://192.168.18.29:8040/
默认用户名: root
密码为空
实现从Mysql实时同步
下载并安装同步工具
使用 SMT、 Flink、Flink CDC connector、flink-connector-starrocks实现实时同步
开启BINLOG日志
[mysqld]
basedir=/mjw/opt/mysql8
datadir=/mjw/opt/mysql8/data
socket=/mjw/opt/mysql8/mysql.sock
log-error=/mjw/opt/mysql8/logs/mysql.err
pid-file=/mjw/opt/mysql8/mysql.pid# 网络设置
port=3306
bind-address=0.0.0.0# 字符集设置
character-set-server=utf8mb4
collation-server=utf8mb4_unicode_ci# 存储引擎
default-storage-engine=InnoDB# 内存设置
key_buffer_size=256M
max_allowed_packet=64M
table_open_cache=2000
sort_buffer_size=4M
read_buffer_size=4M
read_rnd_buffer_size=8M
myisam_sort_buffer_size=64M
thread_cache_size=8# 日志设置
log-bin=mysql-bin
binlog_format=ROW
expire_logs_days=7
slow_query_log=1
slow_query_log_file=/mjw/opt/mysql8/logs/mysql-slow.log
long_query_time=2[client]
socket=/mjw/opt/mysql8/mysql.sock
下载 Flink CDC connector
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.2.0/flink-sql-connector-mysql-cdc-2.2.0.jar
下载 flink-connector-starrocks
只能去maven仓库下载jar包
https://mvnrepository.com/artifact/com.starrocks/flink-connector-starrocks/1.2.3_flink-1.14_2.11
将 Flink CDC connector、Flink-connector-starrocks 的 JAR 包 flink-sql-connector-mysql-cdc-2.2.0.jar、1.2.3_flink-1.14_2.11.jar 移动至 Flink 的 lib 目录。
注意如果 Flink 已经处于运行状态中,则需要先停止 Flink,然后重启 Flink ,以加载并生效 JAR 包。
./bin/stop-cluster.sh
./bin/start-cluster.sh
下载、安装并启动 Flink
# 下载 Flink
wget https://archive.apache.org/dist/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.11.tgz
# 解压 Flink
tar -xzf flink-1.14.5-bin-scala_2.11.tgz
# 移动
mv /opt/flink-1.14.5 /mjw/opt/flink
启动 Flink
# 进入 Flink 目录
cd flink-1.14.5# 启动 Flink 集群
./bin/start-cluster.sh# 返回如下信息,表示成功启动 flink 集群
Starting cluster.
Starting standalonesession daemon on host.
Starting taskexecutor daemon on host.
下载安装SMT
wget https://releases.starrocks.io/resources/smt.tar.gz
配置 SMT 配置文件。 进入 SMT 的 conf 目录,编辑配置文件 config_prod.conf。
[db]
host = 192.168.18.29
port = 3306
user = flinkuser
password = 123456
# currently available types: `mysql`, `pgsql`, `oracle`, `hive`, `clickhouse`, `sqlserver`, `tidb`
type = mysql
# # only takes effect on `type == hive`.
# # Available values: kerberos, none, nosasl, kerberos_http, none_http, zk, ldap
# authentication = kerberos[other]
# number of backends in StarRocks
be_num = 1
# `decimal_v3` is supported since StarRocks-1.8.1
use_decimal_v3 = true
# directory to save the converted DDL SQL
output_dir = ./result# !!!`database` `table` `schema` are case sensitive in `oracle`!!!
[table-rule.1]
# pattern to match databases for setting properties
# !!! database should be a `whole instance(or pdb) name` but not a regex when it comes with an `oracle db` !!!
database = ^demo.*$
# pattern to match tables for setting properties
table = ^.*$
# `schema` only takes effect on `postgresql` and `oracle` and `sqlserver`
schema = ^public$############################################
### flink sink configurations
### DO NOT set `connector`, `table-name`, `database-name`, they are auto-generated
############################################
flink.starrocks.jdbc-url=jdbc:mysql://192.168.18.29:9030
flink.starrocks.load-url=192.168.18.29:8030
flink.starrocks.username= root
flink.starrocks.password=
flink.starrocks.sink.max-retries=10
flink.starrocks.sink.buffer-flush.interval-ms=15000
flink.starrocks.sink.properties.format=json
flink.starrocks.sink.properties.strip_outer_array=true
# # used to set the server-id for mysql-cdc jobs instead of using a random server-id
# flink.cdc.server-id = 5000
运行 SMT
# 运行 SMT
./starrocks-migrate-tool# 进入并查看 result 目录中的文件
cd result
ls result
flink-create.1.sql smt.tar.gz starrocks-create.all.sql
flink-create.all.sql starrocks-create.1.sql
遇到的错误
错误一
[error] failed to initialize database, got error Error 1130: Host 'dw003' is not allowed to connect to this MySQL server
panic: Error 1130: Host 'dw003' is not allowed to connect to this MySQL server
原因:
连接到 MySQL 服务器时被拒绝了
这个问题通常是由于 MySQL 没有为尝试连接的用户配置适当的权限以允许从该特定主机进行连接。
解决:
创建或更新用户权限
CREATE USER 'flinkuser'@'%' IDENTIFIED BY '123456';
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'flinkuser'@'%';
FLUSH PRIVILEGES;
错误二
[301.333ms] [rows:150] SELECT * FROM `information_schema`.`tables` WHERE TABLE_TYPE='BASE TABLE' ORDER BY TABLE_SCHEMA asc,
TABLE_NAME ascpanic: No matching table columns found.原因:
StarRocks Migrate Tool 在尝试迁移数据时遇到了问题,具体来说是在寻找匹配的表字段时失败了并抛出了 panic: No matching table columns found.
的错误。这通常意味着工具在尝试映射源数据库(在这个案例中是 MySQL)和目标数据库(可能是 StarRocks)的表结构时遇到了不兼容或不存在的列定义。
解决:
在mysql中创建对应的库和表
在 StarRocks 中创建目标库和表
连接 StarRocks
使用 MySQL 客户端连接 StarRocks(因为 StarRocks 兼容 MySQL 协议):
mysql -h 127.0.0.1 -P 9030 -uroot
执行 StarRocks 建表 SQL
执行 SMT 生成的建表语句:
# 进入 MySQL 客户端后执行
mysql -h<StarRocks_FE_IP> -P9030 -uroot -p
source /mjw/opt/smt/result/starrocks-create.all.sql;
验证表是否创建成功
SHOW DATABASES;
USE <目标数据库名>;
SHOW TABLES;
提交 Flink SQL 作业
# 进入Flink目录
# 启动 Standalone 集群
./bin/start-cluster.sh# 检查是否启动成功
./bin/flink list# 启动 Flink SQL 客户端
./bin/sql-client.sh
在 SQL 客户端中设置必要参数
-- 设置 Checkpoint 参数(保证 Exactly-Once 语义)
SET 'execution.checkpointing.interval' = '10s';
SET 'execution.checkpointing.mode' = 'EXACTLY_ONCE';
执行 SMT 生成的 Flink SQL
-- 在 SQL 客户端中执行(注意路径要正确)
RUN FILE '/mjw/opt/smt/result/flink-create.all.sql';
遇到的错误
[ERROR] Could not execute SQL statement. Reason:
org.apache.calcite.runtime.CalciteException: Non-query expression encountered in illegal context
原因:
这个错误通常发生在 Flink SQL 客户端尝试执行包含非查询语句(如 SET、CREATE 等)的 SQL 文件时。Flink SQL 客户端对 SQL 文件的执行有一些限制。
解决方式:
逐条执行 SQL 语句
打开flink-create.all.sql 文件
在 Flink SQL 客户端中逐条复制执行:
验证同步状态
检查 Flink 作业运行状态
# 查看运行的作业
./bin/flink list# 查看特定作业的日志
./bin/flink logs -j <JobID>
检查 StarRocks 数据
-- 在 StarRocks 中查询数据
USE <目标数据库>;
SELECT COUNT(*) FROM <表名>;
SELECT * FROM <表名> LIMIT 10;
再次验证是否是实时同步
mysql表中再插入一条数据

查看starRocks库
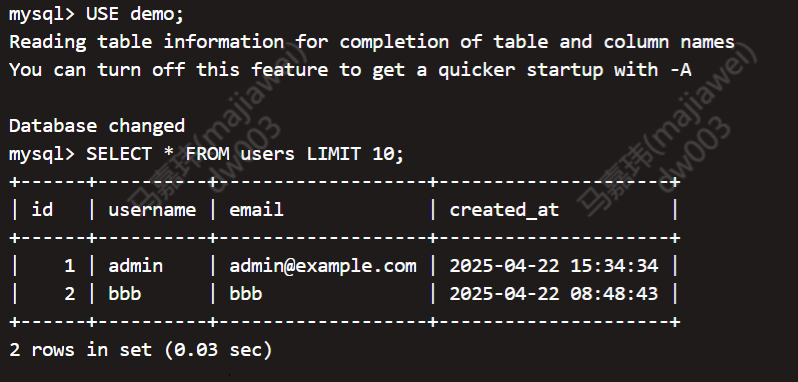
检查监控指标(如果配置了)
访问 Flink Web UI(通常为 http://服务器IP:8081)查看作业运行情况
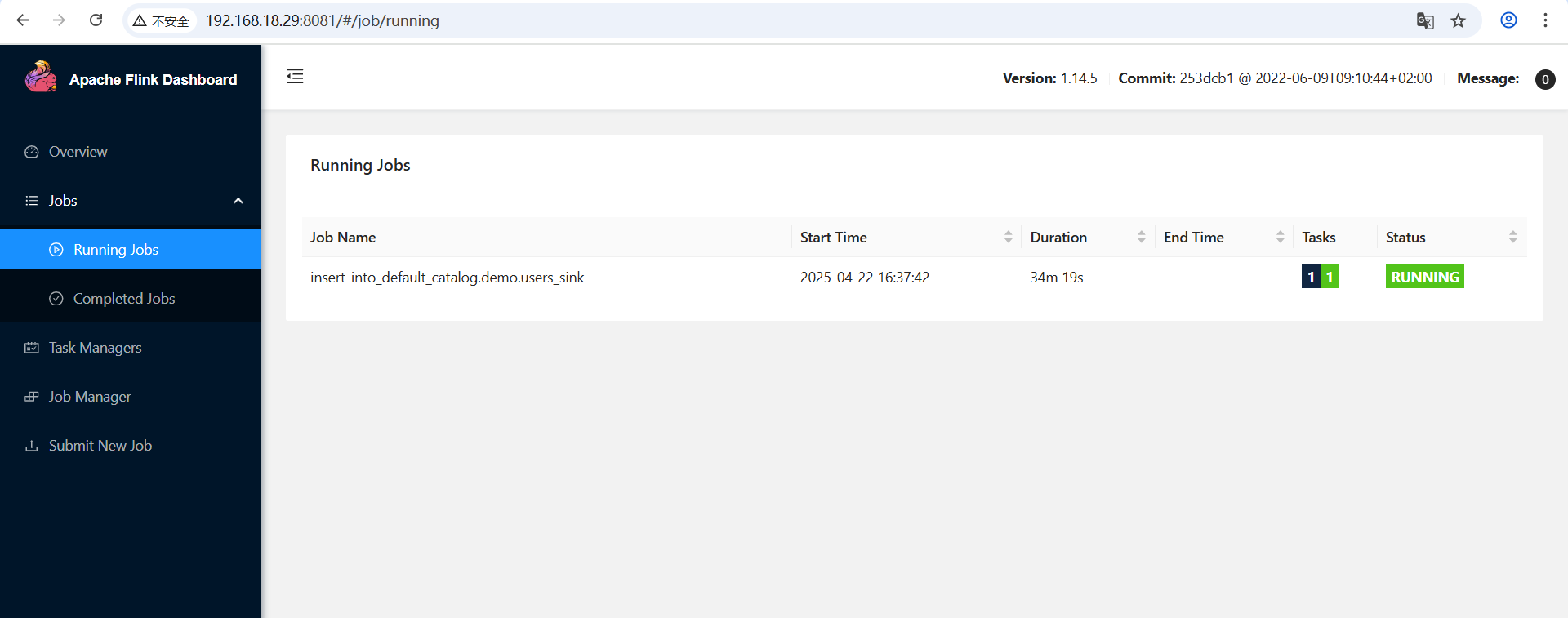
管理同步作业
# 停止作业
./bin/flink cancel <JobID># 重启作业
# 如果作业失败,可以从最新的 checkpoint 恢复:
./bin/flink run -s <checkpoint路径> ...
使用 Kafka connector 导入数据
部署zookeeper
下载
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz
tar -xzf apache-zookeeper-3.8.4-bin.tar.gz
mv apache-zookeeper-3.8.4-bin.tar.gz /mjw/opt/zookeeper
修改配置
创建配置文件 conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/mjw/opt/zookeeper/data
clientPort=2181
admin.serverPort=8080
maxClientCnxns=60
启动 ZooKeeper
# 启动 ZooKeeper
bin/zkServer.sh start# 检查状态
bin/zkServer.sh status
[root@slave1 zookeeper]# bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false. # 连接客户端
bin/zkCli.sh -server localhost:2181
部署 Kafka
下载
wget https://archive.apache.org/dist/kafka/3.6.2/kafka_2.13-3.6.2.tgz">kafka_2.13-3.6.2.tgz
tar -xzf kafka_2.13-3.6.1.tgz
mv kafka_2.13-3.6.1.tgz /mjw/opt/kafka
修改配置
编辑 config/server.properties:
broker.id=0
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://192.168.18.29:9092
log.dirs=/mjw/opt/kafka/log
zookeeper.connect=localhost:2181
启动 Kafka
bin/kafka-server-start.sh -daemon config/server.properties
创建测试 Topic
bin/kafka-topics.sh --create --topic starrocks_test --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1
StarRocks 配置
创建目标表
在 StarRocks 中创建目标表,例如
CREATE DATABASE IF NOT EXISTS kafka_test;USE kafka_test;CREATE TABLE IF NOT EXISTS kafka_source_table (id INT,name VARCHAR(50),age INT,event_time DATETIME
)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES ("replication_num" = "1"
);
创建 Routine Load 任务
CREATE ROUTINE LOAD kafka_test.kafka_json_load ON kafka_source_table
COLUMNS(id, name, age, event_time)
PROPERTIES
("format" = "json","jsonpaths" = "[\"$.id\", \"$.name\", \"$.age\", \"$.event_time\"]"
)
FROM KAFKA
("kafka_broker_list" = "192.168.18.29:9092","kafka_topic" = "starrocks_test","property.group.id" = "starrocks_json_group"
);
遇到的问题
使用 CSV 格式的时候无法将数据解析并写入到StarRocks中
以下是完整的解决过程
验证网络连通性
在 StarRocks BE 节点执行:
# 测试 Kafka 端口连通性
telnet 192.168.18.29 9092# 测试从 BE 访问 Kafka(临时启动消费者)
/mjw/opt/kafka/bin/kafka-console-consumer.sh \
--topic starrocks_test \
--bootstrap-server 192.168.18.29:9092 \
--from-beginning
出现报错
root@dw003:/mjw/opt/starrocks/be# telnet 192.168.18.29 9092
Trying 192.168.18.29...
Connected to 192.168.18.29.
Escape character is '^]'.
^C[2025-04-23 17:49:38,720] WARN [SocketServer listenerType=ZK_BROKER, nodeId=0] Unexpected error from /192.168.18.29 (channelId=192.168.18.29:9092-192.168.18.29:57615-6); closing connection (org.apache.kafka.common.network.Selector)
org.apache.kafka.common.network.InvalidReceiveException: Invalid receive (size = -720899)at org.apache.kafka.common.network.NetworkReceive.readFrom(NetworkReceive.java:92)at org.apache.kafka.common.network.KafkaChannel.receive(KafkaChannel.java:452)at org.apache.kafka.common.network.KafkaChannel.read(KafkaChannel.java:402)at org.apache.kafka.common.network.Selector.attemptRead(Selector.java:674)at org.apache.kafka.common.network.Selector.pollSelectionKeys(Selector.java:576)at org.apache.kafka.common.network.Selector.poll(Selector.java:481)at kafka.network.Processor.poll(SocketServer.scala:1107)at kafka.network.Processor.run(SocketServer.scala:1011)at java.base/java.lang.Thread.run(Thread.java:834)
Connection closed by foreign host.
解决方案是修改Kafka Broker 配置config/server.properties
listeners=PLAINTEXT://0.0.0.0:9092
调整完配置之后执行以下配置发现是能够读到数据了
# 测试从 BE 访问 Kafka(临时启动消费者)
/mjw/opt/kafka/bin/kafka-console-consumer.sh \
--topic starrocks_test \
--bootstrap-server 192.168.18.29:9092 \
--from-beginning
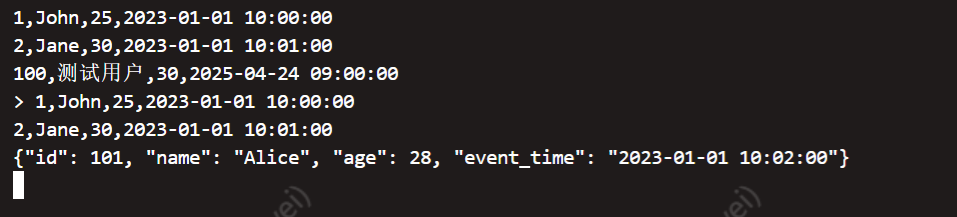
不过Routine Load 任务仍然无法将数据写入到StarRocks
尝试将Routine Load 任务由CSV格式改为JSON格式就成功读取到数据了,大概的猜测是CSV格式解析数据的时候失败了,可能无法识别逗号
数据验证
向 Kafka 发送测试数据
# 发送 JSON 消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic starrocks_test
> {"id": 101, "name": "Alice", "age": 28, "event_time": "2023-01-01 10:02:00"}
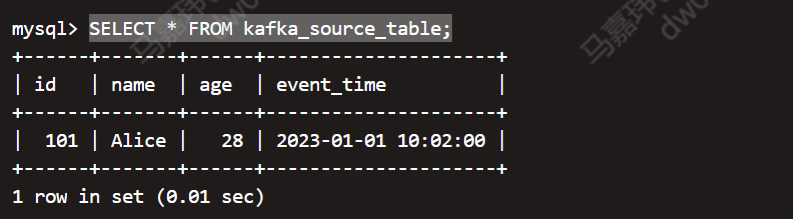
检查 StarRocks 中的数据
mysql -h 127.0.0.1 -P 9030 -uroot
SHOW DATABASES;
USE kafka_test
SHOW TABLES;
SELECT * FROM kafka_source_table;
哎研究了这么多,最终用的还是阿里云的ADB for mysql