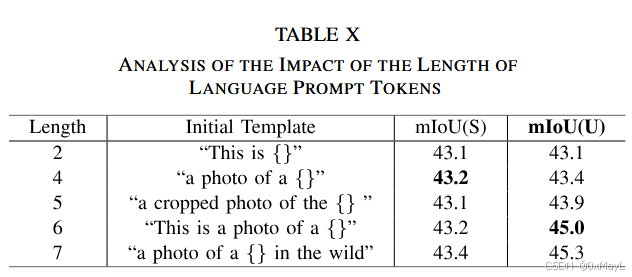
计算机视觉·LDVC
LDVC
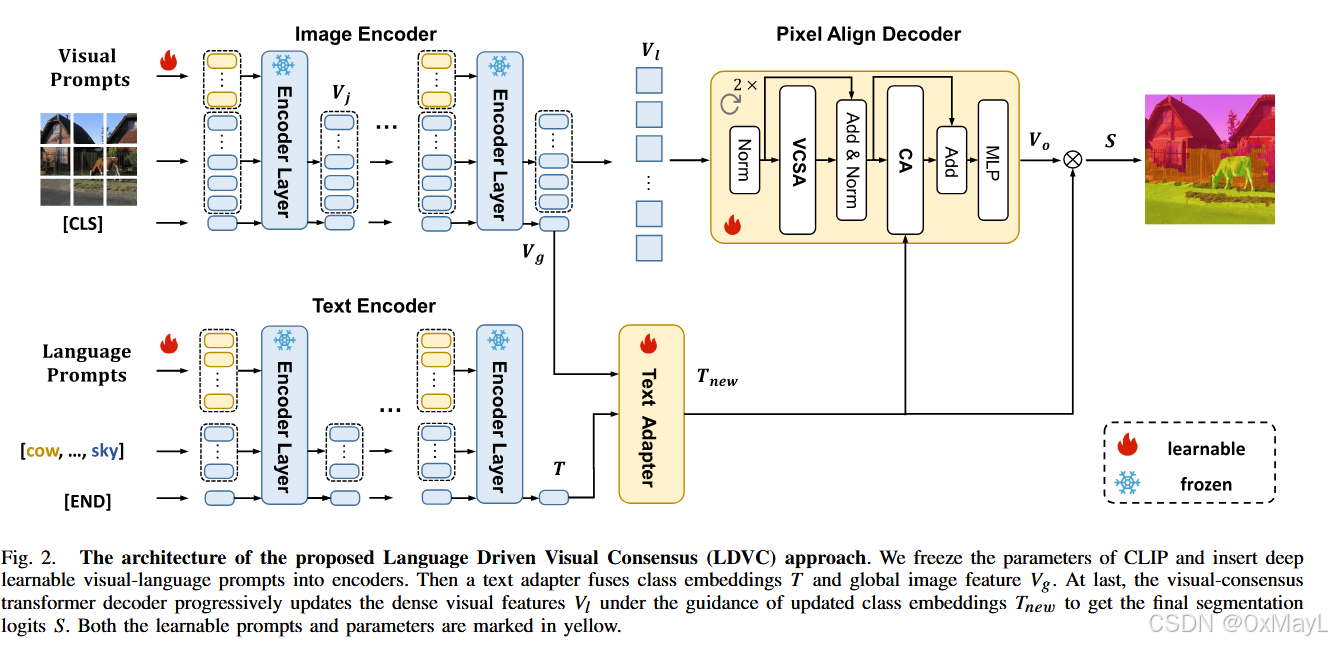
动机
- 之前的工作仍然有对不可见类的过拟合
- 这归咎于解码器的不合理设计:解码器使用文本嵌入进行查询,不适合零样本任务。因为视觉空间相比文本并不足够结构化用于分割。
- 让文本嵌入对齐视觉嵌入,会造成较大的嵌入空间迁移,损害分割性能。
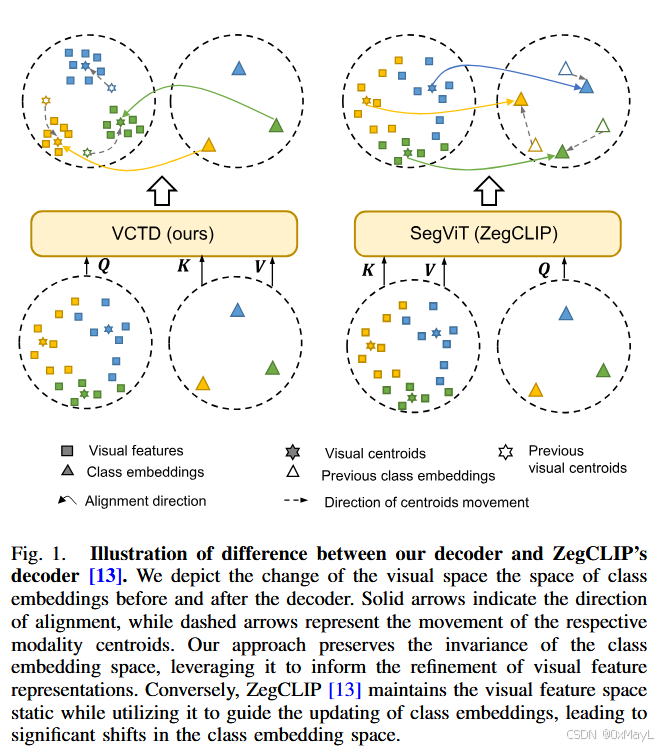

方法
视觉-语言提示
- 就是视觉和语义编码器中都引入了提示token
- 初始化时,视觉提示与VPT中的初始化形式一样
- 语言提示的初始化有点奇怪,每层文本编码器对于手工设计的提示语产生的嵌入用于初始化。
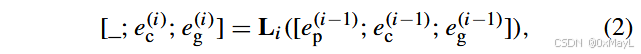

文本适配器
- 将关系描述符表达为文本适配器,与ZegCLIP完全一致,毫无区别
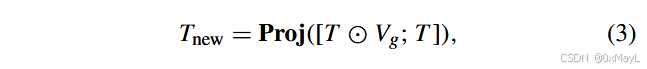
视觉共识解码器
总体流程
- VjV_jVj是视觉编码器中的某一层输出,
作者好像没有具体给出j的取值?


视觉共识自注意力
- 基于路由注意力的机制
- 简单来说就是关注图片中相关的区域,例如“草”的区域关注“草”的区域。
- 首先要对图像窗口化,然后计算注意力权重,保留权重高的窗口,还原得到高度相关的KsK_sKs和VsV_sVs(只有部分patch)
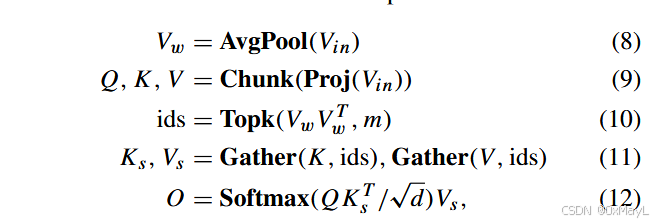
掩码产生机制
- 掩码产生机制几乎完全一样
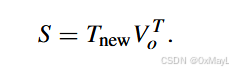
实验
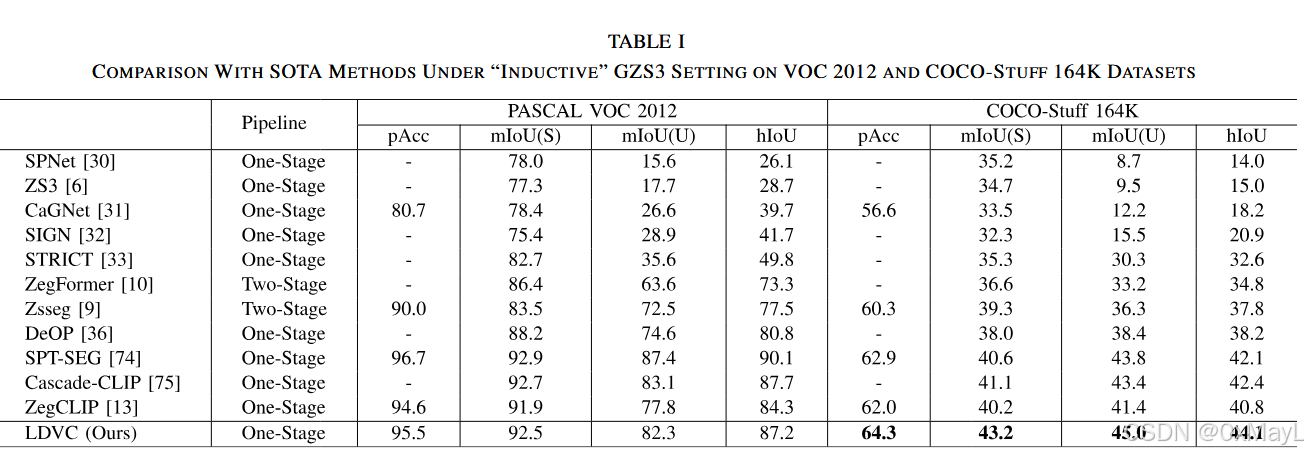
对比实验
- 在归纳设置下,可见类和不可见类都有一定提升
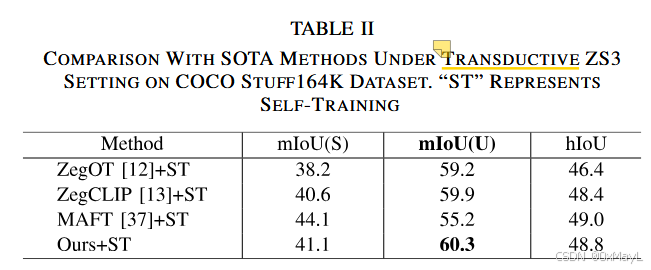
- 在转导设置下,几乎没有任何有效提升。
消融实验
- 交叉注意力图可以学习一下。