容器适配器、关联容器的相关算法题目
题目1
题目链接:155. 最小栈 - 力扣(LeetCode)
题目分析:
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
实现 MinStack 类:
- MinStack() 初始化堆栈对象。
- void push(int val) 将元素val推入堆栈。
- void pop() 删除堆栈顶部的元素。
- int top() 获取堆栈顶部的元素。
- int getMin() 获取堆栈中的最小元素。
提示:
-231 <= val <= 231 - 1pop、top和getMin操作总是在 非空栈 上调用push,pop,top, andgetMin最多被调用3 * 104次
由题目所描述的“能在常数时间内检索到最小元素的栈”,说明时间复杂度为O(1)。“pop、top 和 getMin 操作总是在非空栈上调用”说明在执行 pop,top,getMin 操作时,不需要考虑栈为空的情况。
题目框架:
class MinStack {
public:MinStack() {}void push(int val) {}void pop() {}int top() {}int getMin() {}
};题目示例:
输入: ["MinStack","push","push","push","getMin","pop","top","getMin"] [[],[-2],[0],[-3],[],[],[],[]]输出: [null,null,null,null,-3,null,0,-2]解释: MinStack minStack = new MinStack(); minStack.push(-2); minStack.push(0); minStack.push(-3); minStack.getMin(); --> 返回 -3. minStack.pop(); minStack.top(); --> 返回 0. minStack.getMin(); --> 返回 -2.
算法思路
普通思路:定义一个栈和一个变量 min ,min 来记录入栈的最小元素,如果新入栈的元素小于 min ,则更新 min。但是该思路存在缺陷,如果栈顶的元素即为栈的最小元素,使用 pop 出栈顶的元素,就需要更新栈的最小元素,也就需要遍历一遍栈,来找到最小元素,这样时间复杂度就为 O(N) 了。
最终思路:使用双栈,一个栈存正常数据(st栈),一个存最小值数据(minst栈)。如此一来,若想要获取栈的最小元素,在 minst 中找即可。将待入栈的元素与 minst 栈中的栈顶元素比较大小,判断是否能够插入 minst 栈中:若 stmin 栈为空,则直接插入;若 stmin 栈不为空:若插入的元素小于等于栈顶的元素,则插入;若插入的元素大于栈顶的元素,则不插入。
使用具体例子来说明:如要入栈的数据为 3,5,6,1。
•待插入的元素为 3 ,插入 st 栈后,判断是否可以入 minst 栈,首先判断 minst 栈是否为 空,为空,直接插入 minst 栈
•待插入的元素为 5,插入 st 栈后,判断 minst 栈是否空,不为空,与minst栈的栈顶元素比较,大于 3,不入 minst 栈
•待插入的元素为6,插入 st 栈后,判断 minst 栈是否空,不为空,与minst栈的栈顶元素比较,大于 3 ,不入 minst 栈
•待插入的元素为1,插入 st 栈后,判断 minst 栈是否空,不为空,与minst栈的栈顶元素比较,小于 3,入 minst 栈
具体步骤:
1. 定义两个栈(一个栈命名为 st ,一个栈命名为 minst)
2. 遍历栈,遍历过程中,最小的元素,插入 minst 栈
插入minst栈的逻辑:
若 minst 栈为空,则直接入栈
若 minst 栈不为空:
待插入的元素小于等于 minst 栈的栈顶元素,则入栈
待插入的元素大于 minst 栈的栈顶元素,则不入栈
删除栈的逻辑:
若删除的元素等于minst栈顶元素,则同时删除 st 和 minst
若删除的元素不等于minst栈顶的元素,则只删除 st
代码实现:
class MinStack {
public:MinStack() {}// MinStack 函数中不写内容也没关系,甚至都可以删除void push(int val) {// 直接入 st 栈_st.push(val);// 判断是否要入 minst 栈,先判断 minst 栈是否为空// minst 为空,则直接插入// minst 不为空,比较待插入的元素与 minst 的栈顶元素的大小// 如果待插入的元素小于等于 minst 栈顶元素,则入栈// 如果待插入的元素大于 minst 栈顶元素,则不入栈if(_minst.empty() || val <= _minst.top()){_minst.push(val);}}void pop() {// 判断待删除的元素是否与 minst 的栈顶元素相等// 相等,则删除 st 和 minst 的栈顶元素(不用判断 minst 栈是否为空)// 不相等,则删除 st 的栈顶元素if(_st.top() == _minst.top()){_minst.pop();}_st.pop();}int top() {// 直接取 st 的栈顶元素(不用判断 st 栈是否为空)return _st.top();}int getMin() {// 直接取 minst 的栈顶元素(不用判断 minst 栈是否为空)return _minst.top();}private:stack<int> _st; // 普通栈stack<int> _minst; // 最小栈
};/*** Your MinStack object will be instantiated and called as such:* MinStack* obj = new MinStack();* obj->push(val);* obj->pop();* int param_3 = obj->top();* int param_4 = obj->getMin();*/题目2
题目链接:栈的压入、弹出序列_牛客题霸_牛客网
题目分析:
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。
1. 0<=pushV.length == popV.length <=1000
2. -1000<=pushV[i]<=1000
3. pushV 的所有数字均不相同
题目框架:
class Solution {
public:/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param pushV int整型vector * @param popV int整型vector * @return bool布尔型*/bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {// write code here}
};题目示例:
题目示例:
示例1:
输入:
[1,2,3,4,5],[4,5,3,2,1]复制返回值:
true复制说明:
可以通过push(1)=>push(2)=>push(3)=>push(4)=>pop()=>push(5)=>pop()=>pop()=>pop()=>pop() 这样的顺序得到[4,5,3,2,1]这个序列,返回true示例2:
输入:
[1,2,3,4,5],[4,3,5,1,2]复制返回值:
false复制说明:
由于是[1,2,3,4,5]的压入顺序,[4,3,5,1,2]的弹出顺序,要求4,3,5必须在1,2前压入,且1,2不能弹出,但是这样压入的顺序,1又不能在2之前弹出,所以无法形成的,返回false
算法思路
不要试图找规律,输入的整数序列是无规律的。
我们可以模拟入栈出栈的操作,具体思路:定义一个栈 stack,定义两个变量 pushi 和 popi ,一个遍历 pushV 数组,一个遍历 popV 数组。等到 pushV 数组遍历完毕了,判断 stack 栈中的元素是否为空,若为空,则说明可以序列合法,返回 true ;若非空,则说明序列不合法,返回 false.
具体步骤:
1. 定义一个栈 st,定义两个变量:pushi 和 popi ,一个遍历 pushV 数组,一个遍历 popV 数组
2. pushi指向的数据入栈
3. 持续让 st 栈中的数据与 popi 指向的数据进行比较
若popi等于栈顶元素,则 popi++,出stack栈顶的元素,直到stack栈为空;或者 popi 与栈顶的元素不匹配
4. 重复1,2过程
5. 若 pushi 走到尾,则停止1,2过程;若 st 栈为空,则说明合法;反之,不合法
代码实现:
class Solution {
public:/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param pushV int整型vector * @param popV int整型vector * @return bool布尔型*/bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {// 定义一个栈stack<int> st;// 定义两个变量 pushi 和 popi// pushi 遍历 pushV 栈; popi 遍历 popV 栈int pushi = 0, popi = 0;// pushi 走到尾,停止匹配while(pushi < pushV.size()){// pushi的元素入栈st.push(pushV[pushi++]);// 让st的栈顶元素与popi指向的数据比较// 若popi等于栈顶元素,则 popi++,出stack栈顶的元素// 直到stack栈为空,或者 popi 与栈顶的元素不匹配while(!st.empty() && popV[popi] == st.top()){popi++;st.pop();}}// 若st栈为空,则说明合法,返回true; 反之,不合法,返回falsereturn st.empty();}
};题目3
题目链接:150. 逆波兰表达式求值 - 力扣(LeetCode)
题目分析:
给你一个字符串数组
tokens,表示一个根据 逆波兰表示法 表示的算术表达式。请你计算该表达式。返回一个表示表达式值的整数。
注意:
- 有效的算符为
'+'、'-'、'*'和'/'。- 每个操作数(运算对象)都可以是一个整数或者另一个表达式。
- 两个整数之间的除法总是 向零截断 。
- 表达式中不含除零运算。
- 输入是一个根据逆波兰表示法表示的算术表达式。
- 答案及所有中间计算结果可以用 32 位 整数表示。
逆波兰表达式:
逆波兰表达式是一种后缀表达式,所谓后缀就是指算符写在后面。
- 平常使用的算式则是一种中缀表达式,如
( 1 + 2 ) * ( 3 + 4 )。- 该算式的逆波兰表达式写法为
( ( 1 2 + ) ( 3 4 + ) * )。逆波兰表达式主要有以下两个优点:
- 去掉括号后表达式无歧义,上式即便写成
1 2 + 3 4 + *也可以依据次序计算出正确结果。- 适合用栈操作运算:遇到数字则入栈;遇到算符则取出栈顶两个数字进行计算,并将结果压入栈中
逆波兰表达式也被称为后缀表达式,我们平常使用的都是中缀表达式。后缀表达式的特点:运算符按优先级排列,并且要紧挨着执行运算符的运算数。来理解后缀表达式的运算,中缀表达式 1 + 2 * (3 – 4) 转化为后缀表达式 1 2 3 4 - * + ;中缀表达式 1 + (2 – 3) * 4 - 5 转化为后缀表达式 1 2 3 – 4 * + 5 –(- 紧挨着运算数2和3,* 紧挨着2和3运算的结果和4,+ 紧挨着前面运算结果与 1 ,- 紧挨着前面运算结果与5)。
题目框架:
class Solution {
public:/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param pushV int整型vector * @param popV int整型vector * @return bool布尔型*/bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {// write code here}
};题目示例:
示例 1:
输入:tokens = ["2","1","+","3","*"] 输出:9 解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9示例 2:
输入:tokens = ["4","13","5","/","+"] 输出:6 解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6示例 3:
输入:tokens = ["10","6","9","3","+","-11","*","/","*","17","+","5","+"] 输出:22 解释:该算式转化为常见的中缀算术表达式为:((10 * (6 / ((9 + 3) * -11))) + 17) + 5 = ((10 * (6 / (12 * -11))) + 17) + 5 = ((10 * (6 / -132)) + 17) + 5 = ((10 * 0) + 17) + 5 = (0 + 17) + 5 = 17 + 5 = 22
算法思路
具体步骤:
1. 遍历 tokens,使用 stack 容器
2. 遇到运算数,入栈;遇到运算符,出栈顶的两个数据运算,运算结果继续入栈
(注意:先出栈的元素是右操作数,后出栈的元素是左操作数)
3. 遍历结束,栈顶的元素就是运算的最终结果
代码实现:
class Solution {
public:/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param pushV int整型vector * @param popV int整型vector * @return bool布尔型*/bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {// 定义一个栈stack<int> st;// 定义两个变量 pushi 和 popi// pushi 遍历 pushV 栈; popi 遍历 popV 栈int pushi = 0, popi = 0;// pushi 走到尾,停止匹配while(pushi < pushV.size()){// pushi的元素入栈st.push(pushV[pushi++]);// 让st的栈顶元素与popi指向的数据比较// 若popi等于栈顶元素,则 popi++,出st栈顶的元素// 直到st栈为空,或者 popi 与栈顶的元素不匹配while(!st.empty() && popV[popi] == st.top()){popi++;st.pop();}}// 若st栈为空,则说明合法,返回true; 反之,不合法,返回falsereturn st.empty();}
};题目4
题目链接:102. 二叉树的层序遍历 - 力扣(LeetCode)
题目分析:
给你二叉树的根节点
root,返回其节点值的 层序遍历 。(即逐层地,从左到右访问所有节点)
题目框架:
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {}
};返回值类型为vector<vector<int>>。
题目示例:
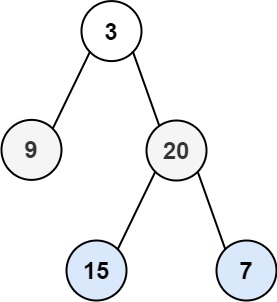
示例 1:
输入:root = [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]]示例 2:
输入:root = [1] 输出:[[1]]示例 3:
输入:root = [] 输出:[]
示例分析:
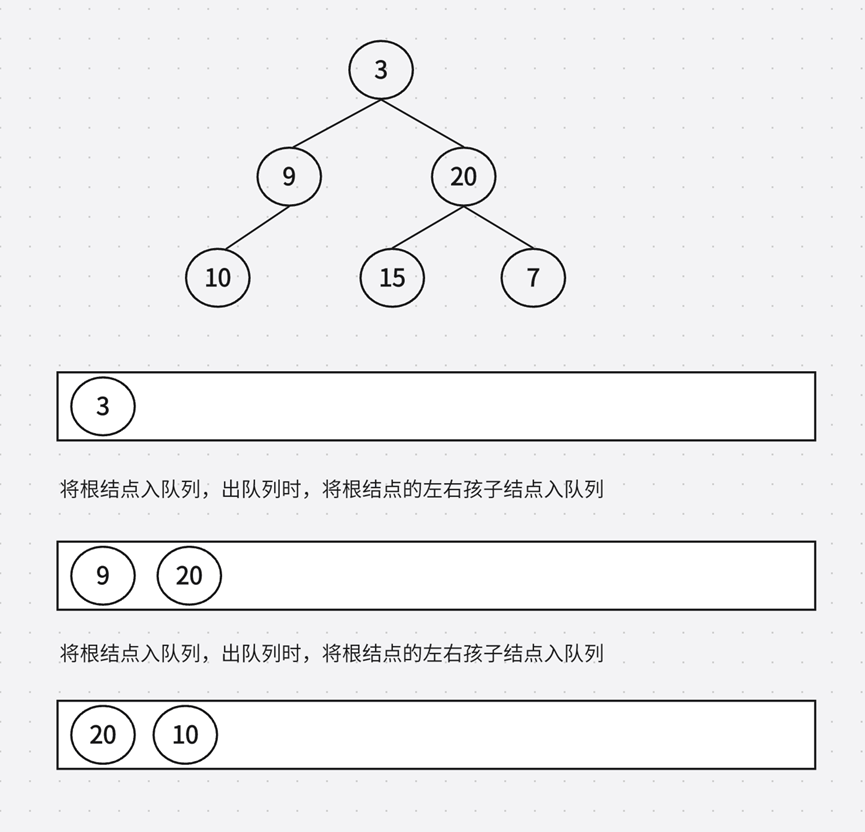
如此一来,队列中就同时含有不同层数的结点,这样处理起来就很复杂了。因为题目返回的是vector<vector<int>>也就是二维数组,每一层的结点在一个数组中,如果只有一个队列,且队列中同时含有不同层数的结点,很难分组。
算法思路:使用单队列和一个变量
具体步骤:
定义一个队列和一个变量 levelSize,变量 levelSize 用来获取当前层有多少个数据
1. 若根结点不为空,则将 root 结点入队列,此时当前层只有一个数据,即 levelSize = 1
2. 只要队列不为空,就一直入队列和出对列,设置循环,每次出一层的数据,一层一层的出,当前层数的数据出完之后,再出下一层的
1. 在出数据的同时,将出的数据存储在一维数组 v 中
2. 若出的结点的左右孩子不为空,则入队列
3. 当前层数出完之后,计算下一层结点的个数,而当前队列中的元素个数,就是下一层结点的个数,使用 size 函数就可以获取
4. 将每一层存储的数据,存在二维数组 vv 中;返回 vv
代码实现:时间复杂度为O(N)
/*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left),* right(right) {}* };*/
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) { // 定义一个队列和一个变量queue<TreeNode*> q;int levelSize = 0;// 若根结点不为空if(root){// 入队列q.push(root);// 当前层数有一个结点levelSize = 1; }// 返回值vector<vector<int>> vv;// 队列不为空while(!q.empty()){// 存一层的数据vector<int> v;// 控制一层一层出while(levelSize--){// 取队头数据TreeNode* front = q.front();// 出队头的数据q.pop();// 存到一维数组 v 中v.push_back(front->val);// 将根结点的左右结点入队列(前提结点不为空)if(front->left) { q.push(front->left); }if(front->right) { q.push(front->right); }}// 更新levelSize,刚入队列了几个元素,那层就有几个元素levelSize = q.size();// 将每层存储的数据存到二维数组中vv.push_back(v);}// 返回返回值return vv;}
};题目5
题目链接:215. 数组中的第K个最大元素 - 力扣(LeetCode)
题目分析:
给定整数数组
nums和整数k,请返回数组中第k个最大的元素。请注意,你需要找的是数组排序后的第
k个最大的元素,而不是第k个不同的元素。你必须设计并实现时间复杂度为
O(n)的算法解决此问题
题目框架:
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {}
};题目示例:
示例 1:
输入:[3,2,1,5,6,4],k = 2 输出: 5示例 2:
输入:[3,2,3,1,2,4,5,5,6],k = 4 输出: 4
算法思路:使用优先级队列
将数组 nums 的数据存储在优先级队列中,优先级对列默认是大堆,pop 前 k-1 次堆顶的数据后,此时堆顶的数据就是第 K 大的元素。
代码实现:
class Solution {
public:int findKthLargest(vector<int>& nums, int k) {// 使用迭代器区间构造优先队列priority_queue<int> pq(nums.begin(), nums.end());// 默认是大堆,循环取k-1次堆顶的元素,出循环后堆顶就是第K大的元素while(--k){pq.pop();}// 取堆顶的元素return pq.top();}
};
题目6
题目链接:142. 环形链表 II - 力扣(LeetCode)
题目分析:
给定一个链表的头节点
head,返回链表开始入环的第一个节点。 如果链表无环,则返回null。如果链表中有某个节点,可以通过连续跟踪
next指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数pos来表示链表尾连接到链表中的位置(索引从 0 开始)。如果pos是-1,则在该链表中没有环。注意:pos不作为参数进行传递,仅仅是为了标识链表的实际情况。不允许修改 链表
总结题目的要求:判断链表是否有环,若有环,返回环的入口点;如无环,返回空指针
题目框架:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/
class Solution {
public:ListNode *detectCycle(ListNode *head) {}
};题目示例:
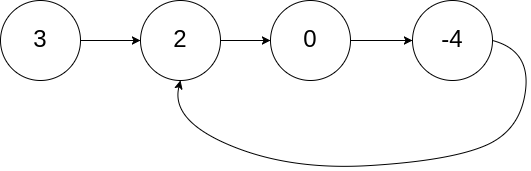
示例 1:
输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。示例 2:
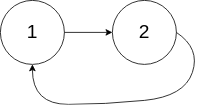
输入:head = [1,2], pos = 0 输出:返回索引为 0 的链表节点 解释:链表中有一个环,其尾部连接到第一个节点。示例 3:
输入:head = [1], pos = -1 输出:返回 null 解释:链表中没有环。

算法思路
思路1:快慢指针
具体步骤:
1. 快指针走两步,慢指针走一步
2. 若有环,快慢指针终会相遇,相遇后,寻找入环点
3. 定义一个指针 cur 指向链表的开头,让 cur 不断的向后移动,slow 也在环中移动
当 cur == slow 时,此时 cur 指向的位置就是入环点
详细的分析看博客:设置循环队列与随机链表的复制(C)_c语言 复制队列-CSDN博客
代码实现:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/
class Solution {
public:ListNode *detectCycle(ListNode *head) {//快慢指针ListNode* slow = head; // 慢指针ListNode* fast = head; // 快指针// 快指针若等于null了,说明没有环// 判断 fast->next 是否为空是解决只有一个结点情况while(fast && fast->next){slow = slow->next; // 慢指针走一步fast = fast->next->next; // 快指针走两步// 快慢指针相遇了,开始找入环点if(slow == fast){// 定义一个指针pcur从链表的开始位置走ListNode* pcur = head;// 当 pcur 和 slow 相等时,此时它们指向的位置就是入环点while(pcur != slow){pcur = pcur->next;slow = slow->next;}return pcur;}}return nullptr;}
};思路2:使用容器set
具体步骤:
1. 实例化容器 set 对象 s
2. 遍历链表,判断链表上的每个结点是否在 s 中,不在就插入,在的第一个点就是入环点
所有结点都不再插入了,链表结束了,就说明不带环
代码实现:
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode(int x) : val(x), next(NULL) {}* };*/
class Solution {
public:ListNode *detectCycle(ListNode *head) {set<ListNode*> s;// 定义一个指针遍历链表ListNode* cur = head;while(cur){// 使用了 pair<iterator,bool> insert (const value_type& val)// pair<iterator, bool> 是 C++ 标准库中一个常见的返回类型// first: 迭代器 (iterator) second: 布尔值 (bool)// 若插入的元素,s中不存在,会将bool设置为true// 若插入的元素,s中存在,会将bool设置为false// 按照这样特性,如果是带环的链表,入环点已经存在s中了// 当它再次插入对象s中时,bool值设置成flaseauto ret = s.insert(cur);if(ret.second == false){return cur;}// 向后移动cur = cur->next;}return nullptr;}
};题目7
题目链接:349. 两个数组的交集 - 力扣(LeetCode)
题目分析:
给定两个数组
nums1和nums2,返回 它们的 交集 。输出结果中的每个元素一定是 唯一 的。我们可以 不考虑输出结果的顺序 。
题目框架:
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {}
};返回值类型为 vector<int>.
题目示例:
示例 1:
输入:nums1 = [1,2,2,1], nums2 = [2,2] 输出:[2]示例 2:
输入:nums1 = [4,9,5], nums2 = [9,4,9,8,4] 输出:[9,4] 解释:[4,9] 也是可通过的
算法思路
思路1:使用set容器
具体步骤:
1. 使用 set 容器存储 nums1 和 nums2 的元素,并且完成去重
2. 遍历 s1,在 s2 中查找与 s1 相等的元素,相等的元素存在返回值中
代码实现:时间复杂度O(N)
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {// 去重set<int> s1(nums1.begin(), nums1.end());set<int> s2(nums2.begin(), nums2.end());// 返回值vector<int> ret;// 遍历s1,在s2中找与s1相等的元素for(auto& e : s1){// 若对象s2中存在e,count函数会返回1,说明e就是交集元素// 将该元素插入到返回值中if(s2.count(e)){ret.push_back(e);}}return ret;}
};思路2:使用 set 容器和双指针
对于找两个数组的交集和并集的题目具体思路如下:
Nums1:[ 1,2,5,7,8 ] nums2:[ 2,3,5,8,9 ]
定义两个变量 it1 和 it2,it1 遍历 nums1,it2 遍历 nums2
找两个数组的交集步骤:
1. it1 和 it2 比较,小的++
2. 相等就是交集,it1 和 it2 都++
找两个数组的差集步骤:
1. It1 和 it2 比较,小的就是差集,小的++
2. 相等,it1 和 it2 都++
3. 一个数组遍历结束了,剩下还没结束的数组中的剩余元素都是差集
代码实现:时间复杂度O(N)
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {// 使用容器 set set<int> s1(nums1.begin(), nums1.end());set<int> s2(nums2.begin(), nums2.end());// 定义两个指针auto it1 = s1.begin(); // 遍历s1auto it2 = s2.begin(); // 遍历s2// 返回值vector<int> v;// 循环遍历nums1和nums2while(it1 != s1.end() && it2 != s2.end()){// 谁小谁++// it1 小于 it2,it1++if(*it1 < *it2) { it1++; }// it2 小于 it1,it2++else if(*it1 > *it2) { it2++; }// 相等就是交集else{v.push_back(*it1);// 相等都++it1++;it2++;}}return v;}
};题目8
题目链接:692. 前K个高频单词 - 力扣(LeetCode)
题目分析:
给定一个单词列表
words和一个整数k,返回前k个出现次数最多的单词。返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序
“返回的答案应该按单词出现频率由高到低排序”需要统计单词出现的次数,如果不同的单词出现的次数相同,需要按照 ASCII 码值排序。如 sort 和 string 出现的次数相同,sort 排在 string 的前面。
题目框架:
class Solution {
public:vector<string> topKFrequent(vector<string>& words, int k) {}
};返回值类型为 vector<string>.
题目示例:
示例 1:
输入: words = ["i", "love", "leetcode", "i", "love", "coding"], k = 2 输出: ["i", "love"] 解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。注意,按字母顺序 "i" 在 "love" 之前。示例 2:
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4 输出: ["the", "is", "sunny", "day"] 解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,出现次数依次为 4, 3, 2 和 1 次。
算法思路:使用 map 容器和 sort 函数
分析:找最大元素会自然想到排序
遍历单词列表,使用operator[ ] 函数统计每个单词出现的次数。sort 函数只支持传随即迭代器,map 容器的迭代器类型为双向迭代器,为了可以使用 sort 函数,可以将 map 容器中的数据转存到vector 容器中,数据类型为 pair<string, int> 类型。再使用sort排序,sort 默认排的是升序,我们要求排降序,获得前 k 个出现次数最多的单词;并且sort排序的数据类型是pair类型,pair 支持比较大小吗?支持比较大小。在这里我们期望按照频率比较大小,也就是 value 值,所以需要自己实现仿函数控制比较逻辑。排序完毕后,将vector容器中前k个的pair类型的数据的first存储在返回值中。
具体步骤:
使用map容器,实例化 map 对象 countMap
1 遍历单词序,使用 [ ] 统计单词出现的频率
2 将 countMap 中的数据转存到 vector 对象 v 中
3 使用sort函数排序,自己实现仿函数的比较逻辑
4 取对象 v 的前 k 个数据的 first 存储在返回值中
细节注意:
vector 容器中的数据类型为 pair<string, int>
代码通过的关键就是仿函数中实现的比较逻辑:
当 second 不相等时,按 second 排序;若 second 相等时,按 first 排序
代码实现:时间复杂度为O(logN)
class Solution {
public:// 仿函数struct Compare{bool operator()(const pair<string, int>& kv1, const pair<string, int>& kv2){// 降序// 若second不相等,按second排序,且second大的在前面,比较使用大于// 若second相等,按first排序,且first小的在前面,比较使用小于return kv1.second == kv2.second ? kv1.first < kv2.first : kv1.second > kv2.second;}};vector<string> topKFrequent(vector<string>& words, int k) {// 使用map容器,遍历结果默认是按照value排序的map<string, int> countMap;// 遍历单词列表,使用operator[ ]函数统计单词出现的次数for(auto& str : words){countMap[str]++;}// 将map容器中的数据转存到vector容器中// vector中的数据类型为pair<string, int>类型// 使用迭代器区间初始化vector<pair<string, int>> v(countMap.begin(), countMap.end());// 排序,按照单词出现的频率比较// 自己实现仿函数控制比较大小逻辑sort(v.begin(), v.end(), Compare());// 返回值,存的是stringvector<string> ret;// 取前k个数据for(int i = 0; i < k; i++){// 返回值类型为vector<string>// ret 中存的数据是 string 类型的,也就是firstret.push_back(v[i].first);}return ret;}
};