OCR的“文艺复兴”:实测登顶HuggingFace的PaddleOCR-VL与DeepSeek-OCR
OCR的“文艺复兴”:实测登顶HuggingFace的PaddleOCR-VL与DeepSeek-OCR
- 写在最前面
- 一、 目标对比:一个“压缩理论”,一个“识别SOTA”
- 二、 性能对决:权威榜单看数据
- 三、 架构浅析:PaddleOCR-VL为什么这么能打?
- 四、 实战测试:极限场景见真章
- 五、 为什么OCR突然又火了?
- 六、 总结:SOTA与实用,两种路径的选择
- 七、参考文献

写在最前面
版权声明:本文为原创,遵循 CC 4.0 BY-SA 协议。转载请注明出处。
最近我的Hugging Face首页快被OCR给刷屏了。
一个月内,DeepSeek、百度、上海AILab三家接连发了新模型。10月21号那天,HuggingFace趋势榜前三全是OCR:百度飞桨的PaddleOCR-VL第一(而且是连续5天霸榜),Deepseek-OCR第二。这热度简直是“文艺复兴”。
这让我很感兴趣,扒了扒两边的技术报告和Demo,发现这俩模型虽然都带“OCR”,但解决问题的思路是两个方向。
一、 目标对比:一个“压缩理论”,一个“识别SOTA”
首先得把概念搞清楚,不然就是“关公战秦琼”。
PaddleOCR-VL: 它的目标非常明确,就是要做“SOTA”(State-of-the-Art)的文档解析与识别。它是一个专门的多模态文档解析模型,目标是解决产业界里最头疼的各种文档处理问题,比如财报、合同、手写体、公式等等。它的目标是实用价值,要做“实用最强”。
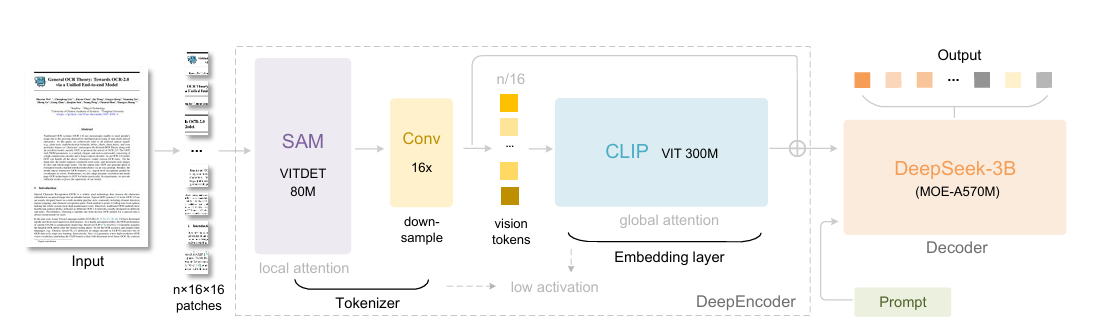
DeepSeek-OCR: 它的核心不是做OCR识别,而是探索一个叫“上下文光学压缩”(Contextual Optical Compression)的理论。简单说,它想解决的是LLM处理长文本时计算量爆炸的问题。DeepSeek的思路很新奇:先把文本渲染成图像,再用一个VL模型去“读取”这个图像,以此实现对上下文的高效压缩。这是一个很有意思的理论创新,目标是LLM的效率。
所以,DeepSeek是在探索“LLM的新输入方式”,而PaddleOCR-VL是在攻坚“如何把文档解析与识别做到极致”。
二、 性能对决:权威榜单看数据
虽然目标不同,但既然都叫OCR,总得在同一个“考场”上比一比。目前国际上最权威的文档理解基准之一是OmniDocBench V1.5。这个基准由清华、达摩院、上海AI Lab等多家机构共建,覆盖了教材、财报、手写笔记等9大类真实场景,是公认的“地狱难度”考卷。
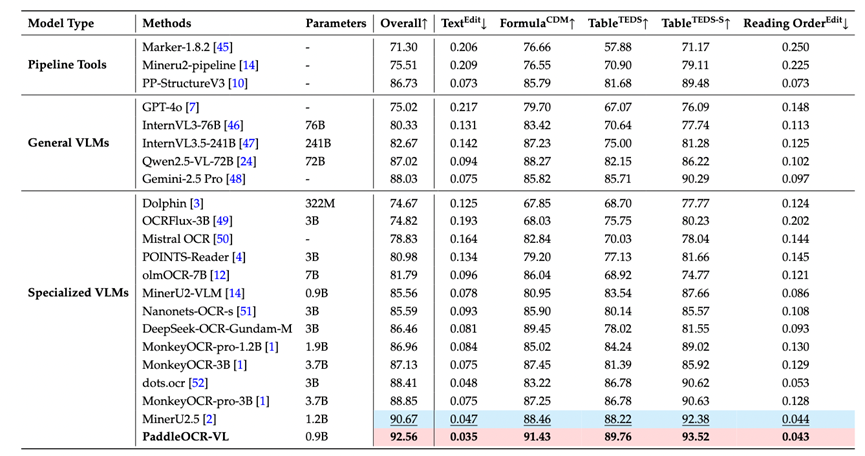
在V1.5最新榜单上,数据很直观:
综合得分:PaddleOCR-VL 以仅 0.9B 的参数量,拿到了92.56分,位居全球第一。DeepSeek-OCR-Gundam-M(3B参数)得分是86.46。参数量小了3倍多,分数反而高了6.1分。
核心能力拆解:在文档解析的四大核心任务上,PaddleOCR-VL实现了全线SOTA。
表格结构理解 (Table TEDS):这是差距最大的地方。PaddleOCR-VL得分93.52,DeepSeek-OCR是78.02,领先了15.5分。这说明在还原复杂表格结构上,PaddleOCR-VL的优势是压倒性的。
表格语义理解 (Table TEDS-S):PaddleOCR-VL得分91.43,DeepSeek-OCR是81.55,领先近10分。
阅读顺序 (Reading Order) :PaddleOCR-VL的误差(0.043)比DeepSeek-OCR(0.093)降低了约54% ,这意味着它解析出的文档顺序更符合人类逻辑。
公式识别 (Formula CDM) :PaddleOCR-VL(89.76)也略高于DeepSeek-OCR(89.45)。
这个数据说明了一切。特别是在表格和阅读顺序上的巨大领先,意味着PaddleOCR-VL对“版面”的理解远超对手。这在金融财报、合同审计等场景是刚需。
顺带一提,DeepSeek论文里用的是V1.0旧考卷,PaddleOCR-VL用的是V1.5新考卷的成绩,含金量更高。
三、 架构浅析:PaddleOCR-VL为什么这么能打?
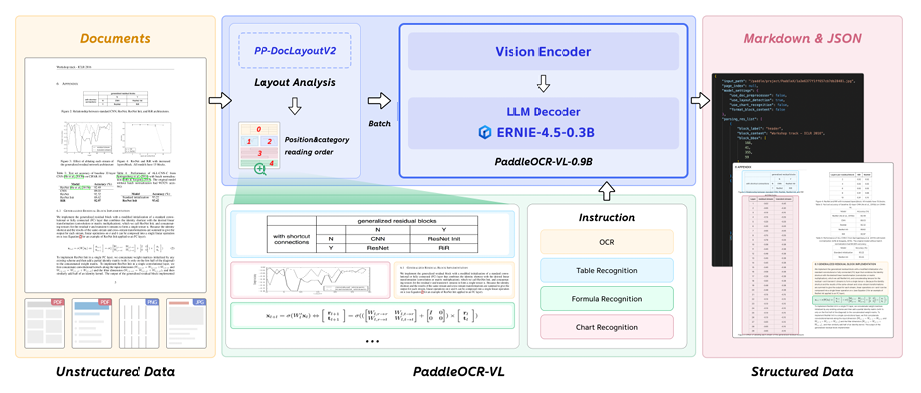
0.9B的小模型反超3B的大模型,这在技术上是很有意思的。我看了下技术报告,PaddleOCR-VL的架构设计非常“务实”:
它采用了一种两阶段混合式架构。
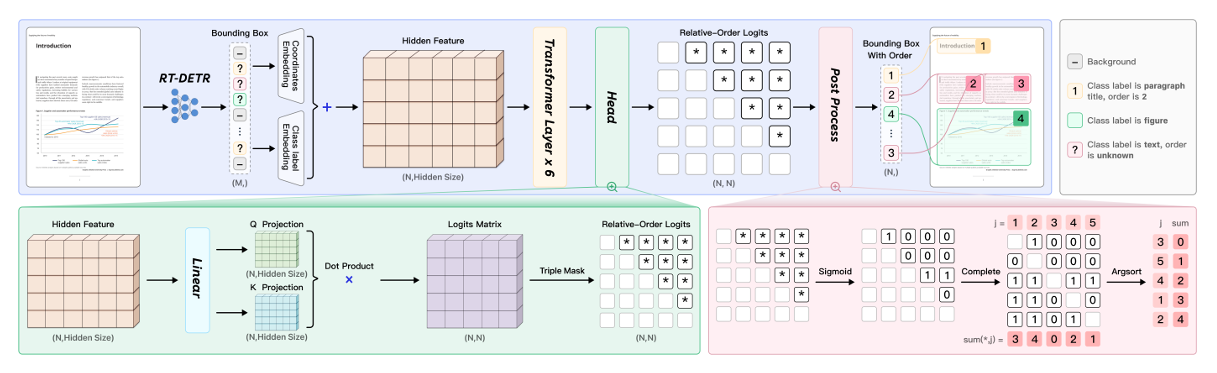
第一阶段: 用一个高精度的版面分析模型(PP-DocLayoutV2)先去执行版面分析(layout analysis),把文档中的标题、正文、表格等区域定位出来,并预测好阅读顺序。
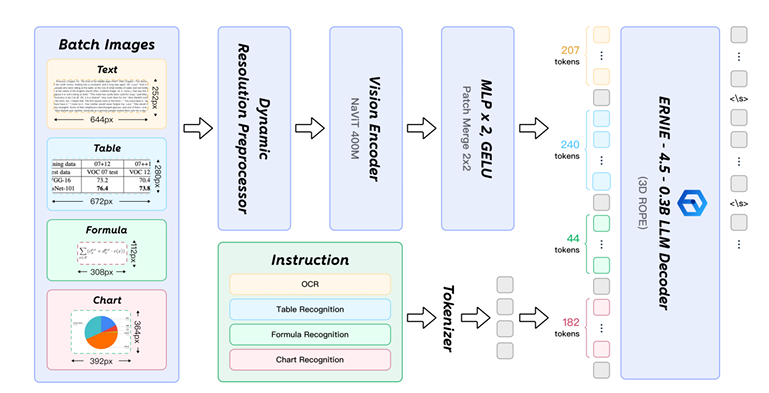
第二阶段: 再用那个0.9B的PaddleOCR-VL-0.9B模型,基于上一步的版面结果,对文本、表格、公式等内容进行细粒度识别。
这种“专业的人做专业的事”(版面分析+内容识别)的管线设计,确保了它在处理复杂版面时的精准度,也解释了为什么它在表格和阅读顺序上得分那么高。此外,它还对手写、公式等做了专项优化,甚至能把图表(Chart)直接转成表格(Table),并且支持109种语言,这完全是为产业落地而生的。
四、 实战测试:极限场景见真章
跑分是跑分,但技术圈更信奉“Talk is cheap, show me the code (and demo)”。我用了几个自己找的“奇葩”案例,在两家的Online Demo上跑了一下。
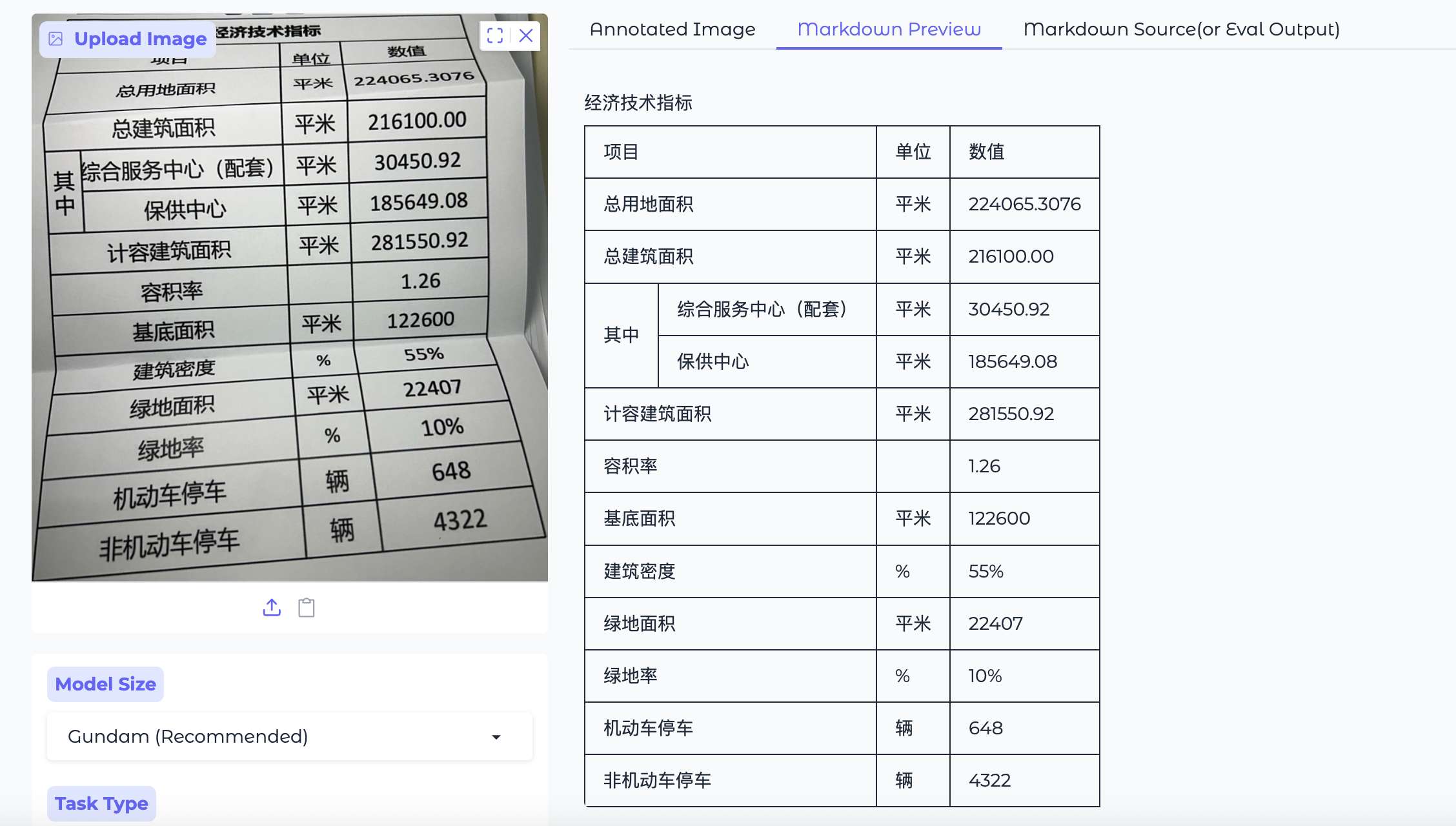
测试1:打印表格的照片
场景: 这是最常见的RPA(机器人流程自动化)场景,比如拍一张纸质报表。
PaddleOCR-VL: 精准识别。完美还原了表格的行列结构,表头和数据都各归其位。
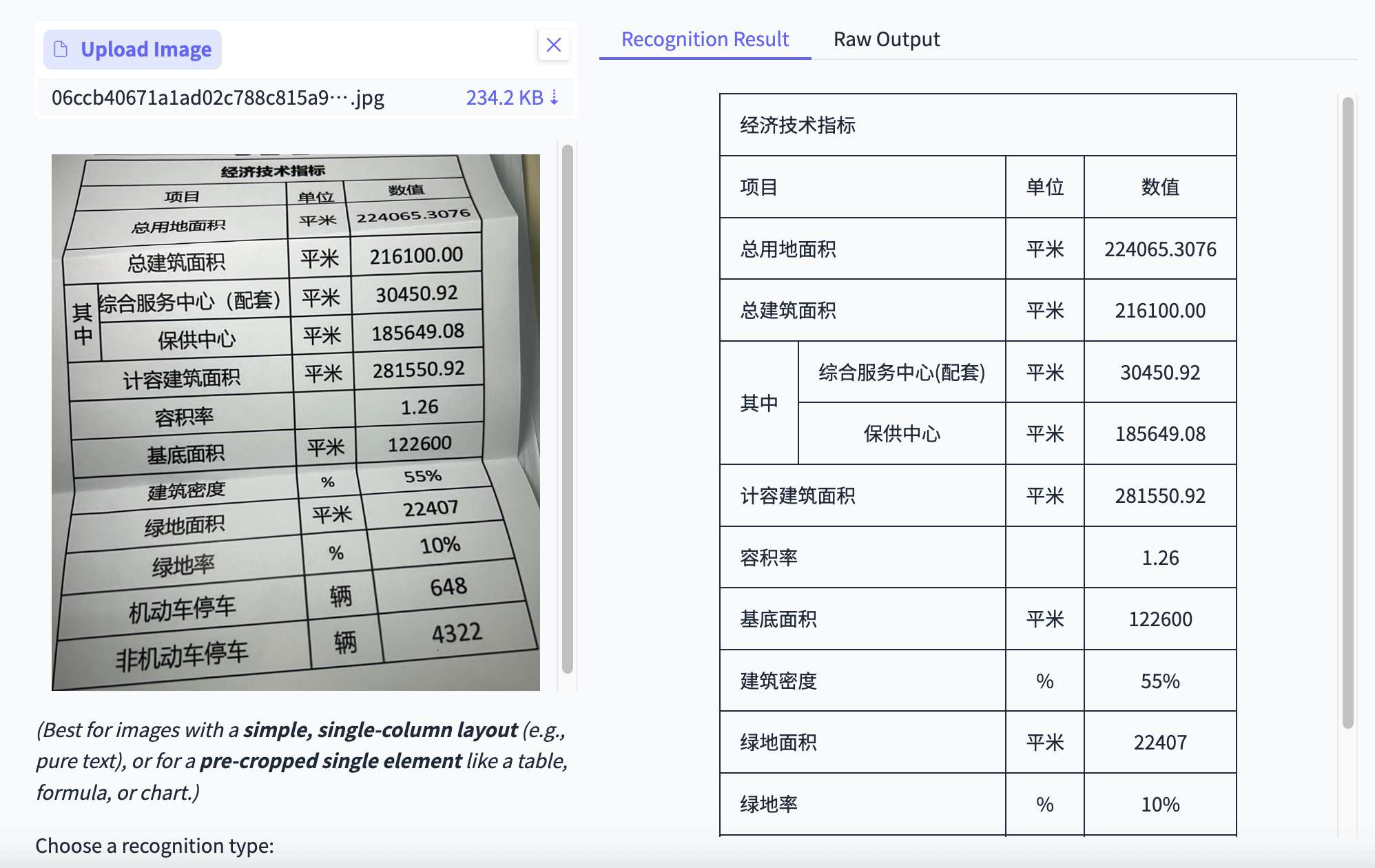
Deepseek-OCR: 识别出了图中的所有文字,但没有生成表格。表头那段文字被当成普通文本混在了结果里,表格结构丢失。
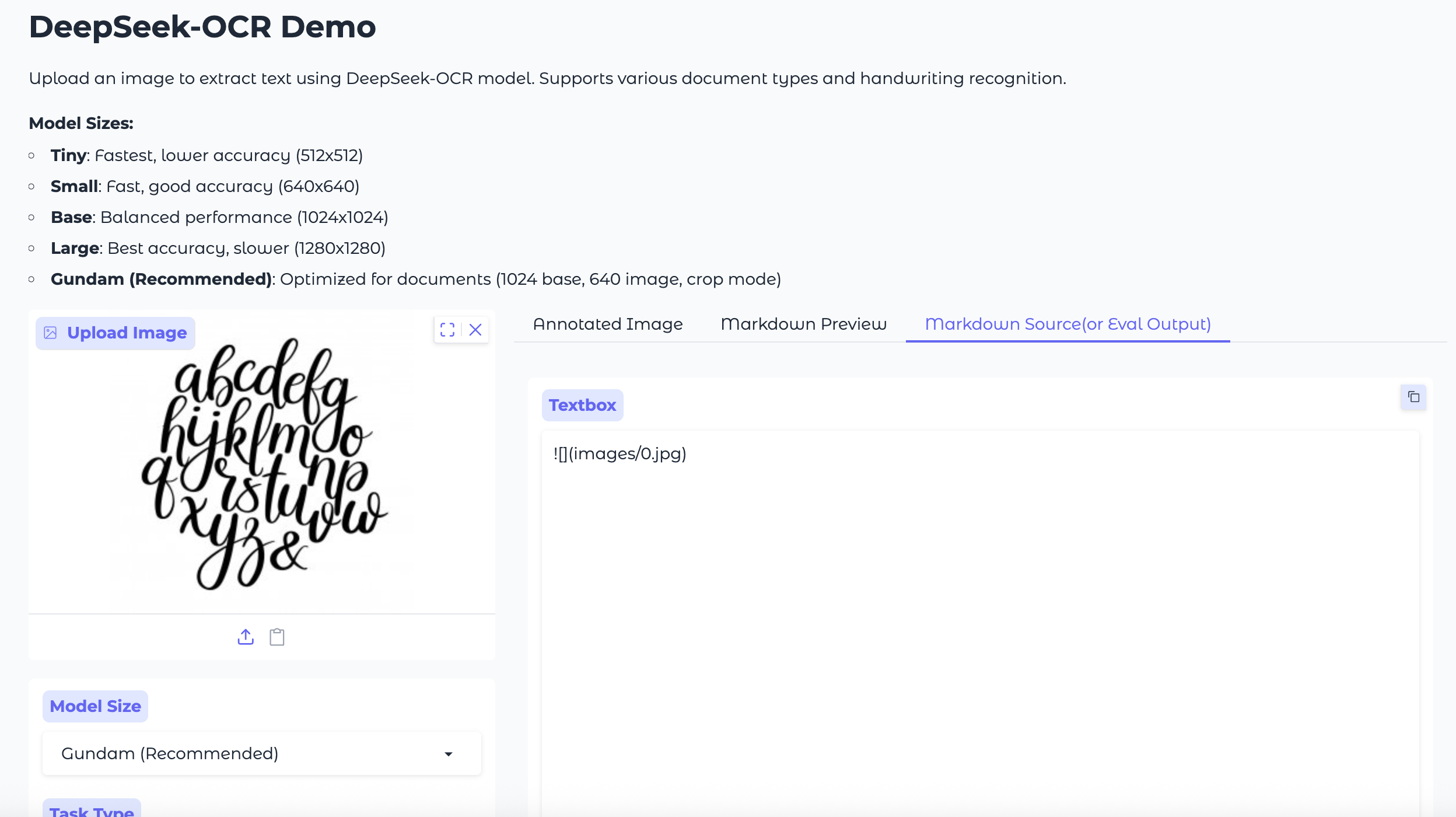
测试2:花体艺术字英文
场景: 识别海报、Logo上的艺术字。
PaddleOCR-VL: 精准识别,连最后那个花体的“&”符号都认出来了。
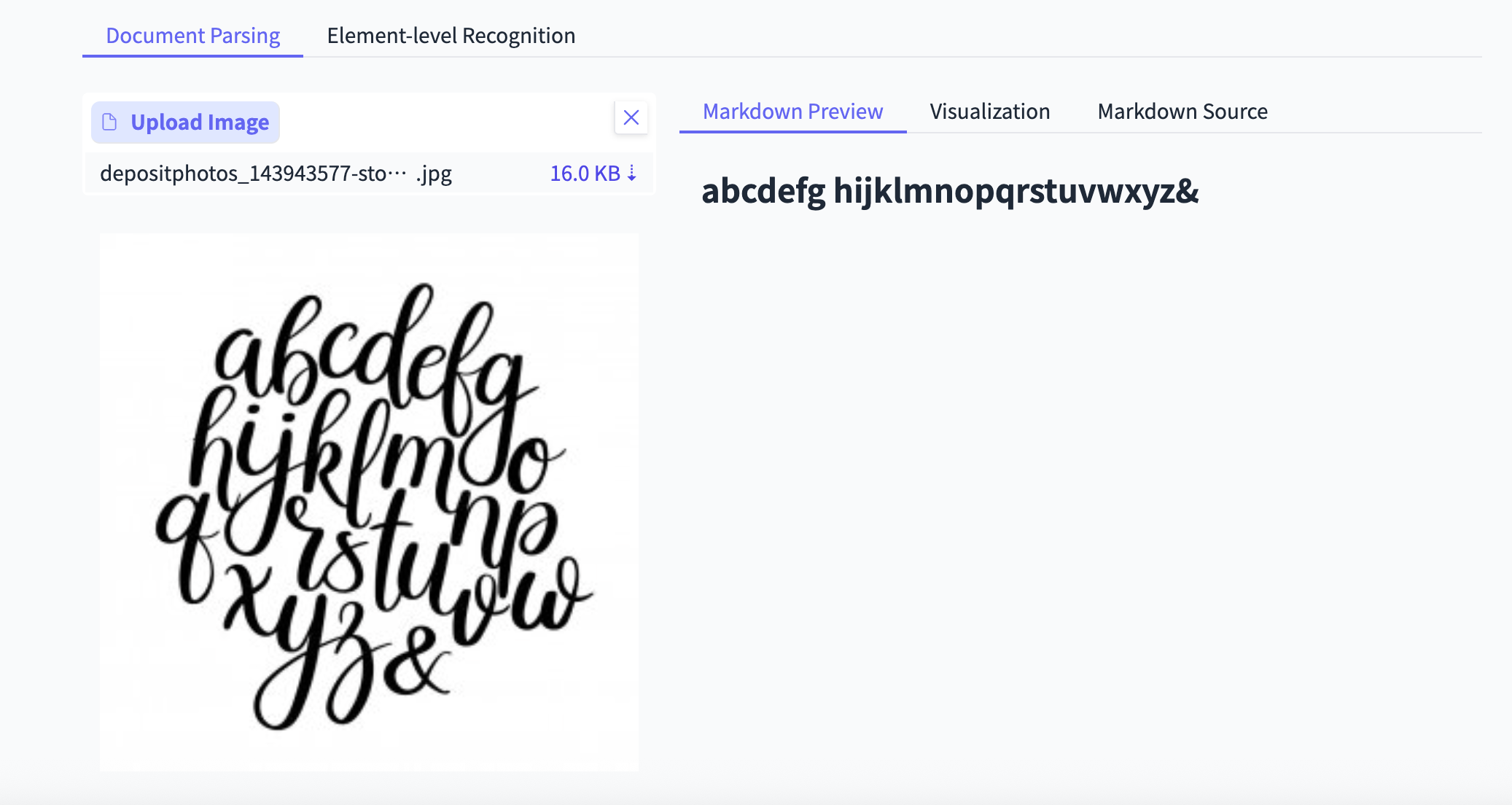
Deepseek-OCR: 识别不出任何内容,返回为空。
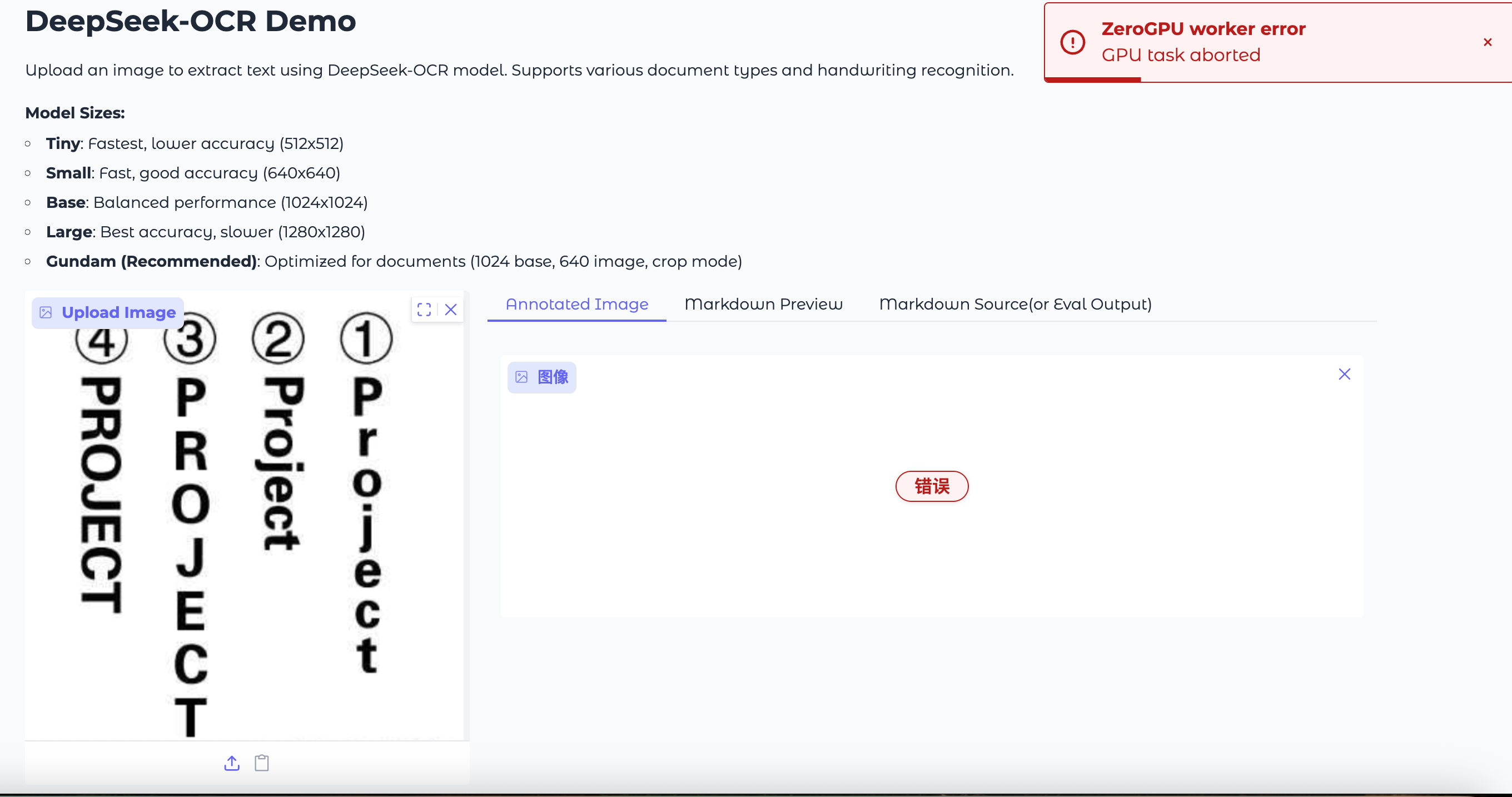
测试3:特殊竖排英文(含圆圈数字)
场景: 一些设计独特的说明书或菜单。
PaddleOCR-VL: 再次精准识别。竖排的英文(含大小写)全部正确,连旁边被圆圈包着的数字也没放过。
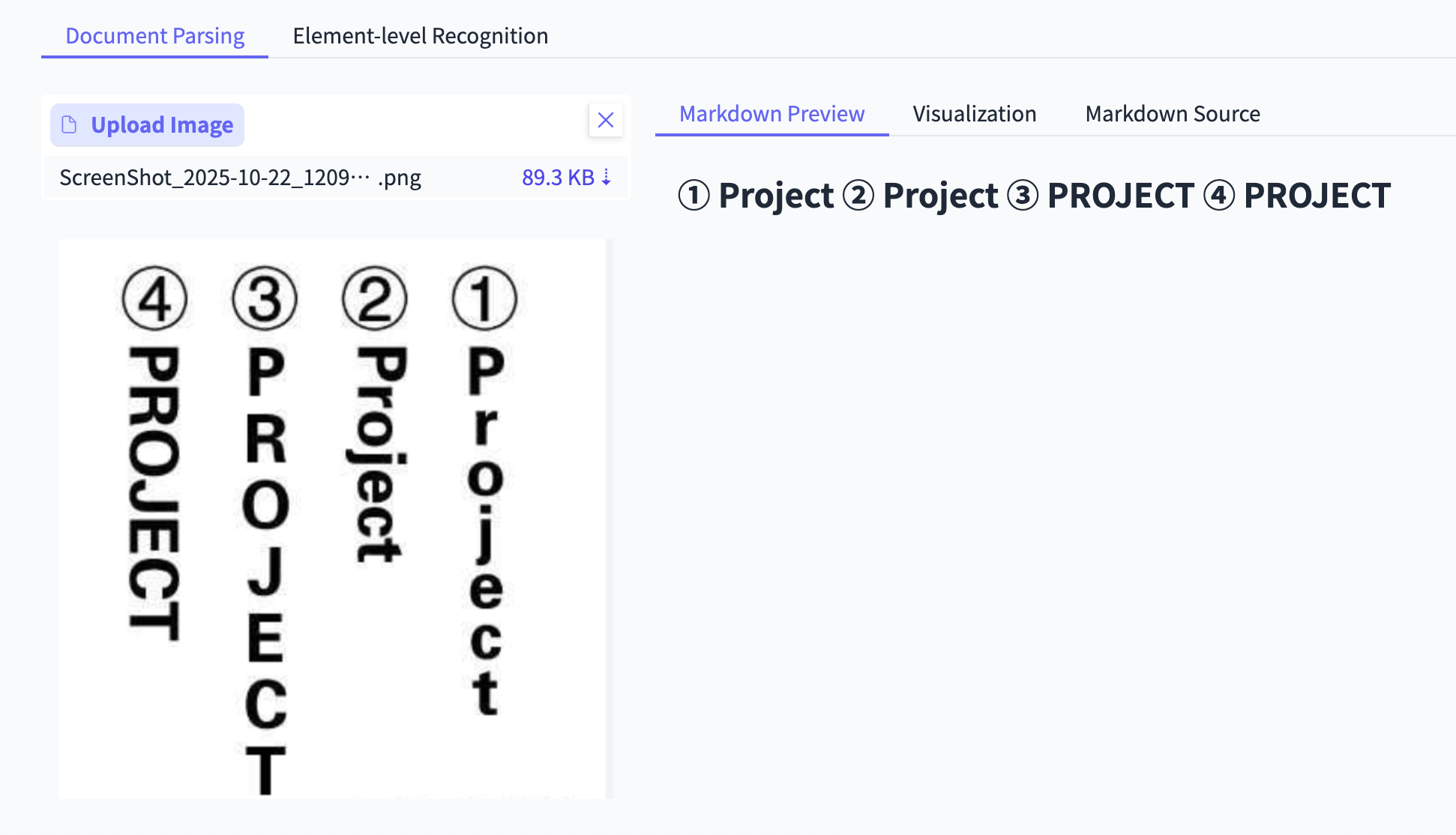
Deepseek-OCR: 报错。
测试4:极限场景-餐厅招牌
场景: 一张“熟成刺身招牌”的照片,光线复杂,且文字不是主体。
PaddleOCR-VL: 我试了它的“Chart Recognition”(图表识别)能力,居然识别出了部分招牌上的文字。
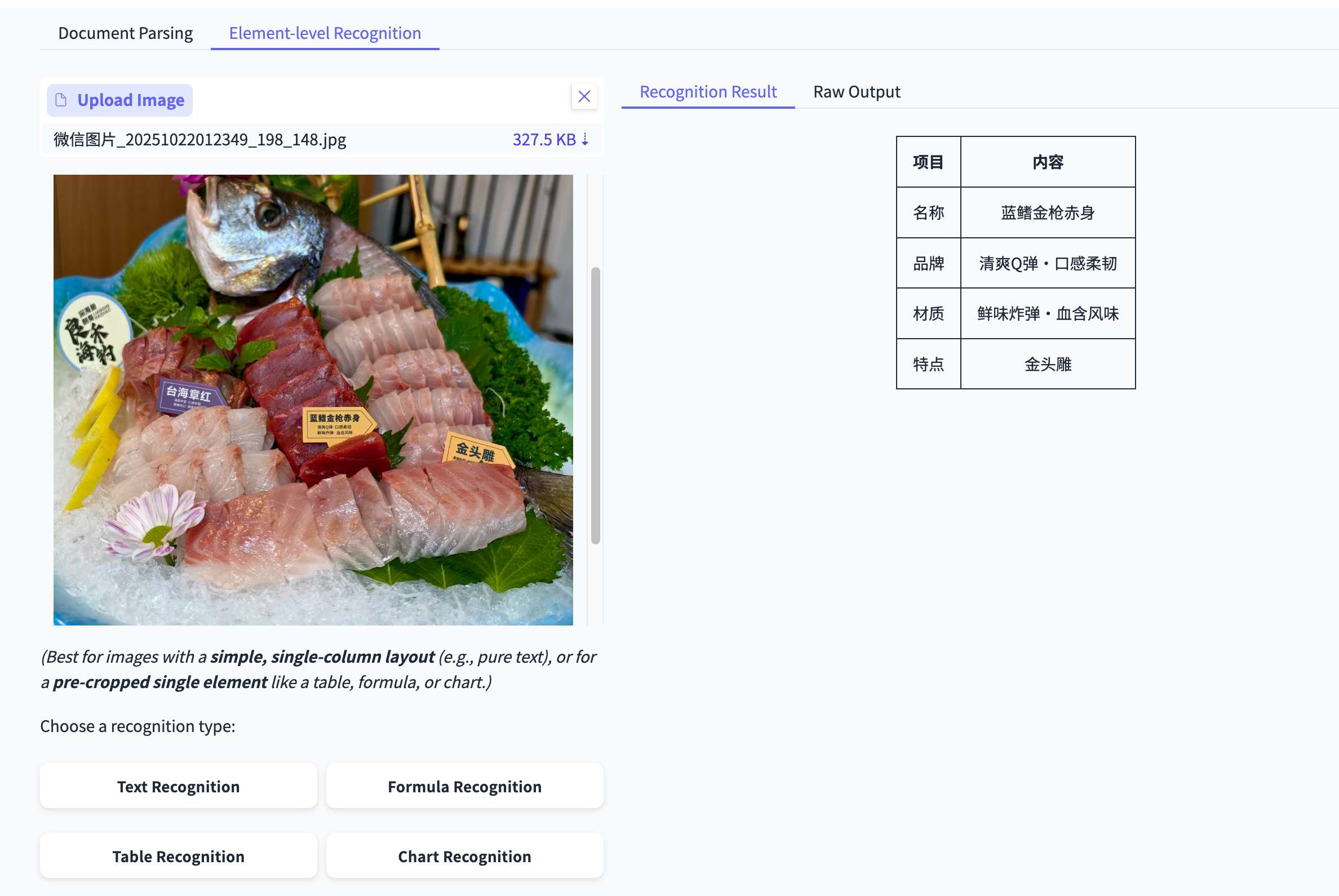
Deepseek-OCR: 识别不出任何内容。
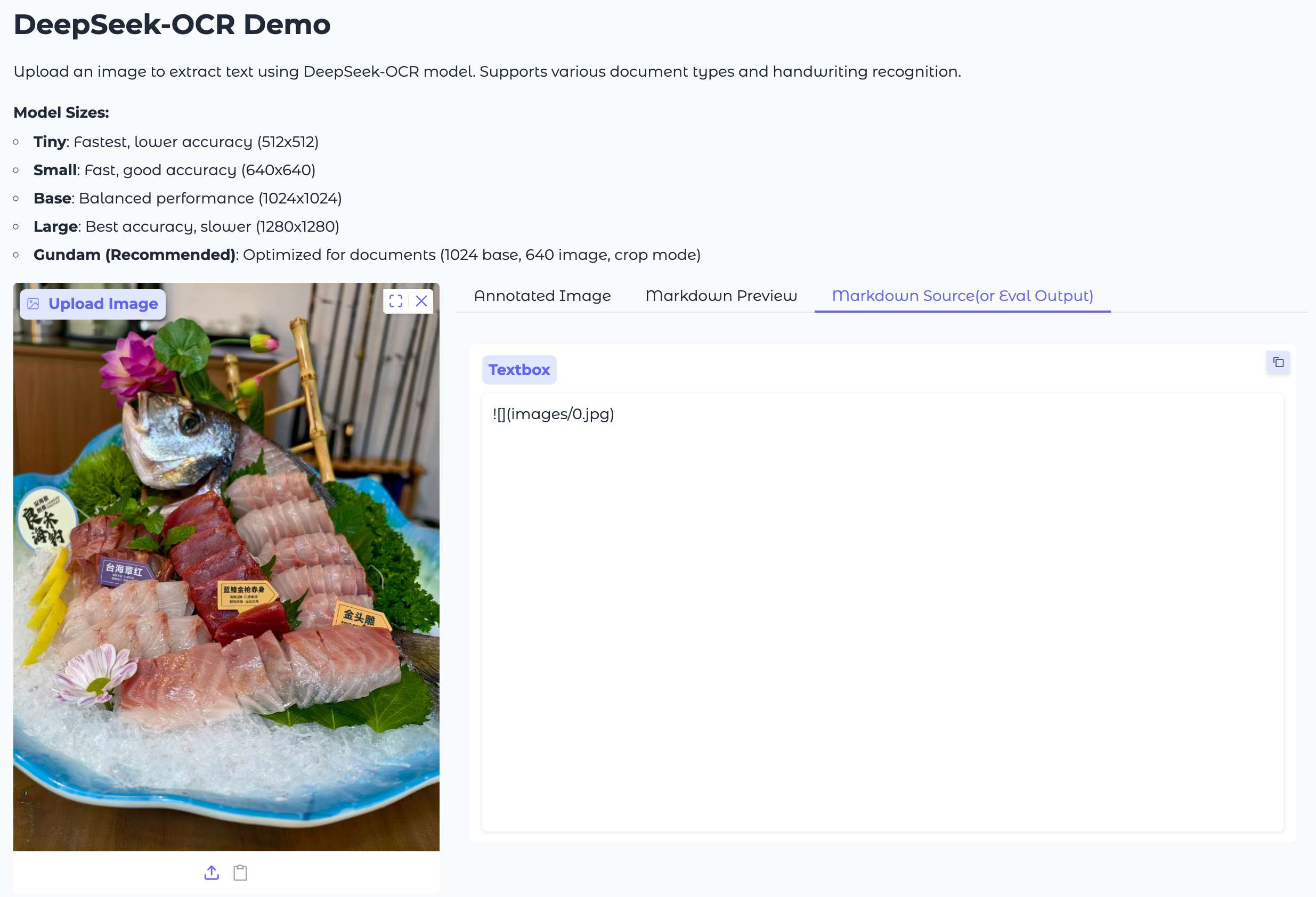
实测小结:
这次测试印证了榜单数据。Deepseek-OCR在面对非标准、有干扰的真实世界图像时,表现不稳定。而PaddleOCR-VL则展现了极强的鲁棒性,无论是对表格结构、艺术字体还是复杂排版,都体现了其作为专业OCR方案的深厚积累。
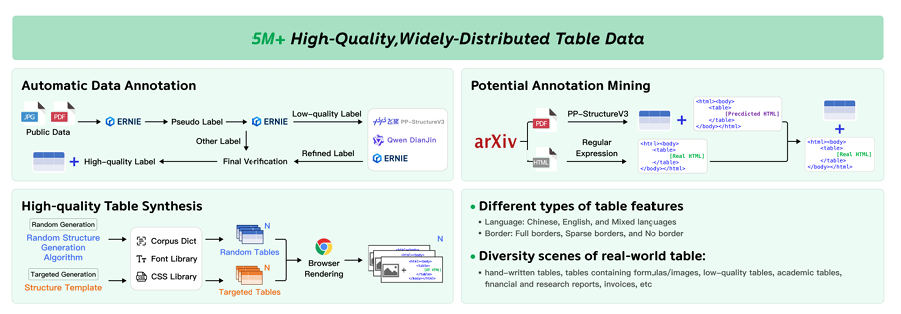
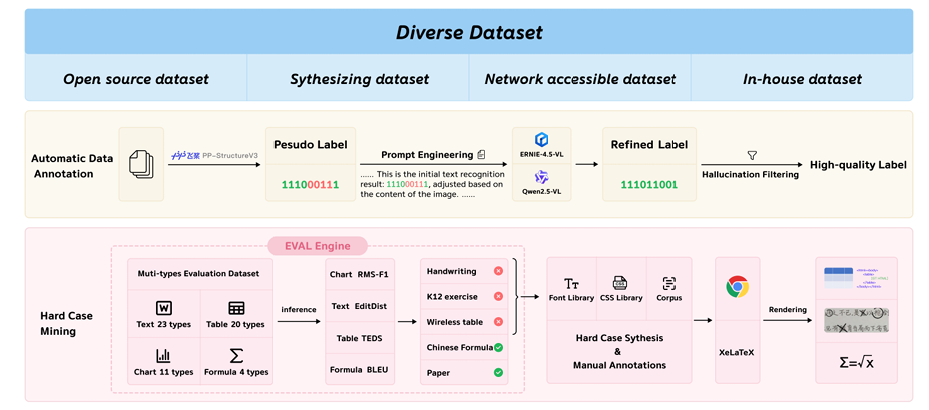
补充材料(PaddleOCR-VL在文字和表格方面的能力拆解):

五、 为什么OCR突然又火了?
这背后其实是更大的行业趋势。OCR这个“老树发新芽”,核心原因是它成了大模型时代最重要的“入口”之一。
RAG 应用: RAG(检索增强生成)是现在最火的应用范式,但企业知识库里全是扫描版的PDF、合同、报告。OCR的质量就是RAG的“知识保真度”,是“Garbage In, Garbage Out”的第一道防线。
产业流程自动化: 金融、物流、保险等行业要降本增效,必须处理海量文档。高精度的OCR就是“成本效益的裁决者”。
大模型进化: 人类知识的载体是书籍、论文。OCR就是那个“文明数字化转换器”,把非结构化信息变成大模型能“吃”的养料。
六、 总结:SOTA与实用,两种路径的选择
这次横评下来,结论其实很清晰了:
DeepSeek-OCR:它是一个非常棒的学术探索,它另辟蹊径地尝试用“视觉压缩”来解决LLM的长上下文难题,这个思路值得点赞。
PaddleOCR-VL:它是一个产业级的SOTA解决方案。不愧是中国OCR技术的老大哥,它目标很务实,就是在复杂多变的真实场景中,把文档解析做到极致。它继承了PaddleOCR开源5年、GitHub超5万Star(唯一Star数超50k的中国OCR项目)、累计下载超900万的深厚积累,这不是一个新玩具,是一个身经百战的成熟系统。
最后说个有意思的“彩蛋”:我去看DeepSeek-OCR的论文,在致谢和数据标注部分,都提到了感谢并使用了PaddleOCR。这说明PaddleOCR早已是这个领域的基础设施。
所以:如果你要发论文、探索新方向,DeepSeek的思路值得一看;但如果你是开发者,或者你的企业需要处理海量的财报、合同、票据,那PaddleOCR-VL无疑是当前综合表现最好、最可靠的选择。
七、参考文献
-
论文: https://arxiv.org/pdf/2510.14528
-
Github: https://github.com/PaddlePaddle/PaddleOCR
-
Blog: https://ernie.baidu.com/blog/posts/paddleocr-vl/
-
HuggingFace: https://huggingface.co/PaddlePaddle/PaddleOCR-VL
-
OCR体验地址:
PaddleOCR-VL:https://aistudio.baidu.com/application/detail/98365
DS-OCR:https://huggingface.co/spaces/axiilay/DeepSeek-OCR-Demo
hello,我是 是Yu欸 。如果你喜欢我的文章,欢迎三连给我鼓励和支持:👍点赞 📁 关注 💬评论,我会给大家带来更多有用有趣的文章。
原文链接 👉 ,⚡️更新更及时。
欢迎大家点开下面名片,添加好友交流。