【大模型微调】LLaMA Factory 微调 LLMs VLMs
LLaMA Factory是一个大模型高效微调平台,在github有60k多收藏了,很适合入门的朋友
提供了“ 一站式”的操作界面,通过可视化操作,就可以完成对LLMs 或 VLMs的微调了
开源地址:https://github.com/hiyouga/LLaMA-Factory
下面是微调的页面,简洁、清晰、功能多:
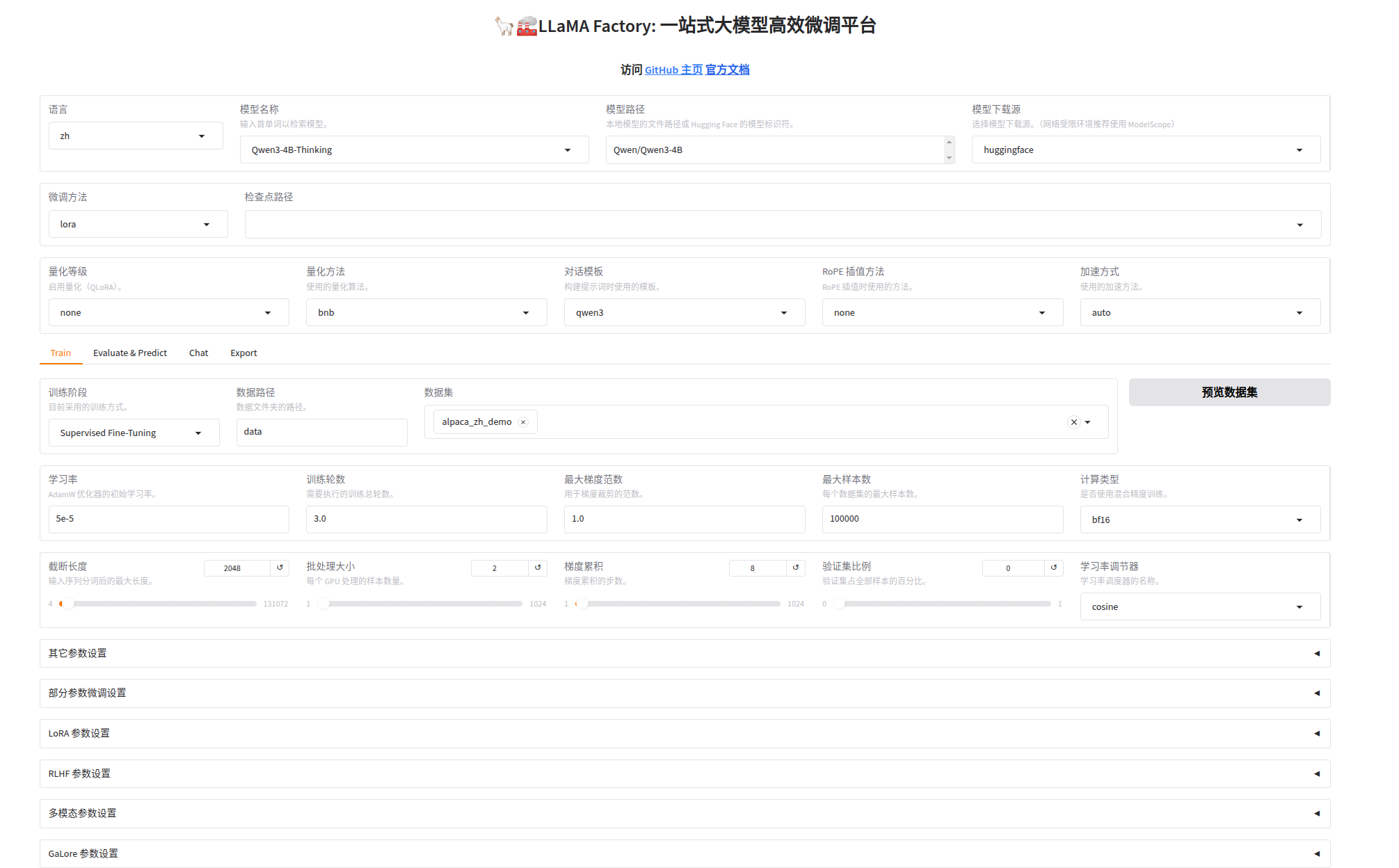
目录
一、LLaMA Factory的特色
二、支持的模型
三、提供的数据集(基础)
四、安装LLaMA Factory
五、微调LLM实践--Qwen3-4B-Thinking
六、微调VLM实践--Qwen/Qwen2.5-VL-3B-Instruct
七、了解源代码
八、其他参考资料
一、LLaMA Factory的特色
- 多种模型:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Qwen2-VL、Qwen3、DeepSeek、Yi、Gemma、ChatGLM、Phi 等等。
- 集成方法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
- 多种精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
- 先进算法:GaLore、BAdam、APOLLO、Adam-mini、Muon、OFT、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
- 实用技巧:FlashAttention-2、Unsloth、Liger Kernel、RoPE scaling、NEFTune 和 rsLoRA。
- 广泛任务:多轮对话、工具调用、图像理解、视觉定位、视频识别和语音理解等等。
- 实验监控:LlamaBoard、TensorBoard、Wandb、MLflow、SwanLab 等等。
- 极速推理:基于 vLLM 或 SGLang 的 OpenAI 风格 API、浏览器界面和命令行接口。
可以对最新的模型进行微调,下面是建议的计划:
| 适配时间 | 模型名称 |
|---|---|
| Day 0 | Qwen3 / Qwen2.5-VL / Gemma 3 / GLM-4.1V / InternLM 3 / MiniCPM-o-2.6 |
| Day 1 | Llama 3 / GLM-4 / Mistral Small / PaliGemma2 / Llama 4 |
支持的训练方法:
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ✅ | ✅ | ✅ | ✅ |
| 指令监督微调 | ✅ | ✅ | ✅ | ✅ |
| 奖励模型训练 | ✅ | ✅ | ✅ | ✅ |
| PPO 训练 | ✅ | ✅ | ✅ | ✅ |
| DPO 训练 | ✅ | ✅ | ✅ | ✅ |
| KTO 训练 | ✅ | ✅ | ✅ | ✅ |
| ORPO 训练 | ✅ | ✅ | ✅ | ✅ |
| SimPO 训练 | ✅ | ✅ | ✅ | ✅ |
二、支持的模型
主要包括下面这些模型:(还有一些没有列出来)
| 模型名 | 参数量 | Template |
|---|---|---|
| Baichuan 2 | 7B/13B | baichuan2 |
| BLOOM/BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | - |
| ChatGLM3 | 6B | chatglm3 |
| Command R | 35B/104B | cohere |
| DeepSeek (Code/MoE) | 7B/16B/67B/236B | deepseek |
| DeepSeek 2.5/3 | 236B/671B | deepseek3 |
| DeepSeek R1 (Distill) | 1.5B/7B/8B/14B/32B/70B/671B | deepseekr1 |
| ERNIE-4.5 | 0.3B/21B/300B | ernie/ernie_nothink |
| Falcon | 7B/11B/40B/180B | falcon |
| Falcon-H1 | 0.5B/1.5B/3B/7B/34B | falcon_h1 |
| Gemma/Gemma 2/CodeGemma | 2B/7B/9B/27B | gemma/gemma2 |
| Gemma 3/Gemma 3n | 270M/1B/4B/6B/8B/12B/27B | gemma3/gemma3n |
| GLM-4/GLM-4-0414/GLM-Z1 | 9B/32B | glm4/glmz1 |
| GLM-4.1V | 9B | glm4v |
| GLM-4.5/GLM-4.5V | 106B/355B | glm4_moe/glm4v_moe |
| GPT-2 | 0.1B/0.4B/0.8B/1.5B | - |
| GPT-OSS | 20B/120B | gpt |
| Granite 3.0-3.3 | 1B/2B/3B/8B | granite3 |
| Granite 4 | 7B | granite4 |
| Hunyuan (MT) | 7B | hunyuan |
| Index | 1.9B | index |
| InternLM 2-3 | 7B/8B/20B | intern2 |
| InternVL 2.5-3.5 | 1B/2B/4B/8B/14B/30B/38B/78B/241B | intern_vl |
| InternLM/Intern-S1-mini | 8B | intern_s1 |
| Kimi-VL | 16B | kimi_vl |
| Ling 2.0 (mini/flash) | 16B/100B | bailing_v2 |
| Llama | 7B/13B/33B/65B | - |
| Llama 2 | 7B/13B/70B | llama2 |
| Llama 3-3.3 | 1B/3B/8B/70B | llama3 |
| Llama 4 | 109B/402B | llama4 |
| Llama 3.2 Vision | 11B/90B | mllama |
| LLaVA-1.5 | 7B/13B | llava |
| LLaVA-NeXT | 7B/8B/13B/34B/72B/110B | llava_next |
| LLaVA-NeXT-Video | 7B/34B | llava_next_video |
| MiMo | 7B | mimo |
| MiniCPM 1-4.1 | 0.5B/1B/2B/4B/8B | cpm/cpm3/cpm4 |
| MiniCPM-o-2.6/MiniCPM-V-2.6 | 8B | minicpm_o/minicpm_v |
| Ministral/Mistral-Nemo | 8B/12B | ministral |
| Mistral/Mixtral | 7B/8x7B/8x22B | mistral |
| Mistral Small | 24B | mistral_small |
| OLMo | 1B/7B | - |
| PaliGemma/PaliGemma2 | 3B/10B/28B | paligemma |
| Phi-1.5/Phi-2 | 1.3B/2.7B | - |
| Phi-3/Phi-3.5 | 4B/14B | phi |
| Phi-3-small | 7B | phi_small |
| Phi-4 | 14B | phi4 |
| Pixtral | 12B | pixtral |
| Qwen (1-2.5) (Code/Math/MoE/QwQ) | 0.5B/1.5B/3B/7B/14B/32B/72B/110B | qwen |
| Qwen3 (MoE/Instruct/Thinking/Next) | 0.6B/1.7B/4B/8B/14B/32B/80B/235B | qwen3/qwen3_nothink |
| Qwen2-Audio | 7B | qwen2_audio |
| Qwen2.5-Omni | 3B/7B | qwen2_omni |
| Qwen3-Omni | 30B | qwen3_omni |
| Qwen2-VL/Qwen2.5-VL/QVQ | 2B/3B/7B/32B/72B | qwen2_vl |
| Qwen3-VL | 235B | qwen3_vl |
| Seed (OSS/Coder) | 8B/36B | seed_oss/seed_coder |
| Skywork o1 | 8B | skywork_o1 |
| StarCoder 2 | 3B/7B/15B | - |
| TeleChat2 | 3B/7B/35B/115B | telechat2 |
| XVERSE | 7B/13B/65B | xverse |
| Yi/Yi-1.5 (Code) | 1.5B/6B/9B/34B | yi |
| Yi-VL | 6B/34B | yi_vl |
| Yuan 2 | 2B/51B/102B | yuan |
三、提供的数据集(基础)
下面这些是基础数据集,提供给我们使用的,我们也可以自定义数据集的。
预训练数据集
- Wiki Demo (en)
- RefinedWeb (en)
- RedPajama V2 (en)
- Wikipedia (en)
- Wikipedia (zh)
- Pile (en)
- SkyPile (zh)
- FineWeb (en)
- FineWeb-Edu (en)
- CCI3-HQ (zh)
- CCI3-Data (zh)
- CCI4.0-M2-Base-v1 (en&zh)
- CCI4.0-M2-CoT-v1 (en&zh)
- CCI4.0-M2-Extra-v1 (en&zh)
- The Stack (en)
- StarCoder (en)
指令微调数据集
- Identity (en&zh)
- Stanford Alpaca (en)
- Stanford Alpaca (zh)
- Alpaca GPT4 (en&zh)
- Glaive Function Calling V2 (en&zh)
- LIMA (en)
- Guanaco Dataset (multilingual)
- BELLE 2M (zh)
- BELLE 1M (zh)
- BELLE 0.5M (zh)
- BELLE Dialogue 0.4M (zh)
- BELLE School Math 0.25M (zh)
- BELLE Multiturn Chat 0.8M (zh)
- UltraChat (en)
- OpenPlatypus (en)
- CodeAlpaca 20k (en)
- Alpaca CoT (multilingual)
- OpenOrca (en)
- SlimOrca (en)
- MathInstruct (en)
- Firefly 1.1M (zh)
- Wiki QA (en)
- Web QA (zh)
- WebNovel (zh)
- Nectar (en)
- deepctrl (en&zh)
- Advertise Generating (zh)
- ShareGPT Hyperfiltered (en)
- ShareGPT4 (en&zh)
- UltraChat 200k (en)
- Infinity Instruct (zh)
- AgentInstruct (en)
- LMSYS Chat 1M (en)
- Evol Instruct V2 (en)
- Cosmopedia (en)
- STEM (zh)
- Ruozhiba (zh)
- Neo-sft (zh)
- Magpie-Pro-300K-Filtered (en)
- Magpie-ultra-v0.1 (en)
- WebInstructSub (en)
- OpenO1-SFT (en&zh)
- Open-Thoughts (en)
- Open-R1-Math (en)
- Chinese-DeepSeek-R1-Distill (zh)
- LLaVA mixed (en&zh)
- Pokemon-gpt4o-captions (en&zh)
- Open Assistant (de)
- Dolly 15k (de)
- Alpaca GPT4 (de)
- OpenSchnabeltier (de)
- Evol Instruct (de)
- Dolphin (de)
- Booksum (de)
- Airoboros (de)
- Ultrachat (de)
偏好数据集
- DPO mixed (en&zh)
- UltraFeedback (en)
- COIG-P (zh)
- RLHF-V (en)
- VLFeedback (en)
- RLAIF-V (en)
- Orca DPO Pairs (en)
- HH-RLHF (en)
- Nectar (en)
- Orca DPO (de)
- KTO mixed (en)
注意:部分数据集的使用需要确认,推荐使用下述命令登录自己的 Hugging Face 账户
pip install --upgrade huggingface_hub
huggingface-cli login四、安装LLaMA Factory
这里推荐“Conda环境+源码安装”的方式
首先下载代码,进入目录,执行命令:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory创建一个Conda环境,名字为LLaMA-Factory,指定Python是3.10:
conda create -n LLaMA-Factory python=3.10然后安装troch=2.5.1,CUDA=12.1,执行命令:
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu121最后安装其他依赖库:
pip install -e ".[torch,metrics]" --no-build-isolation电脑硬件方面,微调训练的参考:
| 方法 | 精度 | 7B | 14B | 30B | 70B | xB |
|---|---|---|---|---|---|---|
Full (bf16 or fp16) | 32 | 120GB | 240GB | 600GB | 1200GB | 18xGB |
Full (pure_bf16) | 16 | 60GB | 120GB | 300GB | 600GB | 8xGB |
| Freeze/LoRA/GaLore/APOLLO/BAdam | 16 | 16GB | 32GB | 64GB | 160GB | 2xGB |
| QLoRA | 8 | 10GB | 20GB | 40GB | 80GB | xGB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | x/2GB |
| QLoRA | 2 | 4GB | 8GB | 16GB | 24GB | x/4GB |
五、微调LLM实践--Qwen3-4B-Thinking
进入代码目录,并进入Conda环境:
conda activate LLaMA-Factory通过下面命令,打开微调可视化界面:
llamafactory-cli webui
然后我们选择模型(Qwen3-4B-Thinking)、微调方法(lora)、训练方式(Supervised Fine-Tuning)监督微调
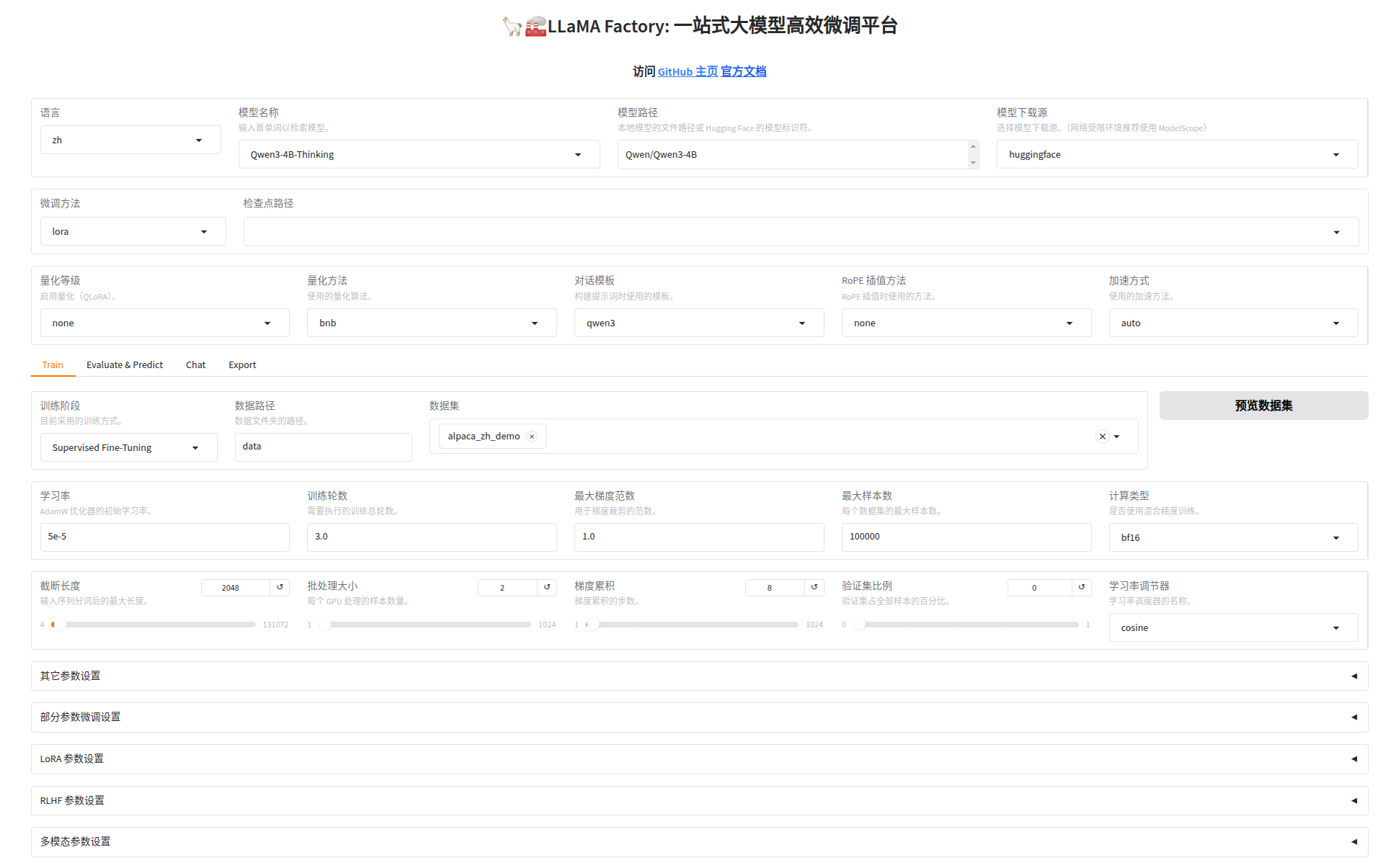
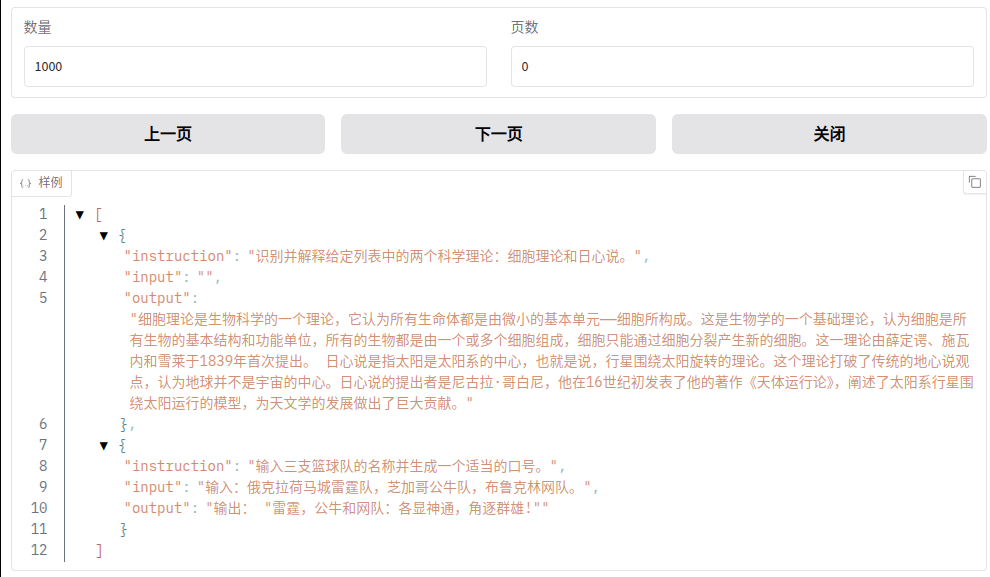
选择数据集(alpaca_zh_demo),点击“预览数据集”能看到:
其他参考可以默认了,然后点击“训练”,等待训练完成
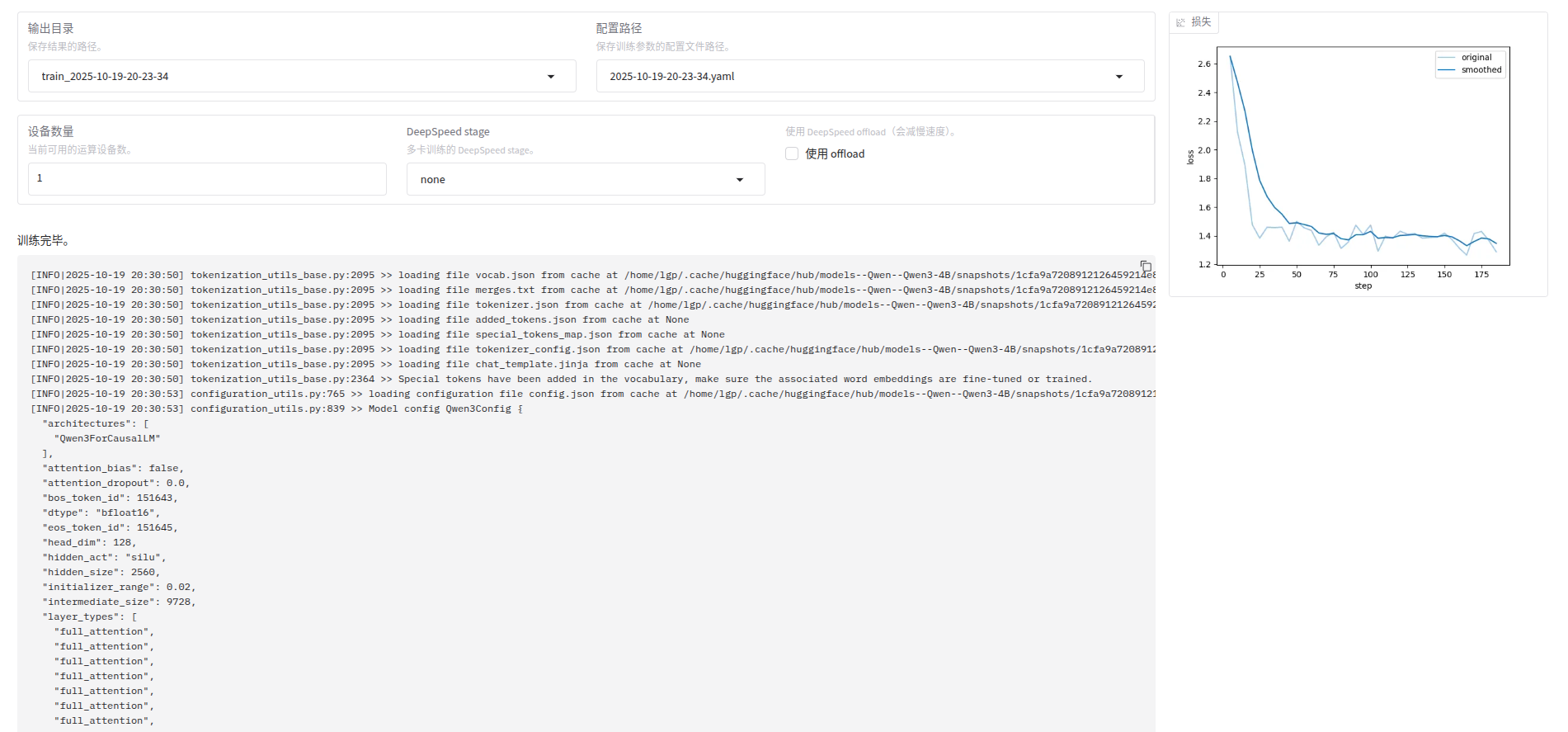
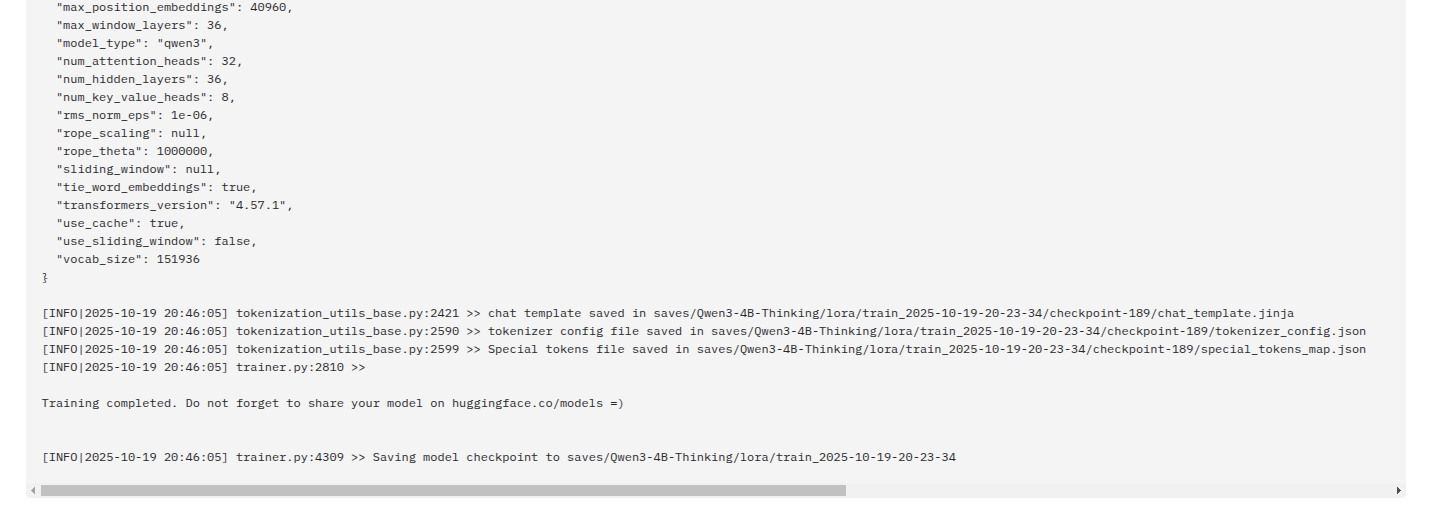
完成LLM微调啦~
六、微调VLM实践--Qwen/Qwen2.5-VL-3B-Instruct
进入代码目录,并进入Conda环境:
conda activate LLaMA-Factory通过下面命令,打开微调可视化界面:
llamafactory-cli webui然后我们选择模型(Qwen/Qwen2.5-VL-3B-Instruct)、微调方法(lora)、训练方式(Supervised Fine-Tuning)监督微调
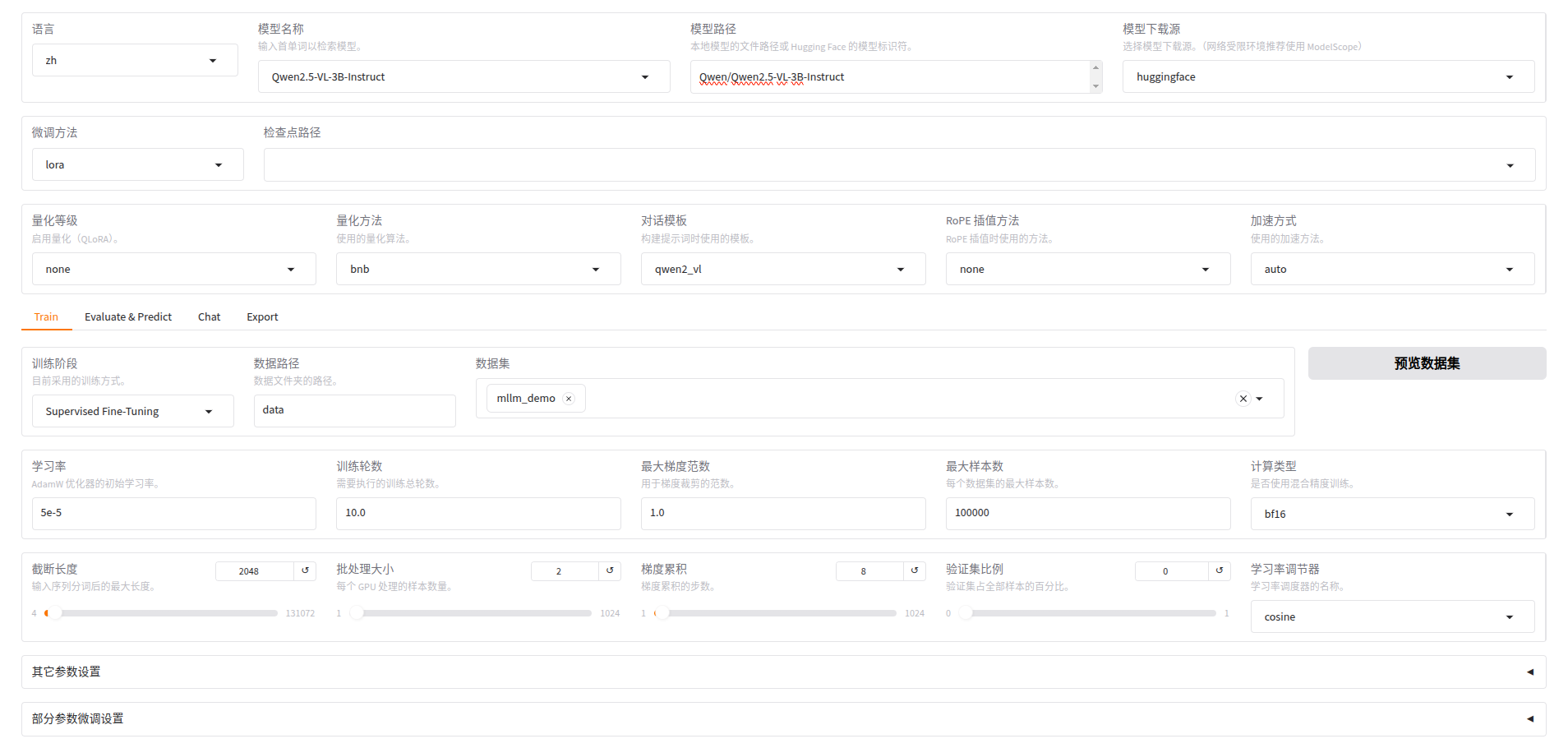
选择数据集(mllm_demo),点击“预览数据集”能看到:

对应的图片:(LLaMA-Factory/data/mllm_demo_data/1.jpg)

微调的训练轮数改为10
其他参考可以默认了,然后点击“训练”,等待训练完成
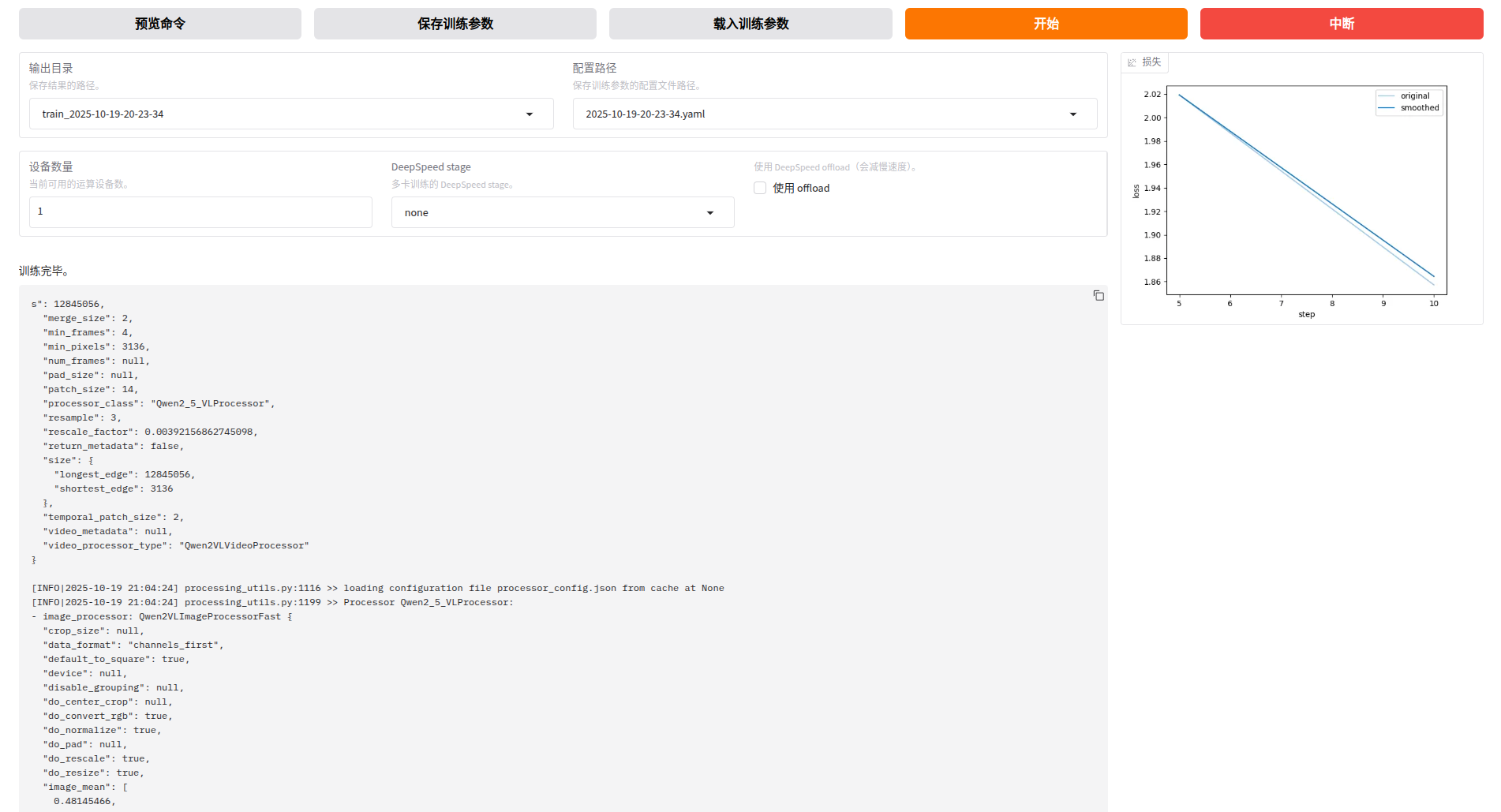
完成VLM微调啦~
七、了解源代码
目录结构,是这样的:
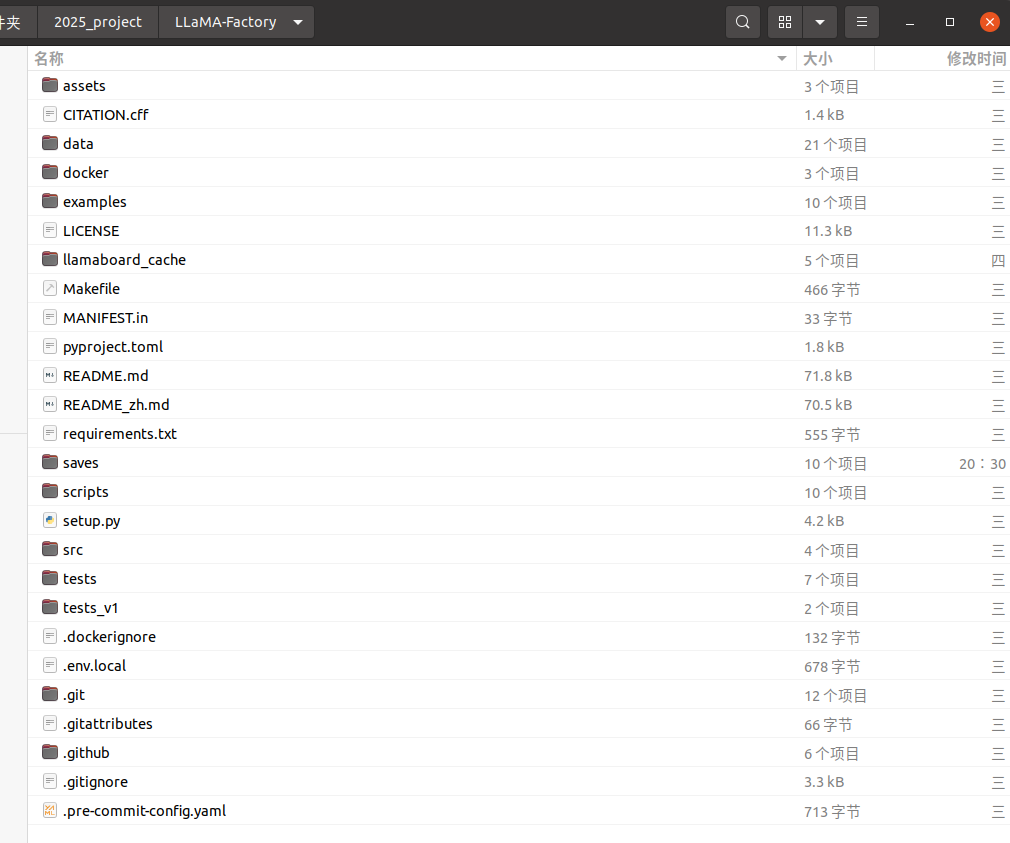
首先看看数据集的目录,有上面微调训练用到的alpaca_zh_demo.json、mllm_demo.json,
还有一些其他数据集,也能使用的
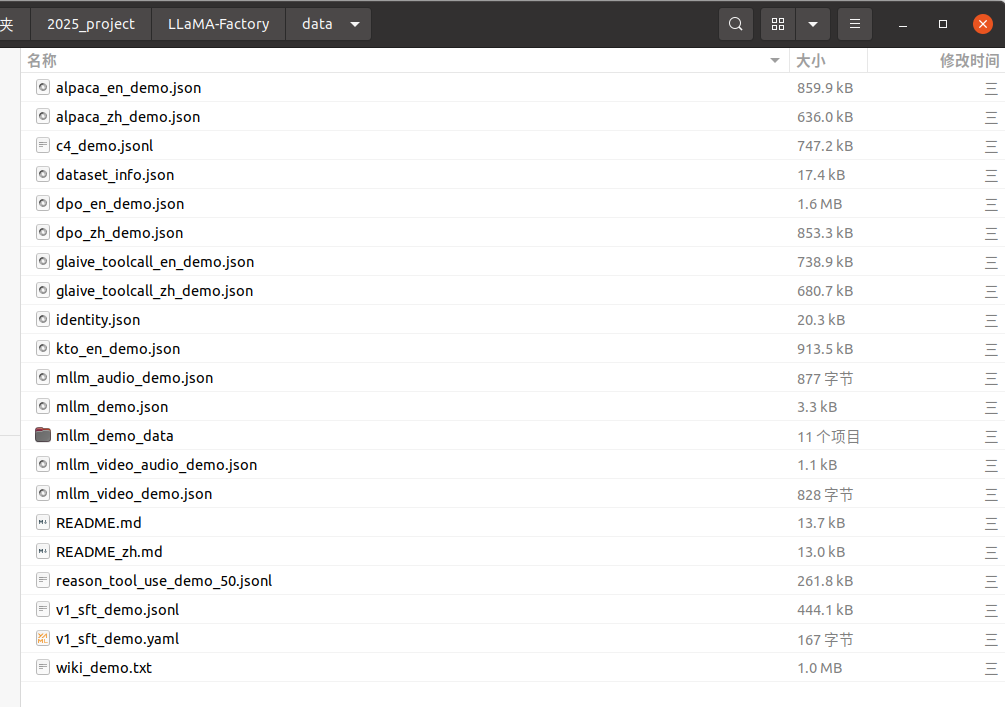
看一下alpaca_zh_demo.json文件的数据:
[{"instruction": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。","input": "","output": "细胞理论是生物科学的一个理论,它认为所有生命体都是由微小的基本单元——细胞所构成。这是生物学的一个基础理论,认为细胞是所有生物的基本结构和功能单位,所有的生物都是由一个或多个细胞组成,细胞只能通过细胞分裂产生新的细胞。这一理论由薛定谔、施瓦内和雪莱于1839年首次提出。\n\n日心说是指太阳是太阳系的中心,也就是说,行星围绕太阳旋转的理论。这个理论打破了传统的地心说观点,认为地球并不是宇宙的中心。日心说的提出者是尼古拉·哥白尼,他在16世纪初发表了他的著作《天体运行论》,阐述了太阳系行星围绕太阳运行的模型,为天文学的发展做出了巨大贡献。"},{"instruction": "输入三支篮球队的名称并生成一个适当的口号。","input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。","output": "输出: \"雷霆,公牛和网队:各显神通,角逐群雄!\""},{"instruction": "比较以下两位著名人物,使用特征列表并以句子形式提供输出。","input": "人物1:阿尔伯特·爱因斯坦\n人物2:斯蒂芬·霍金\n特征:智力、教育、对世界的影响","output": "阿尔伯特·爱因斯坦和斯蒂芬·霍金都是拥有极其出色智力的人物。两人都取得过非常高的教育成就,他们推进了科学发展并在世界范围内产生了深远的影响。爱因斯坦以其相对论和质能关系公式而闻名,而霍金以其关于黑洞和宇宙的发现而著称。两位科学家都以其深厚的学识和非凡的贡献影响了世界。"},{"instruction": "请根据以下文章构建一个需要回答的问题。","input": "","output": "我不好意思,您没有提供任何信息或文章来供我根据它构建问题。 请提供相应的文章或信息,以便我能够帮助您构建问题。"},
.........{"instruction": "描述安第斯山脉的位置。","input": "","output": "安第斯山脉位于南美洲,横跨七个国家,包括委内瑞拉,哥伦比亚,厄瓜多尔,秘鲁,玻利维亚,智利和阿根廷。安第斯山脉是世界上最长的山脉之一,全长约7,000千米(4,350英里),其山脉沿着南美洲西海岸蜿蜒延伸,平均海拔约为4,000米(13,000英尺)。在其南部,安第斯山脉宽度达到700千米(430英里),在其北部宽度约为500千米(310英里)。"}看一下mllm_demo.json文件的数据:
[{"messages": [{"content": "<image>Who are they?","role": "user"},{"content": "They're Kane and Gretzka from Bayern Munich.","role": "assistant"},{"content": "What are they doing?<image>","role": "user"},{"content": "They are celebrating on the soccer field.","role": "assistant"}],"images": ["mllm_demo_data/1.jpg","mllm_demo_data/1.jpg"]},{"messages": [{"content": "<image>Who is he?","role": "user"},{"content": "He's Thomas Muller from Bayern Munich.","role": "assistant"},{"content": "Why is he on the ground?","role": "user"},{"content": "Because he's sliding on his knees to celebrate.","role": "assistant"}],"images": ["mllm_demo_data/2.jpg"]},
.......{"messages": [{"content": "<image>请描述这张图片","role": "user"},{"content": "中国宇航员桂海潮正在讲话。","role": "assistant"},{"content": "他取得过哪些成就?","role": "user"},{"content": "他于2022年6月被任命为神舟十六号任务的有效载荷专家,从而成为2023年5月30日进入太空的首位平民宇航员。他负责在轨操作空间科学实验有效载荷。","role": "assistant"}],"images": ["mllm_demo_data/3.jpg"]}
]
目前支持 alpaca 格式和 sharegpt 格式的数据集。允许的文件类型包括 json、jsonl、csv、parquet 和 arrow。
自定义数据集,参考https://github.com/hiyouga/LLaMA-Factory/blob/main/data/README_zh.md 来制作就好啦
然后在dataset_info.json文件中,添加自定义的数据集名字和格式就好啦.(能看到alpaca_zh_demo和mllm_demo数据集也在里面的)
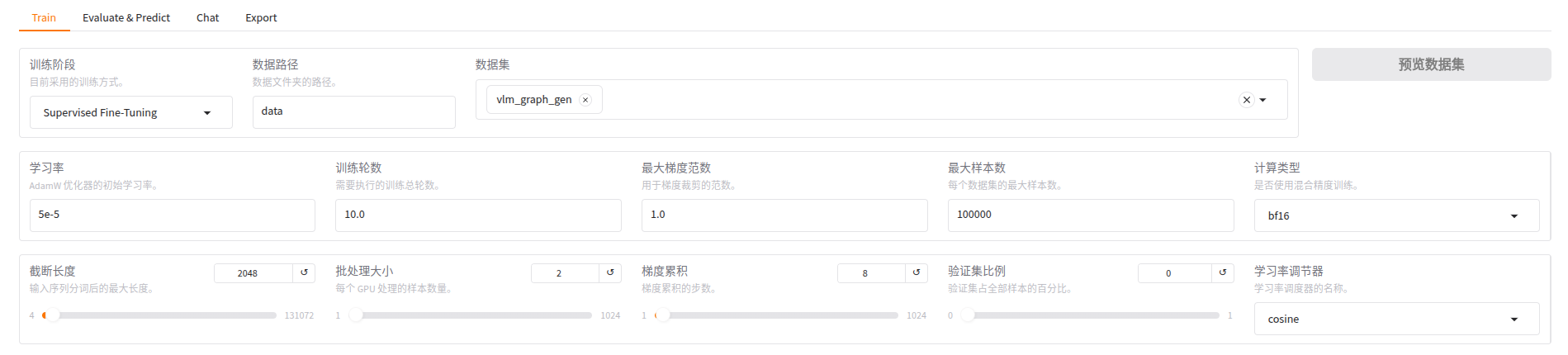
比如,新加了vlm_graph_gen数据集,标注内容在vlm_graph_gen.json中:
{"identity": {"file_name": "identity.json"},"alpaca_en_demo": {"file_name": "alpaca_en_demo.json"},"alpaca_zh_demo": {"file_name": "alpaca_zh_demo.json"},"glaive_toolcall_en_demo": {"file_name": "glaive_toolcall_en_demo.json","formatting": "sharegpt","columns": {"messages": "conversations","tools": "tools"}},"glaive_toolcall_zh_demo": {"file_name": "glaive_toolcall_zh_demo.json","formatting": "sharegpt","columns": {"messages": "conversations","tools": "tools"}},"mllm_demo": {"file_name": "mllm_demo.json","formatting": "sharegpt","columns": {"messages": "messages","images": "images"},"tags": {"role_tag": "role","content_tag": "content","user_tag": "user","assistant_tag": "assistant"}},"vlm_graph_gen": {"file_name": "vlm_graph_gen.json","formatting": "sharegpt","columns": {"messages": "messages","images": "images"},"tags": {"role_tag": "role","content_tag": "content","user_tag": "user","assistant_tag": "assistant"}},在微调训练时,就能选择它训练啦
八、其他参考资料
- 入门教程:https://zhuanlan.zhihu.com/p/695287607
- 微调视频教程:https://www.bilibili.com/video/BV1djgRzxEts/
- 框架文档:https://llamafactory.readthedocs.io/zh-cn/latest/
- 框架文档(昇腾 NPU):https://ascend.github.io/docs/sources/llamafactory/
- Colab(免费):https://colab.research.google.com/drive/1d5KQtbemerlSDSxZIfAaWXhKr30QypiK?usp=sharing
- 本地机器:请见如何使用
- PAI-DSW(免费试用):https://gallery.pai-ml.com/#/preview/deepLearning/nlp/llama_factory
- 九章智算云(算力优惠活动):https://docs.alayanew.com/docs/documents/useGuide/LLaMAFactory/mutiple/?utm_source=LLaMA-Factory
- 官方课程:https://www.lab4ai.cn/course/detail?id=7c13e60f6137474eb40f6fd3983c0f46&utm_source=LLaMA-Factory
- LLaMA Factory Online(在线微调):https://www.llamafactory.com.cn/?utm_source=LLaMA-Factory
官网博客:

- 💡 Easy Dataset × LLaMA Factory: 让大模型高效学习领域知识
- 使用 LLaMA-Factory 微调心理健康大模型
- 使用 LLaMA-Factory 构建 GPT-OSS 角色扮演模型
- 基于 LLaMA-Factory 和 EasyR1 打造一站式无代码大模型强化学习和部署平台 LLM Model Hub
- 通过亚马逊 SageMaker HyperPod 上的 LLaMA-Factory 增强多模态模型银行文档的视觉信息提取
分享完成~