分库分表:基础介绍
1、什么是分库分表?
什么是分库分表?
分库分表分为两个概念,分别是:分库、分表,下面将会一一介绍
分库
分库则是将一个数据库拆分成多个数据库,部署到不同的机器上,如下图:
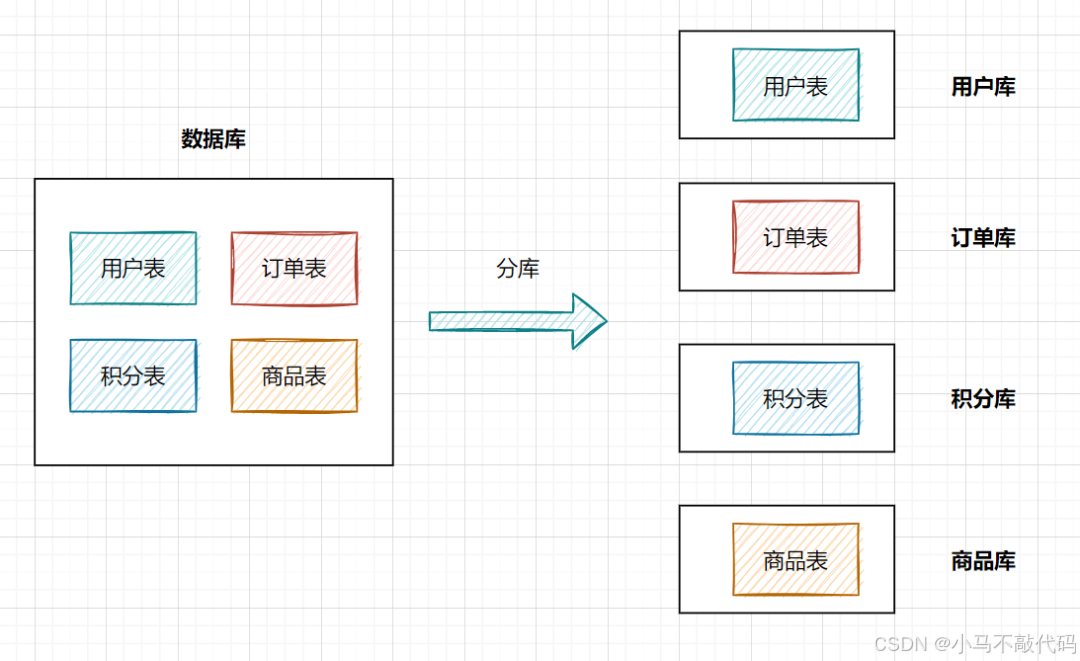
起初单库中有四张表,分别为用户表、订单表、积分表、商品表,经过分库之后将这四张表拆分到了四个数据库中,分别对应的是:用户库、订单库、积分库、商品库 。
分表
分表则是将一张表拆分成多张表,如下图:
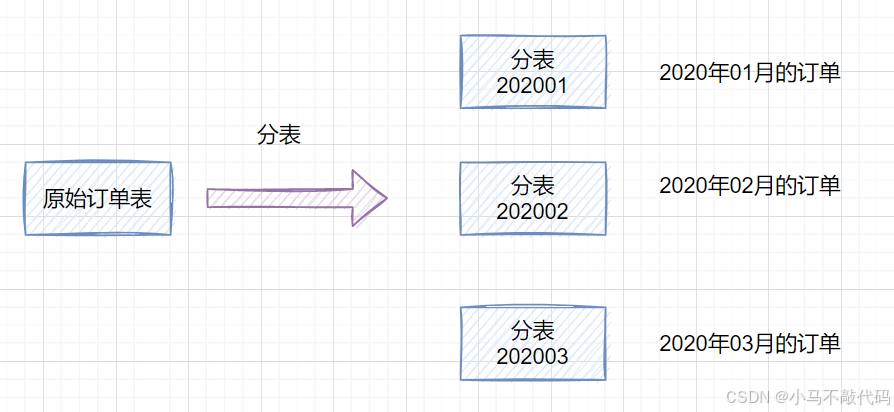
由上图所述起初所有的订单信息都存储在一张表中,那么可以根据日期进行分表,拆分成若干张表,比如:
2020年01月的订单
2020年02月的订单
2020年03月的订单
…
2、为什么需要分库分表?
为什么需要分库?
如果业务量剧增,数据库可能会出现性能瓶颈,这时候我们就需要考虑拆分数据库。从这几方面来看:
磁盘存储
业务量剧增,MySQL单机磁盘容量会撑爆,拆成多个数据库,磁盘使用率大大降低。
并发连接支撑
我们知道数据库连接是有限的。在高并发的场景下,大量请求访问数据库,MySQL单机是扛不住的!当前非常火的微服务架构出现,就是为了应对高并发。它把订单、用户、商品等不同模块,拆分成多个应用,并且把单个数据库也拆分成多个不同功能模块的数据库(订单库、用户库、商品库),以分担读写压力。
为什么需要分表?
数据量太大的话,SQL的查询就会变慢。如果一个查询SQL没命中索引,千百万数据量级别的表可能会拖垮整个数据库。
即使SQL命中了索引,如果表的数据量超过一千万的话,查询也是会明显变慢的。这是因为索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,查询就变慢啦。
小伙伴们是否还记得,MySQL的B+树的高度怎么计算的呢? 顺便复习一下吧
InnoDB存储引擎最小储存单元是页,一页大小就是16k。B+树叶子存的是数据,内部节点存的是键值+指针。索引组织表通过非叶子节点的二分查找法以及指针确定数据在哪个页中,进而再去数据页中找到需要的数据,B+树结构图如下:
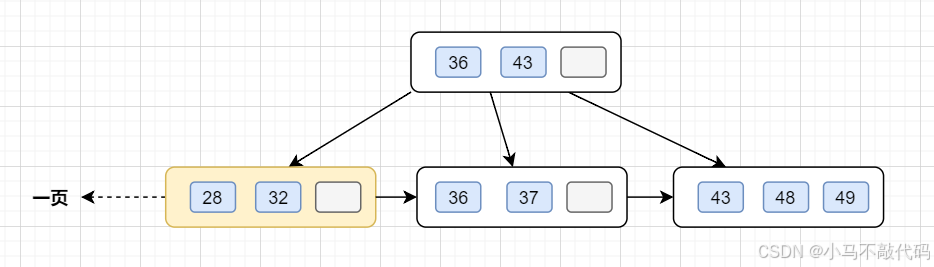
假设B+树的高度为2的话,即有一个根结点和若干个叶子结点。这棵B+树的存放总记录数为=根结点指针数*单个叶子节点记录行数。
- 如果一行记录的数据大小为1k,那么单个叶子节点可以存的记录数 =16k/1k =16 .
- 非叶子节点内存放多少指针呢?我们假设主键ID为bigint类型,长度为8字节(面试官问你int类型,一个int就是32位,4字节),而指针大小在InnoDB源码中设置为6字节,所以就是 8+6=14 字节,16k/14B =16*1024B/14B = 1170
因此,一棵高度为2的B+树,能存放1170 * 16=18720条这样的数据记录。同理一棵高度为3的B+树,能存放1170 *1170 *16 =21902400 ,大概可以存放两千万左右的记录。B+树高度一般为1-3层,如果B+到了4层,查询的时候会多查磁盘的次数,SQL就会变慢。
因此单表数据量太大,SQL查询会变慢,所以就需要考虑分表啦。
3、如何分库分表?
垂直拆分
垂直维度的拆分是针对库的结构、表的结构拆分,分为:
- 垂直分库
- 垂直分表
1.垂直分库
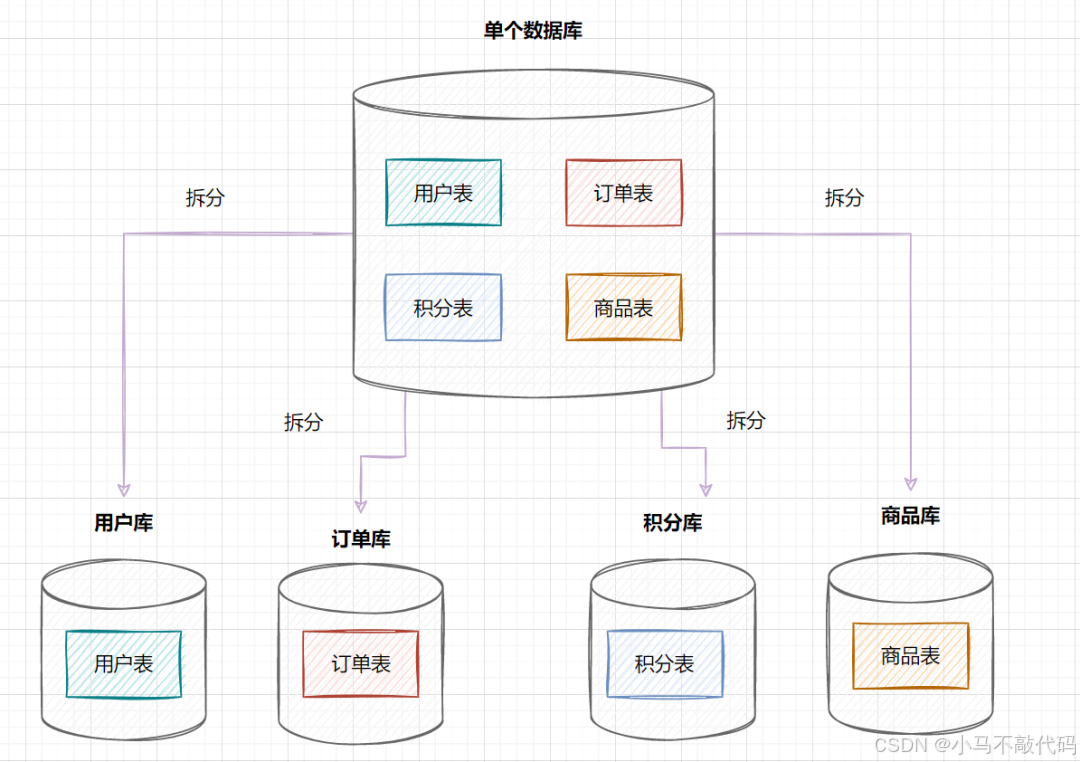
在业务发展初期,业务功能模块比较少,为了快速上线和迭代,往往采用单个数据库来保存数据。数据库架构如下:
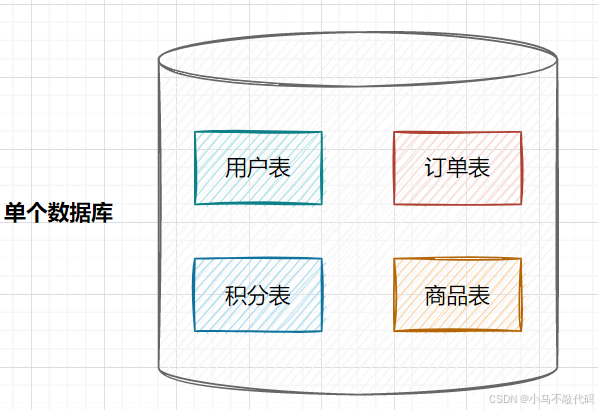
但是随着业务蒸蒸日上,系统功能逐渐完善。这时候,可以按照系统中的不同业务进行拆分,比如拆分成用户库、订单库、积分库、商品库,把它们部署在不同的数据库服务器,这就是垂直分库。
垂直分库,将原来一个单数据库的压力分担到不同的数据库,可以很好应对高并发场景。数据库垂直拆分后的架构如下:
2.垂直分表
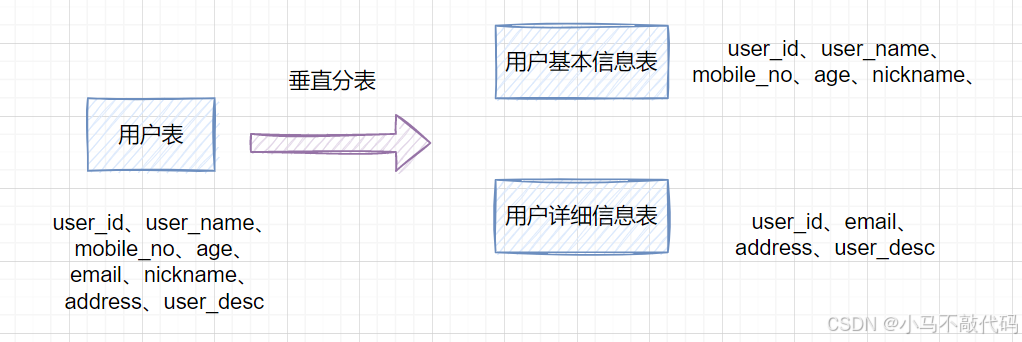
如果一个单表包含了几十列甚至上百列,管理起来很混乱,每次都select * 的话,还占用IO资源。这时候,我们可以将一些不常用的、数据较大或者长度较长的列拆分到另外一张表。
比如一张用户表,它包含user_id、user_name、mobile_no、age、email、nickname、address、user_desc,如果email、address、user_desc 等字段不常用,我们可以把它拆分到另外一张表,命名为用户详细信息表。这就是垂直分表
水平拆分
水平维度是针对数据量的拆分,分为:
- 水平分库
- 水平分表
1.水平分库
水平分库是指,将表的数据量切分到不同的数据库服务器上,每个服务器具有相同的库和表,只是表中的数据集合不一样。它可以有效的缓解单机单库的性能瓶颈和压力。
用户库的水平拆分架构如下:
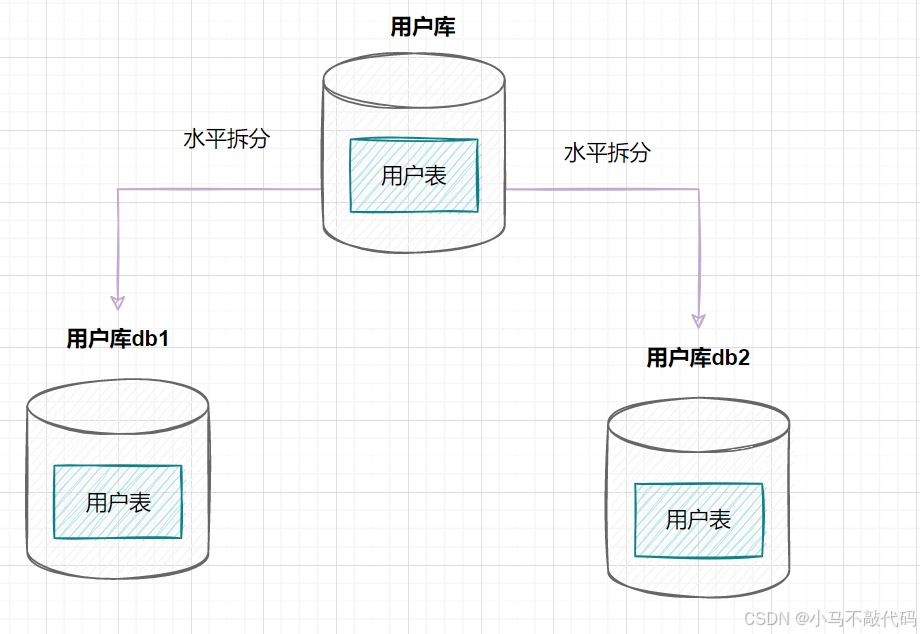
db1+db2 中的数据则是用户库的全量数据
2.水平分表
如果一个表的数据量太大,可以按照某种规则(如hash取模、range ),把数据切分到多张表去。
一张订单表,按时间range 拆分如下:
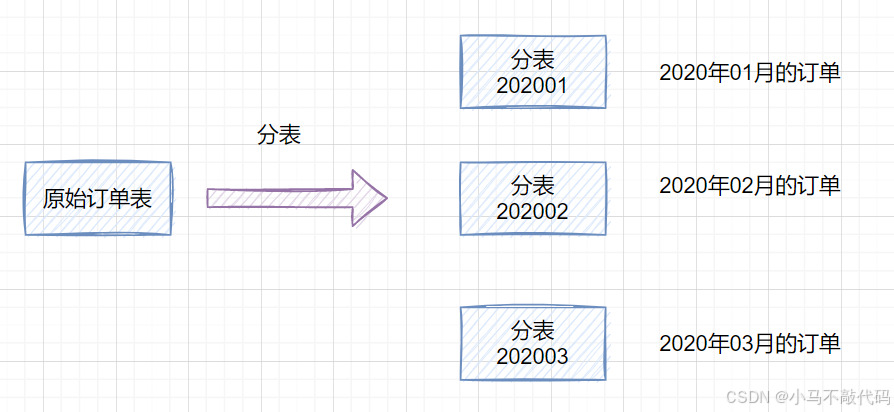
所有订单表的合集则是订单的全量数据
分库分表的中间件有哪些?
目前流行的分库分表中间件比较多:
cobar
Mycat
Sharding-JDBC
Atlas
TDDL(淘宝)
vitess
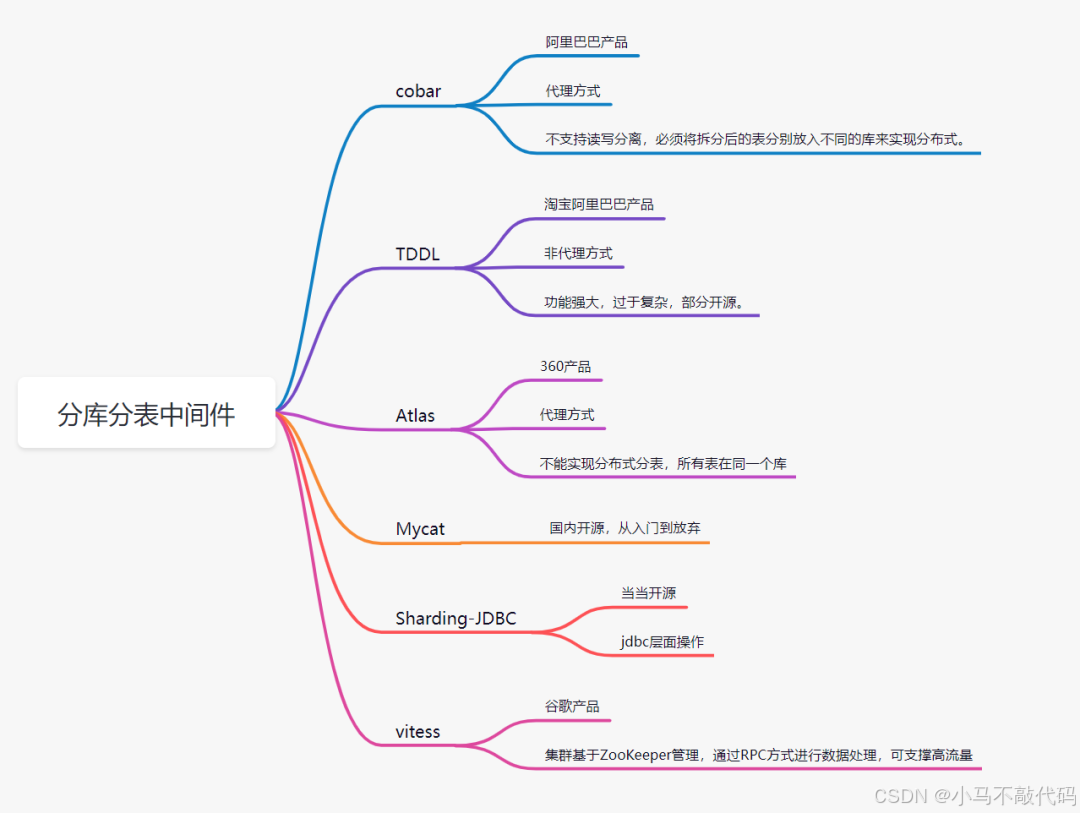
目前用的比较多且受欢迎的则是Sharding-JDBC
4、分库分表后带来的问题和考验
分库分表带来的问题
从单一表、单一库切分成多库、多表对于性能的提升是必然的,但是同时也带来了一些问题。
1.分布式事务问题
由于垂直分库、水平分库,将数据分摊在不同库中,甚至不同的服务器上,势必带来了分布式事务的问题。
2.跨节点关联join问题
在切分之前关联查询非常简单,直接SQL JOIN便能解决,但是切分之后数据分摊在不同的节点上,此时JOIN就比较麻烦了,因此切分之后尽量避免JOIN。
解决这一问题的有些方法:
1、全局表
这种很好理解,对于一些全局需要关联的表可以在每个数据节点上都存储一份,一般是一些数据字典表。
全局表在Sharding-JDBC称之为广播表
2、字段冗余
这是一种典型的反范式设计,为了避免关联JOIN,可以将一些冗余字段保存,比如订单表保存userId时,可以将userName也一并保存,这样就避免了和User表的关联JOIN了。
字段冗余这种方案存在数据一致性问题
3、数据组装
这种还是比较好理解的,直接不使用JOIN关联,分两次查询,从第一次的结果集中找出关联数据的唯一标识,然后再次去查询,最后对得到的数据进行组装
需要进行手动组装,数据很大的情况对CPU、内存有一定的要求
4、绑定表
对于相互关联的数据节点,通过分片规则将其切分到同一个库中,这样就可以直接使用SQL的JOIN 进行关联查询。
Sharding-JDBC中称之为绑定表,比如订单表和用户表的绑定
3.跨节点分页、排序、函数问题
对于跨数据节点进行分页、排序或者一些聚合函数,筛选出来的仅仅是针对当前节点,比如排序,仅仅能够保证在单一数据节点上是有序,并不能保证在所有节点上都是有序的,需要将各个节点的数据的进行汇总重新手动排序。
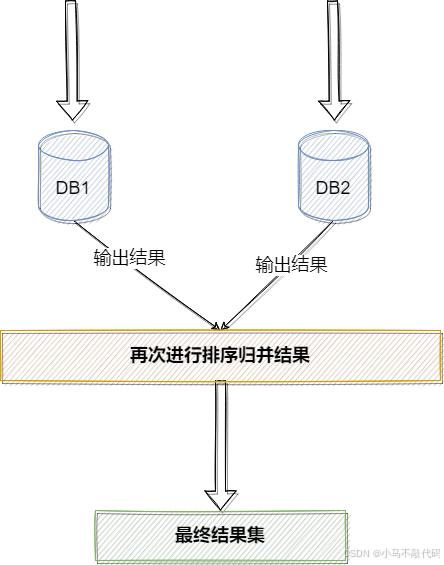
Sharding-JDBC 正是 按照上述流程进行分页、排序、聚合
4.全局主键避重问题
单库单表一般都是使用的自增主键,但是在切分之后每个自增主键将无法使用,因为这样会导致数据主键重复,因此必须重新设计主键。
目前主流的分布式主键生成方案如下:
1、UUID
UUID应该是大家最为熟悉的一种方案,优点非常明显本地生成,性能高,缺点也很明显,太长了存储耗空间,查询也非常耗性能,另外UUID的无序性将会导致InnoDB下的数据位置变动。
2、Snowflake
Twitter开源的由64位整数组成分布式ID,性能较高,并且在单机上递增。
3、UidGenerator
UidGenerator是百度开源的分布式ID生成器,其基于雪花算法实现。 具体参考:
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
4、Leaf
Leaf是美团开源的分布式ID生成器,能保证全局唯一,趋势递增,但需要依赖关系数据库、Zookeeper等中间件。 具体参考:
https://tech.meituan.com/2017/04/21/mt-leaf.html
5、数据迁移、扩容问题
当业务高速发展,面临性能和存储的瓶颈时,才会考虑分片设计,此时就不可避免的需要考虑历史数据迁移的问题。一般做法是先读出历史数据,然后按指定的分片规则再将数据写入到各个分片节点中。此外还需要根据当前的数据量和QPS,以及业务发展的速度,进行容量规划,推算出大概需要多少分片。
如果采用数值范围分片,只需要添加节点就可以进行扩容了,不需要对分片数据迁移。如果采用的是数值取模分片,则考虑后期的扩容问题就相对比较麻烦。