【深入浅出PyTorch】--4.PyTorch基础实战
目录
1.ResNet
1.1.深度网络的“直觉”与现实的矛盾
1.2.根本原因:梯度消失与梯度爆炸
1.3.传统缓解方法及其局限
1.4.ResNet 的突破性思想:残差学习与 Shortcut Connection
1.5.ResNet 如何缓解梯度问题?
1.6.ResNet 的影响与意义
1.7.源码解读
1.8.总结
2.FashionMNIST时装分类
2.1.导入包
2.2.环境和超参数
2.3.数据读入和加载
2.4.可视化数据
2.5.构建模型
2.6.损失函数+优化器
2.7.训练+验证
2.8.保存模型
2.9.加载模型
1.ResNet
残差神经网络(ResNet,Residual neural network)是由微软研究院的何恺明、张祥雨、任少卿、孙剑等人提出的。它的主要贡献是发现了在增加网络层数的过程中,随着训练精度(Training accuracy)逐渐趋于饱和,继续增加层数,training accuracy 就会出现下降的现象,而这种下降不是由过拟合造成的。他们将这一现象称之为“退化现象(Degradation)”,并针对退化现象发明了 “快捷连接(Shortcut connection)”,极大的消除了深度过大的神经网络训练困难问题。神经网络的“深度”首次突破了100层、最大的神经网络甚至超过了1000层。(在此,向已故的孙剑博士表示崇高的敬意)
通过本文你将学习到:
-
梯度消失/爆炸的简介
-
代码里面为什么要设计BasicBlock和Bottleneck两种结构
-
代码里面的expansion作用
1.1.深度网络的“直觉”与现实的矛盾
随着深度学习的发展,人们普遍认为:更深的网络 = 更强的表达能力 = 更好的性能。
因此,早期研究者不断堆叠卷积层或全连接层,期望获得更高的精度。
然而,微软研究院的何恺明、张祥雨、任少卿、孙剑等人在2015年发表的《Deep Residual Learning for Image Recognition》中发现了一个反常现象:
当网络深度增加到一定程度后,训练误差和测试误差不降反升。
这并不是过拟合导致的(因为训练误差也在上升),而是网络难以训练——即使使用了批归一化(Batch Normalization)、合适的初始化等手段。
这个现象说明:深度本身并不保证更好的性能,甚至可能成为训练的障碍。
1.2.根本原因:梯度消失与梯度爆炸
1. 反向传播与链式法则
神经网络通过反向传播算法更新参数,其数学基础是链式求导法则。
对于一个深层网络,损失函数 L 对某一层参数 Wl 的梯度为:

其中每一项都涉及权重和激活函数导数的乘积。
当层数很深时,这些导数需要连续相乘,这就带来了两个极端情况。
2. 梯度消失(Gradient Vanishing)
- 表现:靠近输入层的参数梯度极小,几乎无法更新。
- 原因:
- 激活函数导数小于1(
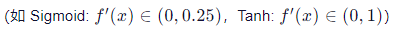 )。
)。 - 多个小于1的数连乘 → 指数级衰减 → 前层梯度趋近于0。
- 激活函数导数小于1(
- 后果:
- 网络前端“学不动”,特征提取能力受限。
- 训练停滞,收敛缓慢。
📌 举例:假设每层梯度平均为0.9,则第10层的梯度为 0.910≈0.350.910≈0.35,第50层则为 0.950≈0.0050.950≈0.005,已接近消失。
3. 梯度爆炸(Gradient Exploding)
- 表现:梯度异常大,权重更新剧烈,导致数值溢出(NaN)。
- 原因:
- 权重初始化过大或某些层的导数 > 1。
- 连续相乘 → 指数级增长。
- 后果:
- 损失函数剧烈震荡。
- 参数更新失控,模型无法收敛。
- 出现
NaN值,训练崩溃。
1.3.传统缓解方法及其局限
| 方法 | 原理 | 局限 |
|---|---|---|
| Xavier / He 初始化 | 控制权重初始分布,使信号方差稳定 | 仅能缓解,无法根治深层问题 |
| Batch Normalization (BN) | 归一化每层输入,防止激活值分布偏移 | 改善了训练稳定性,但极深层仍难训 |
| 使用 ReLU 激活函数 | 导数为1(正区间),避免指数衰减 | 解决了部分消失问题,但爆炸仍可能发生 |
这些方法虽有效,但在极深网络(如超过50层) 中依然难以避免性能退化。
1.4.ResNet 的突破性思想:残差学习与 Shortcut Connection
ResNet 的核心创新在于提出了残差块(Residual Block)。
1. 残差映射(Residual Mapping)
传统网络试图直接学习从输入 x 到输出 H(x) 的映射:
![]()
ResNet 改为学习残差函数:
![]()
其中 F(x)=H(x)−x 是网络实际学习的目标。
💡 直观理解:如果某层的最优解是恒等映射(identity mapping),那么让 F(x)=0 比让整个网络输出H(x)=x 更容易!
2. Shortcut Connection(跳跃连接)
实现方式就是添加一条跳跃连接(skip connection),将输入 x 直接加到输出上:
这种结构使得信息可以在网络中“直接流动”,即使中间层没有学到有用特征,也能通过恒等映射保留原始信息
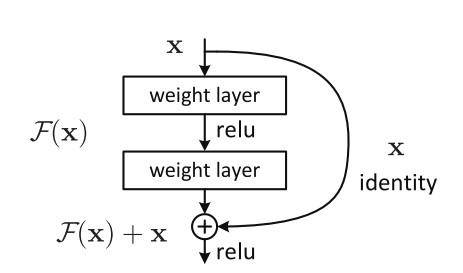
1.5.ResNet 如何缓解梯度问题?
1. 缓解梯度消失
由于跳跃连接的存在,梯度可以通过 shortcut 直接回传。
反向传播时,梯度路径变为:
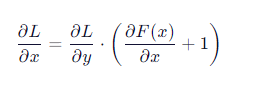
注意那个 +1!它确保了至少有一条梯度路径是“无损”的,避免了连续乘法导致的指数衰减。
✅ 即使
很小,总梯度也不会完全消失。
2. 缓解梯度爆炸
虽然不能完全防止爆炸,但由于残差结构鼓励学习小变化(F(x)≈0),实际梯度幅度更可控。
此外,结合 BN 和合理初始化,可进一步稳定训练。
1.6.ResNet 的影响与意义
- 首次成功训练超过百层的网络(如 ResNet-152)。
- 在 ImageNet 上大幅刷新记录,并赢得 ILSVRC 2015 冠军。
- 开启了“深度革命”:后续的 DenseNet、Transformer 等均受其启发。
- 成为现代深度神经网络的标准构件之一。
1.7.源码解读
1.7.1.卷积核的封装
在代码的开始,首先封装了3x3和1x1的卷积核,这样可以增加代码的可读性。除了这种代码写法外,还有许多深度学习代码在开始也会将卷积层,激活函数层和BN层封装在一起,同样是为了增加代码的可读性。
def conv3x3(in_planes: int, out_planes: int, stride: int = 1, groups: int = 1, dilation: int = 1) -> nn.Conv2d:"""3x3 convolution with padding"""return nn.Conv2d(in_planes,out_planes,kernel_size=3,stride=stride,padding=dilation,groups=groups,bias=False,dilation=dilation,)def conv1x1(in_planes: int, out_planes: int, stride: int = 1) -> nn.Conv2d:"""1x1 convolution"""return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False)1.7.2.基本模块的设计
ResNet网络是由很多相同的模块堆叠起来的,为了保证代码具有可读性和可扩展性,ResNet在设计时采用了模块化设计,针对不同大小的ResNet,书写了BasicBlock和BottleNeck两个基本模块。这种模块化的设计在现在许多常见的深度学习代码中我们可以经常看到。
ResNet常见的大小有下图的ResNet-18,ResNet-34,ResNet-50、ResNet-101和ResNet-152,其中网络后面的数字代表的是网络的层数。
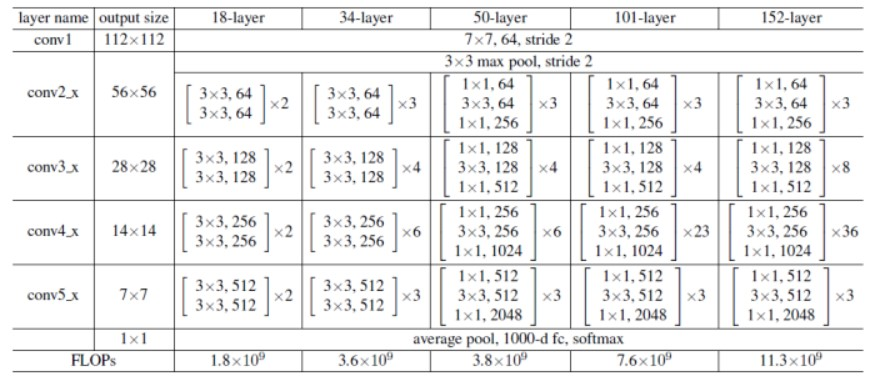
为了帮助大家更好的理解,我们以ResNet101为例。
layer_name
次数
conv1
卷积1次
conv2_x
卷积3 x 3 = 9次
conv3_x
卷积4 x 3 = 12次
conv4_x
卷积23 x 3 = 69次
conv5_x
卷积3 x 3 = 9次
fc
average pool 1次
合计
1 + 9 + 12 + 69 + 9 + 1 = 101次
在ResNet中,使用两个3x3的卷积层替换为1x1 + 3x3 + 1x1的卷积进行计算优化:
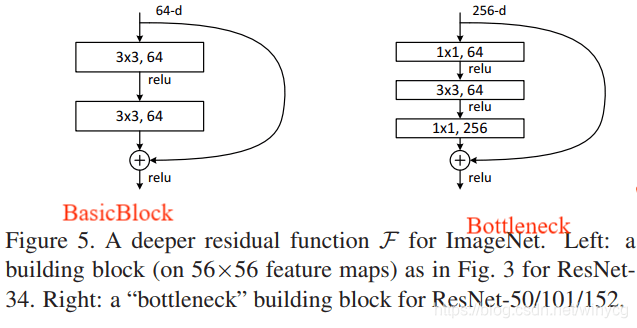
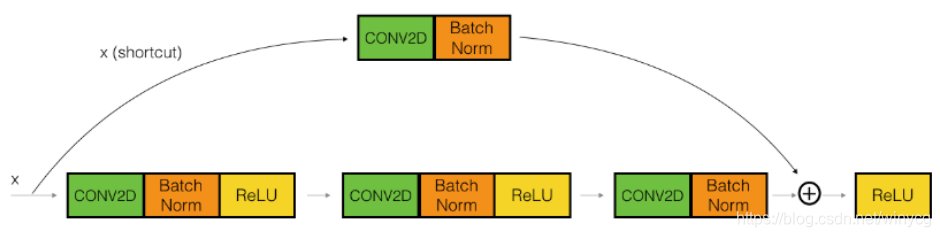
结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量,这种结构称为bottleneck模块。输入和输出要保持相同的维度,若特征图维度不同,对于卷积层的残差块,需要将x xx添加卷积核批标准化处理:
import torch
import torch.nn as nn
import torch.nn.functional as F# 用于ResNet18和34的残差块,用的是2个3x3的卷积
class BasicBlock(nn.Module):expansion = 1def __init__(self, in_planes, planes, stride=1):super(BasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3,stride=stride, padding=1, bias=False)#self.bn1 = nn.BatchNorm2d(planes)# 归一化层,对输入进行归一化处理self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,stride=1, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)# 归一化层,对输入进行归一化处理self.shortcut = nn.Sequential()# 用于处理输入的残差块,如果输入的维度和输出的维度相同,则不用添加残差结构# 经过处理后的x要与x的维度相同(尺寸和深度)# 如果不相同,需要添加卷积+BN来变换为同一维度if stride != 1 or in_planes != self.expansion * planes:self.shortcut = nn.Sequential(nn.Conv2d(in_planes, self.expansion * planes,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion * planes))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = self.bn2(self.conv2(out))out += self.shortcut(x)out = F.relu(out)return out# 用于ResNet50,101和152的残差块,用的是1x1+3x3+1x1的卷积
class Bottleneck(nn.Module):# 前面1x1和3x3卷积的filter个数相等,最后1x1卷积是其expansion倍expansion = 4def __init__(self, in_planes, planes, stride=1):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,stride=stride, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, self.expansion * planes,kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(self.expansion * planes)self.shortcut = nn.Sequential()if stride != 1 or in_planes != self.expansion * planes:self.shortcut = nn.Sequential(nn.Conv2d(in_planes, self.expansion * planes,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(self.expansion * planes))def forward(self, x):out = F.relu(self.bn1(self.conv1(x)))out = F.relu(self.bn2(self.conv2(out)))out = self.bn3(self.conv3(out))out += self.shortcut(x)out = F.relu(out)return outclass ResNet(nn.Module):def __init__(self, block, num_blocks, num_classes=1000):super(ResNet, self).__init__()self.in_planes = 64# conv1: 7x7, stride=2 → 112x112self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# 四个残差块组self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1) # 56x56self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2) # 28x28self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2) # 14x14self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2) # 7x7self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) # 自适应池化到 1x1self.linear = nn.Linear(512 * block.expansion, num_classes)def _make_layer(self, block, planes, num_blocks, stride):strides = [stride] + [1] * (num_blocks - 1)layers = []for stride in strides:layers.append(block(self.in_planes, planes, stride))self.in_planes = planes * block.expansionreturn nn.Sequential(*layers)def forward(self, x):out = F.relu(self.bn1(self.conv1(x))) # 112x112out = self.maxpool(out) # 56x56out = self.layer1(out) # 56x56out = self.layer2(out) # 28x28out = self.layer3(out) # 14x14out = self.layer4(out) # 7x7out = self.avgpool(out) # 1x1out = out.view(out.size(0), -1)out = self.linear(out)return outdef ResNet18():return ResNet(BasicBlock, [2, 2, 2, 2])def ResNet34():return ResNet(BasicBlock, [3, 4, 6, 3])def ResNet50():return ResNet(Bottleneck, [3, 4, 6, 3])def ResNet101():return ResNet(Bottleneck, [3, 4, 23, 3])def ResNet152():return ResNet(Bottleneck, [3, 8, 36, 3])def test():net = ResNet18()x = torch.randn(1, 3, 224, 224) # ImageNet 输入尺寸y = net(x)print("Output size:", y.size()) # torch.Size([1, 1000])print("Model parameters:", sum(p.numel() for p in net.parameters()))if __name__ == "__main__":test()| 步骤 | 输入 | 操作 | 输出 | 尺寸变化 |
|---|---|---|---|---|
| 1 | (3,224,224) | conv1: 7×7, stride=2 | (64,112,112) | ↓2 倍 |
| 2 | (64,112,112) | maxpool: 3×3, stride=2 | (64,56,56) | ↓2 倍 |
| 3 | (64,56,56) | layer1: 2×BasicBlock | (64,56,56) | 无下采样 |
| 4 | (64,56,56) | layer2: 2×BasicBlock, stride=2 | (128,28,28) | ↓2 倍 |
| 5 | (128,28,28) | layer3: 2×BasicBlock, stride=2 | (256,14,14) | ↓2 倍 |
| 6 | (256,14,14) | layer4: 2×BasicBlock, stride=2 | (512,7,7) | ↓2 倍 |
| 7 | (512,7,7) | avgpool | (512,1,1) | 池化 |
| 8 | (512,1,1) | linear | (1000,) | 分类输出 |

1.8.总结
ResNet通过引入残差学习机制解决了深层网络训练中的一些关键问题,如梯度消失和信息丢失等,从而使得构建更深的网络成为可能,并且在很多任务上取得了非常好的效果。下面是对你的描述中提到的一些关键点的总结和补充:
ResNet的核心贡献
- 解决深层网络训练难题:通过引入shortcut连接(也称为跳跃连接),ResNet允许模型学习输入与输出之间的差异(即残差),而不是直接学习到输出的映射。这种方式有效地缓解了深层网络中的梯度消失问题,使得训练非常深的网络变得更加可行。
- 保护信息完整性:shortcut连接使得输入可以直接传递到后续层,减少了信息在层层传递过程中可能遭受的损失。
ResNet的变体
-
ResNeXt:通过引入分组卷积(grouped convolution)的概念,在保持计算复杂度的同时增加了模型的表现力。每个残差块内的多个分支具有相同的拓扑结构,这不仅简化了设计,还提高了效率。
-
Wider ResNet:不同于增加网络深度的做法,Wider ResNet选择加宽网络,即增加每一层的宽度(通道数)。这种方法在某些情况下比单纯增加深度更为有效,尤其是在数据集不是特别庞大时。
-
DarkNet53:作为YOLO目标检测算法的一部分,DarkNet53基于ResNet但做了显著修改。它使用了更复杂的残差块结构,并且在网络的深层使用了更大的步长来减少计算量,同时维持较高的准确率。
结论
ResNet无疑是深度学习领域的一个里程碑式工作,它不仅极大地推动了计算机视觉领域的发展,也为后续的研究提供了宝贵的思想和方法。其变体们在不同的应用场景下展示了各自的特色和优势,证明了ResNet框架的强大适应性和可扩展性。随着技术的不断进步,我们可以期待更多基于ResNet理念的创新出现。
2.FashionMNIST时装分类

我们这里的任务是对10个类别的“时装”图像进行分类,使用FashionMNIST数据集。 上图给出了FashionMNIST中数据的若干样例图,其中每个小图对应一个样本。
FashionMNIST数据集中包含已经预先划分好的训练集和测试集,其中训练集共60,000张图像,测试集共10,000张图像。每张图像均为单通道黑白图像,大小为28*28pixel,分属10个类别。
{'Ankle boot': 9, 'Bag': 8, 'Coat': 4, 'Dress': 3, 'Pullover': 2, 'Sandal': 5, 'Shirt': 6, 'Sneaker': 7, 'T-shirt/top': 0, 'Trouser': 1}
2.1.导入包
import os
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader2.2.环境和超参数
# 配置GPU,这里有两种方式
## 方案一:使用os.environ
# os.environ['CUDA_VISIBLE_DEVICES'] = '0'
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu")## 配置其他超参数,如batch_size, num_workers, learning rate, 以及总的epochs
batch_size = 256#每批次的样本数
num_workers = 0 # 对于Windows用户,这里应设置为0,否则会出现多线程错误
lr = 1e-4# 学习率=0.0001
epochs = 20# 总的训练轮数2.3.数据读入和加载
这里同时展示两种方式:
-
下载并使用PyTorch提供的内置数据集
-
从网站下载以csv格式存储的数据,读入并转成预期的格式
第一种数据读入方式只适用于常见的数据集,如MNIST,CIFAR10等,PyTorch官方提供了数据下载。这种方式往往适用于快速测试方法(比如测试下某个idea在MNIST数据集上是否有效)
第二种数据读入方式需要自己构建Dataset,这对于PyTorch应用于自己的工作中十分重要
同时,还需要对数据进行必要的变换,比如说需要将图片统一为一致的大小,以便后续能够输入网络训练;需要将数据格式转为Tensor类,等等。
这些变换可以很方便地借助torchvision包来完成,这是PyTorch官方用于图像处理的工具库,上面提到的使用内置数据集的方式也要用到。PyTorch的一大方便之处就在于它是一整套“生态”,有着官方和第三方各个领域的支持。这些内容我们会在后续课程中详细介绍。
# 首先设置数据变换
from torchvision import transformsimage_size = 28
data_transform = transforms.Compose([# transforms.ToPILImage(), # 转换为PIL格式# 这一步取决于后续的数据读取方式,如果使用内置数据集读取方式则不需要transforms.Resize(image_size),# 调整图像大小28x28transforms.ToTensor()# 转换为Tensor格式
])## 读取方式一:使用torchvision自带数据集,下载可能需要一段时间
from torchvision import datasetstrain_data = datasets.FashionMNIST(root='./', train=True, download=True, transform=data_transform)
test_data = datasets.FashionMNIST(root='./', train=False, download=True, transform=data_transform)#读入数据
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=num_workers, drop_last=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=num_workers)
读取方式二:自己构建数据集
## 读取方式二:读入csv格式的数据,自行构建Dataset类
# csv数据下载链接:https://www.kaggle.com/zalando-research/fashionmnist
class FMDataset(Dataset):def __init__(self, df, transform=None):self.df = dfself.transform = transformself.images = df.iloc[:,1:].values.astype(np.uint8)self.labels = df.iloc[:, 0].valuesdef __len__(self):return len(self.images)def __getitem__(self, idx):image = self.images[idx].reshape(28,28,1)label = int(self.labels[idx])if self.transform is not None:image = self.transform(image)else:image = torch.tensor(image/255., dtype=torch.float)label = torch.tensor(label, dtype=torch.long)return image, labeltrain_df = pd.read_csv("./FashionMNIST/fashion-mnist_train.csv")
test_df = pd.read_csv("./FashionMNIST/fashion-mnist_test.csv")
train_data = FMDataset(train_df, data_transform)
test_data = FMDataset(test_df, data_transform)2.4.可视化数据
import matplotlib.pyplot as plt
image, label = next(iter(train_loader))#iter()作用是返回迭代器的第一个元素
print(image.shape, label.shape)
plt.imshow(image[99][0], cmap="gray")
2.5.构建模型
由于任务较为简单,这里我们手搭一个CNN,而不考虑当下各种模型的复杂结构,模型构建完成后,将模型放到GPU上用于训练。
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv = nn.Sequential(nn.Conv2d(1, 32, 5),nn.ReLU(),nn.MaxPool2d(2, stride=2),nn.Dropout(0.3),nn.Conv2d(32, 64, 5),nn.ReLU(),nn.MaxPool2d(2, stride=2),nn.Dropout(0.3))self.fc = nn.Sequential(nn.Linear(64*4*4, 512),nn.ReLU(),nn.Linear(512, 10))def forward(self, x):x = self.conv(x)x = x.view(-1, 64*4*4)x = self.fc(x)# x = nn.functional.normalize(x)return xmodel = Net()
model = model.cuda()
# model = nn.DataParallel(model).cuda() # 多卡训练时的写法,之后的课程中会进一步讲解2.6.损失函数+优化器
使用torch.nn模块自带的CrossEntropy损失
PyTorch会自动把整数型的label转为one-hot型,用于计算CE loss
这里需要确保label是从0开始的,同时模型不加softmax层(使用logits计算),这也说明了PyTorch训练中各个部分不是独立的,需要通盘考虑
criterion = nn.CrossEntropyLoss()
# criterion = nn.CrossEntropyLoss(weight=[1,1,1,1,3,1,1,1,1,1])optimizer = optim.Adam(model.parameters(), lr=0.001)2.7.训练+验证
各自封装成函数,方便后续调用
关注两者的主要区别:
-
模型状态设置
-
是否需要初始化优化器
-
是否需要将loss传回到网络
-
是否需要每步更新optimizer
此外,对于测试或验证过程,可以计算分类准确率
def train(epoch):model.train()#1.设置模型为训练模式train_loss = 0#2.初始化训练损失for data, label in train_loader:data, label = data.cuda(), label.cuda()#3.将数据和标签移到GPUoptimizer.zero_grad()#4.梯度清零output = model(data)#5.前向传播loss = criterion(output, label)#6.计算损失loss.backward()#7.反向传播optimizer.step()#8.更新参数train_loss += loss.item()*data.size(0)#9.累计训练损失train_loss = train_loss/len(train_loader.dataset)#10.计算所有伦次数据平均训练损失print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))def val(epoch):model.eval()#1.设置模型为评估模式val_loss = 0#2.初始化评估损失gt_labels = []#初始化真实标签列表pred_labels = []#初始化预测标签列表with torch.no_grad():for data, label in test_loader:data, label = data.cuda(), label.cuda()#3.将数据和标签移到GPUoutput = model(data)#4.前向传播preds = torch.argmax(output, 1)#5.获取预测结果,argmax返回最大值索引gt_labels.append(label.cpu().data.numpy())#6.将标签移回CPU并转换为numpy格式pred_labels.append(preds.cpu().data.numpy())#7.将预测结果移回CPU并转换为numpy格式loss = criterion(output, label)#8.计算损失val_loss += loss.item()*data.size(0)#9.累计评估损失val_loss = val_loss/len(test_loader.dataset)#10.计算所有伦次数据平均评估损失,test_loader.dataset=数据集的大小gt_labels, pred_labels = np.concatenate(gt_labels), np.concatenate(pred_labels)#11.将列表转换为numpy格式acc = np.sum(gt_labels==pred_labels)/len(pred_labels)#12.计算准确率print('Epoch: {} \tValidation Loss: {:.6f}, Accuracy: {:6f}'.format(epoch, val_loss, acc))for epoch in range(1, epochs+1):train(epoch)val(epoch)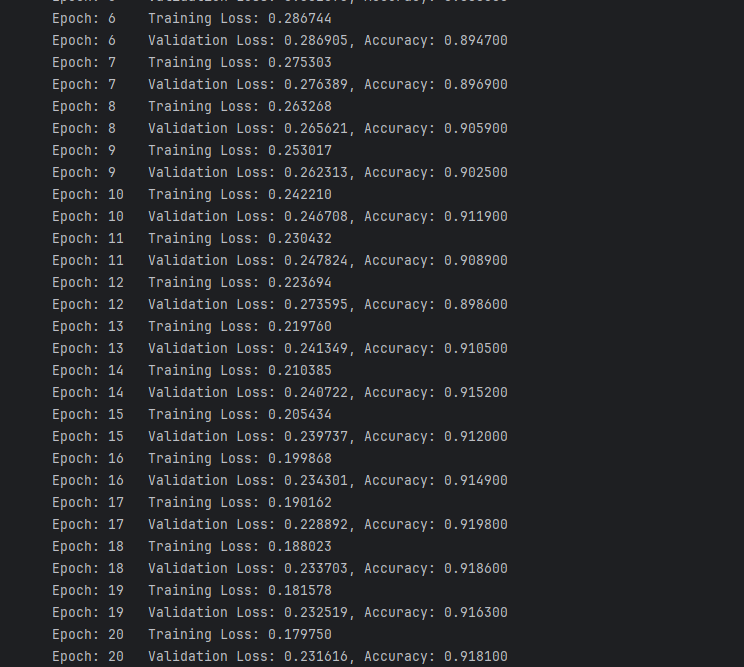
2.8.保存模型
训练完成后,可以使用torch.save保存模型参数或者整个模型,也可以在训练过程中保存模型
这部分会在后面的课程中详细介绍
save_path = "./FahionModel.pkl"
torch.save(model, save_path)2.9.加载模型
import torch
import random
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体作为示例,你可以选择其他支持中文的字体
# 加载保存的模型
model_path = "./FahionModel.pkl"
loaded_model = torch.load(model_path, weights_only=False)
loaded_model.eval() # 设置为评估模式# 随机选择一个测试样本进行预测
indices = list(range(len(test_loader.dataset)))
random_index = random.choice(indices)# 获取随机索引对应的图像和标签
single_image, single_label = test_loader.dataset[random_index]# 如果模型使用的是DataLoader,则需要调整获取单个样本的方式
# 将数据移到GPU(如果模型在GPU上)
single_image = single_image.unsqueeze(0).cuda() # 增加batch维度并移动到cuda# 进行预测
with torch.no_grad():output = loaded_model(single_image)predicted_class = torch.argmax(output, 1)# 将结果移回CPU以便显示
single_image_cpu = single_image.cpu()
predicted_class_cpu = predicted_class.cpu()
true_label_cpu = single_label# 显示结果
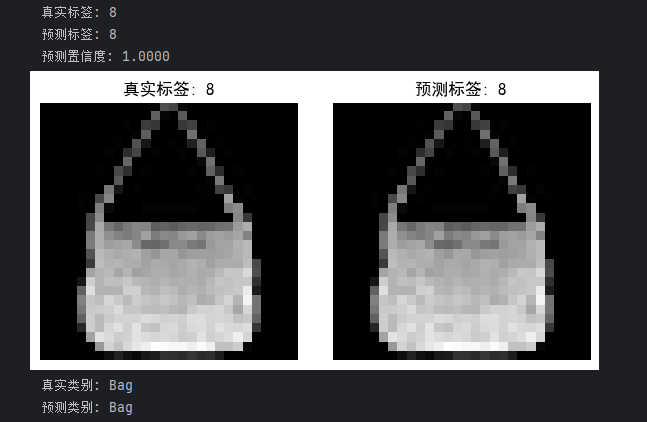
print(f"真实标签: {true_label_cpu}")
print(f"预测标签: {predicted_class_cpu.item()}")
print(f"预测置信度: {torch.softmax(output, 1).max().item():.4f}")# 显示图像
plt.figure(figsize=(6, 3))
plt.subplot(1, 2, 1)
plt.imshow(single_image_cpu[0][0], cmap='gray')
plt.title(f'真实标签: {true_label_cpu}')
plt.axis('off')plt.subplot(1, 2, 2)
plt.imshow(single_image_cpu[0][0], cmap='gray')
plt.title(f'预测标签: {predicted_class_cpu.item()}')
plt.axis('off')plt.tight_layout()
plt.show()# Fashion-MNIST类别名称
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']print(f"真实类别: {class_names[true_label_cpu]}")
print(f"预测类别: {class_names[predicted_class_cpu.item()]}")