数据库架构演进:从读写分离到大数据解析
目录
一、读写分离 / 主从分离架构
二、引入缓存 —— 冷热分离架构
三、垂直分库
四、业务拆分 —— 微服务架构
五、架构演进尾声
六、大数据架构概述
一、读写分离 / 主从分离架构
在前一节中,负载均衡器看起来承担了所有请求,它能顶住压力吗?实际上,负载均衡器的请求处理能力远超应用服务器。这就像团队分工:负载均衡器是领导,负责任务分配;应用服务器是组员,负责执行任务。
那负载均衡器会不会也扛不住?确实有这种可能!注意事项:规模扩大后管理成本会上升、机器增多时故障概率也会增加。
存储服务器优化方案:当应用服务器扩容后,存储服务器压力也会增大。这时可以:增加机器数量(开源)、实施读写分离(节流)。实际场景中读操作频率通常高于写操作。
我们通过负载均衡将用户请求分发到多台应用服务器,实现了请求的并行处理,并能够根据业务增长动态扩展应用服务器数量以缓解压力。然而,在这种架构下,无论扩展多少台应用服务器,所有请求最终仍要访问同一数据库进行数据读写。当业务量增长到一定程度时,数据库压力便成为系统承载能力的主要瓶颈。
那么,能否像扩展应用服务器一样扩展数据库服务器呢?答案是否定的,因为数据库服务具有其特殊性:如果将数据分散到多台服务器上,数据的一致性将难以保障。所谓数据一致性,在这里指的是:对于同一个系统,无论何时何地访问,用户都应该看到统一、准确的数据。试想银行账户管理场景:如果收到一笔转账后,某个数据库更新了数据而其他数据库未更新,用户查询到的存款金额就会出现错误。
我们采用的解决方案是:保留一个主数据库作为写入节点,其他数据库作为从属数据库。从库的所有数据均来自主库,通过数据同步机制,从库能够维护与主库一致的数据状态。为了分担数据库压力,我们将所有写请求交由主库处理,而将读请求分散到各个从库中处理。
由于大多数系统中读写请求比例严重不均(例如100次读请求对应1次写请求),通过将读请求分散到多个从库,数据库的压力得到显著缓解。当然,这种方案并非没有代价——主库到从库的数据同步存在一定的时间延迟,这个问题我们暂不深入探讨。
架构示意图:
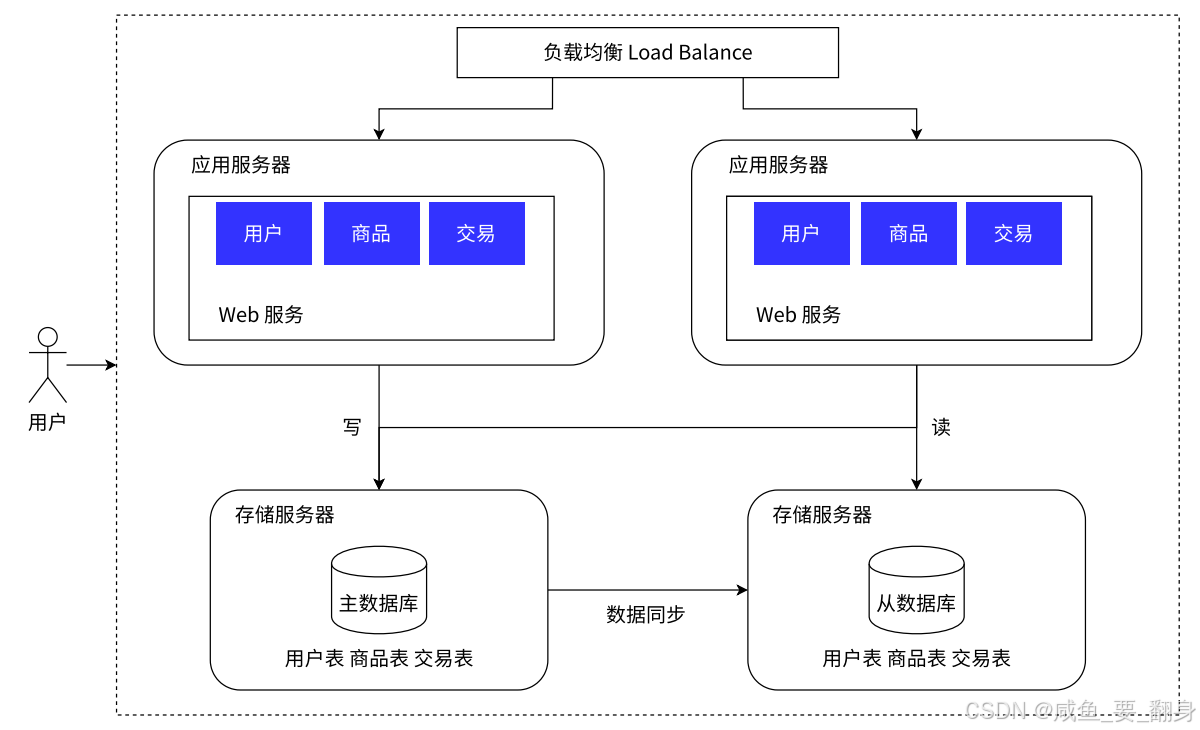
应用中需要对读写请求进行分离处理,可以借助数据库中间件来承担请求分离的职责。
通常采用一主多从的数据库架构,即一个主服务器搭配多个从服务器(上面图中左边是主(master)、右边是从(slave))。从服务器通过负载均衡机制为应用服务器提供访问支持。数据库存在响应速度较慢的固有瓶颈,为此可将数据划分为"冷数据"和"热数据"。将热点数据存入缓存能显著提升访问速度,因为缓存通常比数据库快很多。下面这一点正是讲解这方面!!!
相关软件:MyCat、TDDL、Amoeba、Cobar等数据库中间件。
二、引入缓存 —— 冷热分离架构
随着访问量继续增长,我们发现业务中部分数据的读取频率远高于其他数据(这是最主要的!!!)。这类数据被称为热点数据,与之相对的是冷数据。为了提升热点数据的读取响应速度,我们引入本地缓存和分布式缓存,缓存热门商品信息或热门商品的HTML页面等。
通过缓存机制,绝大多数读请求在到达数据库之前就被拦截,从而大幅降低数据库压力。这一架构涉及的技术包括:使用Memcached作为本地缓存,使用Redis作为分布式缓存,同时还需要解决缓存一致性、缓存穿透/击穿、缓存雪崩、热点数据集中失效等问题。
架构示意图:
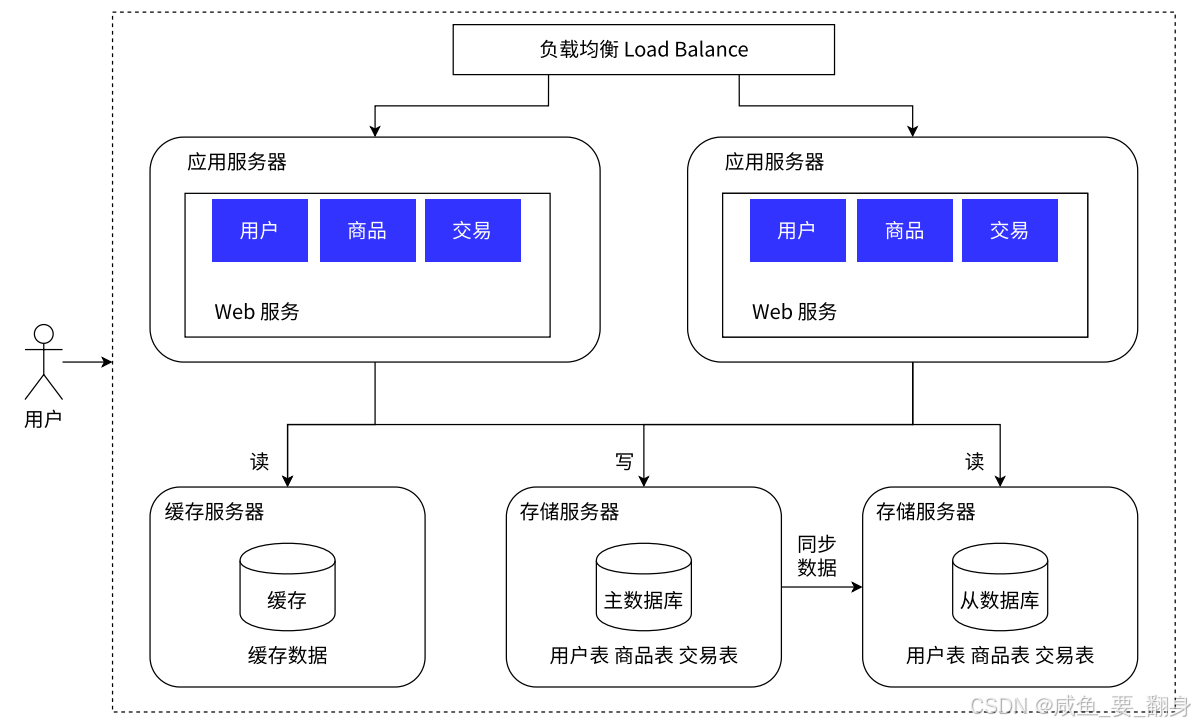
相关软件:Memcached、Redis等缓存软件。
如上图,Redis 此时,缓存服务器就能为数据库服务器分担压力!它只需存储少量热点数据即可发挥显著作用。
这一设计理念源于著名的"二八法则":20%的数据往往能支撑80%的访问量,在某些极端场景下甚至能达到"一九开"。虽然实际应用中的数据分布会有所差异,但这一规律普遍适用。
要想实现高效的缓存性能,就必须做出取舍——保持轻量!正如"欲戴王冠,必承其重"所言,缓存系统虽然存储的是完整数据的子集,却能带来显著的性能提升。
三、垂直分库
采用分布式系统不仅能应对更高的并发请求,还需要处理更大的数据规模。是否会出现单台服务器存储不足的情况?确实存在这种可能。虽然单台服务器的存储容量可达数十TB,但对于短视频等海量数据场景仍可能捉襟见肘。当单机存储达到极限时,就需要通过多台主机进行分布式存储。
此时需要对数据库进行深度拆分:
-
分库:将原本部署在单一数据库服务器上的多个逻辑数据库(通过create database创建的数据集合),分散到不同的物理服务器
-
分表:当单个数据表规模超出单机承载能力时,可对表结构进行水平或垂直拆分
具体实施方案必须紧密结合业务场景。需要特别强调的是:
-
业务需求是核心驱动力
-
技术方案是为业务服务的支撑手段
-
业务形态直接决定技术架构的选型
随着业务数据量持续增大,将所有数据存储在单一数据库中已显得力不从心。我们可以按照业务维度将数据分别存储到不同的数据库中。例如:
-
评论数据可按商品ID进行哈希分片,路由到对应的表中存储
-
支付记录可按小时分表,每个小时表继续拆分为小表,使用用户ID或记录编号进行数据路由
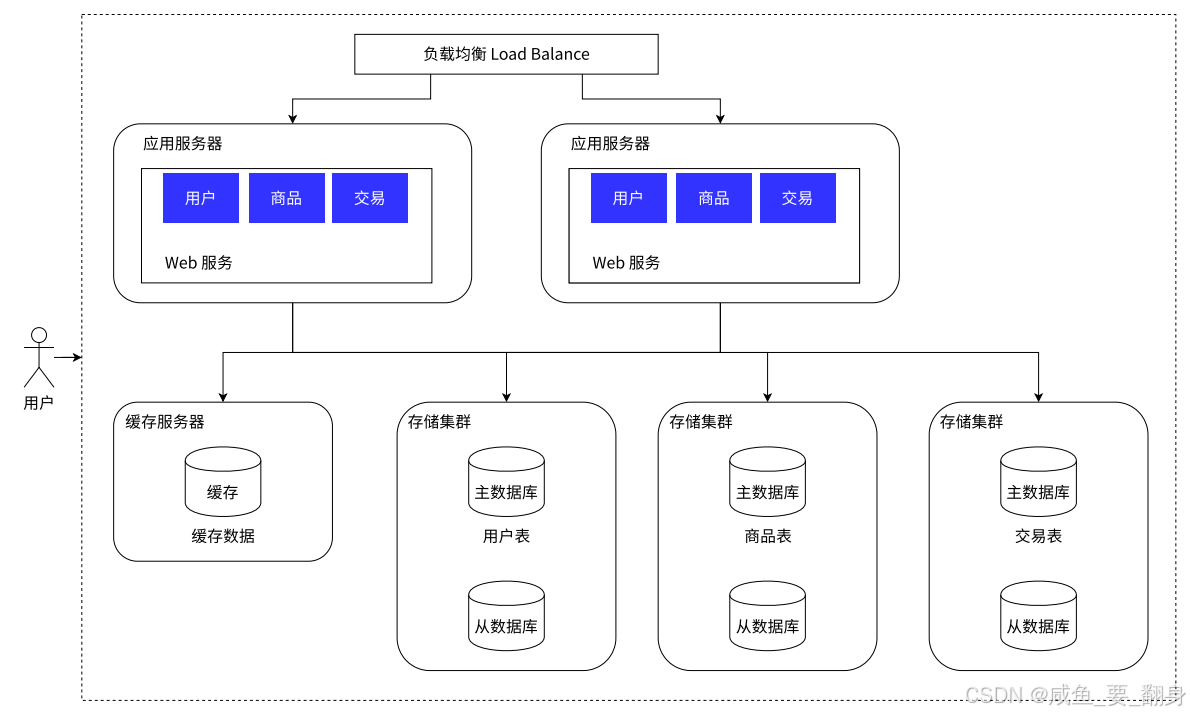
只要实时操作的表数据量足够小,且请求能够均匀分发到多台服务器上的小表,数据库就能通过水平扩展的方式提升性能。前面提到的Mycat也支持在大表拆分为小表情况下的访问控制。
这种做法显著增加了数据库运维的复杂度,对DBA提出了更高要求。当数据库设计达到这种结构时,已可称为分布式数据库。但这仍是一个逻辑上的数据库整体,其中不同组成部分由不同组件实现:
-
分库分表管理和请求分发由Mycat实现
-
SQL解析由单机数据库实现
-
读写分离可能由网关和消息队列实现
-
查询结果汇总由数据库接口层实现
这种架构实际上是MPP(大规模并行处理)架构的一种实现。
相关软件:Greenplum、TiDB、PostgreSQL XC、HAWQ等开源方案,以及GBase、雪球DB、LibrA等商业解决方案。
四、业务拆分 —— 微服务架构
随着团队规模扩大和业务发展,我们将业务分配给不同的开发团队维护,每个团队独立实现自己的微服务。通过数据访问隔离,利用Gateway、消息总线等技术实现服务间的调用关联。甚至可以将用户管理、安全管理、数据采集等通用功能提升为公共服务。
架构示意图:每个子系统都包含独立的应用集群、缓存和存储集群。
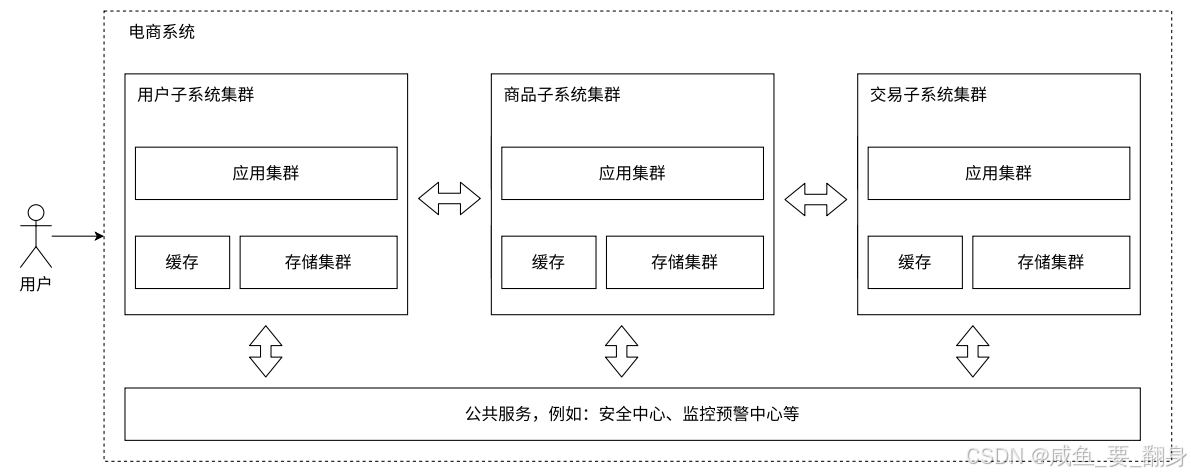
在现代应用服务器架构中,单个服务器程序往往承载过多业务功能,这会导致代码复杂度急剧上升。为提升代码可维护性,我们可以将复杂的单体服务器拆分为多个功能单一、规模较小的独立服务,这就是微服务架构的核心思想。
采用微服务架构后,服务器种类和数量会相应增加。需要特别注意的是,微服务本质上解决的是"人员管理"问题。随着业务复杂度提升,必然需要更多开发人员参与维护,而人员规模扩大后就需要相应的管理机制来协调团队协作。
何时会面临这种"人员管理"问题? 主要出现在大型企业! 对于仅有2-3名开发人员的小公司来说,采用微服务架构并无实际必要。
在组织架构层面,可以将团队划分为多个小组,每个组配备专门的管理人员。通过功能拆分,将业务划分为多组微服务,这种架构能很好地支持团队分工协作。
引入微服务虽然解决了人员管理问题,但也带来以下代价:
1. 系统性能下降:为维持性能水平,需要投入更多硬件资源(意味着更高的成本)。服务拆分后,各功能模块间的通信更依赖网络,而网络传输速度通常比硬盘读写更慢。
-
幸运的是,随着技术进步,万兆网卡已能提供超越硬盘的传输速度
-
但成本较高
2. 系统复杂度上升,可用性面临挑战:
-
服务器数量增加意味着故障概率上升
-
需要建立完善的监控报警体系和运维团队来保障系统稳定性
微服务的核心优势:
-
有效解决人员组织管理问题
-
提升功能模块的复用性
-
支持差异化部署策略
五、架构演进尾声
至此,一个相对合理的高可用、高并发系统的基本雏形已经显现。需要注意的是,上述架构演变顺序只是针对系统某个侧面的单独改进。在实际场景中,可能需要同时解决多个问题,或者系统瓶颈出现在其他方面,这时应该根据实际问题具体分析。
例如,在政府类系统中,并发量可能不大但业务复杂,高并发就不是重点解决的问题,此时更需要关注丰富业务需求的解决方案。
架构设计原则:
-
对于单次实施且性能指标明确的系统,架构设计满足系统性能指标要求即可,但要预留扩展接口
-
对于不断发展的系统(如电商平台),应设计满足下一阶段用户量和性能指标要求的架构,并根据业务增长不断迭代升级
六、大数据架构概述
所谓"大数据"其实是海量数据采集清洗转换、数据存储、数据分析、数据服务等场景解决方案的统称。每个场景都包含多种可选技术:
-
数据采集:Flume、Sqoop、Kettle等
-
数据存储:分布式文件系统HDFS、FastDFS,NoSQL数据库HBase、MongoDB等
-
数据分析:Spark技术栈、机器学习算法等
总的来说,大数据架构是根据业务需求,整合各种大数据组件而成的架构体系,一般提供分布式存储、分布式计算、多维分析、数据仓库、机器学习算法等能力。而服务端架构更多指的是应用组织层面的架构,其底层能力往往由大数据架构来提供。