k8s中Pod和Node的故事(1):过滤、打分、亲和性和拓扑分布
一、调度器的介绍
学过《操作系统》课程的计算机学生,或多或少对多核调度、事件触发、进程就绪、阻塞和挂起都有印象。那本教材用了很多章节都在讲调度的原理和算法问题,相信很多同学都头大过。
其实,这些技术体系和思想一直都在用,比如HPC场景和容器调度场景,都有调度算法和调度管理器,来平衡各种计算任务与算力资源规格的匹配问题。

有两三年,我在HPC技术领域工作,那时候不得不研究各种调度器的原理。
从现在来看,那些调度器与kubernetes中Scheduler的调度策略也没啥大的区别,首先集群都要了解各节点的健康、资源状态,同时也要对待调度的作业/Pod 需求识别清楚,最后就是匹配两者了。
在那段时间里,我用过LSF、Slurm调度器,它们都是十分好用的软件,支持各种丰富的调度策略,如先到先得、资源预留、抢占调度……。这总让我无意识地去对比容器调度器kube-scheduler。
如果读者朋友也接触过HPC领域的调度器,那么对于k8s的调度器和策略也有了解的基础了。

K8s作为一个集群软件,凭借强大的能力推动了云计算技术的前进和应用,现在各种高可用、弹性伸缩的业务底层都离不开它的能力支撑。
二、kube-scheduler如何为Pod选择最合适的Node
调度器通过 K8s 的监测(Watch)机制来发现集群中新创建且尚未被调度到节点上的 Pod。
调度器会将所发现的每一个未调度的 Pod 调度到一个合适的节点上来运行。 调度器会依据下文的调度原则来做出调度选择。
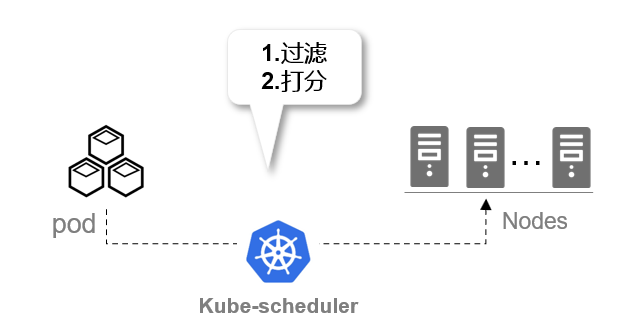
Kube-scheduler 选择一个最佳节点来运行新创建的或尚未调度(unscheduled)的 Pod。 由于 Pod 中的容器和 Pod 本身可能有不同的要求,调度程序会过滤掉任何不满足 Pod 特定调度需求的节点。
kube-scheduler 给一个 Pod 做调度选择时包含两个步骤: 1. 过滤;2. 打分。
2.1 过滤
过滤阶段会将所有满足 Pod 调度需求的节点选出来。
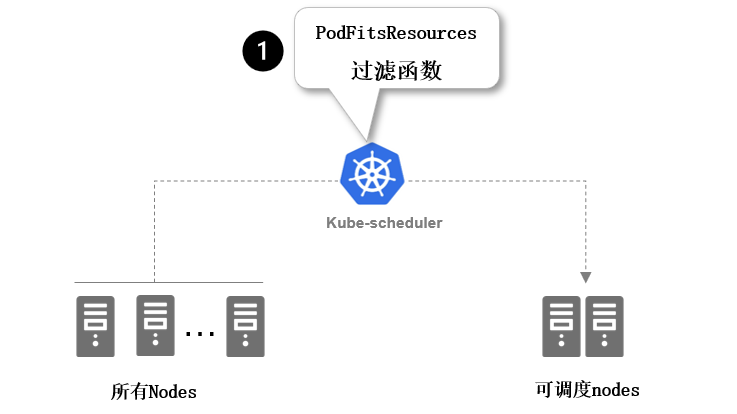
例如,PodFitsResources过滤函数会检查候选节点的可用资源能否满足 Pod 的资源请求。 在过滤之后,得出一个节点列表,里面包含了所有可调度节点;通常情况下, 这个节点列表包含不止一个节点。