数据库--数据库约束和表的设计
我们学完表的增删查改操作之后,我们就查询这个操作进行更深入的操作也就是联合查询
在进行联合查询时,我们先学习表的设计和数据库约束。
1.数据库约束
是关系型数据库的一个重要功能。主要作用时保证数据的完整性,也可以理解数据的正确性(数据本身是否正确,关联关系是否正确。)人工检查数据完整性的工作量非常之大,在数据表中定义一些约束,那么写入数据的时候,数据库会帮我们做检查工作。
约束一般是指定在列上的。
1.1约束类型
1.NOT NULL :指示某列不能存储NULL值。
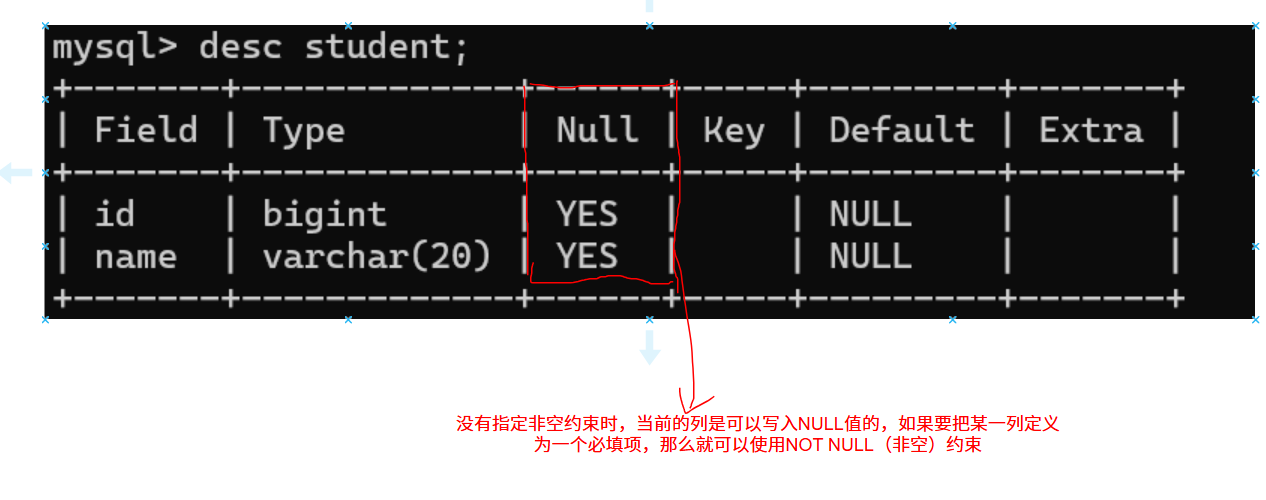
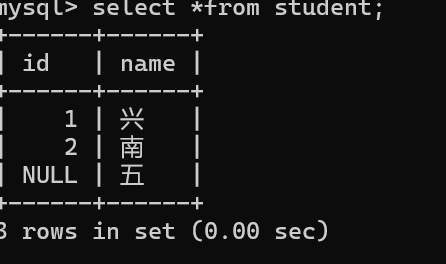
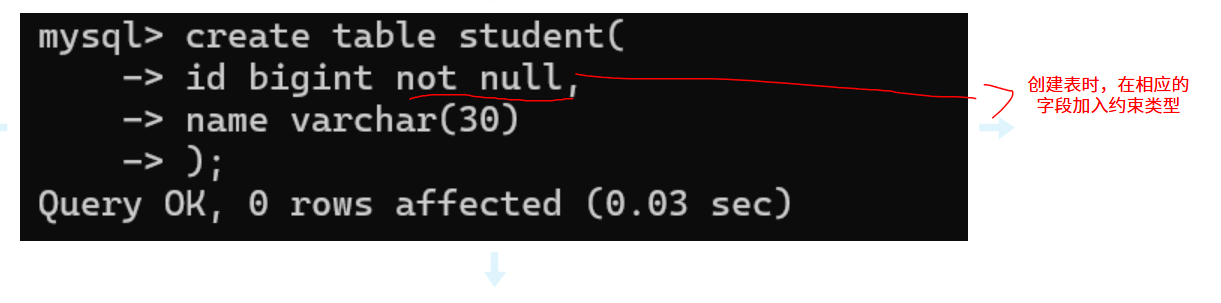
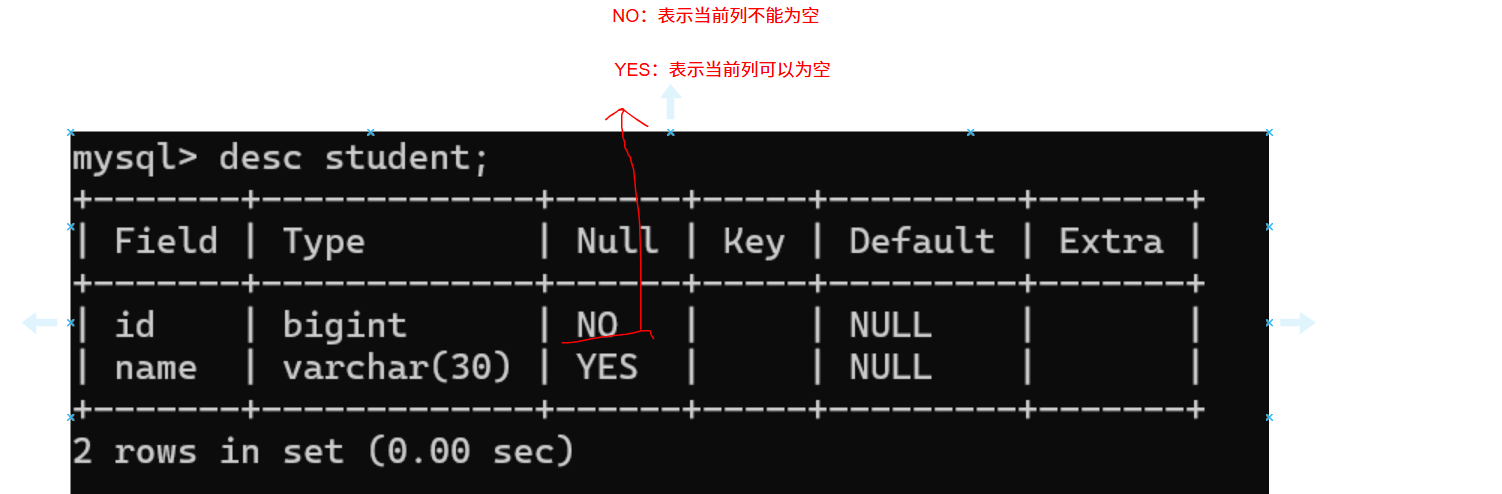

写入数据时会报错,提示不能写入NULL值,数据库帮我们做了一次校验。

非空列值时可以正常写入
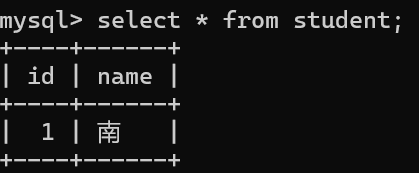
2.UNIQUE- 保证某列的每行必须有唯一的值。
某列的值在在整个表中不能重复,比如说身份证号、学号……
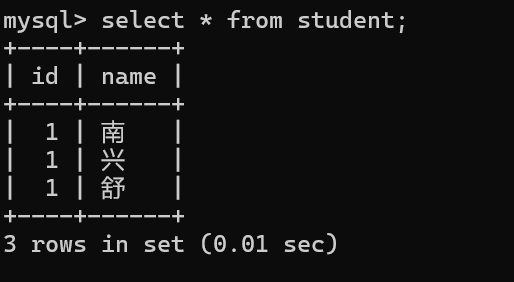
不加唯一约束的时候,可能出现编号相同,但是人名不同的情况,这是不符合逻辑的。
创建一个在ID字段加唯一约束的表。
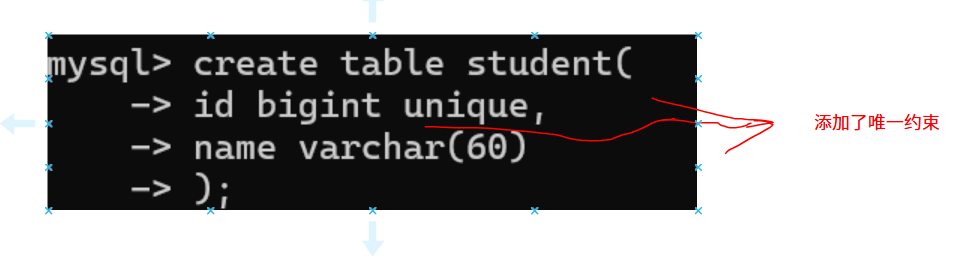
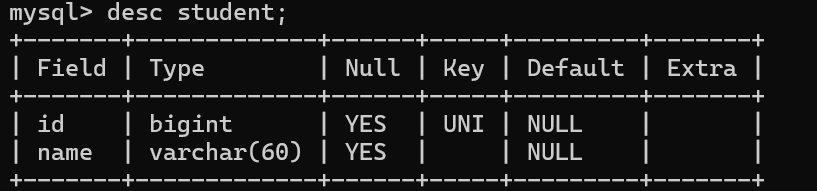
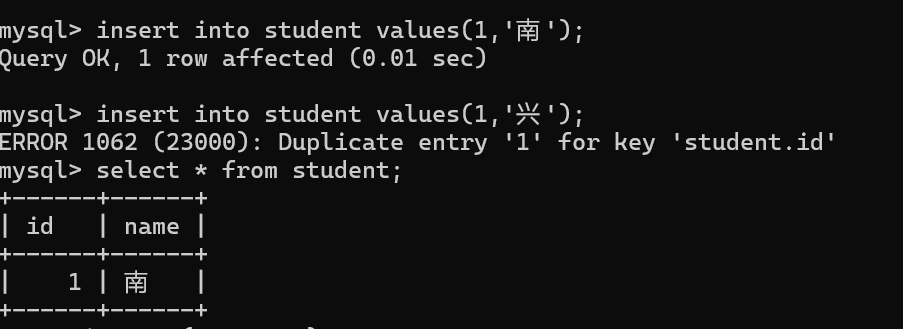

第二次插入相同ID的记录,就报错了,因为id 的列不唯一了。
但是NULL可以重复插入。
3.DEFAULT:规定没有给列赋值时的默认值。
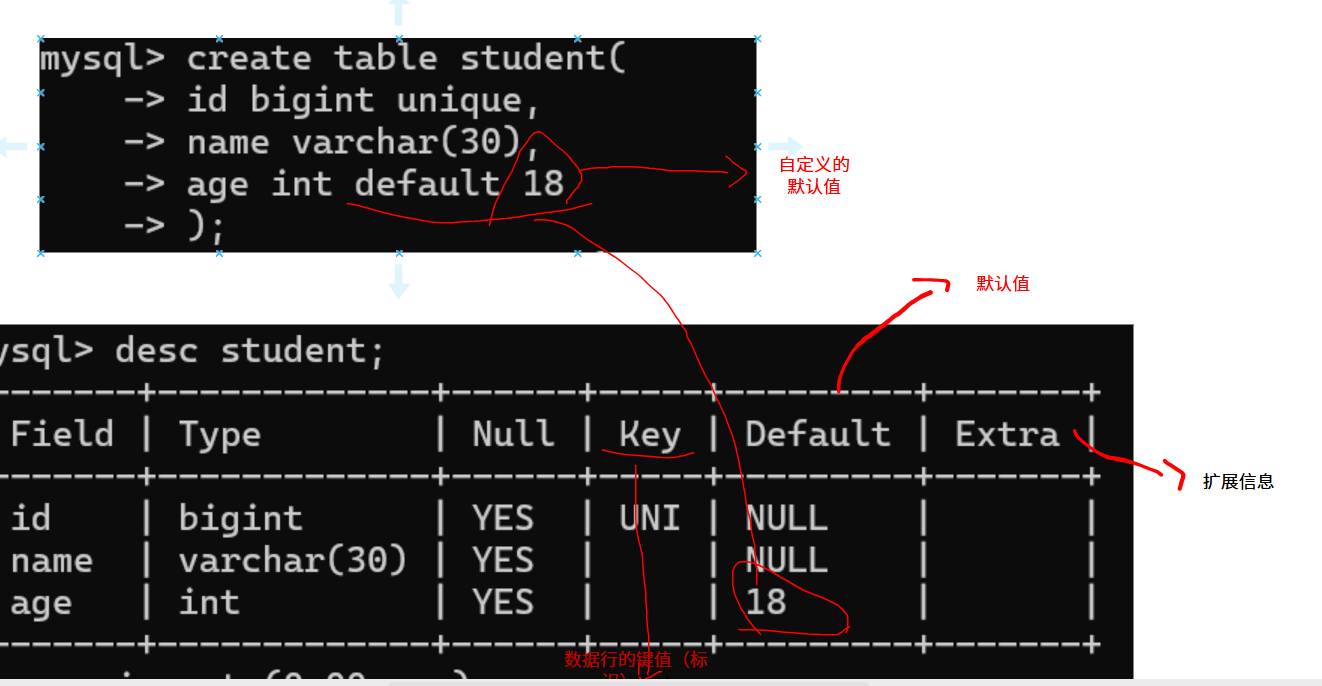
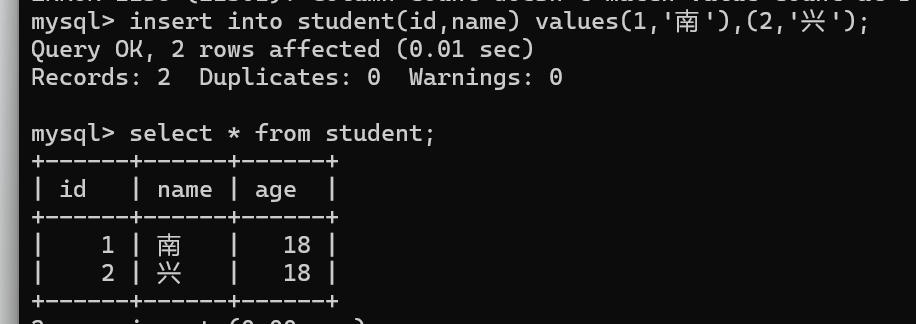
插入时指定了id和name,这时age列使用默认值填充。
当为某列设置了默认约束的时候,如果不给这个列指定值才会使用默认约束。
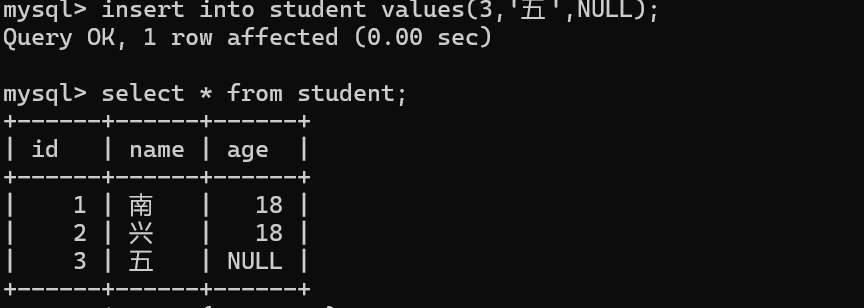
虽然指定的默认约束,但是当我们手动指定这一列的值为NULL时,插入的值依然是NULL,因为这个NULL是我们自己手动指定的,也可以理解为我们想要的值。
用户指定的优先级要高于默认约束。
4.PRIMARY KEY--NOT NULL和 UNIQUE的结合。确保某列(或两个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
主键约束的列既是非空的也是唯一的。
把表中的某一列设置成非空且唯一
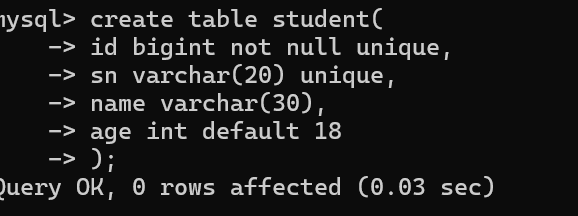
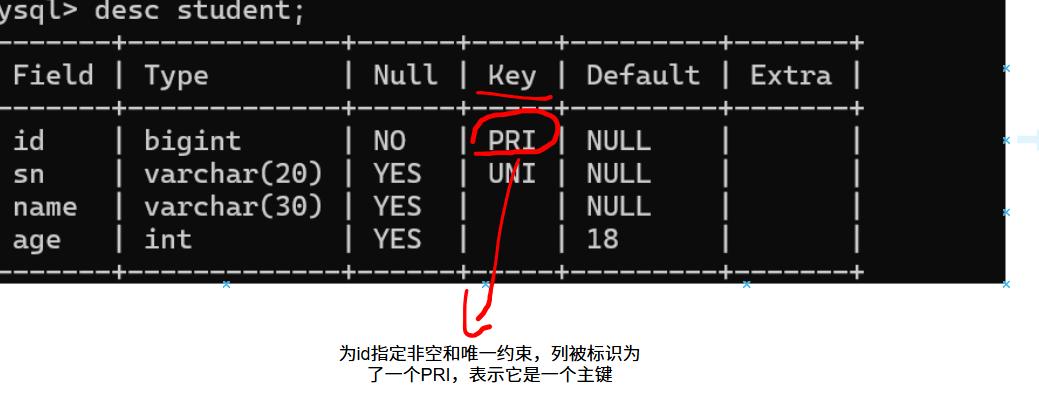

写入数据时两个约束同时生效
主键约束帮我们校验了非空和唯一,这两个校验在写入数据时效率是有一定影响,但是比起不做校验来说,这个性能消耗还是可以承担的,而且主键对后面将的索引起到了非常重要的作用。
强烈建议为每张表添加一个主键
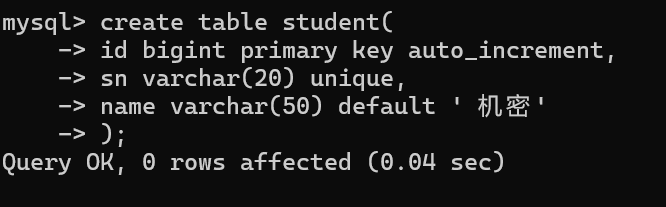
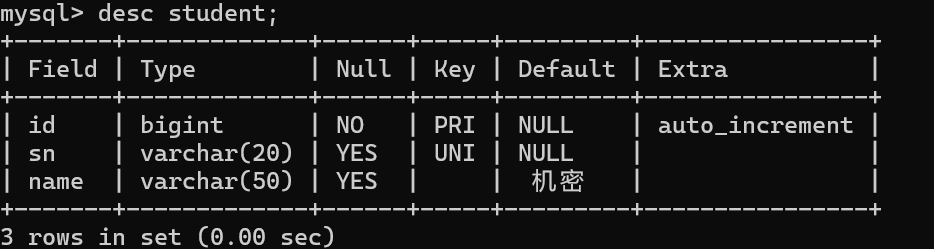
auto_increment:自增类型,表示在当前表中上一条记录的基础上加1即可
让数据库帮我们去维护主键的增长,不用程序员自己去计算了,在插入的时候先找到最大的值,然后在这个基础上加1生成一个新的值,作为新一个数据行主键(id列)的值。
在写入数据时,不具体指定主键的值,而是用NULL代替,全列插入
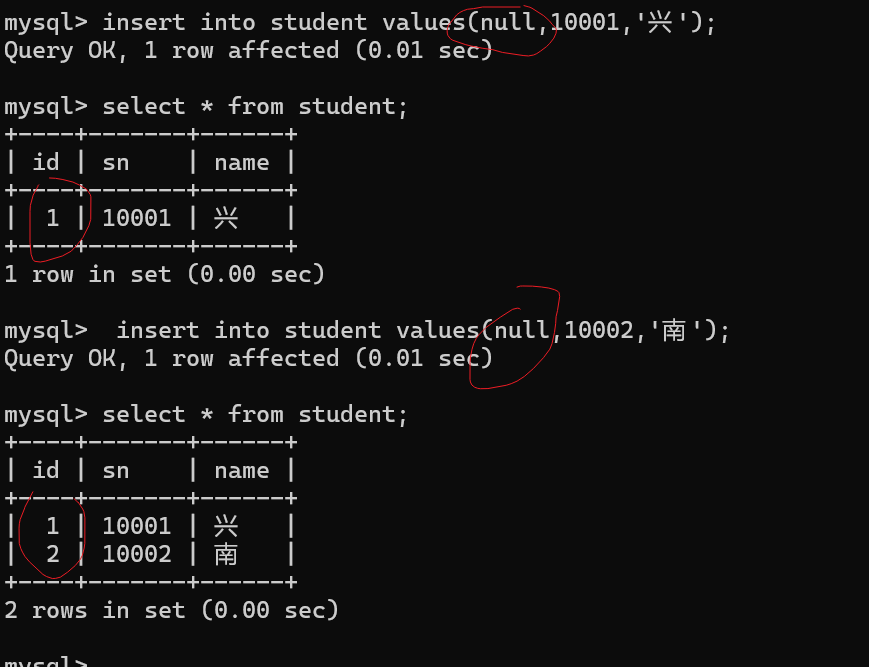
当设置了自增主键之后,发现写入NULL时,也可以成功的插入数据,这里并不是说把这个NULL写入数据库了,而是说让数据库帮我们处理这个列的值(自增操作)
指定列插入
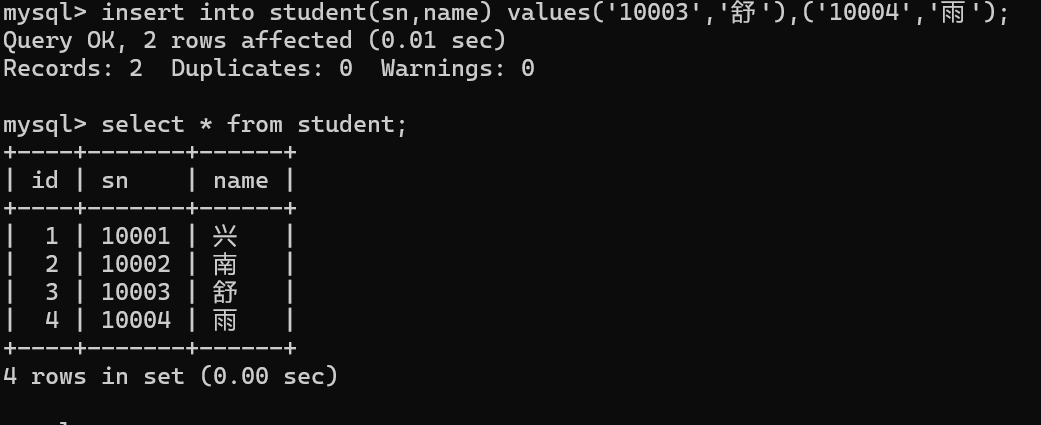
当指定列插入时,也会自动生成id,做为数据行的主键。
可不可以指定一个主键值
可以的,只要主键值不重复即可
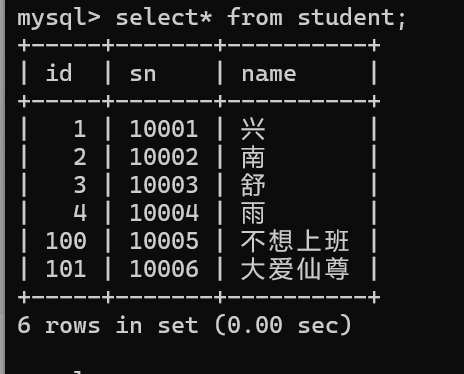
在最大值的基础删加1,那么主键值在数据表有可能是不连续的。
一个表中不允许有两个主键

一个主键同时可以包含多个列(复合主键)
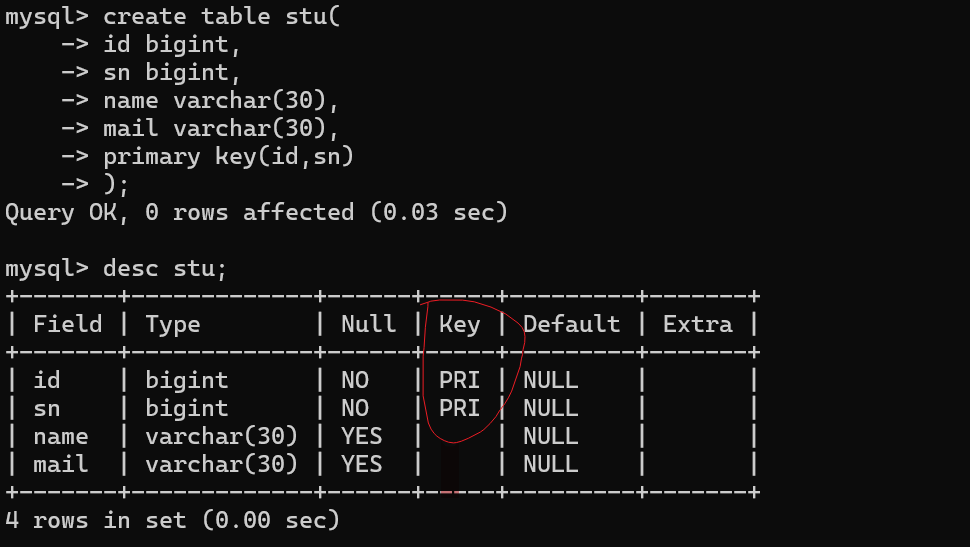
表示当前定义了复合主键,在唯一校验时,只有复合主键中所有的列都相同才被判定为相同。
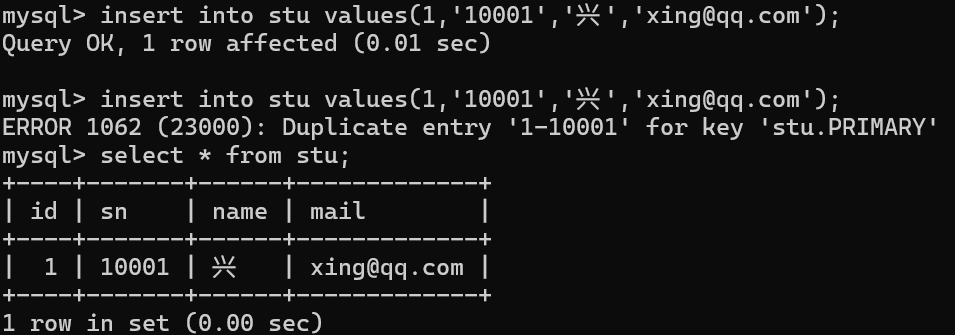
主键的值时定义复合主键时,多个列值的组合。
5.FOREIGN KEY -- 保证一个表中的数据匹配另一个表中的值的参照完整性。
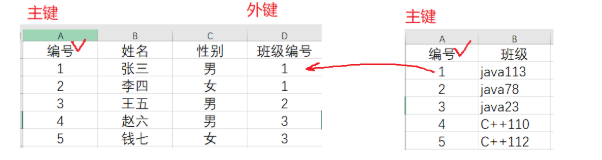
表中某个列的值,必须是另一张表中的主键列,或是唯一约束列的值,也就是当前表中的值在另一张表中必须存在,且满足主键或唯一约束。
创建班级表和学生表
学生表中有一个字段是班级编号,写入数据时这个编号必须是有效的。
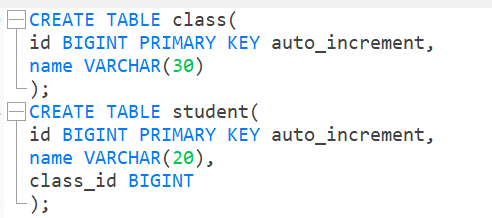
当前创建表的时候是没有设置外键关系的
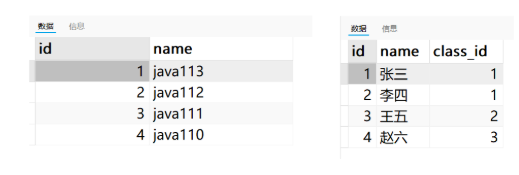

写入一条学生记录,设置了不存的班级编号,数据是可以成功写入的。
外键用于关联其他表的主键或唯一键,语法:
foreign key (字段名) references 主表(列)

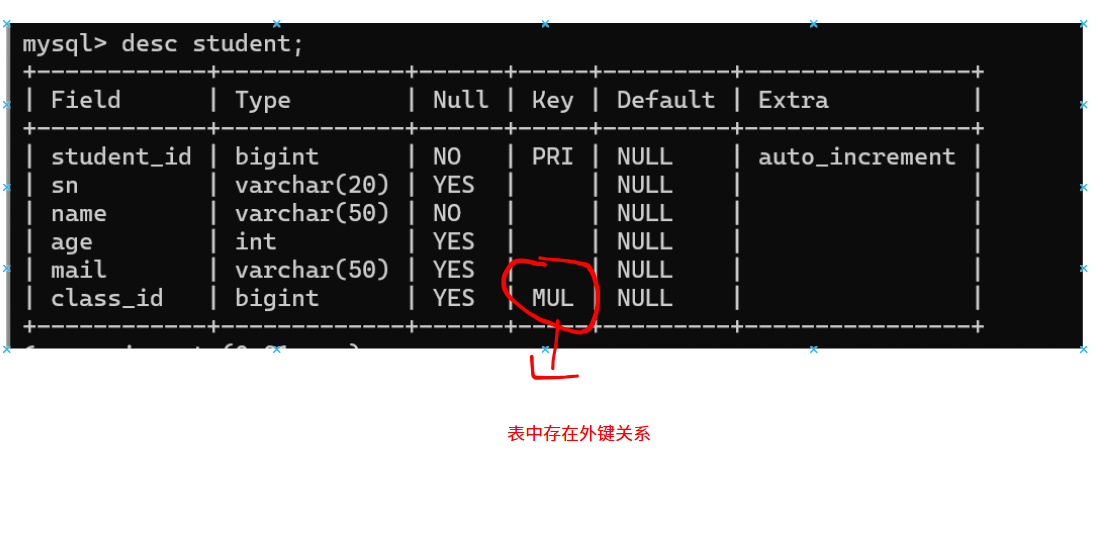

写入正确的数据的时候是可以插入成功的。
写入一条主表中不存在的id记录。
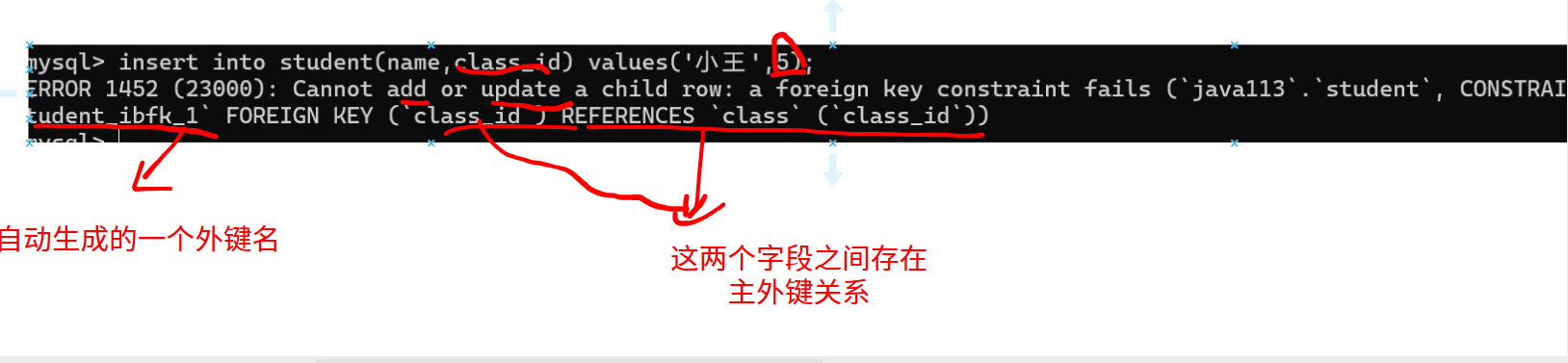
通过外键约束,保证数据的完整性和关系的正确性。
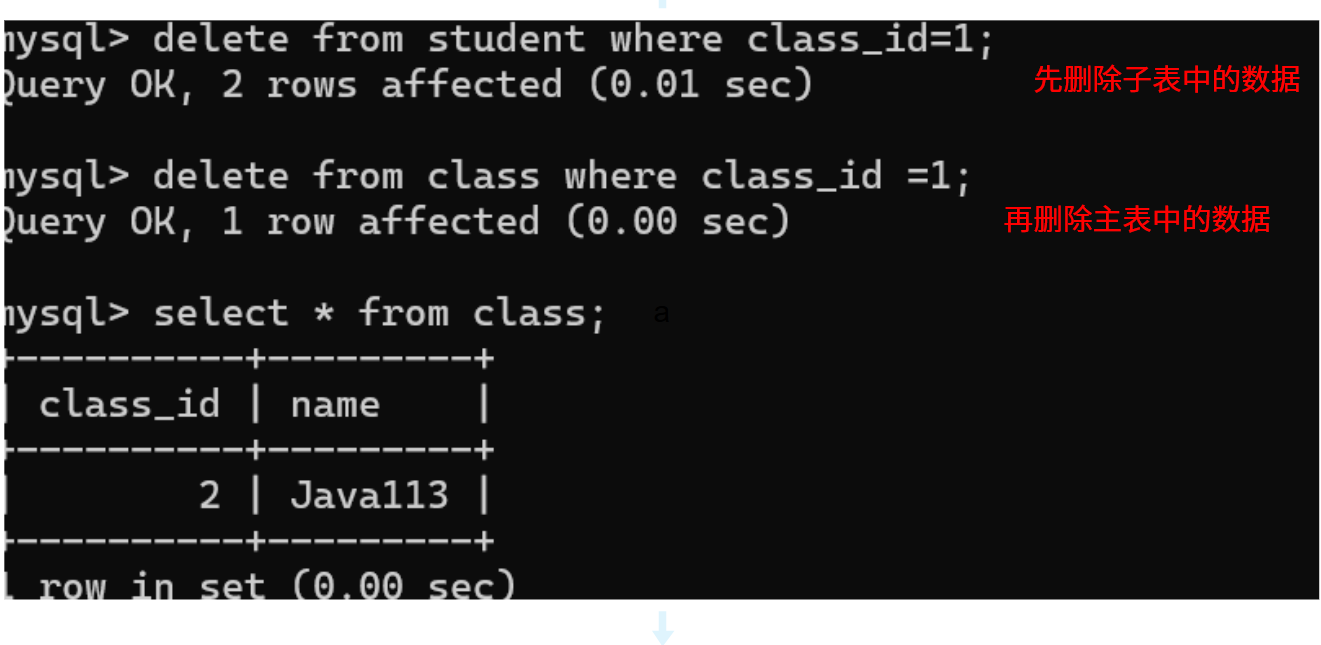
删除主表中的数据
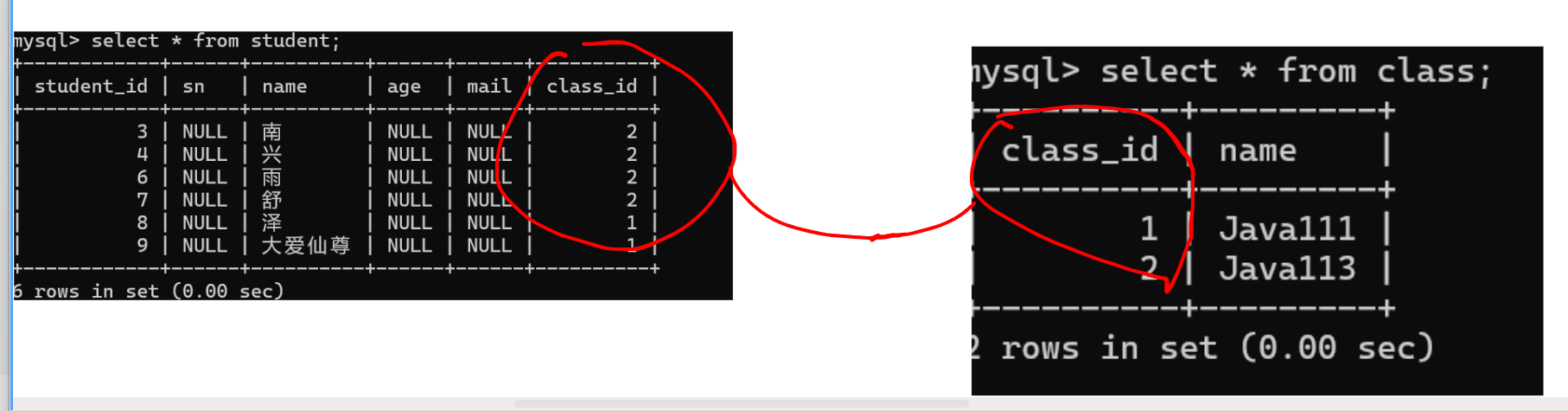
当子表中存在对主表的依赖的时候,那么能不能删除主表中相应的记录呢?

依然会报一个主外键关系的错误。
如果要删除主表中的记录,子表中不能有对该条记录的依赖,
也就意味着要先删除子表中的记录,再去删除主表中的记录。
6.CHECK- 保证列中的值符合指定的条件,对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。
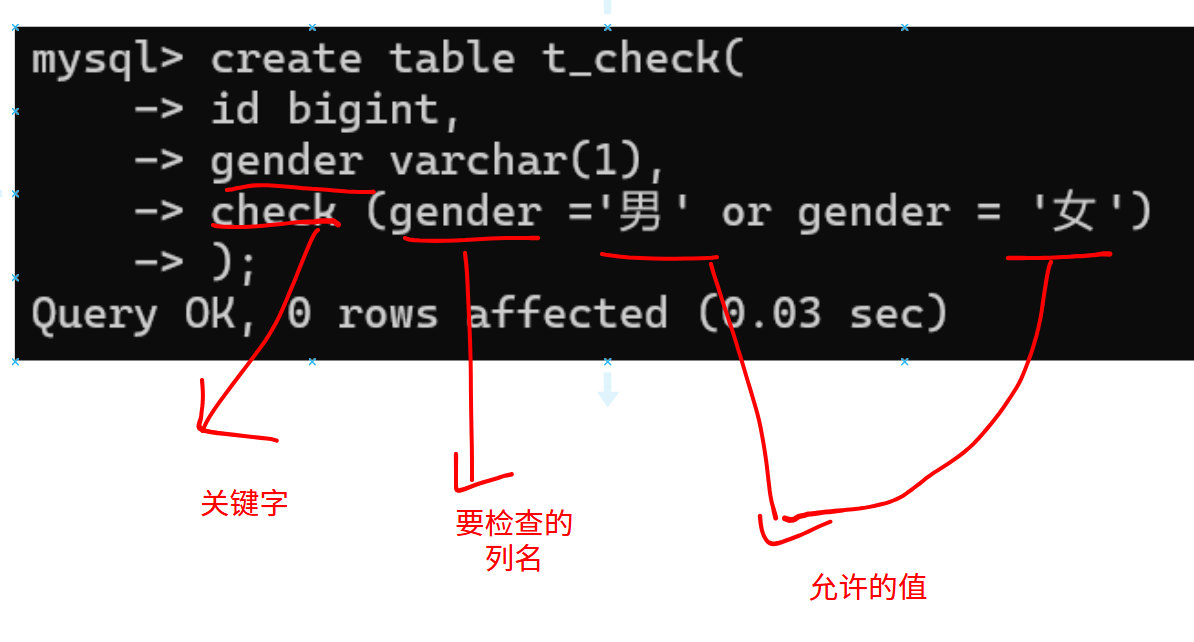
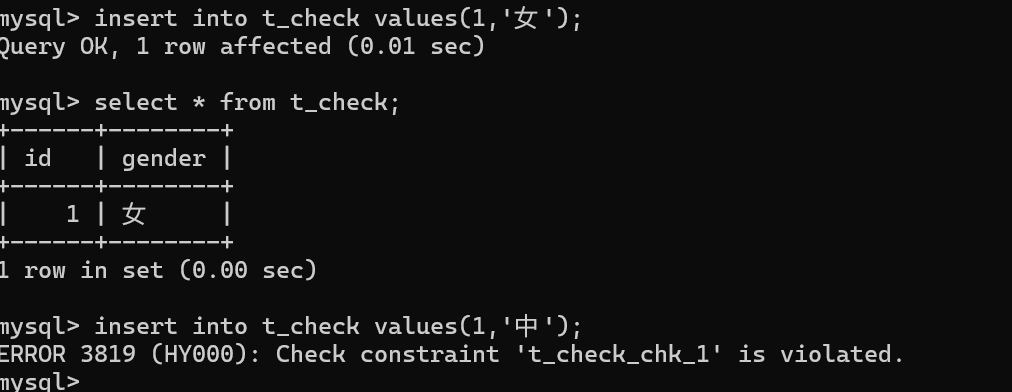
MySQL8.0中是有效的
MySQL5.7中是不生效的。
一般对数据的有效性检验是在代码层面做。
2.表的设计
OOA 面向对象分析 -->OOD 面向对象设计 -->OOP面向对象编程。
1.从需求中获得类,类对应到数据库中的实体,实体在数据库中就表现为一张一张的表,类中的属性就对应着表中的字段(列)。
2.确定类与类之间的关系。
3.使用SQL去创建具体的表。
设计表的时候会遵守一些规则,一般我们把这些规则称之为三大范式
分类:第一范式 1NF,第二范式2NF,第三范式3NF,BC 范式,BCNF
第一范式
关系型数据库的一个最基本的要求,不满足第一范式就不可以称之为关系型数据库
表里的字段不可再拆分。
描述一个学校的信息? 也可以理解为设计一个学生表。
正例:
学生表
学号,姓名,年龄,班级名,学校名,学校地址,学校电话
-- 创建学生表
create table student(
id bigint primary key auto_increment comment '学生编号',
sn varchar(20) not null comment '学号',
age int,
class_name varchar(50),
school_name varchar(70),
school_address varchar(100),
school_phone int (20)
);虽然这样不符合数据库设计的规范,但是每一列都是不可再分的,
最起码可以表明一个学生和班级、学校之间的关系。
在定义表的时候,对照到数据中的数据类型,每一个字段都可以用一个数据类型表示,那么当前这个表就天然满足第一范式。
反面例子:
学生表
学号,姓名,年龄,班级名,学校(还能进行拆分:学校名,学校地址,学校电话),而且并没有一个数据类型用来表示学校。
再比如说,我没写文档的时候,每个段落都有一个编号和标题:
1.概述 ;2.标题1;3.标题2
3.1子标题1……
可以继续拆分再关系型数据库中绝对不允许的
第二范式
再满足第一范式的基础上,不存在非关键字段对任意候选键的部分函数依赖(存在复合主键的抢矿下)。
非关键字段:可以理解为非主键字段。
候选字段:可以理解为主键、外键、没有主键时的唯一键。
复合主键:一个表中不能存在两个主键,但是一个主键中可以包含多个列。
primary key(列名,列名).
场景:学生可以选修课程,课程有相应的学分,学生考试之后会针对每一门选修的课程生成相应的成绩用数据库中的表记录学生的成绩。
正例:
学生表
学号,姓名,年龄
课程表
课程编号,课程名,学分
成绩表
学号,课程编号,成绩
这样设计,每张表都有非主键字段,都依赖于主键,满足了第二范式。
也就是说一个表中没有复合主键(主键只有一列)那么这种表天然满足第二范式。
反面例子
学生选修棵的成绩表
学号,学生姓名,年龄,课程名,学分,成绩
学生相关的信息可以通过学号来确定,学分可以通过课程来确定,成绩可以通过学生和课程共同去分,一个学生选修的课程,经过一次考试之后次啊会生成成绩;
也就是说这个表可以用学生和课程做为复合主键来确定同学当前选修棵的成绩(主要作用)
学生的姓名、年龄和课程没有关系,即学生的姓名、年龄只依赖于学号,不依赖于课程
学分与学生没有关系,即学分只依赖于课程,不依赖学生。
对于由两个或多个关键字段决定一条记录的情况,如果一行数据中有些字段只与关键字段中的一个有关系,那么这种就说明它只存在部分函数依赖。
如果有这样的情况就说明这个表不满足第二范式。
不满足第二范式可能会出现的问题
1.数据冗余
学生姓名、年龄、学分都会重复出现,造成了大量的数据冗余。
2.更新异常
如果需要调整MySQL(选修的课程)的学分,那么就需要更新所有记录中关于MySQL的记录,
如果一旦某些记录更新成功,某些更新失败,就会造成数据表中同一门课程出现不同学分的情况,表现为数据不一致。
3.插入异常
目前这样的设计,每一门课与同学的考试是对应关系,只有同学进行考试之后才会生成一条关于这门课的成绩记录,这条记录中保存了课程的学分,也就是所一门新课在学生考试之前在数据库中是没有相应记录的,因为学生成绩为空时记录是没有意义的。
4.删除异常
把毕业的同学考试成绩全部删除之后,删除记录的同时,也可能把课程对应的学分全都删除了,导致一段时间内,数据中没有课程和学分相应的信息。
第三范式3NF
在第二范式的基础上,不存在非关键字段,对任意候选键的传递依赖
正例:
根据学生与学院的关系,拆分成两张表即可
学院表
学院编号,学院名,学院地址,学院电话
学生表
学号,姓名,年龄,学员编号
这样设计,两张表都依赖于自己表中的追按,学生表可以通过外键和学院表之间建立关联关系。
第三范式可以解决数据冗余、更新异常、插入异常、删除异常的问题。
表的设计方法

1.一对一关系
比如QQ登录界面


登录成功显示的用户名
这样的场景,一般对应着两个实体,一个实体是用户(包括了学生和老师),还有一个实体是账号
一个用户只能有一个账号,一个账号只能给一个用户使用,不能共享。
在设计表之前先按上面的句式把实体之间的关系列出来。
针对一对一关系,设计表时,有两种方式
1.把两个实体所有的信息全都放在一张表里
user(user_id,name,age,phone,mail,username,password)
2.创建两张表,分别记录用户信息与账号信息,并把两张表做关联
第一张关联方法
user(user_id,name,age,phone,mail);
create table users (id bigint primary key auto_increment,name varchar(20) not null, nickname varchar(20),phone_num varchar(11), email varchar(50),gender tinyint(1)
);create table account (id bigint primary key auto_increment,username varchar(20) not null,password varchar(32) not null,users_id bigint
);account(account_id,username,password,user_id);
第二种关联方法
user(user_id,name,age,phone,mail,account_id);
account(account_id,username,password);
create table users (id bigint primary key auto_increment,name varchar(20) not null, nickname varchar(20),phone_num varchar(11), email varchar(50),gender tinyint(1),account_id bigint
);
create table account (id bigint primary key auto_increment,username varchar(20) not null,password varchar(32) not null
);2.一对多关系
学生和班级之间的关系,
一个学生只能存在于一个班级,一个班级中可以有多个学生。

分别为不同的实体创建表
学生表、班级表,创建表之后建立表与表之间的关联关系
create table class(
class_id bigint primary key auto_increment,
name varchar(60)
);
create table student(
student_id primary key auto_increment,
name varchar(60),
age int,
class_id bigint,
foreign key(class_id) references class(class_id)
);通过学生记录中的class_id可以表示学生在哪个班级。
3.多对多关系
一个学生可以选择多门课程
一门课程也可以被多名学生选修
1.分别创建实体表
course(course_id,name);
1 MySQL
2 Java
student(student_id,name, age);
1 南 19
2 兴 20
2.创建关系表,在关系表中为实体之间创建关联关系
student_course(id,student_id,course_id)
1 1 1 南选修了Java课程
2 2 2 兴选修了MySQL课程
通过关系表,就可以把学生修改的课程清楚的记录下来,这样设计同时也满足了第二范式的要求,发现要修改学生的年龄只需要修改学生表中的年龄字段即可,不会影响到关系表。
创建班级表、学生表、课程表、成绩表以及它们之间的关联关系
-- 创建班级表
create table class(
class_id bigint primary key auto_increment,
name varchar(60)
);
-- 创建学生表
create TABLE student(
student_id bigint primary KEY auto_increment,
sn varchar(20),
name varchar(50) not null,
age int,
mail VARCHAR(50),
class_id bigint,
FOREIGN KEY(class_id) REFERENCES class(class_id)
);
create TABLE course(
course_id bigint primary key auto_increment,
name VARCHAR(90)
);
create table score(
score_id bigint primary key auto_increment,
score float,
course_id bigint,
student_id bigint,
FOREIGN KEY(course_id)REFERENCES course(course_id),
FOREIGN KEY(student_id)REFERENCES student(student_id)
);到这里我们的博客就结束,在下章的博客就要开始我们的联合查询了。
感谢各位同道中人的观看与捧场,在这里谢谢大家的支持和喜爱!