达梦数据库常用初始化参数与客户端工具使用
文章目录
- 1概述
- 2初始化参数
- 2.1CASE_SENSITIVE参数
- 2.1.1对表名的影响
- 2.1.2对表中字段名的影响
- 2.1.3对表中数据的影响
- 2.1.4与Oracle、MySQL异同
- 2.2CHARSET与LENGTH_IN_CHAR参数
- 2.3BLANK_PAD_MODE参数
- 3数据库客户端
- 3.1DISQL
- 3.2达梦管理工具(DM Manager)
- 3.3百灵(SQLark)
1概述
在部署数据库前我们需要确认数据库的字符集CHARSET和大小写敏感CASE_SENSITIVE这两个参数,在2024年第二季度以前的版本还可以设置LENGTH_IN_CHAR(VARCHAR类型长度是否以字符为单位)参数,这些初始化参数在实例初始化后不可修改,需要重新初始化再使用逻辑还原或者使用DTS工具进行迁移。不同的参数值会有不一样的现象,在初始化前需要先确认清楚需求。
2初始化参数
2.1CASE_SENSITIVE参数
CASE_SENSITIVE参数用来指定是否大小写敏感,默认为1表示大小写敏感;0为大小写不明感。接下来看一下不同的CASE_SENSITIVE对表名、字段名、字段值的影响。
初始化一个大小写不敏感的数据库实例:
cd /home/dmdba/dmdbms/bin
./dminit path=/dmdata page_size=32 extent_size=32 charset=1 CASE_SENSITIVE=0 log_size=2048 db_name=dmdba instance_name=dmdba SYSDBA_PWD="密码" SYSAUDITOR_PWD="密码" PORT_NUM=5236
再初始化一个大小写敏感的数据库实例:
cd /home/dmdba/dmdbms/bin
./dminit path=/dmdata page_size=32 extent_size=32 charset=1 CASE_SENSITIVE=1 log_size=2048 db_name=dmdb_test instance_name=dmdb_test SYSDBA_PWD="密码" SYSAUDITOR_PWD="密码" PORT_NUM=15236
可以都注册为服务,注册服务需要使用root用户执行:
cd /home/dmdba/dmdbms/script/root/
./dm_service_installer.sh -t dmserver -p dmdb_test -dm_ini /dmdata/dmdb_test/dm.ini
用dmdba用户启动实例:
su - dmdba
cd /home/dmdba/dmdbms/bin
./DmServicedmdb_test start
2.1.1对表名的影响
在大小写不敏感(CASE_SENSITIVE=0)的实例中,创建一张表并插入几条测试数据:
CREATE TABLE TEST.Aa1
(
"FID" INT,
"FDESC" VARCHAR2(200)
);
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'A');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'a');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'Aa');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'aA');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'aa');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'AA');
在DM管理工具可以看到:
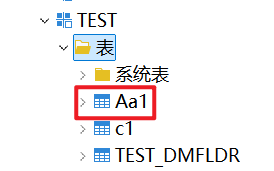
查询表中数据:
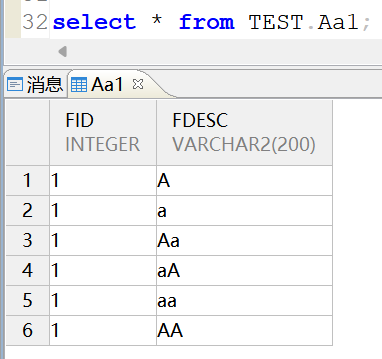
现在进行验证:
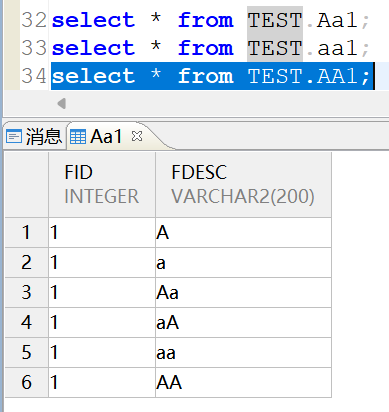
在大小写不敏感(CASE_SENSITIVE=0)的实例中:表名不区分大小写,大小写混用也可以查出来,无需与创建的表名大小写一致。
select * from TEST.Aa1;
select * from TEST.aa1;
select * from TEST.AA1;
select * from TEST."aa1"; -- 也可以查出来
select * from TEST."AA1";-- 也可以查出来
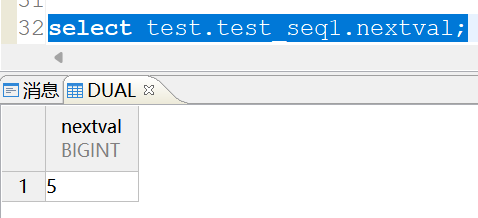
此外,除了表名其他数据库对象也不区分大小写,比如我创建了一个全大写的序列:TEST_SEQ1,然后使用以下大小写混合或者全小写的方式都可以访问到
select TEST.test_seq1.NEXTVAL;
select test.test_seq1.NEXTVAL;
select test.test_seq1.nextval;
在大小写敏感(CASE_SENSITIVE=1)的实例中,也同样创建一张相同的表并插入几条测试数据:
CREATE TABLE TEST.Aa1
(
"FID" INT,
"FDESC" VARCHAR2(200)
);
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'A');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'a');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'Aa');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'aA');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'aa');
insert into TEST.Aa1(FID, FDESC) VALUES(1, 'AA');
然后再DM管理工具可以看到会在创建的时候将表名转换成大写:
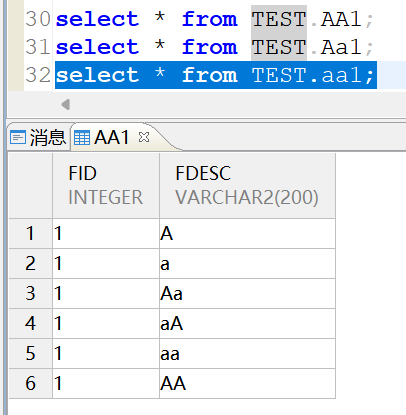
并且在查询的时候也会自动将select from中的对象名转换为大小所以可以查到对应的表:
select * from TEST.AA1;
select * from TEST.Aa1;
select * from TEST.aa1;
这些语句都可以查到内容:
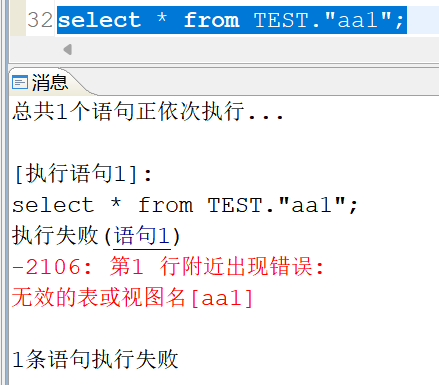
如果只想查小写的表名那么就在表名前后加一个英文的双引号:
select * from TEST.“aa1”; – 加了双引号表示不做转换
由于是大小写敏感所以这种查不出来:
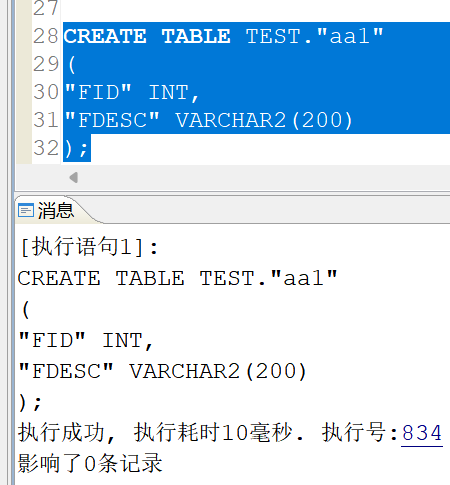
如果再创建一个全是小写的表:
CREATE TABLE TEST."aa1"
(
"FID" INT,
"FDESC" VARCHAR2(200)
);
发现可以创建成功并没有提示表名冲突:
此时可以看到有两张大小写不一致的表:
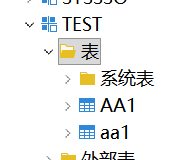
然后下面的查询才能成功执行:
select * from TEST."aa1";
总结:在大小写不敏感(CASE_SENSITIVE=0)时,表名不区分大小写,即使表名加了双引号还是不区分大小写;在大小写敏感(CASE_SENSITIVE=1)时,在执行查询的时候会自动转换为大写表名,不加双引号查询时体验上是一致的,如果加了双引号则必须与该表大小写一致才能查询出结果。
2.1.2对表中字段名的影响
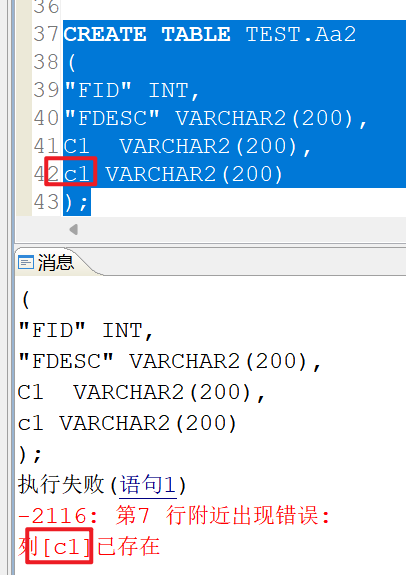
在大小写不敏感(CASE_SENSITIVE=0)的实例中,创建一张表:
CREATE TABLE TEST.Aa2
(
"FID" INT,
"FDESC" VARCHAR2(200),
C1 VARCHAR2(200),
c1 VARCHAR2(200)
);
提示c1已存在:
如果在字段中添加双引号会不会成功呢?
CREATE TABLE TEST.Aa2
(
"FID" INT,
"FDESC" VARCHAR2(200),
"C1" VARCHAR2(200),
"c1" VARCHAR2(200)
);
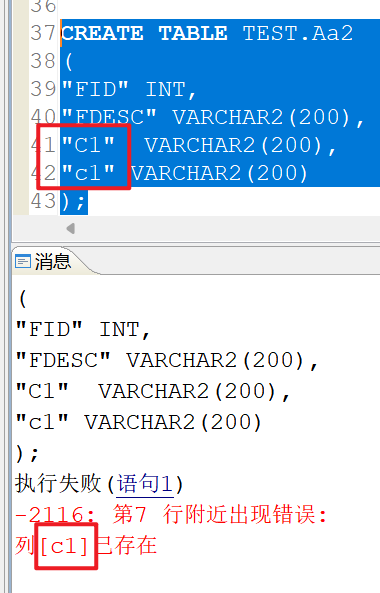
可以看到还是失败,因为大小写不敏感所以c1和C1其实是相同的所以提示字段已存在。
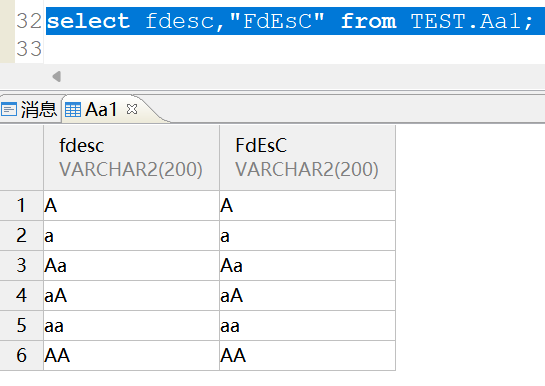
在查询的时候字段也是不区分大小的:
select fdesc,"FdEsC" from TEST.Aa1;
在大小写敏感(CASE_SENSITIVE=1)的实例中,创建一张表:
CREATE TABLE TEST.Aa2
(
"FID" INT,
"FDESC" VARCHAR2(200),
C1 VARCHAR2(200),
c1 VARCHAR2(200)
);
提示C1已存在:
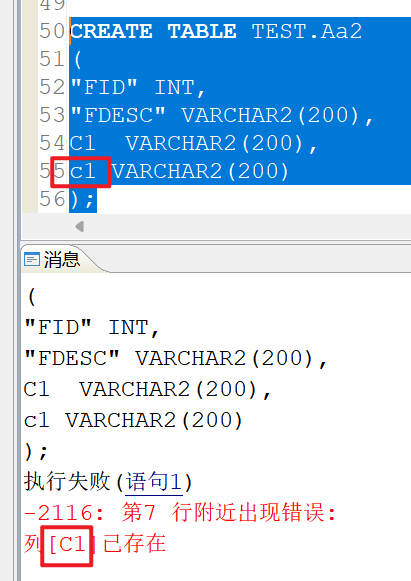
为什么提示的是大写的C因为大小写敏感的情况下,对象名会先转换为大写再进行后续的操作。
CREATE TABLE TEST.Aa2
(
"FID" INT,
"FDESC" VARCHAR2(200),
"C1" VARCHAR2(200),
"c1" VARCHAR2(200)
);
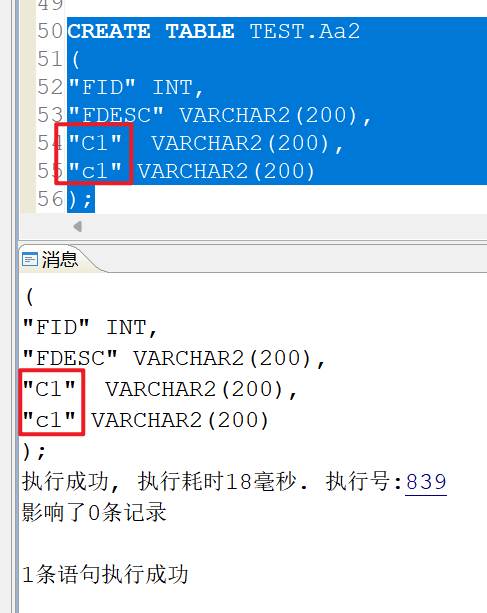
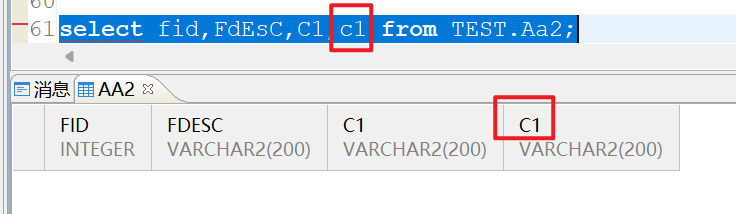
可以看到在大小写敏感的时候,如果字段加了引号就不会转换为大写了,字段c1和C1是不一样的,查询的时候也需要加上引号才能区分,不然查出来的就可能不是你想要的:
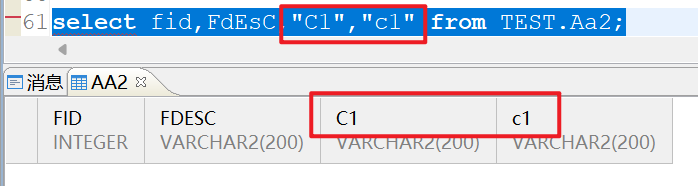
这样才能正确查出来想要的字段:
总结:在大小写不敏感(CASE_SENSITIVE=0)时,字段名不区分大小写,大写一致则认为是相同的字段;在大小写敏感(CASE_SENSITIVE=1)时,在执行查询的时候会自动转换为大写字段名,如果加了双引号则必须与该表大小写一致才能查询出结果。
2.1.3对表中数据的影响
在两个实例中均创建了TEST.Aa1表,其中的全部数据如下:
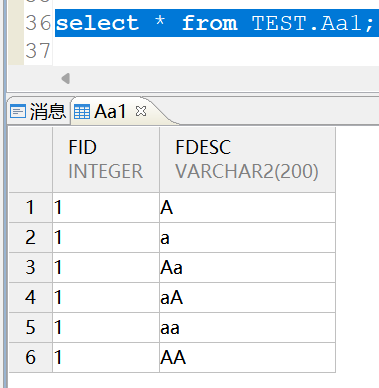
在两个实例中均查询fdesc等于aa的记录:
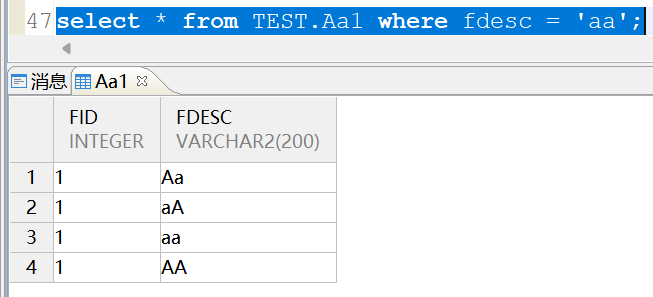
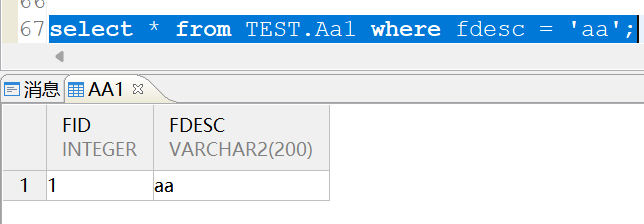
select * from TEST.Aa1 where fdesc = 'aa';
在大小写不敏感(CASE_SENSITIVE=0)的实例中,表中的数据是不区分大小写的,所以查询aa的时候可以查到Aa、aA、aa、AA:
在大小写敏感(CASE_SENSITIVE=1)的实例中,表中的数据是严格区分大小写的,查询aa的时候只能查到aa:
2.1.4与Oracle、MySQL异同
在MySQL中大小写敏感是使用lower_case_table_names进行指定的,安装在在Windows环境下默认为1,Linux系统下默认为0。比如在Linux环境下不指定这个参数的话表名是区分大小写的,字段名和表中数据是不区分大小写的,因此在如果需要从MySQL(postgresql也一样)迁移数据过来的话需要留意CASE_SENSITIVE是否要需要设置为0。
在Oracle中表名、字段名、函数名是不区分大小写的,但是表中的数据是区分大小写的,也就是说查某个字段为a的记录可以查出A和a两种记录。因此,如果源库是Oracle的话需要设置CASE_SENSITIVE=1。
SQL Server也和Oracle一样表名、字段名、函数名是不区分大小写的,但是表中的数据是区分大小写的。
2.2CHARSET与LENGTH_IN_CHAR参数
CHARSET是用来指定数据库的字符集,初始化后不可修改可选3个值,分别是0:GB18030(GBK,默认值);1:UTF-8;2:EUC-KR(韩文字符集)。
不同的字符集可以存储的字符范围不一样,占用的字节长度也不一样以及字符默认排序也不一样。需要看应用场景,如果会用到一些生僻字或者特殊的表情符号比如emoji就需要使用UTF-8,如果涉及到迁移的话要与原库一致。
LENGTH_IN_CHAR表示是否以字符为单位计算字段长度,目前已废弃,无法进行设置,LENGTH_IN_CHAR只能为0,表示以字节为单位计算长度,也就是说建表的时候指定的长度。由于这个参数不能设置了,所以如果是旧版本的数据并且LENGTH_IN_CHAR为1那么就不能通过逻辑备份和物理备份进行迁移到新版的数据库了,因为长度计算方式不一样迁移的时候可能会报错字段超长,只能用DTS在迁移的时候进行批量放大字段长度,具体要放大多少倍还要看是什么字符集。
创建一个字符集为UTF-8的实例:
cd /home/dmdba/dmdbms/bin
./dminit path=/dmdata page_size=32 extent_size=32 charset=1 CASE_SENSITIVE=0 log_size=2048 db_name=dmdba_c1 instance_name=dmdba_c1 SYSDBA_PWD="密码" SYSAUDITOR_PWD="密码" PORT_NUM=15236
再创建一个字符集为GBK的数据库实例:
cd /home/dmdba/dmdbms/bin
./dminit path=/dmdata page_size=32 extent_size=32 charset=0 CASE_SENSITIVE=0 log_size=2048 db_name=dmdba_c0 instance_name=dmdba_c0 SYSDBA_PWD="密码" SYSAUDITOR_PWD="密码" PORT_NUM=25236
使用前台的方式启动就不用注册服务了:
dmserver /dmdata/dmdba_c0/dm.ini
dmserver /dmdata/dmdba_c1/dm.ini
在两个实例上创建一张测试表:
CREATE TABLE "TEST"."TABLE_1"("C1" VARCHAR(5),"C2" VARCHAR(6));
在字符集为GBK(CHARSET=0)的实例,我们往表中插入一条数据:
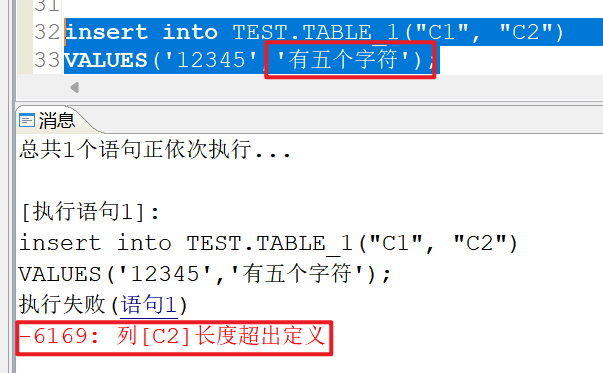
可以看到非汉字的字符串,如果字段长度是5的话可以插入5个字符,如果是汉字的话是不能插入5个字符的,所以汉字等特殊字符和英文、数字字符占用的长度是不一样的。我们使用lengthb函数可以判断VARCHAR字段的内容实际占用的字节大小,使用length函数可以查询VARCHAR字段的字符个数。
插入以下3行数据:
insert into TEST.TABLE_1("C1", "C2") VALUES('1','你');
insert into TEST.TABLE_1("C1", "C2") VALUES('12','你好');
insert into TEST.TABLE_1("C1", "C2") VALUES('123','你好啊');
执行以下查询可以看到在GBK字符集下,汉字占用两个字节:
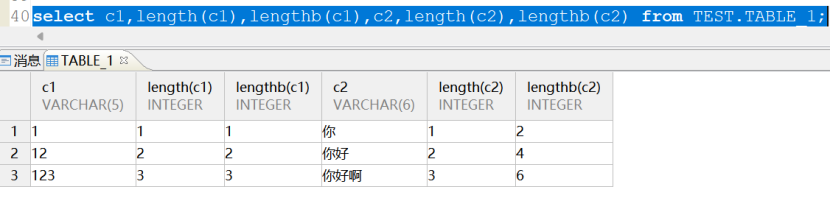
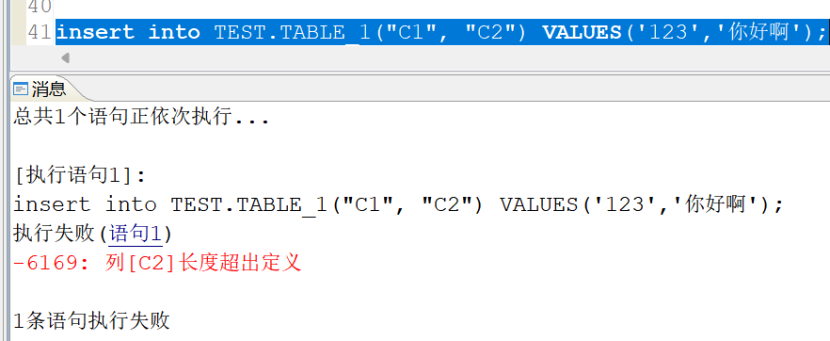
在字符集为UTF-8(CHARSET=1)的实例,我们同样创建并插入数据:发现前两条可以插入,但是字段长度为6的C2字段不能插入3个中文字符
说明字符集不一样汉字占用不一样的字节长度,建字段的时候长度是以字符为单位计算的,查看表中各个字段占用的字节长度:
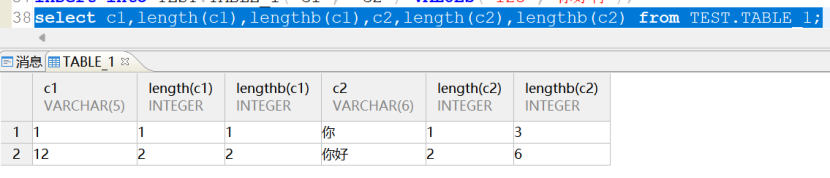
可以看到在字符集为UTF-8时,一个汉字字符占用3个字节长度,所以3个字符占用9个字节自然就不能插入6个字节长度限制的c2字段中。
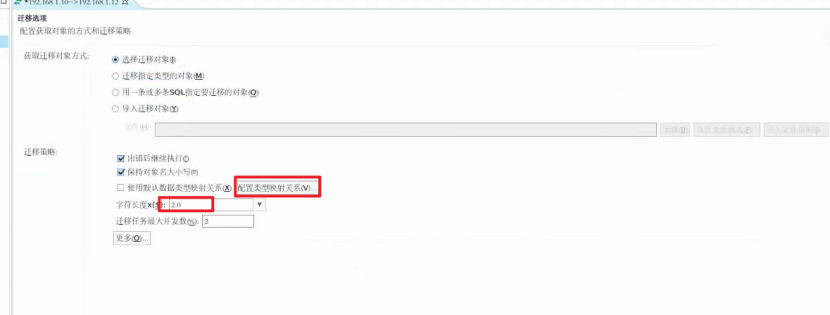
总结:如果要存生僻字等特殊字符,字符集要选用UTF-8;如果需要进行数据迁移,那么需要关注原库的LENGTH_IN_CHAR参数是否为1,如果是1也就是用字符计算字段长度的话就不能要备份还原的方式进行迁移,需要使用DTS进行迁移,迁移的时候可以选择放大的倍数,并配置映射关系,配置VARCHAR放大倍数,具体倍数还要看是什么字符集,如果是原库是GBK字符集,则需要放大2倍的长度,如果是UTF-8则放大3倍。
2.3BLANK_PAD_MODE参数
BLANK_PAD_MODE参数是设置空格填充模式,数据库初始化设置的值可以通过以下命令进行查询:
select '空格兼容模式',para_value from v$dm_ini where para_name='BLANK_PAD_MODE';
默认值为0,表示比较字符时忽略末尾空格的差异,那么“a”和“a ”是相等的;BLANK_PAD_MODE=1时表示会区分末尾的空格,也就说比较的时候“a”和“a ”是不一样的。
创建一个BLANK_PAD_MODE=0的实例:
cd /home/dmdba/dmdbms/bin
./dminit path=/dmdata page_size=32 extent_size=32 BLANK_PAD_MODE=0 charset=1 CASE_SENSITIVE=0 log_size=2048 db_name=dmdba_b0 instance_name=dmdba_b0 SYSDBA_PWD="密码" SYSAUDITOR_PWD="密码" PORT_NUM=15236
再创建一个BLANK_PAD_MODE=1的实例:
cd /home/dmdba/dmdbms/bin
./dminit path=/dmdata page_size=32 extent_size=32 BLANK_PAD_MODE=1 charset=0 CASE_SENSITIVE=0 log_size=2048 db_name=dmdba_b1 instance_name=dmdba_b1 SYSDBA_PWD="密码" SYSAUDITOR_PWD="密码" PORT_NUM=25236
使用前台的方式启动就不用注册服务了:
dmserver /dmdata/dmdba_b0/dm.ini
dmserver /dmdata/dmdba_b1/dm.ini
在两个实例中创建测试表并插入数据:
CREATE TABLE "TEST_B"("C1" VARCHAR(5));insert into SYSDBA.TEST_B("C1") VALUES('aa');
insert into SYSDBA.TEST_B("C1") VALUES(' aa');
insert into SYSDBA.TEST_B("C1") VALUES(' aa ');
insert into SYSDBA.TEST_B("C1") VALUES('aa ');
insert into SYSDBA.TEST_B("C1") VALUES('a a');
然后执行以下查询:
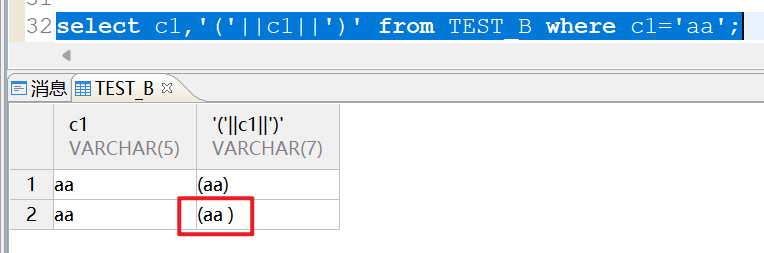
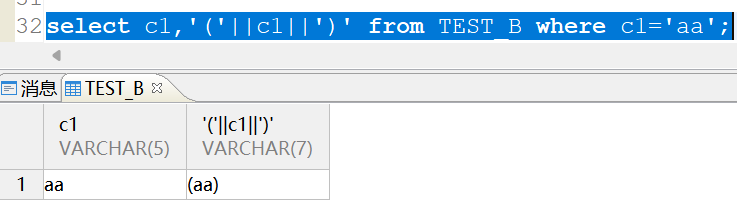
select c1,'('||c1||')' from TEST_B where c1='aa';
在BLANK_PAD_MODE=0的实例:可以看到末尾有空格也查出来了
在BLANK_PAD_MODE=1的实例:末尾有空格的不会查出来
既然BLANK_PAD_MODE=1的实例中,“a”和“a ”是相等的,那主键设置的时候会不会有问题。我们直接在BLANK_PAD_MODE=0的实例中,把TEST_B的C1设置为主键列:
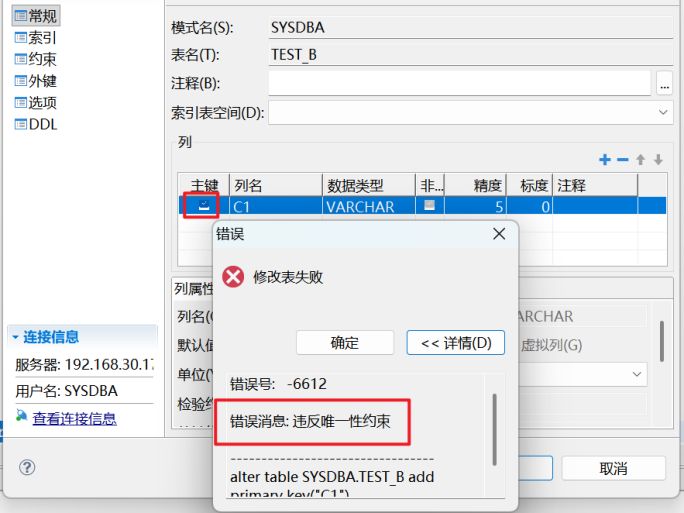
可以看到会提示违反唯一性约束,因为认为表中已有的数据:“aa”和“aa ”是相同的,所以不能设置唯一性约束。因此在迁移数据的时候也要关注这个参数。
在Oracle中默认是区分“a”和“a ”的,所以涉及到从Oracle迁移数据到达梦的话除了修改兼容Oracle的参数,BLANK_PAD_MODE也要设置为1。
3数据库客户端
3.1DISQL
disql也是一种客户端工具,只是没有可视化的图形操作界面而是一款命令行交互客户端。disql命令行工具在数据库软件安装路径的bin目录下。
如果添加了以下环境变量的话就不需要每次都进入bin目录调用disql了:
export DM_HOME=/home/dmdba/dmdbms
export PATH=$PATH:$DM_HOME/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$DM_HOME/bin
连接数据库命令格式:disql username/password@IP:PORT,如果密码含有特殊字符的情况下,需要使用双引号将密码包含进来,同时外层再使用单引号进行转义。以用户名 SYSDBA,密码TEST@2025并且数据库实例和端口号为本机的5236端口为例,则输入:
disql SYSDBA/'"TSET@2025"'

不指定IP和端口号默认连接本地的5236实例。
误输入某个字符后发现退格键和Delete键都无法删除字符,可以使用以下方式重新输入:
(1)Ctrl+U:清空本行;
(2)Ctrl+退格键(Backspace):删除单个字符;
进入disql命令行直接输入需要执行的SQL语句然后回车便可看到执行结果:
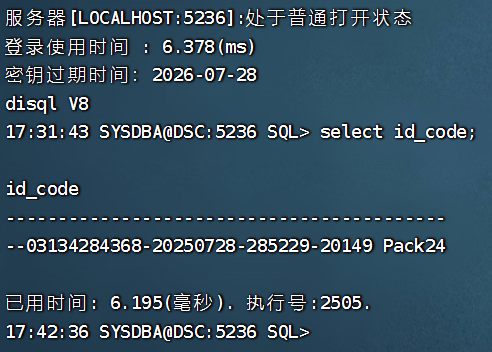
执行脚本:待执行的脚本需要先进行授权给dmdba用户,例如需要执行/temp/AutoParaAdj5.1_dm8.sql脚本:
chown -R dmdba:dinstall /temp/AutoParaAdj5.1_dm8.sql
方法1:文件名直接作为disql参数进行执行:
需要注意的是Linux系统中需要在路径前面加一个`进行转义,而Windows平台不需要转义,如下:(注意执行完成后还是处于sql命令行模式,需要使用quit进行退出)
disql SYSDBA/'"输入你的密码"' \`/temp/AutoParaAdj5.1_dm8.sql
方法2:使用sql命令行进行执行:
(1)使用`:
`/temp/AutoParaAdj5.1_dm8.sql
(2)使用start:
start /temp/AutoParaAdj5.1_dm8.sql
disql连接成功后,在sql命令行输入host回车就会进入系统命令行,可以执行系统命令,但是只能在本机执行,并不不能在数据库服务器所在机器上执行系统命令。
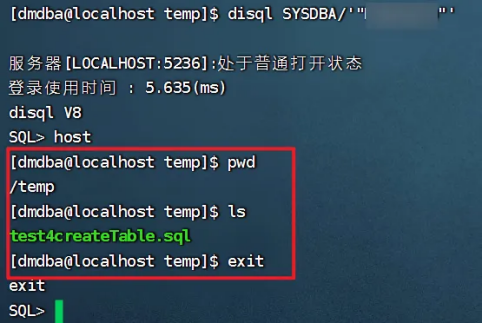
执行单条系统命令:直接在sql命令行:host+要执行的系统命令。
3.2达梦管理工具(DM Manager)
DM Manager是达梦自带的图像化管理工具,在安装达梦数据库的时可以按需勾选,例如选择“典型安装”之后会自动安装,也可以单独安装这个客户端工具,Windows就不必多说安装后直接在系统搜索栏可以搜索并打开,在Linux要打开DM Manager工具的话在$DM_HOME/tool下可以打开:
su - dmdba
cd $DM_HOME/tool
./manager

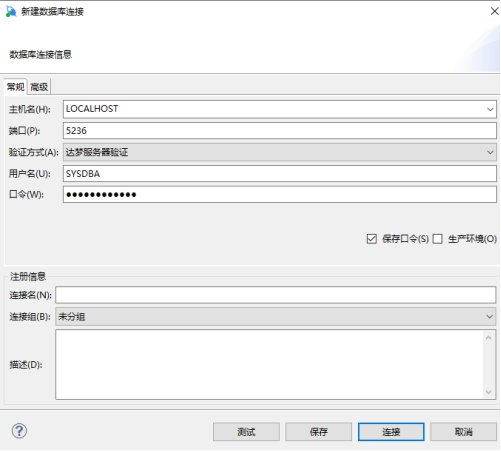
连接数据库:点击“新建连接”按钮,输入连接信息
执行SQL:选中数据库后,点击“新建查询”,在打开的查询窗口里面输入需要执行的SQL语句,点击“执行”按钮即可执行选中的SQL或者整个窗口的SQL语句。在下方的“结果集”列表可以查看到对应的执行结果信息。
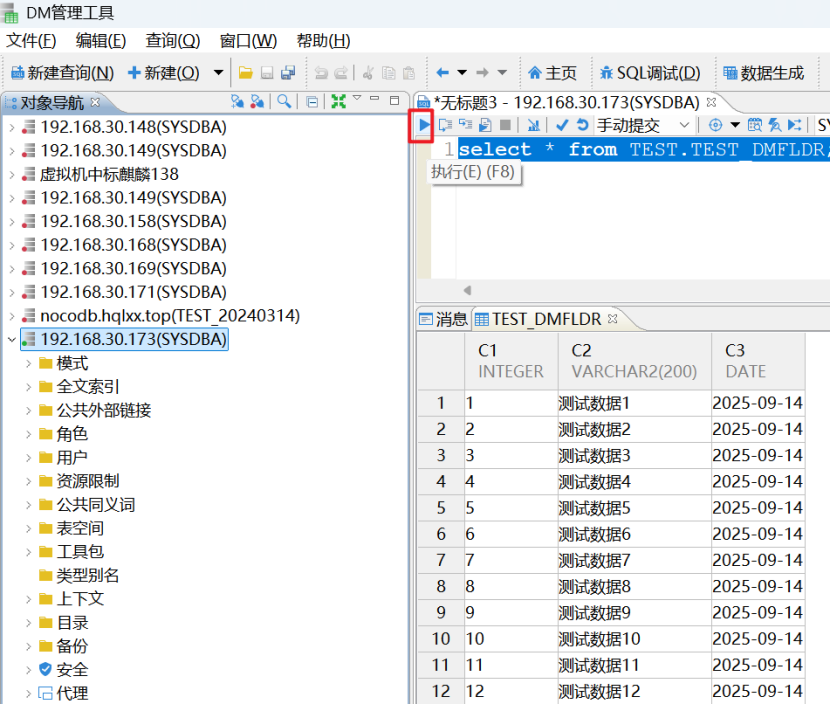
由于达梦数据库默认是需要手动提交事务的,所以执行修改操作有需要commit,或者点击一下“提交”按钮,也可以直接将上方的下拉框选择自动提交事务。
执行脚本:点击查询窗口上方的“执行脚本”按钮,选择需要执行的脚步文件便可执行,在下方的结果窗口就可以看到执行结果。
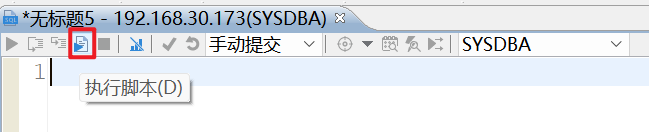
3.3百灵(SQLark)
SQLark又叫百灵连接,是达梦推出的另一款免费的数据库开发管理工具,专为信创场景设计,除了拥有像DM管理工具的数据库对象管理、执行SQL、导入导出等功能,还支持数据迁移、AI协作、ER图功能,还支持连接Oracle、MySQL、PostgreSQL数据库,功能更强大。可以直接在https://www.sqlark.com/进行下载。
连接数据库:点击左上角的连接,选择达梦数据库,输入账号密码等连接信息进行连接。
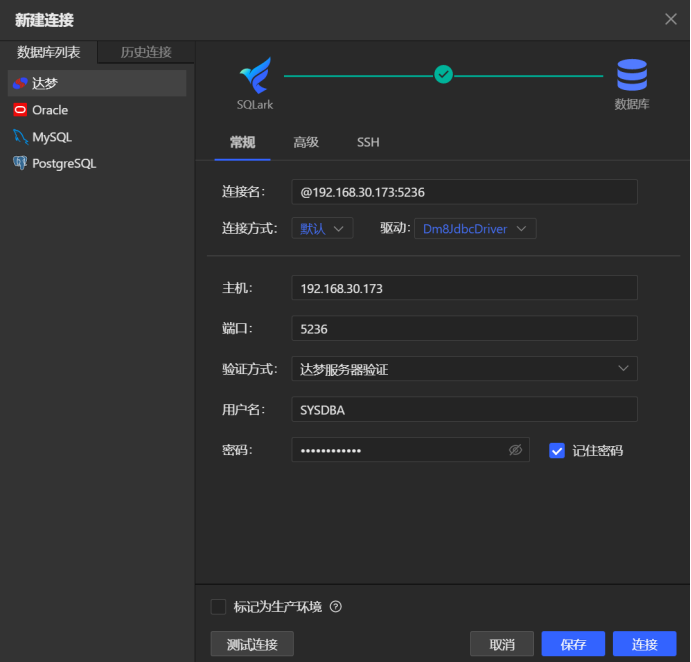
执行SQL:选中数据库,点击“新建查询”按钮,在查询窗口输入SQL后点击“执行”按钮即可执行选中的SQL或者整个窗口的SQL语句。在下方的“结果集”列表可以查看到对应的执行结果信息。
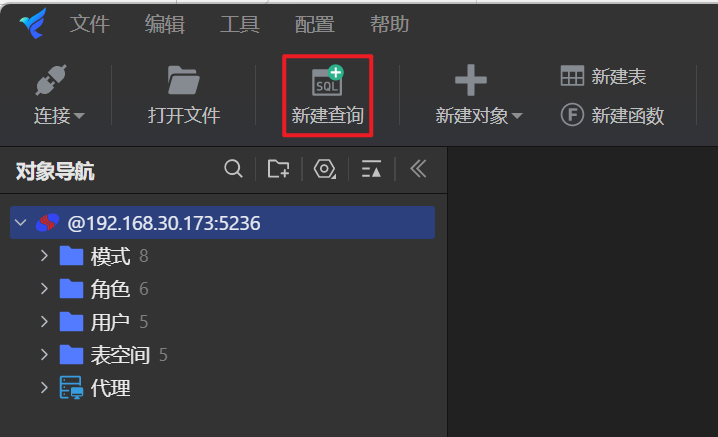
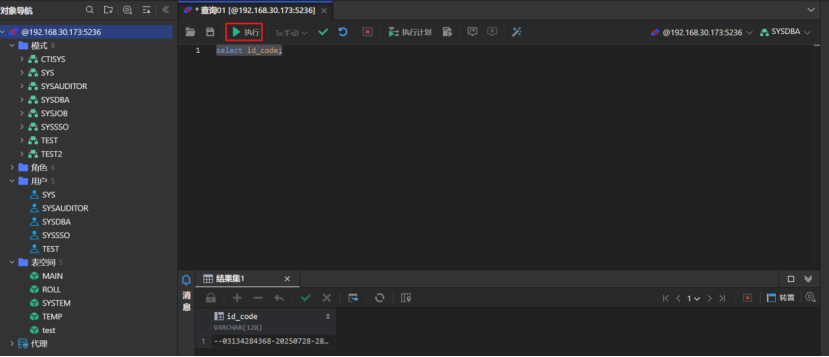
执行脚本:点击查询窗口上方的“执行脚本”按钮,选择需要执行的脚步文件:

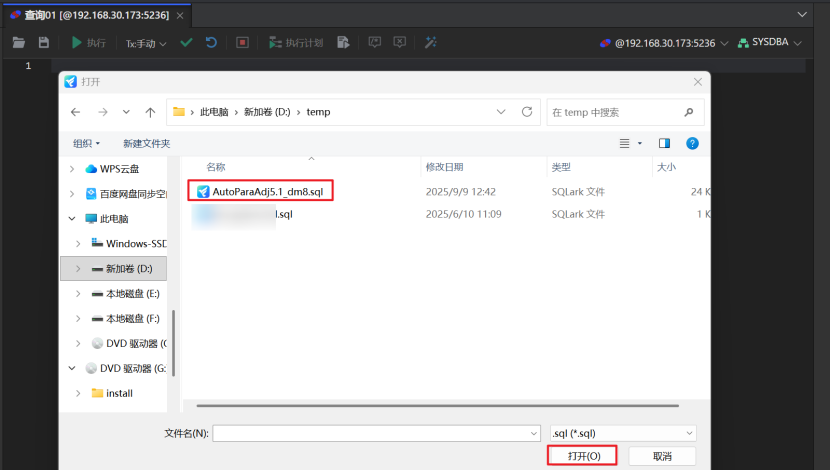
然后点击“执行按钮”执行脚本文件
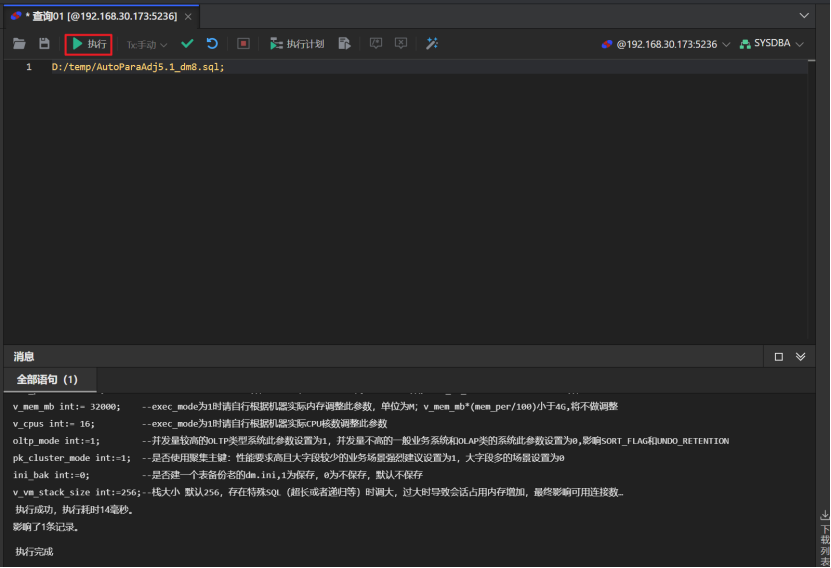
与DM管理工具一样需要手动提交事务的,所以执行修改操作有需要commit,或者点击一下“提交”按钮,也可以直接将上方的下拉框选择自动提交事务。
达梦社区地址:https://eco.dameng.com/