opencv人脸识别
目录
一.LBPH算法
1.什么是LBPH算法
2.实现步骤
3.代码实现
①创建用于训练的图片集
②建立对应的训练标签
③创建特征提取器并完成训练
④预测一张图片
二.EigenFaces算法
1.什么是EigenFaces算法
2.什么是pca
3.代码实现
三.FisherFaces算法
1.基本原理
2.代码实现
要实现人脸识别首先要判断当前图像中是否出现了人脸,这就是人脸检测。只有检测到图像中出现了人脸,才能据此判断这个人到底是谁。我们在上一节已经介绍过人脸检测。这一节讲解人脸识别
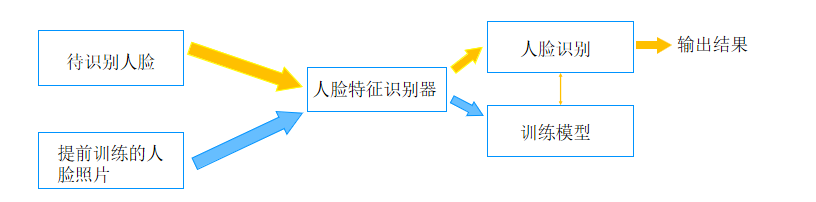
Opencv提供了三种用于识别人脸的特征提取算法。分别是 LBPH 算法、EigenFaces 算法、FisherFaces 算法。
一.LBPH算法
1.什么是LBPH算法
LBPH(Local Binary Patterns Histogram,局部二值模式直方图)算法使用的模型基于LBP(Local Binary Pattern,局部二值模式)算法。LBP 算法最早是被作为一种有效的纹理描述算提出的,因在表述图像局部纹理特征方面效果出众而得到广泛应用。
2.实现步骤
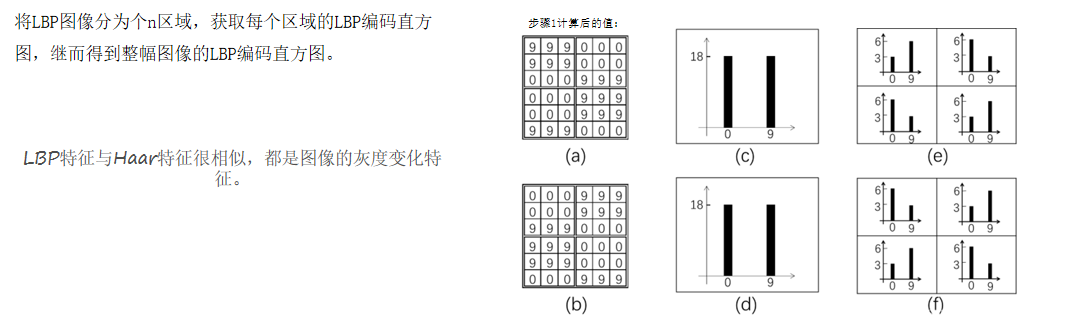
①以每个像素为中心,判断与周围像素灰度值大小关系,对其进行二进制编码,从而获得整幅图像的LBP编码图像;
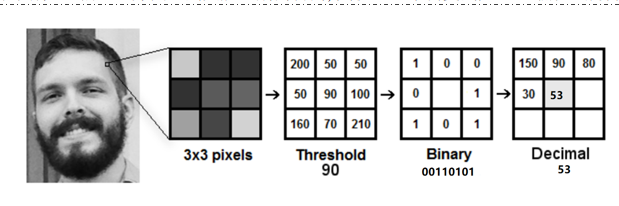
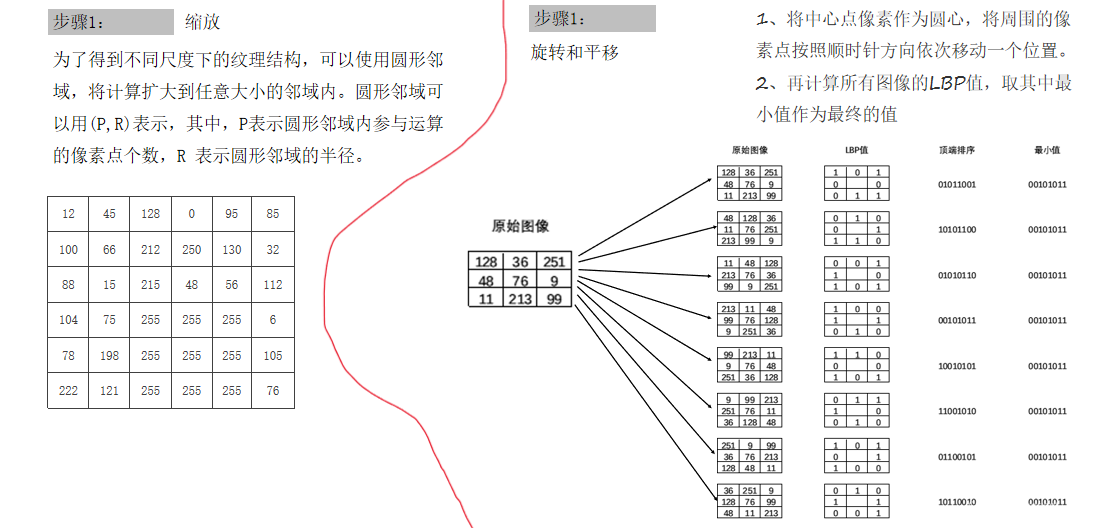
②再将LBP图像分为n个区域,获取每个区域的LBP编码直方图,继而得到整幅图像的LBP编码直方图。 通过比较不同人脸图像LBP编码直方图达到人脸识别的目的,其优点是不会受到光照、缩放、旋转和平移的影响。
3.代码实现
①创建用于训练的图片集
import cv2
import numpy as np
#用于训练的人脸照片
images=[]
images.append(cv2.imread('hg1.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('hg2.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('lm1.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('lm2.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('wyz1.png', cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('wyz2.png', cv2.IMREAD_GRAYSCALE))②建立对应的训练标签
labels=[0,0,1,1,2,2]
dic={0:'胡歌',1:'黎明',2:'吴彦祖',-1:'无法识别'}③创建特征提取器并完成训练
recognizer=cv2.face.LBPHFaceRecognizer_create(threshold=80)
recognizer.train(images,np.array(labels))④预测一张图片
置信度评分confidence越小表示匹配越高,低于80比较可靠
predict_img=cv2.imread('predicted_lm.png', 0)
#置信度评分confidence越小表示匹配越高,低于80比较可靠
label,confidence=recognizer.predict(predict_img)
print('这人是:',dic[label])
print('置信度:',confidence)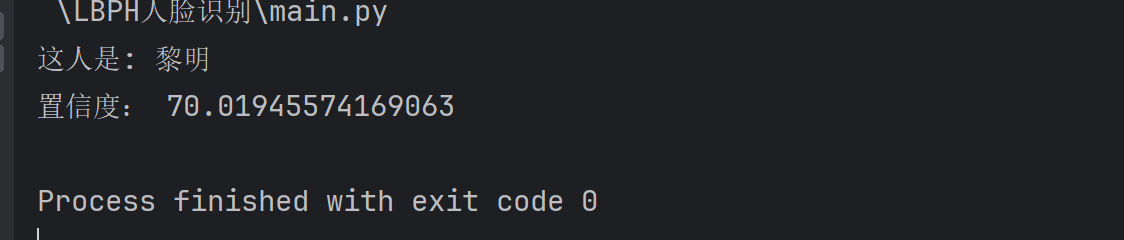
二.EigenFaces算法
1.什么是EigenFaces算法
Eigenfaces是在人脸识别的计算机视觉问题中使用的一组特征向量的名称,Eigenfaces是基于PCA(主成分分析)算法实现的。
2.什么是pca
主成分分析(PCA)是一种矩阵的压缩算法,在减少矩阵维数的同时尽可能的保留原矩阵的信息,简单来说就是将 n×m的矩阵转换成n×k的矩阵,仅保留矩阵中所存在的主要特性,从而可以大大节省空间和数据量。
PCA方法是EigenFaces人脸识别的核心,但是其具有明显的缺点,在操作过程中会损失许多人脸的特征信息。因此在某些特殊的情况下,如果损失的信息刚好是用于分类的关键信息,必然导致结果预测错误。
3.代码实现
自定义一个在OpenCV图像上绘制中文的方法
def cv2_put_text_cn(img, text, org, font_size=20, color=(0, 255, 0)):"""在OpenCV图像上绘制中文参数:img: OpenCV图像(numpy数组)text: 要绘制的中文文本org: 文本起始位置(x, y)font_size: 字体大小color: 文本颜色,BGR格式返回:绘制了文本的图像"""# 转换OpenCV图像为PIL图像img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# 创建绘制对象draw = ImageDraw.Draw(img_pil)# 加载中文字体,这里使用系统中的宋体# 注意:需要根据自己系统的字体路径进行调整try:# Windows系统常见字体路径font = ImageFont.truetype("C:/Windows/Fonts/simhei.ttf", font_size, encoding="utf-8")except:try:# Linux系统常见字体路径font = ImageFont.truetype("/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc", font_size)except:# Mac系统常见字体路径font = ImageFont.truetype("/System/Library/Fonts/PingFang.ttc", font_size)# 绘制中文draw.text(org, text, font=font, fill=(color[2], color[1], color[0]))# 转换回OpenCV格式return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)其余代码与之前并无不同只需换一个特征提取器即可
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
#用于训练的人脸照片
images=[]
a=cv2.imread('hg1.png', cv2.IMREAD_GRAYSCALE)
a=cv2.resize(a,(120,180))
b=cv2.imread('hg2.png', cv2.IMREAD_GRAYSCALE)
b=cv2.resize(b,(120,180))
c=cv2.imread('lm1.png', cv2.IMREAD_GRAYSCALE)
c=cv2.resize(c,(120,180))
d=cv2.imread('lm2.png', cv2.IMREAD_GRAYSCALE)
d=cv2.resize(d,(120,180))
e=cv2.imread('wyz1.png', cv2.IMREAD_GRAYSCALE)
e=cv2.resize(e,(120,180))
f=cv2.imread('wyz2.png', cv2.IMREAD_GRAYSCALE)
f=cv2.resize(f,(120,180))
images.append(a)
images.append(b)
images.append(c)
images.append(d)
images.append(e)
images.append(f)labels=[0,0,1,1,2,2]
dic={0:'胡歌',1:'黎明',2:'吴彦祖',-1:'无法识别'}recognizer=cv2.face.EigenFaceRecognizer_create(threshold=5000)
recognizer.train(images,np.array(labels))
predict_img=cv2.imread('predicted_hg.png', 0)
predict_img=cv2.resize(predict_img,(120,180))
#置信度评分confidence越小表示匹配越高,低于5000比较可靠
label,confidence=recognizer.predict(predict_img)
print('这人是:',dic[label])
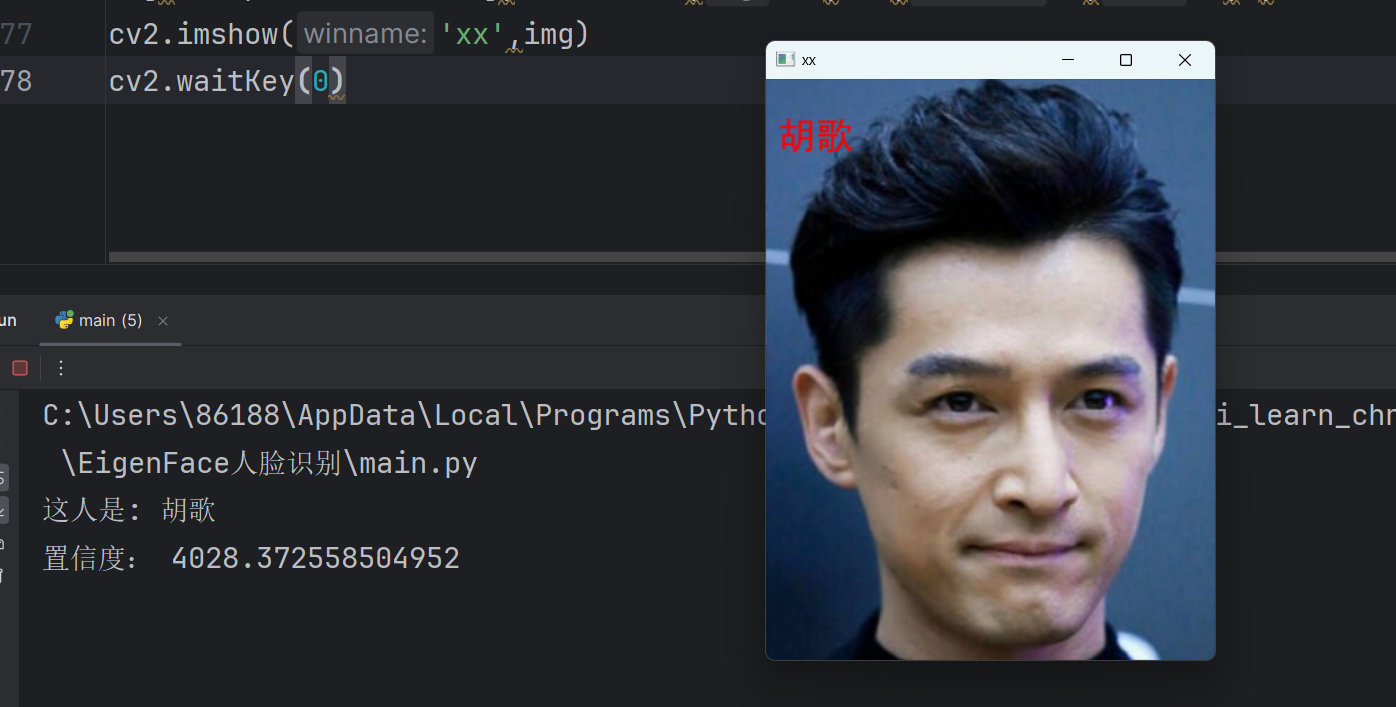
print('置信度:',confidence)img=cv2.imread('predicted_hg.png')
img=cv2_put_text_cn(img,dic[label],(10,30),30,(0,0,255))
cv2.imshow('xx',img)
cv2.waitKey(0)置信度评分confidence越小表示匹配越高,低于5000比较可靠
三.FisherFaces算法
Fisherfaces采用LDA(Linear Discriminant Analysis,线性判别分析)实现人脸识别。
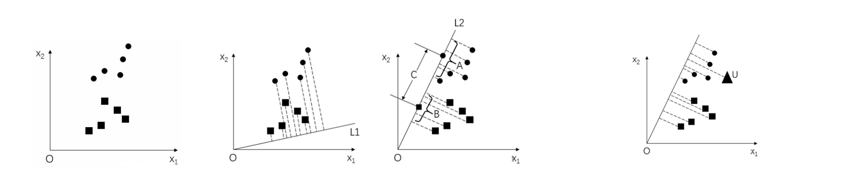
1.基本原理
其基本原理:在低维表示下,首先将训练集样本集投影到一条直线A上,让投影后的点满足: 同类间的点尽可能地靠近 异类间的点尽可能地远离
2.代码实现
只需将特征提取器换为cv2.face.FisherFaceRecognizer_create(threshold=5000)即可
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
#用于训练的人脸照片
images=[]
a=cv2.imread('hg1.png', cv2.IMREAD_GRAYSCALE)
a=cv2.resize(a,(120,180))
b=cv2.imread('hg2.png', cv2.IMREAD_GRAYSCALE)
b=cv2.resize(b,(120,180))
c=cv2.imread('lm1.png', cv2.IMREAD_GRAYSCALE)
c=cv2.resize(c,(120,180))
d=cv2.imread('lm2.png', cv2.IMREAD_GRAYSCALE)
d=cv2.resize(d,(120,180))
e=cv2.imread('wyz1.png', cv2.IMREAD_GRAYSCALE)
e=cv2.resize(e,(120,180))
f=cv2.imread('wyz2.png', cv2.IMREAD_GRAYSCALE)
f=cv2.resize(f,(120,180))
images.append(a)
images.append(b)
images.append(c)
images.append(d)
images.append(e)
images.append(f)labels=[0,0,1,1,2,2]
dic={0:'胡歌',1:'黎明',2:'吴彦祖',-1:'无法识别'}recognizer=cv2.face.FisherFaceRecognizer_create(threshold=5000)
recognizer.train(images,np.array(labels))
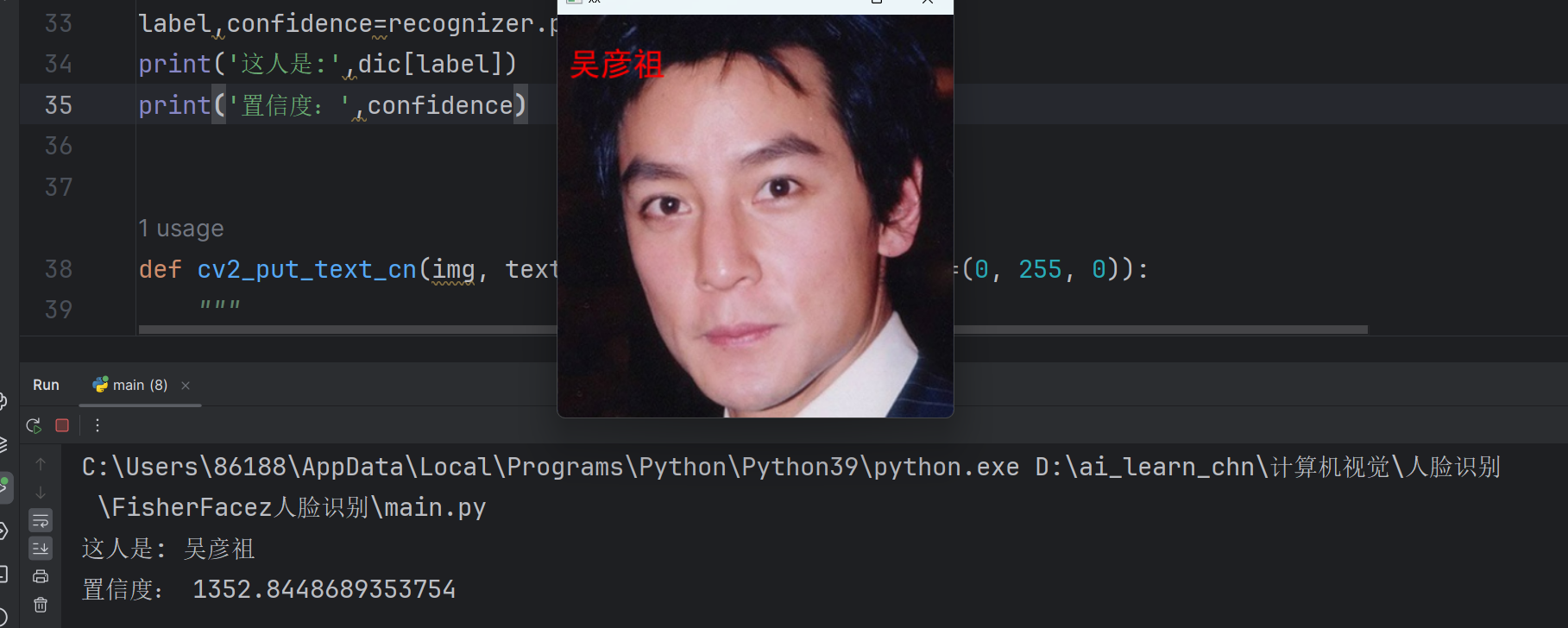
predict_img=cv2.imread('predicted_wyz.png', 0)
predict_img=cv2.resize(predict_img,(120,180))
#置信度评分confidence越小表示匹配越高,低于5000比较可靠
label,confidence=recognizer.predict(predict_img)
print('这人是:',dic[label])
print('置信度:',confidence)def cv2_put_text_cn(img, text, org, font_size=20, color=(0, 255, 0)):"""在OpenCV图像上绘制中文参数:img: OpenCV图像(numpy数组)text: 要绘制的中文文本org: 文本起始位置(x, y)font_size: 字体大小color: 文本颜色,BGR格式返回:绘制了文本的图像"""# 转换OpenCV图像为PIL图像img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# 创建绘制对象draw = ImageDraw.Draw(img_pil)# 加载中文字体,这里使用系统中的宋体# 注意:需要根据自己系统的字体路径进行调整try:# Windows系统常见字体路径font = ImageFont.truetype("C:/Windows/Fonts/simhei.ttf", font_size, encoding="utf-8")except:try:# Linux系统常见字体路径font = ImageFont.truetype("/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc", font_size)except:# Mac系统常见字体路径font = ImageFont.truetype("/System/Library/Fonts/PingFang.ttc", font_size)# 绘制中文draw.text(org, text, font=font, fill=(color[2], color[1], color[0]))# 转换回OpenCV格式return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
img=cv2.imread('predicted_wyz.png')
img=cv2_put_text_cn(img,dic[label],(10,30),30,(0,0,255))
cv2.imshow('xx',img)
cv2.waitKey(0)置信度评分confidence越小表示匹配越高,低于5000比较可靠