Mysql杂志(二十一)——Hash索引和二叉搜索树、AVL树
Hash索引
哈希索引是一种使用哈希表(Hash Table)数据结构实现的数据库索引。它的核心思想是通过一个哈希函数,将索引键值(如user_id、email)映射到一个固定大小的数组(称为“桶”或“槽位”)中的某个位置,从而直接定位到数据。使用哈希索引的核心目的是为了获得极致的点查询(Point Query)性能。
哈希索引通过哈希函数计算一个哈希值,这个值可以理解为一个指针,不需要像数组一样一个一个对比key才能找到对应的value,哈希表直接通过哈希值找到对应的桶,这个桶里存的就是value。
Hash索引的优缺点
优点 | 说明 |
|---|---|
⚡ 极速查询 | 等值查询(=, IN)性能极高,近乎常数时间 |
💾 预测性能 | 查询时间稳定,不随数据量增长而显著增加 |
🔄 插入高效 | 平均插入速度也很快 |
缺点 | 说明 |
|---|---|
❌ 无序性 | 无法支持范围查询(BETWEEN, >, <, ORDER BY) |
🔍 不支持前缀匹配 | 无法支持 |
⚠️ 哈希冲突 | 不同的键可能映射到同一位置,需要额外处理 |
📊 全表扫描 | 对哈希索引列做全表扫描比B树索引慢 |
🔄 维护成本 | 需要好的哈希函数和扩容策略以防性能退化 |
Hash索引使用的场景
数据库 | 应用形式 |
|---|---|
MySQL Memory引擎 | 默认索引类型 |
InnoDB | 自适应哈希索引(AHI):自动为热点页创建哈希索引 |
PostgreSQL | 可通过扩展实现 |
Oracle | 集群哈希表 |
| Redis | 所有键的查找都基于哈希表 |
| MongoDB | 支持哈希分片键,用于数据分布 |
哈希索引在InnoDB中的特殊实现:自适应哈希索引(AHI)
这是MySQL InnoDB引擎的一个精妙特性:
自动创建:InnoDB监控查询模式,自动为频繁访问的B+树索引页在内存中创建哈希索引。
透明使用:对用户和SQL查询完全透明,优化器自动选择。
最佳结合:结合了B+树的范围查询优势和哈希的点查询优势。
二叉搜索树(BST)
二叉搜索树是一种特殊的二叉树数据结构,它在每个节点上都遵循一个简单的排序规则:
1.任意节点的左子树所有节点的值 小于等于 (≤) 该节点的值。2.任意节点的右子树所有节点的值 大于 (>) 该节点的值。3.左、右子树自身也必须是二叉搜索树。也就是任意节点:左子树所有键值<节点键值≤右子树所有键值。
优缺点
优点 | 说明 |
|---|---|
有序性 | 中序遍历即可得到有序序列 |
高效操作 | 平均情况下插入、删除、查找都很快 |
实现简单 | 逻辑清晰,易于理解和实现 |
灵活性 | 支持动态数据集 |
缺点 | 说明 | 后果 |
|---|---|---|
可能不平衡 | 插入顺序严重影响树结构 | 性能退化至O(n) |
无自平衡 | 需要额外算法保持平衡 | 需要AVL/红黑树 |
内存开销 | 每个节点需存储左右指针 | 比数组占用更多空间 |
为什么说最坏的情况是退化成链表呢?因为左子树所有键值<节点键值≤右子树所有键值。那么如果一个数组全部都是增加的,那么所有的树都在右节点上,会形成一个类似于链表的树,也就是层数太深了,和左边的树一点都不平衡。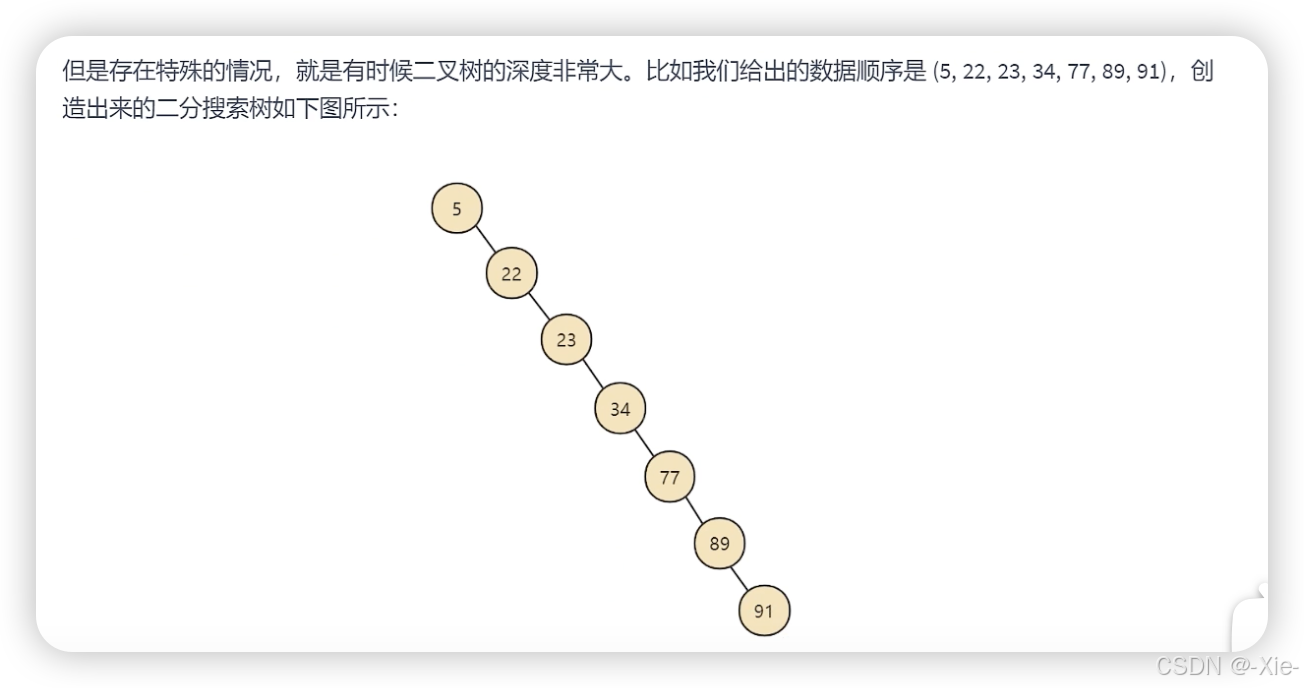
AVL树
在二叉搜索树(BST)的基础上,通过旋转操作来维持一个严格的平衡条件,从而确保树的高度始终保持在O(log n)级别。对于树中的每一个节点,其左子树的高度和右子树的高度之差(称为平衡因子, Balance Factor)的绝对值不能超过1。
平衡因子 = |左子树高度 - 右子树高度|例如:如果左子树高3,右子树高2,平衡因子 = |3-2| = 1 (平衡)如果左子树高3,右子树高1,平衡因子 = |3-1| = 2 (不平衡!需要旋转)至于怎么旋转这个就不细锁了,有兴趣的小伙伴自己找数据结构看看吧。
AVL树的优缺点
优点 | 说明 |
|---|---|
⚡ 查询性能极佳 | 严格的平衡保证了树最矮,查找、插入、删除的时间复杂度最坏情况也是O(log n) |
📊 稳定的性能 | 不会出现普通BST那样的性能退化(退化成链表),性能可预测 |
🔍 范围查询高效 | 中序遍历即是有序序列,适合范围查询 |
缺点 | 说明 |
|---|---|
🔄 维护成本高 | 插入和删除可能触发多次旋转操作,并需要更新从叶子到根路径上所有节点的高度 |
💾 存储开销 | 每个节点需要额外存储高度或平衡因子信息(通常是一个整型) |
⏱️ 更新速度相对慢 | 由于严格的平衡要求,插入和删除操作比普通BST和红黑树慢 |
使用场景
数据库索引:某些数据库的内存索引或对于查询性能要求极高的场景。
字典/地图应用:需要快速查找且数据不常变动的场景,如语言词典、标准代码表。
文件系统:某些文件系统的元数据索引。
内存数据管理:在编程语言的标准库中,虽然红黑树更常见,但AVL树也有应用。
为什么数据库更多用B+树而非AVL树?
这是一个常见的对比。虽然两者都平衡,但设计目标不同:
磁盘I/O vs 内存计算:AVL树追求最少比较次数(适合内存),而B+树追求最少磁盘I/O次数(树更矮,一个节点存储更多键)。
范围查询:B+树的叶子节点链表使得范围查询比AVL树的中序遍历高效得多。
总结
本篇主要讲了Hash索引和AVL树的介绍和各个的优缺点,B和B+树上一篇说过了这边就不再锁了。