Tensorboard学习记录
Tensorboard 是 TensorFlow 生态系统中的一个可视化工具,也被 PyTorch 广泛支持,用于跟踪和可视化机器学习实验的各种指标(如损失值、准确率)、图像数据、模型结构等,帮助开发者理解和优化模型。
( TensorFlow 是由 Google 开发的一个开源机器学习框架,广泛用于构建、训练和部署各种机器学习和深度学习模型。它的核心是一个用于数值计算的开源库,特别适合处理大规模张量(多维数组)运算,这也是其名称中 “Tensor”(张量)的由来。)
一、TensorBoard 核心作用
- scalar 标量可视化:跟踪训练过程中的损失值、准确率等数值指标,直观查看变化趋势。
- image 图像可视化:展示训练 / 测试数据中的图片、模型生成的图像或中间层输出。
- 其他功能 :还支持可视化模型计算图、混淆矩阵、高维数据降维结果(如 PCA、t-SNE)等。
二、完整使用流程
1. 安装 Teboard
在终端(PowerShell 或命令提示符)中安装所需库:
# 安装 PyTorch 相关库(包含 TensorBoard 支持)和图像处理库
pip install torch torchvision tensorboard pillow numpy2. 编写代码生成日志
通过 SummaryWriter 类将数据写入日志文件:
from torch.utils.tensorboard import SummaryWriter # 导入工具
from PIL import Image
import numpy as np# 1. 创建日志写入器,日志会保存在 "logs" 文件夹中
writer = SummaryWriter("logs")# 2. 准备数据:读取图片并转换为 numpy 数组
image_path = r"E:\pycharm\learn_pytorch\date\train\shot\0013035.jpg" # 图片路径(用 r 前缀避免路径转义问题)
img_PIL = Image.open(image_path) # 用 PIL 读取图片
img_array = np.array(img_PIL) # 转换为 numpy 数组(HWC 格式:高度、宽度、通道)# 3. 写入图像数据到日志
# 参数说明:标签名("Ant Image")、图像数据、步数(1)、数据格式(HWC)
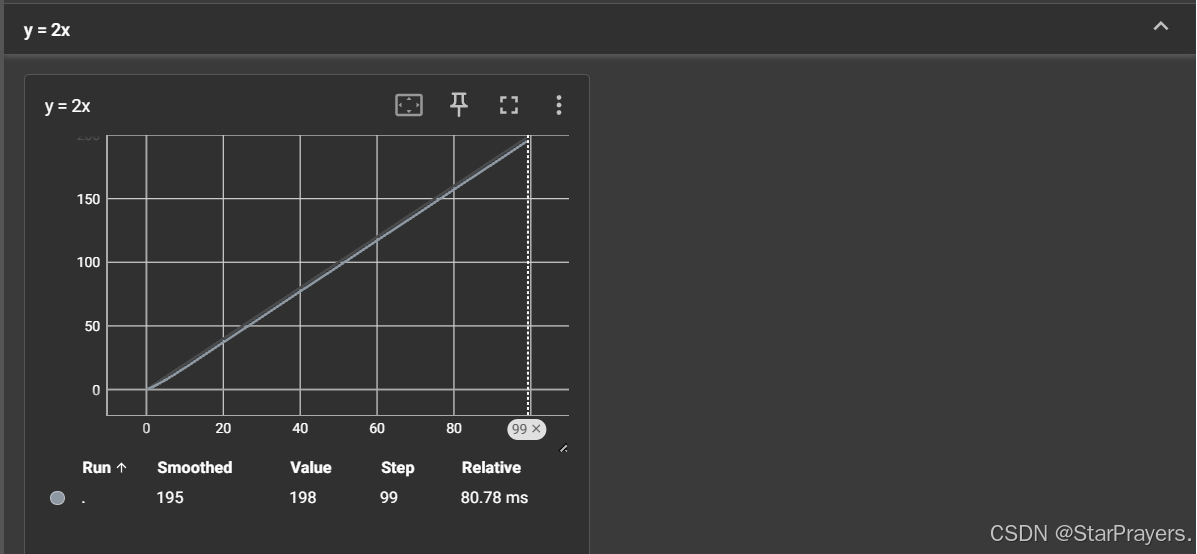
writer.add_image("Ant Image", img_array, 1, dataformats='HWC')# 4. 写入标量数据到日志(示例:y=2x 曲线)
for i in range(100):# 参数:标签名("y = 2x")、数值(2*i)、步数(i)writer.add_scalar("y = 2x", 2*i, i)# 5. 关闭写入器,释放资源
writer.close()
关键函数 :
SummaryWriter("logs"):创建日志写入器,日志文件会保存在当前目录的logs文件夹中。add_image():写入图像数据,需指定数据格式(如HWC表示高度、宽度、通道,与 numpy 数组格式一致)。add_scalar():写入标量数据,适合跟踪损失、准确率等随训练步数变化的指标。
3. 启动 Tensorboard 查看日志
- 运行上述代码,生成
logs文件夹(内含日志文件)。 - 在终端中导航到代码所在目录,执行命令启动 TensorBoard:
tensorboard --logdir=logs # logdir 指定日志文件夹路径 3.打开浏览器,访问终端中显示的地址(通常是 http://localhost:6006)。
4.查看可视化结果
- Scalars 标签页:可看到
y=2x的曲线,横轴是步数,纵轴是数值,用于观察指标变化趋势。 - Images 标签页:可看到你导入的蚂蚁图片,支持放大、对比不同步数的图像。
三、常见问题与解决(结合你的操作)
- 路径中的反斜杠
\会被 Python 解析为转义字符(如\t是制表符),解决方案:- 用原始字符串:
r"E:\path\to\image.jpg"(加r前缀)。 - 用正斜杠:
"E:/path/to/image.jpg"(跨平台兼容,推荐)。 - 用双反斜杠:
"E:\\path\\to\\image.jpg"。
- 用原始字符串:
端口占用:
若提示端口 6006 已被占用,可指定其他端口:
tensorboard --logdir=logs --port=6007 # 使用 6007 端口3.日志不更新:
修改代码后,需重新运行脚本生成新日志,再刷新 TensorBoard 页面
TensorBoard 是机器学习实验的 “可视化仪表盘”,通过 SummaryWriter 写入数据,再启动服务查看,核心价值是帮助直观理解实验过程。
四、TensorBoard 扩展用法详解(进阶)
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
from torchvision import datasets, transforms
import matplotlib.pyplot as plt# 创建SummaryWriter实例,日志会保存在"advanced_logs"文件夹writer = SummaryWriter("advanced_logs")# --------------------------
# 1. 标量(Scalars)的更多用法
# --------------------------
# 模拟训练和验证损失
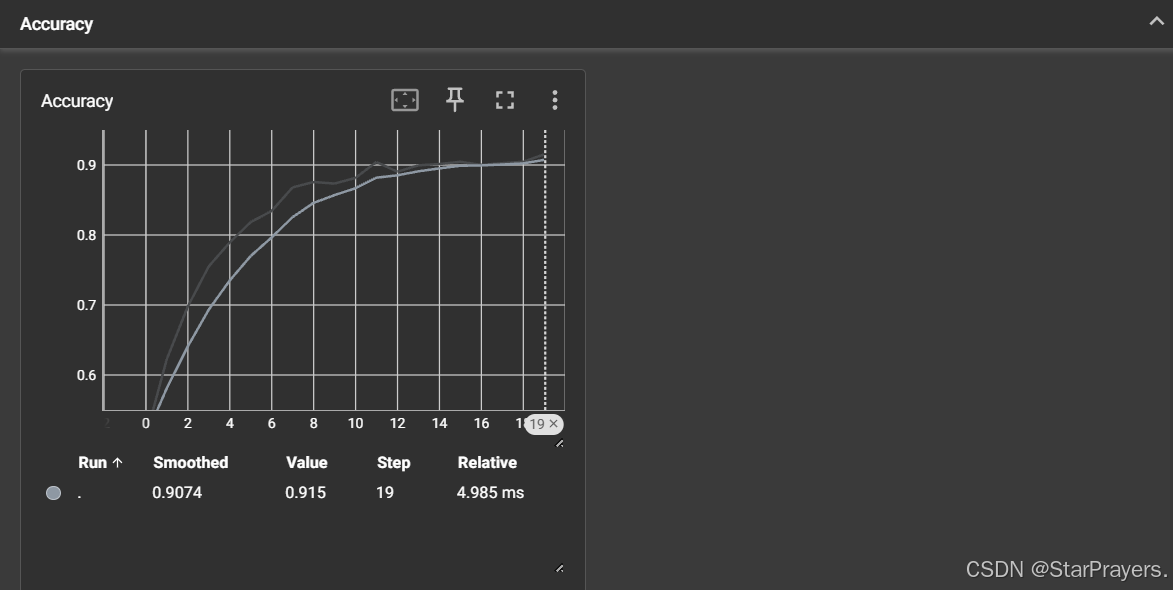
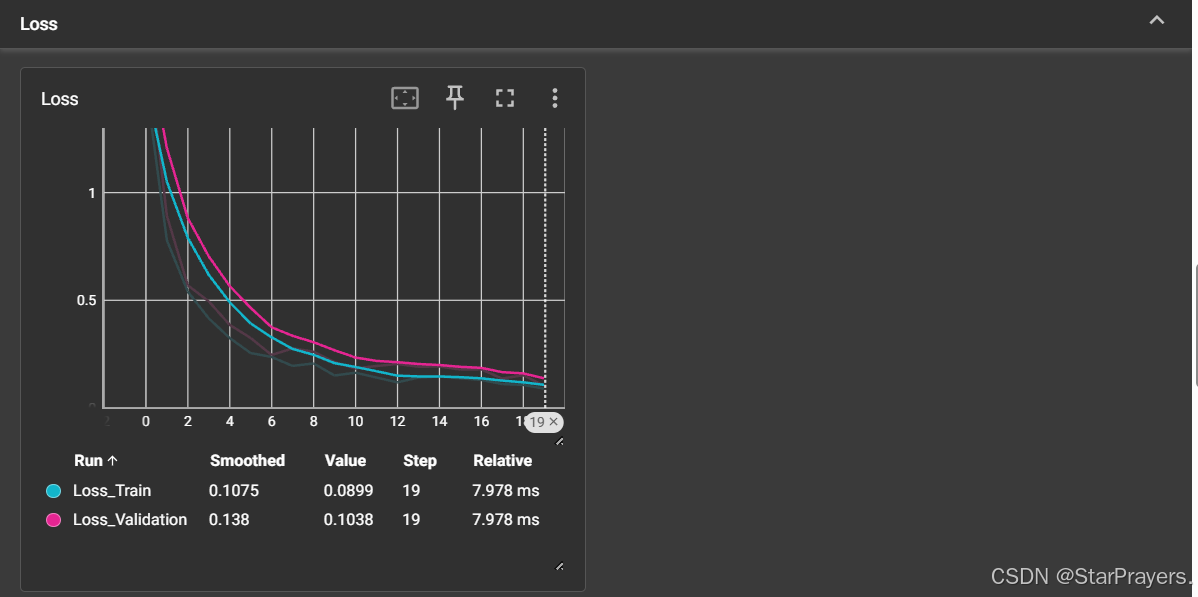
for epoch in range(20):# 模拟训练损失(先降后趋于稳定)train_loss = 1.5 / (1 + epoch) + 0.05 * np.random.random()# 模拟验证损失val_loss = 1.7 / (1 + epoch) + 0.08 * np.random.random()# 可以在同一图表中比较训练和验证损失writer.add_scalars("Loss", {"Train": train_loss,"Validation": val_loss}, epoch)# 模拟准确率accuracy = 0.5 + 0.4 * (1 - np.exp(-0.3 * epoch)) + 0.02 * np.random.random()writer.add_scalar("Accuracy", accuracy, epoch)# --------------------------
# 2. 图像(Images)的更多用法
# --------------------------
# 读取并显示多张图片
image_paths = [r"E:\pycharm\learn_pytorch\date\train\shot\c39e6ff6-d65f-4a9b-b9ef-bf87e52b2665.png",# 可以添加更多图片路径
]# 显示单张图片的不同处理效果
if image_paths:img = Image.open(image_paths[0])img_np = np.array(img)# 原始图片writer.add_image("Original Image", img_np, 0, dataformats='HWC')# 转换为灰度图gray_img = np.mean(img_np, axis=2).astype(np.uint8)writer.add_image("Grayscale Image", gray_img, 1, dataformats='HW')# 亮度调整bright_img = np.clip(img_np * 1.5, 0, 255).astype(np.uint8)writer.add_image("Brightened Image", bright_img, 2, dataformats='HWC')# 显示批量图片
# 使用CIFAR10数据集示例
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])trainset = datasets.CIFAR10(root='./data', train=True,download=True, transform=transform
)# 取出一个批次的图片
images, labels = next(iter(torch.utils.data.DataLoader(trainset, batch_size=16, shuffle=True
)))# 显示批次图片
writer.add_images("CIFAR10 Batch", images, 0)# --------------------------
# 3. 直方图(Histograms)
# --------------------------
# 用于可视化张量分布的变化
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc1 = nn.Linear(100, 200)self.fc2 = nn.Linear(200, 100)self.fc3 = nn.Linear(100, 50)def forward(self, x):x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xmodel = SimpleModel()# 模拟训练过程中权重分布的变化
for step in range(10):# 随机输入x = torch.randn(100, 100)output = model(x)# 记录各层权重的直方图writer.add_histogram("fc1/weights", model.fc1.weight, step)writer.add_histogram("fc1/biases", model.fc1.bias, step)writer.add_histogram("fc2/weights", model.fc2.weight, step)writer.add_histogram("fc3/weights", model.fc3.weight, step)# 模拟参数更新for param in model.parameters():param.data.add_(torch.randn(param.size()) * 0.01)# --------------------------
# 4. 计算图(Graphs)
# --------------------------
# 可视化模型结构
dummy_input = torch.randn(10, 100) # 与模型输入维度匹配
writer.add_graph(model, dummy_input)# --------------------------
# 5. 嵌入向量(Embeddings)
# --------------------------
# 可视化高维数据
# 使用随机数据作为示例
embed_data = torch.randn(100, 50) # 100个样本,每个样本50维
label_img = torch.randn(100, 3, 32, 32) # 每个样本对应的图像writer.add_embedding(embed_data,metadata=list(range(100)), # 每个样本的标签label_img=label_img,tag="example_embedding"
)# --------------------------
# 6. 文本(Text)
# --------------------------
# 记录文本信息
writer.add_text("Training Notes", "Epoch 0: Learning rate set to 0.001", 0)
writer.add_text("Training Notes", "Epoch 10: Loss decreased to 0.34", 10)# --------------------------
# 7. 自定义图表(Figure)
# --------------------------
# 将matplotlib绘制的图表添加到TensorBoard
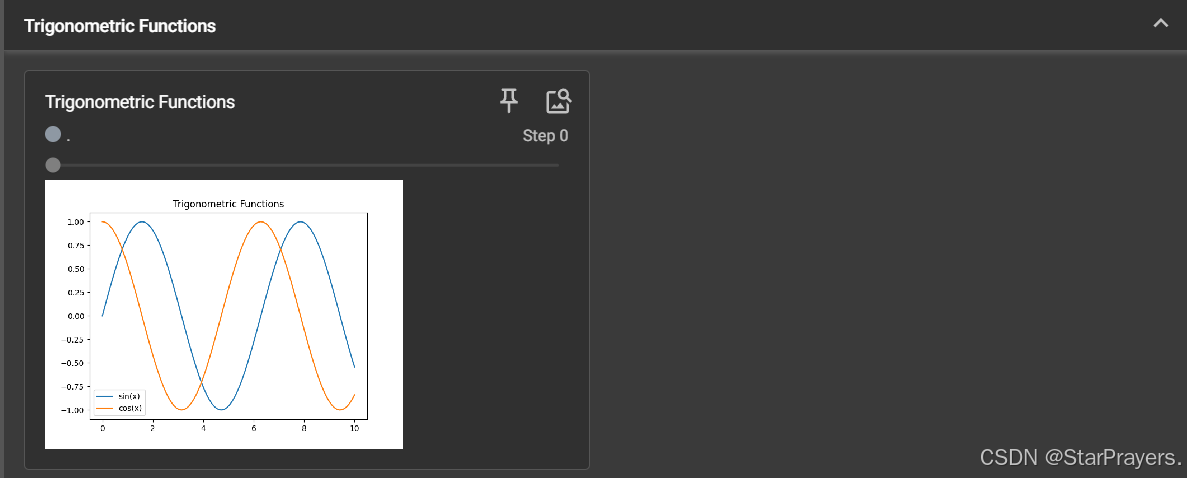
x = np.linspace(0, 10, 100)
y1 = np.sin(x)
y2 = np.cos(x)fig, ax = plt.subplots()
ax.plot(x, y1, label='sin(x)')
ax.plot(x, y2, label='cos(x)')
ax.legend()
ax.set_title('Trigonometric Functions')writer.add_figure("Trigonometric Functions", fig, 0)# 关闭writer
writer.close()
print("所有数据已写入TensorBoard日志。请运行: tensorboard --logdir=advanced_logs")
1.确定在项目路径中
2.启动Tensorboard
3.打开跳转
1. 标量 (Scalars) 的高级用法
- 对应代码位置:最开始的标量可视化部分
- 包含内容:
Loss:包含两条曲线(Train训练损失和Validation验证损失),展示了模拟的 20 个 epoch 中损失值的下降趋势Accuracy:一条曲线,展示了模拟的准确率随训练进程的提升(从 0.5 左右逐渐接近 0.9)
2. 图像 (Images) 的扩展用法
- 对应代码位置:图像可视化部分
- 包含内容:
Original Image:原始图片(步骤 0)Grayscale Image:转换后的灰度图(步骤 1)Brightened Image:亮度增强后的图片(步骤 2)CIFAR10 Batch:CIFAR10 数据集中的 16 张图片(步骤 0,批量展示)Trigonometric Functions:matplotlib 绘制的正弦 / 余弦函数图(步骤 0,自定义图表)
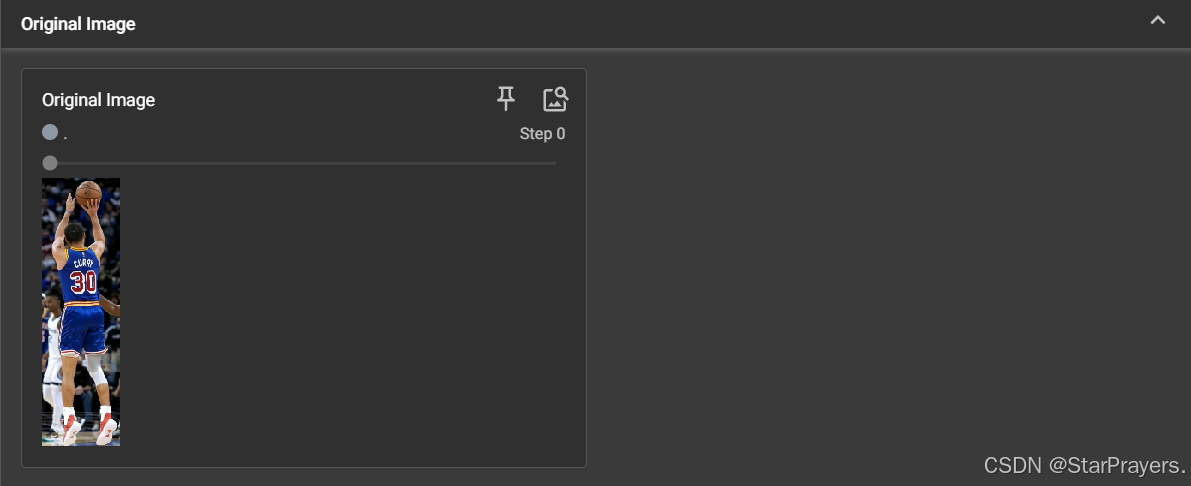
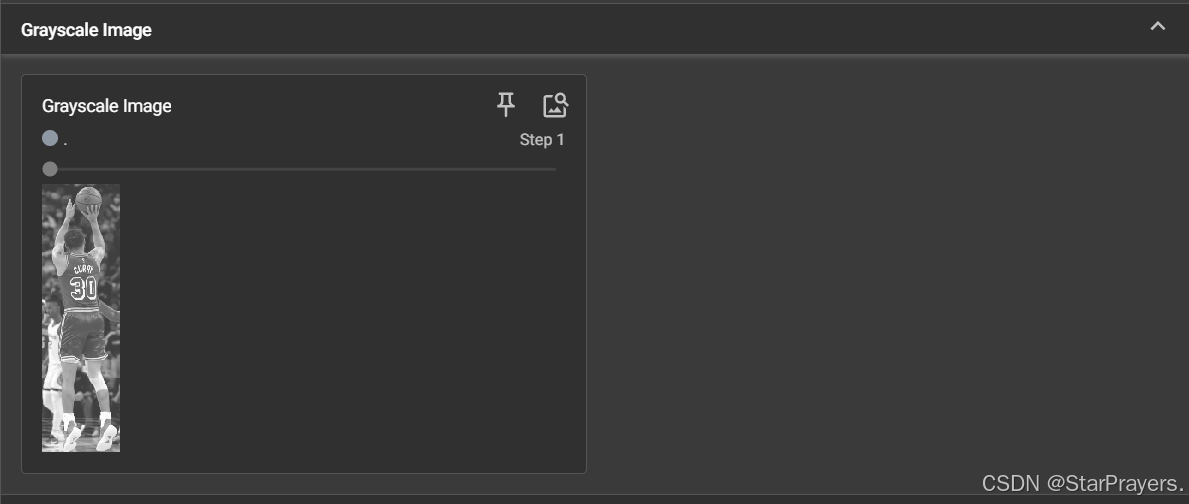
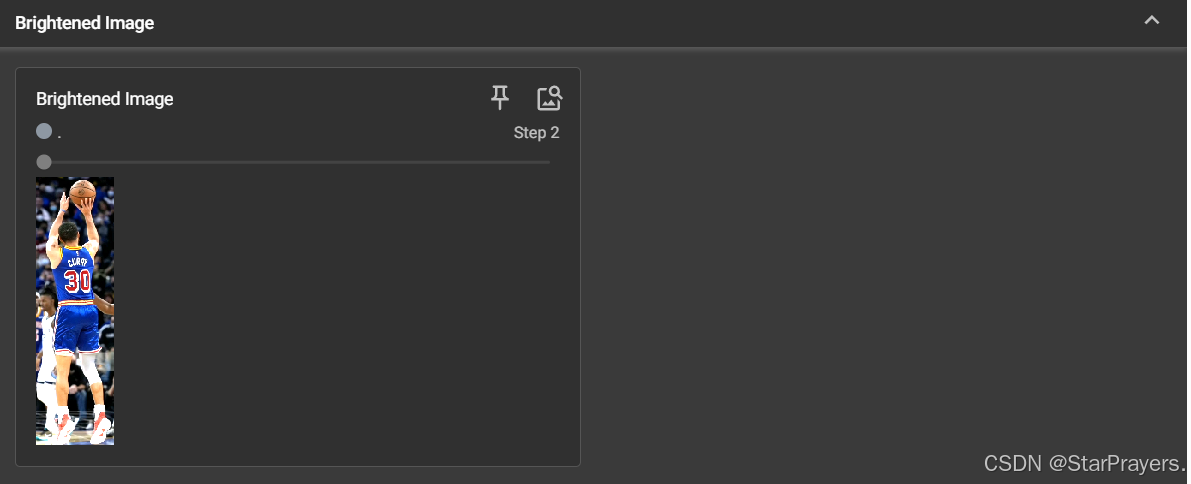
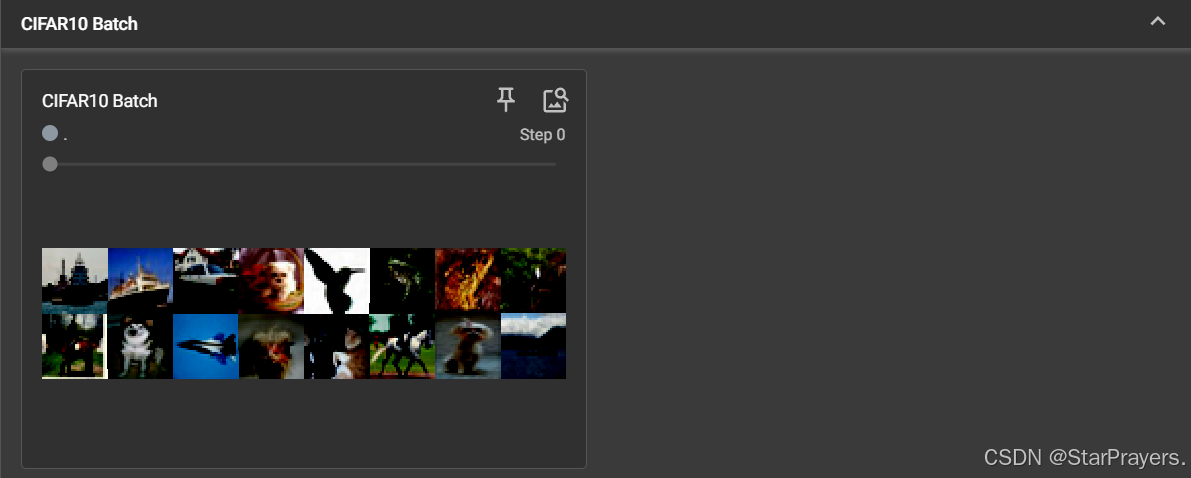
3. 直方图 (Histograms)
- 对应代码位置:模型权重分布可视化部分
- 包含内容:
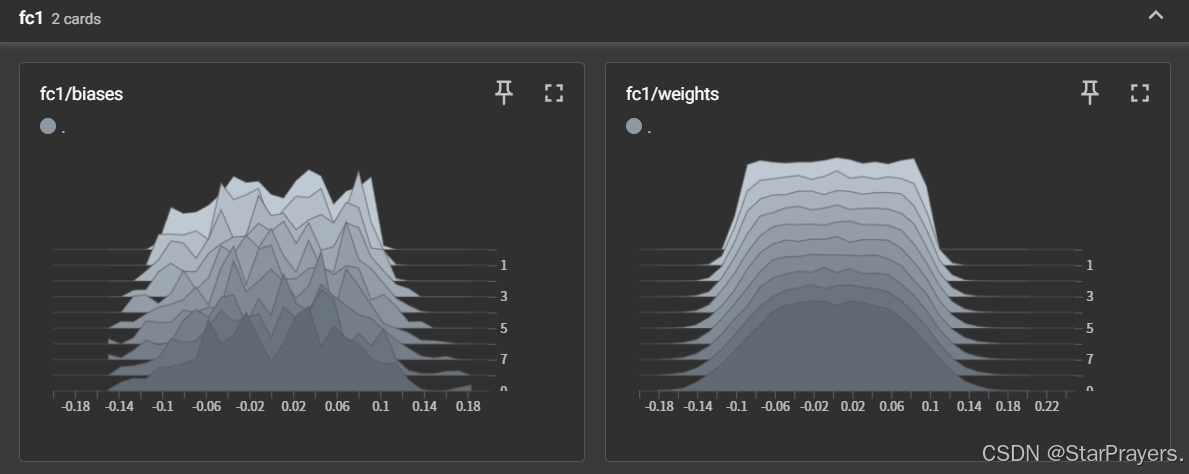
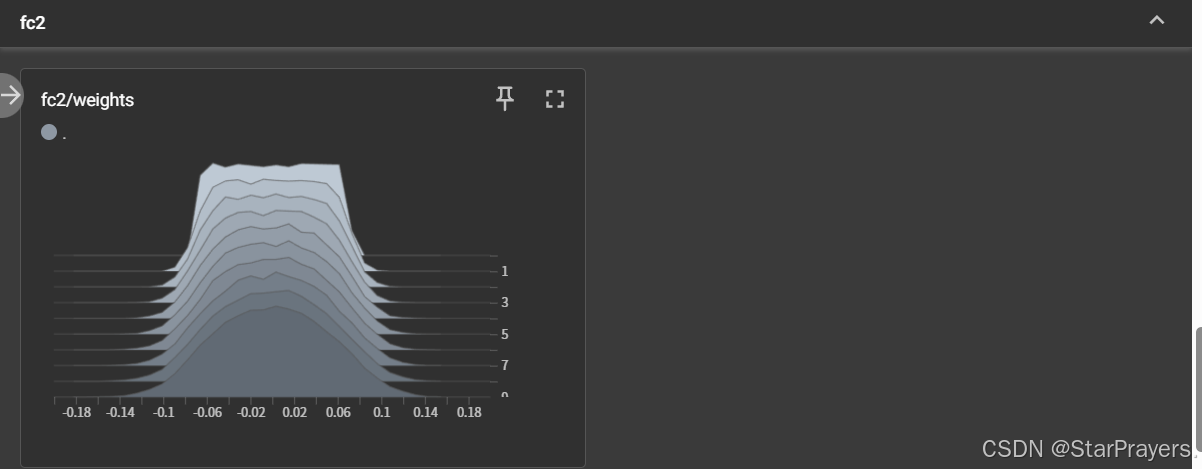
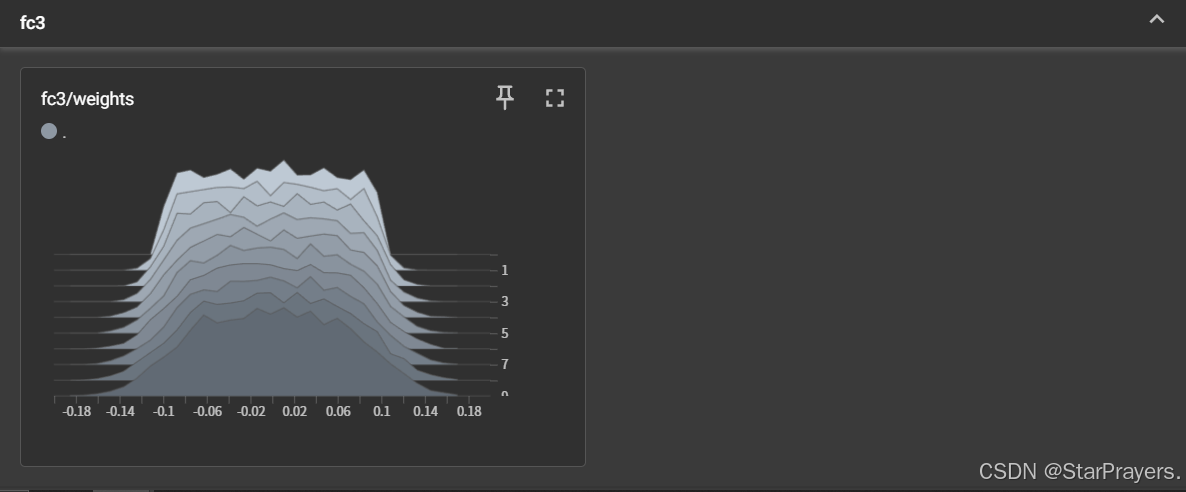
fc1/biases:第一层全连接层偏置的分布变化(共 10 个步骤)fc1/weights:第一层全连接层权重的分布变化fc2/weights:第二层全连接层权重的分布变化fc3/weights:第三层全连接层权重的分布变化(每个直方图展示了不同训练步骤中参数值的分布情况,能看到权重随模拟训练的微小变化)
4. 计算图 (Graphs)
- 模型结构可视化:通过
add_graph()可以直观地看到模型的层次结构和数据流向 - 计算流程分析:帮助理解复杂模型的工作原理,发现可能的结构问题
- 参数统计:可以查看各层的参数数量,评估模型复杂度
5. 嵌入向量 (Embeddings)
- 高维数据可视化:将高维特征通过 PCA、t-SNE 等方法降维到 2D 或 3D 空间,观察数据的聚类情况
- 语义相似性分析:查看相似样本在嵌入空间中的距离,评估模型的特征提取能力
- 错误分析:通过可视化错误分类的样本,分析模型的薄弱环节
6. 其他实用功能
- 文本记录:使用
add_text()记录训练过程中的重要事件、参数调整等 - 自定义图表:通过
add_figure()将 matplotlib 等工具绘制的图表添加到 TensorBoard - PR 曲线:
add_pr_curve()用于绘制精确率 - 召回率曲线,评估分类模型性能 - 音频数据:
add_audio()可以可视化音频波形,适合语音相关任务
7.使用建议
- 组织日志结构:为不同的实验创建不同的日志文件夹,便于管理和对比
- 合理设置记录频率:过于频繁的记录会增加日志大小,影响性能
- 结合过滤器使用:在 TensorBoard 界面使用正则表达式过滤标签,快速定位关注的指标
- 定期清理日志:训练结束后可选择性保留重要日志,避免磁盘空间占用过大
通过这些功能,TensorBoard 可以成为机器学习实验中不可或缺的工具,帮助更深入地理解模型行为,加速模型优化过程。