【论文阅读】OpenVLA:一个开源的视觉-语言-动作模型
OpenVLA引入了一个完全开源的70亿参数视觉-语言-动作模型,为通用机器人操作设定了新的SOTA,其绝对成功率比更大的闭源模型高出16.5%。该模型还展示了有效且高效的微调策略,可在商品硬件上适应新的机器人设置和任务。
概述
OpenVLA 代表着在使先进机器人AI更广泛地为研究社区所用方面迈出了重要一步。该论文介绍了一个70亿参数的视觉-语言-动作(VLA)模型,该模型能够使用自然语言指令和视觉观察来控制多个机器人实体。与现有最先进的闭源模型(如RT-2-X)不同,OpenVLA是完全开源的,提供了对模型权重、训练代码和微调过程的完整访问。
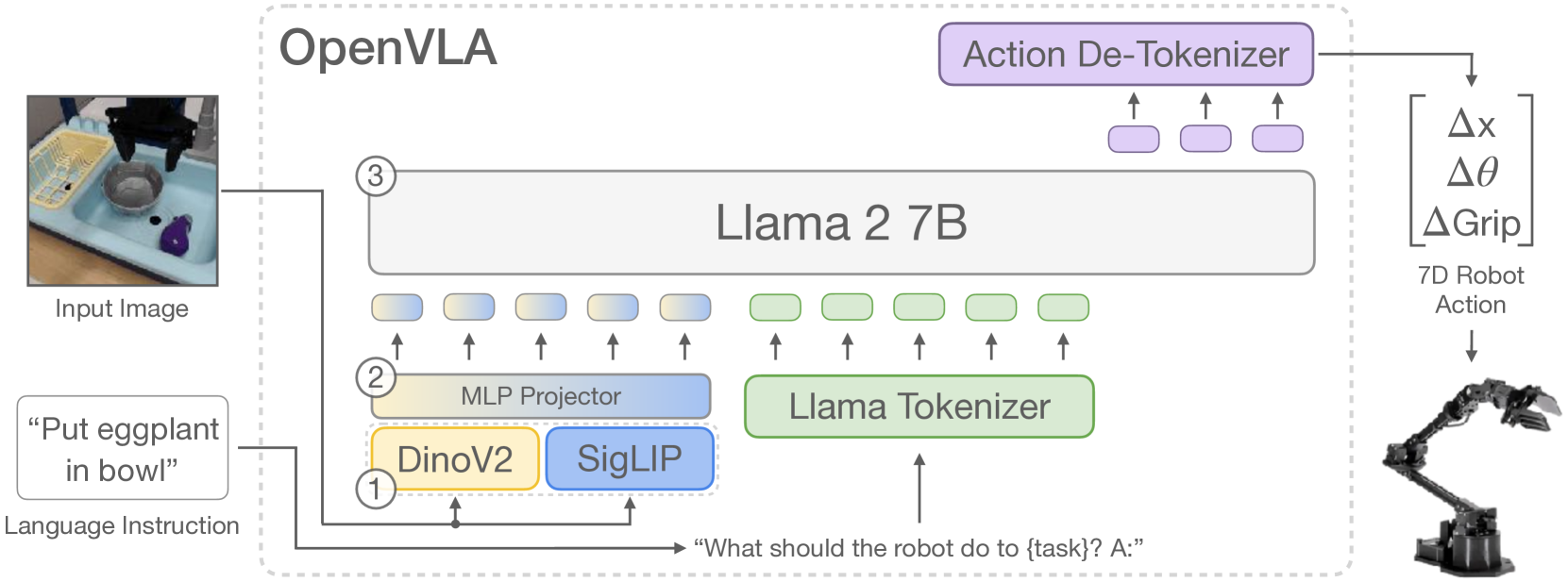
图1:OpenVLA架构,展示了DINOv2和SigLIP视觉编码器融合后馈入Llama 2语言模型骨干,并输出离散化的机器人动作。
该模型在通用机器人操作方面取得了最先进的性能,同时使用的参数比同类闭源模型少7倍。这项工作解决了机器人AI领域的两个关键障碍:可访问性和适应性,使没有大量计算资源的研究人员也能实验并基于先进的VLA功能进行开发。
技术架构与设计
OpenVLA以Prismatic-7B视觉-语言模型为基础,并融入了多项为机器人控制量身定制的关键架构创新。
视觉处理组件采用了独特的双编码器融合方法,结合了两个互补的预训练视觉模型:
- DINOv2:提供对精确操作至关重要的精细空间信息
- SigLIP:贡献更高层次的语义理解
输入图像同时通过两个编码器处理,生成的特征向量通过通道拼接,以创建丰富的视觉表示。这个6亿参数的视觉编码器馈入一个紧凑的2层MLP投影器,将视觉特征映射到语言模型的嵌入空间。
核心推理和动作生成由Llama 2 7B参数语言模型处理。作者做出了一项关键的设计决策:在训练期间对整个视觉编码器进行微调,这与VLM(视觉-语言模型)的常见做法(通常冻结视觉组件)相反。这一选择被证明对于实现机器人控制所需的空间精度至关重要。
动作表示和分词 机器人动作表示为7维连续向量(可能是6自由度末端执行器姿态加上夹持器状态)。这些连续值被离散化为256个均匀的bin,范围覆盖训练数据中动作值的1%到99%分位数——这是一种对简单最小-最大范围的改进,能有效处理异常值。
离散化的动作通过覆盖Llama词汇表中256个最不常用的词元来转换为词元。这种方法使得语言模型的下一个词元预测目标可以直接应用于动作生成,模型经过训练以最小化预测动作词元上的交叉熵损失。
训练方法与数据
OpenVLA的训练利用了Open X-Embodiment数据集,该数据集包含97万个真实世界的机器人演示,涵盖了多种实体、任务和环境。这是迄今为止最大、最多样化的机器人学习数据集之一。
训练过程涉及几个关键的数据整理步骤:
- 筛选出至少有一个第三人称摄像机视角的操纵数据集
- 限制为单臂末端执行器控制场景
- 在实体、任务和场景之间应用平衡的混合权重
- 关键地移除了可能导致策略冻结的“全零”(无操作)动作
该模型在由64个A100 GPU组成的集群上训练了27个周期——明显多于典型的VLM训练——历时14天,累计了大约21,500个A100小时的计算量。整个训练过程中使用了2×10⁻⁵的固定学习率。
初步实验的主要训练见解包括:
- 图像分辨率:224×224像素提供的性能与384×384像素相当,但训练速度快3倍
- 视觉编码器微调:对于机器人控制至关重要,这与通常冻结视觉编码器的典型VLM应用不同
- 延长训练:高 epoch 计数对于实现最佳动作令牌准确性是必要的
实验结果与性能
OpenVLA在多个评估维度上表现出卓越性能,为通用机器人策略树立了新基准。
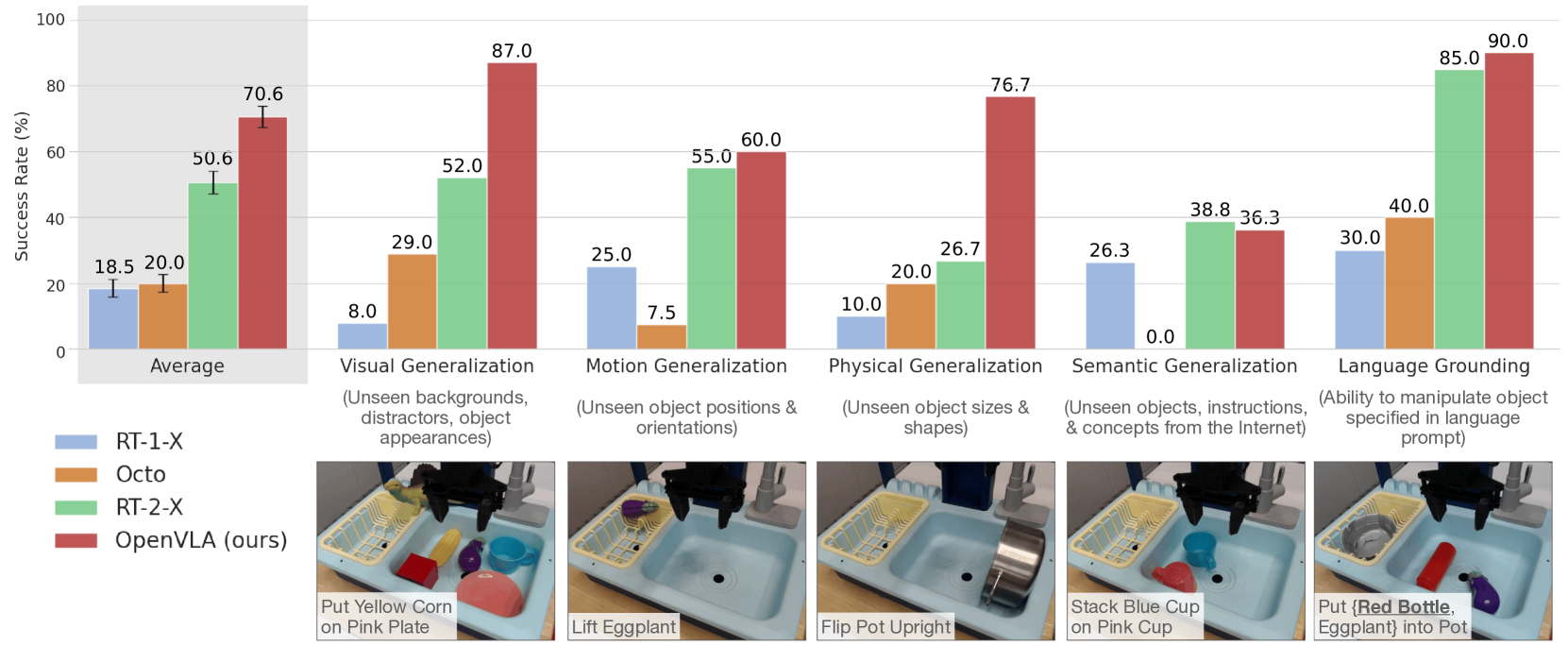
图2:OpenVLA在WidowX机器人任务的不同泛化类别中实现了最先进的性能,尽管参数比RT-2-X少7倍,但表现优于RT-2-X。
通用策略性能 OpenVLA在涵盖两种机器人形态(WidowX和Google Robot)的29项任务中,成功率比RT-2-X(55B参数)绝对提升了16.5%。这代表了通用机器人操作策略的最新技术水平,并且以显著更少的参数实现。
该模型在以下方面表现出特别的优势:
- 视觉泛化:处理未见过的背景、干扰物和物体外观
- 运动泛化:适应新的物体位置和方向
- 物理泛化:处理不同大小和形状的物体
- 语言接地:准确遵循自然语言指令
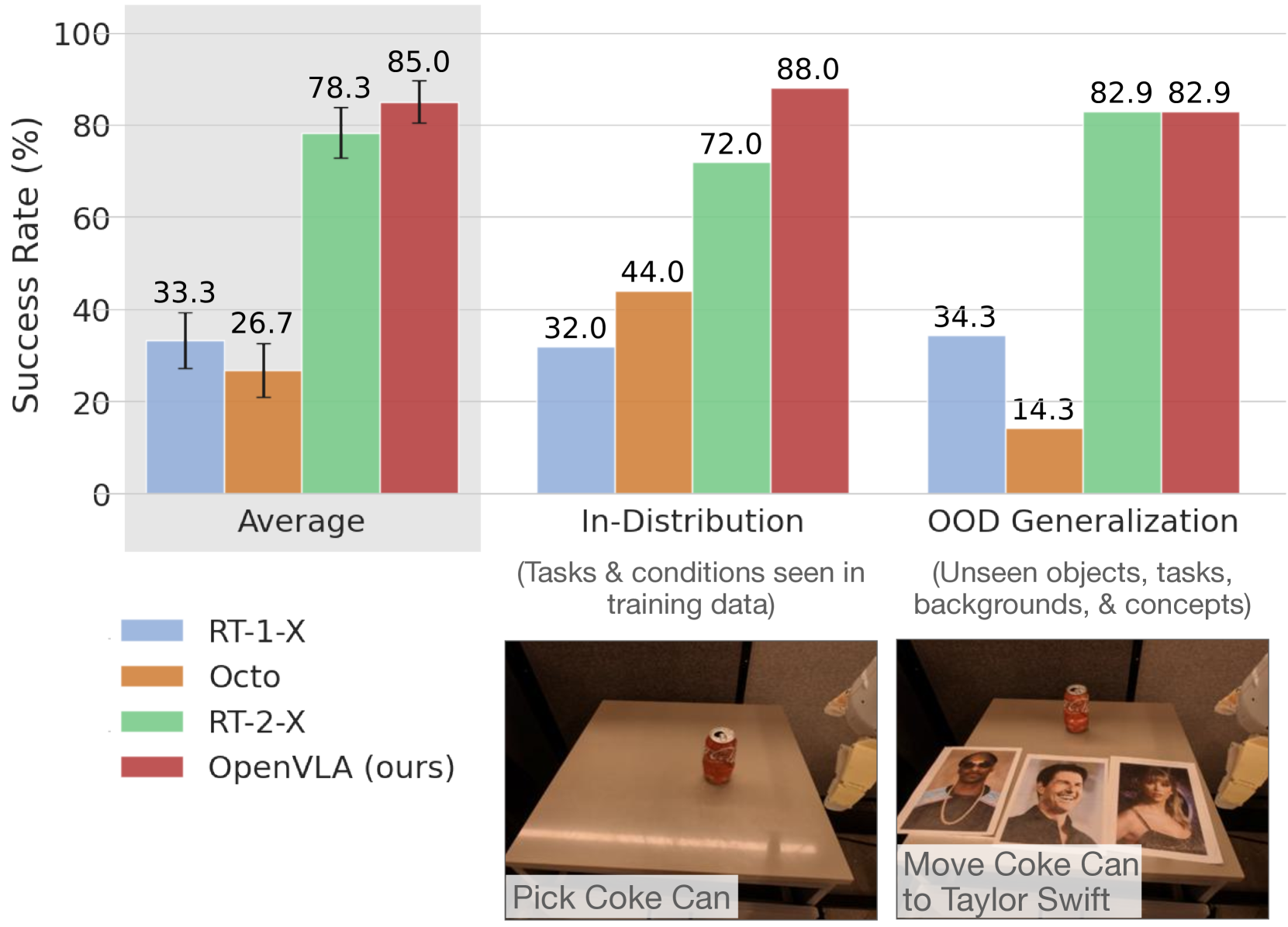
图3:在Google Robot平台上持续表现出卓越性能,尤其是在分布外泛化能力方面表现强劲。
适应新的机器人设置 OpenVLA的微调能力在两个新的机器人平台(Franka-Tabletop和Franka-DROID)上进行了评估,使用了10-150个演示的数据集。结果显示:
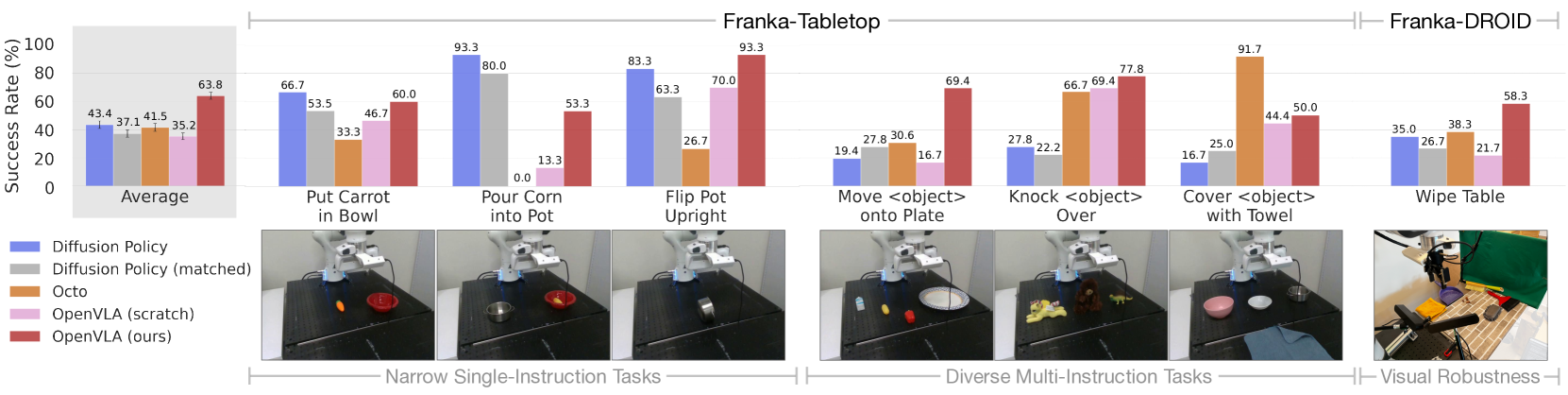
图4:OpenVLA微调结果显示在多样化的多指令任务上比基线方法表现更优。
- 在多样化的多指令任务中比Diffusion Policy 提升20.4%
- 在所有测试任务中均保持一致的鲁棒性(唯一一个普遍达到≥50%成功率的方法)
- 在需要语言接地和干扰物处理的任务中表现更优
- 即使在Diffusion Policy通常表现出色的狭窄单指令任务中也具有竞争力
参数高效训练与部署
作者广泛研究了实际部署策略,以使OpenVLA可在商用硬件上使用。
低秩适应 (LoRA) LoRA微调被证明非常有效,在仅训练模型1.4%的参数的情况下,其性能与完全微调相当:
- 完全微调:成功率69.7%
- LoRA微调:成功率68.2%
- 计算需求减少8倍(1个A100 GPU vs 8个A100 GPU)
- 单GPU训练时间缩短至10-15小时
量化实现高效推理 4位量化取得了令人印象深刻的结果:
- 性能保持:成功率71.9% vs 71.3%(4位 vs bfloat16)
- 内存占用减少>50%:7.0 GB vs 16.8 GB
- 使得在RTX 4090等消费级GPU上部署成为可能
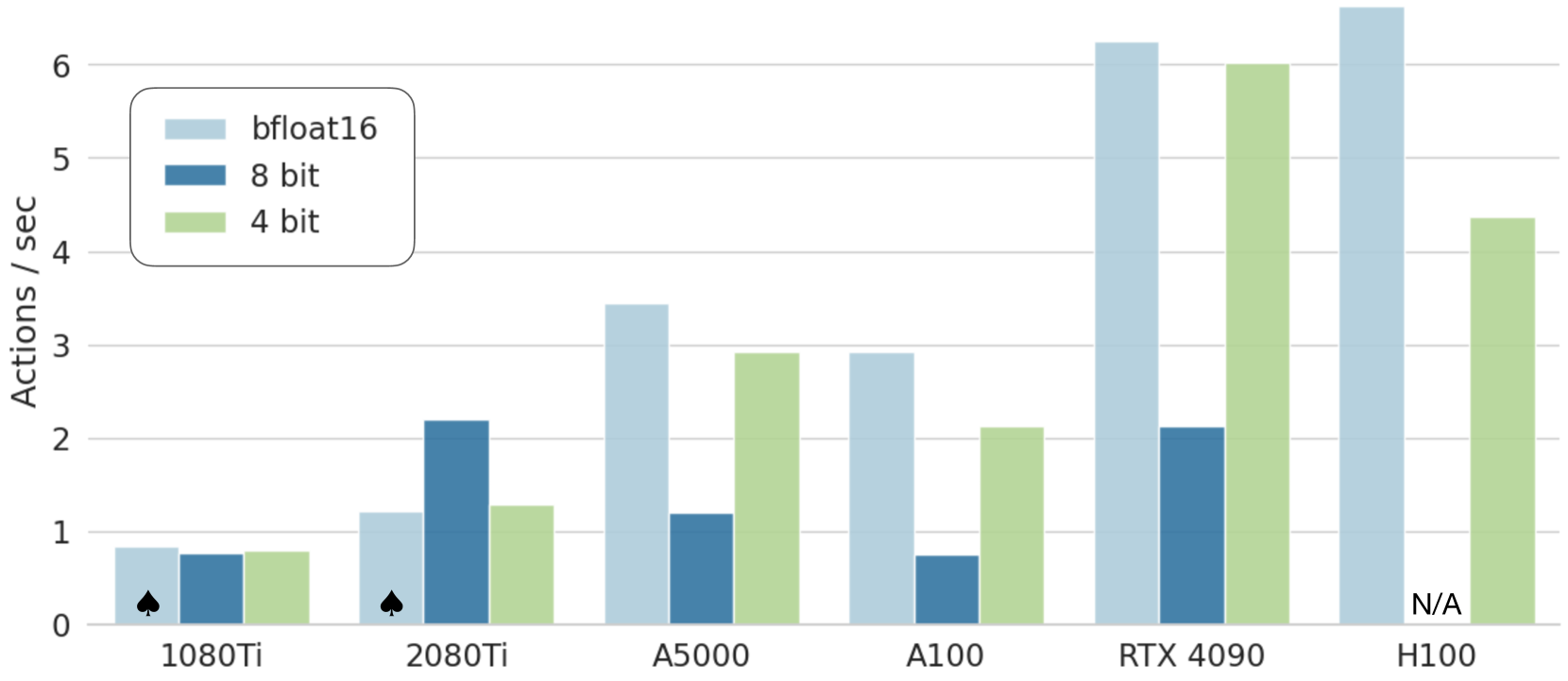
图5:OpenVLA在不同硬件配置和精度级别下的推理性能,显示了实际部署能力。
该模型在RTX 4090硬件上可实现约6Hz的推理速度,适用于大多数操作任务,同时对于没有高端计算基础设施的研究人员来说也易于访问。
意义与影响
OpenVLA 解决了阻碍先进机器人人工智能广泛采用的根本障碍。通过开源尖端 VLA 模型,这项工作使以前仅限于资源丰富的机构和公司才能获得的能力民主化。
该模型在参数比 RT-2-X 少 7 倍的情况下却表现出卓越的性能,这表明精心设计的架构和数据整理可以克服原始参数规模的限制。这一发现对于使先进机器人人工智能更易于访问和实用具有重要意义。
对高效微调和部署策略的全面研究为使用通用硬件将 VLA 模型适应新任务和机器人提供了路线图。LoRA 微调和 4 位量化所展示的有效性使得 OpenVLA 在计算资源受限的实际部署场景中变得实用。
也许最重要的是,OpenVLA 为机器人人工智能的协作开发奠定了基础,类似于围绕开源语言模型出现的生态系统。模型权重、训练代码和评估基准的完整发布使研究社区能够在此工作的基础上进行构建,从而可能加速向更强大、更广泛部署的机器人系统迈进的步伐。
这项工作还为 VLA 设计原则提供了宝贵的见解,包括视觉编码器微调在机器人应用中的重要性以及融合多模态视觉表示的有效性。这些发现为快速发展的机器人学习领域的未来研究方向和架构选择提供了信息。