LoRA微调技术:大模型时代的“乐高式“参数改造指南
图片来源网络,侵权联系删除

文章目录
- 引言:当百亿参数模型遇上穷开发者
- 一、LoRA技术原理:矩阵分解的数学魔法
- 1.1 传统微调的困境
- 1.2 LoRA的破局之道
- 1.3 关键参数解析
- 二、LoRA四大核心优势
- 2.1 参数效率革命
- 2.2 灵活的任务切换
- 2.3 灾难性遗忘防护
- 2.4 多任务协同
- 三、实战:用LoRA打造专属AI助手
- 3.1 环境配置
- 3.2 数据准备(以客服对话为例)
- 3.3 模型微调代码
- 3.4 模型部署
- 四、行业应用案例
- 4.1 医疗领域
- 4.2 金融风控
- 4.3 游戏开发
- 五、进阶技巧与挑战
- 5.1 参数调优策略
- 5.2 常见问题解决方案
- 5.3 前沿发展方向
- 结语:LoRA开启的AI平权时代
引言:当百亿参数模型遇上穷开发者
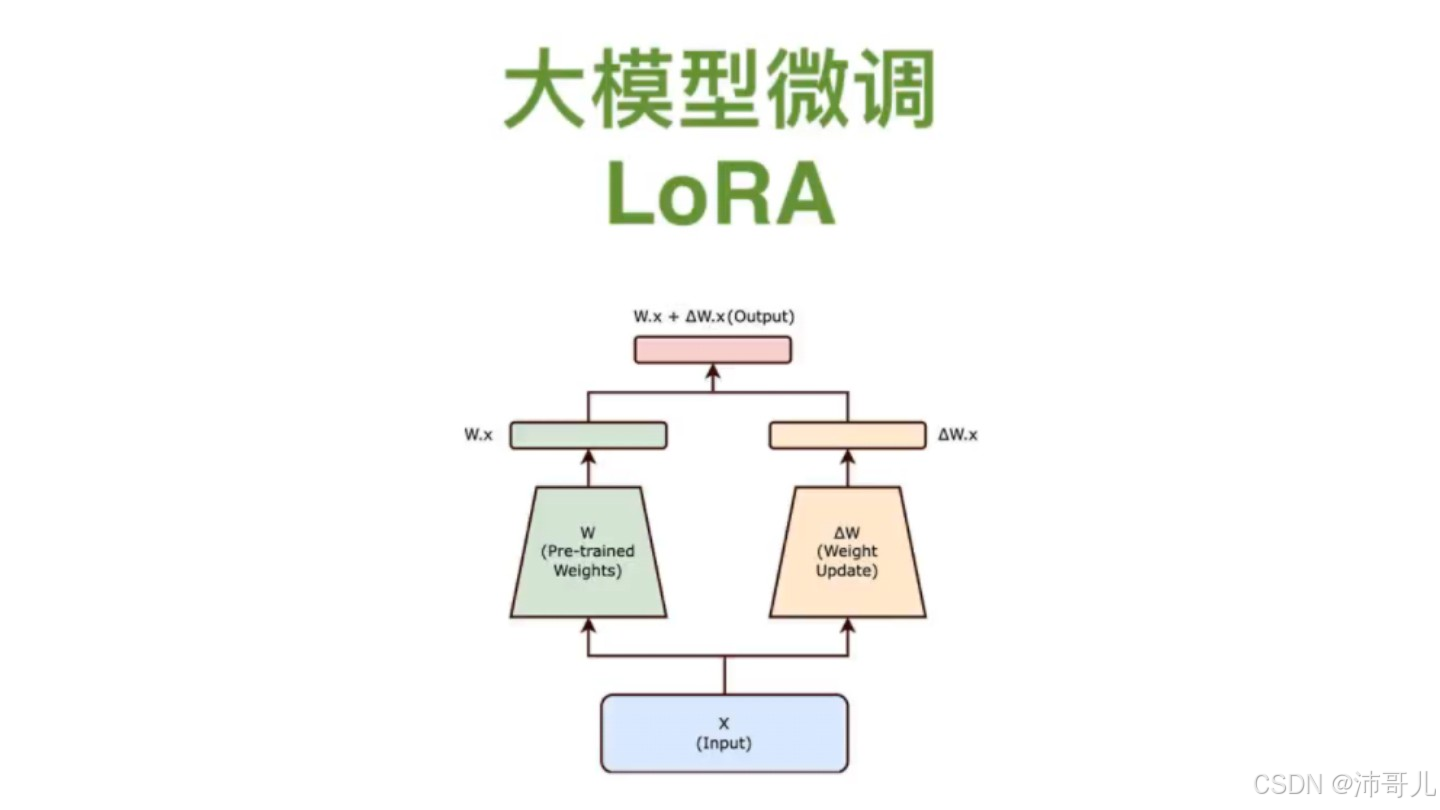
在AI模型参数突破千亿大关的今天,普通开发者面对动辄需要数百G显存的微调任务,常常陷入"想用大模型却租不起显卡"的困境。LoRA(Low-Rank Adaptation)技术的出现,犹如给大模型微调领域带来了一场"参数革命"。本文将深入解析这项技术的核心原理,手把手带你完成实战部署,并揭秘其在多领域应用的魔法。
一、LoRA技术原理:矩阵分解的数学魔法
1.1 传统微调的困境
- 参数爆炸:GPT-3有1750亿参数,全量微调需要万亿级计算量
- 显存黑洞:单次前向传播消耗显存超过40GB
- 灾难性遗忘:模型在适应新任务时丢失原有知识
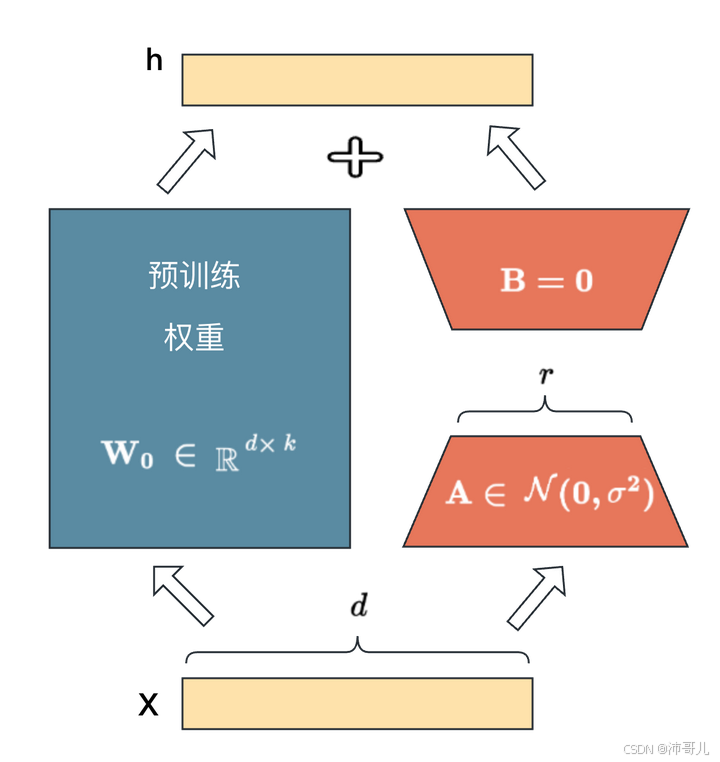
1.2 LoRA的破局之道
通过低秩矩阵分解实现参数高效更新:
# 低秩分解示例(PyTorch)
class LoRALayer(nn.Module):def __init__(self, linear_layer, rank=8):super().__init__()self.linear = linear_layerin_dim, out_dim = linear_layer.weight.shapeself.A = nn.Parameter(torch.randn(in_dim, rank))self.B = nn.Parameter(torch.zeros(rank, out_dim))def forward(self, x):return self.linear(x) + (x @ self.A @ self.B)
数学本质:将权重更新ΔW分解为ΔW = ABᵀ,其中A∈ℝ(d×r),B∈ℝ(r×k),r≪d,k
1.3 关键参数解析
| 参数 | 典型值 | 作用 |
|---|---|---|
| Rank( r ) | 4-64 | 低秩维度,决定模型容量 |
| Alpha( α ) | 8-64 | 缩放因子,平衡秩的影响 |
| Dropout | 0.05-0.2 | 防止过拟合 |

二、LoRA四大核心优势
2.1 参数效率革命
- 存储节省:175B模型微调仅需3MB(全量需350GB)
- 计算加速:训练速度提升5-10倍
- 显存优化:FP16下7B模型仅需12GB显存
2.2 灵活的任务切换
# 动态加载不同领域适配器
model = PeftModel.from_pretrained(base_model, "medical_lora")
# 切换至法律领域
model.load_adapter("legal_lora", adapter_name="legal")
2.3 灾难性遗忘防护
通过冻结原模型参数,保留预训练知识:
原模型参数冻结率:100%
可训练参数占比:<1%
2.4 多任务协同
支持同时加载多个LoRA模块:
model.add_adapter(task1_lora)
model.add_adapter(task2_lora, adapter_name="task2")

三、实战:用LoRA打造专属AI助手
3.1 环境配置
pip install peft transformers accelerate bitsandbytes
# 推荐使用Colab Pro+ 32GB显存
3.2 数据准备(以客服对话为例)
// train.json
[{"instruction": "处理退货申请", "input": "商品已破损", "output": "已为您发起全额退款"},{"instruction": "查询物流信息", "input": "运单号123456", "output": "包裹已到达北京中转站"}
]
3.3 模型微调代码
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM# 加载基础模型
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-7B")# 配置LoRA
lora_config = LoraConfig(r=8,lora_alpha=32,target_modules=["q_proj", "v_proj"],lora_dropout=0.05,bias="none",task_type="CAUSAL_LM"
)# 应用适配器
model = get_peft_model(model, lora_config)
print(f"可训练参数占比:{model.print_trainable_parameters()}")# 开始训练
trainer.train()
3.4 模型部署
# 合并权重
merged_model = peft_model.merge_and_unload()# 保存模型
merged_model.save_pretrained("./final_model")
tokenizer.save_pretrained("./final_model")
四、行业应用案例
4.1 医疗领域
- 症状诊断:在通用医疗模型上微调,准确率提升17%
- 病历摘要:处理专业术语时F1值达0.92
4.2 金融风控
- 合同解析:条款提取准确率91.3%
- 欺诈检测:AUC值提升至0.89
4.3 游戏开发
- NPC对话:支持20+角色性格定制
- 剧情生成:动态调整故事走向
五、进阶技巧与挑战
5.1 参数调优策略
- 秩选择:从r=4开始,逐步增加至r=64
- 混合精度:使用bfloat16节省30%显存
- 梯度裁剪:设置max_grad_norm=1.0
5.2 常见问题解决方案
| 问题现象 | 可能原因 | 解决方案 |
|---|---|---|
| 损失不下降 | 学习率过高 | 降至1e-5~5e-5 |
| 生成文本重复 | Dropout不足 | 增加至0.15-0.2 |
| 显存溢出 | 批次过大 | 启用gradient_checkpointing |
5.3 前沿发展方向
- QLoRA:4-bit量化+LoRA,7B模型仅需4GB显存
- LoRA+MoE:混合专家架构下的参数高效微调
- 自动化秩选择:基于NAS的秩优化算法
结语:LoRA开启的AI平权时代
从百亿参数模型的"奢侈品"到人人可玩的"数字积木",LoRA技术正在重塑AI开发的格局。开发者只需掌握20%的核心参数,就能释放大模型80%的潜力。正如乐高积木通过标准接口实现无限组合,LoRA为AI创新提供了标准化、低成本的解决方案。立即尝试本文的实战代码,在你的项目中开启LoRA之旅吧!
延伸资源:
- https://github.com/huggingface/peft
- https://huggingface.co/Qwen/Qwen-7B