PEFT库实战快速入门
前言
PEFT库AutoPeftModel 的设计理念与 Transformers 库的 AutoModel 一脉相承,旨在少量代码就能自动高效微调任务
介绍

和Transformer一样,PEFT也是Hugging Face提供的库,PEFT 是一个为大型预训练模型提供多种高效微调方法的 Python 库。我们知道微调传统范式是针对每个下游任务微调模型参数。大模型参数总量庞大,这种方式变得极其昂贵和不切实际,而PEFT 采用的高效做法是训练少量提示参数 ( Prompt Tuning ) 或使用低秩适应 ( LoRA ) 等重新参数化方法来减少微调时训练参数的数量。
线上运行测试工具
在huggingface官网上支持线上运行不同模型,如下通过下拉选择模型类型。
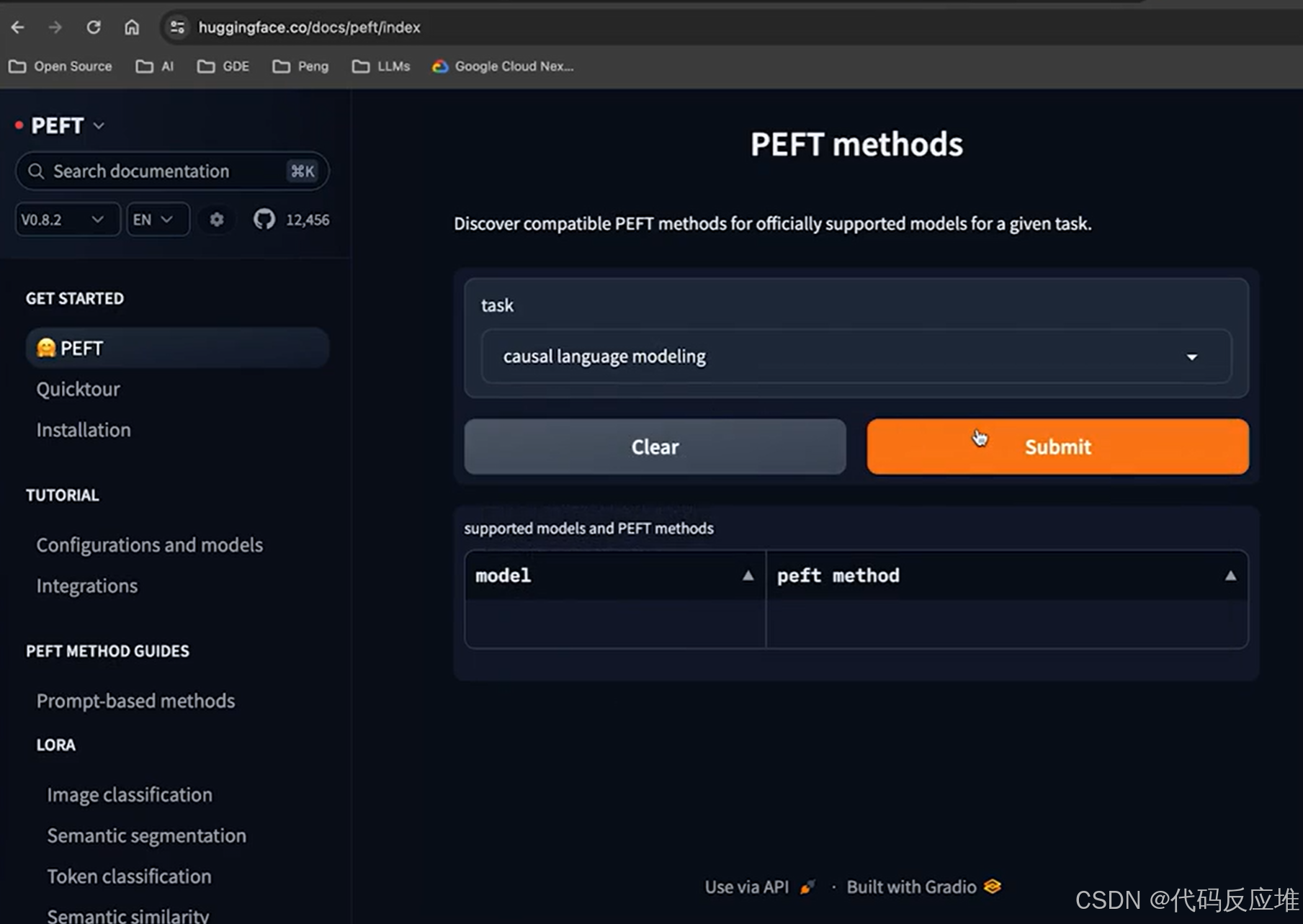
点提交可以看到支持的模型及支持的PEFT的方法
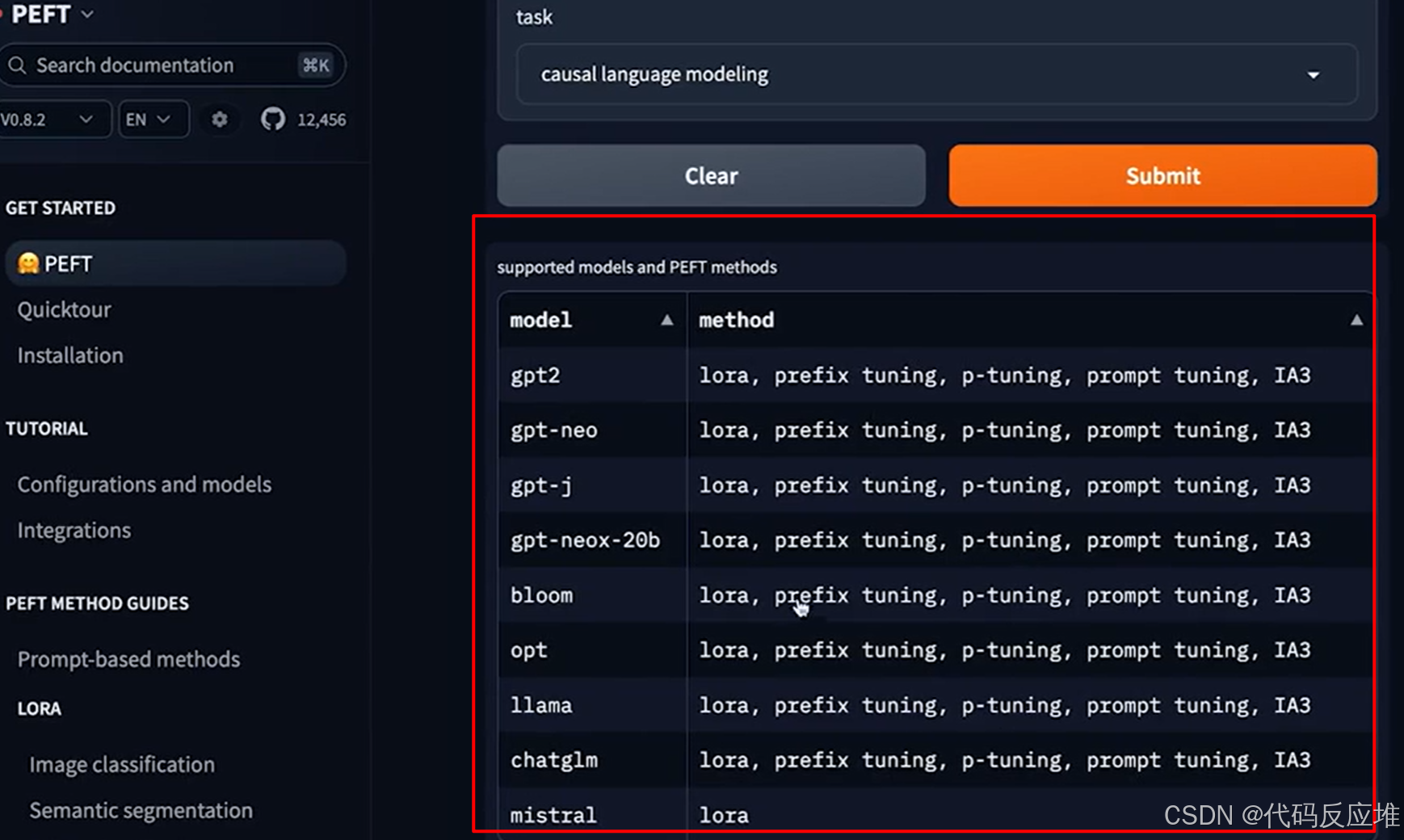
PEFT与Transformers如何集成
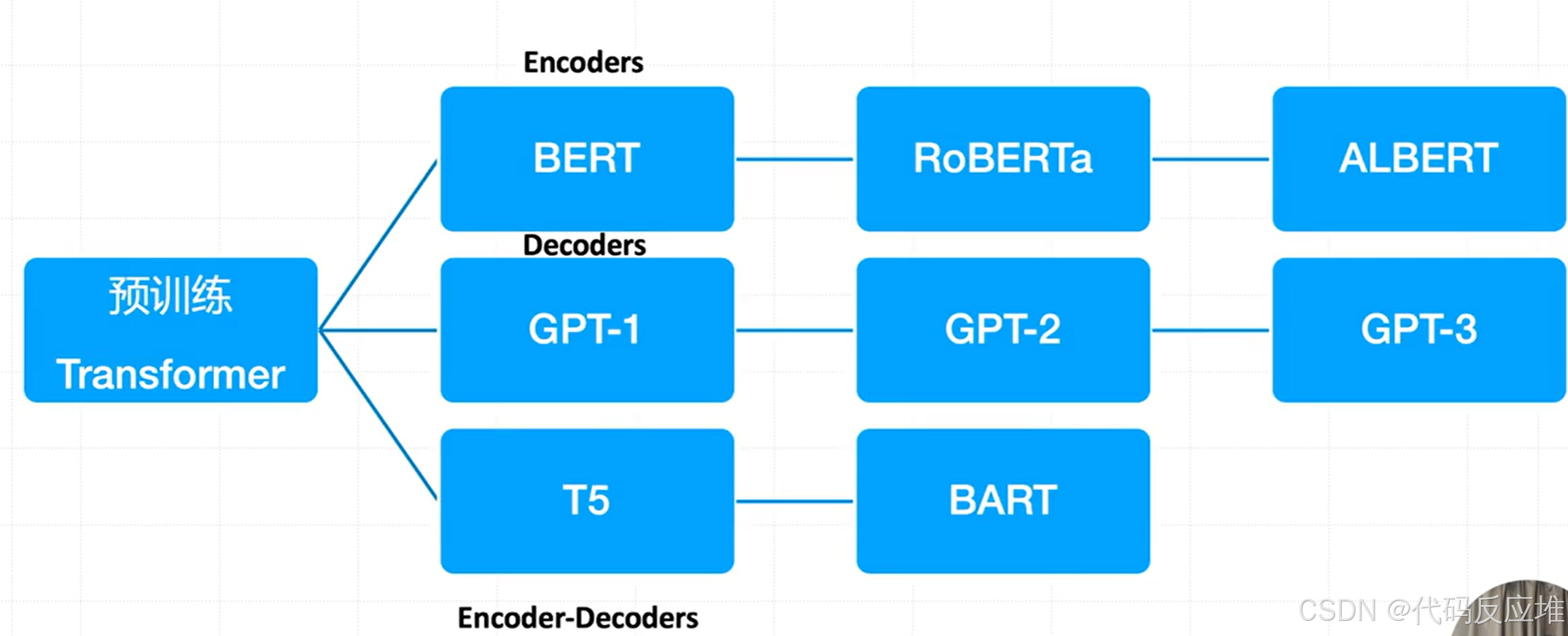
(1)基于 Transformer 的预训练模型分为三大类:
1、Encoders(编码器模型) :主要用于理解语言(如文本分类、实体识别),代表模型:BERT、RoBERTa、ALBERT
2、Decoders(解码器模型):主要用于生成语言(如文本生成),代表模型:GPT-1、GPT-2、GPT-3
3、Encoder-Decoders(编码器-解码器模型):适用于序列到序列的任务(如翻译、摘要),代表模型:T5、BART
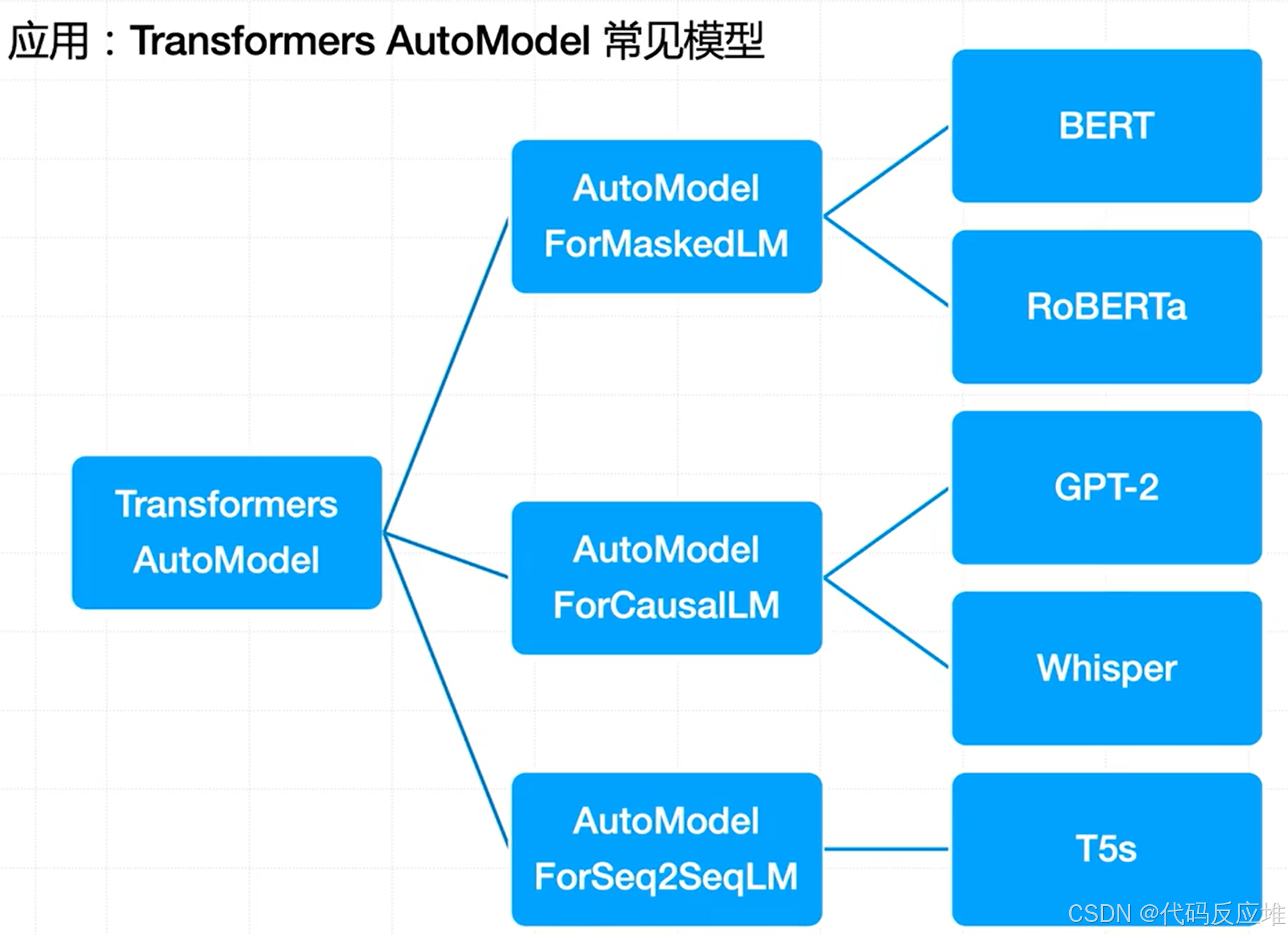
(2)Hugging Face 库中常用的 AutoModel 应用接口对应的典型模型
1、AutoModelForMaskedLM:适用于掩码语言建模(如填空任务),对应模型:BERT、RoBERTa
2、AutoModelForCausalLM:适用于因果语言建模(即自回归生成),对应模型:GPT-2、Whisper(注:Whisper 主要用于语音识别,但也基于 decoder 结构)
3、AutoModelForSeq2SeqLM:适用于序列到序列任务(如翻译、摘要),对应模型:T5
(3)Hugging Face Transformers 库中 AutoClasses 的设计理念与架构
核心思想是提供一个统一、自动化的接口(from_pretrained()),让用户无需关心底层模型的具体结构,仅通过模型名称或路径就能加载所需的全部组件。
- 预训练权重
- 配置文件
- 分词器(Tokenizer)
- 特征提取器(Feature Extractor)
- 处理器(Processor)等
支持 PyTorch、TensorFlow、Flax 三大深度学习框架。覆盖 NLP、CV、音频、多模态等多种AI任务,开发者可以扩展 AutoClasses 以支持新模型或新任务。高度抽象和用户友好的设计,极大降低了使用预训练模型的门槛
AutoClasses的通用基础类(Generic Model Classes):AutoModel负责通用模型加载(默认使用Pytorch),TFAutoModel为TensorFlow 版本,FlaxAutoModel使用JAX/Flax 版本。
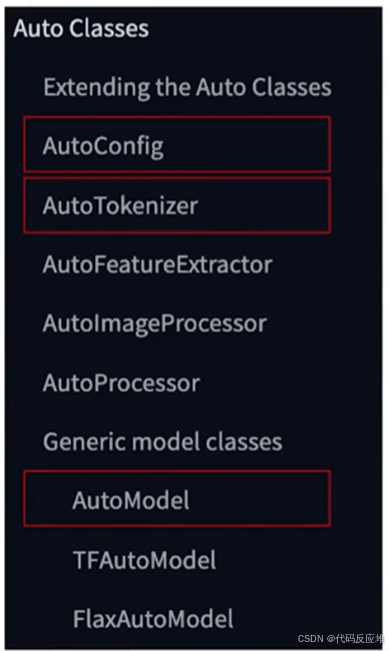
在**自然语言处理(NLP)**上包括多种任务专用类:AutoModelForCausalLM(因果语言模型,如 GPT)、AutoModelForMaskedLM(掩码语言模型,如 BERT)、AutoModelForSeq2SeqLM(序列到序列模型,如 T5、BART),每个类都有 TensorFlow(TF)和 Flax 的版本
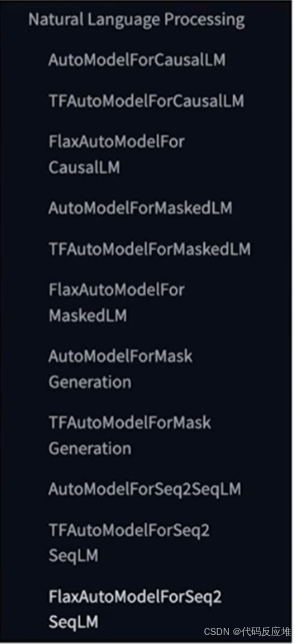
在**计算机视觉(Computer Vision)**上涵盖图像任务,AutoModelForImageClassification(图像分类)
、AutoModelForObjectDetection(目标检测)、AutoModelForDepthEstimation(深度估计)、AutoModelForMaskedImageModeling(掩码图像建模,如 SimMIM、MAE)
在**音频(Audio)**上,AutoModelForAudioClassification(音频分类)、AutoModelForAudioFrameClassification(音频帧分类)

在**多模态(Multimodal)**上处理跨模态任务,AutoModelForTableQuestionAnswering(表格问答)、AutoModelForDocumentQuestionAnswering(文档问答)。
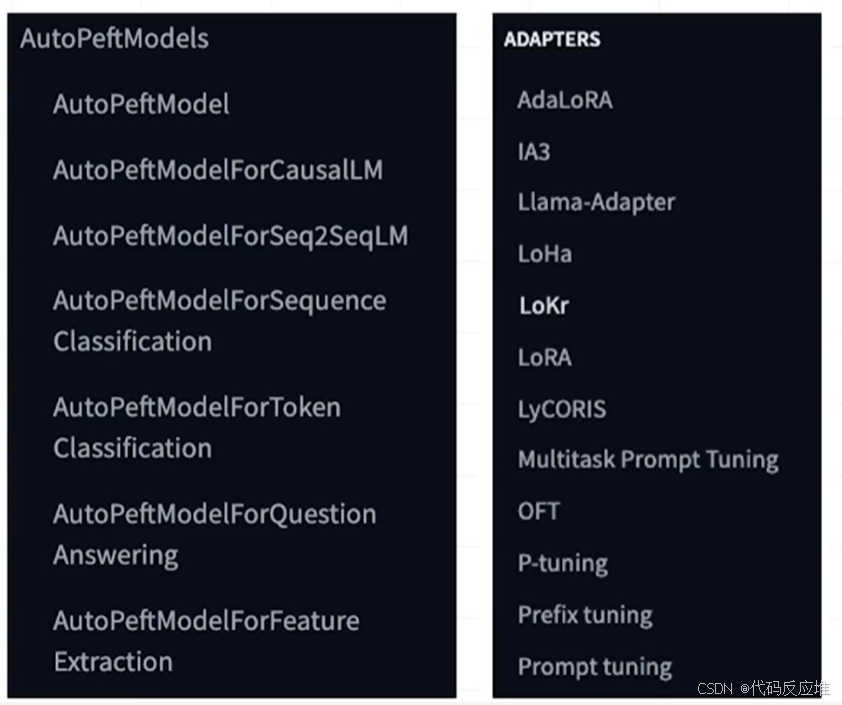
(4)PEFT AutoPeftModels与Adapters设计
AutoPeftModel 的设计理念与 Transformers 库的 AutoModel 一脉相承,旨在一行代码
- 自动推断任务类型(如因果语言建模、序列分类等)。
- 自动加载正确的模型类(如
AutoPeftModelForCausalLM)。 - 自动处理底层的
PeftConfig,用户无需手动指定。
如下图列出了为不同任务设计的AutoPeftModels专用类及支持的适配器,适配器支持多种前沿的参数高效微调技术。
(5)PEFT的LoraModel示例快速配置和应用 LoRA 微调
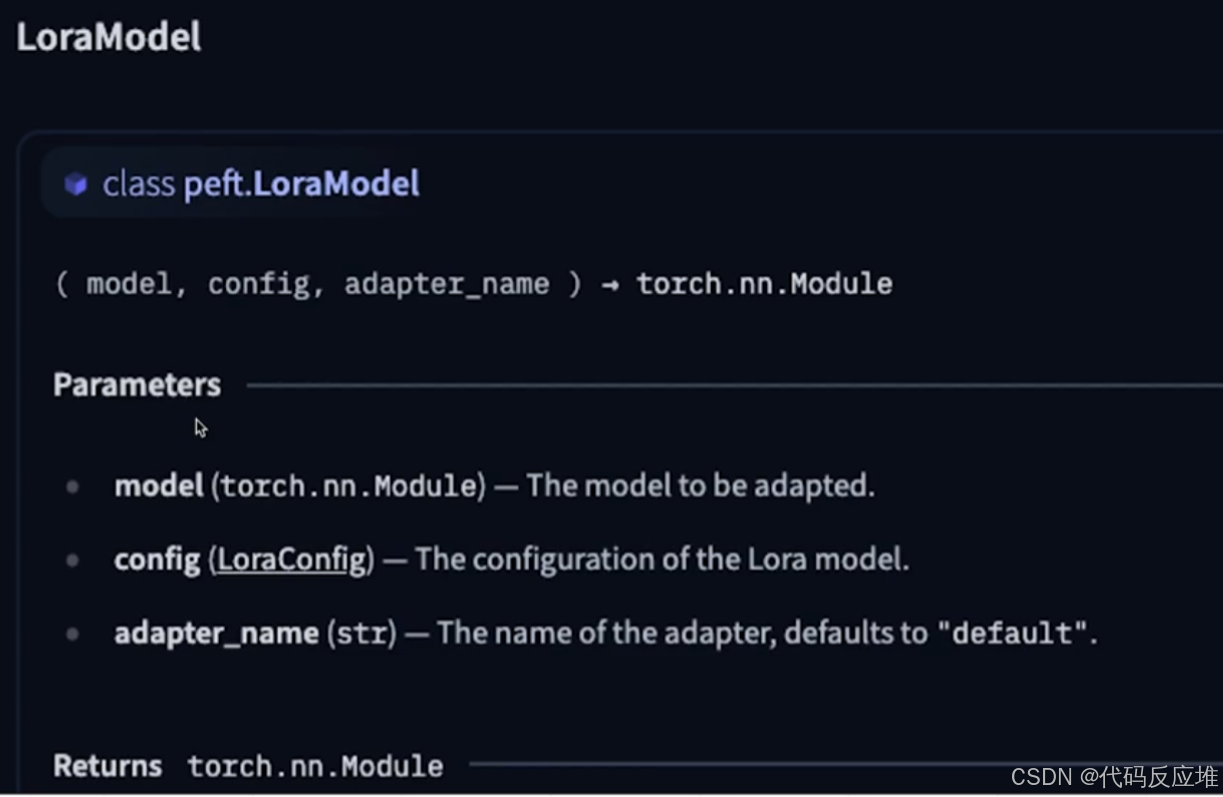
使用 PEFT 库中的 LoraModel 类,将一个普通的预训练模型转换为一个可以进行 参数高效微调 (LoRA) 的模型
# 导入核心工具,LoraConfig: 用于定义 LoRA 的所有超参数。
# get_peft_model: 一个工具函数,它接收原始模型和配置,内部自动创建并返回一个 LoraModel(或更通用的 PeftModel)。这比# 直接实例化 LoraModel 更常用、更便捷。
# 从peft库导入LoraConfig和get_peft_model函数
from peft import LoraConfig, get_peft_model# 创建一个LoraConfig对象,用于设置LoRA (Low-Rank Adaptation) 的配置参数
config = LoraConfig(r=8, # LoRA的秩,影响LoRA矩阵的大小,lora_alpha=32, # LoRA适应的比例因子# 指定将LoRA应用到的模型模块,通常是attention和全连接层的投影target_modules = ["q_proj", "k_proj", "v_proj", "out_proj", "fc_in", "fc_out"], # 指定将 LoRA 适配器添加到原模型的哪些线性层(Linear Layers)。这是最重要的参数之一,需要根据模型架构来指定。lora_dropout=0.05, # 在LoRA模块中使用的dropout率,以防止过拟合。bias="none", # 设置bias的使用方式,偏置项处理。"none" 表示不训练任何偏置参数task_type="CAUSAL_LM" # 任务类型,这里设置为因果(自回归) 语言模型,即自回归生成任务,如 GPT
)# 使用get_peft_model函数和给定的配置来获取一个PEFT模型,原始的大部分参数被冻结,只有在 target_modules 上新增的、数量极少的 LoRA 参数是可训练的。
model = get_peft_model(model, config)# 打印出模型中可训练的参数
model.print_trainable_parameters()
# 输出: trainable params: 8,388,608 || all params: 6,666,862,592 || trainable%: 0.12582542214183376
# 这意味着用户可以用极小的计算资源和存储开销(只需保存这几兆的 LoRA 权重),高效地定制一个庞大的模型。