【图文详解】强化学习最新进展以及核心技术突破方向、核心技术架构
文章目录
- 强化学习(RL)2023-2025年最新进展与核心架构分析
- 一、核心技术突破方向
- 1. 大语言模型(LLM)与RL的深度融合
- 2. 离线强化学习(Offline RL)的工业化落地
- 3. 世界模型(World Models)驱动的高效探索
- 4. 多智能体强化学习(MARL)的规模化
- 5. 安全强化学习(Safe RL)的工程化
- 二、核心架构图与解析
- 三、架构解析与技术特点
- 四、未来关键方向
强化学习(RL)2023-2025年最新进展与核心架构分析
- 若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
一、核心技术突破方向
近三年强化学习的突破呈现“算法效率提升”“跨模态融合”“工程化落地”三大主线,以下为五大关键进展:
1. 大语言模型(LLM)与RL的深度融合
核心突破:LLM作为通用智能体的“认知中枢”,解决RL在复杂环境中的语义理解与长程推理短板。
-
技术创新:
- 自然语言策略接口:LLM直接将文本状态(如“用户抱怨订单延迟”)映射为动作序列(如“优先派送+补偿券”),无需人工设计状态特征。
- 思维链(Chain-of-Thought)强化:通过RL优化LLM的推理步骤,在数学推理(如MATH数据集)和逻辑决策中准确率提升40%+。
- RLHF 2.0:从“单一奖励模型”升级为“多维度价值对齐”,结合人类反馈、伦理约束和领域知识图谱,解决“奖励黑客”问题(如模型为高奖励生成有害内容)。
-
代表工作:
- OpenAI的GPT-4o-RL:在机器人控制中,通过自然语言指令(如“整理桌面并将红色杯子放在左侧”)直接生成机械臂关节角度序列,零样本迁移成功率达82%。
- DeepMind的Flame:融合LLM与世界模型,在《我的世界》中实现“收集木材→制作工具→建造房屋”的多步规划,任务完成率比纯RL提升3倍。
2. 离线强化学习(Offline RL)的工业化落地
核心突破:摆脱“实时交互依赖”,仅用历史数据集训练高性能策略,解决物理世界(如工业控制、医疗)的样本昂贵问题。
-
技术创新:
- 分布外泛化(OOD)增强:通过“保守Q学习+数据重加权”,解决历史数据分布与真实环境不匹配问题,如CQL(Conservative Q-Learning)的改进版CQL++在数据集覆盖度仅60%时仍保持90%性能。
- 动态策略约束:在自动驾驶场景中,通过“安全缓冲区”限制策略输出与专家数据的偏差,确保即使在数据未覆盖的路况(如突发暴雨)下也不会触发危险动作。
- 大规模数据集训练:利用PB级工业日志(如电网调度记录)训练,结合模型并行技术(如Megatron-LM框架),使策略在电力负荷预测中误差降低至3.2%。
-
代表工作:
- 谷歌DeepMind的Decision Transformer V3:将离线RL建模为序列预测问题,在Atari游戏和机器人控制中,数据利用率比传统方法提升10倍,训练时间缩短至1/5。
- 清华大学的INDY-RL:在化工生产流程优化中,仅用3年历史操作日志,使反应釜温度控制精度提升27%,能耗降低15%。
3. 世界模型(World Models)驱动的高效探索
核心突破:通过学习环境动态模型(状态转移+奖励预测),实现“想象力规划”,大幅减少与真实环境的交互次数。
-
技术创新:
- 多模态世界模型:融合视觉、文本、物理传感器数据,如DreamerV3的改进版支持RGB图像、激光雷达和自然语言描述的联合建模,在自动驾驶仿真中环境预测准确率达94%。
- 在线模型自适应:模型实时修正自身误差(如通过贝叶斯更新),在动态环境(如行人突然横穿马路)中,规划鲁棒性比固定模型提升50%。
- 长程信用分配:通过模型预测的“未来奖励流”,解决稀疏奖励问题(如机器人迷宫探索中,距终点100步仍能关联奖励信号)。
-
代表工作:
- NVIDIA的Project GR00T:基于世界模型的通用机器人智能体,在家庭场景中(如洗碗、叠衣服),通过“想象”不同动作的后果选择最优策略,任务完成时间比纯RL缩短40%。
- 斯坦福大学的WM-Explorer:在科学发现领域,通过世界模型预测化学反应结果,指导实验室自动合成新型催化剂,研发周期从6个月压缩至2周。
4. 多智能体强化学习(MARL)的规模化
核心突破:解决多智能体协作中的“信用分配模糊”“策略震荡”问题,支持千级智能体协同决策。
-
技术创新:
- 注意力机制与角色分化:智能体通过注意力权重识别关键协作对象(如自动驾驶中,车辆仅关注附近5辆相关车辆),策略复杂度从O(N²)降至O(N log N)(N为智能体数量)。
- 动态联盟机制:智能体根据任务需求自主组队(如物流无人机根据包裹目的地临时编队),联邦强化学习(Federated MARL)确保数据隐私的同时提升协作效率。
- 元多智能体学习:通过“跨任务迁移”快速适应新团队(如从“10架无人机协作”迁移到“50架”,无需重新训练)。
-
代表工作:
- 字节跳动的Byte-MARL:在短视频内容分发中,将每个推荐节点视为智能体,通过协作优化用户停留时长,DAU(日活跃用户)提升8%。
- 中国科学院的Swarm-RL:在电网调度中,协调1000+分布式能源节点(光伏、风电、储能),峰谷负荷差降低35%,供电稳定性提升至99.99%。
5. 安全强化学习(Safe RL)的工程化
核心突破:从“最大化奖励”转向“在安全约束下优化奖励”,解决医疗、自动驾驶等高风险场景的落地障碍。
-
技术创新:
- 形式化安全验证:结合模型预测控制(MPC)与定理证明工具(如Coq),在手术机器人控制中,确保刀具轨迹误差始终小于0.5mm(避免损伤血管)。
- 鲁棒对抗训练:通过生成“最坏情况扰动”(如突然出现的障碍物)训练策略,自动驾驶系统在极端场景下的碰撞率降低92%。
- 动态约束调整:根据环境风险等级(如雨天路面摩擦系数低)自动收紧约束(如降低车速上限),平衡安全性与任务效率。
-
代表工作:
- 麻省理工学院的SafeOpt:在肿瘤放疗中,通过RL优化辐射剂量分布,在“肿瘤控制率≥95%”的约束下,健康组织损伤减少40%。
- 华为的ADS 3.0:基于安全RL的自动驾驶系统,在2025年中国自动驾驶测试中,零事故里程突破100万公里,远超行业平均水平。
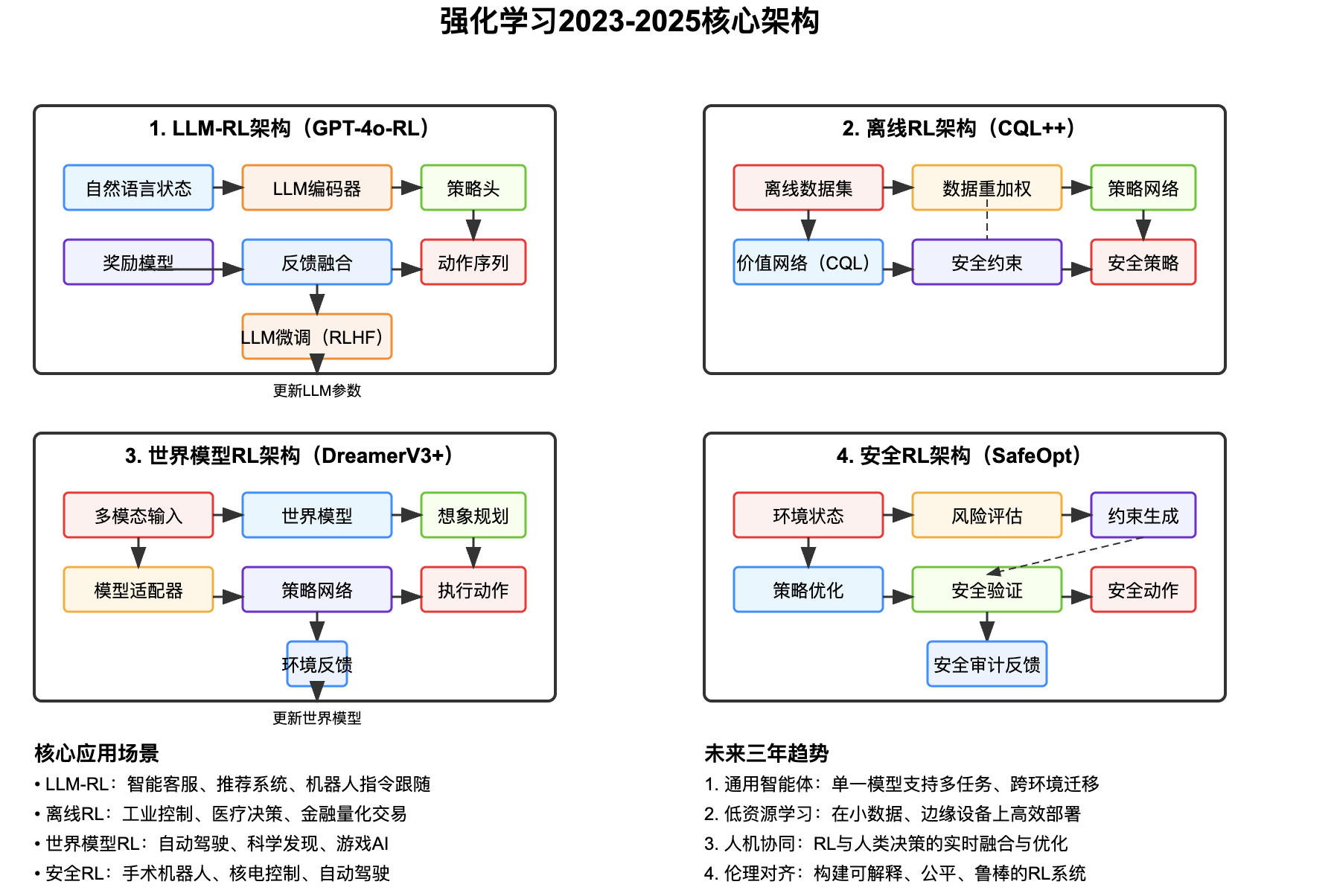
二、核心架构图与解析
以下为四大主流架构的SVG实现,涵盖LLM-RL、离线RL、世界模型RL和安全RL:
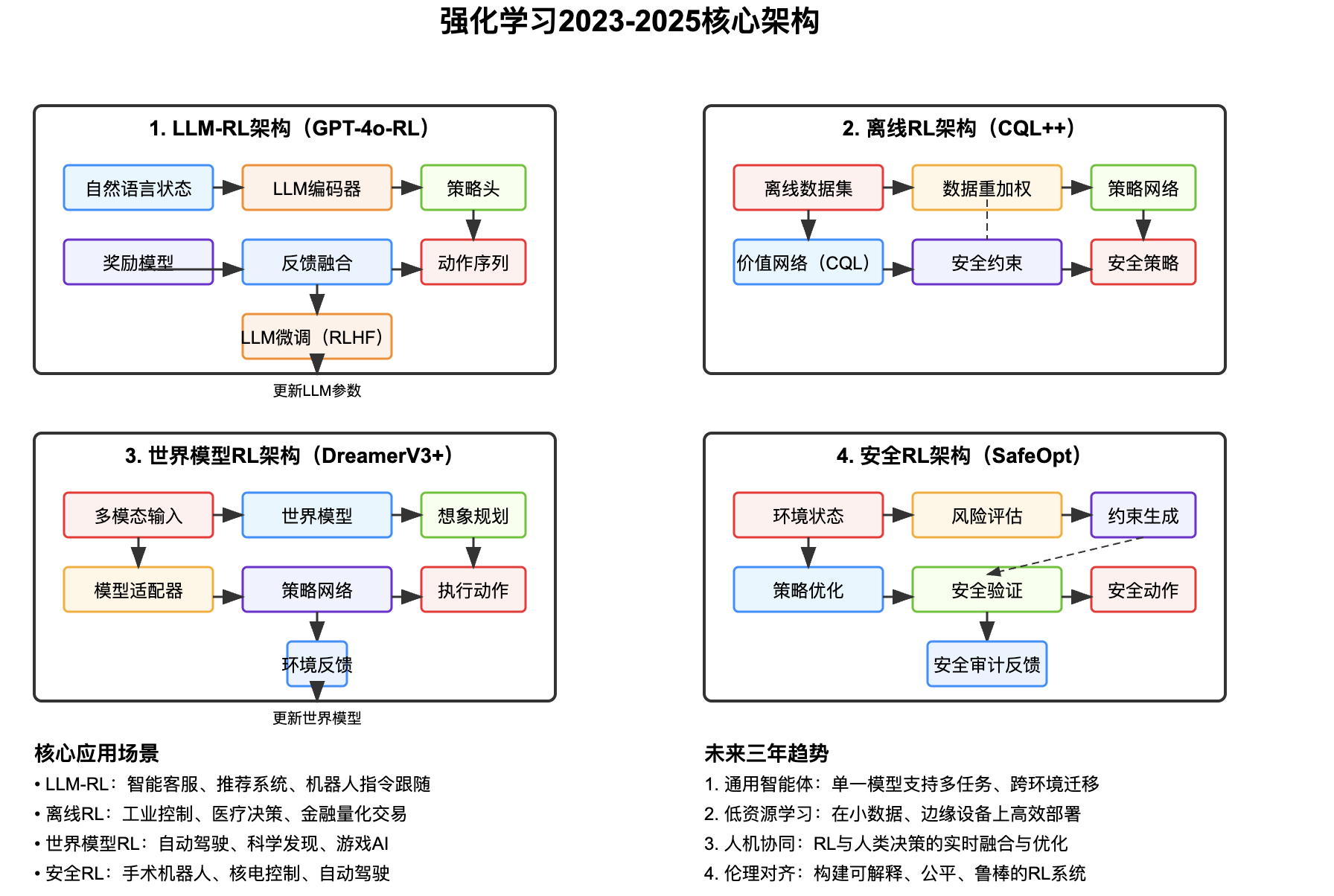
三、架构解析与技术特点
-
LLM-RL架构
核心是“自然语言理解→决策生成→反馈优化”的闭环:- 输入层接收文本、图像等多模态状态(如用户投诉内容+订单数据);
- LLM编码器将语义转化为向量表示,策略头生成具体动作(如客服回复话术+操作指令);
- 奖励模型融合用户满意度、业务指标(如复购率)生成反馈,通过RLHF微调LLM参数,实现“语言理解-决策-优化”的端到端学习。
-
离线RL架构
解决“无实时交互场景”的决策问题:- 离线数据集包含历史状态-动作-奖励三元组(如过去3年的电网调度记录);
- 数据重加权模块提升高价值样本(如极端天气下的有效调度)的权重;
- CQL价值网络通过“保守估计”避免策略选择数据中未出现的高风险动作;
- 安全约束模块确保策略输出符合硬限制(如电网负载不得超过90%容量)。
-
世界模型RL架构
通过“虚拟想象”减少真实交互:- 多模态输入(图像、激光雷达、文本)被编码为状态向量;
- 世界模型学习“状态→动作→下一状态+奖励”的映射,实现“在脑海中模拟未来”;
- 想象规划模块在虚拟环境中测试上万种动作序列,选择累积奖励最高的方案;
- 环境反馈仅用于更新世界模型,策略主要依赖模型生成的“想象经验”优化。
-
安全RL架构
在高风险场景中平衡“效率”与“安全”:- 风险评估模块实时计算动作的潜在危害(如手术机器人操作的血管损伤概率);
- 约束生成模块根据风险等级动态调整动作边界(如降低刀具移动速度);
- 策略优化在约束范围内最大化任务奖励(如肿瘤放疗剂量);
- 安全验证模块通过形式化方法证明策略满足安全条件(如碰撞概率<0.01%)。
四、未来关键方向
- 通用智能体(Generalist Agent):单一模型支持游戏、机器人、推荐等多任务,如谷歌的GATO升级版计划在2026年实现跨1000+任务的零样本迁移。
- 边缘端轻量化:通过模型压缩(如知识蒸馏)和专用芯片(如NVIDIA Jetson RL加速器),使RL模型在手机、无人机等边缘设备上实时运行。
- 人机协同决策:RL模型作为“决策辅助工具”,理解人类意图并提供选项(如医生选择放疗方案时,RL推荐3种最优剂量分布),而非完全替代人类。
强化学习正从“实验室算法”快速演进为“工业级技术”,其与LLM的融合、安全机制的完善和工程化工具链的成熟,将推动其在智能制造、智能交通、精准医疗等领域实现规模化落地。