课题学习——SimCSE
1.调研SimCSE
SimCSE发表于人工智能和机器学习领域的顶级国际会议 ICLR 2021
ICLR 2021 的杰出论文奖
开源代码GitHub 地址:https://github.com/princeton-nlp/SimCSE
2.研究进展
ESimCSE: Enhanced SimCSE
论文:ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
发表会议:EMNLP 2022
核心改进:针对无监督 SimCSE 的一个潜在问题——仅依靠 Dropout 构建正样本对,多样性可能不足。ESimCSE 提出了两种增强方法:
动量对比:引入一个动量编码器来生成更一致的目标表示,类似于 MoCo 在计算机视觉中的做法,可以扩大负样本队列的大小。
单词重复和删除:一种更积极的数据增强策略,通过随机重复或删除句子中的少量单词来构造正样本对,作为 Dropout 之外的有效补充。
PromptBERT: 使用提示(Prompt)改进 BERT 句向量
论文:PromptBERT: Improving BERT Sentence Embeddings with Prompts
发表会议:ACL 2022
核心思想:指出了 BERT 系列模型在获取句向量时的一个根本性问题:各向异性(anisotropy),即词向量分布在一个狭窄的锥形空间中,而不是均匀分布,这限制了其表达能力和表现。SimCSE 通过对比学习缓解了此问题,而 PromptBERT 提供了另一种思路。
方法:通过设计模板(Prompt,例如:
"[X] The sentence is [MASK].")将原始句子[X]填入,然后使用[MASK]位置的输出向量作为整个句子的表示。他们发现,这种方法得到的向量空间各向同性(isotropic)更强,分布更均匀。
SNCSE: 解决语义负例(False Negative)问题
论文:SNCSE: Contrastive Learning for Unsupervised Sentence Embedding with Soft Negative Samples
发表会议:ACL 2023
核心问题:对比学习中的一个关键假设是:负样本在语义上应与锚点样本不同。但在无监督 SimCSE 中,随机从批次中采样的负样本可能实际上与锚点句子是语义相似的(例如,“今天天气真好”和“阳光明媚的一天”),这些被称为 “False Negatives”或“Semantic Negative”。强行拉远这些样本的距离会损害模型性能。
方法:SNCSE 提出了一种方法来软化这些语义负例的惩罚。它通过计算句子之间的语义相似度来估计一个负样本是“真负例”还是“语义负例”的概率,并据此调整对比损失函数,减轻对语义相似句子的推远力度。
SimCSE是影响力很大的一篇文章,关键在于将简单有效,引入对比学习,后续只是在数据、模型、对比学习方面进行了优化。SimCSE的复现资料很多
3.SimCSE解读
SimCSE可以有监督学习和无监督学习,两个版本都取得了当时最好的效果。
论文指出,像BERT这样的预训练模型产生的句子向量存在“各向异性”(Anisotropy)。这意味着这些向量并不是均匀分布的,而是拥挤在一个狭窄的锥形区域里。这样一来,即使两个句子语义上毫不相关,它们的向量因为都被挤在角落,余弦相似度也可能很高。这严重损害了向量表示的质量和区分度。
对比学习通过推远负样本的机制,隐式地最小化了所有句子向量两两相似度的总和。而这个最小化过程,在数学上等价于在约束条件下压平了相似度矩阵的特征值分布,从而将嵌入向量从拥挤的狭小空间解放出来,使其均匀地分布在整个空间中,极大地提升了表示质量。
有监督
SimCSE主要使用两个NLI数据集:SNLI、MNLI
都是三元组(Triplet) 结构,包含一个前提(Premise) 和两个基于该前提生成的假设(Hypothesis),并为每个假设提供一个标签(Label)蕴含、矛盾、中立。中立标签在SimCSE的最终模型中未被使用(作者实验后发现加入它没有提升)。
通常以JSONL格式存储
{
"sentence1": "A soccer game with multiple males playing.",
"sentence2": "Some men are playing a sport.",
"gold_label": "entailment"
}
如何评判句子向量的质量
Alignment:衡量相似样本对应的特征向量在空间上分布的距离是否足够近
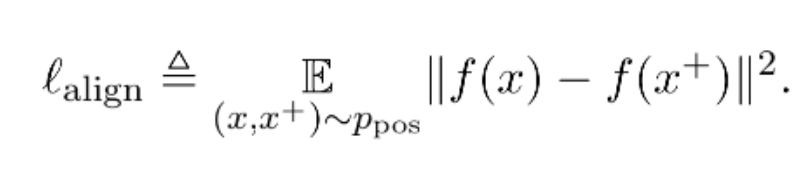 Uniformity:衡量系统保留信息的多样性:映射到单位超球面的特征,尽可能均匀地分布在球面上,分布得越均匀,意味着保留的信息越充分。
Uniformity:衡量系统保留信息的多样性:映射到单位超球面的特征,尽可能均匀地分布在球面上,分布得越均匀,意味着保留的信息越充分。
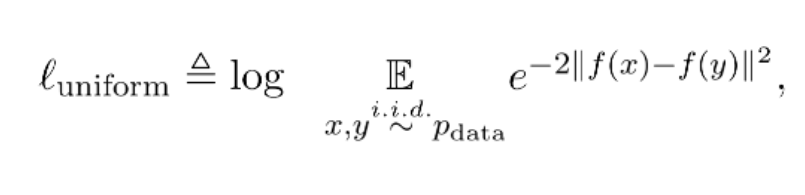
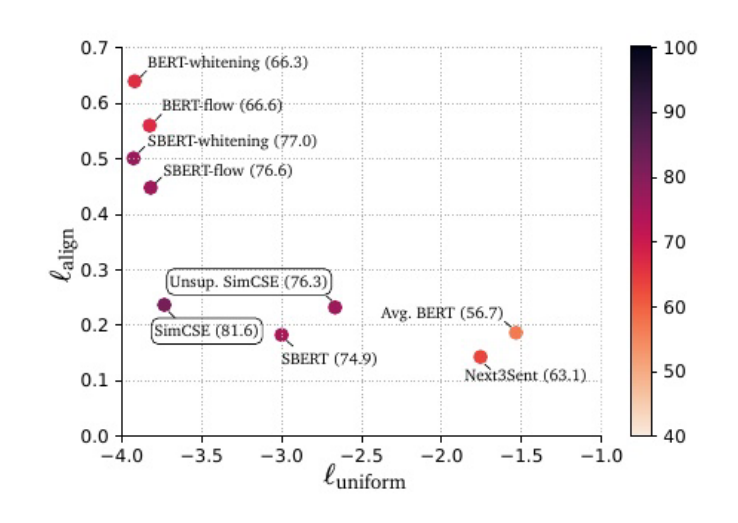
作者将不同方法得到的Sentence Embeddings空间的Alignment和Uniformity指标进行比对(两个指标均为越小越好),通过下图我们可以得到相比于直接使用预训练的Bert,SimCSE方法较大程度提升了uniformity
实验结果
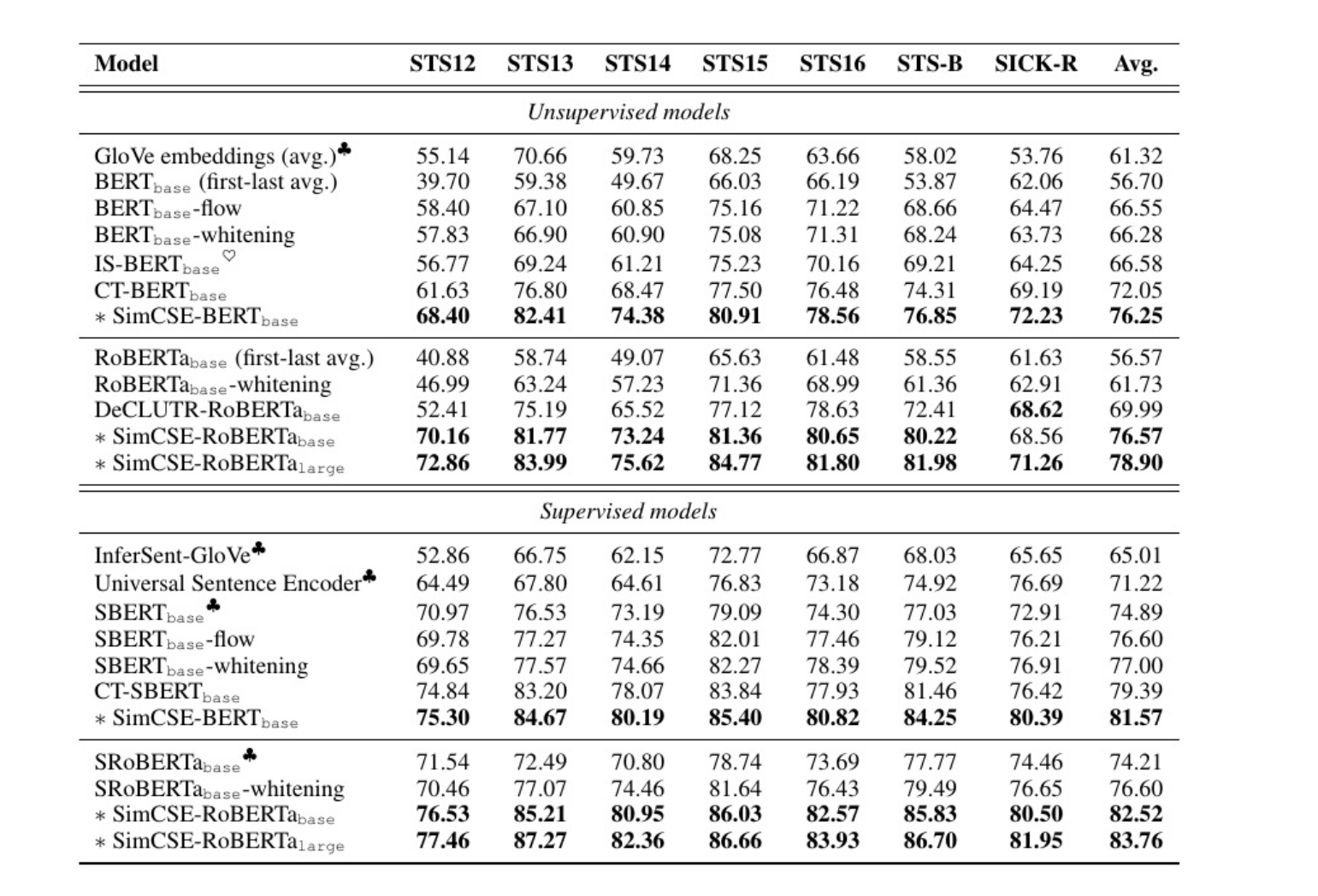
这个表格中的所有数字都是百分比形式的Spearman相关系数(模型预测的句子相似度排名与人工标注的句子相似度排名之间的一致性),数值越大,说明模型越接近人类的语义判断能力。