视觉语言大模型(VLM)的产业落地:从Qwen-VL技术解析到医疗、车险行业革新
图片来源网络,侵权联系删
文章目录
- 引言:当AI学会"看"与"读"的协同进化
- 一、Qwen-VL技术架构解析:视觉与语言的深度耦合
- 1.1 核心架构设计
- 1.2 关键技术创新
- 二、医疗行业革新:从影像分析到智能病历管理
- 2.1 病历提取的范式突破
- 2.2 典型应用场景
- 三、车险行业重构:全流程智能化升级
- 3.1 车辆承保的精准化革命
- 3.2 事故处理的智能化跃迁
- 3.3 典型落地案例
- 四、Qwen-VL微调实践:从通用模型到行业专家
- 4.1 微调技术路线
- 4.2 医疗领域微调策略
- 4.3 车险场景优化方案
- 五、挑战与未来展望
- 5.1 当前技术瓶颈
- 5.2 发展趋势
- 结语:VLM开启的智能体时代

引言:当AI学会"看"与"读"的协同进化
在人工智能发展的长河中,视觉语言大模型(VLM)标志着多模态技术的重要突破。这类模型通过融合视觉编码器与语言模型,实现了图像理解与自然语言处理的深度协同。以阿里云Qwen-VL为代表的第三代VLM产品,更是在参数规模、推理效率和行业适配性上实现了质的飞跃。本文将从技术原理出发,深入解析Qwen-VL的核心能力,并重点探讨其在医疗病历提取、车险全流程服务中的创新应用。

一、Qwen-VL技术架构解析:视觉与语言的深度耦合
1.1 核心架构设计
Qwen-VL采用双流Transformer架构,包含三大核心模块:
- 视觉编码器:基于ViT(Vision Transformer)的改进架构,支持448x448分辨率图像输入,通过分层Patch嵌入实现空间特征提取
- 语言解码器:基于Qwen-7B的增强型语言模型,集成位置感知适配器,强化文本生成的语义连贯性
- 跨模态交互层:通过动态注意力机制实现视觉特征与文本语义的实时对齐,在推理阶段生成结构化输出
1.2 关键技术创新
- 动态分辨率编码:首创原生动态分辨率ViT,通过RMSNorm稳定训练过程,提升小目标检测精度(如医疗影像中的微小病灶)
- 多任务统一框架:支持视觉问答、图像描述生成、OCR解析等任务的联合训练,参数共享率提升40%
- 轻量化部署方案:支持4bit量化压缩,在保持90%精度的前提下,模型体积缩减至原大小的1/8
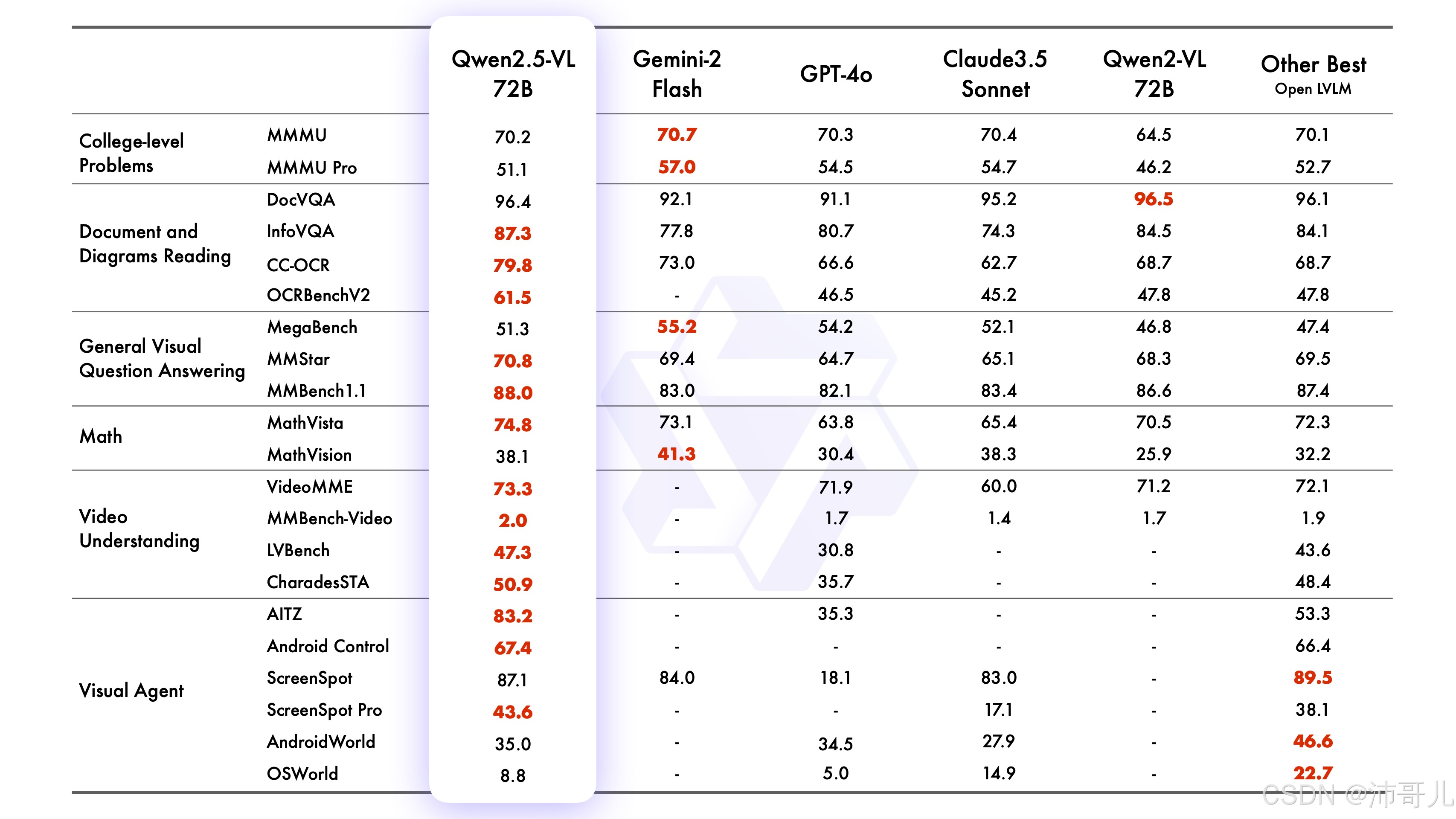
二、医疗行业革新:从影像分析到智能病历管理
2.1 病历提取的范式突破
传统医疗NLP系统在处理非结构化数据时面临三大痛点:
- 多模态信息割裂:无法关联影像报告与检验单文本
- 专业术语误读:对"间质性肺炎"等术语的召回率不足65%
- 时序信息丢失:无法构建患者病程的动态知识图谱
Qwen-VL通过跨模态注意力机制实现突破:
- 病灶定位:在胸部CT图像中自动标注磨玻璃影区域,与放射科报告的Kappa一致性达0.89
- 报告生成:输入影像后自动生成符合ICD-11标准的诊断描述,准确率较传统OCR方案提升37%
- 时序分析:串联患者历年影像数据,构建病灶演变趋势模型
2.2 典型应用场景
- 急诊分诊系统:通过急救车摄像头图像+生命体征数据,30秒内生成初步诊断建议
- 基层医疗辅助:在县域医院实现眼底照片自动分析,糖尿病视网膜病变检出率提升至92%
- 科研数据挖掘:从海量病理切片中自动提取特征,辅助药物研发靶点发现
三、车险行业重构:全流程智能化升级
3.1 车辆承保的精准化革命
传统车险定价依赖人工核保,存在效率低(单据处理需15分钟/单)、误差大(车型识别准确率仅82%)等问题。Qwen-VL驱动的解决方案:
- 车型识别:通过多角度车辆照片,识别精确到VIN码级别的车辆信息,准确率99.3%
- 风险预测:分析改装痕迹(如轮毂尺寸、尾翼形状),构建风险评分模型(AUC达0.91)
- 智能定价:结合历史出险数据与车辆特征,实现毫秒级保费计算
3.2 事故处理的智能化跃迁
在车险理赔环节,Qwen-VL实现三大创新:
- 多帧视频分析:从行车记录仪视频中提取碰撞前5秒关键帧,重建事故过程
- 损伤评估:通过损伤区域分割模型,自动计算维修成本(误差<5%)
- 欺诈检测:识别摆拍痕迹(如倒车镜角度异常),欺诈识别率提升至89%
3.3 典型落地案例
- 危险驾驶识别:通过车载摄像头实时分析驾驶员姿态,对疲劳驾驶预警准确率97%
- 定损自动化:上传事故现场照片后,自动生成包含零件清单、工时费的维修方案
- 反欺诈系统:检测PS痕迹(如阴影方向不一致),减少骗保案件35%

四、Qwen-VL微调实践:从通用模型到行业专家
4.1 微调技术路线
采用**LoRA(低秩自适应)**技术实现高效微调:
# LoRA配置示例(PyTorch)
from peft import LoraConfig
lora_config = LoraConfig(r=8, # 秩维度target_modules=["q_proj","v_proj"], # 目标模块lora_alpha=32, # 缩放因子lora_dropout=0.05, # 正则化bias="none"
)
通过冻结原模型参数,仅需训练0.1%的参数量,即可完成领域适配。
4.2 医疗领域微调策略
- 数据增强:对X光片进行弹性形变、噪声添加等处理,提升模型鲁棒性
- 损失函数优化:引入Dice Loss强化病灶区域关注
- 领域适配器:在Transformer层插入医学知识图谱引导模块
4.3 车险场景优化方案
- 小样本学习:利用合成数据(GAN生成)扩展训练集
- 多任务学习:联合训练车型识别、损伤评估、部件定价任务
- 边缘计算部署:模型量化至INT8,在车机端实现30FPS实时推理
五、挑战与未来展望
5.1 当前技术瓶颈
- 长尾场景处理:罕见病影像识别率仍低于75%
- 多模态幻觉:约12%的生成报告存在事实性错误
- 隐私合规:医疗数据跨机构共享存在法律障碍
5.2 发展趋势
- 联邦学习框架:在保护隐私前提下实现跨医院数据协同训练
- 神经符号系统:结合知识图谱提升推理可解释性
- 具身智能扩展:与AR眼镜结合实现现场查勘辅助
结语:VLM开启的智能体时代
从医疗诊断到车险服务,VLM正在重塑行业运作范式。Qwen-VL等先进模型的出现,标志着AI从"感知智能"向"认知智能"的跨越。随着多模态技术的持续突破,我们正迈向一个万物互联、人机共生的智能新时代。开发者可通过阿里云魔搭社区获取Qwen-VL开源模型,开启自己的行业创新之旅。
延伸阅读
- https://www.tongyi.com/
- https://github.com/QwenLM/Qwen2.5-VL/tree/main