背景建模(基于视频,超炫)项目实战!
什么是背景建模
许多人可能不知道什么是背景建模,,下面我先解释一下
指在计算机视觉中,从视频序列中提取出静态背景的一种技术。在视频中,背景通常被定义为相对稳定的部分,例如墙壁、地面或天空等。背景建模的目标是将动态的前景对象与静态的背景进行分离,以便进一步分析和处理。
方法

解释
我先解释下帧差法,这个就是用视频的前后两个帧图片进行相减,然后求出不同的地方,那么这个不同的地方就是运动的,这个地方就是人或者车子在动。
代码部分
import cv2
import numpy as np# 创建视频捕获对象,读取视频文件
cap = cv2.VideoCapture('test.avi') # 或者使用摄像头: cap = cv2.VideoCapture(0)
# cap = cv2.VideoCapture(0)
# 创建MOG2背景减除器,用于检测运动物体
# history: 用于建模的历史帧数,detectShadows: 是否检测阴影(True为检测)
fgbg = cv2.createBackgroundSubtractorMOG2(history=500, detectShadows=True)# 创建椭圆形结构元素(卷积核),用于形态学操作
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (3, 3))while True:# 读取视频帧ret, frame = cap.read()if not ret:break# 应用背景减除器,获取前景掩码(运动物体区域)fgmask = fgbg.apply(frame)# 形态学开运算(先腐蚀后膨胀),去除噪声和小斑点fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)# 查找轮廓contours, _ = cv2.findContours(fgmask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 在原帧上绘制检测结果for contour in contours:# 过滤掉太小的轮廓(可能是噪声)if cv2.contourArea(contour) < 188: # 面积阈值,可根据需要调整continue# 获取轮廓的边界框x, y, w, h = cv2.boundingRect(contour)# 在原图上绘制矩形框标记运动物体cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)cv2.putText(frame, "Moving Object", (x, y - 5),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)# 显示原始帧和处理结果cv2.imshow('Original Frame', frame)cv2.imshow('Foreground Mask', fgmask)# 按ESC键退出if cv2.waitKey(30) & 0xFF == 27:break# 释放资源
cap.release()
cv2.destroyAllWindows()效果展示
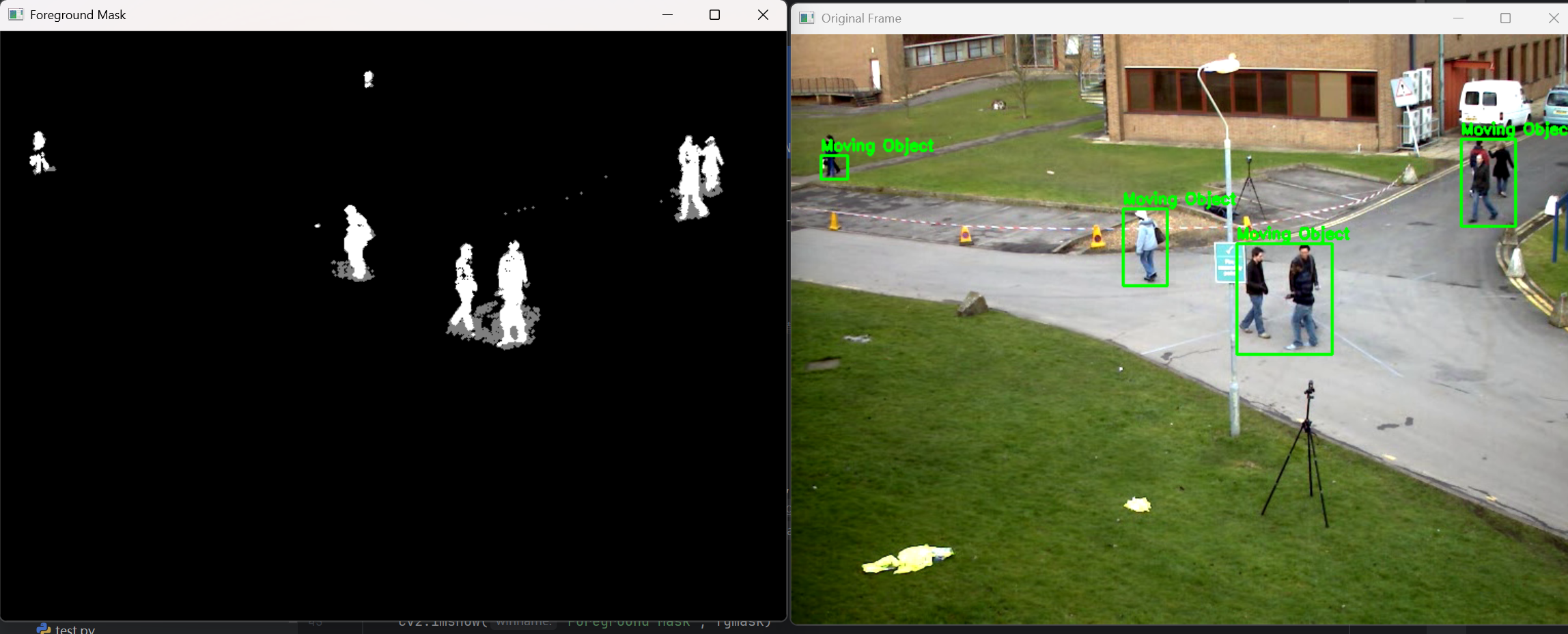
关键步骤解读
1 模型建立
fgbg = cv2.createBackgroundSubtractorMOG2(history=500, detectShadows=True)# 创建椭圆形结构元素(卷积核),用于形态学操作
kernel = cv2.getStructuringElement(cv2.MORPH_CROSS, (3, 3))我们先从cv2的库中找到这些接口,然后创建,再创建出结构元素,用于对图片进行处理。
2 背景去除器
fgmask = fgbg.apply(frame)cv2.imshow('frame', fgmask)# 形态学开运算(先腐蚀后膨胀),去除噪声和小斑点fgmask = cv2.morphologyEx(fgmask, cv2.MORPH_OPEN, kernel)这个我=相当于我们有一个掩膜,帮助我们去除除了运动物体外的东西,例如背景,然后我们经过开运算去除一些噪点。

3 画出人
for contour in contours:# 过滤掉太小的轮廓(可能是噪声)if cv2.contourArea(contour) < 188: # 面积阈值,可根据需要调整continue# 获取轮廓的边界框x, y, w, h = cv2.boundingRect(contour)# 在原图上绘制矩形框标记运动物体cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)cv2.putText(frame, "Moving Object", (x, y - 5),cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)这里就是把人的轮廓画出来,然后把比较小的轮廓给去除了,然后把是人的地方取外界矩形,然后就可以画出来了,并添加文字。
ok啦上面就是我们的全部内容了,这里我们可以仔细想想,是不是我们老家的摄像头会有一种功能,就是有人的时候就会警告,其实就是用这种方法来进行的。
