【论文阅读】4D-VLA:时空视觉-语言-动作预训练与跨场景校准
4D-VLA将4D时空信息整合到视觉-语言-动作(VLA)预训练中,解决了机器人操作中的坐标系混乱和状态混乱等问题。该模型在LIBERO基准测试中实现了12.1%的更高成功率,并在真实世界任务中展现了强大的泛化能力,提高了控制和精度。
引言
视觉-语言-动作(VLA)模型已成为开发通用机器人策略的一种有前途的方法,这些策略能够理解自然语言指令并执行复杂的操纵任务。然而,现有的VLA预训练方法由于输入表示不足而面临根本性限制,导致动作预测模糊。本文介绍了4D-VLA,一个通过将显式4D时空信息融入预训练过程来解决这些挑战的框架。
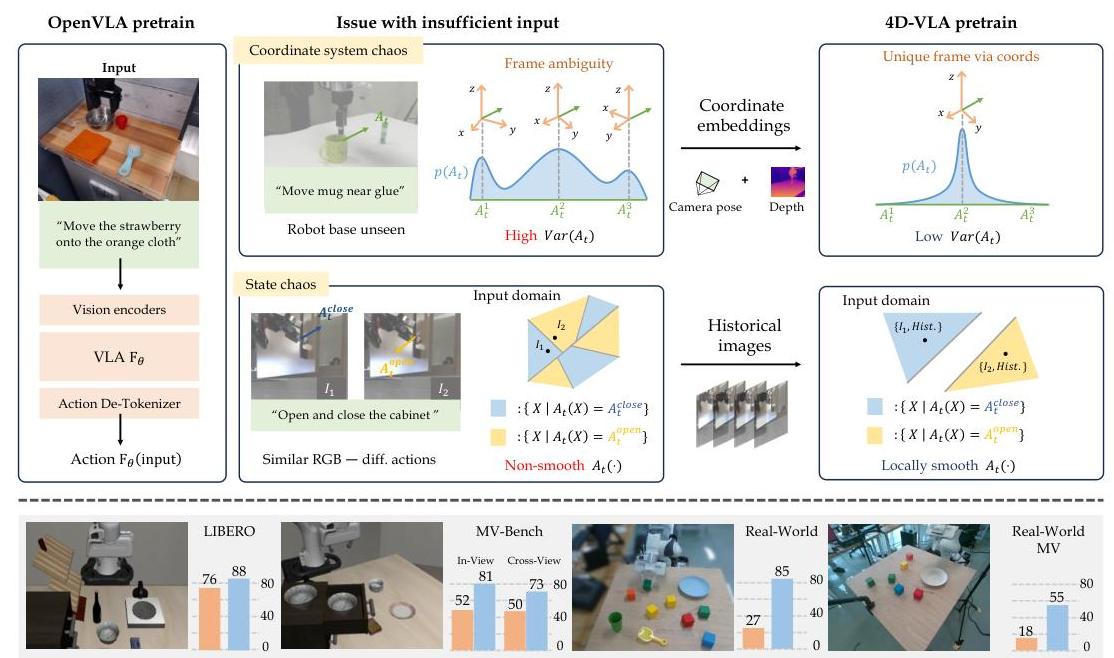
图1:OpenVLA和4D-VLA方法的比较。左侧显示了输入不足如何导致坐标系统混乱和状态混乱,从而产生高方差的动作分布。右侧展示了4D-VLA如何使用坐标嵌入和历史图像来创建更集中、低方差的动作分布。
问题识别:当前VLA模型中的混乱
作者指出了阻碍当前VLA预训练方法有效性的两个关键问题:
坐标系统混乱发生在机器人动作在机器人局部坐标系中定义时,但视觉观测缺乏足够的空间上下文来确定机器人的精确位置和方向。例如,在DROID数据集中,67%的样本机器人的底座被遮挡,使得空间上准确地确定动作位置变得不可能。这种模糊性导致条件动作分布分散,相同的视觉输入可能对应着截然不同的有效动作。
状态混乱发生在单个视觉帧提供不足的时间或上下文信息来推断正确动作时。例子包括对称轨迹,其中运动方向无法从静态图像中确定,或者视觉上相似但需要完全不同响应的状态。这种时间模糊性导致不平滑、高方差或多模态的动作分布,使学习复杂化。
这些根本性问题显著降低了预训练效率,并限制了VLA模型在不同场景下的泛化能力。
方法论:4D时空整合
4D-VLA建立在InternVL-4B视觉-语言模型骨干之上,并引入了几项关键创新来解决已识别的挑战。
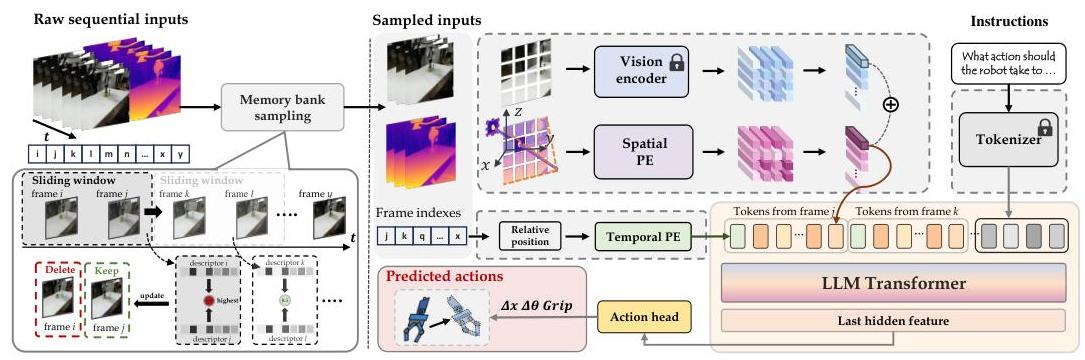
图2:4D-VLA架构展示了从原始序列输入到内存库采样、空间和时间编码,再到动作预测的完整流水线。
空间感知视觉令牌
为了解决坐标系统混乱,4D-VLA引入了显式编码3D坐标信息的空间感知视觉令牌:
RGB-D输入处理:与之前只使用RGB图像的方法不同,4D-VLA利用序列RGB-D图像来捕获颜色和深度信息。
3D坐标提取:对于每个输入图像$I$和对应的深度图$D$,模型使用相机外参$[R|T]$和内参$K$将深度值反投影到3D坐标$P_w$:
$$
P_w = R^{-1}(K^{-1} \cdot D \cdot [u, v, 1]^T - T)
$$其中$$[u, v]$$是像素坐标。
空间特征整合:对3D坐标应用可学习的位置嵌入$E_S$,并将得到的空间信息通过元素级加法与原始视觉特征融合:
$$
e_{ST} = P(E(I) + E_S(P_w))
$$其中$P$是MLP投影器,$E$是视觉编码器。
用于时间上下文的内存库采样
为了在保持计算效率的同时解决状态混乱,4D-VLA引入了内存库采样(MBS),这是一种自适应的历史帧采样方法:
def memory_bank_sampling(frames, n, k):"""从 n 个可用的历史帧中选择 k 个信息量大的帧参数:frames: n 个历史帧的列表n: 可用的总帧数k: 期望采样的帧数返回:selected_frames: k 个信息量最大的帧"""memory_bank = []similarity_queue = []for frame in frames:if len(memory_bank) < k:memory_bank.append(frame)similarity_queue.append(compute_similarity(frame, memory_bank))else:current_sim = compute_similarity(frame, memory_bank)if current_sim < max(similarity_queue):# 替换信息量最少的帧idx = similarity_queue.index(max(similarity_queue))memory_bank[idx] = framesimilarity_queue[idx] = current_simreturn memory_bank
时间位置编码
由于 MBS 导致非均匀采样,因此显式时间位置编码至关重要。该模型引入了可学习的时间编码令牌:
$$
e_T = E_T(t - j)
$$
其中 $t$ 是当前帧的时间戳,$j$ 是历史帧 $j$ 的时间戳。
损失函数增强
该模型的动作头部使用综合损失函数预测动作 $[\Delta x_{hat}, \Delta\theta_{hat}, g_{hat}]$:
$$
L_{total} = L_t + L_r + L_g + L_d
$$
其中:
- $$L_t$$ 和 $L_r$ 是平移和旋转的 L2 损失
- $L_g$ 是夹持器状态的二元交叉熵
- $L_d = ||d(\Delta x_{hat}) - d(\Delta x)||^2$ 是一种新颖的方向损失,强调小幅度平移的方向精度,其中 $d(x)$ 将向量归一化为单位方向
实验验证
MV-Bench:多视角评估框架
作者引入了 MV-Bench,一个基于 LIBERO-SPATIAL 构建的严格评估基准,用于测试空间理解和对新视角的泛化能力。
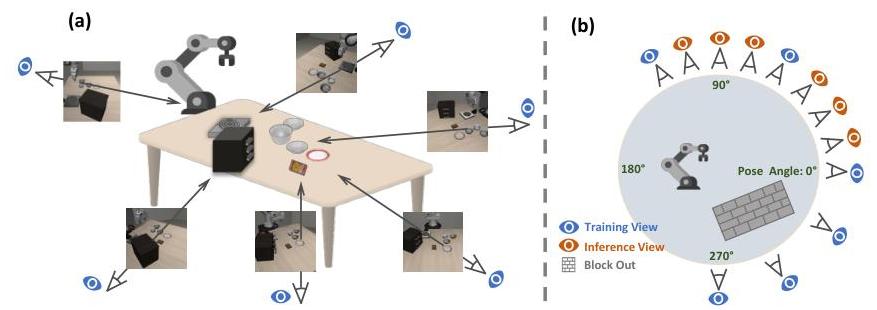
图 3:(a) MV-Bench 设置,显示机器人工作空间周围的多个摄像头视角。(b) 摄像头放置图,训练视角(蓝色)和测试视角(橙色)分布在 270° 范围内。
模拟结果
4D-VLA 在所有 LIBERO 基准测试中都表现出持续的优越性:
- LIBERO-SPATIAL: 相较于 OpenVLA 提升 5.2%
- LIBERO-OBJECT: 相较于 DiffusionPolicy 提升 2.7%
- LIBERO-GOAL: 相较于 Octo 提升 6.3%
- LIBERO-LONG: 在高难度长时任务上相较于 OpenVLA 显著提升 25.4%
在 MV-Bench 上,4D-VLA 在视角内成功率达到 81.0%,而 OpenVLA 为 52.2%;在交叉视角评估中,4D-VLA 保持 73.8% 的成功率,而 OpenVLA 为 50.5%。
真实世界评估

图 4:设计了四个真实世界的操作任务,以评估空间泛化能力、对干扰物的鲁棒性、精确放置和指令遵循能力。
使用 Franka 机器人手臂在四个不同的操作任务上进行的真实世界实验表明,4D-VLA 的平均成功率达到 85.63%,而 OpenVLA 为 27.70%,基础模型为 15.67%。
消融研究
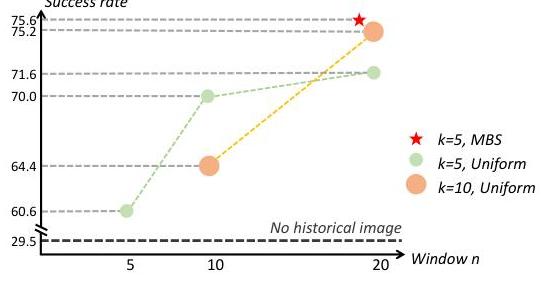
图 5:记忆库采样分析显示,历史窗口大小 (n) 比采样帧数 (k) 更重要,且 MBS 比均匀采样表现更好。
消融研究揭示了几个关键见解:
- 历史信息影响:总历史窗口大小 $n$ 比采样帧数 $k$ 更为关键
- MBS 有效性:内存库采样在较少帧数下比均匀采样实现了更优的性能
- 坐标系混乱缓解:具有 3D 信息的模型即使在坐标系扰动下也能保持高性能
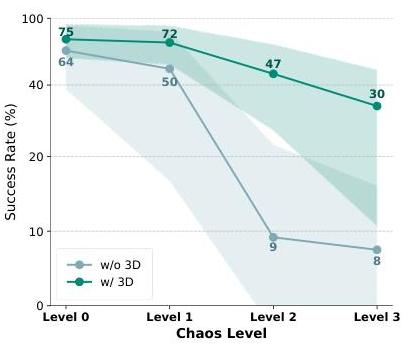
图6:演示了3D感知模型如何在坐标系混乱程度增加的情况下保持性能,而没有3D信息的模型则遭受了严重的性能下降。
多视角泛化
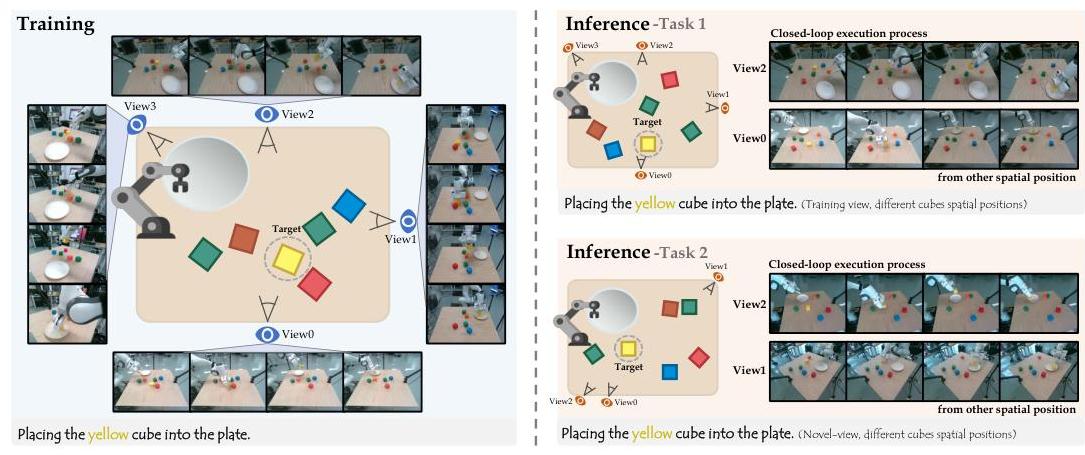
图7:多视角真实世界评估显示了在多个视口上进行训练并测试对新颖视角的泛化能力。4D-VLA 在不同相机位置下展示了强大的空间理解能力。
这项多视角评估表明,4D-VLA 在真实世界环境中对完全未见的相机视点具有强大的泛化能力,其性能显著优于 OpenVLA(平均成功率分别为 55% 对 18%)。
意义和影响
4D-VLA 代表了 VLA 模型预训练的一个重大进展,它解决了基本的输入表示限制。通过整合显式的 4D 时空信息,有效解决了坐标系和状态混乱问题,从而产生了更鲁棒、更具泛化性的机器人策略。
这项工作的关键贡献包括:
- 理论框架:明确识别并形式化了坐标系混乱和状态混乱问题
- 技术创新:空间感知视觉令牌和内存库采样,用于高效的时间上下文集成
- 评估方法:引入 MV-Bench,用于严格的多视角空间理解评估
- 实际影响:在模拟和真实世界机器人操作任务中都显示出显著改进
增强的空间理解和时间推理能力使 4D-VLA 对于需要精确操作、长时程规划以及跨多样化环境进行鲁棒泛化的应用尤其有价值。通过提供更完整的输入表示,这项工作推动该领域更接近于实现真正通用的机器人代理,这些代理能够在各种条件下通过自然语言指导执行复杂的操纵任务。