【论文阅读】RynnVLA-001:利用人类示范改进机器人操作
由达摩院和湖畔实验室开发的 RynnVLA-001 引入了一种视觉-语言-动作 (VLA) 模型,通过对大规模人类第一视角视频演示进行预训练,改进了机器人操控。它在实际操作任务中取得了 90.6% 的平均成功率,超越了 GR00T N1.5 (55.6%) 和 Pi0 (70.4%) 等最先进的基线模型。
引言
机器人操作仍然是人工智能领域最具挑战性的问题之一,它要求视觉感知、语言理解和精确运动控制的无缝集成。虽然大型语言模型和计算机视觉系统通过利用网络上的海量数据集取得了显著成功,但机器人技术面临一个根本性的瓶颈:大规模机器人操作数据的稀缺性。通过远程操作收集此类数据成本高昂、耗时且需要专业知识,这限制了视觉-语言-动作(VLA)模型可以训练的规模。

RynnVLA-001 的三阶段训练方法概述,从自我中心视频生成到轨迹感知建模,最终实现机器人专用控制。
RynnVLA-001 由达摩院(阿里巴巴集团)和湖畔实验室的研究人员开发,通过一种创新方法解决了这一挑战,该方法利用了丰富的人类演示视频。该模型引入了一种多阶段预训练方法,逐步弥合了通用视觉理解与特定机器人控制之间的鸿沟,在实际操作任务中取得了卓越性能,同时展示了对环境复杂性和干扰物的显著鲁棒性。
技术架构和方法
RynnVLA-001 的核心创新在于其三阶段训练流水线,该流水线系统地将知识从人类自我中心视频转移到机器人操作任务中。该模型建立在 Chameleon 图像到视频架构之上,采用自回归 Transformer 来处理语言和视觉 token 的交错序列。
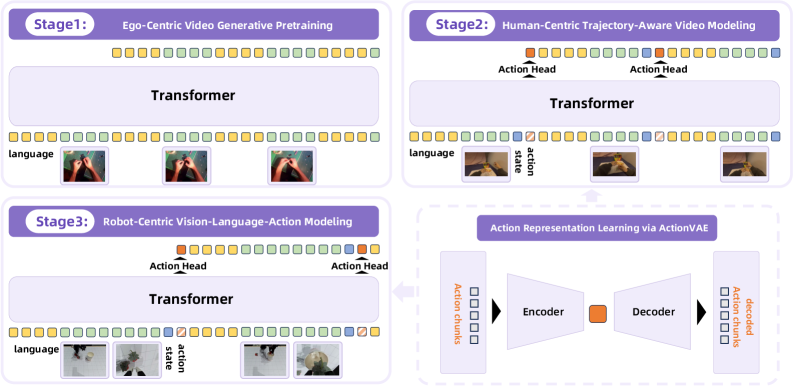
详细架构图显示了三个训练阶段和用于动作表示的 ActionVAE 组件。
数据整理与准备
研究团队开发了一个复杂的流水线,用于从网络资源中整理自我中心操作视频。此过程涉及使用姿态估计模型进行关键点检测,通过筛选可见的手腕和手部关键点同时排除面部地标来识别第一人称视角。该流水线使用 Qwen2-VL-7B 生成文本描述,最终形成一个包含 1200 万个自我中心人类操作视频以及 244,000 个机器人操作视频的数据集。
阶段 1:自我中心视频生成式预训练
第一阶段训练一个图像到视频模型,根据初始视觉观察和语言指令预测未来的视频帧。该模型使用以下序列结构从自我中心视角学习物理动力学:
[语言 token, 视觉 token_t, 语言 token, 视觉 token_{t+1}, ...]
此阶段建立了对人类演示中观察到的视觉动力学和运动模式的基本理解。
阶段 2:以人为中心的轨迹感知视频建模
第二阶段引入了一项关键创新,通过联合预测未来的视觉帧和相应的人体关键点轨迹。这通过将手腕关键点作为末端执行器位置的代理,弥合了视觉预测和动作生成之间的鸿沟。模型架构通过一个轻量级动作头进行扩展,该动作头将 Transformer 的隐藏状态映射到连续动作嵌入。
训练目标结合了视觉 token 的交叉熵损失和动作预测的 L1 损失:
\mathcal{L} = \mathcal{L}_{visual} + \lambda \mathcal{L}_{action}
其中 $\mathcal{L}_{visual}$ 表示视觉 token 预测的交叉熵损失,$\mathcal{L}_{action}$ 表示动作嵌入预测的 L1 损失。
ActionVAE:压缩动作表示
一个关键技术贡献是ActionVAE组件,它将动作块压缩成紧凑、连续的潜在嵌入。这种方法能够预测动作序列而不是单步动作,从而提高时间一致性和执行平滑度。VAE由一个将动作块映射到潜在嵌入的编码器和一个重建原始动作序列的解码器组成。
阶段3:以机器人为中心的视觉-语言-动作建模
最后一个阶段通过在机器人特定数据上进行微调,使轨迹感知模型适应真实世界的机器人控制。该架构继承了阶段2的权重,但用机器人特定变体取代了人类特定的动作头。该模型处理双摄像头视图(前置和腕部)以及当前机器人关节状态,以预测机器人动作块嵌入。
实验评估和结果
实验评估展示了RynnVLA-001在机器人操纵能力的多个维度上的卓越性能。

四种评估场景测试了操纵能力和鲁棒性的不同方面。
性能比较
RynnVLA-001在三个真实世界操纵任务中取得了平均90.6%的成功率,显著优于包括GR00T N1.5 (55.6%) 和 Pi0 (70.4%) 在内的最先进基线。该模型在不同复杂程度下保持一致的性能:
- 单目标操纵:93.3% 成功率
- 多目标操纵:86.7% 成功率
- 带干扰物的指令跟随:91.7% 成功率
消融研究和设计验证
全面的消融研究验证了所提出方法的每个组件:
预训练的有效性:未经预训练的模型仅达到4.4%的成功率,而完整的三阶段方法达到了90.6%,这表明所提出的课程至关重要。
阶段性贡献:
- 阶段1(以自我为中心的视频预训练)将性能从50.0%提高到84.4%
- 阶段2(轨迹感知建模)将性能进一步提高到90.6%
技术设计选择:
- 384×384输入分辨率在保真度和计算效率之间提供了最佳平衡
- ActionVAE表示优于直接动作序列预测
- 简单的单层动作头比更深的架构更有效

以自我为中心的视频预训练阶段的视频生成示例,显示了逼真的运动和内容一致性。
鲁棒性分析
该模型对环境变化和干扰物表现出卓越的鲁棒性。与在杂乱环境中表现出显著性能下降的基线方法不同,RynnVLA-001保持了稳定的高性能。相机分析显示,前置摄像头为粗略定位提供了关键的3D空间信息,而腕部摄像头则实现了精细的操纵调整。

双摄像头系统分析显示前置摄像头视角对成功操纵的重要性。
意义与影响
RynnVLA-001代表了视觉-语言-动作建模的重大进步,为机器人学和人工智能领域做出了几项重要贡献:
方法论创新
三阶段预训练方法提供了一种系统方法,将操作技能从人类演示转移到机器人控制。这种渐进式课程——从通用视觉动力学到人类轨迹建模再到机器人特定控制——为开发有能力的VLA模型提供了一个可复制的框架,而无需大量的机器人特定数据集。
实际意义
高成功率(平均90.6%)、对干扰物的鲁棒性以及高效推理的结合,使得RynnVLA-001适用于实际部署。该模型遵循复杂指令的能力,同时在杂乱环境中保持稳定性能,满足了实际机器人应用的关键需求。
技术贡献
用于压缩动作表示的ActionVAE组件和轨迹感知建模方法为未来的VLA开发提供了宝贵的架构见解。详细的消融研究为最佳模型设计选择提供了实用指导,包括输入分辨率选择和动作头架构。

机械臂操作任务期间的摄像机视角比较,突出显示了前置摄像机和腕部摄像机的互补作用。
未来研究方向
尽管RynnVLA-001展示了令人印象深刻的能力,但评估主要集中在受控实验室环境中的单一机器人形态。未来的研究应将评估扩展到多样化的机器人平台、非结构化环境和动态场景,以充分评估泛化能力。该方法的成功预示着在扩展到更复杂的机械臂操作任务和多模态机器人学习场景方面具有广阔前景。
这项工作为在机器人学习中利用丰富的人类演示数据奠定了坚实基础,有望加速开发出更强大、更易用的机器人系统,涵盖制造、物流和家庭辅助等各个领域。