联邦学习论文分享:Federated Learning with GAN-based Data Synthesis for Non-IID Clients
摘要
问题背景:
联邦学习允许多个客户端在不共享原始数据的情况下协同训练模型,但当各客户端的数据分布不一致(非IID)时,模型性能会受到影响。
提出的方案:
作者提出了一种新框架,叫 Synthetic Data Aided Federated Learning(SDA-FL),通过共享合成数据来缓解非IID问题。
每个客户端预训练一个本地的生成对抗网络(GAN),生成差分隐私的合成数据。
这些合成数据上传到参数服务器(PS),由服务器构建一个全局共享的合成数据集。
核心技术点:
服务器采用迭代伪标签机制(iterative pseudo labeling)为合成数据生成可靠的标签。
客户端在训练时结合本地真实数据和带伪标签的合成数据,使得不同客户端的数据分布更接近,从而提升本地模型一致性,改善全局模型聚合效果。
实验结果:
在多个基准数据集上,SDA-FL在监督和半监督学习场景下均显著优于现有基线方法。
引言
1. 背景与问题
联邦学习(FL)允许客户端在不共享本地数据的情况下协同训练全局模型(FedAvg 是典型算法)。
当客户端数据是 IID 时效果良好,但在非IID(数据分布偏斜)时:
不同客户端学习到的模型差异大(本地模型不一致)
全局模型聚合效果下降,性能显著降低。
2. 现有方法及局限
基于模型正则化的方法:
通过全局模型或其他客户端的本地模型信息来约束本地模型
限制:无法在极端非IID情况下取得显著提升。
数据增强方法:
生成合成样本(例如混合真实样本)
限制:缺乏隐私保护,存在数据泄露风险。
3. 作者提出的 SDA-FL 框架
核心思想:通过共享差分隐私的合成数据解决非IID问题,而不是直接共享真实数据。
流程概述:
每个客户端预训练本地的 差分隐私 GAN 生成合成数据。
将合成数据上传到参数服务器(PS),构建全局合成数据集。
迭代伪标签机制:
PS 根据收到的本地模型更新合成数据的伪标签
随着训练轮次增加,伪标签的可信度提高
有助于提升本地更新和全局聚合效果
优点:
避免直接共享真实数据,保护隐私
兼容多种现有联邦学习方法
可用于监督学习和半监督学习场景
不需要真实数据标签也能工作
4. 实验验证
实验会验证:
SDA-FL 的性能提升
隐私预算的影响
各关键步骤(如伪标签机制)的有效性
相关工作
1. Non-IID Challenges in Federated Learning
问题:非IID数据分布是联邦学习的核心障碍,它会导致本地模型差异过大,从而使聚合模型性能下降。
已有解决思路:
修改本地目标函数:利用全局模型或其他客户端的模型信息来缓解客户端漂移(client drift),但在严重非IID场景下效果有限。
调整模型结构:允许不同客户端使用不同的本地模型结构,以适应各自的数据分布。
优化参数服务器操作:例如改进模型聚合方式、客户端选择策略、客户端聚类或分类器校准等。
2. Data Augmentation and Privacy Preserving
数据共享思路:近年来,一些研究尝试通过数据增强或数据共享来缓解非IID问题。
代表性方法:
Mixup 技术:通过混合客户端的真实样本来生成新的全局数据集,帮助缓解非IID问题。但频繁数据交换可能带来隐私泄露风险。
GAN 增强:在服务器上利用客户端上传的少量样本训练生成器,再下发给客户端使用。但上传真实样本违背隐私保护原则。
FedDPGAN:让所有客户端在联邦学习框架下协作训练一个全局生成模型,以补充本地数据。但问题是:
GAN 训练需要频繁交换生成模型,通信开销很大
同时存在被对抗攻击利用的风险
前提知识
1. Federated Learning (FL) 基础
介绍了经典的 FedAvg 算法流程:
每轮训练,选取一部分客户端下载全局模型参数 wt。
客户端用本地数据 Dk=(Xk,Yk) 通过 SGD 更新本地模型。
将更新后的本地模型上传到服务器。
服务器对模型进行加权聚合,得到新的全局模型。
问题:在非IID场景下,本地模型差异过大,聚合模型性能显著下降。
解决思路:用生成对抗网络(GAN)生成高质量的合成数据,在客户端和服务器之间共享,用于缓解数据分布不一致问题。
2. 差分隐私生成对抗网络(DP-GAN)
为了稳定训练,采用 WGAN-GP(Wasserstein GAN with Gradient Penalty)。
在训练中引入 差分隐私 (DP),通过在判别器梯度更新时加入高斯噪声来保护隐私。
公式解释了差分隐私的定义 (ϵ,δ),以及噪声方差与采样概率、批次数之间的关系。
关键点:判别器加噪声 → 生成器通过反向传播间接接收噪声 → 保证生成器输出的合成数据也满足 DP。
3. 伪标签机制(Pseudo Labeling)
由于半监督场景下标签稀缺,无法直接训练有条件的生成模型(如 ACGAN)。
作者采用 伪标签策略:
给合成样本预测类别,如果某一类别的预测概率 最大且超过阈值 τ,则将其作为伪标签。
否则不赋标签。
这样能保证只有高置信度的合成数据才被赋予伪标签,用于更新模型。
在整个联邦学习过程中,伪标签会随着本地模型的不断改进而迭代更新,逐步提升标签质量。
核心算法
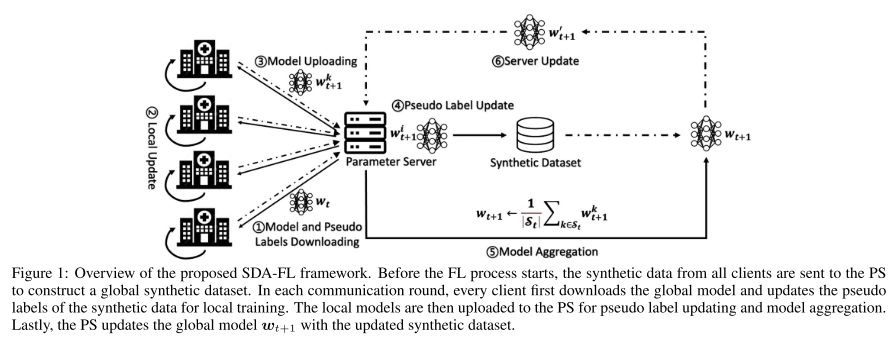
1. 全局合成数据集构建 (Global Synthetic Dataset Construction)
每个客户端先用本地数据预训练一个 GAN,生成差分隐私的合成数据。
客户端上传合成数据到服务器(PS),由 PS 构建一个全局共享的合成数据集。
伪标签生成:
与已有方法不同,SDA-FL 不是用其他客户端的模型,而是用本地模型给对应的合成数据打伪标签(因为它们训练于同一数据分布,匹配性更高)。
PS 在每一轮 FL 收到客户端模型后,更新全局合成数据的伪标签。随着本地模型变强,伪标签质量逐步提升。
2. 基于合成数据的模型训练 (Synthetic Data Aided Model Training)
客户端训练:
客户端使用真实数据和带高置信度伪标签的合成数据进行联合训练。
采用 Mixup 技术(将真实数据和合成数据线性插值),生成更均匀的数据分布。
定义两类损失函数:
Mixup 损失 ℓ1:结合真实样本和合成样本。
真实数据损失 ℓ2:避免在早期训练阶段伪标签不准带来的不稳定性。
最终更新规则:
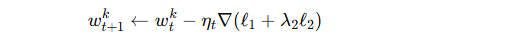
服务器训练:
传统 FL 的 PS 仅做模型聚合,没有数据。
SDA-FL 的 PS 保存全局合成数据集,用它直接更新全局模型,进一步提升效果。
3. 模型训练与合成数据更新的交互 (Interplay between Model Training and Dataset Updating)
每一轮中:
合成数据帮助客户端训练出更好的本地模型;
改进后的本地模型提升伪标签质量,从而增强全局合成数据集;
PS 基于更可靠的合成数据提升全局模型;
下一轮客户端再受益于更强的全局模型。
这种 循环增强机制 是 SDA-FL 成功的关键。
4. SDA-FL 与传统 FL 的对比 (SDA-FL vs. Traditional FL)
传统 FL:
客户端仅依赖本地数据训练,容易因非IID导致模型不一致,全局性能下降。
PS 只做简单参数聚合。
SDA-FL:
客户端利用合成数据增强本地数据分布,缓解非IID问题。
PS 不仅聚合模型,还利用合成数据直接训练全局模型。
总结:通过共享合成数据集 + 迭代伪标签机制,SDA-FL 有效克服了数据异质性,提升了全局模型性能。
实验
设置
1. 数据集 (Datasets)

使用 四个常见基准数据集:MNIST、FashionMNIST、CIFAR-10、SVHN。
采用 非IID划分方式:
每个客户端只分到少数类别的数据。
数据先划分为单类别子集,再随机分配给客户端。
超参数设置:
伪标签阈值 τ = 0.95,γ = 10.0,λ₂ = 1.0。
客户端数 = 10(每轮全选)。
每个客户端上传 4000 条合成数据给服务器。
GAN预训练:
CIFAR-10:36,000次迭代
其他数据集:18,000次迭代
训练设置:
总轮次 200
PS 更新:CIFAR-10 10次迭代 / 其他数据集 50次迭代
客户端本地更新:监督学习 E=90 / 半监督学习 E=40
优化器:SGD,学习率 0.03
批量大小:监督学习 B=64 / 半监督学习 B=80(含16有标签样本+64无标签样本)
2. 现实数据验证 (COVID-19 dataset)
为了检验 SDA-FL 的实际应用价值,还在 真实 COVID-19 医学影像数据集 上测试。
特点:Pneumonia 样本稀缺 → 只设置 6 个客户端,每个客户端分到 2 类数据。
GAN 本地训练:4,500 次迭代。
本地模型更新:30次迭代;全局模型更新:10次迭代。
3. 对比方法 (Baselines)
监督学习对比:
FedAvg、FedProx、SCAFFOLD、Naivemix、FedMix
在 COVID-19 数据集上额外比较 FedDPGAN(面向医疗的全局GAN方法)。
半监督学习对比:
SemiFL、Local Fixmatch、Local Mixup。
为公平比较,调优了 FedProx 的正则化参数 μ 和 FedMix 的混合比例 λ。
4. 模型结构 (Models)
简单 CNN:用于 MNIST 和 FashionMNIST。
ResNet18:用于 CIFAR-10、SVHN、COVID-19。
生成器与判别器:
生成器:4层反卷积。
判别器:4层卷积 + 1层全连接。
结果
1. 监督式联邦学习的表现 (Federated Supervised Learning)

在不同类别数量的客户端实验中,SDA-FL 显著优于基线方法。
在 CIFAR-10 上,SDA-FL 比 Naivemix 和 FedMix 至少高 5%(客户端有 3 个类别时)。
在 COVID-19 数据集上:

SDA-FL 比 FedDPGAN 高 1.68%。
甚至比 IID 情况下的 FedAvg 还高 1.14%,说明 SDA-FL 对医学场景尤其有优势。
2. 半监督式联邦学习的表现 (Federated Semi-Supervised Learning)
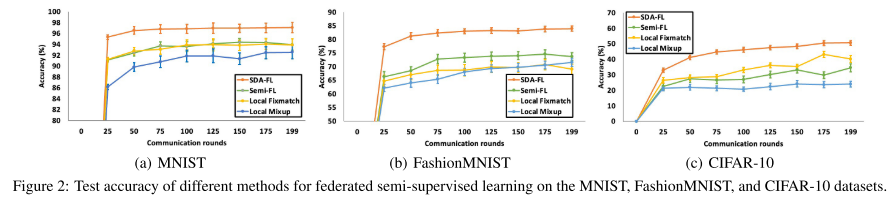
收敛更快、精度更高,比其他算法更稳定。
在 FashionMNIST 上,比 Semi-FL 高将近 10%。
在 CIFAR-10 上,基线方法无法收敛到可用模型(准确率 < 40%),而 SDA-FL 能收敛并显著提升准确率。
原因:伪标签机制能为合成数据和无标签数据提供高质量标签。
3. 隐私预算与性能的权衡 (Privacy vs. Performance)
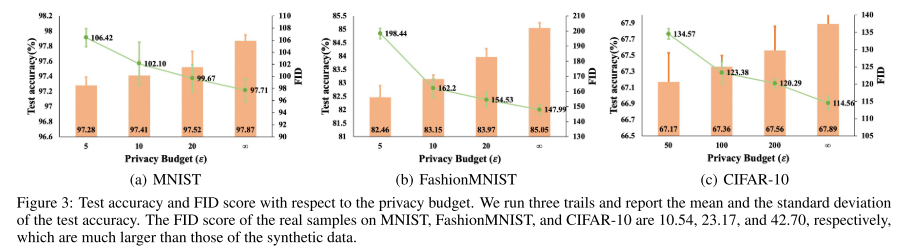
用差分隐私控制参数 ε 时:
更严格的隐私预算(ε=5)导致 FID 分数上升(图像质量下降)。
进而引起 MNIST 降低约 0.61%、FashionMNIST 降低约 2.59% 的准确率,CIFAR-10 也有类似趋势。
但即便在隐私约束下,SDA-FL 依然保持了领先性能。
4. 服务器更新与伪标签更新的有效性
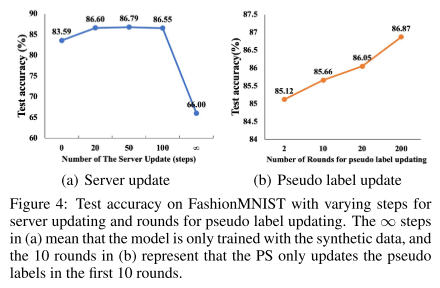
服务器更新 (PS 用合成数据训练全局模型):
如果不在服务器更新 → FashionMNIST 上准确率下降近 3%。
如果只用合成数据更新(无限次) → 准确率只有 66%,说明合成数据要与真实数据平衡使用。
伪标签更新:
每轮更新伪标签能逐步提升模型精度(随着伪标签置信度增加)。
额外通信开销极小,因为只传输标签而非样本。
5. 与 AC-WGAN-GP 的对比

尝试在 GAN 训练时直接加上标签(AC-WGAN-GP),与 WGAN-GP、SDA-FL 对比:
WGAN-GP 的合成数据质量更高(FID 更低)。
虽然 AC-WGAN-GP 可以生成带标签的样本,但 SDA-FL 的 伪标签机制效果更好,最终分类准确率高于 AC-WGAN-GP。
说明 “高质量数据 + 伪标签机制” > “低质量数据 + 自带标签”。