使用 modelscope gpu 跑通第一个 cuda 入门实例
文章目录
- 1、前往 modelscope -- 我的 Notebook
- 2、编写cuda程序
- 3、编译 运行
1、前往 modelscope – 我的 Notebook
https://www.modelscope.cn/my/mynotebook
选择有 GPU 的实例
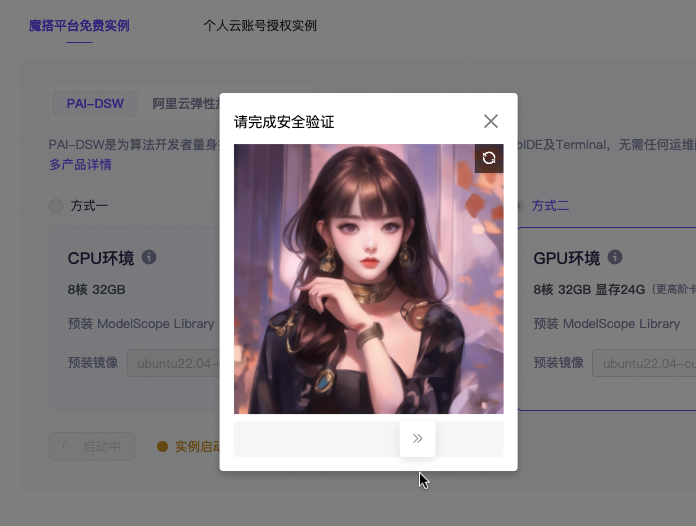
安全验证都很漂亮
2、编写cuda程序
以下是一个经典的“向量加法”示例
#include <iostream>
#include <cuda_runtime.h>// 定义核函数 (Kernel Function),在GPU上执行
// __global__ 关键字表示这是一个核函数 [[7]]
__global__ void vectorAdd(float *A, float *B, float *C, int N) {// 计算当前线程处理的元素索引int i = blockIdx.x * blockDim.x + threadIdx.x;// 检查索引是否越界if (i < N) {C[i] = A[i] + B[i]; // 执行加法}
}int main() {int N = 1000; // 向量大小size_t size = N * sizeof(float);// 在主机(CPU)上分配内存float *h_A = new float[N];float *h_B = new float[N];float *h_C = new float[N];// 初始化主机数据for (int i = 0; i < N; i++) {h_A[i] = i;h_B[i] = i * 2;}// 在设备(GPU)上分配内存float *d_A, *d_B, *d_C;cudaMalloc(&d_A, size);cudaMalloc(&d_B, size);cudaMalloc(&d_C, size);// 将数据从主机复制到设备cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);// 定义执行配置:1个Block,每个Block有 N 个线程(简单起见,假设 N 不太大)int threadsPerBlock = 256; // 通常选择 256 或 512int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock; // 向上取整// 调用核函数vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);// 将结果从设备复制回主机cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);// 验证结果(打印前10个元素)std::cout << "Result (first 10 elements):" << std::endl;for (int i = 0; i < 10; i++) {std::cout << h_C[i] << " ";}std::cout << std::endl;// 释放设备内存cudaFree(d_A);cudaFree(d_B);cudaFree(d_C);// 释放主机内存delete[] h_A;delete[] h_B;delete[] h_C;return 0;
}
3、编译 运行
打开终端:
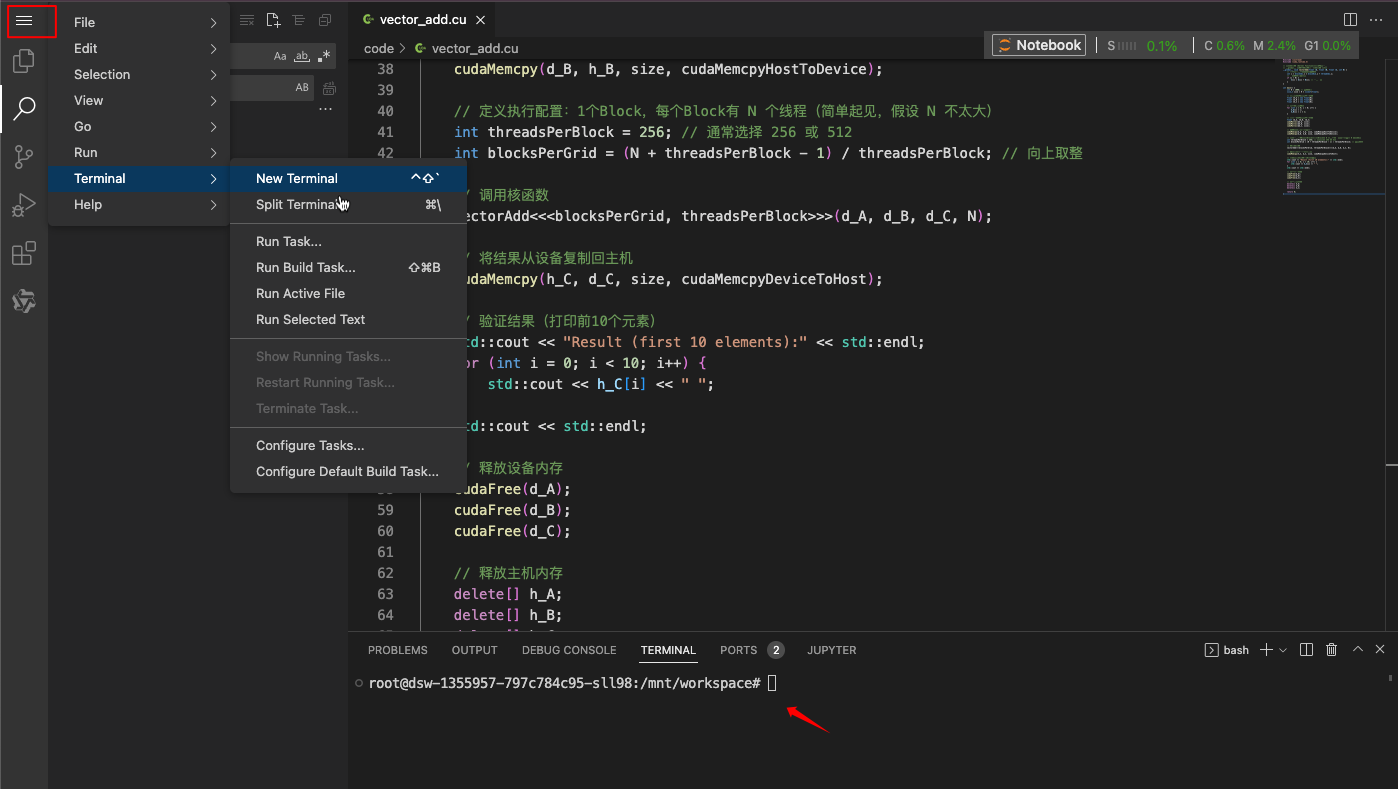
nvcc -o vector_add vector_add.cu./vector_add
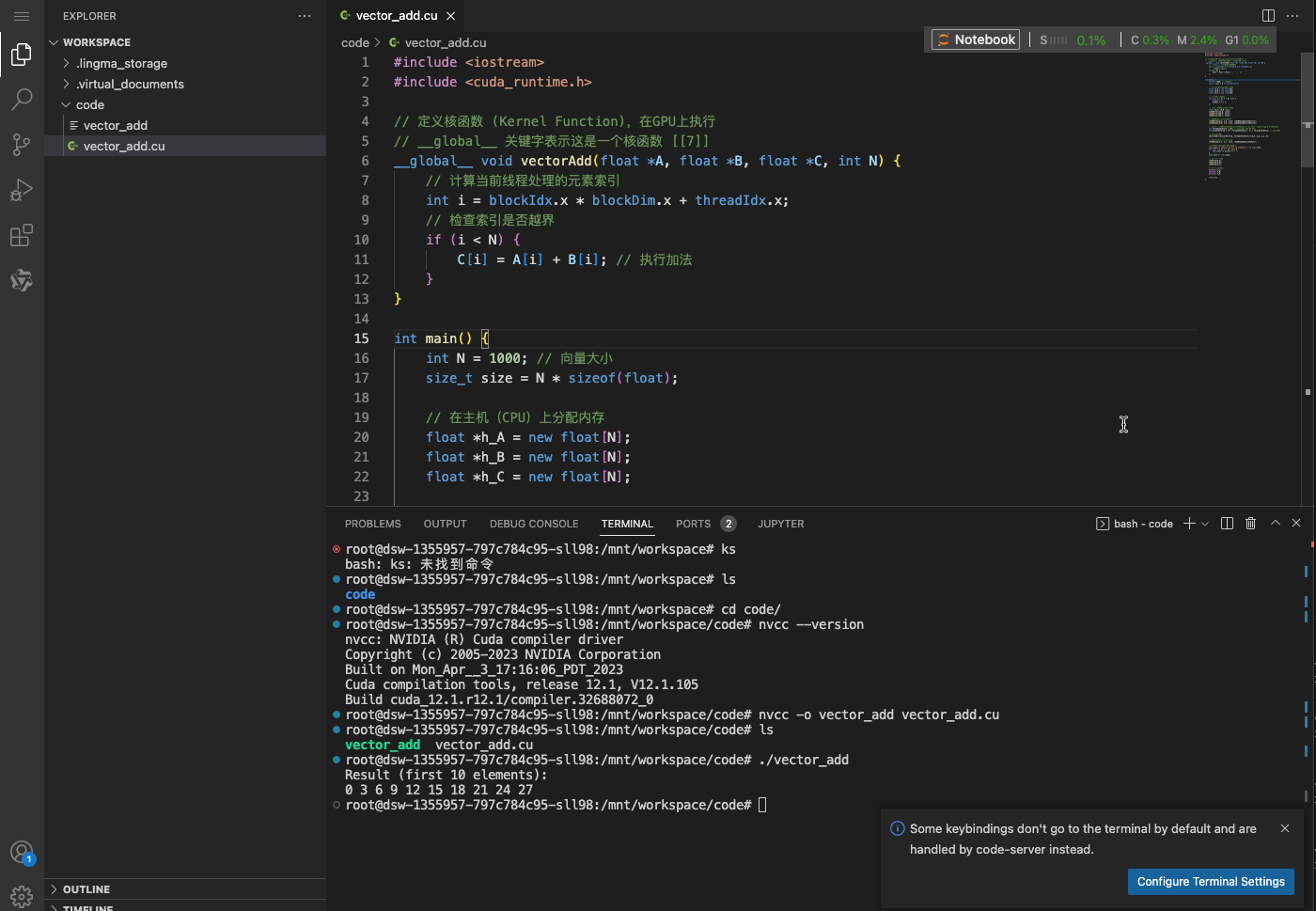
执行日志
# ./vector_add
Result (first 10 elements):
0 3 6 9 12 15 18 21 24 27
执行效果:
··***