字典树 Trie 介绍、实现、封装与模拟 C++STL 设计
字典树 Trie 介绍、实现、封装与模拟 C++STL 设计
- 一、介绍
- 二、实现与封装(C++ 实现)
- 1. 变量成员
- 2. 基本函数
- insert 函数实现
- find 函数实现
- erase 函数实现
- prefixMatch 函数实现
- 3. 基本实现源码展示
- 4. 封装代码
- 三、模拟 C++STL 设计
- 1. 迭代器变量成员
- 2. 迭代器 ++
- 3. 迭代器 --
- 4. 迭代器判断
- 5. Trie 成员函数返回迭代器
- begin 函数 和 end 函数
- rbegin 函数 和 rend 函数
- 使用事项
- 6. 源码展示
- 四、Trie 特点与其变体 基数树
以下代码环境为 VS2022 C++。
一、介绍
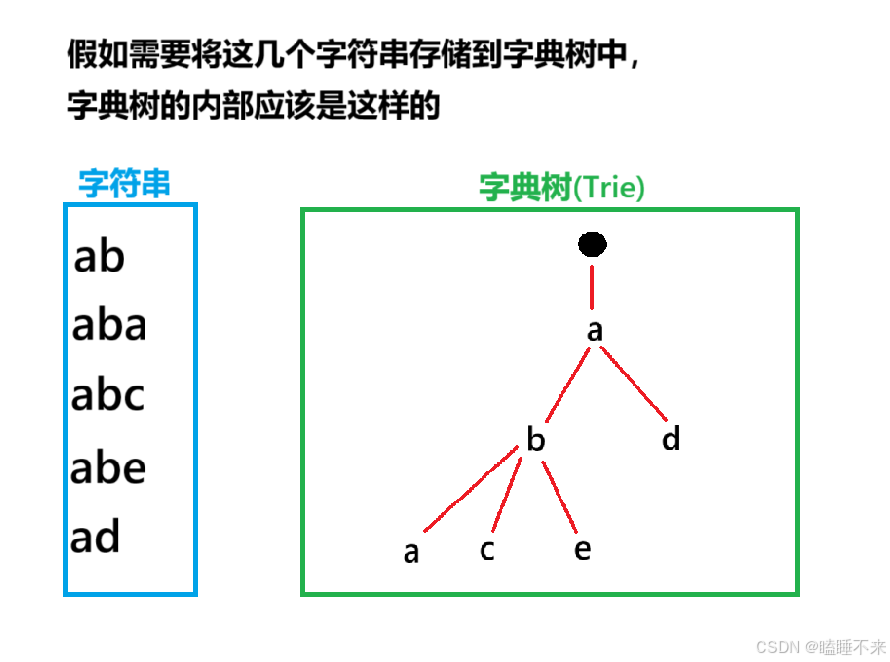
字典树(Trie) 又称前缀树,是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销,从而达到高效检索的目的。
特点:
-
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
-
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
-
每个节点的所有子节点包含的字符都不相同。
-
天然支持字典序排序。
-
搜索时间复杂度仅与字符串 n 长度相关(O(n))。
二、实现与封装(C++ 实现)
1. 变量成员
字典树实际底层容器合适的有 map 和 unordered_map ,并且一个节点里的子节点数量是未知的,对于子节点的存储,最好使用指针:
struct TrieNode
{bool _isWord = false; // 表示当前节点是否是一个存储的字符串末尾std::map<char, TrieNode*> _con; // 子节点表,用于存储子节点指针
};
考虑到字典树有序,我们就优先实现 map 的。
class Trie
{
private:struct TrieNode{bool _isWord = false; // 表示当前节点是否是一个存储的字符串末尾std::map<char, TrieNode*> _con; // 子节点表,用于存储子节点指针};using pTrieNode = TrieNode*;private:pTrieNode _pHead; // 根节点,不包含字符
};2. 基本函数
Trie 的基本函数一般有:
-
insert :插入字符串到 Trie 中。
-
find :查找字符串是否在 Trie 内。
-
erase :删除 Trie 对应的字符串。
-
prefix match :返回传入的字符串与 Trie 有相同前缀的所有字符串。
insert 函数实现
insert 插入成功返回 true,插入重复返回 false。其内部使用一个指针查找对应单个字符,有则访问字符对应的节点,没有则创建,再将 _isWord 更改即可:
bool insert(const std::string& str)
{pTrieNode ptr = _pHead; // 临时指针for (auto& e : str){if (!ptr->_con.count(e)) // 查找当前节点是否有对应字符{ptr->_con.insert({ e, new TrieNode }); // 没有则创建一个对应子节点}ptr = ptr->_con[e]; // 有则直接指针访问并将指针指向对应子节点}// 修改 _isWord 并返回 insert 执行结果return ptr->_isWord == false ? ptr->_isWord = true : false;
}
find 函数实现
同理于 find 函数,只需查找对应字符是否出现在 Trie 即可返回结果,这里复用 _find 的代码用于 erase 使用:
pTrieNode _find(const std::string& str) // 只在 Trie 内部使用
{pTrieNode ptr = _pHead;for (auto& e : str){if (ptr->_con.count(e)) // 有对应字符则进入{ptr = ptr->_con[e];}else{return nullptr; // 没有返回 nullptr}}return ptr == _pHead ? nullptr : ptr; // 查找到返回指针
}bool find(const std::string& str)
{pTrieNode ptr = _find(str);return ptr != nullptr && ptr->_isWord == true; // 指针不为空 并且 节点 _isWord 标注是单词
}
erase 函数实现
判断 _find 返回的指针,只需修改 _isWord 即可:
bool erase(const std::string& str)
{pTrieNode ptr = _find(str);if (ptr == nullptr || ptr->_isWord == false){return false;}// erase 不用删除释放节点,只需修改 _isWord 即可ptr->_isWord = false; // 一是因为当前节点可能有对应的子节点return true; // 二是删除释放的做法时间消耗更大
}
prefixMatch 函数实现
前缀匹配函数会将 Trie 里前缀与传入字符串相同的字符串全部返回,比如:
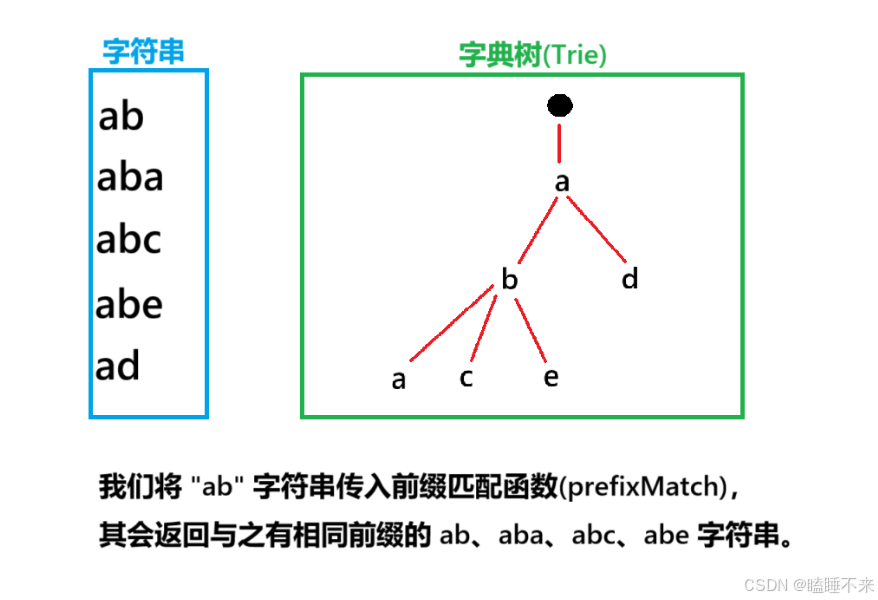
并且保证返回的有序性,我们使用的是前序遍历(也可以说是回溯算法):
void _TracebackMatch(pTrieNode root, std::string& path, std::vector<std::string>& words)
{if (root == nullptr){return;}if (root->_con.size() == 0 && root->_isWord == true) // 末尾单词{words.push_back(path);return;}if (root->_isWord == true) // 中间单词{words.push_back(path);}for (auto& e : root->_con) // 遍历每个节点,而 map 是有序的,则遍历也是有序的,返回结果同理{path += e.first;_TracebackMatch(e.second, path, words);path.pop_back();}
}std::vector<std::string> prefixMatch(const std::string& prefix)
{std::vector<std::string> words;std::string path = prefix;pTrieNode ptr = _find(prefix);if (prefix.size() == 0) // 字符串为空等价遍历 Trie{ptr = _pHead;}if (ptr != nullptr){_TracebackMatch(ptr, path, words);}return words;
}
3. 基本实现源码展示
里面的其它源码这里就不做分析了:
#pragma once#include <map>
#include <string>
#include <vector>
#include <iostream>class Trie
{
private:struct TrieNode{bool _isWord = false; // 表示当前节点是否是一个存储的字符串末尾std::map<char, TrieNode*> _con; // 子节点表,用于存储子节点指针};using pTrieNode = TrieNode*;public:Trie():_pHead(new TrieNode){;}bool insert(const std::string& str){pTrieNode ptr = _pHead; // 临时指针for (auto& e : str){if (!ptr->_con.count(e)) // 查找当前节点是否有对应字符{ptr->_con.insert({ e, new TrieNode }); // 没有则创建一个对应子节点}ptr = ptr->_con[e]; // 有则直接指针访问并将指针指向对应子节点}// 修改 _isWord 并返回 insert 执行结果return ptr->_isWord == false ? ptr->_isWord = true : false;}bool find(const std::string& str){pTrieNode ptr = _find(str);return ptr != nullptr && ptr->_isWord == true; // 指针不为空 并且 节点 _isWord 标注是单词}bool erase(const std::string& str){pTrieNode ptr = _find(str);if (ptr == nullptr || ptr->_isWord == false){return false;}// erase 不用删除释放节点,只需修改 _isWord 即可ptr->_isWord = false; // 一是因为当前节点可能有对应的子节点return true; // 二是删除释放的做法时间消耗更大}std::vector<std::string> prefixMatch(const std::string& prefix){std::vector<std::string> words;std::string path = prefix;pTrieNode ptr = _find(prefix);if (prefix.size() == 0) // 字符串为空等价遍历 Trie{ptr = _pHead;}if (ptr != nullptr){_TracebackMatch(ptr, path, words);}return words;}void traverse(){std::string path;for (auto& e : _pHead->_con){path += e.first;_PreorderTraversal(e.second, path);path.pop_back();}}~Trie(){this->_PostorderTraversal(_pHead);}private:pTrieNode _find(const std::string& str) // 只在 Trie 内部使用{pTrieNode ptr = _pHead;for (auto& e : str){if (ptr->_con.count(e)) // 有对应字符则进入{ptr = ptr->_con[e];}else{return nullptr; // 没有返回 nullptr}}return ptr == _pHead ? nullptr : ptr; // 查找到返回指针}void _PostorderTraversal(pTrieNode root){if (root == nullptr){return;}for (auto& e : root->_con){_PostorderTraversal(e.second);}delete root;}void _TracebackMatch(pTrieNode root, std::string& path, std::vector<std::string>& words){if (root == nullptr){return;}if (root->_con.size() == 0 && root->_isWord == true) // 末尾单词{words.push_back(path);return;}if (root->_isWord == true) // 中间单词{words.push_back(path);}for (auto& e : root->_con) // 遍历每个节点,而 map 是有序的,则遍历也是有序的,返回结果同理{path += e.first;_TracebackMatch(e.second, path, words);path.pop_back();}}void _PreorderTraversal(pTrieNode root, std::string& path){if (root == nullptr){return;}if (root->_con.size() == 0 && root->_isWord == true){std::cout << path << std::endl;return;}if (root->_isWord == true){std::cout << path << std::endl;}for (auto& e : root->_con){path += e.first;_PreorderTraversal(e.second, path);path.pop_back();}}private:pTrieNode _pHead; // 根节点,不包含字符
};
4. 封装代码
上述的代码底层容器使用的是 map ,插入的时间复杂度准确来说是(O(logm * n))。这里我们扩展原来的代码,将 unordered_map 也作为底层容器的选项之一,并模版化字符和字符串以便加入宽字符。不过要明确知道,unordered_map 为底层的 Trie ,插入为 (O(n)),但是内部的字符串并不是有序的。
#pragma once#include <map>
#include <string>
#include <vector>
#include <unordered_map>template<class Type>
struct unordered_TrieNode // 同理与 TrieNode
{bool _isWord = false;std::unordered_map<Type, unordered_TrieNode<Type>*> _con;
};template<class Type>
struct TrieNode // TrieNode 和 map 皆使用模版,不好分开
{bool _isWord = false;std::map<Type, TrieNode<Type>*> _con;
};template<class Type = char, class String = std::string, class Node = TrieNode<Type>>
class TrieBase
{
private:using pNode = Node*;public:TrieBase():_pHead(new Node){;}bool insert(const String& str){pNode ptr = _pHead;for (auto& e : str){if (!ptr->_con.count(e)){ptr->_con.insert({ e, new Node });}ptr = ptr->_con[e];}return ptr->_isWord == false ? ptr->_isWord = true : false;}bool find(const String& str){pNode ptr = _find(str);return ptr != nullptr && ptr->_isWord == true;}bool erase(const String& str){pNode ptr = _find(str);if (ptr == nullptr || ptr->_isWord == false){return false;}ptr->_isWord = false;return true;}std::vector<String> prefixMatch(const String& prefix){std::vector<String> words;String path = prefix;pNode ptr = _find(prefix);if (prefix.size() == 0){ptr = _pHead;}if (ptr != nullptr){_TracebackMatch(ptr, path, words);}return words;}~TrieBase(){this->_PostorderTraversal(_pHead);}private:pNode _find(const String& str){pNode ptr = _pHead;for (auto& e : str){if (ptr->_con.count(e)){ptr = ptr->_con[e];}else{return nullptr;}}return ptr == _pHead ? nullptr : ptr;}void _PostorderTraversal(pNode root){if (root == nullptr){return;}for (auto& e : root->_con){_PostorderTraversal(e.second);}delete root;}void _TracebackMatch(pNode root, String& path, std::vector<String>& words){if (root == nullptr){return;}if (root->_con.size() == 0 && root->_isWord == true) {words.push_back(path);return;}if (root->_isWord == true) {words.push_back(path);}for (auto& e : root->_con) {path += e.first;_TracebackMatch(e.second, path, words);path.pop_back();}}protected:pNode _pHead;
};using unordered_wTrie = TrieBase<wchar_t, std::wstring, TrieNode<wchar_t>>;
using wTrie = TrieBase<wchar_t, std::wstring, TrieNode<wchar_t>>;using unordered_Trie = TrieBase<char, std::string, unordered_TrieNode<char>>;
using Trie = TrieBase<char, std::string, TrieNode<char>>;
三、模拟 C++STL 设计
Trie 模拟 C++STL,最主要是迭代器的实现,所以这里我们只分析其迭代器的实现。
1. 迭代器变量成员
注意到,我们使用的 TrieNode 本身并不知道自己存储的是什么字符,只有它的父节点的 _con 的 key 值存储了它本身的字符。下图为了方便展示,_con 结构使用的是数组(也可以说是 unordered_map):
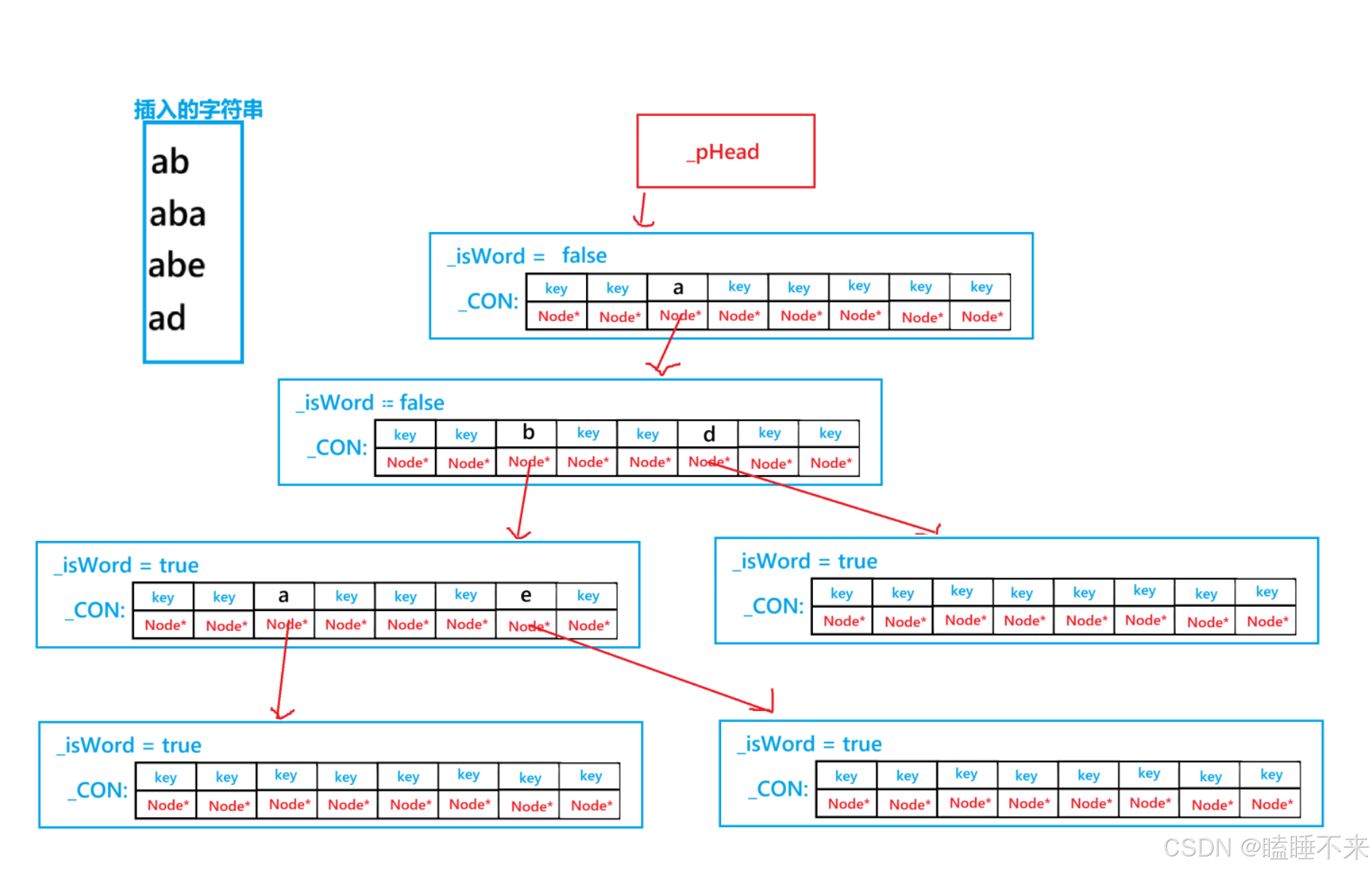
通过上图我们可以知道迭代器的需要哪些变量成员:
-
path :收集遍历过程中的字符,组织成为字符串。
-
pNode :指向当前节点的父节点,方便使用迭代器移动。
-
conIt :父节点的迭代器,其指向当前节点和它字符的对应位置。
-
root :结束根节点,当节点遍历到指定根节点就停止,这个变量是为 Trie 量身定制的前缀迭代器(prefix_iterator) 做准备,可以类比 unordered_map 中哈希表的桶迭代器 local_iterator。
template<class Type, class Reference, class Pointer, class Node, class ContainerIterator>
class TrieIterator
{using Self = TrieIterator<Type, Reference, Pointer, Node, ContainerIterator>;private:Type _path; // 字符串路径Node* _pNode = nullptr; // 当前字符所处的父节点ContainerIterator _conIt; // 父节点的容器迭代器,指向当前节点和字符Node* _root = nullptr; // 指定的根节点
};
但是迭代器无法找到当前节点的父节点,所以我们还需要在节点本身添加指向父节点的指针:
template<class Type>
struct unordered_TrieNode
{bool _isWord = false;std::unordered_map<Type, unordered_TrieNode<Type>*> _con;unordered_TrieNode<Type>* _parent = nullptr;unordered_TrieNode() = default;unordered_TrieNode(unordered_TrieNode<Type>* parent):_parent(parent){;}
};template<class Type>
struct TrieNode
{bool _isWord = false;std::map<Type, TrieNode<Type>*> _con;TrieNode<Type>* _parent = nullptr;TrieNode() = default;TrieNode(TrieNode<Type>* parent):_parent(parent){;}
};
2. 迭代器 ++
考虑 map 为底层容器,简单分析当前节点 ++ 时,下一个节点要么是 map 内部的下一个容器迭代器,要么是父节点的 map 的下一个容器迭代器。
则我们从一个节点的视角思考,并且只考虑找到下一个节点,不关心它的 _isWord 是否为真。则当 Trie 迭代器 ++ 时,迭代器指向的当前节点只有两种选择:
-
当前节点有子节点,获得子节点第一个字符就算是下一个迭代器,然后返回。
-
当前节点没有子节点,移动到下一个兄弟节点。此时兄弟节点就是下一个迭代器,但是兄弟节点为容器 end() 的话,就回到父节点并 ++ 当前容器迭代器,此时情况与第二个选择类似,则递归问题,直到到达规定的 _root 节点,表示结束。
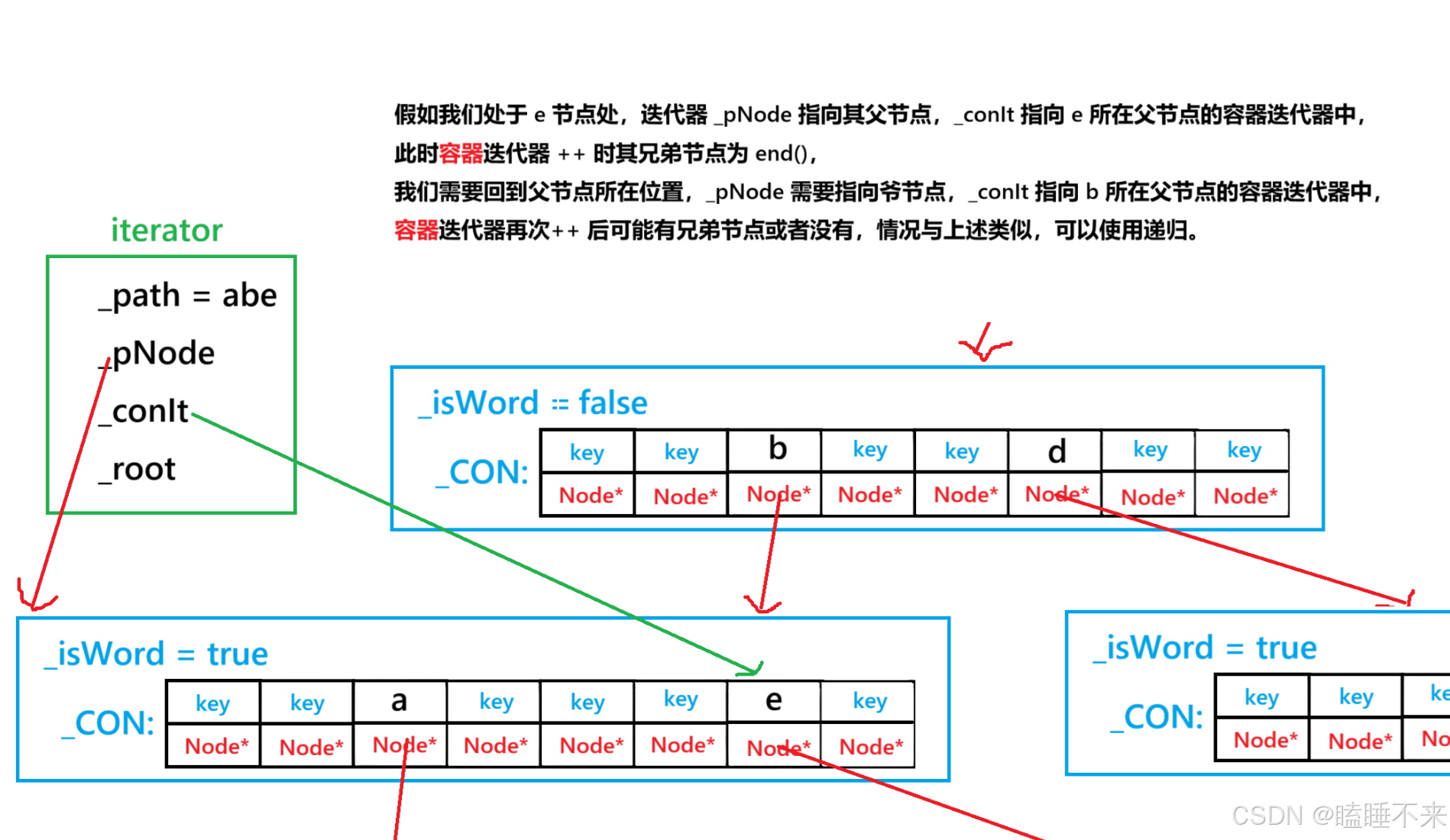
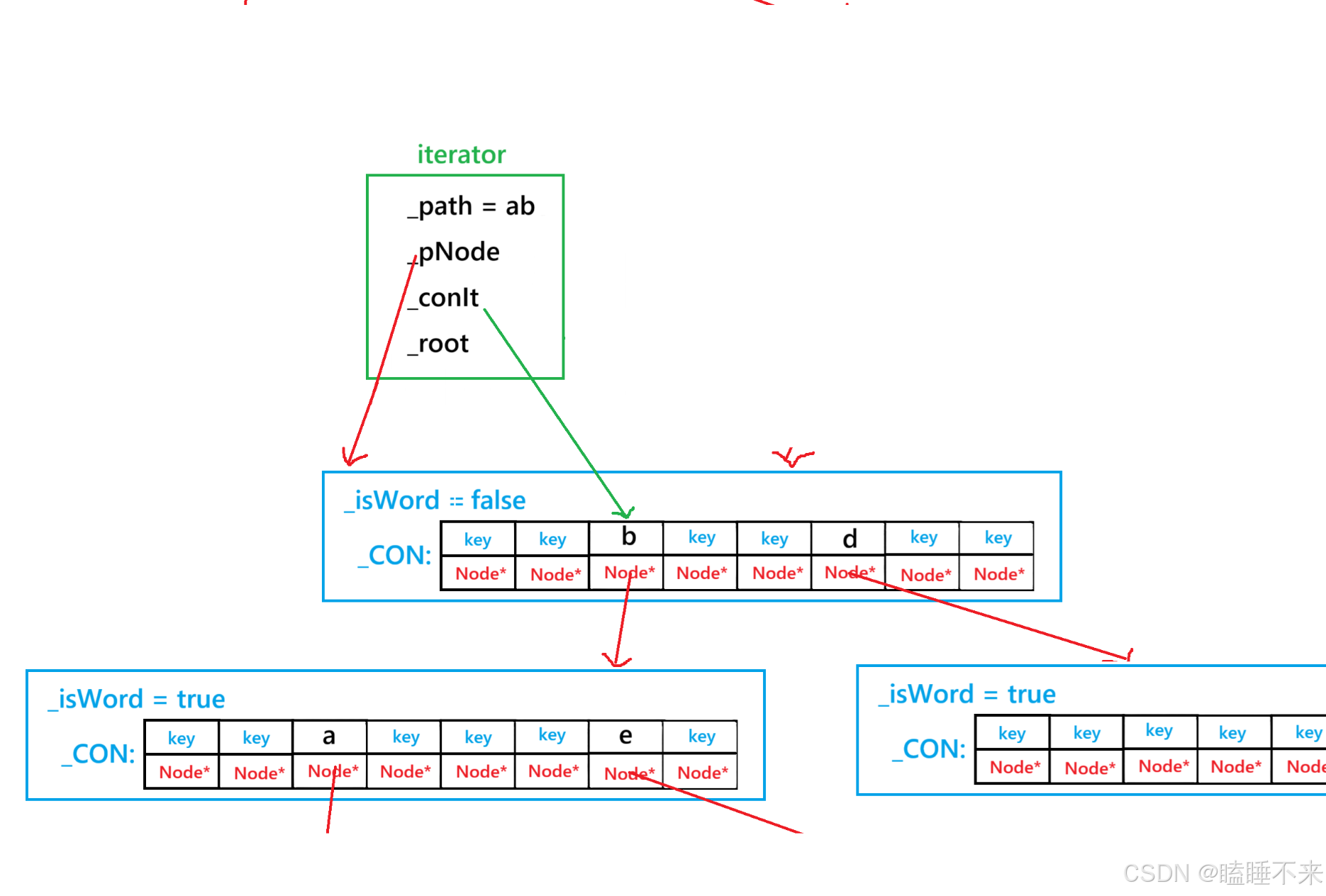
代码可以这样写:
void _solveAddition()
{if (_conIt->second == nullptr || _conIt->second->_con.size() == 0) {_additionLeftPosition(); // 没有子节点则离开当前节点}else{_additionEnterPosition(); // 否则进入子节点}
}void _additionLeftPosition()
{++_conIt;_path.pop_back(); // 移除 _path 残留的上一个字符if (_conIt != _pNode->_con.end()) // 不是 end() 直接填入字符退出{_path.push_back(_conIt->first);return;}if (_pNode->_parent == _root) // 由根为 nullptr 扩展到前缀迭代器规定的 _root 停止{ // 此时表示 Trie 的迭代器已经到达规定的 end(),该结束了return; // 并且 return 时 _conIt 指向的是 end(),方便后续判断}_pNode = _pNode->_parent; // 回到爷节点_conIt = _pNode->_con.find(_path.back()); // 指向父节点所在的爷节点容器迭代器位置_additionLeftPosition(); // 递归问题
}void _additionEnterPosition()
{_pNode = _pNode->_con[_conIt->first]; // 进入子节点_conIt = _pNode->_con.begin(); // 获取第一个字符所在的容器迭代器_path.push_back(_conIt->first); // 获取字符
}
现在我们需要解决的问题还有两个:
-
当前节点的 _isWord 为假,不允许合成为一个已经插入的字符串并返回给用户使用。
-
_additionLeftPositiion() 函数递归到指定的 _root 结束,此时 _conIt 为 end() ,访问 _isWord 非法。
这里只需要在迭代器++ 函数中判断即可:
Self& operator++()
{assert(_conIt != _pNode->_con.end());do{_solveAddition(); } while (_conIt != _pNode->_con.end() && _conIt->second->_isWord == false);// 循环出来到这只有两种情况:// 1. _conIt 为父节点容器迭代器的 end(),表示到达 Trie 迭代器的 end()// 2. _isWord 等于 true ,表示真正的到达下一个合法的 Trie 迭代器return *this;
}
3. 迭代器 –
同理于迭代器 ++ 的做法,但是注意,当 -- 时,当前节点的子节点所有字符都已经遍历过了,寻找的只是上一个节点。
则我们从一个节点的视角思考,并且只考虑找到上一个节点,不关心它的 _isWord 是否为真。则当迭代器 -- 时,迭代器指向的当前节点移动到上一个节点后只有两种选择:
-
当前节点不为 end() ,如果没有子节点直接返回,反之需要递归寻找到最后一个字符。
-
当前节点为 end() ,需要回到爷节点,如果爷节点为 _root 直接返回,不然修改 _pNode 和 _conIt。
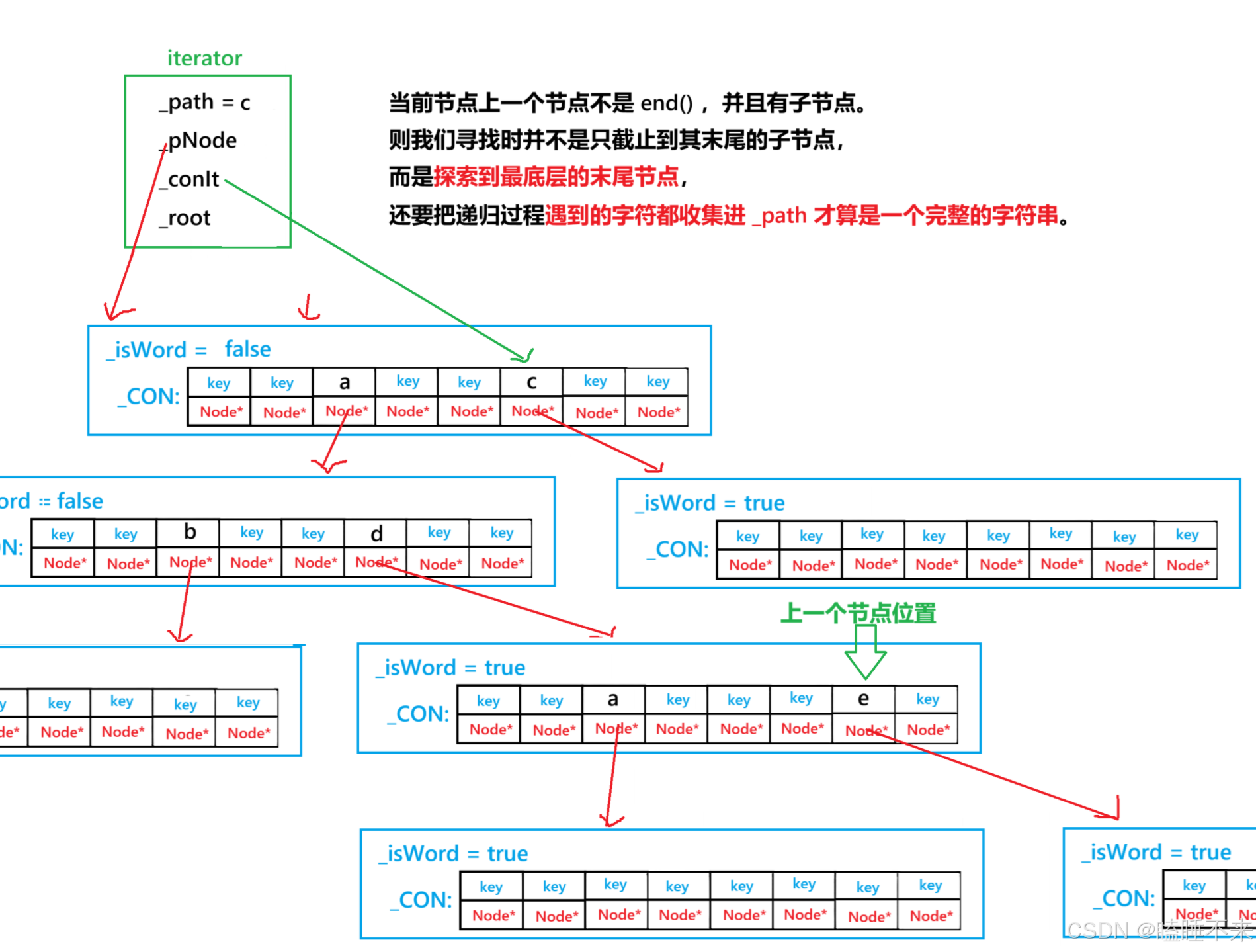
代码可以这样写:
void _solveSubtraction()
{--_conIt; // 移动到上一个节点_path.pop_back(); // 移除残留的字符if (_conIt != _pNode->_con.end()) // 当前节点不为 end() {_subtractionEnterPosition(); // 进入后合并路上遇到的字符而且还要合并最后一个字符}else {_subtractionLeftPosition(); // 离开当前节点}
}void _subtractionLeftPosition()
{if (_pNode->_parent == _root) // 由根为 nullptr 扩展到前缀迭代器规定的 _root 停止{ // 此时表示 Trie 的迭代器已经到达规定的 end(),该结束了return; // 并且 return 时 _conIt 指向的是 end(),方便后续判断}_pNode = _pNode->_parent; // 回到爷节点_conIt = _pNode->_con.find(_path.back()); // 回到父节点所在爷节点的容器迭代器
}void _subtractionEnterPosition()
{_path.push_back(_conIt->first); // 合并路上遇到的字符if (_conIt->second == nullptr || _conIt->second->_con.size() == 0){return; // 当前节点没有子节点,直接退出}_pNode = _pNode->_con[_conIt->first]; // 进入子节点_conIt = std::prev(_pNode->_con.end()); // 回到子节点最后一个容器迭代器位置_subtractionEnterPosition(); // 递归判断是否还有孙子节点或者辈分更小的节点
}
同理与迭代器 ++ ,现在我们需要解决的问题还有两个:
-
当前节点的 _isWord 为假,不允许合成为一个已经插入的字符串并返回给用户使用。
-
_subtractionLeftPosition() 函数遇到 _root 结束,此时 _conIt 为 end() ,访问 _isWord 非法。
这里只需要在迭代器-- 函数中判断即可:
Self& operator--()
{assert(_conIt != _pNode->_con.end());do{_solveSubtraction();} while (_conIt != _pNode->_con.end() && _conIt->second->_isWord == false);// 循环出来到这只有两种情况:// 1. _conIt 为容器迭代器的 end(),表示到达 Trie 迭代器的 end()// 2. _isWord 等于 true ,表示真正的到达下一个合法的 Trie 迭代器return *this;
}
4. 迭代器判断
迭代器判断实现只需要判断其中的容器迭代器,但不同节点的容器迭代器类型是相同的,所以还需要考虑当前所在字符的 _pNode 是否相同:
bool operator!=(const Self& other) const
{if (_pNode != other._pNode){return true;}return _conIt != other._conIt;
}bool operator==(const Self& other) const
{return !(*this != other);
}
5. Trie 成员函数返回迭代器
Trie 成员函数返回迭代器只用实现四种类型,共计八个函数,并且遵循左闭右开原则。其它均为复用:
-
iterator begin():返回 Trie 第一个有效字符串迭代器。 -
iterator end():返回 Trie 最后一个有效字符串后面一位迭代器。 -
reverse_iterator rbegin():返回 Trie 倒数第一个有效字符迭代器。 -
reverse_iterator rend():返回 Trie 倒数最后一个有效字符串后面一位迭代器。 -
prefix_iterator begin(const String&):返回 Trie 前缀匹配的第一个有效字符串迭代器。 -
prefix_iterator begin(const String&):返回 Trie 前缀匹配的最后一个有效字符串后面一位迭代器。 -
reverse_prefix_iterator rbegin(const String&):返回 Trie 前缀匹配的倒数第一个有效字符迭代器。 -
reverse_prefix_iterator rend(const String&):返回 Trie 前缀匹配的倒数最后一个有效字符串后面一位迭代器。
至于 prefix_iterator 具体的类型,只需要复用 iterator 就行,reverse_prefix_iterator 同理。
begin 函数 和 end 函数
之前我们已经说明了迭代器内变量成员的作用,这里只需按照对应规则创建即可。
对于 begin 函数:
iterator begin()
{auto it = _pHead->_con.begin();iterator temp(String(), _pHead, _pHead->_con.begin(), nullptr);temp._path += it->first;if (it->second->_isWord == false) // 考虑第一个是否为插入的字符串{++temp;}return temp;
}prefix_iterator begin(const String& str)
{pNode aim = _find(str);if (aim == nullptr){return this->end();}prefix_iterator temp(str, aim->_parent, aim->_parent->_con.find(str.back()), aim->_parent->_parent);if (aim->_isWord == false) // 需要考虑前缀本身是否是其中的元素{++temp;}return temp;
}
end 函数实现:
iterator end()
{return { String(), _pHead, _pHead->_con.end(), nullptr };
}prefix_iterator end(const String& str)
{pNode aim = _find(str);if (aim == nullptr){return this->end();}return { String(), aim->_parent, aim->_parent->_con.end(), aim->_parent->_parent };
}
rbegin 函数 和 rend 函数
rbegin 函数需要寻找倒数第一个字符串,但问题是 Trie 中的字符是被拆成一个个字符,这意味着我们到达倒数第一个字符串时需要收集路径上的字符:
reverse_iterator _collect_char(pNode ptr, String path, pNode root)
{ContainerIterator conIt;// 由于 Trie 中的字符是分散的,rbegin 就必须将路径上的所有字符都收集到 path 中while (ptr->_con.size() > 0){conIt = std::prev(ptr->_con.end());path += conIt->first;ptr = ptr->_con[conIt->first];}iterator temp(path, ptr->_parent, conIt, root);if (temp._conIt->second->_isWord == false){--temp;}return reverse_iterator(temp);
}reverse_iterator rbegin()
{if (this->_size <= 0){return this->rend();}String path;return _collect_char(_pHead, path, _pHead->_parent);
}reverse_prefix_iterator rbegin(const String& str)
{pNode aim = _find(str);if (aim == nullptr){return this->rend();}return this->_collect_char(aim, str, aim->_parent->_parent);
}
rend 函数实现:
reverse_iterator rend()
{return reverse_iterator(this->end());
}reverse_prefix_iterator rend(const String& str)
{pNode aim = _find(str);if (aim == nullptr){return this->rend();}// rend 函数需要找到前缀匹配倒数最后一个的后一个节点,需要借助 iterator -- 到达目标。prefix_iterator temp(str, aim->_parent, aim->_parent->_con.find(str.back()), aim->_parent->_parent);--temp;return temp;
}
使用事项
-
Trie 内部的字符是分散的,迭代器内的 _path 路径不允许修改,则 iterator 和 const_iterator 两者没有区别。
-
我们实现的 end、rend 中,只有 reverse_prefix_iterator 实现的 rend 使用了迭代器的 -- 移动,除此之外其它内部的 _path 都是空的,返回的字符串没有意义。
-
iterator 和 prefix_iterator 迭代器虽然类型相同,但最好不要混淆并且用来比较,其内部指向的 _root 有可能不是相同的,其它同理。
-
unordered_map 只有 begin 和 end ,并且容器迭代器没有--,不能正常使用 rbegin 和 rend 迭代器遍历内部元素。
6. 源码展示
内部实现了其它函数,但不是重点,这里不多赘述:
#pragma once#include <map>
#include <string>
#include <vector>
#include <cassert>
#include <iterator>
#include <unordered_map>namespace my
{template<class Type>struct unordered_TrieNode{bool _isWord = false;std::unordered_map<Type, unordered_TrieNode<Type>*> _con;unordered_TrieNode<Type>* _parent = nullptr;unordered_TrieNode() = default;unordered_TrieNode(unordered_TrieNode<Type>* parent):_parent(parent){;}};template<class Type>struct TrieNode{bool _isWord = false;std::map<Type, TrieNode<Type>*> _con;TrieNode<Type>* _parent = nullptr;TrieNode() = default;TrieNode(TrieNode<Type>* parent):_parent(parent){;}};template<class Type, class Reference, class Pointer, class Node, class ContainerIterator>class TrieIterator{private:template<class Type, class String, class Node, class Container>friend class TrieBase;using Self = TrieIterator<Type, Reference, Pointer, Node, ContainerIterator>;private:void _solveAddition(){if (_conIt->second == nullptr || _conIt->second->_con.size() == 0){_additionLeftPosition(); // 没有子节点则离开当前节点}else{_additionEnterPosition(); // 否则进入子节点}}void _additionLeftPosition(){++_conIt;_path.pop_back(); // 移除 _path 残留的上一个字符if (_conIt != _pNode->_con.end()) // 不是 end() 直接填入字符退出{_path.push_back(_conIt->first);return;}if (_pNode->_parent == _root) // 由根为 nullptr 扩展到前缀迭代器规定的 _root 停止{ // 此时表示 Trie 的迭代器已经到达规定的 end(),该结束了return; // 并且 return 时 _conIt 指向的是 end(),方便后续判断}_pNode = _pNode->_parent; // 回到爷节点_conIt = _pNode->_con.find(_path.back()); // 指向父节点所在的爷节点容器迭代器位置_additionLeftPosition(); // 递归问题}void _additionEnterPosition(){_pNode = _pNode->_con[_conIt->first]; // 进入子节点_conIt = _pNode->_con.begin(); // 获取第一个字符所在的容器迭代器_path.push_back(_conIt->first); // 获取字符}void _solveSubtraction(){--_conIt; // 移动到上一个节点_path.pop_back(); // 移除残留的字符if (_conIt != _pNode->_con.end()) // 当前节点不为 end() {_subtractionEnterPosition(); // 进入后合并路上遇到的字符而且还要合并最后一个字符}else{_subtractionLeftPosition(); // 离开当前节点}}void _subtractionLeftPosition(){if (_pNode->_parent == _root) // 由根为 nullptr 扩展到前缀迭代器规定的 _root 停止{ // 此时表示 Trie 的迭代器已经到达规定的 end(),该结束了return; // 并且 return 时 _conIt 指向的是 end(),方便后续判断}_pNode = _pNode->_parent; // 回到爷节点_conIt = _pNode->_con.find(_path.back()); // 回到父节点所在爷节点的容器迭代器}void _subtractionEnterPosition(){_path.push_back(_conIt->first); // 合并路上遇到的字符if (_conIt->second == nullptr || _conIt->second->_con.size() == 0){return; // 当前节点没有子节点,直接退出}_pNode = _pNode->_con[_conIt->first]; // 进入子节点_conIt = std::prev(_pNode->_con.end()); // 回到子节点最后一个容器迭代器位置_subtractionEnterPosition(); // 递归判断是否还有孙子节点或者辈分更小的节点}public:Reference operator*() const{return _path;}Pointer operator->(){return &_path;}Self& operator++(){assert(_conIt != _pNode->_con.end());do{_solveAddition();} while (_conIt != _pNode->_con.end() && _conIt->second->_isWord == false);// 循环出来到这只有两种情况:// 1. _conIt 为父节点容器迭代器的 end(),表示到达 Trie 迭代器的 end()// 2. _isWord 等于 true ,表示真正的到达下一个合法的 Trie 迭代器return *this;}Self& operator--(){assert(_conIt != _pNode->_con.end());do{_solveSubtraction();} while (_conIt != _pNode->_con.end() && _conIt->second->_isWord == false);// 循环出来到这只有两种情况:// 1. _conIt 为容器迭代器的 end(),表示到达 Trie 迭代器的 end()// 2. _isWord 等于 true ,表示真正的到达下一个合法的 Trie 迭代器return *this;}bool operator!=(const Self& other) const{if (_pNode != other._pNode){return true;}return _conIt != other._conIt;}bool operator==(const Self& other) const{return !(*this != other);}public:TrieIterator() = default;TrieIterator(const Type& path, Node* pNode, ContainerIterator conIt, Node* root):_path(path), _pNode(pNode), _conIt(conIt), _root(root){;}private:Type _path; // 字符串路径Node* _pNode = nullptr; // 当前字符所处的父节点ContainerIterator _conIt; // 父节点的容器迭代器,指向当前节点和字符Node* _root = nullptr; // 指定的根节点};template<class Type, class Reference, class Pointer, class Node, class ContainerIterator>class ReverseTrieIterator{using iterator = TrieIterator<Type, Reference, Pointer, Node, ContainerIterator>;using Self = ReverseTrieIterator<Type, Reference, Pointer, Node, ContainerIterator>;public:Reference operator*() const{return *_it;}Pointer operator->(){return _it->operator->();}Self& operator++(){--_it;return *this;}Self& operator--(){++_it;return *this;}bool operator!=(const Self& other) const{return _it != other._it;}bool operator==(const Self& other) const{return _it == other._it;}public:ReverseTrieIterator() = default;ReverseTrieIterator(const Type& path, Node* pNode, ContainerIterator conIt, Node* root):_it(path, pNode, conIt, root){;}ReverseTrieIterator(iterator it):_it(it){;}private:iterator _it;};template<class Type = char, class String = std::string, class Node = TrieNode<Type>, class Container = std::map<Type, Node*>>class TrieBase{private:using Self = TrieBase<Type, String, Node, Container>;using pNode = Node*;using ContainerIterator = typename Container::iterator;public:using iterator = TrieIterator<String, const String&, const String*, Node, ContainerIterator>;using reverse_iterator = ReverseTrieIterator<String, const String&, const String*, Node, ContainerIterator>;using const_iterator = iterator;using const_reverse_iterator = reverse_iterator;using prefix_iterator = iterator;using const_prefix_iterator = prefix_iterator;using reverse_prefix_iterator = reverse_iterator;using const_reverse_prefix_iterator = reverse_iterator;iterator begin(){auto it = _pHead->_con.begin();iterator temp(String(), _pHead, _pHead->_con.begin(), nullptr);temp._path += it->first;if (it->second->_isWord == false) // 考虑第一个是否为插入的字符串{++temp;}return temp;}prefix_iterator begin(const String& str){pNode aim = _find(str);if (aim == nullptr){return this->end();}prefix_iterator temp(str, aim->_parent, aim->_parent->_con.find(str.back()), aim->_parent->_parent);if (aim->_isWord == false) // 需要考虑前缀本身是否是其中的元素{++temp;}return temp;}iterator end(){return { String(), _pHead, _pHead->_con.end(), nullptr };}prefix_iterator end(const String& str){pNode aim = _find(str);if (aim == nullptr){return this->end();}return { String(), aim->_parent, aim->_parent->_con.end(), aim->_parent->_parent };}reverse_iterator rbegin(){if (this->_size <= 0){return this->rend();}String path;return _collect_char(_pHead, path, _pHead->_parent);}reverse_prefix_iterator rbegin(const String& str){pNode aim = _find(str);if (aim == nullptr){return this->rend();}return this->_collect_char(aim, str, aim->_parent->_parent);}reverse_iterator rend(){return reverse_iterator(this->end());}reverse_prefix_iterator rend(const String& str){pNode aim = _find(str);if (aim == nullptr){return this->rend();}// rend 函数需要找到前缀匹配倒数最后一个的后一个节点,需要借助 iterator -- 到达目标。prefix_iterator temp(str, aim->_parent, aim->_parent->_con.find(str.back()), aim->_parent->_parent);--temp;return temp;}const_iterator begin() const{return this->begin();}const_iterator end() const{return this->end();}const_iterator cbegin() const{return this->begin();}const_iterator cend() const{return this->end();}const_prefix_iterator begin(const String& str) const{return this->begin(str);}const_prefix_iterator end(const String& str) const{return this->end(str);}const_prefix_iterator cbegin(const String& str) const{return this->begin(str);}const_prefix_iterator cend(const String& str) const{return this->end(str);}const_reverse_iterator rbegin() const{return this->rbegin();}const_reverse_iterator rend() const{return this->rend();}const_reverse_iterator crbegin() const{return this->rbegin();}const_reverse_iterator crend() const{return this->rend();}const_reverse_prefix_iterator rbegin(const String& str) const{return this->rbeign(str);}const_reverse_prefix_iterator rend(const String& str) const{return this->rend(str);}const_reverse_prefix_iterator crbegin(const String& str) const{return this->rbegin(str);}const_reverse_prefix_iterator crend(const String& str) const{return this->rend(str);}public:TrieBase():_pHead(new Node), _size(0){;}TrieBase(const Self& trie):_pHead(new Node), _size(trie._size){auto it = trie.begin();auto itEnd = trie.end();while (it != itEnd){this->insert(*it);++it;}}Self& operator=(const Self& trie){if (this == &trie){return *this;}Self temp(trie);swap(temp);return *this;}TrieBase(Self&& trie):_pHead(new Node), _size(0){swap(trie);}Self& operator=(Self&& trie){swap(trie);return *this;}void swap(Self& trie){std::swap(_pHead, trie._pHead);std::swap(_size, trie._size);}template<class InputIterator>TrieBase(InputIterator first, InputIterator last):_pHead(new Node), _size(0){while (first != last){insert(*first);++first;}}TrieBase(std::initializer_list<String> list):_pHead(new Node), _size(0){for (auto& e : list){insert(e);}}public:bool insert(const String& str){assert(_pHead != nullptr);pNode ptr = _pHead;for (auto& e : str){if (!ptr->_con.count(e)){ptr->_con.insert({ e, new Node(ptr) });}ptr = ptr->_con[e];}if (ptr->_isWord == false){++_size;return ptr->_isWord = true;}else{return false;}}iterator find(const String& str){pNode ptr = _find(str);if (ptr == nullptr || ptr->_isWord == false){return this->end();}return { str, ptr->_parent, ptr->_parent->_con.find(str.back()), ptr->_parent };}bool erase(const String& str){assert(_size > 0);pNode ptr = _find(str);if (ptr == nullptr || ptr->_isWord == false){return false;}ptr->_isWord = false;--_size;return true;}std::vector<String> prefixMatch(const String& prefix){std::vector<String> words;auto it = this->begin(prefix);if (prefix.size() == 0){it = this->begin();}if (it == this->end()){return words;}auto itEnd = this->end(prefix);while (it != itEnd){words.push_back(*it);++it;}return words;}template<class InputIterator>void insert(InputIterator first, InputIterator last){while (first != last){insert(*first);++first;}}void insert(std::initializer_list<String> list){for (auto& e : list){insert(e);}}iterator erase(iterator pos){assert(_size > 0);iterator temp = pos;++temp;pos._conIt->second->_isWord = false;--_size;return temp;}iterator erase(const_iterator first, const_iterator last){assert(_size > 0);while (first != last){first._conIt->second->_isWord = false;++first;--_size;}return last;}bool erasePrefix(const String& str){assert(_size > 0);prefix_iterator pbegin = this->begin(str);prefix_iterator pend = this->end(str);if (pbegin == pend){return false;}while (pbegin != pend){pbegin._conIt->second->_isWord = false;++pbegin;--_size;}return true;}size_t size() const{return _size;}~TrieBase(){this->_PostorderTraversal(_pHead);}private:pNode _find(const String& str){assert(_pHead != nullptr);pNode ptr = _pHead;for (auto& e : str){if (ptr->_con.count(e)){ptr = ptr->_con[e];}else{return nullptr;}}return ptr == _pHead ? nullptr : ptr;}void _PostorderTraversal(pNode root){if (root == nullptr){return;}for (auto& e : root->_con){_PostorderTraversal(e.second);}root->_parent = nullptr;delete root;}reverse_iterator _collect_char(pNode ptr, String path, pNode root){ContainerIterator conIt;// 由于 Trie 中的字符是分散的,rbegin 就必须将路径上的所有字符都收集到 path 中while (ptr->_con.size() > 0){conIt = std::prev(ptr->_con.end());path += conIt->first;ptr = ptr->_con[conIt->first];}iterator temp(path, ptr->_parent, conIt, root);if (temp._conIt->second->_isWord == false){--temp;}return reverse_iterator(temp);}private:pNode _pHead = new Node(nullptr);size_t _size = 0;};using unordered_wTrie = TrieBase<wchar_t, std::wstring, unordered_TrieNode<wchar_t>,std::unordered_map<wchar_t, unordered_TrieNode<wchar_t>*>>;using unordered_Trie = TrieBase<char, std::string, unordered_TrieNode<char>,std::unordered_map<char, unordered_TrieNode<char>*>>;using wTrie = TrieBase<wchar_t, std::wstring, TrieNode<wchar_t>, std::map<wchar_t, TrieNode<wchar_t>*>>;using Trie = TrieBase<char, std::string, TrieNode<char>, std::map<char, TrieNode<char>*>>;
}
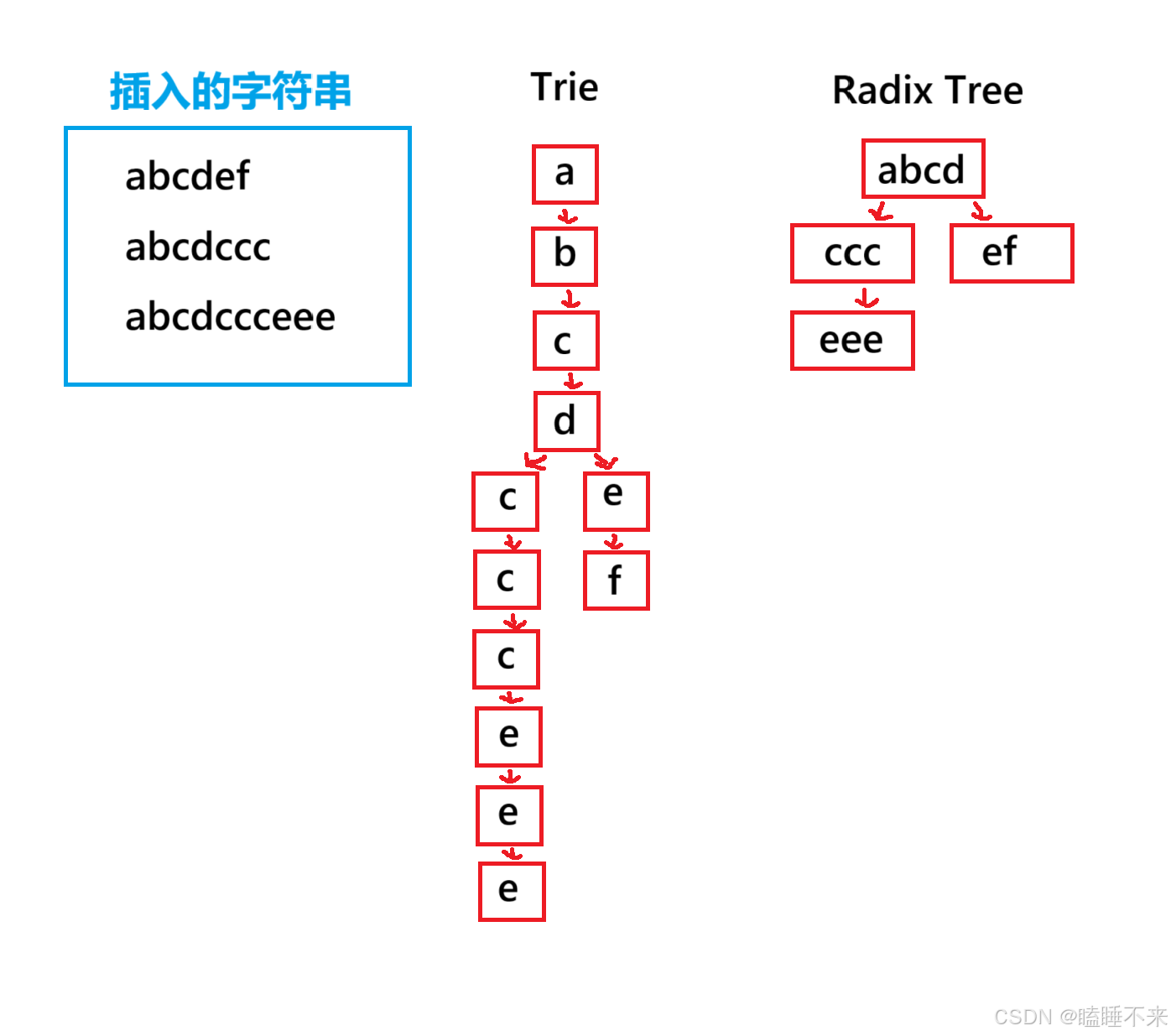
四、Trie 特点与其变体 基数树
Trie 优点:
-
查询高效:查询一个单词或前缀的时间复杂度为 O(n),其中 n 是单词或前缀的长度。与数据集中的单词总数无关,这在处理大规模数据时优势巨大。
-
前缀查询:非常适合做前缀匹配和自动补全,这是哈希表等数据结构不擅长的。
Trie 缺点:
-
空间消耗大:每个节点都需要一个 map 或 unordered_map(即便使用对应的指针或更节省空间的容器,也只是在常量上减少空间)。
-
适用范围:主要用于字符串(尤其是具有公共前缀的字符串)检索。对于非字符串数据或前缀不明显集中的场景,优势不大。
Trie 这种结构一个字符就是一个节点,它的链式结构过长,不仅增加了树的深度,浪费内存,也降低查找效率。
而 基数树 RadixTree (也称为压缩前缀树 CompressedTrie) 或紧凑前缀树,是一种基于 Trie 的空间优化数据结构。其核心思想就是将链式结构中连续的单个字符的节点合并成一个字符串节点,减少了大量不必要存在的节点,大大节省空间,是实际工程中更常用的变体。