Windows 系统部署 PaddleOCR —— 基于 EPGF 架构
Windows 系统部署 PaddleOCR ——基于 EPGF 架构

PaddlePaddle/PaddleOCR:将任何 PDF 或图像文档转换为 AI 的结构化数据。一个功能强大、轻量级的 OCR 工具包,可弥合图像/PDF 和 LLM 之间的差距。支持 80+ 语言。
一、EPGF 架构搭建与 Python 环境准备
【00】EPGF 架构搭建教程之 总揽篇
【收藏级】Windows AI 本地开发「完全体」环境搭建清单
在 EPGF 架构下,推荐使用精简路径和统一管理的多版本 Python 环境。以 Conda 的 Python 3.10 为例,路径结构示例如下:
D:\
└── A\ # Anaconda 安装根目录├── Library\├── Scripts\└── envs\py310\ # Conda 虚拟环境:Python 3.10└── python.exe # 解释器路径
此路径将作为后续 PyCharm 和命令行的基础解释器,确保环境可控、可迁移、可复现。
二、克隆 PaddleOCR 仓库
项目地址:
https://github.com/PaddlePaddle/PaddleOCR
步骤 1:使用 GitHub Desktop 克隆仓库
-
启动 GitHub Desktop 应用。
-
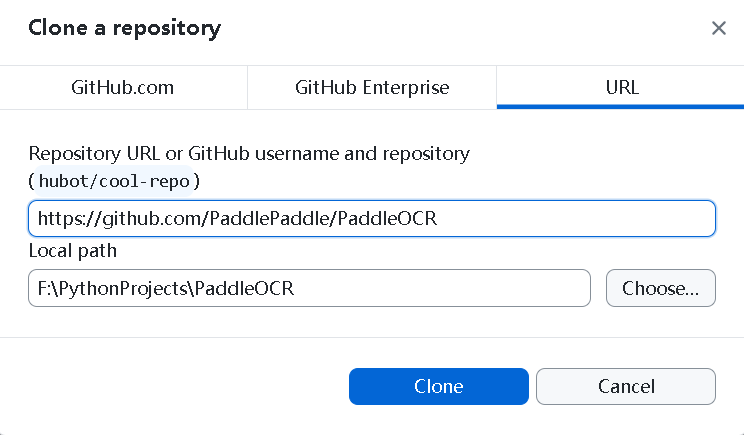
点击 Clone a repository → 选择 URL 选项卡。
-
在输入框中填入:
-
Repository URL:
https://github.com/PaddlePaddle/PaddleOCR -
Local Path:
F:\PythonProjects\PaddleOCR
-
-
点击 Clone 按钮开始克隆。
Repository URL:
https://github.com/PaddlePaddle/PaddleOCRLocal Path:
F:\PythonProjects\PaddleOCR
步骤 2:等待克隆完成
GitHub Desktop 会显示克隆进度条,等待进度达到 100%。
步骤 3:在外部编辑器中打开项目
克隆完成后,在右侧点击 Open in external editor,将项目直接打开到 PyCharm。
三、在 PyCharm 配置虚拟环境
-
打开 PyCharm,载入项目
F:\PythonProjects\PaddleOCR。 -
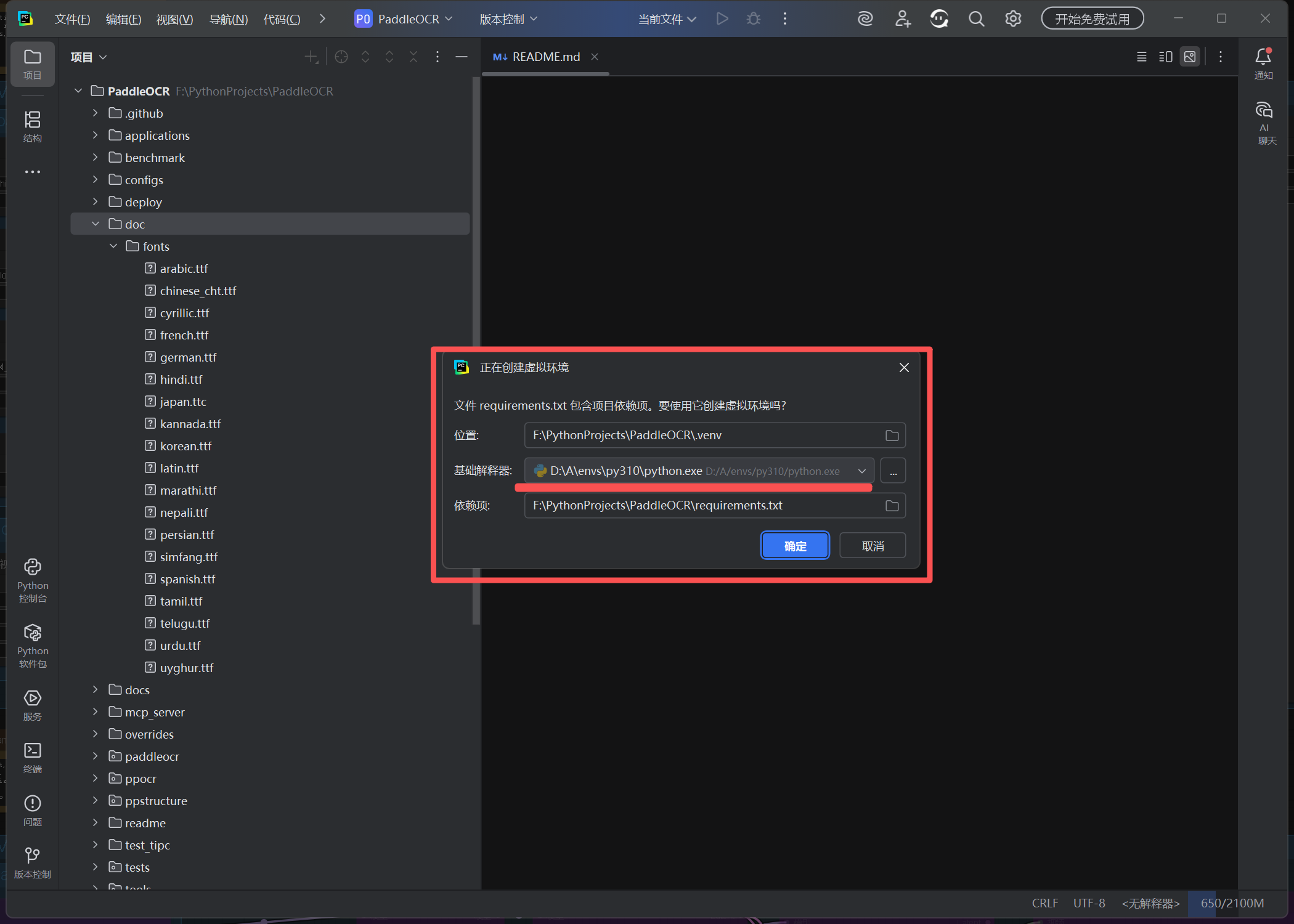
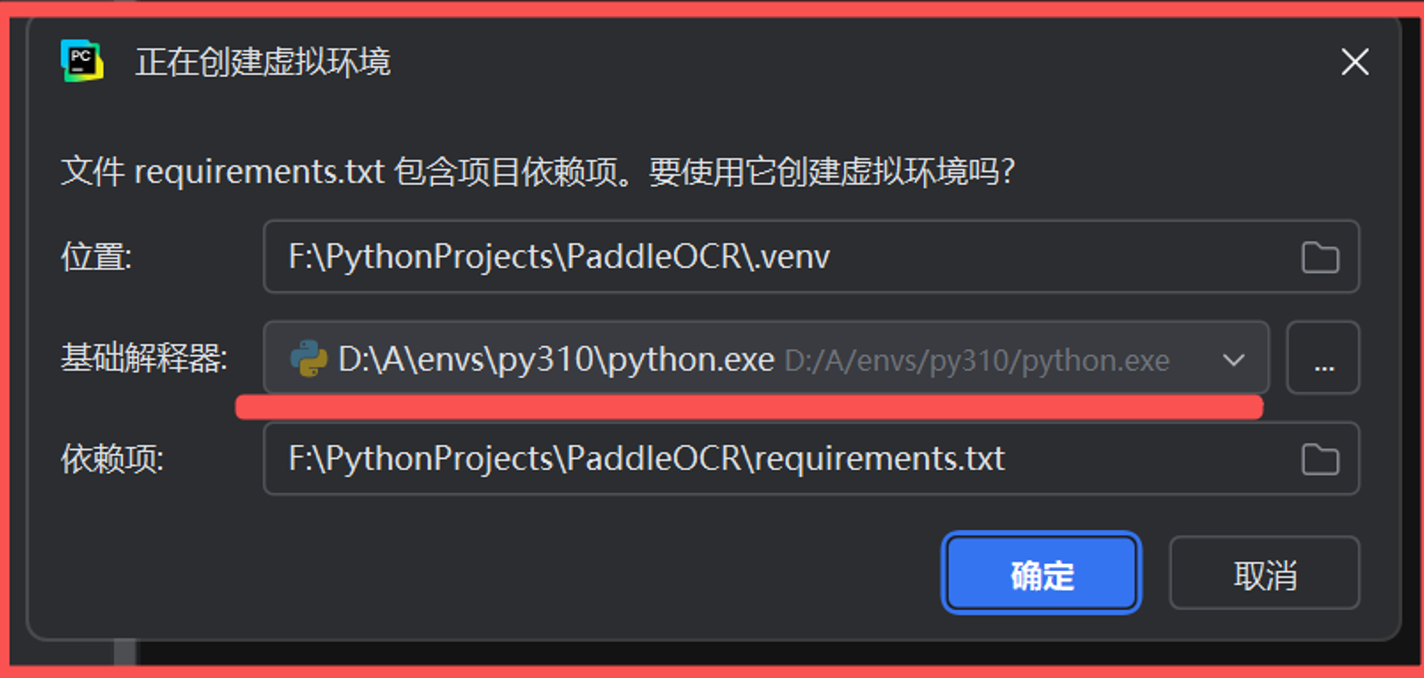
如果 PyCharm 自动提示创建虚拟环境,检查配置:
-
位置:
F:\PythonProjects\PaddleOCR\.venv -
基础解释器:选择
D:\A\envs\py310\python.exe (来源于 EPGF 架构) -
依赖文件:
requirements.txt
-
-
点击 OK,PyCharm 会创建
.venv并安装依赖。 -
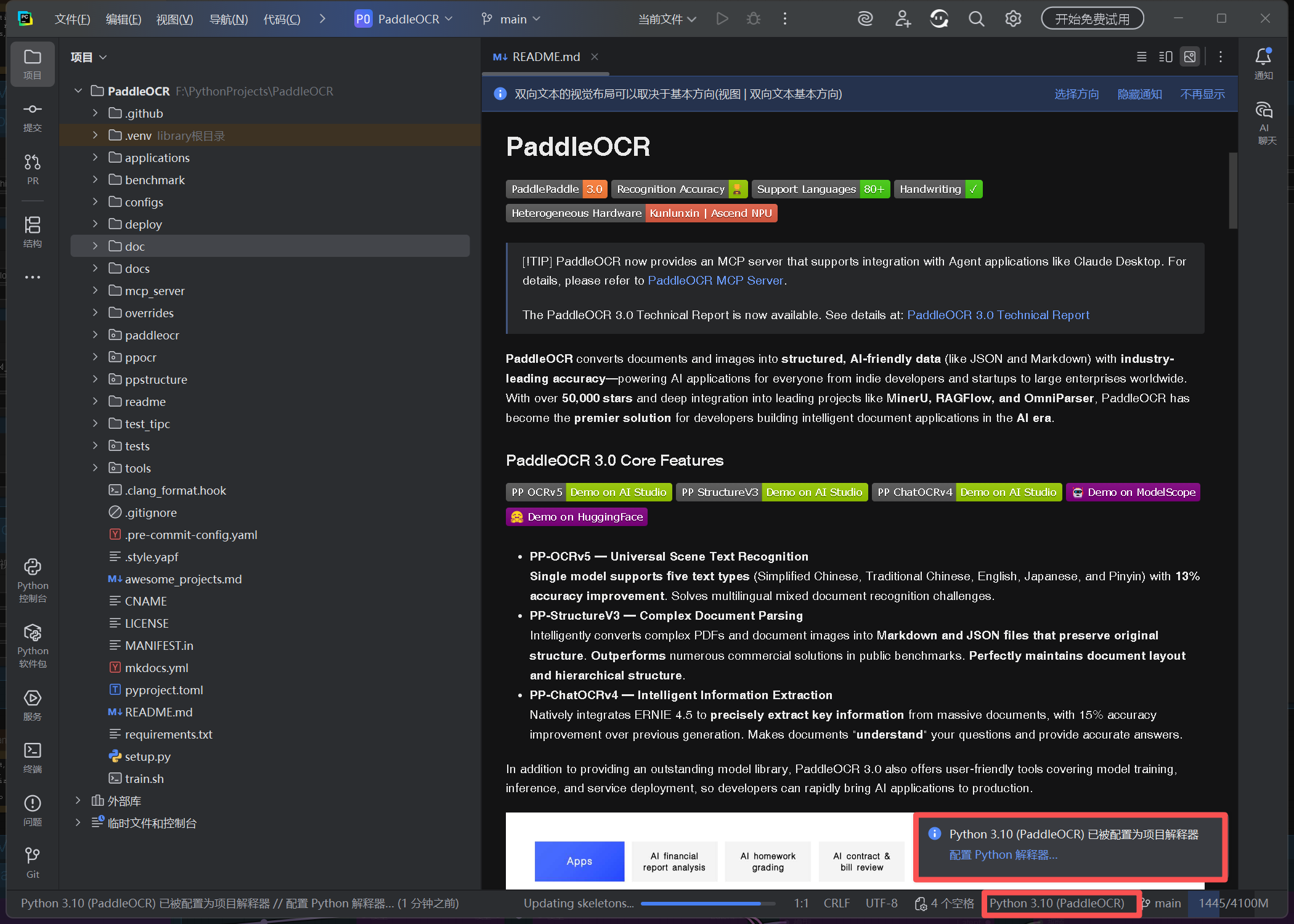
配置完成后,状态栏应显示解释器:
Python 3.10 (.venv)。
建议:即使 Conda 已提供环境,仍使用项目级
.venv,可提高可迁移性。
四、安装 PaddleOCR 及依赖
在 PyCharm 终端或系统命令行执行:
python -m pip install --upgrade pip setuptools wheel
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simplepip install -r requirements.txt
python -m pip install paddlepaddle-gpu==3.0.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
可选:安装
ccache加速编译
下载安装包:https://github.com/ccache/ccache/releases/tag/v4.12
解压ccache-4.12-windows-x86_64.zip并将可执行文件路径加入环境变量。
验证 PaddlePaddle 是否安装成功:
python -c "import paddle; print(paddle.__version__)"
安装 PaddleOCR:
pip install paddleocr
五、运行测试脚本
在项目根目录创建 run.py,内容如下:
from paddleocr import PaddleOCR# 初始化 PaddleOCR,使用 use_textline_orientation 替代已弃用的 use_angle_cls
ocr = PaddleOCR(use_textline_orientation=True, lang='ch')# 图像路径(请修改为自己的文件路径)
img_path = "E:/Downloads/IndexTTS2_banner.png"# 执行识别
result = ocr.predict(img_path)# 输出结果
for line in result:print(line)
执行:
python run.py
注意修改成自己的测试图片路径:
# 图像路径
img_path = "E:/Downloads/IndexTTS2_banner.png"
附此次的测试图片:
"E:/Downloads/IndexTTS2_banner.png"

六、验证部署
确保终端输出识别结果,如无报错即部署成功。
七、运行结果解析与状态说明
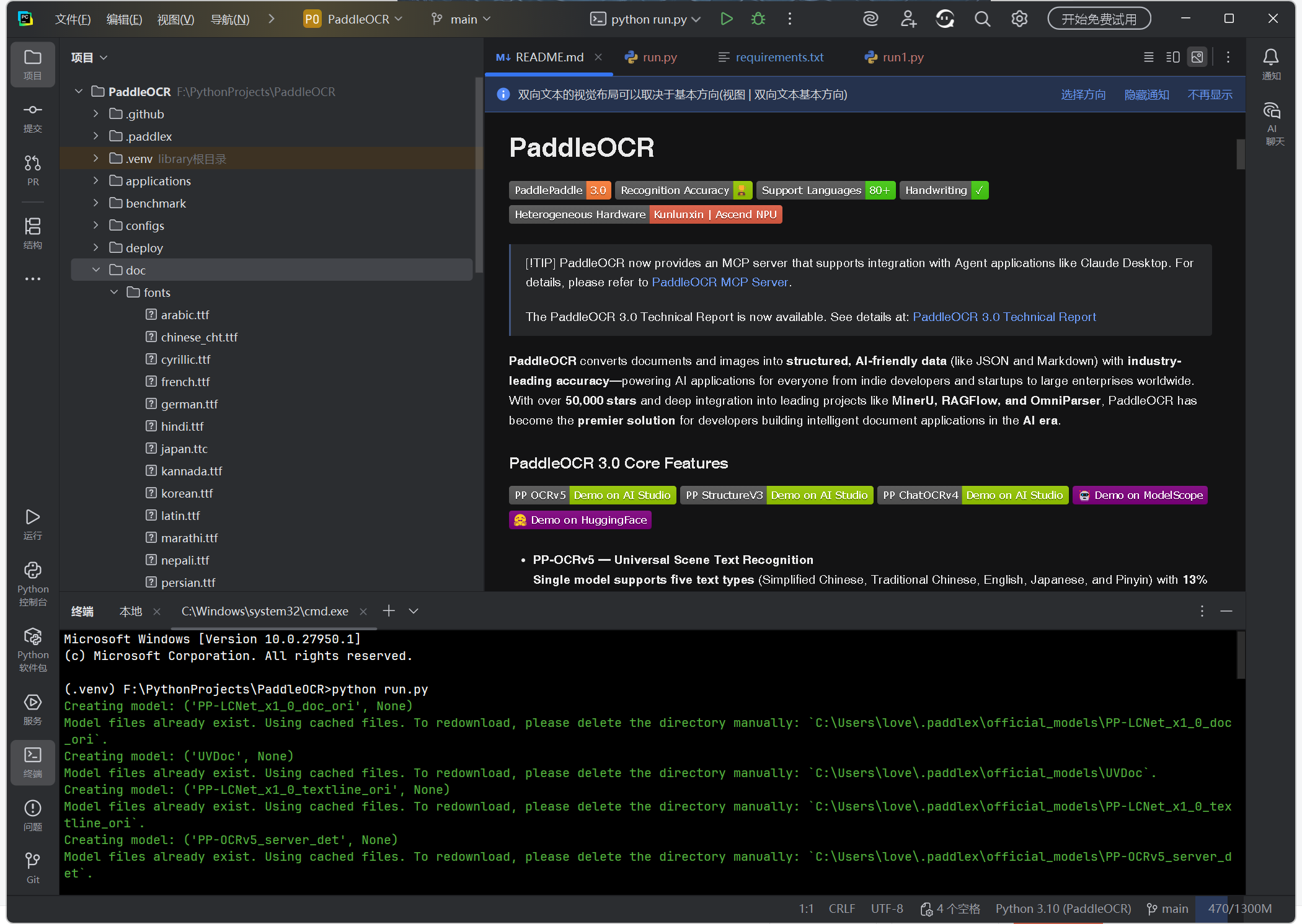
运行结果:
(完整示例)
(.venv) F:\PythonProjects\PaddleOCR>python run.py
Creating model: ('PP-LCNet_x1_0_doc_ori', None)
Model files already exist. Using cached files. To redownload, please delete the directory manually: `C:\Users\love\.paddlex\official_models\PP-LCNet_x1_0_doc_ori`.
Creating model: ('UVDoc', None)
Model files already exist. Using cached files. To redownload, please delete the directory manually: `C:\Users\love\.paddlex\official_models\UVDoc`.
Creating model: ('PP-LCNet_x1_0_textline_ori', None)
Model files already exist. Using cached files. To redownload, please delete the directory manually: `C:\Users\love\.paddlex\official_models\PP-LCNet_x1_0_textline_ori`.
Creating model: ('PP-OCRv5_server_det', None)
Model files already exist. Using cached files. To redownload, please delete the directory manually: `C:\Users\love\.paddlex\official_models\PP-OCRv5_server_det`.
Creating model: ('PP-OCRv5_server_rec', None)
Model files already exist. Using cached files. To redownload, please delete the directory manually: `C:\Users\love\.paddlex\official_models\PP-OCRv5_server_rec`.
{'input_path': 'E:/Downloads/IndexTTS2_banner.png', 'page_index': None, 'doc_preprocessor_res': {'input_path': None, 'page_index': None, 'input_img': array([[[ 7, ..., 2],...,[ 8, ..., 1]],...,[[10, ..., 1],...,[10, ..., 1]]], shape=(1080, 3195, 3), dtype=uint8), 'model_settings': {'use_doc_orientation_classify': True, 'use_doc_unwarping': True}, 'angle': 0, 'rot_img': array([[[ 7, ..., 2],...,[ 8, ..., 1]],...,[[10, ..., 1],...,[10, ..., 1]]], shape=(1080, 3195, 3), dtype=uint8), 'output_img': array([[[ 10, ..., 1],...,[ 12, ..., 2]],...,[[104, ..., 37],...,[ 26, ..., 0]]], shape=(1080, 3195, 3), dtype=uint8)}, 'dt_polys': [array([[3027, 31],...,[3028, 73]], shape=(4, 2), dtype=int16), array([[ 92, 368],...,[ 92, 546]], shape=(4, 2), dtype=int16), array([[2147, 379],...,[2147, 523]], shape=(4, 2), dtype=int16), array([[1772, 571],...,[1771, 639]], shape=(4, 2), dtype=int16), array([[2004, 564],...,[2004, 645]], shape=(4, 2), dtype=int16), array([[359, 577],...,[360, 647]], shape=(4, 2), dtype=int16)], 'model_settings': {'use_doc_preprocessor': True, 'use_textline_orientation': True}, 'text_det_params': {'limit_side_len': 64, 'limit_type': 'min', 'thresh': 0.3, 'max_side_limit': 4000, 'box_thresh': 0.6, 'unclip_ratio': 1.5}, 'text_type': 'general', 'text_rec_score_thresh': 0.0, 'return_word_box': False, 'rec_texts': ['bilibili', 'Index TTS2 Official', 'Release', 'Now', 'Generating', 'The Future ofVoice'], 'rec_scores': [0.9994111061096191, 0.9371538758277893, 0.9967735409736633, 0.7368625998497009, 0.986785888671875, 0.9726100564002991], 'rec_polys': [array([[3027, 31],...,[3028, 73]], shape=(4, 2), dtype=int16), array([[ 92, 368],...,[ 92, 546]], shape=(4, 2), dtype=int16), array([[2147, 379],...,[2147, 523]], shape=(4, 2), dtype=int16), array([[1772, 571],...,[1771, 639]], shape=(4, 2), dtype=int16), array([[2004, 564],...,[2004, 645]], shape=(4, 2), dtype=int16), array([[359, 577],...,[360, 647]], shape=(4, 2), dtype=int16)], 'vis_fonts': [<paddlex.utils.fonts.Font object at 0x000002027EEAB880>, <paddlex.utils.fonts.Font object at 0x000002027EEAB880>, <paddlex.utils.fonts.Font object at 0x000002027EEAB880>, <paddlex.utils.fonts.Font object at 0x000002027EEAB880>, <paddlex.utils.fonts.Font object at 0x000002027EEAB880>, <paddlex.utils.fonts.Font object at 0x000002027EEAB880>], 'textline_orientation_angles': [0, 0, 0, 0, 0, 0], 'rec_boxes': array([[3027, ..., 73],...,[ 359, ..., 647]], shape=(6, 4), dtype=int16)}运行结果解析:
(一)模型加载状态
执行 python run.py 后,终端日志显示 5 个核心模型均加载成功,具体信息如下:
- 加载的模型包括:
PP-LCNet_x1_0_doc_ori、UVDoc、PP-LCNet_x1_0_textline_ori、PP-OCRv5_server_det、PP-OCRv5_server_rec。 - 加载方式:所有模型均使用本地缓存(日志提示
Model files already exist. Using cached files),未触发重新下载,节省运行时间。 - 缓存路径:当前模型缓存存放于默认路径
C:\Users\love\.paddlex\official_models\(若需迁移至项目内,需按前文「PADDLE_HOME配置 + 删除旧缓存」步骤操作)。
(二)识别结果核心信息解析
终端输出的字典包含图像预处理、文本检测、文字识别全流程数据,核心有效信息整理如下:
1. 基础配置信息
| 字段 | 含义 |
|---|---|
input_path | 待识别图像路径:E:/Downloads/IndexTTS2_banner.png |
text_type | 识别文本类型:general(通用文本,支持中英文等多语言) |
text_rec_score_thresh | 识别置信度阈值:0.0(当前未过滤低置信度结果,可按需调整) |
angle | 图像旋转角度:0(图像方向正常,无需旋转矫正) |
2. 核心识别结果(文本 + 置信度)
rec_texts(识别文本)与 rec_scores(对应置信度)一一对应,置信度取值范围为 0~1,越接近 1 表示识别越准确:
| 序号 | 识别文本 | 置信度 | 可信度评价 |
|---|---|---|---|
| 1 | bilibili | 0.9994 | 极高(推荐采纳) |
| 2 | Index TTS2 Official | 0.9372 | 高(推荐采纳) |
| 3 | Release | 0.9968 | 极高(推荐采纳) |
| 4 | Now | 0.7369 | 中等(需核对) |
| 5 | Generating | 0.9868 | 极高(推荐采纳) |
| 6 | The Future ofVoice | 0.9726 | 极高(推荐采纳) |
3. 文本位置信息
rec_polys 字段记录了每个识别文本在图像中的位置坐标(4 个角点,以图像左上角为原点,x 轴向右、y 轴向下),示例如下:
- 文本 “bilibili” 位置:
[[3027, 31], [3098, 31], [3098, 73], [3028, 73]],表示该文本位于图像右上角区域(左上角 x=3027,y=31,右下角 x=3098,y=73)。 - 文本 “Index TTS2 Official” 位置:
[[92, 368], [1008, 368], [1008, 546], [92, 546]],表示该文本位于图像左侧中间区域,占据较大面积。
(三)运行状态总结
- 功能验证:PaddleOCR 文字识别功能完全正常,成功提取图像中的 6 段文本,核心信息(如 “Index TTS2 Official”“The Future ofVoice”)识别准确。
- 待优化点:模型加载自 C 盘默认缓存路径,未实现项目内自包含(需删除 C 盘
.paddlex文件夹,并重新配置PADDLE_HOME= <路径> 环境变量来实现迁移)。 - 结果可用性:除 “Now”(置信度 0.7369)需人工核对外,其余文本置信度均>0.9,识别结果具备较高参考价值。
- 实用价值:有待后续开发演化。
八、迁移与复现
- 固化依赖状态,传递 requirements 文件实现重现
pip freeze > requirements20250920.txt- 若不想重新部署,只需拷贝:
F:\PythonProjects\PaddleOCR\
包含 .venv 和 .paddlex 即可在同配置新机零配置运行。
🔑 核心总结
-
py310 仅做工具箱,不做开发
-
项目内
.venv是唯一开发环境 -
所有依赖、模型、工具链本地化,路径可控
-
requirements.txt 保证状态可复现