链家租房数据爬虫与可视化项目 Python Scrapy+Django+Vue 租房数据分析可视化 机器学习 预测算法 聚类算法✅
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机专业毕业设计选题大全(建议收藏)✅
1、项目介绍
技术栈:Python语言、Django框架、Scrapy爬虫、K-means聚类算法、线性回归预测算法、链家租房网数据、租房数据分析可视化系统、毕业设计
研究背景:租房市场信息复杂且动态变化,传统人工筛选租房信息效率低、主观性强。利用Scrapy爬虫实时抓取链家网租房多维度数据,结合Django+Vue构建前后端分离平台,集成数据分析与可视化模块,可在分钟级完成“爬取-存储-分析-大屏”闭环,为租客与房东提供低成本、高效率的量化决策工具。
研究意义:系统全程本地部署,保障数据隐私;模块化代码支持接入其他租房平台,适合作为“数据分析”“Web开发”课程实践与毕业设计模板,推动大数据在租房领域的教学落地与产业应用。
2、项目界面
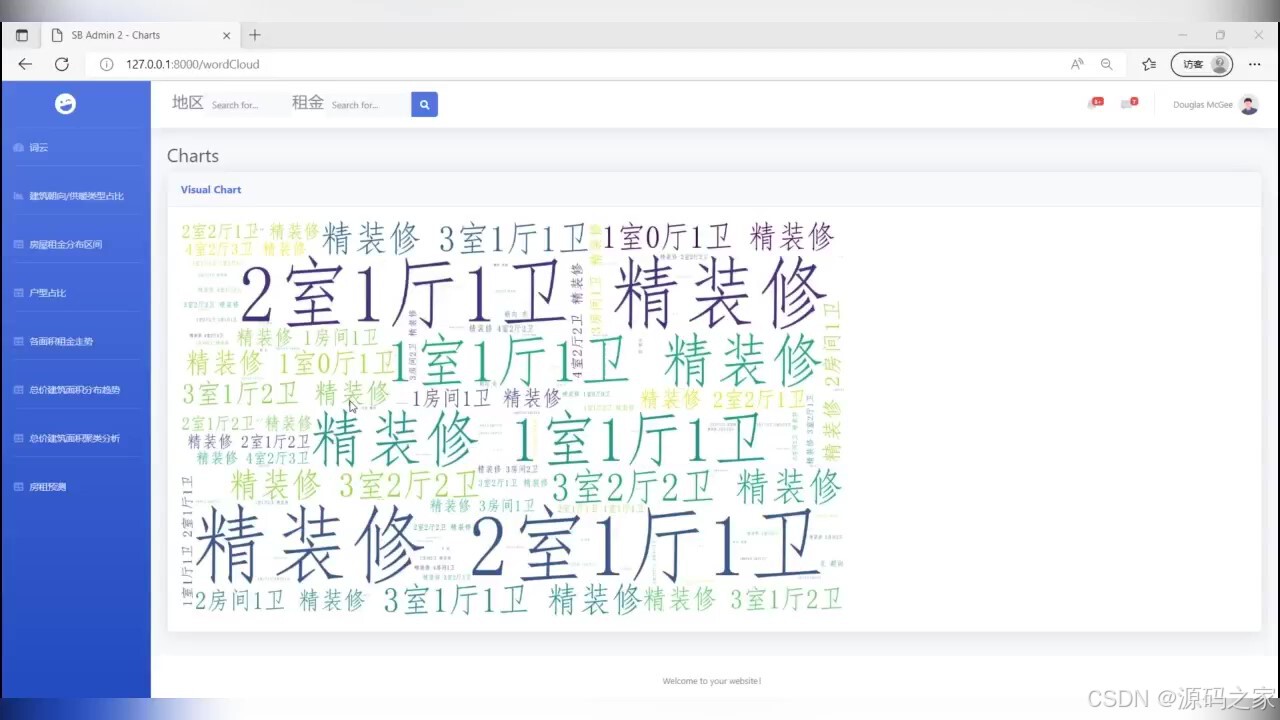
(1)词云图分析
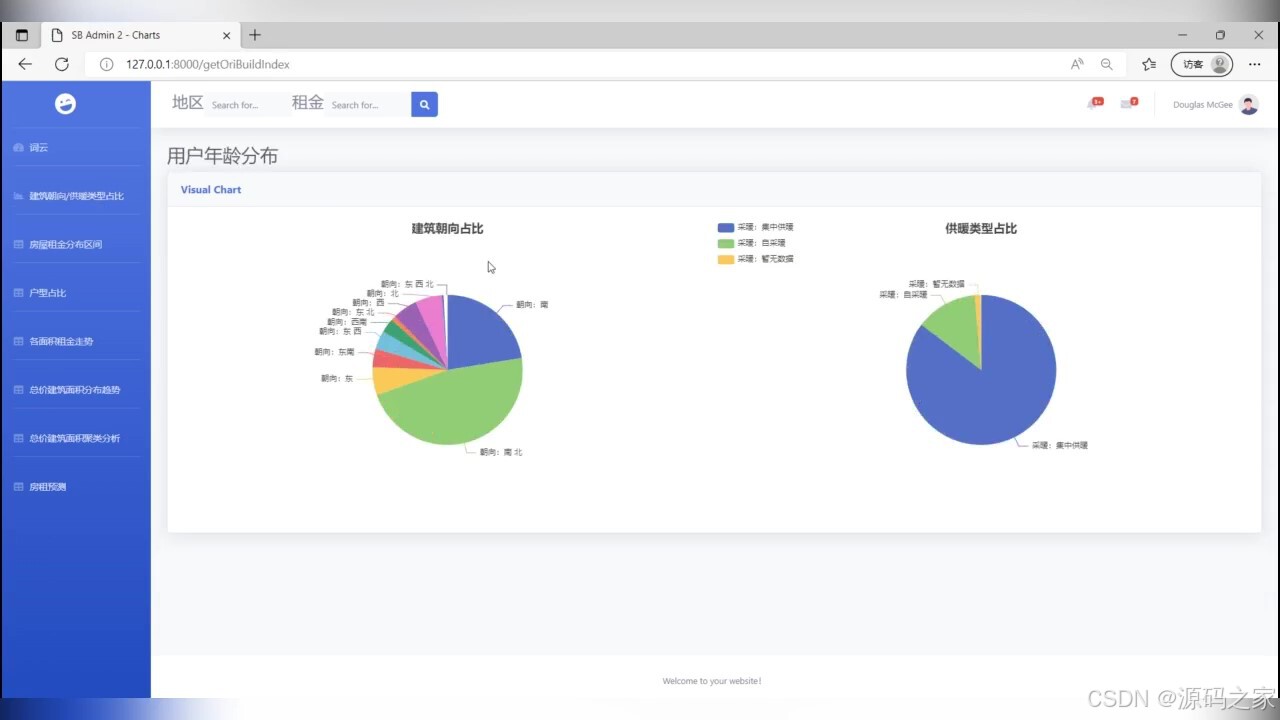
(2)用户年龄分布
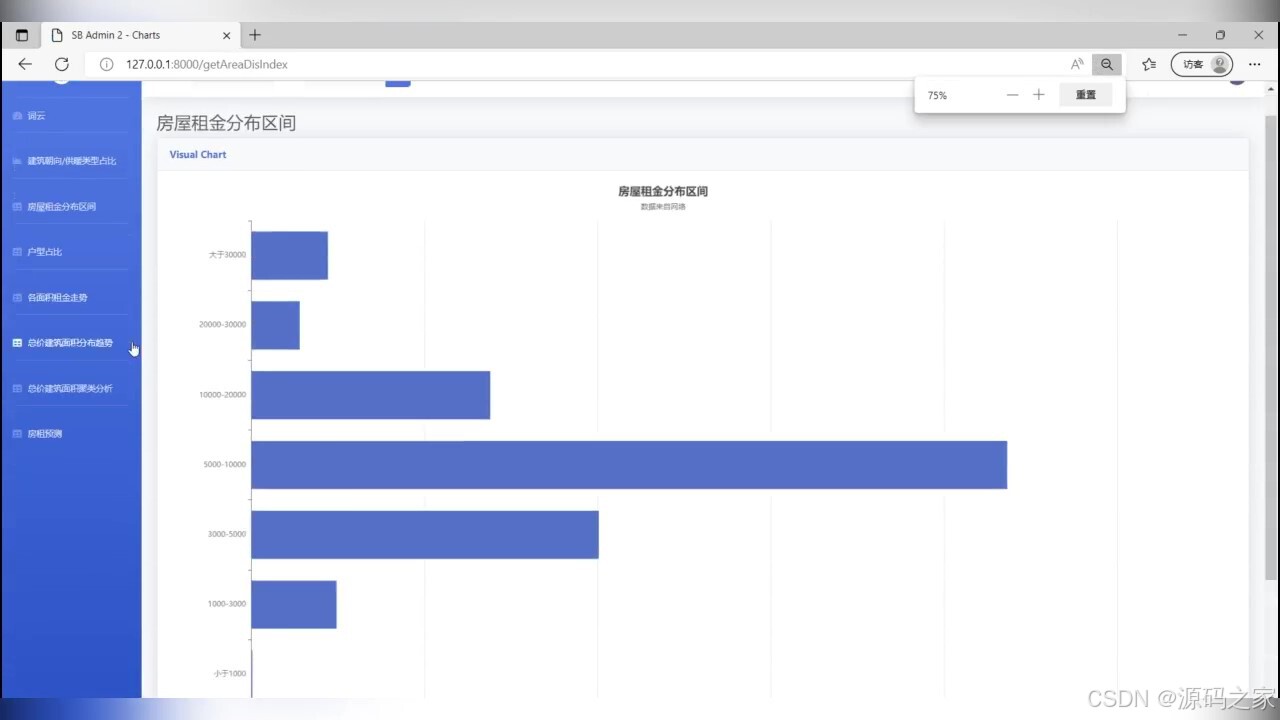
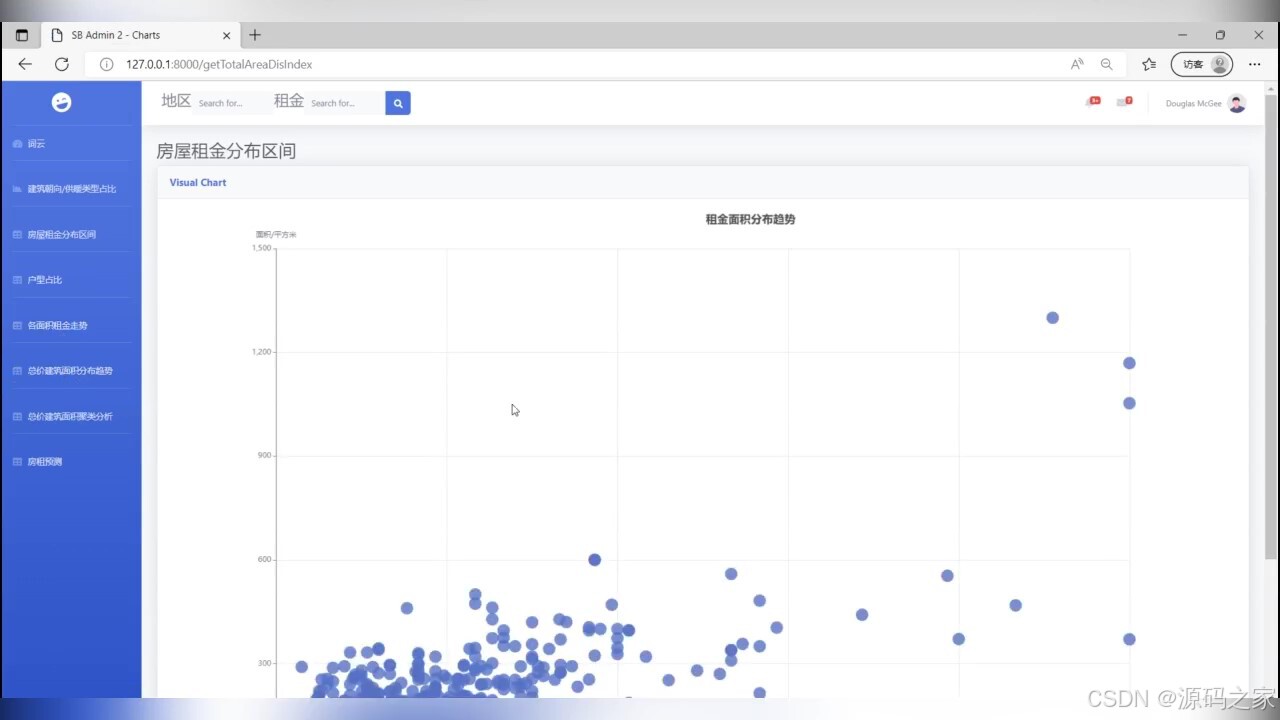
(3)房屋租金分布区间
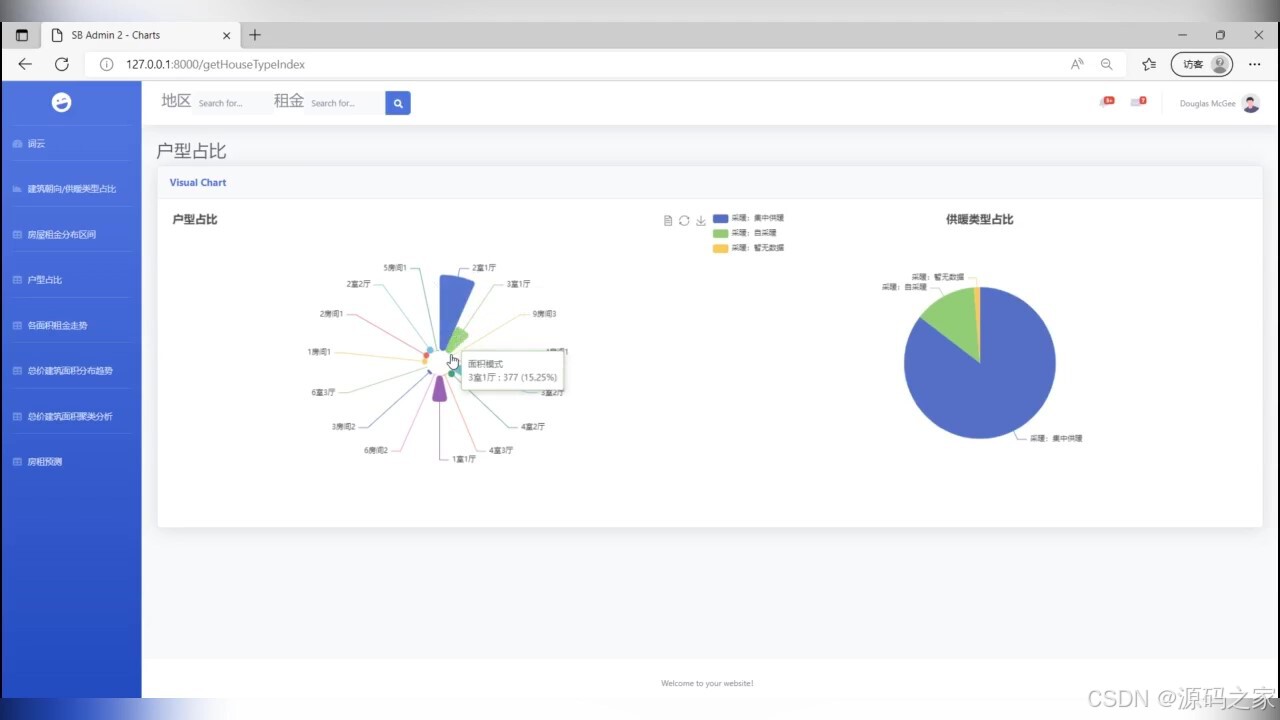
(4)户型占比
(5)房屋数据
(6)房屋租金分布区间散点图
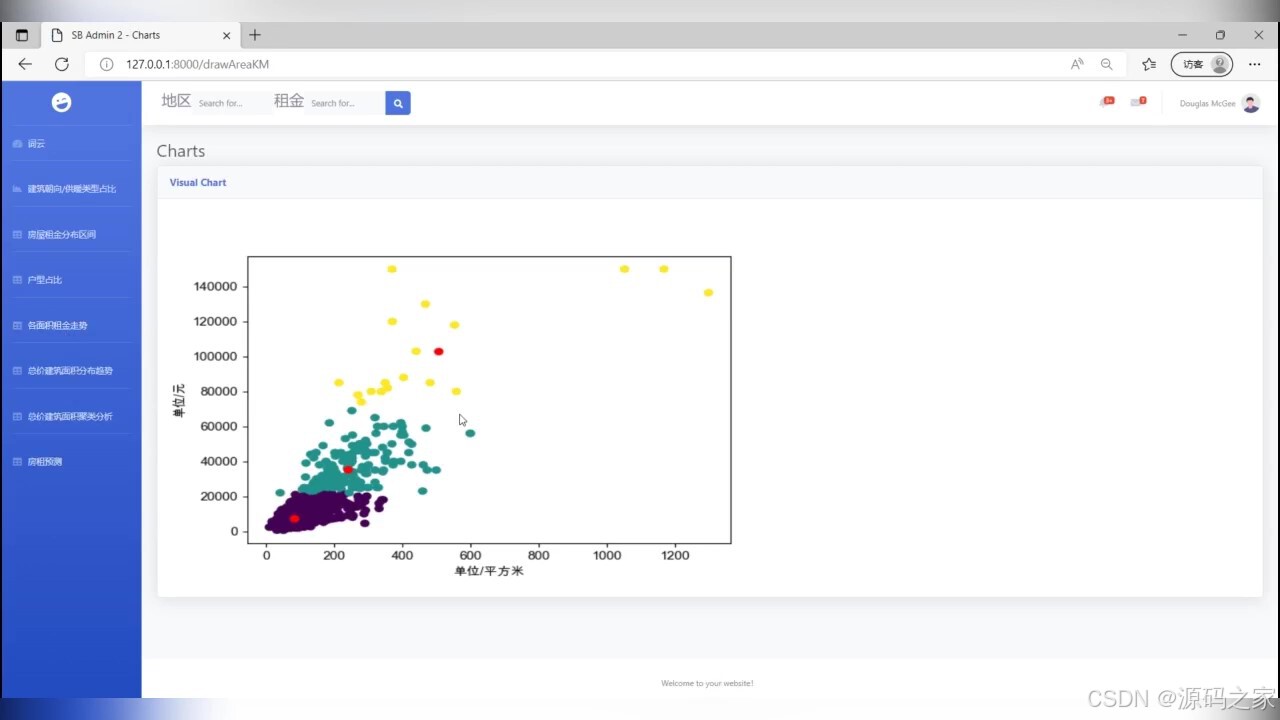
(7)聚类分布图
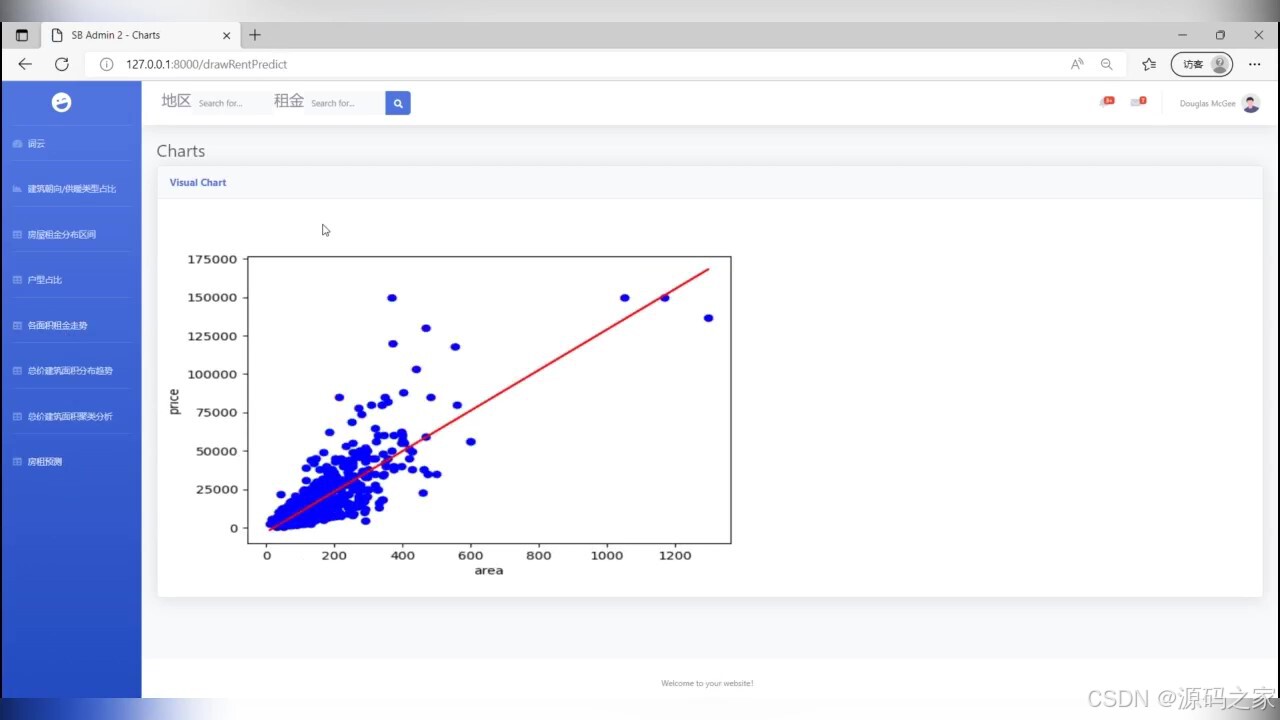
(8)预测分析
(9)数据爬取
3、项目说明
租房数据分析可视化系统采用Django+Vue前后端分离架构:Scrapy定时抓取链家网房源信息、租金、位置等多字段数据,经Pandas清洗后存入MySQL;后端利用Django REST Framework提供分页、搜索、筛选接口,前端Vue+Echarts实现租金分布柱状图、户型占比饼图、租金走势折线图、词云图等多维可视化,支持按区域、户型、租金区间动态联动刷新。
数据爬取模块采用“Scrapy+随机UA+代理池”方案,通过分布式任务调度绕过链家网反爬,增量写入确保数据时效性;清洗模块自动去除重复房源、填补缺失租金字段,保证数据质量。数据分析子模块按区域聚合租金中位数,揭示热门商圈租金波动;推荐系统基于用户浏览历史与收藏偏好,结合协同过滤算法实时推送匹配房源。
后台管理基于Django Admin二次开发,支持房源批量上下架、租金手动修正、爬虫任务启停及日志查看;权限分级为超级管理员与运营员两级,确保数据安全。搜索功能采用Whoosh全文索引,支持房源标题、小区名模糊查询,结果高亮显示,响应时间<200ms。分页与懒加载技术保障房源列表万级数据流畅展示。
系统全程本地运行,不依赖外网API,既保护数据隐私,又降低运维成本;代码开源且注释详尽,配套部署文档与演示数据,可作为“数据分析”“Web开发”课程实践案例,也可直接用于毕业设计、科研baseline,推动爬虫与可视化技术从理论走向生产,助力高校与企业快速构建属于自己的租房大数据平台。
4、核心代码
import pymysql
import re
import numpy as np
from numpy import *
from matplotlib import pyplot as pltdef load_data_set():dataSet = [] # 初始化一个空列表"""加载数据集"""conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='123456', db='lianjiarent',charset='UTF8')cur = conn.cursor()sql = "SELECT price,area FROM rent"cur.execute(sql)data = cur.fetchall()print(data)for i in data:temp = []price = i[0]area = i[1]pattern = re.compile('面积:(.*?)㎡')area2 = re.findall(pattern, area)if(area2==[]):temp.append(float(area[0]))else:temp.append(float(area2[0]))temp.append(float(price))dataSet.append(temp)print(dataSet)return dataSetdef distance_euclidean(vector1, vector2):"""计算欧氏距离"""return sqrt(sum(power(vector1-vector2, 2))) # 返回两个向量的距离def rand_center(dataSet, k):"""构建一个包含K个随机质心的集合"""n = shape(dataSet)[1] # 获取样本特征值# 初始化质心,创建(k,n)个以0填充的矩阵centroids = mat(zeros((k, n))) # 每个质心有n个坐标值,总共要k个质心# 遍历特征值for j in range(n):# 计算每一列的最小值minJ = min(dataSet[:, j])# 计算每一列的范围值rangeJ = float(max(dataSet[:, j]) - minJ)# 计算每一列的质心,并将其赋给centroidscentroids[:, j] = minJ + rangeJ * random.rand(k, 1)return centroids # 返回质心def k_means(dataSet,k,distMeas = distance_euclidean,creatCent = rand_center):"""K-means聚类算法"""m = shape(dataSet)[0] # 行数# 建立簇分配结果矩阵,第一列存放该数据所属中心点,第二列是该数据到中心点的距离clusterAssment = mat(zeros((m, 2)))centroids = creatCent(dataSet, k) # 质心,即聚类点# 用来判定聚类是否收敛clusterChanged = Truewhile clusterChanged:clusterChanged = Falsefor i in range(m): # 把每一个数据划分到离他最近的中心点minDist = inf # 无穷大minIndex = -1 #初始化for j in range(k):# 计算各点与新的聚类中心的距离distJI = distMeas(centroids[j,:],dataSet[i,:])if distJI < minDist:# 如果第i个数据点到第j中心点更近,则将i归属为jminDist = distJIminIndex = j# 如果分配发生变化,则需要继续迭代if clusterAssment[i,0] != minIndex:clusterChanged = True# 并将第i个数据点的分配情况存入字典clusterAssment[i,:] = minIndex,minDist**2print(centroids)for cent in range(k): # 重新计算中心点# 去第一列等于cent的所有列ptsInClust = dataSet[nonzero(clusterAssment[:, 0].A == cent)[0]]# 算出这些数据的中心点centroids[cent, :] = mean(ptsInClust, axis=0)return centroids, clusterAssmentdef draw():datMat = mat(load_data_set())myCentroids, clusterAssing = k_means(datMat, 3)plt.scatter(array(datMat)[:, 0], array(datMat)[:, 1], c=array(clusterAssing)[:, 0].T)plt.scatter(myCentroids[:, 0].tolist(), myCentroids[:, 1].tolist(), c="r")plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.xlabel("单位/平方米")plt.ylabel("单位/元")plt.savefig("../static/image/total.png")plt.show()if __name__ == '__main__':draw()
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻