【图像算法 - 26】使用 YOLOv12 实现路面坑洞智能识别:构建更安全的智慧交通系统
摘要: 在城市交通管理与自动驾驶领域,路面状况的实时感知至关重要。坑洞不仅影响驾驶舒适性,更可能导致爆胎、车辆损坏甚至交通事故。传统依赖人工巡检的方式效率低、成本高、覆盖不全。
关键词: YOLO12, 坑洞检测, 计算机视觉, 深度学习, PyTorch, OpenCV
【图像算法 - 26】使用 YOLOv12 实现路面坑洞智能识别:构建更安全的智慧交通系统
1. 引言:路面坑洞检测的挑战与AI的机遇
坑洞等是路面状况健康评估的关键指标,极易增大道路安全隐患。及时发现路面坑洞对于预防性维护至关重要。然而,传统的人工目视检查方法存在效率低、主观性强、危险性高等缺点。
在众多先进的模型中,YOLO12凭借其速度快、精度高、易于部署的特点脱颖而出。在保持YOLO系列高效推理速度的同时,实现了卓越的性能,非常适合部署在无人机、巡检机器人或边缘设备上进行实时检测。
本文将详细介绍如何使用 YOLO12 来训练一个路面坑洞智能识别模型。
2. 技术选型:为什么是YOLO12?
- YOLO12 (You Only Look Once 12): 由Ultralytics开发,是YOLO系列的最新迭代。它在架构上进行了优化(如Anchor-Free设计、更高效的Backbone和Neck),在速度和精度上取得了新的平衡。
- Ultralytics库: 提供了极其简洁的API,使得数据准备、模型训练、验证和推理变得异常简单,大大降低了开发门槛。
3. 数据准备:高质量标注是成功的关键
数据是深度学习的基石。对于路面坑洞,我们需要带有检测框的数据集。
3.1 数据集获取
- 公开数据集:
- 网络收集资源
- 自建数据集: 使用无人机、相机拍摄真实场景的路面坑洞图片,更具实际应用价值。

3.2 数据标注
- 工具推荐: LabelMe, CVAT, Roboflow。
- 标注要求: 为每一张图像中的每个路面坑洞绘制精确的矩形框。标注工具会生成对应的JSON或COCO格式的标注文件。
- 数据格式: YOLO12支持 COCO格式 或其自定义的 YOLO格式(文本文件,每行代表一个实例:
class_id center_x center_y width height。我们通常使用COCO格式。
3.3 数据集划分与组织 将数据集划分为训练集(train)、验证集(val)和测试集(test)。典型的划分比例是 70%:15%:15% 或 80%:10%:10%。
组织目录结构如下:
pothole/
├── images/
│ ├── train/ # 训练集图像
│ ├── val/ # 验证集图像
│ └── test/ # 测试集图像
└── labels/├── train/ # 训练集标签 (COCO JSON 或 YOLO txt)├── val/ # 验证集标签└── test/ # 测试集标签
3.4 数据增强 (Data Augmentation) Ultralytics YOLO在训练时默认应用了强大的数据增强策略(如Mosaic, MixUp, 随机旋转、缩放、裁剪、色彩抖动等),这有助于提高模型的泛化能力,防止过拟合,尤其在数据量有限时效果显著。
4. 模型训练:使用YOLO12
4.1 环境搭建
# 1. 安装PyTorch (根据CUDA版本选择)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118# 2. 安装Ultralytics
pip install ultralytics# 3. (可选) 其他依赖
pip install opencv-python matplotlib
4.2 配置文件 (data.yaml) 创建一个 pothole.yaml 文件,描述数据集路径和类别信息:
# 数据集路径
path: ./pothole # 数据集根目录
train: images/train # 训练集图像相对路径
val: images/val # 验证集图像相对路径
test: images/test # 测试集图像相对路径 (可选)# 类别信息
names:0: pothole # 类别名称,索引从0开始
4.3 开始训练 使用一行命令即可启动训练!Ultralytics提供了丰富的参数供调整。
from ultralytics import YOLO# 加载已训练的YOLO12
model = YOLO('yolo12n.pt') # 推荐使用s或m版本在精度和速度间平衡# 开始训练
results = model.train(data='pothole.yaml', # 指定数据配置文件epochs=100, # 训练轮数imgsz=640, # 输入图像尺寸batch=16, # 批次大小 (根据GPU显存调整)device=0, # 使用GPU 0, 多GPU用 [0, 1, 2]# 以下为可选高级参数# optimizer='AdamW', # 优化器# lr0=0.01, # 初始学习率# lrf=0.01, # 最终学习率 (lr0 * lrf)# patience=20, # EarlyStopping 耐心值# augment=True, # 是否使用Mosaic等增强 (默认True)# fraction=1.0, # 使用数据集的比例# project='my_projects', # 结果保存的项目目录
)
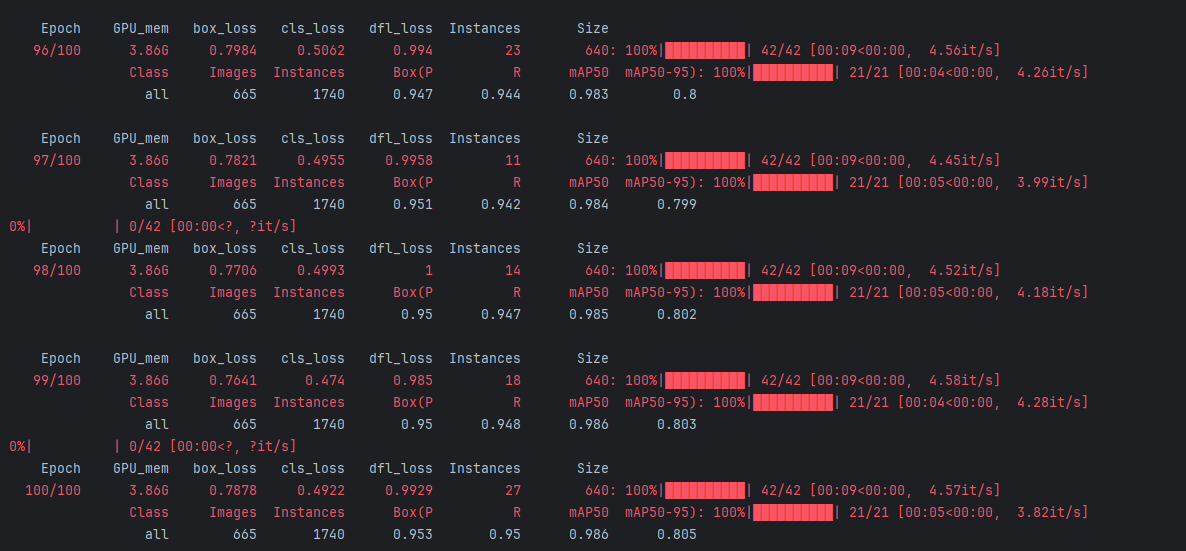

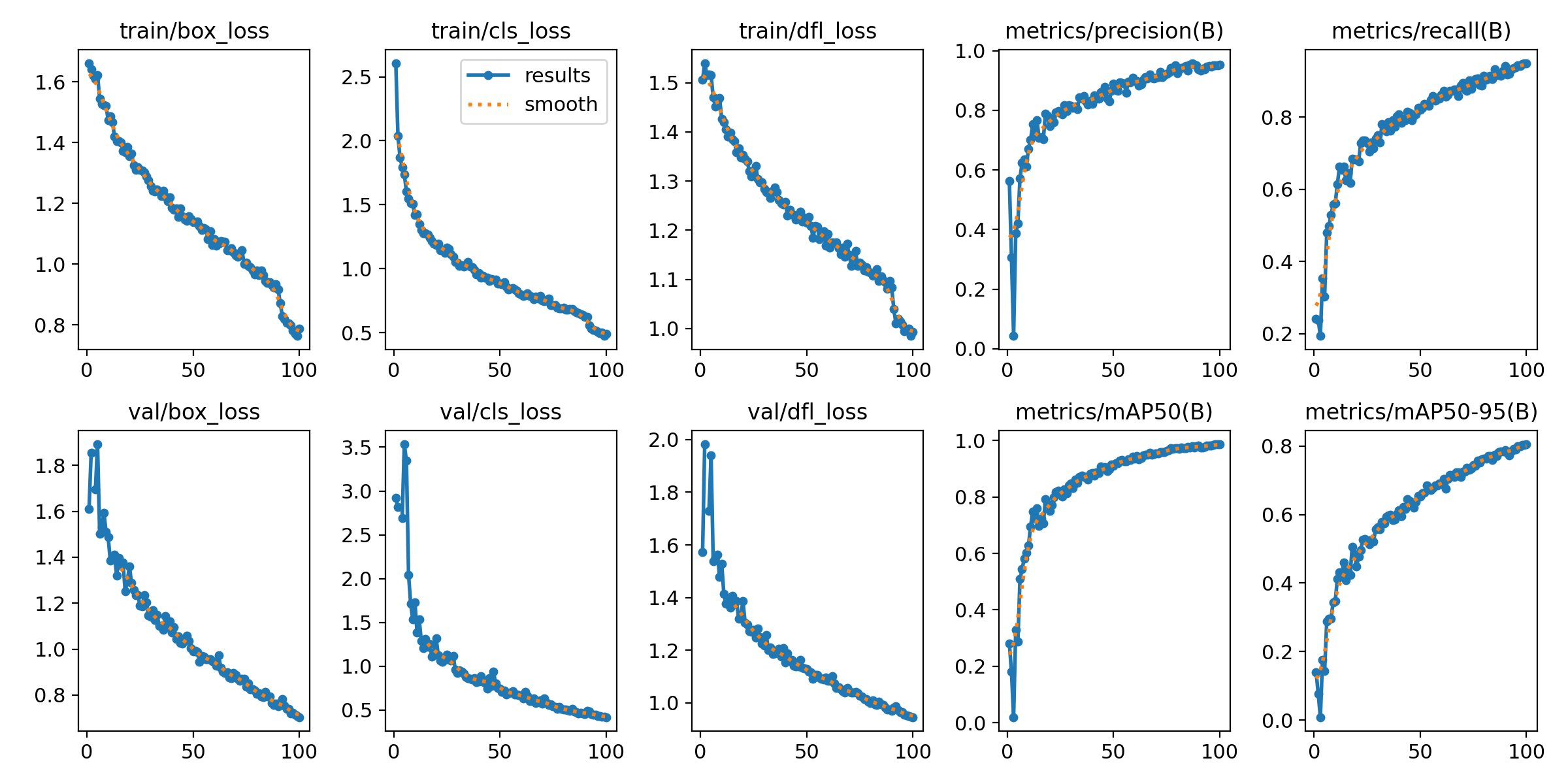
4.4 训练过程监控
- 训练过程中,Ultralytics会实时打印损失值(
box_loss,seg_loss,cls_loss,dfl_loss)和评估指标(precision,recall,mAP50,mAP50-95)。 - 在
runs/detect/xxx/目录下会生成详细的训练日志、指标曲线图(如results.png)和最佳权重文件(weights/best.pt)。
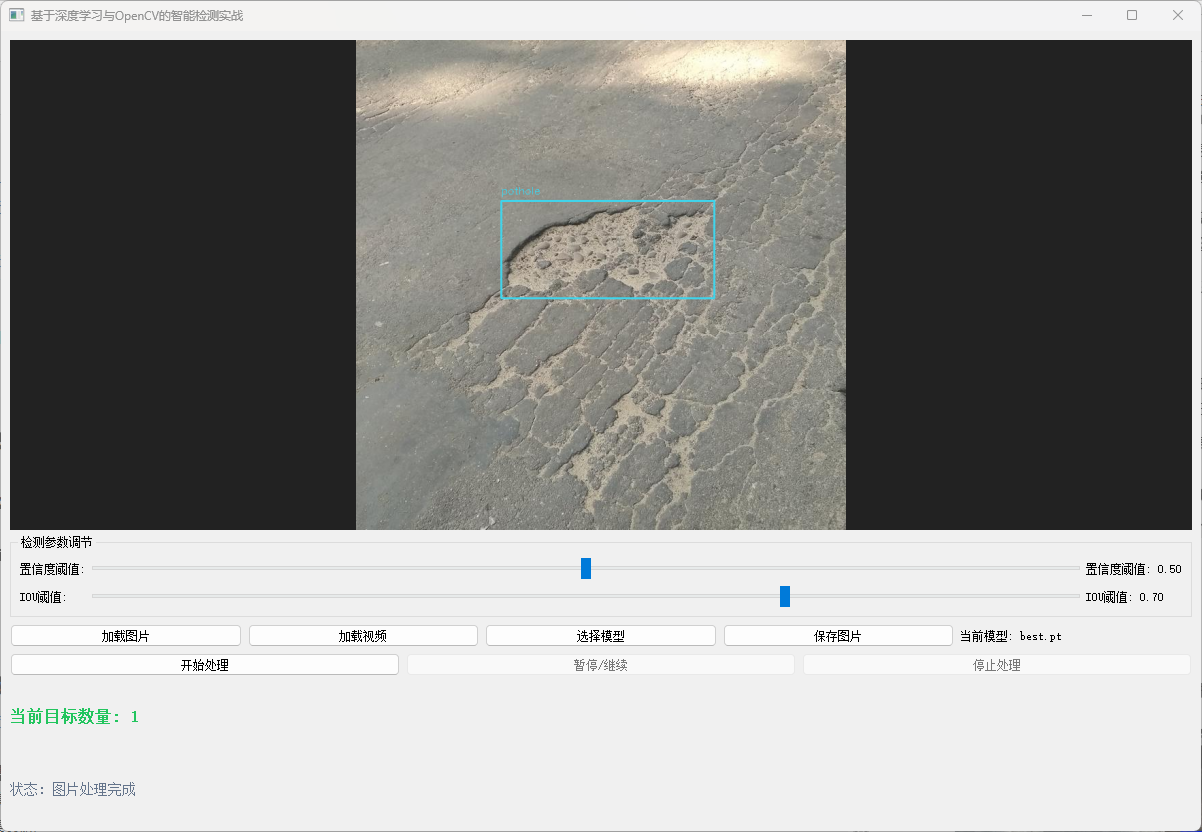
5. 模型验证与推理
5.1 验证模型性能 训练完成后,使用验证集评估模型:
# 加载训练好的最佳模型
model = YOLO('runs/detect/xxx/weights/best.pt')# 在验证集上评估
metrics = model.val()
print(metrics.box.map) # mAP50 for detection
print(metrics.seg.map) # mAP50 for segmentation
print(metrics.box.map50_95) # mAP50-95 for detection
print(metrics.seg.map50_95) # mAP50-95 for segmentation
5.2 进行推理 (检测新图像)
# 加载模型
model = YOLO('runs/detect/xxx/weights/best.pt')# 对单张图像进行预测
results = model('path/to/your/test_image.jpg', imgsz=640, conf=0.25) # conf: 置信度阈值# 结果可视化
for r in results:# 方法1: 使用Ultralytics内置的plot方法 (快速显示)im_array = r.plot() # 绘制边界框、标签im = Image.fromarray(im_array[..., ::-1]) # BGR to RGBim.show() # 显示图像



5.3 批量推理
# 对整个文件夹进行预测
results = model.predict(source='path/to/test_images_folder/', save=True, save_txt=True, imgsz=640, conf=0.25)
# save=True: 保存带标注的图像
# save_txt=True: 保存预测结果到txt文件 (可选)
6. 结果分析与应用
-
当前挑战:
- 阴影、积水、光照变化干扰检测
- 远距离小坑洞漏检
- 多坑洞密集场景误合并
-
优化建议:
- 引入多尺度测试(TTA)
- 使用CBAM或SimAM注意力模块
- 融合深度信息(双目摄像头/激光雷达)
- 在线学习机制,持续更新模型
-
应用场景拓展
- 市政道路巡检车自动上报
- 共享单车/网约车路况众包采集
- 自动驾驶车辆提前避障
- 保险行业定损辅助
- 城市数字孪生系统数据输入