Meta 开源 MobileLLM-R1 系列小参数高效模型,颠覆大模型竞赛
目录
前言:当所有人都向“大”,Meta选择了“小”
一、核心亮点:用十分之一的“口粮”,喂出更壮的“猛兽”
二、技术拆解:MobileLLM-R1的“三板斧”
2.1 第一板斧:精巧的架构——让“小个子”拥有强健骨骼
2.2 第二板斧:聪明的训练——三步走,榨干每一份数据
2.3 第三板斧:精准的定位——不做“万金油”,要做“手术刀”
三、性能实测:数据不会说谎
四、它也有“弱点”,但这恰恰是它的聪明之处
结语:一场关于“高效”的革命,AI正在走进你的口袋

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 Meta 开源 MobileLLM-R1 系列小参数高效模型
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言:当所有人都向“大”,Meta选择了“小”
近两年来,AI大模型的竞赛仿佛陷入了一个怪圈:参数量从百亿卷到千亿,再到万亿,模型体积越来越庞大,训练成本也节节攀升。大家似乎默认了一个规则——模型越大,能力就越强。
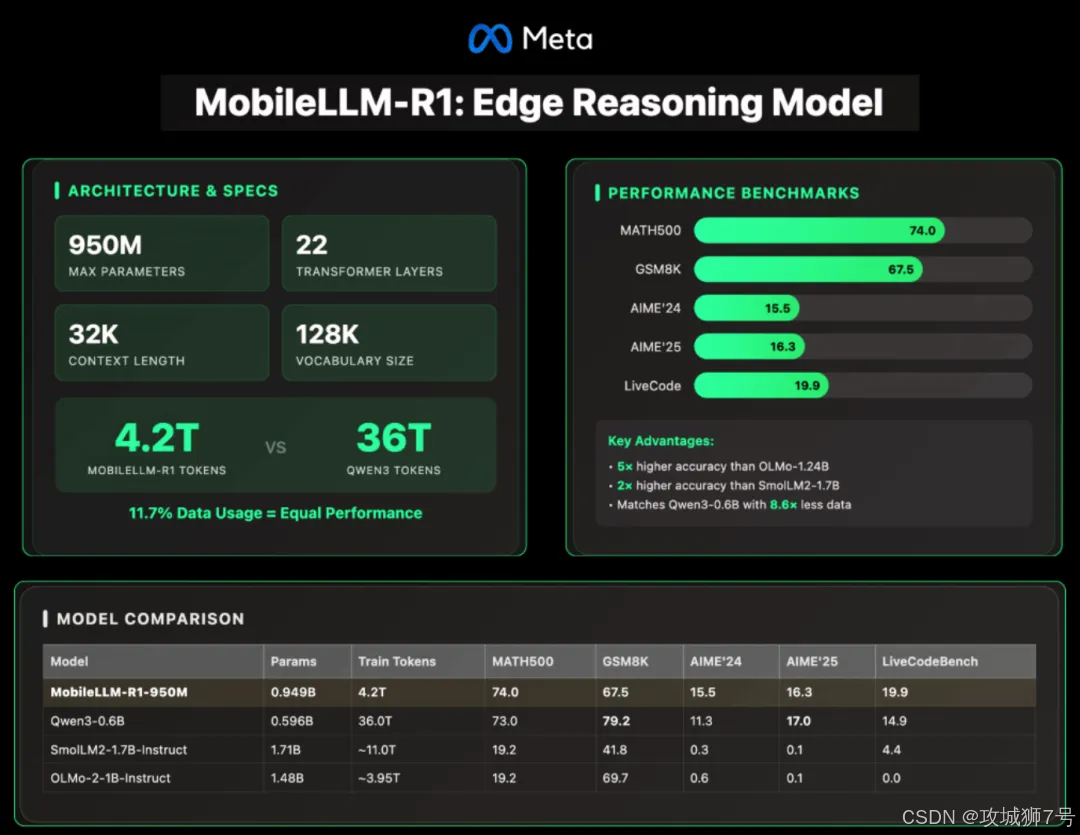
就在这场“军备竞赛”愈演愈烈之时,Meta AI 悄悄扔出了一枚“小炸弹”,彻底搅动了这池春水。他们开源了 MobileLLM-R1 系列模型,其中最大的版本参数量还不到10亿(950M)。
这并非一次简单的技术迭代,而是一次对主流路线的“反叛”。Meta似乎在用行动告诉整个行业:AI的未来,不只有“大而全”的巨无霸,更有“小而精”的特种兵。
一、核心亮点:用十分之一的“口粮”,喂出更壮的“猛兽”
MobileLLM-R1最令人震惊的,并非其“小”,而是其令人难以置信的“高效”。
要衡量一个模型的好坏,不仅要看它的最终能力,更要看它达到这个能力所付出的“代价”——也就是训练数据量。我们来看一组惊人的对比:
(1)Meta MobileLLM-R1-950M:总训练数据量不足5万亿(5T) tokens。
(2)阿里 Qwen3-0.6B:一款同样优秀的轻量化模型,训练数据量高达36万亿(36T) tokens。
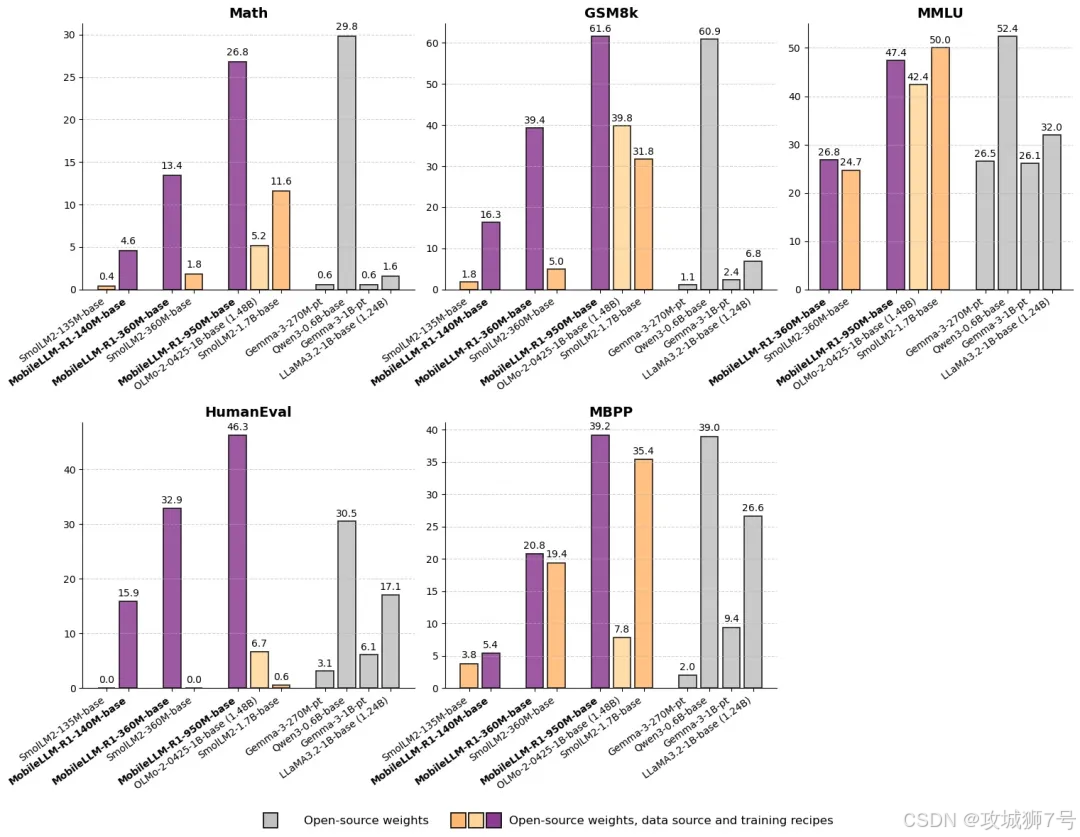
结果如何?在MATH(数学)、GSM8K(数学推理)、LiveCodeBench(编程)等多个高难度、专业化的基准测试中,MobileLLM-R1的表现与Qwen3-0.6B相当,甚至在某些项目上更胜一筹。
这意味着,Meta仅仅用了对手约十分之一的训练数据(或者说“口粮”),就喂出了一只同等强壮甚至更精悍的“猛兽”。这种极致的训练效率,直接意味着研发成本和时间的指数级下降,这对于整个AI生态来说,意义非凡。
二、技术拆解:MobileLLM-R1的“三板斧”
如此惊人的效率从何而来?MobileLLM-R1的成功并非偶然,而是源于其在架构、训练和定位上的三大核心创新。
2.1 第一板斧:精巧的架构——让“小个子”拥有强健骨骼
为了在有限的参数预算内实现最强的性能,Meta的工程师们对模型架构进行了精雕细琢。
(1)深窄化网络:不求宽但求深
传统的思路是,想让模型变强,就得把网络层做得更“宽”(增加隐藏层维度)。但MobileLLM-R1反其道而行,采用了“深窄化”的设计。比如其950M版本,拥有22层Transformer网络,通过增加网络深度而非宽度,来提升模型的语义表达和推理能力。事实证明,这条路走对了。
(2)GQA与权重共享:为效率“减负”
模型虽小,但每一分计算资源都得花在刀刃上。MobileLLM-R1引入了分组查询注意力(GQA)机制,允许多个查询头共享同一套“键值对”,大幅减少了推理时的计算量和内存占用。同时,相邻块权重共享技术,让模型在有效深度翻倍的情况下,推理延迟仅增加2.6%,堪称“四两拨千斤”的典范。
2.2 第二板斧:聪明的训练——三步走,榨干每一份数据
光有好的骨骼还不够,如何“喂养”才是关键。MobileLLM-R1采用了精心设计的“三阶段递进式”训练方案,确保每一份数据都被高效利用。
(1)第一阶段:通用预训练,打好语言基础
在初始阶段,模型会先学习约4万亿tokens的高质量通用语料(如网页、代码、数学文本等),目的是建立扎实的语言基础和世界知识。这是打地基的阶段。
(2)第二阶段:知识蒸馏,让小模型“拜师”大模型
这是最关键、最见功力的一步。Meta让MobileLLM-R1向自家的“老大哥” Llama-3.1-8B 模型学习。这个过程被称为“知识蒸馏”,就像一位经验丰富的老师傅,手把手地把自己的“内功心法”(推理逻辑、知识关联等)传授给小徒弟。通过这种方式,小模型能以极低的成本,高效吸收大模型的“智慧”,实现能力的跃迁。
(3)第三阶段:专项微调,打造“特种兵”
在吸收了通用知识和高级推理能力后,模型会进入最后的“特训”阶段。研究人员会用专门的数学、编程和科学推理数据集对它进行监督微调(SFT),让它在这些特定领域的能力得到极限强化,最终成为一名“特种兵”。
2.3 第三板斧:精准的定位——不做“万金油”,要做“手术刀”
MobileLLM-R1从诞生之初,目标就异常明确:它不是要成为一个什么都能聊的通用聊天机器人,而是要成为一个能在手机、物联网设备等终端上,高效解决数学、编程、科学推理等硬核问题的“专业工具”。
这种“术业有专攻”的策略,让它得以将宝贵的参数和训练资源集中在刀刃上,避免了在通用闲聊等任务上的能力浪费。正是这种精准的定位,才使其在专业赛道上展现出远超同体量通用模型的惊人表现。
三、性能实测:数据不会说谎
经过这三板斧的锤炼,MobileLLM-R1的实战能力如何?
在MATH基准测试中,它的准确率是同级别开源模型Olmo 1.24B的5倍,是SmolLM2 1.7B的2倍。
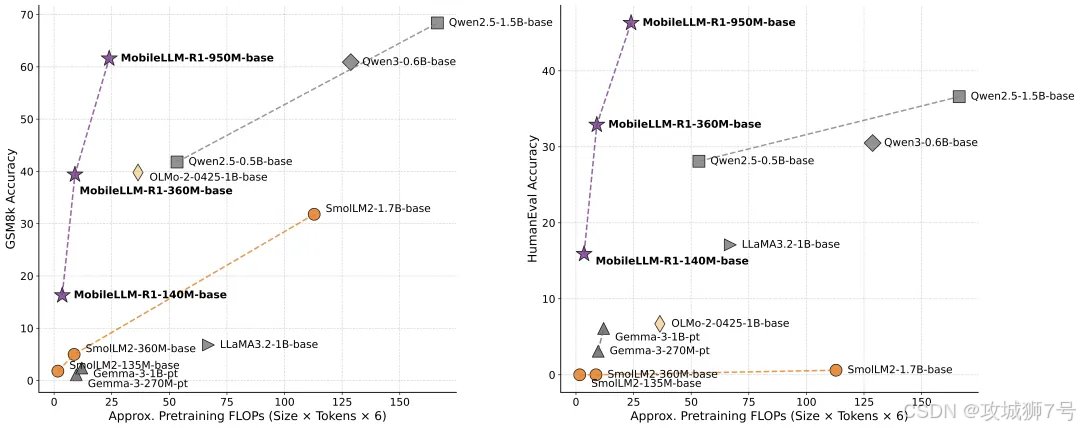
在LiveCodeBench编程测试中,它在Python和C++代码生成上的表现,远超其他同类开源模型,创下了新的纪录。
这些冰冷的数据背后,是一个清晰的事实:通过高效的训练和精巧的设计,小模型完全有能力在专业领域与那些消耗了数倍资源的大模型一较高下。
四、它也有“弱点”,但这恰恰是它的聪明之处
当然,MobileLLM-R1并非完美。如果你让它写诗、聊八卦或者进行开放式创作,它的表现会远不如GPT-4或Llama 3这样的大型通用模型。
但这并非它的缺陷,反而是其设计理念的体现。它放弃了成为“万金油”的幻想,专注于成为一把锋利的“手术刀”。对于那些需要在端侧设备上实现高效计算、代码解析或逻辑推理的应用场景(如智能计算器、工业设备诊断、离线编程助手等)来说,MobileLLM-R1无疑是近乎完美的选择。
结语:一场关于“高效”的革命,AI正在走进你的口袋
MobileLLM-R1的发布,为整个AI行业带来了深刻的启示:模型的未来,不应只有“越大越好”这一条路。
它用无可辩驳的成果证明了,“小而精”的路线同样大有可为。这场由Meta引领的,关于“效率”的革命,将深刻地改变AI技术的应用格局:
(1)降低门槛:极低的训练和部署成本,让中小企业和个人开发者也能玩得起高质量的AI。
(2)隐私安全:模型可以直接在本地设备上运行,敏感数据无需上传云端,从根源上解决了隐私顾虑。
(3)真正普及:轻量化的模型意味着AI能力可以被轻松塞进手机、汽车、智能手表乃至家里的冰箱里,实现真正的“AI Everywhere”。
由三位杰出华人科学家领衔打造的MobileLLM-R1,不仅是一次技术上的胜利,更是一次思想上的破局。它让我们看到,AI不再是遥远云端的数据中心里轰鸣的巨兽,而是即将走进我们每个人口袋里的,那个聪明、高效且可靠的私人助手。
体验链接:
HuggingFace:https://huggingface.co/collections/facebook/mobilellm-r1-68c4597b104fac45f28f448e
在线试用:https://huggingface.co/spaces/akhaliq/MobileLLM-R1-950M
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!