【PyTorch】梯度检查点 checkpoint 实现源码剖析
梯度检查点实现 PyTorch 源码解读
基于 pytorch-2.8.0/torch/utils/checkpoint.py
- 梯度检查点实现 PyTorch 源码解读
- 可重入实现(old)
- forward:正向
- backward:重建现场 + 重算 + 取梯度
- 非可重入实现(propose)
- 入口
- 生成器逻辑
_checkpoint_without_reentrant_generator - 环境状态捕获
_CheckpointFrame - 输入捕获
_NoopSaveInputs- 基类
- 实现
- 占位符
_Holder - 前向反向 Hook
_checkpoint_hook- 基类
- 前向实现
pack_hook - 重算 Hook
_recomputation_hook实现
- 时序图:前向 (Forward Pass)
- 时序图:反向 & 重计算 (Backward Pass)
- 时序图:
_Holder
- 其他的细节
- 简单使用示例
- 嵌套 checkpoint
- 可重入实现(old)
reentrant 是什么,为什么叫“可重入”
“reentrant(可重入)checkpoint” 的做法是:在前向阶段用 torch.no_grad() 运行被 checkpoint 的函数,不记录它的 autograd 计算图;等到反向阶段,autograd 引擎会“再次进入(re-enter)用户前向函数”,把这段前向重新跑一遍,用于重建需要的激活并继续求梯度。简单说:正向不记图,反向再“重入前向”重算。
“non-reentrant(非可重入)checkpoint” 则在正向时正常记图,并通过“已保存张量钩子”来在需要时只重建必要的中间量;因此它允许你在 checkpoint 区域内部也能再做一次 backward 等等,适配面更广。
之所以叫“可重入”,就是因为反向时会“重入”的前向函数去重算(而不是复用正向时记录的图)。当前更推荐 non-reentrant。
可重入实现(old)
在这不重点分析了
forward:正向
- 把
run_function、preserve_rng_state、推断出的 设备类型(cuda/cpu/其他)和 autocast 配置 缓存在ctx上。 - 若需要保存 RNG:保存 CPU RNG,并在已初始化的相应设备上(如 CUDA)保存每个参与的 device 的 RNG 状态(
get_device_states)。 - 仅把 Tensor 型输入通过
ctx.save_for_backward存起来,非 Tensor 输入保存在ctx.inputs,Tensor 在那里留一个None的占位,然后在torch.no_grad()下执行真正的前向,因此中间激活并不会入图保存。
backward:重建现场 + 重算 + 取梯度
- 首先检查兼容性:当
use_reentrant=True时,不允许使用.grad()或.backward(inputs=…)这种“显式指定输入”的反向路径,否则抛错;这是这条实现最重要的限制之一。 - 复原输入:把刚才保存的 Tensors 填回
ctx.inputs里的占位。 - RNG 恢复:用
torch.random.fork_rng把外部 RNG 状态备份一下,然后把 CPU RNG + 对应设备的 RNG 恢复到“前向当时”的状态。 - AMP/Autocast 恢复:根据 forward 时记录的设备与
cpu的 autocast 状态,分别进入相同的 autocast 上下文。 - 重算:对分离后的输入(
detach_variable,并保留requires_grad标志)调用run_function。这样会重新构建一张“临时前向图”。 - 喂入反向梯度:把
backward传进来的*args当作上游梯度,调用 Autograd 让它在这张“重算图”上做传播。
非可重入实现(propose)
不再在 Autograd 的 backward 回调里重跑前向,而是借助 Saved Tensor Hooks 控制“什么时候、如何重算出需要的中间张量”。
入口
非重入实现使用以下逻辑
@torch._disable_dynamo
def checkpoint(...):gen = _checkpoint_without_reentrant_generator(function, preserve, context_fn, determinism_check, debug, *args, **kwargs)# - Runs pre-forward logicnext(gen)ret = function(*args, **kwargs)# - Runs post-forward logictry:next(gen)except StopIteration:return retgen = _checkpoint_...(): 在checkpoint函数中,一个生成器对象gen被创建。此时,_checkpoint_...函数内的代码一行都未执行。next(gen)- 第一次迭代:- 前置工作
- 最重要的是进入了
with _checkpoint_hook(...)上下文管理器。 - 控制权返回到
checkpoint函数,next(gen)调用结束。
ret = function(...)- 核心执行:checkpoint函数现在调用用户传入的function。- 虽然这个调用发生在
checkpoint函数的作用域里,但由于上一步激活的_checkpoint_hook仍然“存活”在暂停的生成器中,这个钩子会对function的执行产生作用!它会拦截所有需要保存以备反向传播的张量,用一个轻量级的占位符_Holder替换它们,从而实现节省内存的目的。 function执行完毕,返回结果ret。
next(gen)- 第二次迭代:with _checkpoint_hook(...)语句块执行完毕,上下文管理器正常退出。- 执行清理代码。
_checkpoint_...函数执行到末尾,自然结束。
StopIteration:- 当一个生成器函数执行完毕时,它会自动引发一个
StopIteration异常。 checkpoint函数中的except StopIteration:捕获了这个异常,这标志着整个流程(前置-执行-后置)已经成功完成。- 函数返回
ret。
- 当一个生成器函数执行完毕时,它会自动引发一个
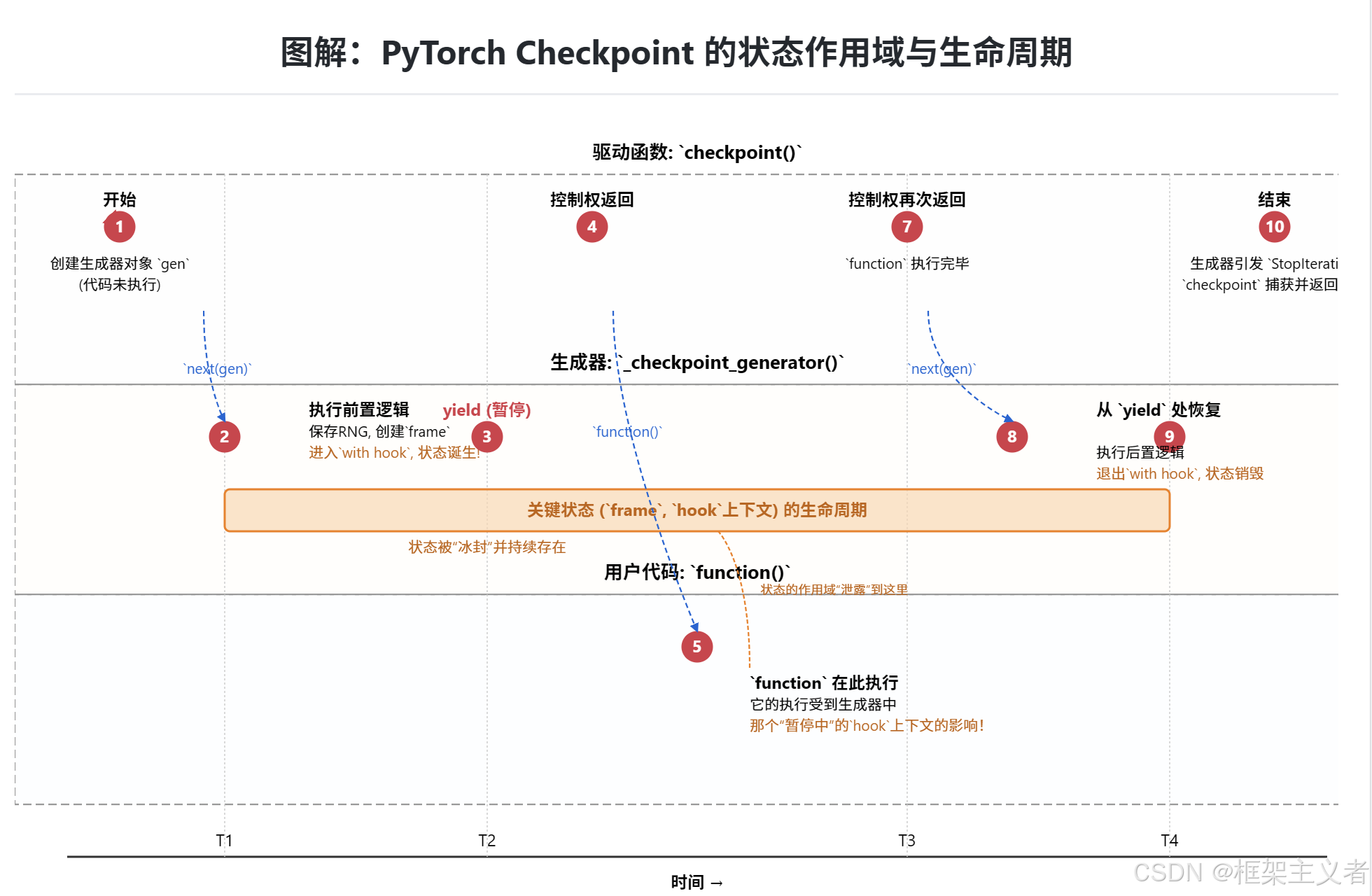
一般做法是将生成器转化为上下文管理器 contextlib.contextmanager。这里是反过来了。一个在生成器内部启动的上下文,其效果作用于生成器外部的函数调用
TorchDynamo 说明 TorchDynamo 不会进入utils.checkpoint函数内部进行分析。整个流程如下:可能的解释是:为了将“状态的生命周期”与“函数的执行”解耦:
checkpoint的设计巧妙地将状态的创建/销毁逻辑(在生成器中)与被该状态影响的核心业务逻辑(用户的function)分离开来。checkpoint函数作为“指挥官”,协调着两者的交互,但两者本身互不知晓对方的内部实现。这是一种高度内聚、低耦合的优雅设计。
当 TorchDynamo 遇到 utils.checkpoint 函数时,会尝试将其封装为一个高阶操作符(HigherOrderOp)。这个过程分为三个阶段:
- TorchDynamo 会先试探性地检查传入的前向传播函数是否可以安全地被追踪(即函数内部是否包含 Dynamo 支持的运算)。如果函数逻辑简单且符合追踪规范,则进入下一步。
- 如果前向传播函数被判定为安全,TorchDynamo 会将 utils.checkpoint 整体封装为一个高阶操作符,并将其加入生成的 Fx 计算图中。此时,Dynamo 不会深入分析 utils.checkpoint 内部的具体实现逻辑,而是将其视为一个不可拆分的原子操作。
- 如果前向传播函数无法被安全追踪(例如包含动态控制流或未知操作),TorchDynamo 会触发图中断(graph break),回退到 PyTorch 的急切模式(eager mode)执行。此时,@torch._disable_dynamo 装饰器会确保 Dynamo 不会对 utils.checkpoint 内部创建的计算帧再次触发优化流程。
生成器逻辑 _checkpoint_without_reentrant_generator
- 保存状态:保存 CPU 和 GPU 的随机数生成器状态,确保重计算时有完全相同的随机行为。
- 定义
recompute_fn:创建一个闭包,它知道如何使用保存的 RNG 状态和上下文来重新执行原始函数 fn。 - 创建
_CheckpointFrame:初始化一个状态对象,用于在前后向之间传递信息。 - 应用
_NoopSaveInputs.apply(dummy, *args),将所有输入 args “保存”到计算图中。这样在反向传播时,我们可以通过它的 grad_fn 访问到这些原始输入。 - 设置钩子:通过
with _checkpoint_hook(frame):激活我们的自定义保存行为。
# In torch.utils.checkpoint
def _checkpoint_without_reentrant_generator(fn, preserve_rng_state, ...):# =======================================================# "前置" 逻辑:在第一个 yield 之前执行# =======================================================# * 状态捕获# - 初始化错误回调# - 检查调试模式与上下文函数的兼容性# - 验证确定性检查参数:是否检查张量形状、类型、设备等。# - 推断设备类型并获取# - 生成前向与重计算上下文 默认没有 `noop_context_fn`# - 在编译模式 `_is_compiling` 下进行类型断言# - 获取自动混合精度的配置参数# - 保存随机数状态if preserve_rng_state:fwd_cpu_state = torch.get_rng_state()# ... and GPU states# 创建一个闭包,它知道如何使用保存的 RNG 状态和上下文来重新执行原始函数 fn。def recompute_fn(*inputs):...# 创建 `_CheckpointFrame` 一个状态对象,用于在前后向之间传递信息。new_frame = _CheckpointFrame(recompute_fn, ...)# * 输入捕获# 创建一个哑的 autograd.Function,用于在计算图中保存输入dummy = torch.empty((0,), requires_grad=True)new_frame.input_saver = _NoopSaveInputs.apply(dummy, kwargs, *args)# 本身没有 梯度环境的时候 自然不用if new_frame.input_saver.grad_fn is None:yieldreturn# * 创建一个钩子,并用 with 语句激活它# 这个 with 语句的生命周期将横跨整个生成器的暂停阶段with _checkpoint_hook(new_frame), forward_context:# =======================================================# 暂停点!控制权返回给 checkpoint 函数yield# in checkpoint fnuc: ret = function(*args, **kwargs)# =======================================================# =======================================================# "后置" 逻辑:在第二次 next() 调用时恢复执行# =======================================================# Debugging & 检查...# 函数自然结束,将会隐式地引发 StopIteration
环境状态捕获 _CheckpointFrame
# 创建 `_CheckpointFrame` 一个状态对象,用于在前后向之间传递信息。new_frame = _CheckpointFrame(recompute_fn, ...)
- 管理前向期间所有被 checkpoint 的张量(用弱引用占位符替代本体)。
- 调度和缓存反向期间的重计算结果,支持嵌套、多次 backward 等复杂场景。
- 支持提前终止重计算,提升效率。
- 元数据比对与 Debug 支持,强力保障模型梯度正确性。
- 通过 WeakKeyDictionary 等机制高效管理内存和生命周期,无需手动清理。
class _CheckpointFrame:def __init__(self, recompute_fn, early_stop, ... 用于异常和校验 ):"""recompute_fn: 封装了 如何重算前向区域 的函数闭包。注意它会复现原来的 RNG 状态、上下文环境等。early_stop: 是否允许在重计算时“提前终止”。如果为 True,只要所有需要的张量已重算出来就立即中断,节约计算。"""# - 如何重算前向区域的函数闭包self.recompute_fn = recompute_fn# - 用于保存前向区域的输入(包括张量和非张量)。# - 实际上会被赋值为 `_NoopSaveInputs.apply(dummy, kwargs, *args)` 的返回值。# - 它的 `.grad_fn` 可以在反向时恢复所有输入(见 unpack_hook 逻辑)。self.input_saver = None# - 存储每一个“被 checkpoint 机制保存的张量”的占位符 `_Holder` 的**弱引用**。# - 弱引用因为张量本体早已被释放,只要 Autograd 计算图清理了变量,这里的 `_Holder` 也会自动失效,无需手工管理生命周期。self.weak_holders: List[ReferenceType] = []# - 这是一个二级结构:# - 外层 key: `gid`,即当前反向传播过程的唯一 id(graph task id),防止多次 backward 混淆。# - 内层 value: `WeakKeyDictionary`,其 key 是 `_Handle`(每个张量占位符分配的唯一句柄),value 是重算出来的张量。# - 目的:支持高阶 backward(如 retain_graph=True 多次反向)或嵌套 checkpoint 时,不同的 graph task 能独立缓存各自的重计算张量。# - 为什么用 WeakKeyDictionary?方便垃圾回收,某些张量一旦用完即可释放。# We store this as a weakkeydictionary so that in the case of a partial# backward, the entries in the dict are cleared alongside the Holder# which will be removed when the SavedVariable is cleared.self.recomputed: DefaultDict[int, weakref.WeakKeyDictionary[_Handle, torch.Tensor]] = defaultdict(weakref.WeakKeyDictionary)# - 计数器,记录在某个 gid 下已经重算了多少个张量。用于 early stop 时判断是否所有张量都已生成。# We need both recomp_counter and recomputed since they can diverge# https://github.com/pytorch/pytorch/pull/90105#discussion_r1135889885self.recomp_counter: DefaultDict[int, int] = defaultdict(int)# - 标记:在某个 graph task id 下,frame 是否已经完成过一次重计算(防止重复重算,提高效率)。self.is_recomputed: DefaultDict[int, bool] = defaultdict(bool)# See Rule 5self.early_stop = early_stop# Debugging...
输入捕获 _NoopSaveInputs
No Operation Save Inputs:与 Autograd 计算图生命周期绑定的存储方式
- 问题:我们需要一种独立于 Python GC、与计算图生命周期同步的方式来保存
checkpoint的输入。 - 方案:我们不自己实现这个复杂的生命周期管理,而是“欺骗”并“利用”Autograd 引擎,让它来为我们做这件事。
- 实现:通过一个“空操作”的
autograd.Function,Autograd 引擎可以将张量的生命周期与计算图绑定。只要这个计算节点还在图中(即未来的反向传播还需要它),Autograd 就会确保save_for_backward保存的张量是可访问的。通过上下文对象ctx.saved_tensors把它们取回来
基类
torch.autograd.Function 是 PyTorch 中自定义自动微分逻的核心抽象类,用于突破默认自动微分(依赖计算图追踪)的限制,让开发者手动定义算子的前向传播(forward)与反向传播(backward,梯度计算)规则。
在这里我们需要的是借助 ctx 上下文对象保存张量
class _SingleLevelFunction(_C._FunctionBase, FunctionCtx, _HookMixin, metaclass=FunctionMeta
):@staticmethoddef forward(*args: Any, **kwargs: Any) -> Any:r"""定义自定义 autograd Function 的前向传播。这个函数需要被所有子类重写。定义 forward 有两种方式:用法 1 (合并 forward 和 ctx)::@staticmethoddef forward(ctx: Any, *args: Any, **kwargs: Any) -> Any:pass- 它必须接受一个上下文对象 ctx 作为第一个参数,后面跟着任意数量的参数(张量或其他类型)。- 更多细节请参见 :ref:`combining-forward-context`。用法 2 (分离 forward 和 ctx)::@staticmethoddef forward(*args: Any, **kwargs: Any) -> Any:pass@staticmethoddef setup_context(ctx: Any, inputs: Tuple[Any, ...], output: Any) -> None:pass- 此时 forward不再接受 ctx 参数。- 相反,你必须同时重写 :meth:`torch.autograd.Function.setup_context` 这个静态方法来处理 `ctx` 对象的设置。`output` 是 forward 的输出,`inputs` 是一个包含 forward 所有输入的元组(Tuple)。- 更多细节请参见 :ref:`extending-autograd`。上下文 `ctx` 可以用来存储任意数据,这些数据可以在反向传播过程中被取出。张量不应该直接存储在 `ctx` 上(尽管为了向后兼容目前没有强制执行)。相反,如果张量打算在 `backward` (等价于 `vjp`) 中使用,应该用 :func:`ctx.save_for_backward` 保存;如果打算在 `jvp` 中使用,则用 :func:`ctx.save_for_forward` 保存。"""raise NotImplementedError("你必须为自定义的 autograd.Function 实现 forward 函数。")@staticmethoddef setup_context(ctx: Any, inputs: tuple[Any, ...], output: Any) -> Any:r"""定义 autograd.Function 前向传播有两种方式。其中一种是:1. 使用 `forward(ctx, *args, **kwargs)` 签名来重写 forward。此时 `setup_context` 不需要被重写。为反向传播设置 ctx 的操作在 `forward` 内部完成。2. 使用 `forward(*args, **kwargs)` 签名来重写 forward,并同时重写 `setup_context`。此时为反向传播设置 ctx 的操作在 `setup_context` 内部完成(而不是在 `forward` 内部)。更多细节请参见 :meth:`torch.autograd.Function.forward` 和 :ref:`extending-autograd`。"""raise NotImplementedError("setup_context 未被实现。")@staticmethoddef backward(ctx: Any, *grad_outputs: Any) -> Any:r"""为该操作定义在反向模式自动微分下的求导法则。这个函数需要被所有子类重写。(定义这个函数等价于定义 `vjp` 函数。)它必须接受一个上下文 :attr:`ctx` 作为第一个参数,后面跟着与 :func:`forward` 返回值一样多的梯度输出(对于 forward 返回的非张量输出,这里会传入 None),并且它应该返回与 :func:`forward` 的输入一样多的张量。每个参数都是对应输出的梯度,而每个返回值应该是对应输入的梯度。如果某个输入不是张量,或者是一个不需要梯度的张量,你可以为那个输入直接返回 None 作为梯度。上下文 `ctx` 可以用来取回在前向传播中保存的张量。它还有一个属性 :attr:`ctx.needs_input_grad`,是一个布尔值的元组,表示每个输入是否需要梯度。例如,如果 :func:`forward` 的第一个输入需要计算梯度,那么在 :func:`backward` 中``ctx.needs_input_grad[0]`` 的值就会是 ``True``。"""raise NotImplementedError("为了在反向模式AD中使用你的自定义 autograd.Function,""你必须实现 backward 或 vjp 方法。")# vjp 和 backward 是彼此的别名vjp = backward # 反向模式求导(Vector-Jacobian Product)@staticmethoddef jvp(ctx: Any, *grad_inputs: Any) -> Any: # 前向模式求导(Jacobian-Vector Product)r"""为该操作定义在前向模式自动微分下的求导法则。"""class Function(_SingleLevelFunction):r"""用于创建自定义 `autograd.Function` 的基类。要创建一个自定义的 `autograd.Function`,需要继承这个类并实现:meth:`forward` 和 :meth:`backward` 这两个静态方法。然后,在前向传播中使用你的自定义操作时,调用类方法 ``apply``。不要直接调用 :meth:`forward`。为了确保正确性和最佳性能,请确保你在 ``ctx`` 上调用了正确的方法,并使用:func:`torch.autograd.gradcheck` 来验证你的 backward 函数。"""def __init__(self, *args, **kwargs): warnings.warn()def __call__(self, *args, **kwargs): raise RuntimeError()# 永远不要直接调用 MyFunction.forward(...)。要通过 MyFunction.apply(...) 来调用。@staticmethoddef vmap(info, in_dims, *args): raise NotImplementedError()# 提供了与 torch.vmap(自动向量化)集成的接口@classmethoddef apply(cls, *args, **kwargs):def bind_default_args(func, *args, **kwargs):signature = inspect.signature(func)bound_args = signature.bind(*args, **kwargs)bound_args.apply_defaults()return bound_args.argsis_setup_ctx_defined = _is_setup_context_defined(cls.setup_context)if is_setup_ctx_defined:args = bind_default_args(cls.forward, *args, **kwargs)if not torch._C._are_functorch_transforms_active():# 参见注意:[functorch vjp 和 autograd 交互]args = _functorch.utils.unwrap_dead_wrappers(args)return super().apply(*args, **kwargs) # type: ignore[misc]if not is_setup_ctx_defined:raise RuntimeError("为了将 autograd.Function 与 functorch 转换(vmap, grad, jvp, jacrev, ...)一起使用,""它必须重写 setup_context 静态方法。更多细节,请参见 ""https://pytorch.org/docs/main/notes/extending.func.html")return custom_function_call(cls, *args, **kwargs)def _is_setup_context_defined(fn):return fn != _SingleLevelFunction.setup_contex
以 y = x² 为例,手动实现前向与反向(反向梯度应为 dy/dx = 2x):
import torchclass SquareFunction(torch.autograd.Function):@staticmethoddef forward(ctx, x):# 前向计算:y = x²y = x ** 2# 保存反向所需的中间结果 xctx.save_for_backward(x)return y@staticmethoddef backward(ctx, grad_y):# 取出前向保存的 xx, = ctx.saved_tensors# 反向计算:输入梯度 = 下游梯度 * 2xgrad_x = grad_y * 2 * xreturn grad_x # 与 forward 输入数量一致(仅 x)# 使用方式:通过 apply 方法调用
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = SquareFunction.apply(x) # 前向
y.sum().backward() # 反向
print(x.grad) # 输出梯度:tensor([2., 4.]),符合 2x 的预期
自定义 Function 会被视为计算图中的一个“原子节点”:
- 前向时,
Function.apply(x)会在计算图中插入一个“自定义节点”,并通过ctx隐式关联前向数据与反向逻辑; - 反向时,Autograd 引擎遇到该节点,会直接调用其
backward方法,而非自动推导梯度。
实现
- 一个自定义的
autograd.Function。 - 它的
forward方法几乎什么都不做(No-op)。 setup_context使用ctx.save_for_backward把所有我们需要的输入保存起来。
class _NoopSaveInputs(torch.autograd.Function):@staticmethoddef forward(*args):# 这个 forward 方法本身是“空操作”的,它返回一个空的哑元张量,# 只是为了在计算图中留下一个节点。return torch.empty((0,))@staticmethoddef setup_context(ctx: Any, inputs: Tuple[Any, ...], output: Any) -> None:# 这个函数在 forward 之后、backward 之前被调用。# 它的职责就是设置反向传播所需的上下文 ctx。# `inputs` 是 .apply() 传入的完整参数元组,即 (dummy, kwargs, *args)# 1. 分离张量与非张量输入# `save_for_backward` 只能保存张量。其他类型的参数(如int, str, dict, None)# 必须直接保存在 ctx 对象上。tensor_indices, tensors = zip(*[(i, o) for i, o in enumerate(inputs) if isinstance(o, torch.Tensor)])# `idx2saved_idx` 是一个映射,用于后续从 saved_tensors 中恢复张量。# key是张量在原始 inputs 元组中的索引,value是它在 tensors 列表(即将被保存)中的索引。idx2saved_idx = {b: a for a, b in enumerate(tensor_indices)}# 2. 准备一个“模板”,用于恢复所有参数# 创建一个列表,其中张量被替换为 None 占位符,非张量保持原样。args = [None if isinstance(o, torch.Tensor) else o for o in inputs]# 3. 定义一个恢复函数 `get_args`,并将其挂载到 ctx 上def get_args(saved_tensors):# `saved_tensors` 是反向传播时,Autograd 提供的、当初保存的张量元组。# 遍历模板,用 `saved_tensors` 填充 None 占位符ret = [saved_tensors[idx2saved_idx[i]] if i in tensor_indices else ofor i, o in enumerate(args)]# `inputs` 的结构是 (dummy, kwargs, *args),我们只需要后面的 kwargs 和 *args# 所以返回切片 [1:]return ret[1:]ctx.get_args = get_args# 4. 最后,调用核心的保存方法# 将所有张量交给 Autograd 引擎保管。ctx.save_for_backward(*tensors)@staticmethoddef backward(ctx, *grad_outputs):# 我们永远不期望对 _NoopSaveInputs 的输出(那个哑元张量)进行反向传播。# 这个节点只是一个“数据胶囊”,不参与梯度计算。# 如果代码逻辑意外地走到了这里,说明有地方出错了,所以直接断言。raise AssertionError("Did not expect to backward on this graph")
# * 输入捕获# 创建一个哑的 autograd.Function,用于在计算图中保存输入dummy = torch.empty((0,), requires_grad=True)new_frame.input_saver = _NoopSaveInputs.apply(dummy, kwargs, *args)
torch.autograd.Function 是自定义可微操作的核心类,而 apply 方法是其唯一实例化调用入口,用于触发自定义操作的前向传播(forward)与后续反向传播(backward)逻辑
dummy: 这是一个需要梯度的张量(torch.empty((0,), requires_grad=True))。它的作用是确保_NoopSaveInputs这个操作被记录到计算图中。如果所有输入都不需要梯度,Autograd 引擎可能会优化掉这个节点,保存机制就会失效。kwargs,*args: 需要传递给用户函数fn的所有参数.apply(...): 执行时:_NoopSaveInputs.forward被调用,它接收(dummy, kwargs, *args)作为参数,然后返回一个空张量。_NoopSaveInputs.setup_context被调用,打包了所有args和kwargs,将张量部分交给ctx.save_for_backward,并创建了一个ctx.get_args函数用于未来的恢复。
new_frame.input_saver = ...:.apply()的返回值是一个张量,这个张量拥有一个.grad_fn属性,它指向一个代表_NoopSaveInputs反向节点的对象。这个对象内部就包含了我们设置好的ctx
图不一定连通:_NoopSaveInputs 形成了一个并行的、逻辑上的分支。虽然它不直接参与梯度计算流,但它通过 dummy.requires_grad=True 这个属性,作为一个有效的图节点存在。
在反向传播期间,checkpoint 内部的钩子 _checkpoint_hook 会被触发,这个钩子可以通过 new_frame.input_saver 找到这个 _NoopSaveInputsBackward 节点,并从中提取出保存的输入 x 来进行重计算。
# 在 unpack_hook 内部
def unpack_hook(holder):# ...# 从 frame 中取出这个“时空胶囊”ctx = frame.input_saver.grad_fn# 调用我们当初存下的恢复函数,传入从 Autograd 取回的被保存的张量original_inputs = ctx.get_args(ctx.saved_tensors)# 拿到了原始的所有输入!# 现在可以调用重计算函数了frame.recompute_fn(*original_inputs)# ...
占位符 _Holder
_Holder:保存张量的占位符对象(不是张量本体)。正向在saved_tensors_hooks(pack, unpack)的pack_hook中为每个需要“保存”的张量创建一个_Holder并把它塞回计算图里,真正的张量稍后在反向触发“重算”时再填充到缓存。_Holder内部维护一个handles: Dict[int, Optional[_Handle]],把一次前向里出现的保存位映射到对应的_Handle_Handle:每个“保存位”的键对象。帧级缓存用WeakKeyDictionary[_Handle, Tensor]存(key 是 _Handle,value 才是重算得到的真实 Tensor)。这样只要 _Handle 没有强引用(由 _Holder 持有的引用消失),缓存项就会自动被回收,适配“只做了部分反向”的情况。
_CheckpointFrame.weak_holders: List[ReferenceType].recomputed: DefaultDict[int, weakref.WeakKeyDictionary[_Handle, torch.Tensor]].recomp_counter: DefaultDict[int, int].is_recomputed: DefaultDict[int, bool]
class _Handle:"""它的实例被用作 `_CheckpointFrame.recomputed` 字典的键(key)"""passclass _Holder:def __init__(self):"""- 键 `int` 类型,代表 `gid` (graph_task_id),即当前反向传播任务的唯一ID。每次调用 `.backward()` 都会生成一个新的 `gid`。- 值 `Optional[_Handle]`。它是一个 `_Handle` 实例,作为在 `_CheckpointFrame.recomputed` 字典中查找重计算张量的键。当张量被解包使用后,这个值会被设为 `None`,以防止在同一次反向传播中被重复使用。"""self.handles: Dict[int, Optional[_Handle]] = {}
_Holder 的生命周期贯穿了检查点机制的三个关键阶段:前向传播(打包)、反向传播(解包与重计算)、以及状态清理。
阶段一:前向传播(打包 - Pack)
def pack_hook(x):holder = _Holder()frame.weak_holders.append(weakref.ref(holder))return holder
为什么是弱引用? Autograd 引擎会将 holder 实例保存在一个 SavedVariable 对象中。如果 retain_graph=False,反向传播结束后,SavedVariable 会被销毁,对 holder 的强引用就消失了。这时,如果没有其他地方强引用 holder,垃圾回收器就会回收它。
阶段二:反向传播(解包 - Unpack 与重计算)
当反向传播过程需要用到被 _Holder 替代的那个张量时,_checkpoint_hook 的 unpack_hook 会被调用。
def unpack_hook(holder):gid = torch._C._current_graph_task_id()if gid == -1: gid = int(uuid.uuid4())if not frame.is_recomputed[gid]:# ... (触发重计算的逻辑)with _recomputation_hook(weakref.ref(frame), gid), torch.autograd.enable_grad():frame.recompute_fn(*args)...# 标记重计算已完成frame.is_recomputed[gid] = True# 从 holder 中获取重计算结果的“钥匙” Handle_internal_assert(gid in holder.handles)if holder.handles[gid] is None:raise CheckpointError(...) # 防止重复解包handle_key = holder.handles[gid]# 使用 handle_key 从 frame.recomputed 字典中取出张量_internal_assert(handle_key in frame.recomputed[gid])ret = frame.recomputed[gid][handle_key]# 清理 handle,防止在同一次 backward 中被再次使用holder.handles[gid] = Nonereturn ret
_Holder 在重计算过程中的角色:
重计算由 _recomputation_hook 控制。它的 pack_hook 会在重计算过程中再次“保存”张量。
class _recomputation_hook(torch.autograd.graph.saved_tensors_hooks):def __init__(self, target_frame_ref: ReferenceType, gid: int):def pack_hook(x):# ... (一些索引和错误检查) ...# a. 通过弱引用获取原始的 _Holderholder = target_frame.weak_holders[recomp_idx]()if holder is not None:# b. 创建一个新的 _Handle 实例作为“钥匙”_internal_assert(holder.handles.get(gid, None) is None)holder.handles[gid] = _Handle()# c. 将重计算的张量 x 与“钥匙”关联起来,存入 frame.recomputedtarget_frame.recomputed[gid][holder.handles[gid]] = x# ... (提前停止逻辑) ...return x# ...
前向反向 Hook _checkpoint_hook
基类
saved_tensors_hooks 是一个上下文管理器(with 语句),用于定义张量在反向传播中被保存和读取时的自定义操作。
class saved_tensors_hooks:"""上下文管理器,用于为保存的张量设置一对打包 / 解包钩子。使用这个上下文管理器来定义操作的中间结果应该如何在保存前进行打包,并在检索时进行解包。在这个上下文中,每次操作保存一个张量用于反向传播时(这包括使用:func:`~torch.autograd.function._ContextMethodMixin.save_for_backward` 保存的中间结果,也包括由 PyTorch 定义的操作记录的张量),都会调用 ``pack_hook`` 函数。``pack_hook`` 的输出将被存储在计算图中,而不是原始张量。当需要访问保存的张量时(即在执行 :func:`torch.Tensor.backward()` 或:func:`torch.autograd.grad()` 时),会调用 ``unpack_hook``。它接收 ``pack_hook`` 返回的*打包后的对象*作为参数,并应返回一个与原始张量内容相同的张量(即在对应 ``pack_hook`` 中传入的张量)。钩子函数应具有如下签名:pack_hook(tensor: Tensor) -> Anyunpack_hook(Any) -> Tensor其中 ``pack_hook`` 的返回值应是 ``unpack_hook`` 的有效输入。通常,你希望 ``unpack_hook(pack_hook(t))`` 在值、大小、数据类型和设备上与 ``t`` 相等。示例::>>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_AUTOGRAD)>>> def pack_hook(x):... print("Packing", x)... return x>>>>>> def unpack_hook(x):... print("Unpacking", x)... return x>>>>>> a = torch.ones(5, requires_grad=True)>>> b = torch.ones(5, requires_grad=True) * 2>>> with torch.autograd.graph.saved_tensors_hooks(pack_hook, unpack_hook):... y = a * bPacking tensor([1., 1., 1., 1., 1.], requires_grad=True)Packing tensor([2., 2., 2., 2., 2.], grad_fn=<MulBackward0>)>>> y.sum().backward()Unpacking tensor([1., 1., 1., 1., 1.], requires_grad=True)Unpacking tensor([2., 2., 2., 2., 2.], grad_fn=<MulBackward0>).. warning ::在钩子的输入上执行原地操作可能导致未定义行为。.. warning :: <--- 会用到这个特性同一时间只允许使用一对钩子。当递归嵌套使用此上下文管理器时,只有最内层的一对钩子会被应用。"""def __init__(self,pack_hook: Callable[[torch.Tensor], Any],unpack_hook: Callable[[Any], torch.Tensor],) -> None:
checkpoint 继承:
class _checkpoint_hook(torch.autograd.graph.saved_tensors_hooks):def __init__(self, frame: _CheckpointFrame):def pack_hook(x): ...def unpack_hook(holder): ...super().__init__(pack_hook, unpack_hook)
前向实现 pack_hook
在前向传播时,当 Autograd 引擎想要保存一个大的中间激活张量时,_checkpoint_hook 会介入,阻止保存这个大张量,而是保存一个极小的“凭证”(placeholder)。
with _checkpoint_hook(new_frame), forward_context:yield# in checkpoint fnuc: ret = function(*args, **kwargs)
_checkpoint_hook 依赖于 _CheckpointFrame 来存储状态
依赖于 _Holder 作为返回给 Autograd 的占位符
_CheckpointFrame.weak_holders: List[ReferenceType] = [] # 占位符的弱引用列表
class _checkpoint_hook(torch.autograd.graph.saved_tensors_hooks):def __init__(self, frame: _CheckpointFrame):def pack_hook(x): # 参数 x: 需要丢弃的原始激活张量。# 原始的张量 x 的引用计数会减少。如果没有其他地方引用它,就会把它从内存中释放掉# _Holder 是一个空对象,它的实例在内存中的地址是唯一的。holder = _Holder()# 将占位符的弱引用存入 frameframe.weak_holders.append(weakref.ref(holder))# ... (可选) 保存元数据用于确定性检查# Autograd 把这个轻量级的 holder 保存在计算图中。return holderdef unpack_hook(holder):... # 后文
重算 Hook _recomputation_hook 实现
在反向传播时,当 Autograd 引擎需要这个张量来计算梯度时,_checkpoint_hook 再次介入。它接收到之前保存的“凭证”,意识到张量并不存在,于是立即触发一段“重计算”流程来重新生成这个张量,然后将新鲜出炉的张量交给 Autograd 引擎。
class _CheckpointFrame:def __init__(self, recompute_fn, early_stop, unpack_error_cb, metadata_fn):self.recompute_fn = recompute_fn # 知道如何重计算的函数self.input_saver = None # 保存了原始输入的哑函数self.weak_holders: List[ReferenceType] = [] # 占位符的弱引用列表# ...class _checkpoint_hook(torch.autograd.graph.saved_tensors_hooks):def __init__(self, frame: _CheckpointFrame):def pack_hook(x):... # 前文# 负责触发重计算。def unpack_hook(holder):# 参数 holder: 正是 pack_hook 中返回的那个占位符对象。# 1. 获取当前反向传播任务的唯一ID (Graph Task ID)。# 为什么需要这个?因为可能存在多次独立的 backward() 调用(例如,当# retain_graph=True 时)。gid 确保了每一次 backward() 都有自己# 独立的重计算上下文,避免互相干扰。gid = torch._C._current_graph_task_id()if gid == -1:# 如果不在一个标准的 backward 任务中(例如,直接调用 .grad()),# gid 可能为 -1。此时我们生成一个临时的 UUID 作为唯一标识。gid = int(uuid.uuid4())# 2. 检查当前 backward 任务是否已经执行过重计算。# frame.is_recomputed 是一个以 gid 为键的字典。# 这是一个重要的优化:对于同一次 backward(),整个 checkpointed 区域# 只需要重计算一次。当需要第一个被 checkpoint 的张量时,我们重计算# 整个区域,并把所有需要的张量都缓存起来。后续再需要这个区域的其他# 张量时,直接从缓存中取即可。if not frame.is_recomputed[gid]:# ---- 如果还没有重计算,那就现在----# a. 获取原始输入。# frame.input_saver 是前向传播时创建的 _NoopSaveInputs 的实例。# 它的 grad_fn 保存了 checkpointed 函数的所有原始输入。ctx = frame.input_saver.grad_fnargs = ctx.get_args(ctx.saved_tensors)try:# b. 激活“重计算钩子”并执行重计算。with _recomputation_hook(weakref.ref(frame), gid), torch.autograd.enable_grad():# c. 调用重计算函数。frame.recompute_fn(*args)except _StopRecomputationError: # d. (优化) 捕获提前终止信号。pass# e. 标记本次 backward 的重计算已完成。frame.is_recomputed[gid] = True# ... 检查与断言# ... 检查与断言# 3. 从缓存中获取重计算出的张量。ret = frame.recomputed[gid][holder.handles[gid]]# 4. 清理# 将句柄设为 None,防止重复解包。# 更重要的是,这也有助于及时释放内存。一旦张量被 Autograd 使用完毕,# 如果没有其他引用,这个清理操作有助于垃圾回收。holder.handles[gid] = None# 5. 返回真实的(重计算出的)张量return ret
为什么 _recomputation_hook 要单独设计?:如果用同一个 hook,就必须在 pack_hook 内加多层 if 来区分“我是 forward 还是 recompute”,还要避免 forward 阶段误存真实张量/重算阶段误产 Holder,逻辑会极度耦合与脆弱。而拆分成两个 hook,可以利用“上下文覆盖”这一特性,天然保证不会交叉污染。
class _recomputation_hook(torch.autograd.graph.saved_tensors_hooks):def __init__(self, target_frame_ref: ReferenceType, gid: int):# 构造函数接收两个关键参数:# 1. target_frame_ref: 一个对 _CheckpointFrame 实例的弱引用。# 这是它与 _checkpoint_hook 共享状态的唯一途径。# 使用弱引用是为了防止引用循环,确保资源可以被正常回收。# 2. gid: 当前反向传播任务的全局唯一ID。# 这保证了它捕获的张量会被存放在专属于本次 backward() 的 key 里,# 不会与其它并发或后续的 backward() 调用混淆。# 在重计算过程中,当 Autograd 尝试保存张量时,此函数被调用def pack_hook(x):# 参数 x: 在重计算过程中,由某个操作(如 matmul)产生,# 并且需要为后续操作(如 add)的反向传播而保存的真实张量。# 1. 分离张量的计算历史。# 我们只关心这个张量的“值”,不关心它在“重计算图”中的梯度历史。# 因为我们的目标是把这个值送回“原始计算图”去计算梯度。# .detach() 操作创建了一个共享底层数据但没有 autograd 历史的新张量。x = x.detach() if x.requires_grad else x# 2. 获取共享的状态机 frame。target_frame = target_frame_ref()assert target_frame is not None # appease mypy# 3. 获取并递增“重计算计数器”。# 这个计数器 (recomp_counter) 追踪在本次重计算中,这是第几个被保存的张量。# 它的顺序必须与原始前向传播中创建 _Holder 的顺序严格一致。recomp_idx = target_frame.recomp_counter[gid]target_frame.recomp_counter[gid] += 1# 4. 健壮性与确定性检查。# 如果重计算想要保存的张量数量超过了原始前向传播记录的数量if recomp_idx >= len(target_frame.weak_holders):assert not target_frame.early_stopif not target_frame.forward_completed:# We run into this case when early stop is not enabled and do# grad within checkpoint.# We need to set this flag, so we don't error out later when# we check if the number of tensors saved during forward and# recomputation match.target_frame.ignore_saved_mismatch = Truereturn xraise CheckpointError()# 5. 获取原始的占位符 _Holder。# 通过与计数器同步的索引,我们从 frame 中取出原始前向传播时# 创建的那个 _Holder 的弱引用。holder = target_frame.weak_holders[recomp_idx]()# 6. 建立“凭证 -> 真实张量”的映射关系。if holder is not None: # 检查 holder 是否已被垃圾回收# a. 在 holder 上为本次 backward(gid) 创建一个唯一的句柄 (_Handle)。_internal_assert(holder.handles.get(gid, None) is None)holder.handles[gid] = _Handle()# b. **核心操作**:将重计算出的张量 x 存入 frame 的缓存中。# 这个缓存是一个字典,键是刚刚创建的唯一句柄,值是张量 x。target_frame.recomputed[gid][holder.handles[gid]] = x# _checkpoint_hook.unpack_hook 通过 holder -> gid -> handle# 精确地找到这个刚刚被我们存进去的张量# 7. (优化) 检查是否可以提前终止重计算。# 如果已捕获的张量数量等于原始记录的数量,说明所有“债”都还清了。if target_frame.early_stop and target_frame.recomp_counter[gid] == len(target_frame.weak_holders):# 抛出特殊异常,这个异常会被 unpack_hook 的 try...except 块捕获,# 从而安全地跳出重计算函数,节省计算资源。raise _StopRecomputationError# 8. 返回张量 x,使得重计算过程中的后续操作可以正确执行。return x# 在重计算过程中,我们不希望再触发另一层嵌套的重计算def unpack_hook(x):return xsuper().__init__(pack_hook, unpack_hook)
时序图:前向 (Forward Pass)
sequenceDiagramparticipant C as checkpoint()participant G as _checkpoint_..._generatorparticipant Autograd as Autograd 引擎participant UserFunc as 用户 function()participant Hook as _checkpoint_hook%% ====================== 1. 准备阶段 ======================rect rgb(230, 247, 255)note over C: 开始执行 checkpoint() 函数C->>+G: gen = _checkpoint_..._generator(...)note right of G: 生成器对象被创建,代码<br/>此时一行都未执行。G-->>-C: 返回 gen 对象end%% ====================== 2. 前置设置与暂停 (关键阶段) ======================rect rgb(255, 243, 230)C->>G: next(gen)note right of G: 第一次唤醒:执行生成器的“前置”逻辑G->>G: 1. 保存RNG状态、创建 _CheckpointFrame (frame)note over G, Autograd: 2. 应用 _NoopSaveInputs 保存输入G->>Autograd: _NoopSaveInputs.apply(dummy, *args, **kwargs)note left of Autograd: Autograd 执行 _NoopSaveInputs 的<br/> `forward` 和 `setup_context`Autograd->>Autograd: a. 在计算图中创建 _NoopSaveInputsBackward (grad_fn) 节点Autograd->>Autograd: b. 将 *args, **kwargs 保存到该 grad_fn 节点中Autograd-->>G: 返回一个哑输出note right of G: 将这个 grad_fn 节点的引用<br/>保存在 frame.input_saver 中note over G, Hook: 3. 进入 `with _checkpoint_hook(frame)` 上下文G->>Hook: 激活 _checkpoint_hooknote right of Hook: 状态: **激活** <br/> (pack_hook 已准备就绪)note over G: 4. 到达 `yield`,暂停执行!G-->>C: 控制权返回给 checkpoint()end%% ====================== 3. 核心执行与钩子拦截======================rect rgb(232, 255, 232)note over C: 生成器已暂停,但其内部的<br/>`_checkpoint_hook` 仍然激活!C->>+UserFunc: ret = function(*args, **kwargs)note right of UserFunc: 开始执行用户代码...UserFunc->>UserFunc: e.g., y = op1(x)note over UserFunc, Autograd: Autograd 尝试为 op1 保存其输入 xUserFunc->>Autograd: (内部调用)note left of Autograd: 发现有激活的 saved_tensors_hooksAutograd->>Hook: 调用 pack_hook(x)note right of Hook: 丢弃张量,返回占位符Hook->>Hook: a. 创建 _Holder 占位符Hook->>Hook: b. 在 frame 中存入 holder 的弱引用Hook->>Hook: c. 丢弃对真实张量 x 的引用Hook-->>Autograd: d. 返回 _Holder 对象note left of Autograd: 收到并保存了轻量级的 _Holder,<br/>而非沉重的张量 x。内存节省达成!Autograd-->>UserFunc:UserFunc->>UserFunc: ...更多操作...UserFunc-->>-C: function 执行完毕,返回 retend%% ====================== 4. 恢复与清理 ======================rect rgb(255, 243, 230)note over C: 准备执行“后置”逻辑C->>G: next(gen)note right of G: 第二次唤醒:从 `yield` 之后恢复执行note over G, Hook: 5. 离开 `with _checkpoint_hook(...)` 上下文G->>Hook: 停用 _checkpoint_hooknote right of Hook: 状态: **非激活**G->>G: 6. 执行清理工作 (e.g., frame.forward_completed = True)note right of G: 7. 生成器函数执行完毕G-->>C: 抛出 StopIteration 异常end%% ====================== 5. 结束 ======================rect rgb(230, 247, 255)note over C: 捕获 StopIteration,表示流程正常结束C->>C: return retnote over C: checkpoint() 执行结束end时序图:反向 & 重计算 (Backward Pass)
sequenceDiagramparticipant User as 用户代码participant Autograd as Autograd 引擎participant UnpackHook as _checkpoint_hook.unpack_hookparticipant Frame as _CheckpointFrame (状态中心)participant Inputs as _NoopSaveInputs Backward (输入源)participant RecompHook as _recomputation_hookparticipant RecompFn as recompute_fn%% ====================== 1. 反向传播启动,遇到“凭证” ======================rect rgb(255, 235, 238)User->>Autograd: loss.backward()note over Autograd: 开始反向传播...Autograd->>Autograd: 遇到一个需要已保存张量 `x` 的节点note over Autograd: 从计算图中取出保存物,<br/>发现它是一个 `_Holder` 对象,而非 Tensor!note over Autograd: 检测到有 saved_tensors_hooks (unpack_hook)Autograd->>+UnpackHook: 调用 unpack_hook(holder)end%% ====================== 2. UnpackHook 协调重计算 (核心逻辑) ======================rect rgb(255, 248, 225)note over UnpackHook: 接收到 holder 凭证UnpackHook->>Frame: 检查 is_recomputed[gid] 是否为 Falsenote right of Frame: 状态: 首次请求,返回 Falsenote over UnpackHook, Inputs: **需要启动重计算!**<br/>第一步:获取原始输入。UnpackHook->>Frame: 获取 frame.input_saverUnpackHook->>Inputs: 从 grad_fn 节点中<br/>提取保存的 *args, **kwargsInputs-->>UnpackHook: 返回原始输入note over UnpackHook, RecompFn: 第二步:启动生产线 (recompute_fn)UnpackHook->>RecompHook: 激活 `with _recomputation_hook(...)`note right of RecompHook: 状态: **激活**<br/>(pack_hook 已准备就绪,开始“监工”)UnpackHook->>+RecompFn: 调用 recompute_fn(原始输入)end%% ====================== 3. 重计算执行,RecompHook 捕获张量 ======================rect rgb(232, 242, 255)note over RecompFn: 开始执行重计算...<br/>(内部逻辑与用户原始 function 一致)RecompFn->>RecompFn: e.g., y = op1(x)note over RecompFn, Autograd: 重计算图中的 Autograd 尝试保存 `x`RecompFn->>Autograd: (内部调用)note left of Autograd: 发现有激活的 hooks (RecompHook)Autograd->>RecompHook: 调用 pack_hook(x)note right of RecompHook: **执行“捕获与缓存”操作**RecompHook->>RecompHook: a. detach 张量 xRecompHook->>RecompHook: b. 创建唯一句柄 _HandleRecompHook->>Frame: c. 将 (handle -> x) 存入<br/> frame.recomputed[gid] 缓存RecompHook-->>Autograd: d. 返回原始张量 xnote left of Autograd: 收到 x,重计算图<br/>内部的反向传播得以正常进行Autograd-->>RecompFn:note over RecompFn: ...更多重计算操作...RecompFn-->>-UnpackHook: recompute_fn 执行完毕UnpackHook->>RecompHook: `with` 语句结束,停用 RecompHooknote right of RecompHook: 状态: **非激活**end%% ====================== 4. UnpackHook 返回结果,Autograd 继续 ======================rect rgb(224, 247, 224)note over UnpackHook, Frame: 第三步:完成收尾,提供“货物”UnpackHook->>Frame: 标记 is_recomputed[gid] = TrueUnpackHook->>Frame: 从 frame.recomputed[gid] 缓存中<br/>根据 holder 凭证找到张量 xFrame-->>UnpackHook: 返回重计算出的张量 xUnpackHook-->>-Autograd: 返回新鲜出炉的张量 xnote over Autograd: 成功拿到所需的张量!Autograd->>Autograd: 使用 x 计算梯度...Autograd->>Autograd: ...继续反向传播...end
时序图:_Holder
其他的细节
简单使用示例
import torch
from torch import nn
from torch.utils.checkpoint import checkpointclass Block(nn.Module):def __init__(self, dim):super().__init__()self.net = nn.Sequential(nn.Linear(dim, dim*4),nn.GELU(),nn.Linear(dim*4, dim))def forward(self, x):return self.net(x)class Model(nn.Module):def __init__(self, depth=12, dim=768):super().__init__()self.blocks = nn.ModuleList([Block(dim) for _ in range(depth)])def forward(self, x):for i, blk in enumerate(self.blocks):# 对每个 Block 开启激活检查点x = checkpoint(blk, x, use_reentrant=False)return xx = torch.randn(8, 768, requires_grad=True)
m = Model()
out = m(x)
loss = out.pow(2).mean()
loss.backward()
嵌套 checkpoint
源码中的解释:
注意 [ 可嵌套的检查点(Nestable Checkpoint)]
嵌套检查点的语义可以通过两个基本规则来定义。遵循这两个规则会引出一个重要的推论,该推论是设计动机的核心。
规则 1:保存的张量仅由最内层的检查点管理,并对所有外层检查点隐藏。
规则 2:内层检查点的输入被视为被保存到其父级检查点中的张量。
推论:
要重新计算任何一个给定的已保存张量,我们必须重新计算所有包裹它的检查点。
为什么这是必然的?
在反向传播中解包某个已保存张量X时,我们需要重新计算包含X的最内层检查点(根据规则 1)。而为了重新计算这个检查点,我们又需要它的输入,这些输入是由该检查点的父级检查点所管理的(根据规则 2),因此父级也必须先被重新计算。以此类推可以发现:为了成功解包X,所有在X被保存时处于激活状态的检查点都必须被重新计算(除非在当前反向传播过程中,由于其他张量的需求已经完成过这些重计算)。在实践中,我们使用一个无操作的自动微分函数(noop autograd Function)将输入作为“已保存张量”进行存储。在解包时调用
ctx.saved_tensor会触发父级检查点的重新计算。规则 3:开始重新计算时应假设当前没有任何检查点处于激活状态。但在重新计算过程中遇到的新检查点仍需被尊重。
当我们启动重新计算时,会在栈上压入一个专用于重新计算的“已保存变量钩子”(saved variable hook)。更多上下文请参见规则 6 中的示例。
除了上述针对嵌套检查点的基本语义之外,我们还施加了若干额外约束,这些约束可能普遍适用于检查点机制本身。
规则 4:重新计算出的张量的生命周期
重新计算出的张量只属于特定一次反向传播调用,在它们被解包后立即清除。
特别地,即使设置了retain_graph=True,我们也要求这样做。[规则 4 的实现细节]
如果我们允许在设置
retain_graph=True时让重新计算出的张量继续存活,那么我们可以将这些张量作为值存入一个WeakKeyDictionary(弱键字典),并将强引用打包为键。这样,在反向传播结束时,只要retain_graph=False,打包的键就会被清除,从而自动删除字典中的对应项。但如果我们希望在
retain_graph=True的情况下也能在解包时立刻清除重新计算出的张量,则不能依赖反向传播自动清除打包的键。取而代之的是:我们将强引用包装在一个容器对象中,并在解包时手动清空该容器。一个重要细节是:如果发生了第二次反向传播,第二次的重新计算需要重置该容器并创建一个新的键。
规则 5:一旦完成了所需张量的重新计算,就应立即停止重新计算过程。
[规则 5 的实现细节]
在重新计算期间,当已重新计算的张量数量达到预期目标数量时,抛出一个异常。我们在外部通过
try-catch捕获这一特定异常以提前终止执行。具体示例见下方规则 6。规则 6:支持在检查点上下文中执行反向传播
[保留图结构的情况:
retain_graph=True]def fn(x):y = x.sin()z = y.cos()gx, = torch.autograd.grad(z, x, retain_grad=True)return gx, zout = checkpoint(fn)(inp) out.backward()由于
z是在启用检查点的情况下由cos()保存的,它实际上不会被真正保存。因此内部的.grad()调用必须触发一次重新计算。在重新计算过程中,“内部打包钩子”有两个职责:
- 和通常一样,填充用于存储重新计算出张量的
WeakKeyDictionary;- 打包实际的张量(已分离),以便可以在重新构建的计算图上执行反向传播。这些被打包的张量将一直存在直到本次重新计算结束;或者更早地,如果有人以
retain_graph=False执行反向传播,则会被提前释放。更一般地说,在以下情况中会对重新构建的图执行反向传播:
- 如果在前向传播中执行了反向传播:
- 在原始前向传播期间(若未启用提前停止)
- 在原始反向传播期间
- 如果存在多个
.grad()或.backward()调用,即使启用了提前停止,我们也会对重新构建的图执行反向传播(见下例)[不保留图结构的情况:
retain_graph=False]下面的例子展示了:在重新计算过程中,如果我们发现某些试图重新计算的张量已经被清除会发生什么。
剧透:我们不做特殊处理,直接跳过它们!
def fn(x):y = x.sin() # (1)z = y.cos() # (2)gx, = torch.autograd.grad(z, x) # (3)return x.cos() * gx # (4)out = checkpoint(fn)(inp) out.backward() # (5)
- (1)(2):由于处于检查点内,不保存
x和y。- (3):触发
fn的重新计算,因为x和y未被保存。
根据是否启用提前停止,可能运行到 (2) 就停止,或继续执行下去。
因为此次反向传播使用了retain_graph=False,所以我们会清除x和y对应的持有者(holder)。- (4):仍在检查点内,不保存
x。- (5):调用
.backward()再次触发fn的重新计算。
在这次重新计算中,我们发现x和y在原图中的持有者已是None(已被清除),于是直接跳过它们。
但我们仍然会在 (4) 处保存x(因为此时它的持有者仍然有效)。
嵌套使用示例
假设 Block 内又想对子结构再切分:
class SubBlock(nn.Module):def __init__(self, dim):super().__init__()self.lin1 = nn.Linear(dim, dim)self.lin2 = nn.Linear(dim, dim)def forward(self, x):# 这里再嵌套一次def inner(y):return torch.relu(self.lin2(torch.relu(self.lin1(y))))return checkpoint(inner, x, use_reentrant=False)class OuterBlock(nn.Module):def __init__(self, dim):super().__init__()self.sub1 = SubBlock(dim)self.sub2 = SubBlock(dim)def forward(self, x):# 外层再 checkpoint 整体def big(y):y = self.sub1(y)y = self.sub2(y)return yreturn checkpoint(big, x, use_reentrant=False)
此时内层与外层是嵌套 checkpoint,反向时若只需要来自 big 内某一步保存的中间张量,会触发两层级联重算但利用“早停 + 不重复”逻辑最小化代价。