【论文阅读】One-Minute Video Generation with Test-Time Training
先看一篇介绍文章:无剪辑一次直出60秒《猫和老鼠》片段
文章链接:https://mp.weixin.qq.com/s/5KvV8gyxLUa2ssYJzHDzxQ
使用测试时训练的一分钟视频生成
卡兰·达拉尔4 丹尼尔·科切亚2 加什恩·侯赛因2 徐嘉瑞1,3 赵岳5 宋友进2 韩世豪1 张嘉俊1 简·考茨1 卡洛斯·奎斯特林2 桥本健典2 康米·科耶乔2
崔铉俊1 孙宇1,2 王晓龙1,3
NVIDIA3 斯福大学 加州大学圣地亚哥分校 加州大学伯克利分校 瑞克萨斯大学奥斯汀分校

在-个阳光明媚的早晨,纽约的汤姆,一只背着公交包的蓝色猫,来到世界贸易中心的办公室。当他安顿下来时,他的电脑突然关机了一次猫,一只淘气的棕色老鼠,咬断了线。一场追逐开始了,最后汤姆被捕,而杰瑞逃进了他的鼠洞。决心之下,汤姆冲进了一个办公室,杰瑞,一只淘气的棕色老鼠,咬断了线。一场追逐开始了,最后汤姆捕,而杰瑞逃进了他的鼠洞。决心之下,汤姆冲进了一个办公室,杰瑞,一只淘气的棕色老鼠,咬断了线。一场追逐开始了会议,他愤怒地将它赶走。在舒适的鼠洞里,杰瑞嘲笑这场混乱。

杰瑞在整洁的厨房里开心地吃奶酪,直到汤姆俏皮地把它拿走,逗他。杰瑞生气地打包行李离家,拖着一个小手提箱。后来,汤姆注意到杰瑞不见了,感到难过,跟着杰瑞小小的脚印一直到了旧金山。杰瑞沮丧地坐在一条小巷里,汤姆找到他,温柔地递上一块奶酪作为道歉。杰瑞原谅了汤姆,接受了奶酪,两人一起回家,友谊得以恢复。
图1。TTT层使预训练的扩散Transformer能够从文本故事板生成一分钟的视频。我们使用汤姆和杰瑞卡通片作为概念验证。视频讲述复杂的故事,由动态运动组成的连贯场景。每个视频都是由模型一次性直接生成,无需编辑、拼接或后期处理。每个故事都是新创作的。
摘要
Transformers如今仍然难以生成一分钟视频,因为自注意力层在长上下文中效率低下。Mamba层等替代方案在处理复杂多场景故事时也面临挑战,因为它们的隐藏状态表达能力较弱。我们实验了测试时训练(TTT)层,其隐藏状态本身可以是神经网络,因此更具表达能力。将TTT层添加到预训练的Transformer中,使其能够从文本故事板生成一分钟视频。为了验证概念,我们基于《汤姆和杰瑞》卡通片构建了一个数据集。与Mamba2、GatedDeltaNet和滑动窗口注意力层等基线相比,TTT层生成的视频更加连贯,能够讲述复杂的故事,并在人类评估中每方法100个视频的评分上领先34个Elo分数。
在人类评估中每方法100个视频的评分上领先34个Elo分数。尽管前景光明,但结果仍存在伪影,可能由于预训练5B模型的能力有限。我们的实现效率也可以进一步提高。由于资源限制,我们仅实验了一分钟视频,但该方法可以扩展到更长的视频和更复杂的故事。
示例视频、代码和注释可在以下网址获取:https://test- time- training.github.io/videos- dit
1.简介
尽管在视觉和物理真实感方面取得了显著进展,最先进的视频Transformer仍然主要生成单个场景的短片段,而没有复杂的故事。在撰写本文时(2025年3月),视频生成公共API的最大长度为:Sora(OpenAI)20秒,MovieGen(Meta)16秒,Ray2(Luma)10秒

图2。所有RNN层都可以表示为一个根据更新规则转换的隐藏状态。[43]中的关键思想是使隐藏状态本身成为一个带有权重 WWW 的模型 fff ,而更新规则是对自监督损失的梯度步。因此,在测试序列上更新隐藏状态相当于在测试时训练模型 fff 。这个过程称为测试时训练(TTT),它被编程到TTT层中。图和标题取自[43]。
(Ve02(Google))8秒。这些API都无法自主生成复杂的跨场景故事。
这些技术限制背后的一个基本挑战是长上下文,因为Transformer中的自注意力层的成本随着上下文长度的增加呈平方级增长。这个挑战对于具有动态运动的视频生成尤其尖锐,其上下文无法通过分词器轻松压缩。使用标准分词器,我们每个一分钟的视频需要超过 300k300\mathrm{k}300k 个上下文标记。使用自注意力机制,生成一分钟的视频将比生成20个3秒的视频花费 11×11\times11× 更长的时间,训练也将花费 12×12\times12× 更长的时间。
为了应对这一挑战,最近关于视频生成的研究调查了RNN层作为自注意力机制的高效替代方案,因为它们的成本随着上下文长度的增加呈线性增长[47]现代RNN层,尤其是线性注意力[23,37]变体的Mamba[8,12]和DeltaNet[35,53],在自然语言任务中表现出色。然而,我们尚未看到由RNN生成的具有复杂故事或动态运动的长视频。[47]中的视频(链接)具有高分辨率且为一分钟长,但只包含单个场景和慢动作,更不用说复杂的故事了。
我们相信这些RNN层生成的视频更简单,因为它们的隐藏状态表达能力较弱。RNN层只能将过去的token存储到固定大小的隐藏状态中,这仅是一个用于线性注意力变体(如Mamba和DeltaNet)的矩阵。将数十万个向量压缩到只有数千个秩的矩阵中本身就具有挑战性,因此,这些RNN层难以记住远处token之间深层的关系。
我们实验了一种替代的RNN层类,其隐藏状态本身可以是神经网络。具体来说,我们使用了两层MLP,其隐藏单元数量和非线性比线性(矩阵)隐藏状态在线性注意力变体中更多。由于神经网络隐藏状态即使在测试序列上也会通过训练进行更新,因此这些新层被称为测试时训练(TTT)层[43]。
我们从预训练的扩散Transformer(CogVideo- X5B[19])开始,该模型只能生成3秒的短片段,帧率为16fps(或6秒,帧率为8fps)。然后,我们添加从零初始化的TTT层,并微调此模型以从文本故事板生成一分钟的视频。我们将自注意力层限制在3秒的片段内,以保持其成本在可控范围内。仅通过初步的系统优化,我们的训练运行在256个H100上相当于50小时。
我们基于 ≈7\approx 7≈7 小时汤姆和杰瑞卡通片和人工标注的故事板,构建了一个文本到视频的数据集。我们有意将研究范围限制在这个特定领域,以便快速迭代。作为一个概念验证,我们的数据集强调复杂、多场景和长距离的故事,其中动态运动仍需改进;而在视觉和物理真实性方面,已经取得了显著进展,因此我们较少关注。我们相信,针对这个特定领域的长上下文能力的改进将迁移到通用视频生成。
与Mamba2[8]GatedDeltaNet[53],和滑动窗口注意力层等强基线相比,TTT层生成的视频更加连贯,能够用动态运动讲述复杂的故事,在每方法100个视频的人体评估中领先34个Elo分数。以供参考,GPT- 4o在LMSysChatbotArena[6]中比GPT- 4Turbo高29个Elo分数。
示例视频、代码和标注可在https://test- time- training.github.io/video- dit获取。
2.测试时训练层
遵循标准实践[44,54],每个视频都会被预处理成一个由 TTT token组成的序列,其中 TTT 由其持续时间和分辨率决定。本节回顾了用于通用序列建模的测试时训练(TTT)层,并使用[43]第2节中的一些内容进行说明。我们首先讨论如何以因果方式(时间顺序)处理通用输入序列。第3节讨论如何通过以相反方向调用它们来在非因果主干中使用RNN层。
2.1.TTT作为更新隐藏状态
所有RNN层在固定大小的隐藏状态中压缩历史上下文。这种压缩有两个后果。一方面,将输入token xtx_{t}xt 映射到输出token Zt\mathcal{Z}_tZt 是高效的,因为更新规则和输出规则每个token都需要常数时间。另一方面,RNN层记住长上下文的能力受其隐藏状态可以存储的信息量的限制。[43]的目标是设计具有表达性隐藏状态的RNN层,这些隐藏状态可以压缩大量上下文。作为灵感,他们观察到自监督学习可以将大量训练集压缩到机器学习模型的权重中。
在[43]中的关键思想是使用自监督学习将历史上下文 x1,…,xtx_{1},\ldots ,x_{t}x1,…,xt 压缩成一个隐藏状态 Wt,W_{t},Wt, 通过将上下文作为无标签数据集,将隐藏状态作为机器学习模型 fff 的权重。更新规则,如图2所示,是在某个自监督损失 ℓ\ellℓ 上的梯度下降的一步:
Wt=Wt−1−η∇ℓ(Wt−1;xt),(1)W_{t} = W_{t - 1} - \eta \nabla \ell (W_{t - 1};x_{t}), \tag{1} Wt=Wt−1−η∇ℓ(Wt−1;xt),(1)
以学习率 η∘\eta_{\circ}η∘ 直观地,输出标记只是 xtx_{t}xt 上的预测,由 fff 使用更新的权重 WtW_{t}Wt 做出:
zt=f(xt;Wt).(2)z_{t} = f(x_{t};W_{t}). \tag{2} zt=f(xt;Wt).(2)
ℓ\ellℓ 的一个选择是重建 xtx_{t}xt 本身。为了使学习问题不平凡,可以先处理 xtx_{t}xt 成一个损坏的输入 x~t\tilde{x}_tx~t (参见第2.2节),然后优化:
ℓ(W;xt)=∥f(x~t;W)−xt∥2.(3)\ell (W;x_t) = \| f(\tilde{x}_t;W) - x_t\| ^2. \tag{3} ℓ(W;xt)=∥f(x~t;W)−xt∥2.(3)
类似于去噪自编码器[46] fff 需要发现 xtx_{t}xt 维度之间的相关性,以便从部分信息 x~t\tilde{x}_tx~t 中重建它。
与其他RNN层和自注意力机制一样,这个将输入序列 x1,…,xTx_{1},\ldots ,x_{T}x1,…,xT 映射到输出序列 z1,…,zTz_{1},\ldots ,z_{T}z1,…,zT 的算法可以被编程到序列建模层的正向传递中。即使在测试时,该层仍然为每个输入序列训练不同的权重序列 W1,…,WT0W_{1},\ldots ,W_{T_{0}}W1,…,WT0 因此,它被称为测试时训练(TTT)层。
从概念上讲,在 ∇ℓ\nabla \ell∇ℓ 上调用backward意味着对梯度进行梯度求导——这是一种在元学习中被广泛研究的技巧。TTT层与RNN层和自注意力机制具有相同的接口,因此可以在任何更大的网络架构中替换。[43]指的是将更大的网络作为外层循环进行训练,并在每个TTT层内部训练 WWW 作为内层循环。
2.2.学习TTT的自监督任务
可以说,TTT最重要的一部分是由 ℓ\ellℓ 指定的自监督任务。与从人类先验中手工设计自监督任务不同,[43]采取了一种端到端的方法,将其作为外部循环的一部分进行学习。从方程3中的简单重建任务开始,他们使用低秩投影 ℓ\ellℓ ,其中[43]是一个在外部循环中可学习的矩阵。
从方程3中的简单重建任务开始,他们使用低秩投影 x~t=θKxt\tilde{x}_t = \theta_Kx_tx~t=θKxt ,其中 θK\theta_KθK 是一个在外部循环中可学习的矩阵。
此外,也许 xtx_{t}xt 中的所有信息都值得记住,因此重建标签也可以是一个低秩投影 θVxt\theta_{V}x_{t}θVxt 而不是 xt0x_{t_0}xt0 总之,[43]中的自监督损失为:
ℓ(W;xt)=∥f(θKxt;W)−θVxt∥2.(4)\ell (W;x_t) = \| f(\theta_Kx_t;W) - \theta_Vx_t\| ^2. \tag{4} ℓ(W;xt)=∥f(θKxt;W)−θVxt∥2.(4)
最后,由于 θKxt\theta_Kx_tθKxt 的维度比 xtx_{t}xt 少,[43]不再可以使用方程2中的输出规则。因此,他们进行了另一个投影 θQxt,\theta_{Q}x_{t},θQxt, 并将输出规则更改为:
zt=f(θQxt;Wt).(5)z_{t} = f(\theta_{Q}x_{t};W_{t}). \tag{5} zt=f(θQxt;Wt).(5)
请注意,在内层循环中,只有 WWW 被优化,因此作为 ℓ\ellℓ 的参数写入; θ\thetaθ 是这个内层循环损失函数的“超参数”。 θK,θV,θQ\theta_{K},\theta_{V},\theta_{Q}θK,θV,θQ 在外层循环中优化,类似于自注意力机制中的查询、键和值参数。
2.3.TTT-MLP实例化
遵循[43],,我们将内循环模型 fff 实例化为一个围绕 fMLPf_{\mathsf{MLP}}fMLP 的包装器:一个类似于Transformer中的两层MLP。具体来说,隐藏维度是 4×4\times4× 输入维度,然后是一个GELU激活[16]。为了在TTT过程中更好的稳定性, fff 总是包含LayerNorm和残差连接。也就是说,
f(x)=x+LN(fMLP(x)).f(x) = x + \mathsf{LN}(f_{\mathsf{MLP}}(x)). f(x)=x+LN(fMLP(x)).
具有这种 fff 的TTT层称为TTT- MLP,这是本文中默认的实例化方式。在第4节中,我们还实例化了TTT- Linear(上述包装一个线性模型)作为基线。
3.方法
从高层次来看,我们的方法简单地在预训练的扩散Transformer中添加TTT层,并在带有文本标注的长视频上进行微调。从实际角度来看,让这种方法起作用涉及许多设计选择。
3.1.架构
预训练扩散Transformer。我们的方法是在添加TTT层后进行微调,原则上可以与任何骨干架构一起工作。我们选择扩散Transformer[32]进行初始演示,因为它是最受欢迎的视频生成架构。由于在视频上预训练扩散Transformer的成本是高昂的,我们从称为CogVideo- X5B[19]的预训练检查点开始。
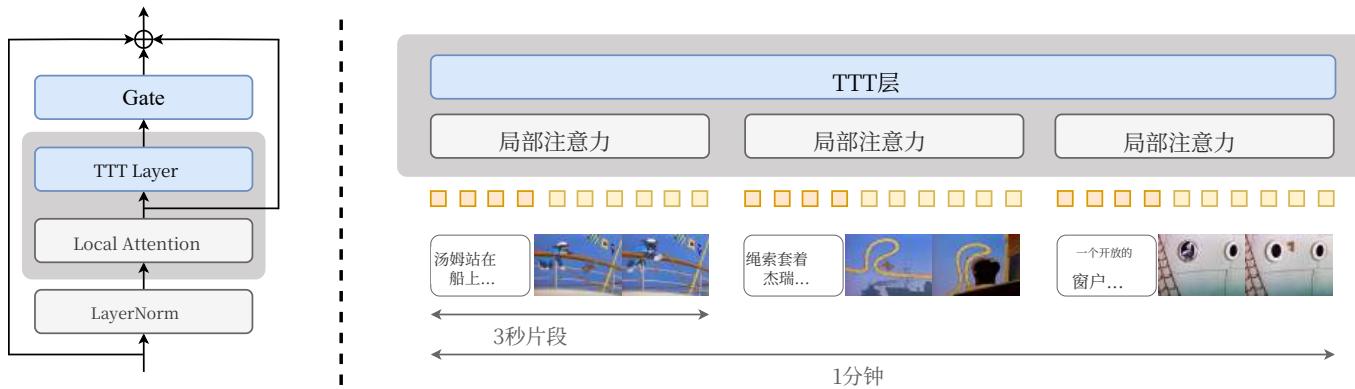
图3。我们方法的整体概述。左:我们的修改后架构在每个注意力层之后添加了一个TTT层和学习门控。参见第3.1节。右:我们的整体流程创建了由3秒片段组成的输入序列。这种结构使我们能够在片段上局部应用自注意力层,在整个序列上全局应用TTT层。参见第3.2节。
门控。给定一个输入序列 X=(x1,…,xT)X = (x_{1},\ldots ,x_{T})X=(x1,…,xT) ,其中每个标记 xt∈Rdx_{t}\in \mathbb{R}^{d}xt∈Rd ,一个TTT层会产生一个输出序列 Z=(z1,…,zT)=TT(X)∘Z = (z_{1},\ldots ,z_{T}) = \mathrm{TT}(X)_{\circ}Z=(z1,…,zT)=TT(X)∘ 每个 zt∈Rdz_{t}\in \mathbb{R}^{d}zt∈Rd 都遵循第2节中方程1、4和5所描述的递归关系。天真地将TTT层插入预训练网络会在微调开始时大幅恶化其预测,此时TTT层是随机初始化的。为了避免这种退化,我们按照标准做法[1]使用一个学习向量 α∈Rd\alpha \in \mathbb{R}^dα∈Rd 对TTT进行门控:
gate(TT,X;α)=tanh(α)⊗TT(X)+X,(6)\mathtt{gate}(\mathtt{TT},X;\alpha) = \tanh (\alpha)\otimes \mathtt{TT}(X) + X, \tag{6} gate(TT,X;α)=tanh(α)⊗TT(X)+X,(6)
其中 tanh(α)∈(−1,1)d\tanh (\alpha)\in (- 1,1)^dtanh(α)∈(−1,1)d 逐元素与 Z=TT(X)Z = \mathrm{TT}(X)Z=TT(X) 中的每个 ztz_{t}zt 相乘。我们将 α\alphaα 中的所有值初始化为0.1,因此 tanh(α)\tanh (\alpha)tanh(α) 中的值在微调开始时接近0 (≈0.1)(\approx 0.1)(≈0.1) 。这种 α\alphaα 的初始化允许TTT仍然对gate(TTT X;α)X;\alpha)X;α) 做出贡献,而不会显著覆盖 X∘X_{\circ}X∘
双向。扩散模型,包括CogVideo- X,是非因果的,这意味着输出标记 ztz_{t}zt 可以依赖于 x1…xT∖∖x_{1}\ldots x_{T\setminus \setminus}x1…xT∖∖ ,而不是仅依赖于过去的标记 x1…xtx_{1}\ldots x_{t}x1…xt ,。要在非因果方式中使用TTT层,我们应用了一个标准的技巧,称为双向 [30]∘[30]_{\circ}[30]∘ 给定一个在时间上反转 X=(x1,…,xT)X = (x_{1},\ldots ,x_{T})X=(x1,…,xT) 的算子
rev(X)=(xT,…,x1)\mathsf{rev}(X) = (x_{T},\ldots ,x_{1})rev(X)=(xT,…,x1) ,我们定义
TTT′(X)=rev(TTT(rev(X))).(7)\mathsf{TTT}^{\prime}(X) = \mathsf{rev}(\mathsf{TTT}(\mathsf{rev}(X))). \tag{7} TTT′(X)=rev(TTT(rev(X))).(7)
由于rev被应用了两次, TTT′(X)\mathrm{T}\mathrm{T}\mathrm{T}^{\prime}(X)TTT′(X) 仍然按时间顺序排列。但其中内部的TTT层现在按逆时间顺序扫描 XXX 0
修改后的架构。标准Transformer,包括CogVideo- X,包含交错序列建模块和MLP块。具体来说,一个标准序列建模块接收输入序列 XXX 并产生
X′=self_attn(LN(X))Y=X′+X,(9)\begin{array}{l}{X^{\prime} = \mathsf{self\_attn}(\mathsf{LN}(X))}\\ {Y = X^{\prime} + X,} \end{array} \tag{9} X′=self_attn(LN(X))Y=X′+X,(9)
其中LN是LayerNorm,而 X′+XX^{\prime} + XX′+X 形成一个残差连接。我们仅修改序列建模块,架构中的其他部分保持不变。每个修改后的块,如图3左侧面板所示,继续从方程8中的 X′X^{\prime}X′ 并产生
Z=⌈⌉(TTTX′;α),(10)Z = \lceil \rceil (\mathrm{TTT}X^{\prime};\alpha), \tag{10} Z=⌈⌉(TTTX′;α),(10)
Z′=⌈⌉(TTT′,Z′;β),(11)Z^{\prime} = \lceil \rceil (\mathrm{TTT}^{\prime},Z^{\prime};\beta), \tag{11} Z′=⌈⌉(TTT′,Z′;β),(11)
Y=Z′+X.(12)Y = Z^{\prime} + X. \tag{12} Y=Z′+X.(12)
注意 TTT′\mathrm{TTT^{\prime}}TTT′ 仅对TTT进行另一次调用,因此它们共享相同的底层参数 θK,θV,θQ∘\theta_K,\theta_V,\theta_{Q^\circ}θK,θV,θQ∘ 但对于门控,方程10和11使用不同的参数 α\alphaα 和 β∘\beta_{\circ}β∘
3.2.整体流程
在本小节中,我们讨论如何创建输入序列的标记以供我们的架构使用,以及每个序列如何按段进行处理。除了即将讨论的前两个文本格式外,所有内容都适用于微调和推理。我们的流程如图3的右图所示。
场景和片段。我们构建视频以包含多个场景,2每个场景包含一个或多个3- 秒片段。我们使用3秒片段作为文本到视频配对的原子单元,有三个原因:
·原始预训练的CogVideo- X生成最大长度为3秒。·汤姆和杰瑞剧集中的大多数场景长度至少为3秒。·给定3秒片段,构建多阶段数据集(第3.3节)最为方便。
文本提示的格式。在推理时,用户可以按任意顺序使用以下三种格式中的一种来编写长视频的文本提示
列出的格式,按详细程度递增的顺序。参见附录中的图8,了解每种格式的示例。·格式1:用5- 8句话简要概述剧情。一些示例显示在图1中。·格式2:用大约20句话更详细地描述剧情,每句话大致对应3秒的片段。句子可以被标记为属于某些场景或场景组,但这些标签仅被视为建议。
·格式3:故事板。每个3秒的片段由3- 5句话的段落描述,包含背景颜色和摄像机移动等细节。一个或多个段落组成的组严格强制属于具有关键词 <<< 场景开始 >>> 和 <<< 场景结束 >>> 的某些场景。
我们的文本分词器的实际输入在微调和推理期间始终为格式3。格式之间的转换由Claude3.7Sonnet按顺序 1→2→3.31\rightarrow 2\rightarrow 3. ^{3}1→2→3.3 进行。对于微调,我们的人工标注已经是格式3,如3.3节所述。
从文本到序列。在原始CogVideo- X对每个视频的输入文本进行分词后,它将文本标记与噪声视频标记连接起来,形成输入Transformer的序列。为了生成长视频,我们对每个3秒段独立应用相同的步骤。具体来说,给定一个Format3的故事板,其中包含 nnn 段落,我们首先生成 nnn 序列段,每个序列段包含从相应段落中提取的文本标记,然后是视频标记。然后我们将所有 nnn 序列段连接在一起,形成输入序列,该序列现在具有交错文本和视频标记。
局部注意力,全局TTT。CogVideo- X使用自注意力层对每个最大长度为3秒的视频的全输入序列进行全局处理,但全局注意力对于长视频效率不高。为了避免增加自注意力层的上下文长度,我们将它们设置为每个3秒段的局部,独立地注意每个 nnn 序列段。4
TTT层因为它们在长上下文中效率高,所以处理整个输入序列的全局。
3.3.微调配方和数据集
多阶段上下文扩展。遵循LLM的标准实践[51],我们将我们修改后架构的上下文长度扩展到五阶段的一分钟。首先,我们在Tom和Jerry的3秒片段上微调整个预训练模型,以适应这个领域。新参数(特别是TTT层和门中的参数)被
在这个阶段分配了更高的学习率。在接下来的四个阶段中,我们在9、18、30和最终63秒的视频上进行微调。为了避免忘记太多预训练的世界知识,我们只微调TTT层、门和自注意力层,在这些四个阶段使用较低的学习率。有关详细配方,请参阅附录A。
对原始视频进行超分辨率处理。我们从1940年至1948年间发布的81集汤姆和杰瑞开始。每集大约5分钟,所有剧集加起来大约有7小时。原始视频的分辨率各不相同,按现代标准来看都相当差。我们在原始视频上运行一个视频超分辨率模型[49],生成具有共享分辨率 720×480720\times 480720×480 的视觉增强视频,用于我们的数据集。
多阶段数据集。根据3.2节中讨论的结构,我们首先让人类标注员将每集分解为场景,然后从每个场景中提取3秒的片段。接下来,我们让人类标注员为每个3秒片段撰写详细的段落。第一阶段直接在这些片段上进行微调。为了为最后四个阶段创建数据,我们将连续的3秒片段连接成9、18、30和63秒的视频,并附带其文本注释。场景边界由3.2节中相同的关键词标记。结果,所有训练视频的标注都采用Format3格式。
3.4.非因果序列的并行化
第2节中讨论的更新规则不能简单地跨序列中的token并行化,因为计算 WtW_{t}Wt 需要 ∇ℓ(Wt−1;xt)\nabla \ell (W_{t - 1};x_t)∇ℓ(Wt−1;xt) ,而 ∇ℓ(Wt−1;xt)\nabla \ell (W_{t - 1};x_t)∇ℓ(Wt−1;xt) 又需要 Wt−10W_{t - 10}Wt−10 为了实现并行化,我们在 bbb 个token上一次更新 WWW ,这[43]称为一个内部循环的小批处理。在整个论文中,我们设置 b=64∘b = 64_{\circ}b=64∘
具体来说,对于小批处理 i=1…T/bi = 1\dots T / bi=1…T/b ,,假设 TTT 是b的整数倍),
Wib=W(i−1)b−ηb∑t=(i−1)b+1ib∇ℓ(W(i−1)b;xt).(13)W_{ib} = W_{(i - 1)b} - \frac{\eta}{b}\sum_{t = (i - 1)b + 1}^{ib}\nabla \ell \left(W_{(i - 1)b};x_t\right). \tag{13} Wib=W(i−1)b−bηt=(i−1)b+1∑ib∇ℓ(W(i−1)b;xt).(13)
由于序列是非因果的,我们然后使用 WibW_{ib}Wib 来为小批处理 iii 中的所有时间步生成输出token:
zt=f(Wib;xt),fort=(i−1)b+1,…,ib.(14)z_{t} = f(W_{ib};x_{t}),\qquad \mathrm{for} t = (i - 1)b + 1,\ldots ,ib. \tag{14} zt=f(Wib;xt),fort=(i−1)b+1,…,ib.(14)
注意, W(i−1)b+1…Wib−1W_{(i - 1)b + 1}\dots W_{ib - 1}W(i−1)b+1…Wib−1 ,不再需要。
在此修改之后, fff 可以并行处理一个(内部循环)的小批次令牌,类似于常规的MLP处理一个(外部循环)的小批次训练数据。作为额外的益处,我们观察到跨令牌平均梯度可以减少方差并稳定对 WWW 的每次更新。
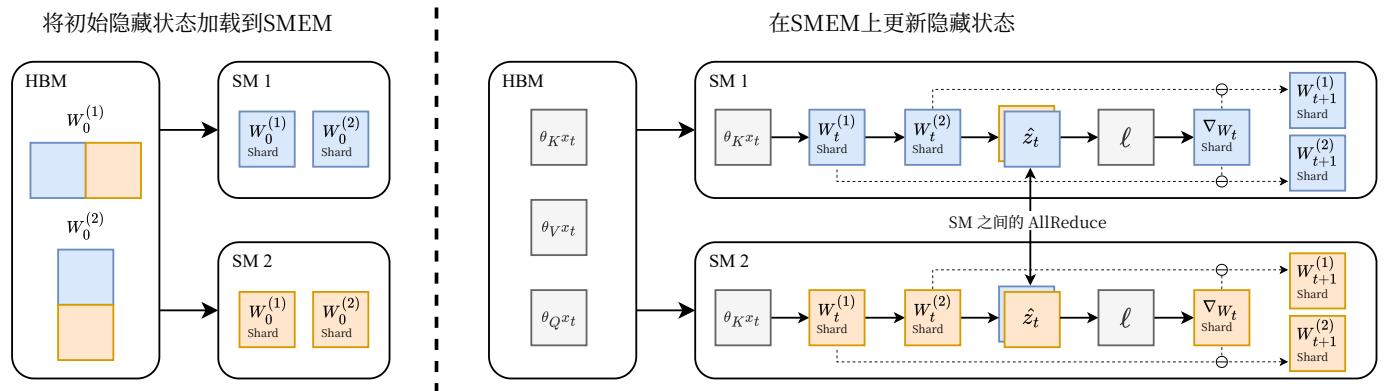
图4。片上张量并行,讨论于3.5节。左:为了减少每个SM上TTT-MLP所需的内存,我们将隐藏状态 W(1)W^{(1)}W(1) 和 W(2)W^{(2)}W(2) 跨SM分片,仅在初始加载和最终输出时在HBM和SMEM之间传输。右:我们在片上完全更新隐藏状态,并使用NVIDIAHopper GPU架构上的DSMEM功能在SM之间AllReduce中间激活。
3.5。片上张量并行
为GPU高效实现TTT- MLP需要特殊设计以利用其内存层次结构。GPU上的芯片称为流式多处理器(SM),类似于CPU上的核心。GPU上的所有SM共享一个相对较慢但较大的全局内存,称为HBM,然后每个SM都有一个快速但小的片上内存,称为SMEM。GPU上频繁的SMEM和HBM之间的数据传输会显著影响整体效率。
Mamba和自注意力层(FlashAttention[9])的高效实现使用内核融合来最小化这种类型的传输。这些实现的高级思想是将输入和初始状态加载到每个SMEM中,完全在片上执行计算,并且仅将最终输出写回HBM。然而,TTT- MLP的隐藏状态,即两层MLP fff 的权重 W(1)W^{(1)}W(1) 和 W(2)W^{(2)}W(2) ,太大而无法存储在单个SM的SMEM中(当与输入和激活结合时)。
为了减少每个SM所需的内存,我们使用Tensor并行[39]将 W(1)W^{(1)}W(1) 和 W(2)W^{(2)}W(2) 跨SM分片,如图4所示。类似于大型MLP层可以被分片并在多个GPU的HBM上进行训练,我们现在将相同的思想应用于多个SM的SMEM上,将每个SM视为GPU的类比。我们使用NVIDIAHopperGPU架构上的DSMEM功能在SM之间实现AllReduce。我们内核的更多细节在附录B中讨论。
我们的实现显著提高了效率,因为隐藏状态和激活现在仅在初始加载和最终输出时从HBMs读取和写入。作为一个一般原则,如果模型架构 fff 可以使用标准的Tensor并行性跨GPU分片,那么当 fff 用作隐藏状态时,相同的分片策略可以应用于SMs。
4.评估
我们对TTT- MLP和五个基线进行了人工评估,所有基线都具有线性复杂度:局部注意力、TTT- Linear、Mamba2、GatedDeltaNet和滑动窗口注意力层。
4.1.基线
除了局部注意力之外,所有基线都使用第3.1节中的方法添加到相同的预训练CogVideo- X5B中;它们的修改后架构都具有7.2B参数。所有基线都使用第3.3节和附录A中的相同微调配方。接下来我们详细讨论基线。
·局部注意力:不修改原始架构,该架构对每个3秒片段独立执行自注意力。
·TTT- Linear[43]:一个TTT层,实例化 f(x)=f(x) =f(x)= x+LN(fLinear(x))x + \mathsf{LN}(f_{\mathrm{Linear}}(x))x+LN(fLinear(x)) ,其中 fff Linear是一个线性模型。·Mamba2[8]:一个具有矩阵隐藏状态的现代RNN层,其隐藏状态比TTT- Linear中的更大,但比TTT- MLP中的更小。
·GatedDeltaNet[53]:DeltaNet[52]和Mamba2的扩展,具有改进的更新规则。·滑动窗口注意力[3]:具有8192个token(约1.5秒视频)的固定窗口的自注意力。
4.2.评估轴和协议
从MovieGen[44],的六个评估轴中,我们采用与我们的领域相关的四个用于人工评估.6
door of the house and ferry runs to his mouse on walls into the wall.

actions.

e pie.

in later frames.

oughout the video.
TTT- MLP demonstrates better
| Text following | Motion naturalness | 美学 | 时间一致性 | 平均 | |
| Mamba 2 | 985 | 976 | 963 | 988 | 978 |
| 门控DeltaNet | 983 | 984 | 993 | 1004 | 991 |
| 滑动窗口 | 1016 | 1000 | 1006 | 975 | 999 |
| TTT-MLP | 1014 | 1039 | 1037 | 1042 | 1033 |
表1. 一分钟视频的人类评估结果。TTT- MLP平均比第二好的方法提高了34个Elo分。改进最多的轴是场景一致性 (+38)(+38)(+38) 和运动平滑度 (+39)(+39)(+39) 。作为参考,GPT- 4比GPT- 3.5 Turbo高46个Elo分,在Chatbot Arena中GPT- 4o比GPT- 4 Turbo高29个[6]。
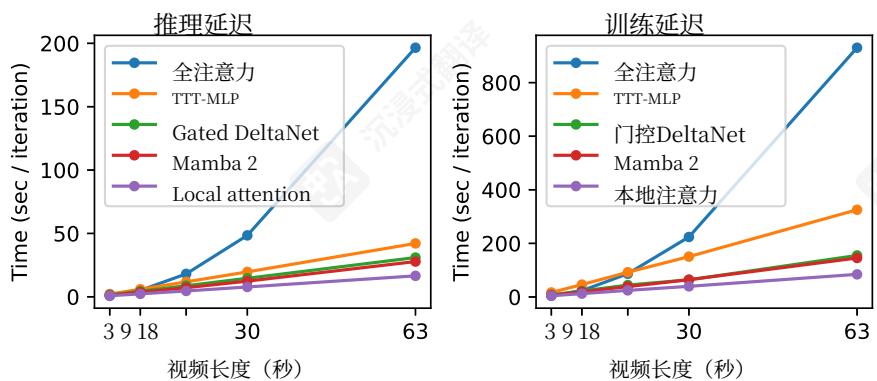
图6. 对于63秒视频,全注意力推理(超过300k个token)会花费 11×11\times11× 比局部注意力更长,训练 12×12\times12× 也更长,如第1节所述。TTT- MLP分别需要 2.5×2.5\times2.5× 和 3.8×3.8\times3.8× ——比全注意力显著高效,但仍然比例如GatedDeltaNet低效,后者在推理和训练中都比局部注意力花费 1.8×1.8\times1.8× 更长。
·文本后续:“与提供的提示一致。”·动作自然度:“自然的肢体动作、面部表情,以及遵循物理定律。看起来不自然或怪异的动作将被扣分。”
·美学:“有趣且引人入胜的内容、光照、色彩和相机效果。
·时间一致性:在场景内部和跨场景。
引述的描述来自MovieGen[44]
我们的评估基于盲法比较中的成对偏好,因为直接对长视频进行评分或一次性对许多视频进行排序具有挑战性。具体来说,评估者会从上述四个中随机获得一个轴,并随机获得一对共享相同剧情的视频,然后被要求指出该轴上更好的视频。为了收集视频库,我们首先使用Claude3.7Sonnet(如3.2节中讨论的Format 1→2→31\rightarrow 2\rightarrow 31→2→3 )采样100个剧情,然后为每个方法每个剧情生成一个视频。生成视频的方法对评估者始终是未知的。
我们的评估员通过prolific.com招募,筛选条件为:居住在美国、英语为母语、年龄在18至35岁之间、至少有100次之前的提交记录,且批准率至少为 98%98\%98% 我们评估员的统计数据已在网站上公布,如下所示。
·性别: 50.78%50.78\%50.78% 男性, 47.66%47.66\%47.66% 女性, 1.56%1.56\%1.56% 其他。·种族: 57.03%57.03\%57.03% 白人, 23.44%23.44\%23.44% 黑人, 10.94%10.94\%10.94% 混合种族, 5.47%5.47\%5.47% 亚裔,以及 3.12%3.12\%3.12% 其他。根据这些信息,我们相信我们的评估者
代表了美国人口的一个代表性样本。
4.3.结果
我们使用LMSysChatbotArena中的Elo系统[6]聚合成对偏好。Elo分数显示在表1中。
TTT- MLP平均比第二好的方法提高了34个Elo分数。以供参考,GPT- 4比GPT- 3.5Turbo(1163vs.1117)高46个Elo分数,GPT- 4o比GPT- 4Turbo(1285vs.1256)高29个Elo分数,在LMSysChatbotArena[6],中,我们提高的34个Elo分数在实际中具有意义。7图5比较了TTT- MLP和基线生成的样本视频帧。图5中展示的视频可以在项目网站上访问:https://test- time- training.github.io/video- dit
18秒淘汰赛。请注意,本地注意力机制和TTT- Linear未出现在表1中。为了避免在每种方法上评估更长的视频产生的高成本,我们首先使用18秒视频进行了淘汰赛,遵循了第4.2节中讨论的相同流程。这一轮淘汰了表现最差的本地注意力机制,以及表现不如TTT- MLP的TTT- Linear。淘汰赛的结果显示在附录中的表3中。

时间一致性:方框在相同场景的3秒片段之间变形。

运动自然性:奶酪悬浮在空中,而不是自然地落到地面。

美学:当Tom转身时,厨房的灯光变得明显更亮。
图7。由TTT- MLP生成的视频中的伪影。时间一致性:对象有时在3秒片段的边界处变形,可能是因为扩散模型在片段之间从不同的模式采样。运动自然性:对象有时不自然地漂浮,因为重力效应没有被正确建模。美学:除非明确提示,否则灯光变化不会始终与动作一致。复杂的摄像机运动,如视差,有时被描绘得不准确。
4.4.限制
短上下文。对于上述讨论的18秒淘汰赛,GatedDeltaNet平均表现最佳,领先Mamba227个Elo分,领先TTT- MLP28分(参见附录中的表3)。对于18秒视频,上下文长度大约为100k个token。这项评估显示了线性(矩阵)隐藏状态的RNN层(如GatedDeltaNet和Mamba2)仍然是最有效的场景。此外,18秒和63秒视频的评估结果表明,GatedDeltaNet在Mamba2上取得了显著的改进。
墙上时钟时间。即使应用了我们在第3.4节和3.5节中的改进,TTT- MLP的效率仍然不如GatedDeltaNet和Mamba2。这个限制在图6中突出显示,其中使用TTT- MLP进行推理和训练是 1.4×1.4\times1.4× 和 2.1×2.1\times2.1× 比使用GatedDeltaNet更慢,例如。第6节讨论了我们TTT- MLP内核的两个潜在改进,以提高效率。请注意,在我们的应用中,训练效率不是一个重要的问题,因为RNN层是在预训练后集成的,这构成了整体训练预算的大部分。RNN层的训练效率仅在微调期间相关,而微调本身只占预算的一小部分。相比之下,推理效率更有意义。
视频伪影。生成的63秒视频展示了作为概念验证的明显潜力,但仍包含显著的伪影,尤其是在运动自然性和美学方面。图7说明了与我们的三个评估轴对应的伪影示例。我们观察到,具有这些伪影的视频并不特别针对TTT- MLP,而是所有方法中常见的。这些伪影可能是由于预训练的CogVideo- X5B模型能力有限造成的。例如,由原始CogVideo- X生成的视频(链接)似乎也具有有限的运动自然性和美学。
5.相关工作
现代RNN层,尤其是线性注意力变体[23,37],如Mamba[8,12]和DeltaNet[35,52]。在自然语言任务中已展现出令人印象深刻的性能。受其成功和FastWeightProgrammers[7,21,24,36],[43]的启发,提出了可扩展且实用的方法来使隐藏状态更大且非线性,从而更具表达能力。近期工作[2]开发了更大且更非线性的隐藏状态,并使用更复杂的优化技术进行更新。[43]中的相关工作部分对TTT层的灵感来源进行了详细讨论。[48]对RNN层的最新发展给出了一个很好的概述。
长视频建模。一些早期工作[40]通过训练GAN[11,22]来根据当前帧和运动矢量预测下一帧,从而生成长视频。由于自回归(AR)和基于扩散的方法[13,25,44,54]的近期进展,生成质量已显著提高。TATS[10]在Transformer上提出了滑动窗口注意力,以生成比训练长度更长的视频。Phenaki[45]以类似自回归的方式工作,但每一帧都是由MaskGIT[4]生成的。通过使用级联[15,50,55]流[17],和添加过渡[5],预训练的扩散模型可以扩展以生成更长的视频。
故事合成方法(如[10,26,28,29,31,33])生成与文本故事中单个句子对应的图像或视频序列。例如,Craft[14]通过检索生成复杂场景的视频,而StoryDiffusion[56]使用扩散技术来提高帧之间过渡的平滑度。虽然与文本到视频生成相关,但故事合成方法通常需要在它们的管道中添加额外的组件以保持场景之间的连贯性,这些组件不是端到端处理的。
6.未来工作
我们概述了未来工作的几个有前景的方向。更快的实现。我们当前的TTT- MLP内核受寄存器溢出和非最优异步指令排序的限制。通过最小化寄存器压力和开发更编译器感知的异步操作实现,效率可能进一步提高。
更好的集成。使用双向和学习的门只是将TTT层集成到预训练模型的一种可能策略。更好的策略应进一步提高生成质量并加速微调。其他视频生成骨干(如自回归模型)可能需要不同的集成策略。
更长的视频和更大的隐藏状态。我们的方法有可能扩展到生成线性复杂度的更长的视频。我们相信实现这一目标的关键在于将隐藏状态实例化为比我们的两层MLP更大的神经网络。例如,f本身可以是一个Transformer。
致谢。我们感谢HyperbolicLabs提供计算支持,感谢邓云天在运行实验方面的帮助,以及感谢AaryanSinghal、ArjunVikram和BenSpecter在系统问题上的帮助。赵岳想要感谢PhilippKr"ahenb"uhl的讨论和反馈。孙宇想要感谢他的博士导师AlyoshaEfros在机器学习工作中关于查看像素的深刻建议。
关于作者身份的说明。GashonHussein和宋友进在CVPR的初始版本提交后加入了团队,并对最终版本做出了重大贡献。由于CVPR不允许我们在提交后添加作者,他们的名字无法出现在OpenReview和会议网页上。然而,我们都同意官方作者名单应该包括他们的名字,正如我们发布的PDF中所示。没有他们的工作,这个项目是不可能的。
参考文献
[1] Jean- Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few- shot learning. NeurIPS, 2022. 4[2] Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time. arXiv preprint arXiv:2501.00663, 2024. 9[3] Iz Beltagy, Matthew E Peters, and Arman Cohan. Long- former: The long- document transformer. arXiv preprint arXiv:2004.05150, 2020. 6[4] Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. In CVPR, 2022. 10[5] Xinyuan Chen, Yaohui Wang, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Seine: Short- to- long video diffusion model for generative transition and prediction. In ICLR, 2023. 10[6] Wei- Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael Jordan, Joseph E Gonzalez, et al. Chatbot arena: An open platform for evaluating llms by human preference. In ICML, 2024. 2, 8[7] Kevin Clark, Kelvin Guu, Ming- Wei Chang, Panupong Pasupat, Geoffrey Hinton, and Mohammad Norouzi. Meta- learning fast weight language models. EMNLP, 2022. 9[8] Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality. In ICML, 2024. 2, 6, 9[9] Tri Dao, Dan Fu, Stefano Ermon, Aiti Rudra, and Christopher Ré. Flashattention: Fast and memory- efficient exact attention with io- awareness. In NeurIPS, 2022. 6[10] Songwei Ge, Thomas Hayes, Harry Yang, Xi Yin, Guan Pang, David Jacobs, Jia- Bin Huang, and Devi Parikh. Long video generation with time- agnostic vqgan and time- sensitive transformer. In ECCV, 2022. 10[11] Ian Goodfellow, Jean Pouget- Abadie, Mehdi Mirza, Bing Xu, David Warde- Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. Communications of the ACM, 2020. 10[12] Albert Gu and Tri Dao. Mamba: Linear- time sequence modeling with selective state spaces. In COLM, 2024. 2, 9[13] Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Fei- Fei Li, Irfan Essa, Lu Jiang, and José Lezama.
Photorealistic video generation with diffusion models. In ECCV, 2024. 10[14] Tanmay Gupta, Dustin Schwenk, Ali Farhadi, Derek Hoiem, and Aniruddha Kemphavi. Imagine this! scripts to compositions to videos. In ECCV, 2018. 10[15] Yingqing He, Tianyu Yang, Yong Zhang, Ying Shan, and Qifeng Chen. Latent video diffusion models for high- fidelity long video generation. arXiv preprint arXiv:2211.13221, 2022. 10[16] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016. 3[17] Roberto Henschel, Levon Khachatryan, Daniil Hayrapetyan, Hayk Poghosyan, Tahram Tadevosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Streaming2v: Consistent, dynamic, and extendable long video generation from text. arXiv preprint arXiv:2403.14773, 2024. 10[18] Jonathan Ho and Tim Salimans. Classifier- free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022. 1[19] Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large- scale pretraining for text- to- video generation via transformers. In ICLR, 2023. 2, 3[20] Ting- Hao Huang, Francis Ferraro, Nasrin Mostafazadeh, Ishan Misra, Aishwarya Agrawal, Jacob Devlin, Ross Girshick, Xiaodong He, Pushmeet Kohli, Dhruv Batra, et al. Visual storytelling. In NAACL, 2016. 10[21] Kazuki Irie, Imano Schlag, Robert Csordas, and Jurgen Schmidhuber. Going beyond linear transformers with recurrent fast weight programmers. NeurIPS, 2021. 9[22] Tero Karras, Samuel Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. Analyzing and improving the image quality of stylegan. In CVPR, 2020. 10[23] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and Francois Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In ICML, 2020. 2, 9[24] Louis Kirsch and Jurgen Schmidhuber. Meta learning backpropagation and improving it. NeurIPS, 34:14122- 14134, 2021. 9[25] Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, Weiyan Wang, Wenqing Yu, Xinchi Deng, Yang Li, Yi Chen, Yutao Cui, Yuanbo Peng, Zhentao Yu, Zhiyu He, Zhiyong Xu, Zixiang Zhou, Zunnan Xu, Yangyu Tao, Qinglin Lu, Songtao Liu, Dax Zhou, Hongfa Wang, Yong Yang, Di Wang, Yuhong Liu, Jie Jiang, and Caesar Zhong. Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv 2412.03603, 2025. 10[26] Yitong Li, Zhe Gan, Yelong Shen, Jingjing Liu, Yu Cheng, Yuexin Wu, Lawrence Carin, David Carlson, and Jianfeng Gao. Storygan: A sequential conditional gan for story visualization. In CVPR, 2019. 10[27] Shanchuan Lin, Bingchen Liu, Jiashi Li, and Xiao Yang. Common diffusion noise schedules and sample steps are flawed. In WACV, 2024. 1
[28] Chang Liu, Haoning Wu, Yujie Zhong, Xiaoyun Zhang, Yanfeng Wang, and Weidi Xie. Intelligent grimm- open- ended visual storytelling via latent diffusion models. In CVPR, 2024. 10[29] Adyasha Maharana, Darryl Hannan, and Mohit Bansal. Storydall- e: Adapting pretrained text- to- image transformers for story continuation. In ECCV, 2023. 10[30] Shentong Mo and Yapeng Tian. Scaling diffusion mamba with bidirectional ssms for efficient image and video generation. arXiv preprint arXiv:2405.15881, 2024. 4[31] Xichen Pan, Pengda Qin, Yuhong Li, Hui Xue, and Wenhui Chen. Synthesizing coherent story with auto- regressive latent diffusion models. In WACV, 2024. 10[32] William Peebles and Saining Xie. Scalable diffusion models with transformers. In CVPR, 2023. 3, 4[33] Tanzila Rahman, Hsin- Ying Lee, Jian Ren, Sergey Tulyakov, Shweta Mahajan, and Leonid Sigal. Make- a- story: Visual memory conditioned consistent story generation. In CVPR, 2023. 10[34] Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. In ICLR, 2022. 1[35] Imanol Schlag, Kazuki Irie, and Jurgen Schmidhuber. Linear transformers are secretly fast weight programmers. In ICML, 2021. 2, 9[36] Jurgen Schmidhuber. Learning to control fast- weight memories: An alternative to dynamic recurrent networks. Neural Computation, 4(1):131- 139, 1992. 9[37] Jurgen Schmidhuber. Learning to control fast- weight memories: An alternative to dynamic recurrent networks. Neural Computation, 4(1):131- 139, 1992. 2, 9[38] Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention- 3: Fast and accurate attention with asynchrony and low- precision, 2024. 1[39] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron- lm: Training multi- billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019. 6[40] Ivan Skorokhodov, Sergey Tulyakov, and Mohamed Elhoseiny. Stylegan- v: A continuous video generator with the price, image quality and perks of stylegan2. In CVPR, 2022. 10[41] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In ICLR, 2021. 1[42] Benjamin F Spector, Simran Arora, Aaryan Singhal, Daniel Y Fu, and Christopher Ré. Thunderkittens: Simple, fast, and adorable ai kernels. In ICLR, 2025. 1[43] Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, and Carlos Guestrin. Learning to (learn at test time): Rnns with expressive hidden states. arXiv preprint arXiv:2407.04620, 2024. 2, 3, 5, 6, 9, 1[44] The Movie Gen team. Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720, 2024. 2, 6, 8, 10
[45] Ruben Villegas, Mohammad Babaeizadeh, Pieter- Jan Kindermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual description. In ICLR, 2023. 10[46] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre- Antoine Manzagel. Extracting and composing robust features with denoising autoencoders. In ICML, 2008. 3[47] Hongjie Wang, Chik- Yao Ma, Yen- Cheng Liu, Ji Hou, Tao Xu, Jialiang Wang, Felix Juefei- Xu, Yaqiao Luo, Peizhao Zhang, Tingbo Hou, Peter Vajda, Niraj K. Jha, and Xiao- liang Dai. Lingen: Towards high- resolution minute- length text- to- video generation with linear computational complexity, 2024. 2[48] Ke Alexander Wang, Jiaxin Shi, and Emily B Fox. Test- time regression: a unifying framework for designing sequence models with associative memory. arXiv preprint arXiv:2501.12352, 2025. 9[49] Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real- esrgan: Training real- world blind super- resolution with pure synthetic data. In ICCVW, 2021. 5[50] Yaohui Wang, Xinyuan Chen, Xin Ma, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, et al. Lavie: High- quality video generation with cascaded latent diffusion models. IJCV, 2024. 10[51] Wenhan Xiong, Jingyu Liu, Igor Molybog, Hejia Zhang, Prajjwal Bhargava, Rui Hou, Louis Martin, Rashi Rungta, Karthik Abinav Sankararaman, Barlas Oguz, et al. Effective long- context scaling of foundation models. In NAACL, 2024. 5[52] Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. In NeurIPS, 2024. 6, 9[53] Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated delta networks: Improving mamba2 with delta rule. In ICLR, 2025. 2, 6[54] Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text- to- video diffusion models with an expert transformer. In ICLR, 2025. 2, 10, 1[55] Shengming Yin, Chenfei Wu, Huan Yang, Jianfeng Wang, Xiaodong Wang, Minkong Ni, Zhengyuan Yang, Linjie Li, Shuguang Liu, Fan Yang, et al. Nuwa- xl: Diffusion over diffusion for extremely long video generation. arXiv preprint arXiv:2303.12346, 2023. 10[56] Yupeng Zhou, Daquan Zhou, Ming- Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffusion: Consistent self- attention for long- range image and video generation. In NeurIPS, 2024. 10
| 视频长度。上下文长 度 | 可训练参数 | 学习率 | 计划 | 步数 | |
| 3秒 | 18048 | TTT / 预训练参数 | 1 × 10-4 / 1 × 10-5 | 余弦 / 常数 | 5000 |
| 9秒 | 51456 | TTT + 本地注意力 (QKVO) | 1 × 10-5 | 常数 | 5000 |
| 18秒 | 99894 | TTT + 本地注意力 (QKVO) | 1 × 10-5 | 常数 | 1000 |
| 30秒 | 168320 | TTT + 本地注意力 (QKVO) | 1 × 10-5 | 常数 | 500 |
| 63秒 | 341550 | TTT + 本地注意力 (QKVO) | 1 × 10-5 | 常数 | 250 |
表2. 多阶段微调的超参数。首先,整个预训练模型在汤姆和杰瑞的3秒片段上进行微调,并将更高的学习率分配给新引入的TTT层和门。然后,仅在TTT层、门和自注意力参数上以较低的学习率进行微调。
| 文本跟随 | 运动自然度 | 美学 | 时间一致性 | 平均 | |
| 局部注意力 | 965 | 972 | 969 | 944 | 962 |
| TTT-Linear | 1003 | 995 | 1007 | 1001 | 1001 |
| Mamba 2 | 1023 | 987 | 1008 | 1004 | 1005 |
| Gated DeltaNet | 1020 | 1039 | 1044 | 1026 | 1032 |
| SWA | 995 | 1004 | 993 | 980 | 993 |
| TTT-MLP | 994 | 1002 | 1002 | 1019 | 1004 |
表3.18秒视频的人类评估结果,讨论于第4.3节和4.4节。
A.实验细节
扩散调度。遵循CogVideoX[54],我们使用v预测[34],对模型进行微调,该预测包括一个具有1000步的扩散噪声调度,并在最终步骤强制执行Zero- SNR[27]
训练配置。我们为所有训练阶段使用以下超参数:
·优化器:AdamWwith (β1,β2)=(0.9,0.95)(\beta_{1},\beta_{2}) = (0.9,0.95)(β1,β2)=(0.9,0.95) ·学习率:线性预热,占训练步骤的 2%2\%2% ·批大小:64·梯度裁剪:0.1·权重衰减: 10−410^{- 4}10−4 应用于所有参数,除偏差和归一化层外·VAE缩放因子:1.0·Dropout:以概率0.1将文本提示置零·精度:使用PyTorchFSDP2的混合精度
TTT配置。TTT层的Akey超参数是内循环学习率 η\etaη ,我们为TTT- Linear设置 η=1.0\eta = 1.0η=1.0 ,为TTT- MLP设置 η=0.1\eta = 0.1η=0.1 0
采样计划。我们遵循DDIM采样器[41],使用50步,应用动态分类器无引导(CFG)[18],该引导从1增加到4,并利用负面提示进一步增强视频质量。
B.片上张量并行细节
我们使用ThunderKittens[42]实现TTT- MLP内核,如第3.5节所述。
隐藏状态分片。我们遵循张量并行的标准策略,对第一层按列分片,对第二层按行分片。由于GeLU非线性是逐元素的,TTT层的正向传递需要单个归约来计算用于更新隐藏状态的内部损失。
进一步的延迟优化。我们结合了来自FlashAttention- 3[38]的多种技术,以进一步降低NVIDIAHopperGPU上的I/O延迟。特别是,我们实现了一种多阶段流水线方案,异步预取来自HBM的未来小批量,将数据传输与当前小批量的计算重叠。这种方法,称为生产者- 消费者异步,涉及为数据加载(生产者)或计算(消费者)分配专门的功能组(warpgroups)。
梯度检查点。我们将梯度检查点沿序列维度[43]直接集成到我们的融合内核中。为了减少I/O引起的停顿和CUDA线程工作负载,我们使用张量内存加速器(TMA)执行异步内存存储。
格式1
格式1汤姆在厨房桌子旁开心地吃着苹果派。杰瑞渴望地看着,希望自己也有一些。杰瑞走到房子的前门并按门铃。当汤姆来开门时,杰瑞绕到后面跑到厨房。杰瑞偷走了汤姆的苹果派。杰瑞拿着派跑到他的老鼠洞,而汤姆在追他。就在汤姆快要抓住杰瑞时,杰瑞钻进了老鼠洞,汤姆撞到了墙上。
格式2
片段1- 2:汤姆拿着一个苹果派走进厨房。他坐在桌子旁开始吃
片段3- 5:视角移到柜台后面,揭示了杰瑞躲在盐罐后面。杰瑞走出来,看着汤姆吃派,并兴奋地揉着肚子。然后他快速地移出屏幕到右侧。
片段6- 8:在房子外面,杰瑞走向前门,跳起来按门铃,然后迅速跑开。
故事继续…
格式3
<开始场景>厨房有柔和的黄色墙壁、白色橱柜,以及一扇挂着红白格纹窗帘的窗户,透进柔和的阳光。中间有一张圆形木桌,配有相配的椅子,放在干净的白色瓷砖地板上。蓝灰色的汤姆猫从左侧走进来,手里拿着一个温暖的金褐色派,放在闪亮的银质托盘上。他平静地穿过房间走向桌子,小心地将派放下,拉出椅子,舒适地坐下。摄像机从左到右平稳地跟随汤姆,清晰地展示了他的每一个动作。
厨房有柔和的黄色墙壁、白色橱柜,以及一扇挂着红白格纹窗帘的窗户,透进柔和的阳光。中间有一张圆形木桌,配有相配的椅子,放在干净的白色瓷砖地板上。蓝灰色的汤姆猫舒适地坐在桌子旁,金褐色的派放在它面前的闪亮银质托盘上。他小心地用爪子从托盘上拿起一片,举向嘴边,大口咬了一口。摄像机慢慢靠近,清晰地展示汤姆享受派的样子,碎屑轻轻落在桌子上,结束场景>
<开始场景>厨房有柔和的黄色墙壁、白色橱柜,以及一扇挂着红白格纹窗帘的窗户,透进柔和的阳光。橱柜上青白色的台面,上面放着一个高玻璃盐瓶。在背景中,蓝灰色的猫Tom坐在圆木桌旁,吃着金黄色的派。棕色的老鼠Jerry站在白色台面上,藏在盐瓶后面。Jerry短暂地环顾四周,然后从盐瓶后面走出来。镜头捕捉到Jerry从盐瓶后面走出来,站在台面上。
厨房有柔和的黄色墙壁、白色橱柜,以及一扇挂着红白格纹窗帘的窗户,透进柔和的阳光。橱柜上有白色的台面,上面放着一个高玻璃盐瓶。在背景中,蓝灰色的猫Tom坐在圆木桌旁,吃着金黄色的派。棕色的老鼠Jerry站在盐瓶旁边的台面上。Jerry用爪子揉着肚子,看着蓝灰色的猫Tom。镜头保持在Jerry旁边稍微一侧的位置,捕捉他饥饿的表情。
厨房有柔和的黄色墙壁、白色橱柜,以及一扇挂着红白格纹窗帘的窗户,让温暖的阳光透进来。橱柜上有白色的台面,上面放着一个高高的玻璃盐瓶。在背景中,蓝灰色的猫Tom坐在圆木桌旁,正在吃金黄色的派。棕色的老鼠Jerry站在盐瓶旁边的台面上。Jerry最后拍了拍肚子,然后向左转,快速沿着台面向场景右侧跑去。镜头捕捉到Jerry消失在屏幕外,end_seene>
<start_scene>房子的前部有浅蓝色的墙壁、一扇白色的木制前门,旁边有一个小圆形白色门铃按钮,以及一个小阳台,有台阶通向整洁的绿色草坪。红色和黄色的明亮花朵沿着小路排列,阳光温暖地洒满区域。棕色的老鼠Jerry从右侧平静地走上阳台,向场景中心的门和门铃移动。镜头平稳地追踪Jerry的脚步,清晰地捕捉到他穿过阳台,来到台阶附近,谨慎地向上瞥了一眼门铃。
故事继续…
图8。展示3.2小节中讨论的三种提示格式:(1)剧情的简短摘要,(2)句子级别的描述段落的描述,以及(3)详细的故事板。