kafka高可用数据不丢失不重复分区内有序性
系列文章目录
文章目录
- 系列文章目录
- 一、acks的确认机制
- 二、重试机制+幂等性
- 三、总结
- 四、kafka事务如何保证精准一次持久化?
- 1、kafka事务基本流程
一、acks的确认机制
2个重要的参数: acks和min.insync.replicas
将acks=all和min.insync.replicas结合起来,就能保证数据端到端的高可用。其中acks是producer生产者端配置参数,min.insync.replicas是broker端配置参数
acks参数指定了必须要有多少个分区副本收到消息,生产者才认为该消息是写入成功的
kafka版本<3.0, acks=1; >3.0, acks=all或者-1
acks=0, 生产者在发送消息时就认为已经成功写入,不需要等待来自broker端服务器的响应. 只管发,发送即忘,吞吐量高,所有网络带宽都用来发送消息,但是可靠性低
acks=1, 需要等待leader 响应。
acks=-1, 表示所有副本都写入消息,客户端才会收到成功响应
二、重试机制+幂等性
重新发送会造成数据重复,数据乱序。
幂等生产者可以保证发送数据不丢失,分区内数据不重复以及分区内数据的顺序性。
Broker端怎么知道一条消息是不是重复的呢?可以给这条消息加上唯一键标识,唯一键应该选择什么粒度呢?kafka的设计是在分区的维度上设计唯一键,让每个分区的leader判断数据是否重复。选择设计的唯一键是producer+topicPartition维度。
如何保证消息的顺序性呢?生产者在发送消息时会同时发送一个序列号,序列号以topicPartition为基础,从0开始,并随着每条消息的产生而递增。在broker端通过序列号判断消息是否顺序发送。所以,kafka要做到幂等性,就要遵循
- PID: 每个生产者都要有一个Id
- sequence number: 生产者发送消息时会发送一个序列号,序列号以topicPartition为基础,从0开始
- 新消息:beoler新收到的消息的序列号刚好比给给定生产者在本地存储的系列号大1
- 重复消息:broker新收到的消息的序列号小于等于生产者保存的最大序列号
- 失序:Broker新收到的消息序列号-本地最大序列号的差大于1. 意味着有消息丢失了
总结一下,如何解决重复:假设第一批发送到broker,但是由于网络抖动,producer没有收到响应,于是再次发送相同的数据,broker收到数据后会检查seq, 如果baseSeq小于第一批里面的lastSeq,说明重复发送了,那么就会丢弃当前这批数据,给生产者一个ack。
如何解决乱序?由于inFlightRequest可以并行发送多个请求。最大可以发送5个请求,比如下面这组数据,
123,789,456, 乱序
123,456,789,有序
Broker 端对序列号的校验,Kafka 幂等性不能保证请求之间的顺序,但可以确保每条消息的 序列号是严格递增的,从而保证 写入日志的顺序 是正确的。
broker端落盘数据示例
每一个producerbatch会存储第一条消息的序列号,以及最后一条的序列号
baseOffset: 5522708 lastOffset: 5522745 count:38 baseSequence: 239704 lastSequence: 239741 ...|offset: 5522708 CreateTime: xxx sequence: 239704...
|offset: 5522709 CreateTime: xxx sequence: 239705...
|offset: 5522710 CreateTime: xxx sequence: 239706...
|offset: 5522711 CreateTime: xxx sequence: 239707...三、总结
幂等性生产者可以避免分区内消息重复,保持消息的顺序性,即使飞行队列中有多个请求也不例外。借助producerBatch中的序列号,broker可以拒绝任何序列号不等于最后一个序列号+1的消息。 但是幂等性只能保证单个绘画内消息不丢不重复不乱序, 如果producer端重启了,就不能保证了。
幂等性不能跨多个topicPartition,只能保证producer在单个topicPartition内的幂等性。当涉及多个topicPartition时,这些状态信息并没有同步
如果需要实现跨会话,跨多个topicPartition的幂等性,需要使用kafka的事务性。
故事1:
leader收到三条消息,还没回ack,follower还没来得及同步完,leader就挂了
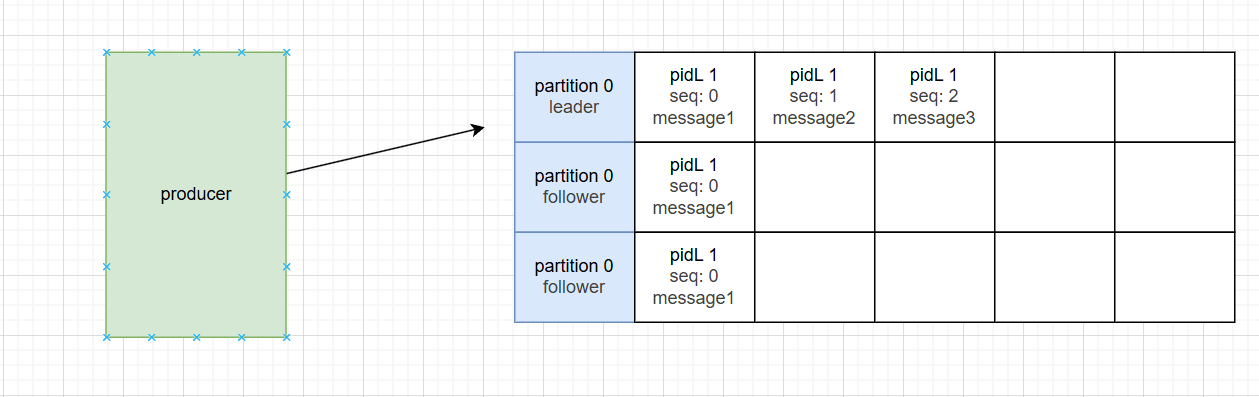
broker现在选出新的leader。producer再次发送三条消息,leader会检查sequence number,也就是说已经收到的message1不会重复消费,follower也会同步最新的message2和message3,所以能保证同一个会话中数据重复问题
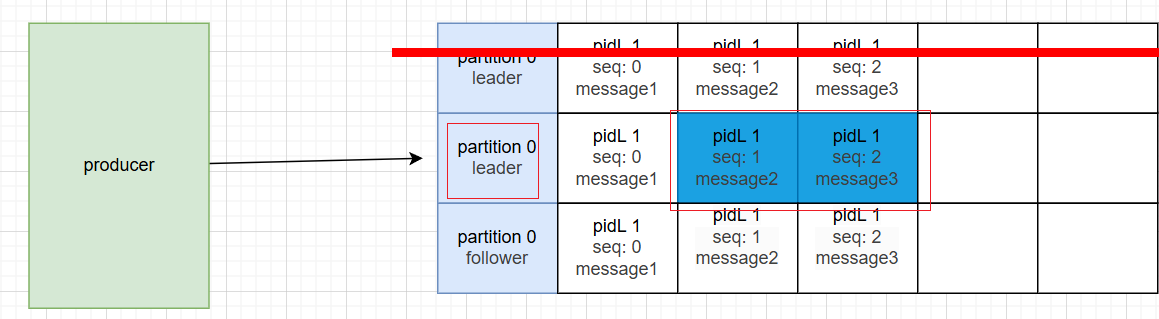
故事2:
生产者宕机,当producer 重启,pid发生变化,消息的key<pid, partition, sequenceNumber>会发生变化,所以producer再次发送三条消息,broker认为是新的数据,导致同一个分区跨会话的消息重复
故事3:
生产者宕机,当producer 重启,pid发生变化,消息的key<pid, partition, sequenceNumber>会发生变化,所以producer再次发送三条消息,假设此时不往protition 0发送,而是向partition1 发送。对于重新启动的生产者来说,会按照下面公式计算路由分区。重启后生产者线程编号!=旧生产者的线程编号,可能导致重启后的生产者将数据发到partition 1。 当然也可能发到partition 0. 于是造成了分区间数据重复。
int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());
newPart = availablePartitions.get(random % availablePartitions.size()).partition();
public int nextPartition(String topic, Cluster cluster, int prevPartition) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);Integer oldPart = indexCache.get(topic);Integer newPart = oldPart;// Check that the current sticky partition for the topic is either not set or that the partition that // triggered the new batch matches the sticky partition that needs to be changed.if (oldPart == null || oldPart == prevPartition) {List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (availablePartitions.isEmpty()) {int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = random % partitions.size();} else if (availablePartitions.size() == 1) {newPart = availablePartitions.get(0).partition();} else {while (newPart == null || newPart.equals(oldPart)) {int random = Utils.toPositive(ThreadLocalRandom.current().nextInt());newPart = availablePartitions.get(random % availablePartitions.size()).partition();}}// Only change the sticky partition if it is null or prevPartition matches the current sticky partition.if (oldPart == null) {indexCache.putIfAbsent(topic, newPart);} else {indexCache.replace(topic, prevPartition, newPart);}return indexCache.get(topic);}return indexCache.get(topic);}四、kafka事务如何保证精准一次持久化?
Kafka 事务(Transactions)机制是为了解决 跨多个分区的消息写入的一致性问题,特别是在使用 幂等生产者(Idempotent Producer) 无法满足需求的场景下。比如:
多个消息需要一起写入不同分区
消息必须要么全部成功写入,要么全部失败(ACID 特性)
1、kafka事务基本流程
Producer 发起事务
使用 beginTransaction() 开始一个事务。
Producer 写入消息到多个分区
每条消息都会携带一个 producer_id 和 sequence_number(类似幂等机制)
消息被写入对应的分区日志中
Producer 提交事务
调用 commitTransaction() 提交事务
或调用 abortTransaction() 中止事务
事务协调器记录事务状态
将事务状态保存到一个特殊的分区(如 __transaction_state 分区)
这个分区由 Kafka 自动维护,用于记录所有事务的状态
Broker 确认事务
Broker 收到提交请求后,会检查事务是否已成功完成
如果是提交,则将这些消息标记为“已提交”
如果是中止,则丢弃这些消息
开启事务: producer将partition信息提交给TC,TC将<transactionId, TopicPartition>的对应关系写到_transaction_state中
producer.send: 往分区中写入数据
准备提交事务: 具体做法就是往分区对应的目录中的最新log文件中写入一条记录,标识之前的消息是否写入成功。
TC修改事务状态
