webrtc弱网-ProbeBitrateEstimator类源码分析与算法原理
一、核心功能
ProbeBitrateEstimator 是 WebRTC 中用于估计网络带宽的探测器类,其主要功能是通过分析探测包(probe packets)的发送和接收情况,来估算当前网络的可用带宽。它在拥塞控制中起到关键作用,帮助确定合适的发送速率。
二、核心算法原理
算法基于发送和接收探测包的时间间隔和数据量来计算带宽:
将属于同一探测簇(cluster)的包进行聚合统计
计算发送端速率:
(总数据量 - 最后一个包大小) / (最后发送时间 - 最先发送时间)计算接收端速率:
(总数据量 - 第一个包大小) / (最后接收时间 - 最先接收时间)取两个速率的最小值作为初步估计
如果接收速率远小于发送速率,则应用目标利用率系数进行调整
三、关键数据结构
struct AggregatedCluster {int num_probes = 0; // 探测包数量Timestamp first_send = Timestamp::PlusInfinity(); // 最早发送时间Timestamp last_send = Timestamp::MinusInfinity(); // 最晚发送时间Timestamp first_receive = Timestamp::PlusInfinity(); // 最早接收时间Timestamp last_receive = Timestamp::MinusInfinity(); // 最晚接收时间DataSize size_last_send = DataSize::Zero(); // 最后发送包大小DataSize size_first_receive = DataSize::Zero(); // 最先接收包大小DataSize size_total = DataSize::Zero(); // 总数据量
};四、核心方法详解
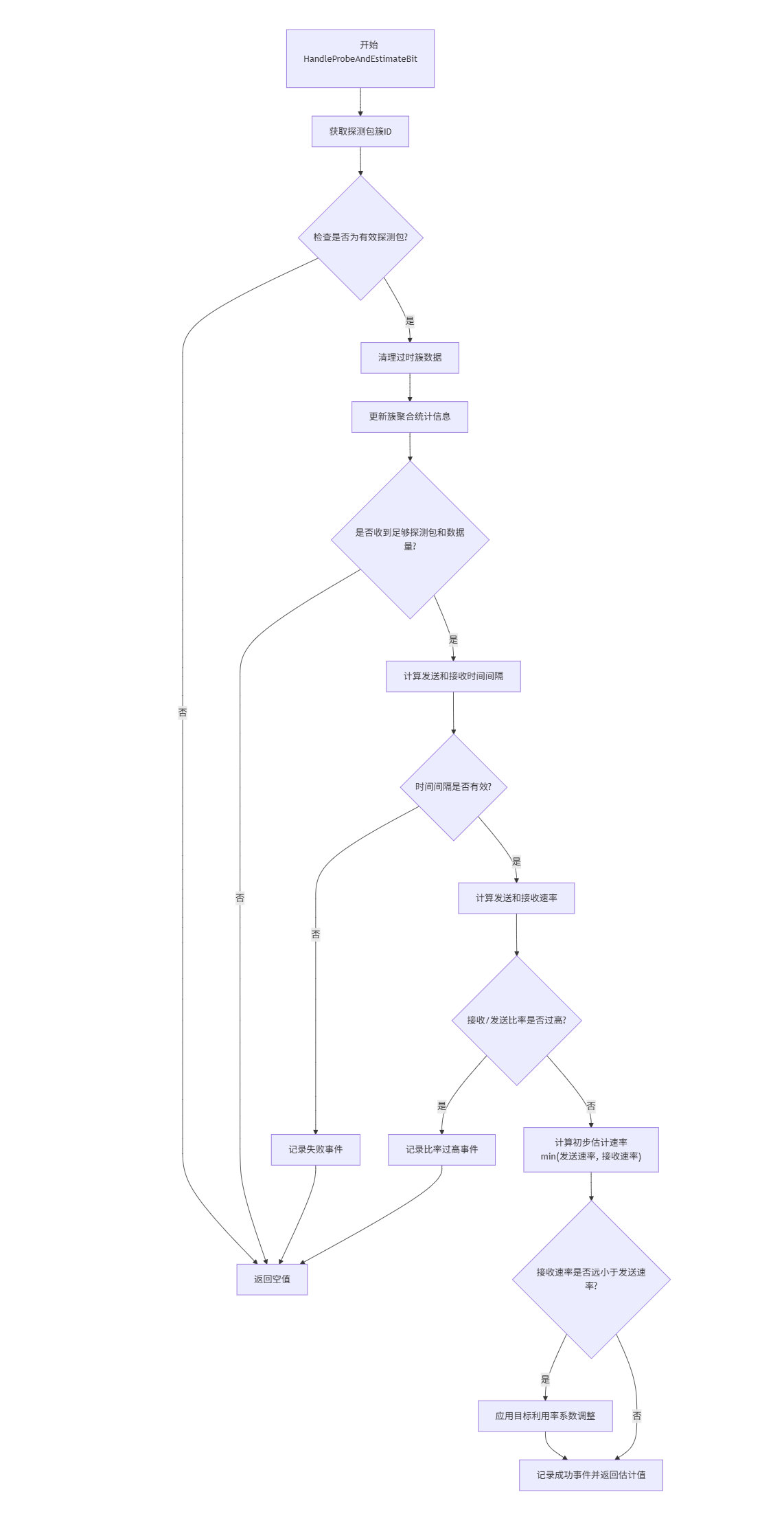
HandleProbeAndEstimateBitrate
absl::optional<DataRate> HandleProbeAndEstimateBitrate(const PacketResult& packet_feedback) {int cluster_id = packet_feedback.sent_packet.pacing_info.probe_cluster_id;// 确认是探测包RTC_DCHECK_NE(cluster_id, PacedPacketInfo::kNotAProbe);// 清理过时的簇数据EraseOldClusters(packet_feedback.receive_time);// 获取或创建对应簇ID的聚合数据AggregatedCluster* cluster = &clusters_[cluster_id];// 更新聚合统计信息(时间窗口和数据量)if (packet_feedback.sent_packet.send_time < cluster->first_send) {cluster->first_send = packet_feedback.sent_packet.send_time;}// ... 更多统计更新代码// 检查是否收到足够多的探测包反馈int min_probes = packet_feedback.sent_packet.pacing_info.probe_cluster_min_probes * kMinReceivedProbesRatio;DataSize min_size = DataSize::Bytes(packet_feedback.sent_packet.pacing_info.probe_cluster_min_bytes) * kMinReceivedBytesRatio;if (cluster->num_probes < min_probes || cluster->size_total < min_size)return absl::nullopt;// 计算发送和接收时间间隔TimeDelta send_interval = cluster->last_send - cluster->first_send;TimeDelta receive_interval = cluster->last_receive - cluster->first_receive;// 验证时间间隔有效性if (send_interval <= TimeDelta::Zero() || send_interval > kMaxProbeInterval ||receive_interval <= TimeDelta::Zero() || receive_interval > kMaxProbeInterval) {// 记录失败事件并返回空值return absl::nullopt;}// 计算发送速率(排除最后一个包)DataSize send_size = cluster->size_total - cluster->size_last_send;DataRate send_rate = send_size / send_interval;// 计算接收速率(排除第一个包)DataSize receive_size = cluster->size_total - cluster->size_first_receive;DataRate receive_rate = receive_size / receive_interval;// 验证接收/发送比率double ratio = receive_rate / send_rate;if (ratio > kMaxValidRatio) {// 比率过高,记录失败事件return absl::nullopt;}// 计算最终估计速率DataRate res = std::min(send_rate, receive_rate);// 如果接收速率显著低于发送速率,应用目标利用率系数if (receive_rate < kMinRatioForUnsaturatedLink * send_rate) {res = kTargetUtilizationFraction * receive_rate;}// 记录成功事件并返回估计值estimated_data_rate_ = res;return estimated_data_rate_;
}EraseOldClusters
void EraseOldClusters(Timestamp timestamp) {// 清理超过最大历史时间的簇数据for (auto it = clusters_.begin(); it != clusters_.end();) {if (it->second.last_receive + kMaxClusterHistory < timestamp) {it = clusters_.erase(it);} else {++it;}}
}五、设计亮点
时间窗口管理:自动清理过期数据,防止内存无限增长
有效性验证:通过多种条件(最小包数、最小数据量、时间间隔、速率比率)确保估计结果的可靠性
排除边界包:在计算速率时排除第一个和最后一个包,减少边界效应的影响
事件日志记录:详细记录探测成功和失败的情况,便于调试和分析
保守估计策略:当接收速率远低于发送速率时,采用目标利用率系数,避免过度乐观估计
六、典型工作流程
发送端发送一组探测包(属于同一探测簇)
接收端收到包后发送反馈
对每个反馈包调用
HandleProbeAndEstimateBitrate方法内部聚合同一簇的包统计信息
当收到足够多的反馈时,计算带宽估计值
通过
FetchAndResetLastEstimatedBitrate获取估计结果定期清理过时的簇数据
ProbeBitrateEstimator 在 WebRTC 中是实现网络带宽主动探测的核心组件。它通过分析专门发送的探测数据包的发送和接收情况,估算当前网络的实际可用带宽。该类聚合同一探测簇的包统计信息,计算发送端和接收端速率,并采用保守策略(如目标利用率系数)确保估计结果可靠。其输出为拥塞控制算法提供关键输入,用于动态调整媒体流的发送速率,避免网络过载的同时最大化带宽利用率,是 WebRTC 实现自适应码率控制和保证音视频传输质量的重要基础模块。