高并发内存池(二):三层缓存的整体框架设计


一、什么是高并发内存池
高并发内存池是一种针对多线程高并发场景优化的内存分配管理组件,本质上来讲它是系统和用户之间对于内存管理的一个新的软件层。理解高并发内存池我们首先需要理解在高并发场景(如秒杀系统、高频交易平台、大型分布式服务等)中,传统内存分配方案(如标准库的 malloc/free)暴露出的严重的性能瓶颈和资源浪费问题。
1> 严重的锁竞争
标准内存分配器(如 glibc 的 ptmalloc2、Windows 的 HeapAlloc)为了保证线程安全,会使用全局锁保护内存分配 / 释放过程。在高并发场景下:
- 大量线程同时申请 / 释放内存时,会频繁竞争同一把锁,导致线程阻塞等待(“锁争用” 问题)。
- 锁等待会浪费大量 CPU 资源,甚至出现 “CPU 利用率不高但吞吐量极低” 的现象(例如,1000 个线程竞争锁时,实际并行处理的线程可能不足 10 个)。
举例:某秒杀系统每秒有 10 万次请求,每个请求需要 5-10 次内存分配(如创建请求对象、临时缓冲区等)。使用 malloc 时,线程会频繁卡在锁等待上,导致系统响应延迟从毫秒级飙升至秒级,甚至触发超时。
2> 分配效率低下,无法适配高频小对象分配
高并发场景中,内存分配的典型特征是 **“高频次、小对象”**(如网络数据包、任务结构体、缓存项等,通常小于 1KB)。传统分配器的设计目标是 “通用”(适配各种大小的对象),导致:
- 分配逻辑复杂:需要遍历空闲链表、合并碎片、计算对齐等,单次分配耗时较长(通常在几十到几百纳秒,高频次下会累积成显著开销)。
- 小对象分配冗余:为了满足内存对齐(如 8 字节、16 字节对齐),小对象分配会产生大量 “内部碎片”(例如,分配 1 字节实际占用 8 字节),浪费内存。
高并发内存池会针对小对象做专门优化(如按大小分类的 “对象池”),单次小对象分配可优化至 10 纳秒以内,且几乎无碎片。
3. 内存碎片严重,利用率极低
频繁的分配和释放会产生内碎片与外碎片问题,在高并发场景下会被无限放大:
某分布式缓存服务使用 malloc 管理内存,运行 24 小时后,内存利用率可能从 80% 骤降至 30%(大量内存被碎片占用),不得不重启服务释放碎片,严重影响可用性。
为了避免与解决上述问题,我们在用户和系统之间设计了一种高效的内存管理的方案即高并发内存池这是为高并发场景量身定制的性能优化工具。
高并发内存池通过分层设计(通常为 Thread-Cache → Central-Cache → Page-Cache)和针对性优化,实现了四大核心目标:
| 核心目标 | 解决的传统方案痛点 | 具体实现思路 |
|---|---|---|
| 无锁 / 低锁并发 | 全局锁竞争导致吞吐量低 | 线程优先使用 Thread-Cache(线程私有,无锁),仅当本地缓存不足时才访问全局缓存。 |
| 极致分配效率 | 通用分配逻辑复杂、耗时高 | 按对象大小分类管理(如 8B、16B、32B...),小对象直接从对应 “槽位” 快速分配。 |
| 近乎零碎片 | 内 / 外部碎片导致内存利用率低 | 小对象复用固定大小块(无内部碎片),大对象按页分配并支持合并(无外部碎片)。 |
下面我们概括性介绍一下高并发内存池的三级缓存:
二、三级缓存设计
2.1 ThreadCache
ThreadCache是直接面向用户对象的缓存设计,就类似一个饭馆中的店小二。它主要向用户提供两个接口,一个用来申请内存一个用来释放内存。但与上一章定长内存池的设计不同,我们的高并发内存池要支持任意大小的内存空间的申请与释放。
在上一章定长内存池的设计中自由链表(_FreeList)的作用是回收并管理用户主动释放或者生命周期到期的对象的空闲内存块。当用户需要一小块内存空间时会首先检查_FreeList是否为空,不为空则直接Pop一个空闲内存块,如果为空则再去大块内存资源上进行切分。我们发现对比直接从自由链表Pop一个内存块,去大块内存资源上进行切分显得十分浪费时间:
从自由链表中获取内存块的操作极其简单,本质是 指针移动”:
- 自由链表的表头指针指向第一个空闲块;
- 分配时,只需将表头指针更新为 “第一个块的 next 指针”(即跳过当前块);
- 返回这个被 “摘下” 的块的地址。
整个过程仅涉及2-3 次指针读写操作(读取表头→读取块的 next→更新表头),无需复杂计算,且这些指针通常存储在 CPU 缓存中(因频繁访问),耗时极短。
可以理解为:自由链表就像 “提前打包好的快递盒”,需要时直接从货架上拿一个,无需拆箱或裁剪。
从大块内存中切割新内存块,是一个 “从零构建可用内存块” 的过程,步骤复杂且耗时:
- 定位可用的大块内存:内存池需要先找到一块 “未被完全使用的大块内存”(可能需要遍历页缓存的管理结构,如空闲页链表);
- 计算切割位置:根据需要分配的大小(如申请 32B),在大块内存中确定切割的起始地址(需满足内存对齐,如 8 字节对齐);
- 切割与标记:从大块内存中 “切出” 32B 的块,同时更新大块内存的元数据(标记已使用区域和剩余空闲区域的边界);
- 处理剩余空间:切割后剩余的空间(如 4KB 大块切出 32B 后还剩 4064B)需要被记录到对应的空闲结构中(可能需要创建新的自由链表节点)。
这些步骤涉及多次内存读写、边界计算、元数据更新,甚至可能触发缓存失效(因访问的大块内存地址可能不在 CPU 缓存中)。整个过程耗时通常是自由链表 Pop 的好几倍。
为了提高效率,在ThreadCache中会维护多个自由链表,每个自由链表的成员都是固定大小的空闲内存块,但是链表之间的成员大小并不相同:
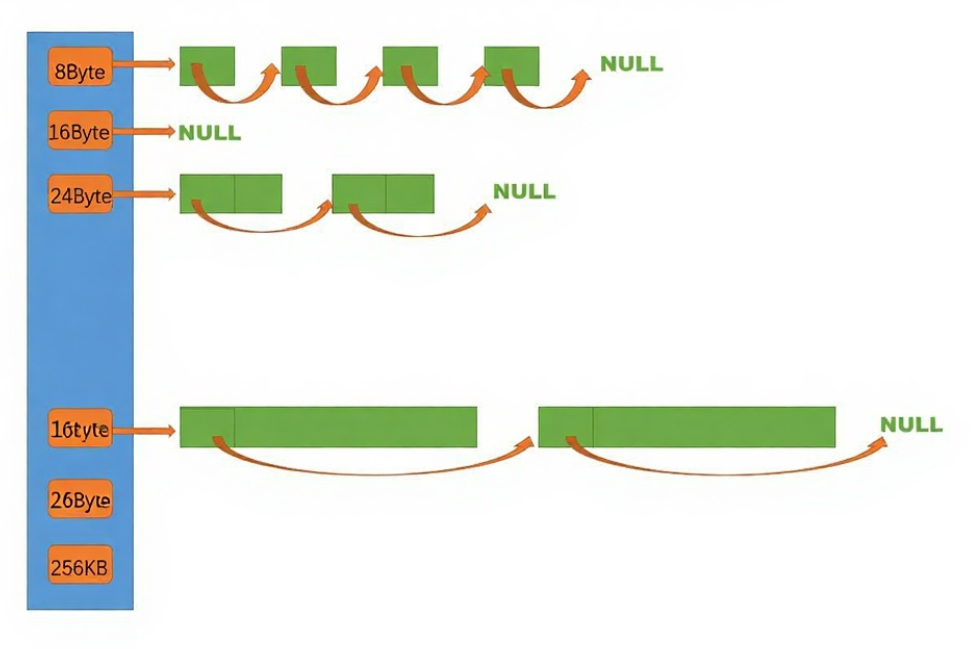
这主要是为了高效地分配不同大小地内存块,当用户需要一块8字节的内存空间时直接去成员为8字节内存块的自由链表Pop一个内存块,当用户需要一块24字节的内存空间时直接去成员为24字节内存块的自由链表Pop一个内存块,相比于频繁地切分大块资源分配预先准备好的空闲内存块大大提高了分配效率。
ThreadCache除了处理用户申请内存空间的请求还有管理释放后回到内存池的内存块的功能。这些内存块会被用来重新分配给用户。
除了这些ThreadCache每个线程独有一份,存储在线程本地存储(TLS,Thread Local Storage)中,其他线程无法访问。线程操作自己的ThreadCache无需加锁,分配 / 释放效率极高(纳秒级),彻底避免锁竞争。
2.2 CentralCache
CentralCache全局唯一,所有线程共享,是 Thread Cache 与 Page Cache 的桥梁。与 Thread Cache 类似,按大小类维护自由链表,但为了避免多线程访问每个链表对应一把锁(如自旋锁),仅当操作某类内存块时才竞争对应锁。
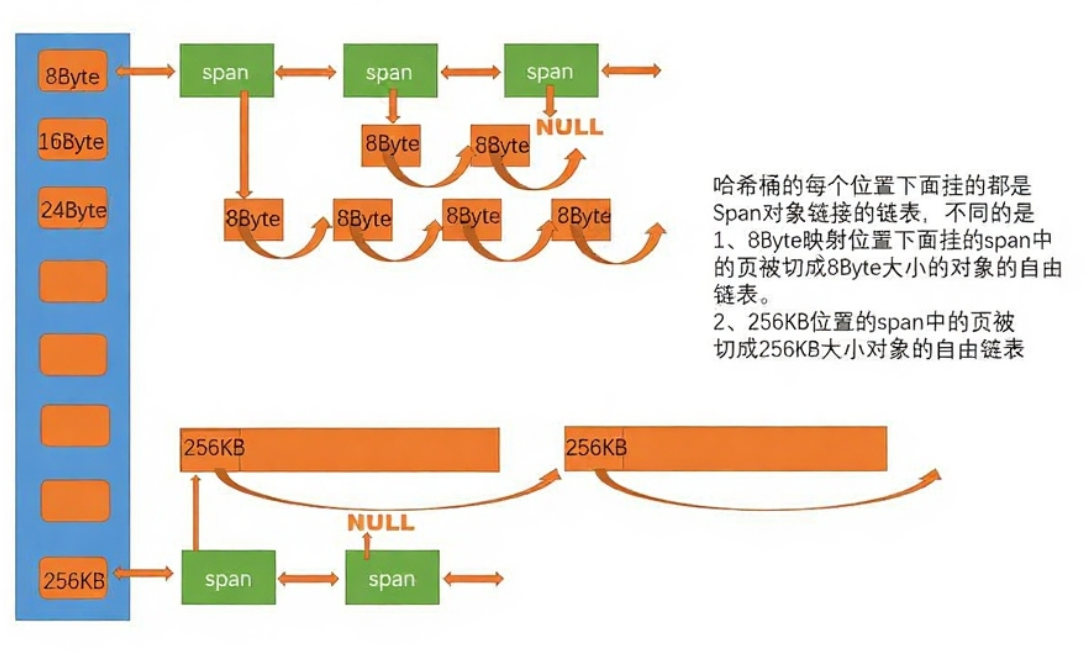
当 Thread Cache 某大小类链表为空时,会向 Central Cache 的同类链表(也就是管理相同大小内存块的自由链表)申请一批内存块。Central Cache 会从自己的链表中取出指定数量的内存块并分配给上层ThreadCache,除了为 Thread Cache 提供批量内存块补充外,当 Thread Cache 某链表满时,会将多余的块批量归还给 Central Cache 的同类链表,Central Cache 会合并相邻的空闲块(若可能),减少外部碎片。
2.3 PageCache
PageCache用来管理大块内存,对接操作系统的 “底层”。在多线程环境下PageCache全局唯一,类似于上一章定长内存池中的_memory管理的大块内存资源管理从操作系统申请的大块内存(以 “页” 为单位,如 4KB、8KB、16KB 等)
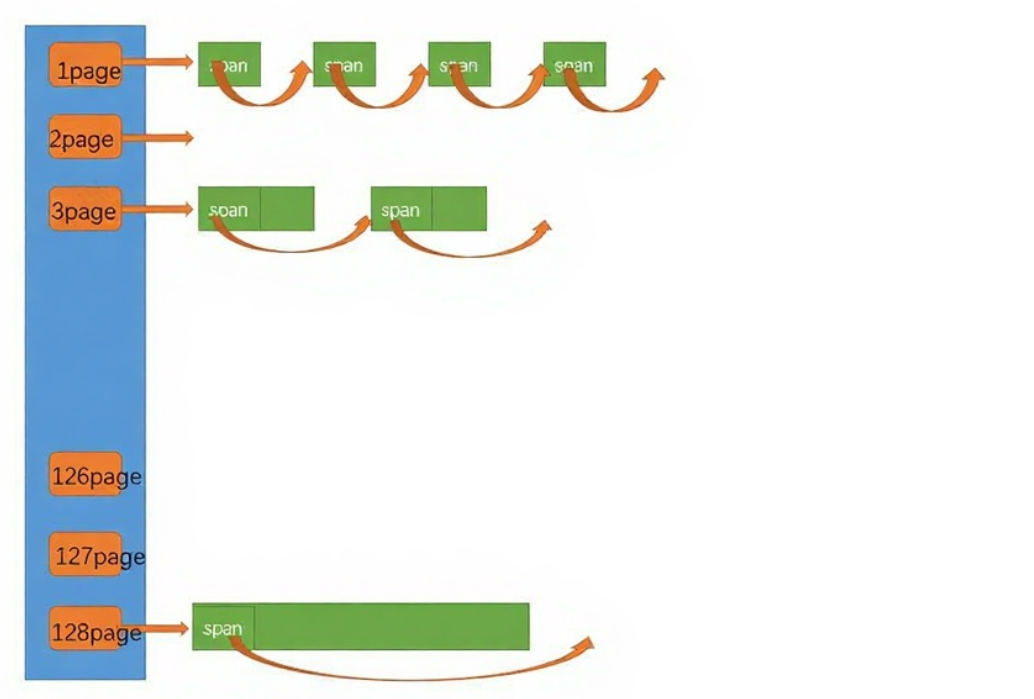
核心作用:向 Central Cache 提供大块内存,切割后供上层使用;同时接收 Central Cache 回收的内存块,合并成大块后按需归还给操作系统。
数据结构:按 “页数量” 维护空闲链表(如 1 页、2 页、4 页… 最大页),每个链表存储连续的物理页块(称为 “Span”),并为每个 Span 记录页号、大小等元数据。
三级缓存是高并发内存池的 “灵魂架构”,通过 “线程私有→全局共享→系统交互”** 的分层设计,完美解决了传统内存分配器的锁竞争、效率低、碎片多等问题。其中,Thread Cache 负责 “快”,Central Cache 负责 “匀”,Page Cache 负责 “省”,三者协同让高并发场景下的内存管理既高效又稳定。
三、总结
| 层级 | 归属与访问权限 | 核心作用 | 关键设计与优势 |
|---|---|---|---|
| Thread Cache | 线程私有(TLS 存储) | 处理 90%+ 的分配 / 释放请求,是性能核心 | 按 “大小类” 维护自由链表,完全无锁,分配 / 释放仅需操作指针(纳秒级效率),彻底避免锁竞争 |
| Central Cache | 全局共享 | 为 Thread Cache 批量 “补内存”、接收其批量 “还内存”,协调线程间资源均衡 | 按 “大小类”+桶锁(仅同类内存竞争),避免全局锁瓶颈;合并空闲块,减少碎片 |
| Page Cache | 全局共享 | 对接操作系统,管理大块内存(以 “页” 为单位) | 按 “页数量” 维护连续内存块(Span),合并相邻空闲块(减少外部碎片);批量与系统交互(减少mmap/munmap等系统调用开销) |
对于高并发内存池的设计中只是一味地看文章是不够地,更要上手实践。在之后的文章中我们会对三级缓存进行更加细致入微的讲解,之后我们会对C++中内存的管理的理解更上一步台阶。