TGRS | 视觉语言模型 | 语言感知领域泛化实现高光谱跨场景分类, 代码开源!
TGRS | 视觉语言模型 | 语言感知领域泛化实现高光谱跨场景分类, 代码开源!

论文信息
题目:Language-Aware Domain Generalization Network for Cross-Scene Hyperspectral Image Classification
出版:TGRS
日期:2023-01-03
第一作者:Yuxiang Zhang
通讯作者: Mengmeng Zhang
单位:北京理工大学
代码:https://github.com/YuxiangZhang-BIT/IEEE_TGRS_LDGnet
原文链接:LDGnet
一、总结
1.1 概述
Purpose: Summarize your contributions
Style:
-What is the problem
在高光谱图像(HSI)分类任务中,包括有关土地覆被类别的大量先验知识在内的文本信息一直被忽视。探索语言模式在辅助高光谱图像分类中的有效性是有必要的。
此外,大规模预训练图像-文本基础模型在各种下游应用(包括零样本传输)中表现出色。然而,大多数领域泛化方法从未涉及挖掘语言模态知识以提高模型的泛化性能。
-What is the work
为了弥补上述不足,我们提出了一种语言感知领域泛化网络(language-aware domain generalization network,LDGnet),从跨域共享先验知识中学习跨域不变表示。
-Features of the work
所提出的方法只在源域(SD)上进行训练,然后将模型转移到目标域(TD)。双流架构包括图像编码器和文本编码器,用于提取视觉和语言特征,其中粗粒度和细粒度文本表征设计用于提取两个层次的语言特征。
此外,语言特征被用作跨领域的共享语义空间,并通过语义空间的监督对比学习完成视觉-语言配准。
-Results
在三个数据集上进行的广泛实验证明,与最先进的技术相比,所提出的方法更胜一筹。
1.2 主要成就
- 以语言为导向的HSI分类框架的工作,引入具有先验知识的语言模式作为监督信号改善了视觉表征学习。
- 由语言特征组成的语义空间被视为跨域共享空间,视觉特征通过视觉-语言配准映射到语义空间,以最小化跨域差异。
- 在语义空间中,设计粗粒度和细粒度文本表征,丰富语义监督信号,促进领域不变表征学习。
1.3 核心思想
LDGnet通过手工设计的粗粒度和细粒度语言特征来辅助视觉表征学习,并使用有监督的对比学习来将视觉特征投射到语义空间,以实现领域无关(domain-invariant)的分类。
二、研究目标
- 大多数基于 CNN 的分类方法只适用于固定场景
⟹\Longrightarrow⟹ 开展源域(SD)和目标域(TD)之间的跨场景域适应(DA)分类任务
- 域泛化(DG)作为一种更难的任务被提出,但是大多都胡DG都在考虑如何从多个 SD 或单个 SD 学习视觉层面的领域不变表征,从未尝试过利用语言知识来辅助视觉表征学习,并通过视觉-语言一致性来实现泛化。
⟹\Longrightarrow⟹ 提出了一种适用于HSI的多模态域泛化框架,即语言感知域泛化网络(LDGnet)
三、研究的背景以及问题陈述
3.1 Introduction
受深度学习(DL)技术成功的启发,基于卷积神经网络(CNN)的遥感图像分类受到广泛关注,并取得了卓越的性能,尤其是在高光谱图像(HSI)分类方面。
然而,大多数基于 CNN 的分类方法只适用于固定场景,即训练样本和测试样本是独立且相同分布的。在获取 HSI 的过程中,不可避免地会受到各种因素的影响,如传感器非线性、季节和天气条件等,从而导致同一土地覆盖类别的源域(SD)和目标域(TD)之间的光谱反射率发生变化。
因此,在跨场景分类任务中,基于 CNN 的分类具有较高的泛化误差和较差的解释效果。值得欣慰的是,迁移学习有助于解决这一问题,其中基于**域适应(domain adaptation,DA)**的方法被广泛用于跨场景分类。从 DA 的角度来看,已经开发出许多用于跨场景分类的 DA 方法,其中最主要的是基于统计、子空间学习、主动学习或 DL 的相关方法。
近年来,计算机视觉领域出现了一种难度更大的任务,域泛化(domain generalization,DG)。**DA 的训练样本是有标签的 SD 和无标签的 TD,即模型在训练过程中会访问 TD;而 DG 的训练样本只有有标签的 SD,不允许访问 TD。**DG 的目标是从一个或几个不同但相关的领域(即不同的训练数据集)中学习一个模型,该模型在 TD 上具有良好的泛化能力。
将遥感图像与语言相结合以完成图像标题、图像分类和图像检索等任务是主要研究方向之一。从遥感图像中提取视觉特征并生成描述已成为一项具有挑战性的任务。
目前,大多数 DG 论文都在考虑如何从多个 SD 或单个 SD 学习视觉层面的领域不变表征。他们从未尝试过利用语言知识来辅助视觉表征学习,并通过视觉-语言一致性来实现泛化。此外,已有研究证明,在多模态学习中,语言有助于视觉表征学习。然而,在HSI分类任务中,缺乏最能反映土地覆被类别先验知识的文本信息。因此,如何构建一个多模态学习工具来帮助学习者更好地理解地表信息,是一个值得思考的问题。
为解决上述问题,提出了一种适用于HSI的多模态域泛化框架,即语言感知域泛化网络(LDGnet)。
语言知识被视为 SD 和 TD 之间的共享知识。语义空间统一了包含先验知识的视觉模态和语言模态。
设计了一种简洁的视觉-语言对齐策略,以减少领域偏移并提高模型的通用性。具体来说,LDGnet 分成三个部分:图像编码器、文本编码器和视觉语言对齐。
在视觉模式中,图像编码器使用深度残差三维 CNN 网络从图像补丁中提取视觉特征。其次,为了在语言模式中创建语义空间,粗粒度和细粒度文本描述旨在为监督信号补充语义信息。文本编码器使用通用语言模型transformer。
**LDGnet 的核心设计是视觉语言对齐策略,其中语义空间被视为跨域共享空间。**为了学习与领域无关的表征,使用了有监督的对比学习来将视觉特征投射到语义空间。
3.2 Related work
Domain Generalization (DG)
DG 比 DA 更具挑战性,因为 DG 的目标是通过 SD 数据学习模型,而不需要在训练阶段访问 TD。模型可以在推理阶段扩展到 TD。
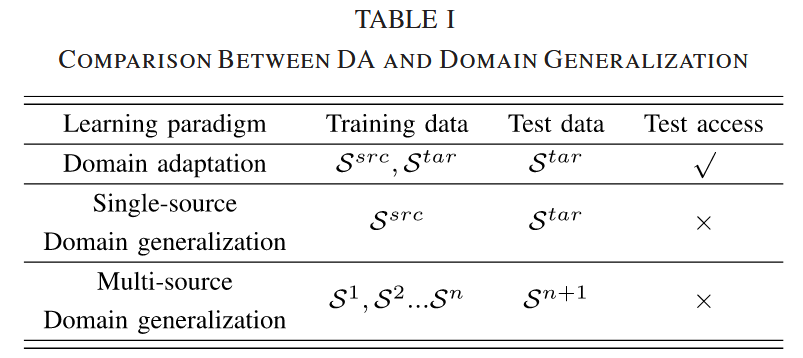
DA 和 DG 的比较,其中 S 代表domain领域。
现有的 DG 方法分为两类:学习领域不变表示法和数据操作法。
- 第一类方法的主要思想是减少多个 SD 领域表征之间的领域偏移,主要应用于多源 DG。最典型的策略是显式特征对齐。
- 数据处理主要应用于单源 DG。这类方法一般会增加或生成与 SD 相关的域外样本,然后使用这些样本训练 SD 模型并将其转移到 TD。数据生成可以创建多样化和丰富的数据,以帮助泛化。例如,变异自动编码器(VAE)和生成式对抗网络(GANs) 经常用于这些目的。
Image–Text Foundation Models
一些研究提出了图像-文本基础模型,这些模型通过对大规模图像-文本对的预训练学习两种模态之间的强联合表征,并在一些下游视觉和语言任务中表现出极佳的可移植性。主流的图像-文本基础模型根据其模型架构设计分为两类:单流(两种输入模态的早期融合)和双流(后期融合)。前者将 VisualBERT [31] 和统一模态预训练架构(UNIMO)中的图像和文本输入嵌入合并在一起,在单一语义空间的单一transformer中对图像和文本表示建模。而后者则使用解耦图像编码器和文本编码器进行高级表征,如对比语言图像预训练(CLIP) 和 Coca ,对图像和文本进行独立编码。CLIP、DeCLIP 和 Coca 采用对比学习作为训练目标。对比学习的主要原理是自动建立相似的正向样本对和不相似的负向样本对,目的是使正向样本对在投影空间中相互靠近,负向样本对相互远离。本文在 LDGnet 中使用了双流架构和对比学习,以实现灵活的设计和相对低廉的计算成本。
四、模型详解
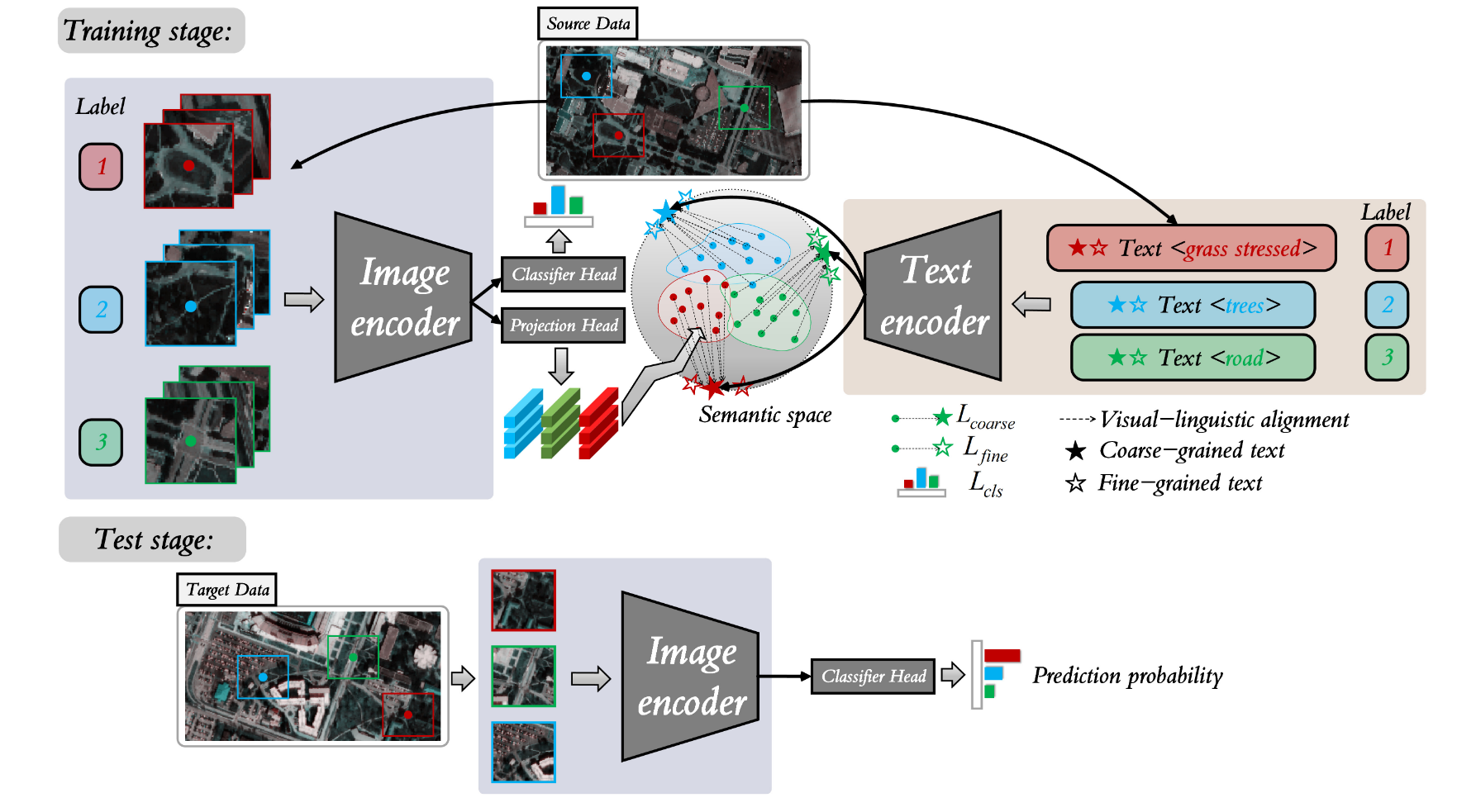
LDGnet 的流程图。
在训练阶段,图像编码器提取视觉特征,文本编码器提取粗粒度和细粒度语言特征,形成语义空间。然后,利用视觉语言对齐来缩小视觉特征与语言特征之间的类别差距,最后输出视觉模态的分类预测概率。
在测试阶段,图像编码器和分类器头用于预测来自 TD 的图像Patch。红色、绿色和蓝色分别代表三个类别。
在语义空间中,圆点代表视觉特征,五角星代表语言特征。
4.1 概述
LDGnet 分为三个部分:图像编码器、文本编码器和视觉语言配准。
从SD图像中选取 13×13×d13 × 13 × d13×13×d 的空间Patch样本,根据Patch的类别为每个Patch分配一个粗粒度文本和两个细粒度文本。
在视觉模式下,图像被传送到图像编码器提取特征,然后分类头 Cls 用于计算交叉熵损失,投影头 Proj 输出视觉特征进行视觉-语言对齐。
为了提取语言特征并创建跨域共享语义空间,文本被传递给文本编码器。
最后,监督对比学习用于视觉-语言对齐,按类别对齐图像和文本。
4.2 Image Encoder
鉴于HSI是由数百个光谱通道组成的三维数据立方体,具有丰富的空间和光谱信息,因此采用深度残差三维 CNN 网络来提取空间-光谱特征,如图所示。
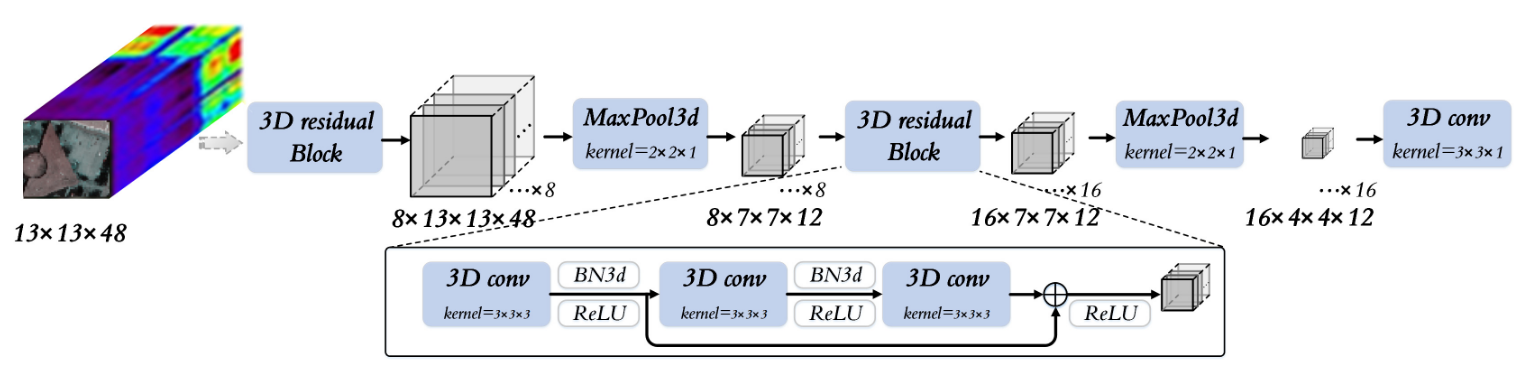
图像编码器由两个 3-D residual Block 、两个MaxPool3d 模块和一个 Conv3d 模块组成,其中 3-D residual Block 是提取鲁棒视觉特征的核心模块。

3-D residual Block的具体组成
Image Encoder 提取的空间-光谱特征被发送到分类头,并与真值数据计算交叉熵。同时,它还被送入投影头,以获得视觉特征,用于视觉模式和语言模式的特征配准。
4.3 Text Encoder
文本编码器是一个语言模型Transformer,根据 Radford 等人的研究进行了修改 (GPT2的结构)。文本编码器以 33M参数、三层、512 宽、八个注意力头的模型为基础。与 CLIP 类似,文本由transformer使用小写字节对编码(BPE)表示,vocabulary size 为 49,152。为了提高计算效率,最大序列长度限制为 76。然后,按层对这一语言特征进行归一化处理,并将其线性映射到语义空间中。
根据 SD 场景中土地覆盖类别的先验知识,为每个土地覆被类别分配粗粒度和细粒度文本描述。
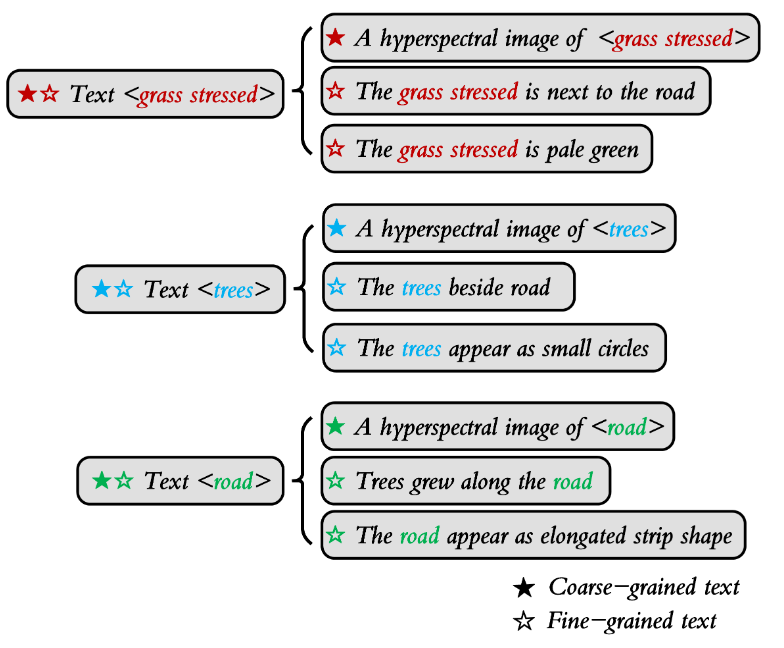
如图 所示,以 *A HSI of < class name>*为模板,以掐头去尾的方式为每个类构建粗粒度文本描述(实心五角星)
对于细粒度文本,则结合先验知识,对颜色、形状、分布和相邻关系进行人工描述,如The grass stress is pale green, The trees beside road, and The road appears as elongated strip shape。每个土地覆盖类别设置两个细粒度文本(空心五角星)
4.4 Visual–Linguistic Alignment
为了缩小视觉特征与语言特征之间的距离,我们进行了有监督的对比学习,并开发了由语言驱动的领域不变表征,从而将模型推广到 TD。
有监督对比损失:
让同一个类别的样本在特征空间里“抱团”聚集,让不同类别的样本彼此“疏远”分离。
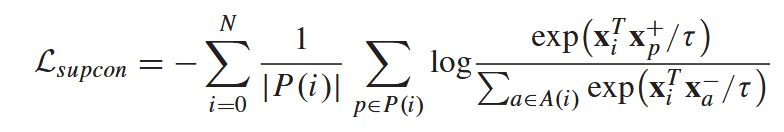
文本-图像粗粒度对比损失:
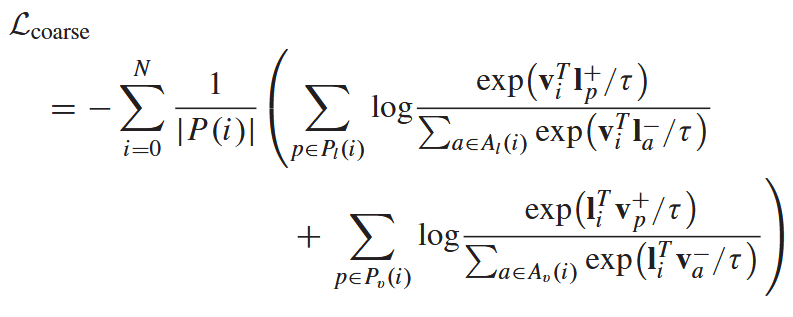
LfineL_{fine}Lfine 的基本公式同上。通过LcoarseL_{coarse}Lcoarse 和 LfineL_{fine}Lfine 优化图像编码器和文本编码器,使同一类别的特征更接近,不同类别的样本更接近。这样,语言知识就可以融入视觉表征的学习过程,从而帮助图像编码器获得特定类别的领域不变表征。在 LDGnet 中,图像编码器和文本编码器是联合训练的。综合上述损失函数,LDGnet 的总损失定义为
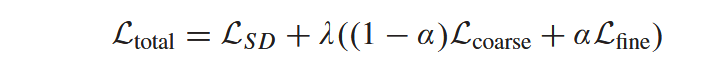
五、实验方法
5.1 数据集
(1) Houston dataset
Houston 2013 and Houston 2018 [43] scenes
(2) Pavia dataset
University of Pavia (UP) and Pavia Center (PC)
(3) Gaofen image dataset (GID)
GID 数据集由武汉大学构建,其中包含在中国许多地区不同时间拍摄的多光谱图像(MSI)。我们选择 2015 年 1 月 3 日在江西南昌拍摄的 GID-nc 作为 SD,2016 年 4 月 11 日在湖北武汉拍摄的 GID-wh 作为 TD。
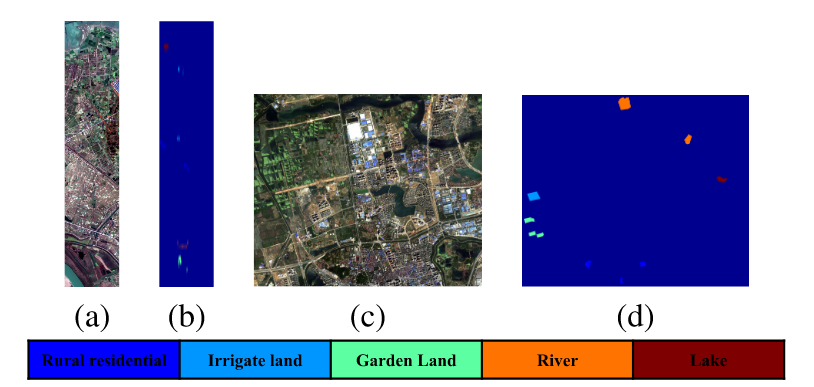
GID 数据集的伪彩色图像和地面真值图。(a) GID-nc 的伪彩色图像 (b) GID-nc 的地面真值图 © GID-wh 的伪彩色图像 (d) GID-wh 的地面真值图。
5.2 实验环境
- patch size:13 × 13
- 采用Adaptive Moment Estimation (Adam)
- 所有模块的 L-2 正则化默认值为 1e-4,用于权重衰减
- 加载 CLIP 预训练的 ViT-B-32.pt作为文本编码器的初始化
A HSI of <class name>用作模板,为每个类生成粗粒度文本描述。
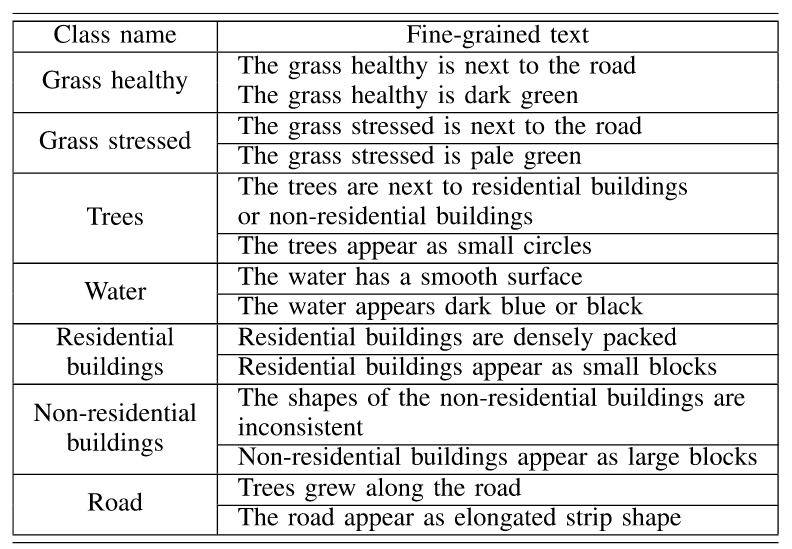
HOUSTON DATASET的细粒度文本表示
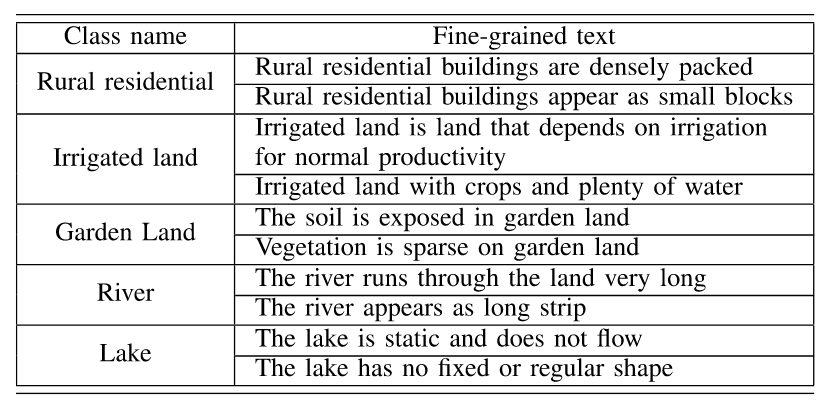
PAVIA DATASET的细粒度文本表示
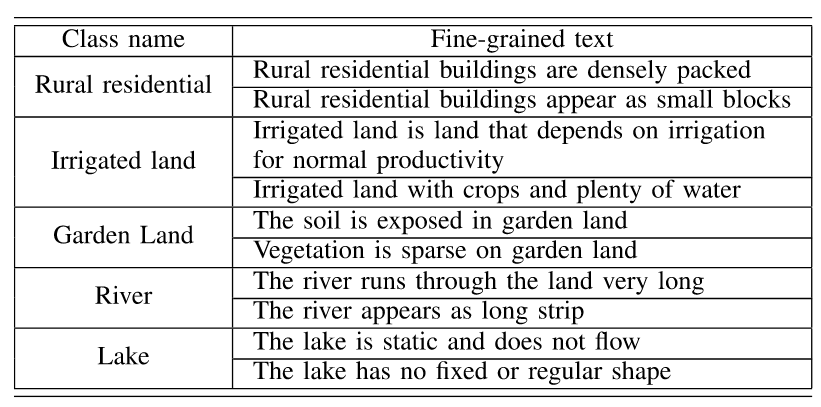
GID DATASET的细粒度文本表示
5.3 消融实验
图像编码器和文本编码器是 LDGnet 的关键组成部分,视觉语言对齐是学习域不变表征的主要策略。通过从整个框架中剔除每个组件来进行消减分析,以评估 LDGnet 重要组件的贡献。
- “LDGnet (cls)”:从 LDGnet 中删除文本编码器和投影头,用于评估图像编码器的性能;
- “LDGnet (coarse)”:删除细粒度文本;
- “LDGnet (fine)”:删除粗粒度文本。
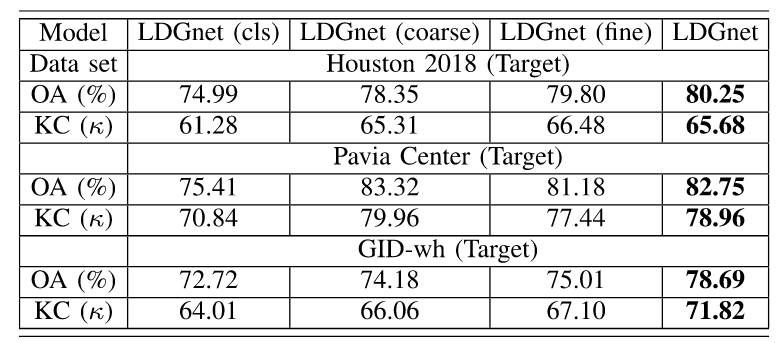
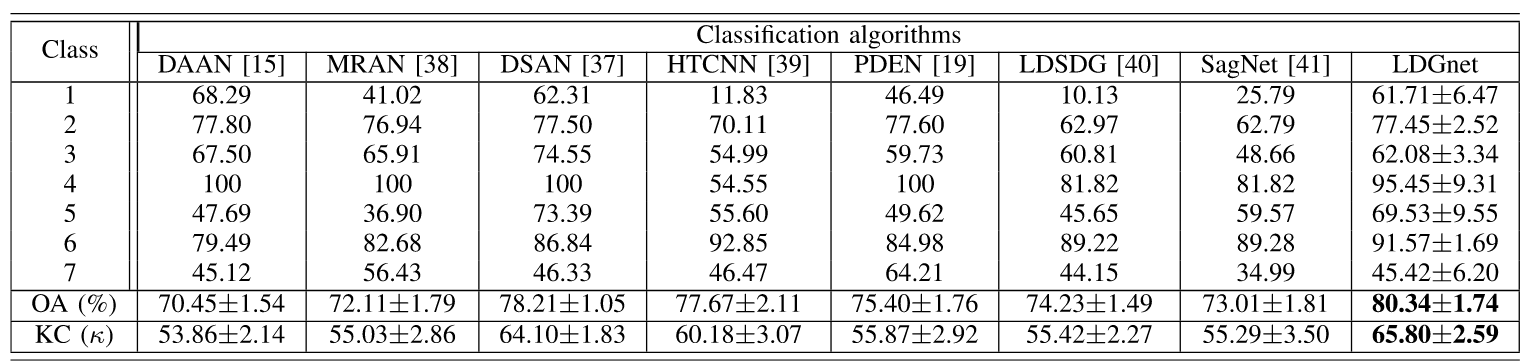
5.4 分类结果

六、结论
提出了结合视觉和语言模式的 LDGnet。使用双流架构同时提取视觉和语言特征。具有先验知识的文本表示被视为跨领域共享知识,旨在指导跨领域不变表示的学习。
具体来说,设计了粗粒度和细粒度文本表示,分别使用基于 CNN 的图像编码器和基于Transformer的文本编码器来提取视觉特征、粗粒度和细粒度语言特征。由语言特征构成的语义空间被视为跨域共享空间,并通过有监督的对比学习来逐步缩小视觉特征与语言特征之间的差距,从而实现视觉语言对齐。最后,为实现 TD 场景泛化,应用了嵌入共同语言知识的图像编码器。
在三个数据集上进行的综合实验验证了所提出的 LDGnet 在领域泛化方面的有效性。