六边形箱图 (Hexbin Plot):使用 Matplotlib 处理大规模散点数据
六边形箱图 (Hexbin Plot):使用 Matplotlib 处理大规模散点数据
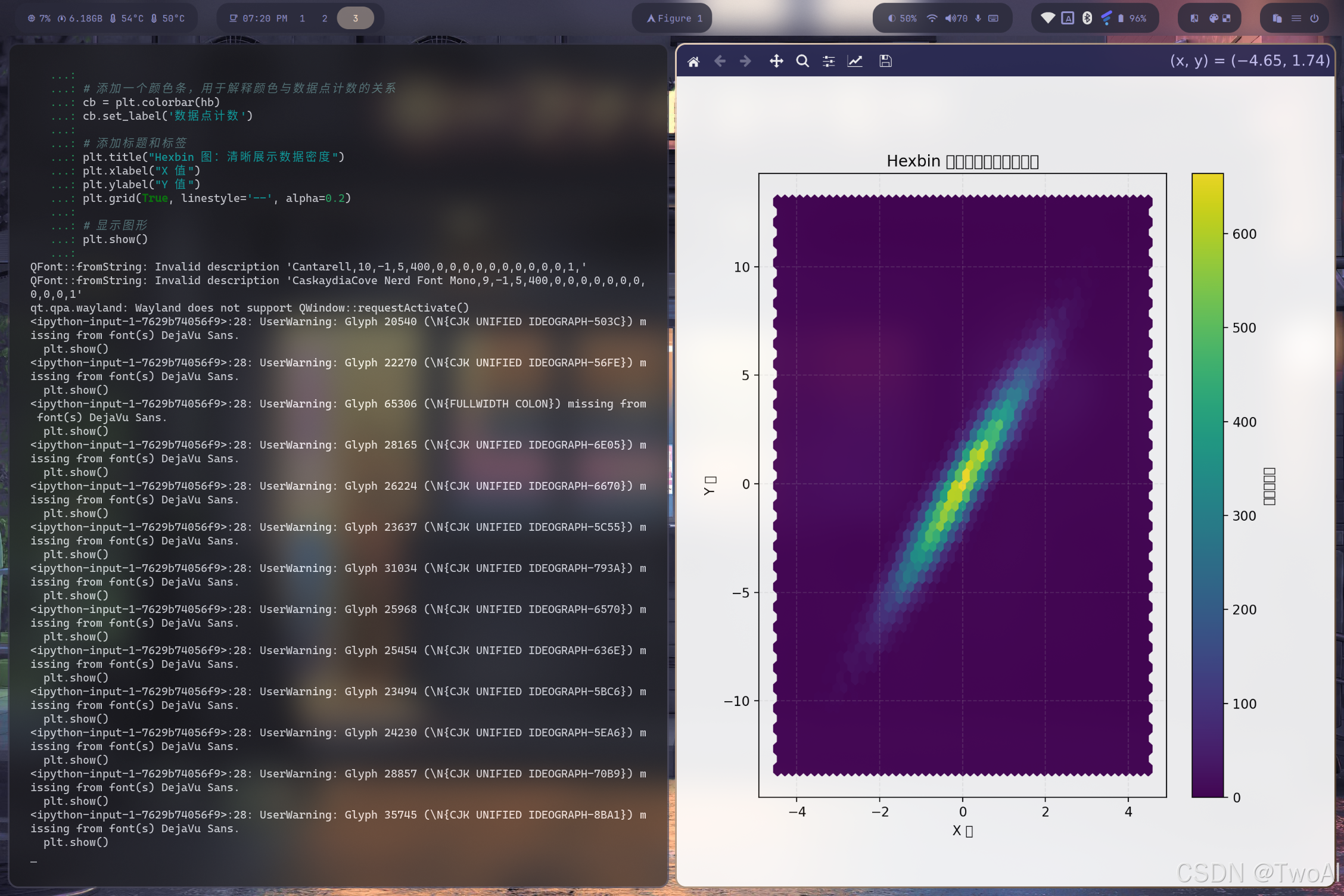
以下代码展示了一个高质量 Hexbin 图的生成过程,它清晰地揭示了大规模数据点的密度分布,是本文核心技术的直观展示。
import numpy as np
import matplotlib.pyplot as plt# 生成 50000 个符合正态分布的数据点
np.random.seed(42)
x = np.random.normal(size=50000)
y = x * 3 + np.random.normal(size=50000)# 创建一个图形实例
plt.figure(figsize=(10, 7))# 绘制 Hexbin 图
# gridsize 控制六边形的数量,值越大,六边形越小
# cmap 定义了颜色映射方案,'viridis' 是一个视觉友好的常用选项
hb = plt.hexbin(x, y, gridsize=50, cmap='viridis')# 添加一个颜色条,用于解释颜色与数据点计数的关系
cb = plt.colorbar(hb)
cb.set_label('数据点计数')# 添加标题和标签
plt.title("Hexbin 图:清晰展示数据密度")
plt.xlabel("X 值")
plt.ylabel("Y 值")
plt.grid(True, linestyle='--', alpha=0.2)# 显示图形
plt.show()
一、引言:当散点图不堪重负
散点图是数据可视化中最基础、最常用的图表之一,用于展示两个数值变量之间的关系。然而,当数据量变得非常大时,传统的散点图会遭遇一个严重的问题——过度绘制(Overplotting)。
成千上万的数据点堆叠在一起,形成一个无法辨认的“墨水团”,这不仅使得图表难以解读,也掩盖了数据真实的密度分布。我们无法分辨哪些区域是数据真正的聚集地,哪些区域只是稀疏地散落着几个点。
看一个过度绘制的例子:
import numpy as np
import matplotlib.pyplot as plt# 生成 50000 个数据点
np.random.seed(42)
x = np.random.normal(size=50000)
y = x * 3 + np.random.normal(size=50000)# 绘制传统散点图
plt.figure(figsize=(8, 6))
plt.plot(x, y, 'o', markersize=2, alpha=0.1)
plt.title("过度绘制的散点图 (50,000 个点)")
plt.xlabel("X 值")
plt.ylabel("Y 值")
plt.grid(True)
plt.show()
面对这样的“墨水团”,我们需要一种更智能的可视化方法来揭示其内部结构。六边形箱图(Hexbin Plot) 正是为此而生的强大工具。
在深入这项技术前,若想在数据分析和编程学习中获得智能助力,不妨了解一下这款强大的 AI 助手。
AI 助手推荐
- 官网:
https://0v0.pro- 特色:
- 🆓 开源模型全免费:Llama、Qwen、Deepseek 等。
- 😲 基础模型全免费:gpt-4o、o4-mini 、gpt-5-mini 等。
- ♾️ 对话真正无限制:不限时间、不限次数。
- 🫡 每周免费一个旗舰模型:本周免费 gpt-5,不限使用!
二、六边形箱图 (Hexbin Plot) 的工作原理
Hexbin 图是一种二维密度图,它的工作方式如下:
- 划分网格:将整个二维绘图空间划分为一系列规则的六边形网格。
- 计数聚合:统计每个六边形“箱子”(bin)中落入了多少个数据点。
- 颜色映射:根据每个六边形内数据点的数量,为其赋予不同的颜色。通常,数据点越密集的区域,颜色越深。
为什么是六边形?
选择六边形而不是正方形(像二维直方图那样)是有原因的。在所有能够无缝平铺平面的形状中,六边形最接近圆形,这意味着它在聚合数据时,从中心到各个边缘的距离更加均匀,从而减少了因网格形状带来的视觉偏差。
三、使用 Matplotlib.pyplot.hexbin
Matplotlib 的 pyplot 模块提供了 hexbin() 函数,让我们可以轻松创建六边形箱图。
1. 基础 Hexbin 图
让我们用 hexbin 来重新绘制上面那个“墨水团”例子。
import numpy as np
import matplotlib.pyplot as plt# 使用与之前相同的数据
np.random.seed(42)
x = np.random.normal(size=50000)
y = x * 3 + np.random.normal(size=50000)plt.figure(figsize=(10, 7))# 绘制 Hexbin 图
hb = plt.hexbin(x, y, gridsize=50, cmap='viridis')# 添加颜色条
cb = plt.colorbar(hb)
cb.set_label('数据点计数')plt.title("Hexbin 图:清晰展示数据密度")
plt.xlabel("X 值")
plt.ylabel("Y 值")
plt.grid(True, linestyle='--', alpha=0.2)
plt.show()
效果立竿见见影!现在我们可以清晰地看到数据主要集中在一条对角线上,中心的密度最高,向两边逐渐稀疏。
2. 核心参数详解
plt.hexbin() 提供了丰富的参数来控制图表的外观和行为。
gridsize
控制六边形网格的粒度。它接受一个整数或一个元组 (nx, ny)。
- 整数:表示在 x 方向上六边形的数量,y 方向的数量会自动计算以保持六边形形状规则。
- 值越大,六边形越小,分辨率越高。
# 比较不同 gridsize 的效果
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 6))ax1.hexbin(x, y, gridsize=20, cmap='Blues')
ax1.set_title("gridsize = 20 (低分辨率)")ax2.hexbin(x, y, gridsize=80, cmap='Blues')
ax2.set_title("gridsize = 80 (高分辨率)")plt.show()
cmap
颜色映射(Colormap),用于指定从低密度到高密度的颜色渐变方案。常用的 cmap 包括 viridis (默认), plasma, inferno, magma, cividis, Blues, Reds 等。
bins
控制颜色条的刻度。默认是线性的,但当数据密度差异巨大时(例如,中心点有 1000 个点,而外围只有几个点),使用对数刻度 bins='log' 会非常有用。
plt.figure(figsize=(10, 7))hb = plt.hexbin(x, y, gridsize=50, cmap='inferno', bins='log')cb = plt.colorbar(hb)
cb.set_label('数据点计数 (Log Scale)')plt.title("使用对数刻度的 Hexbin 图")
plt.show()
使用对数刻度后,即使是计数较少的区域也能被清晰地着色,从而展示出更多的细节。
mincnt
设置一个阈值,只有当六边形内的数据点数量大于等于 mincnt 时,该六边形才会被绘制。这对于过滤掉稀疏的背景噪声、聚焦核心分布区域非常有效。
plt.hexbin(x, y, gridsize=50, cmap='viridis', mincnt=10)
plt.title("只显示计数 >= 10 的区域")
plt.show()
3. 高级应用:聚合第三方变量 (C)
Hexbin 图最强大的功能之一是,它不仅可以统计每个六边形内的点的数量,还可以计算这些点第三方变量 C 的统计值(如平均值、总和等)。
假设我们除了 x 和 y 坐标外,还有一个变量 z,我们想知道在数据密集的区域,z 的平均值是多少。
import numpy as np
import matplotlib.pyplot as plt# 生成数据
np.random.seed(42)
n_points = 50000
x = np.random.normal(size=n_points)
y = x * 3 + np.random.normal(size=n_points)
# z 值与 x, y 的距离相关,中心区域 z 值较小
z = np.sqrt(x**2 + y**2)plt.figure(figsize=(10, 7))# C 参数传入 z 值,reduce_C_function 指定聚合函数为求均值
hb = plt.hexbin(x, y, C=z, gridsize=50, cmap='cividis', reduce_C_function=np.mean)cb = plt.colorbar(hb)
cb.set_label('Z 值的平均值')plt.title("Hexbin 图:按 Z 值的平均值着色")
plt.xlabel("X 值")
plt.ylabel("Y 值")
plt.show()
这张图的颜色不再代表点的数量,而是代表落入每个六边形内所有点的 z 值的平均值。这使得 Hexbin 图从一个二维密度图升级为了一个可以展示三维信息的强大工具。
四、自动化数据故事
在创建了像 Hexbin 这样信息丰富的图表后,下一步就是解读它并形成结论。例如,我们可以识别出高密度区域的坐标,或者 z 值最高的区域。这个过程可以借助 AI 自动化。
通过编程方式提取 Hexbin 的计算结果,然后将这些数据(如“密度最高的六边形位于(x, y)附近”)发送给大语言模型(LLM)API,就可以自动生成一份数据摘要或报告。在进行这类探索性开发时,API 成本是一个考量点。
LLM AI API 推荐 🗨️
1. 按量计算 (适合高频使用)
- 官网:
https://llm-all.pro - 优势:
- 😊 主流模型超低价:OpenAI, Claude, Gemini 等模型,价格约为官方的 1 折。
- 🤓 国内模型折扣大:豆包、千问、DeepSeek 等,普遍享受 2-6 折 优惠。
2. 按次计算 (适合轻量或测试)
- 官网:
https://fackai.chat - 优势:
- 高性价比:提供国内外全模型,1 元可购 100 次 调用,非常划算。
五、总结
六边形箱图(Hexbin Plot)是处理大规模散点数据时不可或缺的可视化工具。它完美地解决了传统散点图的过度绘制问题,通过美观的六边形网格和直观的颜色映射,清晰地揭示了数据的密度分布。
何时使用 Hexbin 图?
- 当你的散点图数据点过多,已经变成了一个看不清细节的“墨水团”。
- 当你想直观地了解二维数据的密度分布,找出“热点”区域。
- 当你想在二维平面上可视化第三个变量的聚合统计值。
下次再遇到大规模散点数据时,不妨放弃 plt.plot(),试试 plt.hexbin(),它将为你打开一扇新的数据洞察之门。