【序列晋升】40 Spring Data R2DBC 轻量异步架构下的数据访问最佳实践
目录
一、什么是Spring Data R2DBC?
二、诞生背景与技术演进
2.1 传统JDBC的局限性
2.2 R2DBC技术演进
三、架构设计与组件关系
3.1 核心组件与交互流程
3.2 响应式事务管理
四、解决的问题与优势
4.1 解决的核心问题
4.2 与传统JDBC的对比
五、关键特性与功能
5.1 响应式编程模型
5.2 轻量级Repository抽象
5.3 连接池管理
5.4 动态查询构建
5.5 批量操作支持
六、与同类产品的对比
6.1 与Spring Data JDBC的对比
6.2 与MyBatis-Plus的对比
6.3 与Reactive MongoDB的对比
七、使用方法与最佳实践
7.1 项目搭建与依赖引入
7.2 数据库连接配置
7.3 实体定义与Repository
7.4 数据操作示例
7.5 端到端集成示例
7.6 最佳实践与性能优化
八、常见问题与解决方案
8.1 依赖冲突问题
8.2 连接配置问题
8.3 响应式编程模型问题
九、应用场景与未来展望
9.1 适用场景
9.2 未来发展趋势
十、总结与建议
Spring Data R2DBC是Spring框架为响应式应用提供的关系型数据库访问解决方案,它通过异步非阻塞的编程模型,显著提升了高并发场景下的系统性能和可扩展性。 本文将深入剖析Spring Data R2DBC的核心概念、架构设计、关键特性及使用方法,帮助开发者全面理解这一技术并将其应用于实际项目。

一、什么是Spring Data R2DBC?
Spring Data R2DBC是Spring Data家族的一部分,它实现了对Reactive Relational Database Connectivity(R2DBC)规范的支持,为Java应用提供了响应式关系型数据库访问能力。与传统JDBC不同,R2DBC采用异步非阻塞的编程模型,允许应用在等待数据库响应时继续处理其他任务,从而提高资源利用率和系统吞吐量。
在Spring生态中,Spring Data R2DBC与Spring WebFlux等响应式框架紧密集成,实现了从Web层到数据库层的完整响应式链路。开发者可以通过熟悉的Spring Data抽象(如ReactiveCrudRepository)或低级API(如DatabaseClient)与数据库交互,返回Flux或Mono等响应式类型,无需手动处理异步回调。
Spring Data R2DBC旨在简化概念,它不提供缓存、延迟加载、后写或ORM框架的许多其他功能,而是一个简单、有限、特定情况的对象映射器。这种设计使其能够专注于提供高效、轻量级的响应式数据库访问能力。
二、诞生背景与技术演进
2.1 传统JDBC的局限性
在传统Java后端开发中,JDBC(Java Database Connectivity)是数据库访问的事实标准。然而,JDBC基于同步阻塞IO模型,每个数据库操作会阻塞当前线程,直到数据库返回结果。这种模型在低并发场景下表现稳定,但在高并发场景中存在显著瓶颈:
- 线程资源浪费:为处理并发请求,需创建大量线程(1个请求1个线程),线程切换成本随并发量指数级增长。
- 资源利用率低:线程在IO等待期间处于空闲状态,CPU资源未被有效利用。
- 扩展性受限:垂直扩展(增加CPU/内存)无法线性提升吞吐量,水平扩展(增加服务器)受限于数据库连接池大小。
2.2 R2DBC技术演进
为解决上述问题,R2DBC技术应运而生,其演进路径可分为三个阶段:
- 2017-2018:概念萌芽:Pivotal(现VMware)提出响应式数据库访问需求,社区开始讨论"JDBC的响应式替代方案"。
- 2018-2020:规范落地:Eclipse基金会主导制定R2DBC 1.0规范,定义了
ConnectionFactory、Statement、Result等核心接口,支持MySQL、PostgreSQL、H2等主流数据库的驱动实现。 - 2020至今:生态成熟:Spring Data R2DBC(Spring 5.2+)正式集成,与Spring WebFlux形成"响应式端到端"解决方案,Micronaut、Quarkus等框架跟进支持。
R2DBC的诞生直接回应了高并发场景下传统JDBC的性能瓶颈问题,通过异步非阻塞的编程模型,使关系型数据库能够更好地融入响应式应用架构。 与传统JDBC相比,R2DBC在高并发场景下表现优异,能够显著提高系统吞吐量和资源利用率。
三、架构设计与组件关系
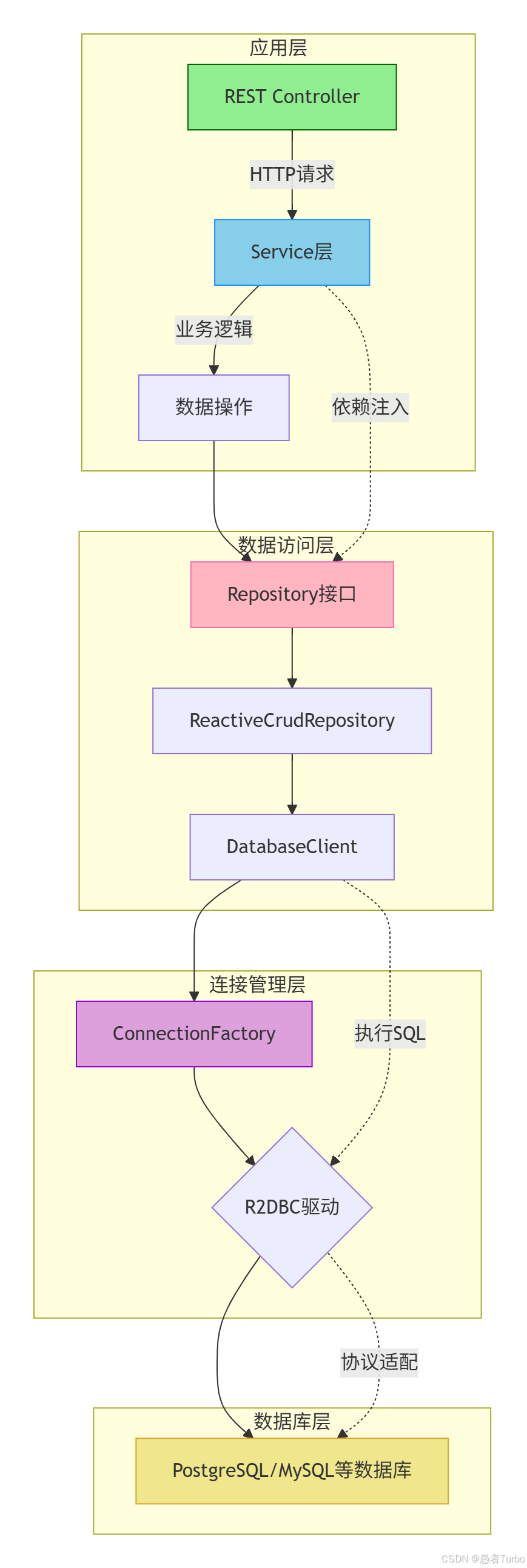
Spring Data R2DBC的架构设计基于R2DBC规范,与Spring生态深度整合。其核心架构可分为四层(从下到上):
| 层级 | 组件 | 职责 |
|---|---|---|
| 数据库层 | PostgreSQL、MySQL、SQL Server等 | 实际存储数据的关系型数据库 |
| 驱动层 | r2dbc postgreSQL、r2dbc mysql等 | 实现R2DBC规范的具体驱动,提供异步非阻塞的数据库访问能力 |
| 核心层 | Spring Data R2DBC、R2dbcTransactionManager | 提供响应式Repository抽象、事务管理、连接池等核心功能 |
| 应用层 | 开发者代码、业务逻辑 | 使用Spring Data R2DBC提供的API进行数据库操作 |
3.1 核心组件与交互流程
Spring Data R2DBC的核心组件包括:
ConnectionFactory:负责创建数据库连接,是访问数据库的入口点。它通常由具体的R2DBC驱动实现,如PostgresqlConnectionFactory或MySql基金会。DatabaseClient:提供低级API,用于执行SQL查询和操作。开发者可以通过DatabaseClient直接编写和执行SQL语句。ReactiveCrudRepository:提供高级抽象,简化CRUD操作。开发者只需定义接口,Spring Data会自动实现其方法。R2dbcTransactionManager:管理事务,确保数据库操作的原子性和一致性。RowMapper:将查询结果映射为Java对象,提供类型安全的数据转换。
一个典型的查询操作交互流程如下:
- 应用层调用
UserRepository.findById("123"),返回Mono<User>。 - Spring Data R2DBC将调用委托给
SimpleR2dbcRepository。 SimpleR2dbcRepository通过R2dbcEntityTemplate构建SQL查询(SELECT * FROM user WHERE id = $1)。R2dbcEntityTemplate从ConnectionFactory获取Mono<Connection>12 。- 连接就绪后,创建
Statement并绑定参数。 - 执行
Statement#execute()返回Publisher(Result)。 Result按行发布数据,通过RowMapper转换为User对象。- 最终结果封装为
Mono<User>返回给应用层 。
3.2 响应式事务管理
在Spring Data R2DBC中,事务管理通过以下两种方式实现:
声明式事务:使用@Transactional注解,Spring会自动管理事务的开始、提交和回滚。
@Service
public class UserTransactionService {private final UserRepository userRepository;private final TransactionalOperator transactionalOperator;public UserTransactionService(UserRepository userRepository,TransactionalOperator transactionalOperator) {this.userRepository = userRepository;this.transactionalOperator = transactionalOperator;}@Transactionalpublic Mono<User> createUserWithDefaultSettings(User user) {return userRepository.save(user).flatMap(savedUser -> {// 创建用户设置(在同一事务中)UserSettings settings = new UserSettings(savedUser.getId());return settingsRepository.save/settings).thenReturn(savedUser);});}
}编程式事务:使用TransactionalOperator手动控制事务边界,适用于需要更精细控制的场景。
@Bean
public TransactionalOperator transactionalOperator(ReactiveTransactionManager txm) {return TransactionalOperator.create(txm);
}// 使用编程式事务
Mono<Void> atomicOperation = db.execute().sql("INSERT INTO person (name, age) VALUES('Joe', 34)").fetch().rowsUpdated().then(db.execute().sql("INSERT INTO contacts (name) VALUES('Joe')")).then();// 将操作包裹在事务中
atomicOperation.as(transactionalOperator::transactional).subscribe();事务管理在响应式环境中需要特别注意,事务的作用范围由订阅点决定,而非方法调用边界。 这意味着开发者必须确保事务操作被正确订阅,才能触发事务的提交或回滚。
四、解决的问题与优势
4.1 解决的核心问题
Spring Data R2DBC主要解决了以下问题:
- 高并发场景下的性能瓶颈:通过异步非阻塞的编程模型,减少线程在IO等待期间的闲置时间,提高资源利用率。
- 与响应式框架的集成困难:提供与Spring WebFlux等响应式框架无缝集成的能力,实现端到端响应式应用。
- 复杂查询的类型安全问题:通过
RowMapper和@Query注解,提供类型安全的查询结果映射,避免手动处理ResultSet带来的潜在错误。 - 事务管理的挑战:在非阻塞环境中提供声明式和编程式事务支持,确保数据操作的原子性和一致性。
4.2 与传统JDBC的对比
Spring Data R2DBC与传统JDBC在多个方面存在显著差异:
| 特性 | JDBC | Spring Data R2DBC |
|---|---|---|
| 编程模型 | 同步阻塞 | 异步非阻塞 |
| 线程模型 | 每个连接一个线程 | 少量IO线程共享 |
| 资源消耗 | 高 | 低 |
| 性能特征 | 低并发下稳定 | 高并发下优异 |
| 事务管理 | 基于ThreadLocal | 基于响应式流 |
Spring Data R2DBC的优势在于它能够在保持关系型数据库特性(事务、ACID)的前提下,实现非阻塞、异步的数据库IO。 这使得它特别适合高并发、低延迟的场景,如电商秒杀、实时数据分析。
五、关键特性与功能
5.1 响应式编程模型
Spring Data R2DBC基于以下响应式原则构建:
- 异步非阻塞:操作不会阻塞调用线程,允许线程在等待数据库响应时处理其他任务。
- 事件驱动:通过事件通知机制处理结果,而非轮询或阻塞等待。
- 背压感知:消费者(如应用程序)可控制数据流速度,避免内存溢出。
- 函数式风格:使用声明式API组合操作,简化异步编程模型。
5.2 轻量级Repository抽象
Spring Data R2DBC提供了ReactiveCrudRepository和ReactiveSortingRepository等接口,开发者只需继承这些接口并定义方法名,Spring Data会自动实现其方法。
public interface UserRepository extends ReactiveCrudRepository<User, Long> {Flux<User> findByNameStartingWith(String prefix);Mono<User> findByEmail(String email);
}这种轻量级的Repository抽象大幅简化了数据访问层的开发,同时保持了代码的一致性和简洁性。 与传统JPA相比,Spring Data R2DBC不提供复杂的ORM映射和会话管理,转而采用更直接的函数式API,这使其更适合响应式应用的开发。
5.3 连接池管理
Spring Data R2DBC通过r2dbc-pool模块提供连接池管理,优化数据库连接的重用和生命周期。连接池配置可通过ConnectionPoolConfiguration进行,如:
@Bean
public ConnectionFactory connectionFactory() {ConnectionFactory connectionFactory = new Postgresql基金会(PostgresqlConnectionConfiguration.builder().host("localhost").database("test").username("user").password("password").build());ConnectionPoolConfiguration configuration = ConnectionPoolConfiguration.builder(connectionFactory).maxSize(20) // 最大连接数.maxIdleTime(Duration.ofMinutes(5)) // 最大空闲时间.maxAcquireTime(Duration.ofSeconds(10)) // 获取连接的最大等待时间.build();return new ConnectionPool(configuration);
}连接池管理是Spring Data R2DBC的重要特性,它通过复用数据库连接,减少连接创建和销毁的开销,提高系统性能。 在高并发场景下,合理的连接池配置可以显著提升系统吞吐量。
5.4 动态查询构建
Spring Data R2DBC提供了DatabaseClient和Fluent API,支持动态查询构建:
Flux<User> users = databaseClient.execute().sql("SELECT * FROM users WHERE age > $1 AND status = $2").bind("$1", 18).bind("$2", "active").fetch().all();或使用Fluent API:
Flux<User> users = databaseClient.select().from("users").where("age > :age AND status = :status").bind("age", 18).bind("status", "active").fetch().all();Fluent API提供了类型安全的查询构建方式,避免了SQL注入风险,同时保持了接近原生SQL的写法表现。 虽然目前Fluent API对复杂查询(如JOIN)的支持有限,但它仍然是Spring Data R2DBC的重要特性之一。
5.5 批量操作支持
Spring Data R2DBC支持批量操作,可以通过ReactiveCrudRepository的saveAll方法实现:
Flux<User> users = Flux.just(new User(null, "John", "Doe"),new User(null, "Jane", "Doe"));Mono<Integer> affectedRows = userRepository.saveAll(users).count();或使用Statement构建批量操作:
Mono<Integer> affectedRows = databaseClient.execute().sql("INSERT INTO users (name, age) VALUES ($1, $2), ($3, $4)").bind(0, "John").bind(1, 30).bind(2, "Jane").bind(3, 25).fetch().rowsUpdated();批量操作是Spring Data R2DBC的重要特性,它通过减少数据库连接的开销和提高数据传输效率,显著提升了批量数据操作的性能。
六、与同类产品的对比
6.1 与Spring Data JDBC的对比
Spring Data JDBC是Spring Data家族中用于传统JDBC的模块,它与Spring Data R2DBC的主要区别在于:
- 编程模型:Spring Data JDBC基于同步阻塞模型,而Spring Data R2DBC基于异步非阻塞模型 。
- 资源消耗:Spring Data JDBC需要为每个并发请求创建一个线程,而Spring Data R2DBC通过少量IO线程处理大量并发请求,显著降低了资源消耗。
- 适用场景:Spring Data JDBC适合低并发场景,而Spring Data R2DBC更适合高并发场景。
Spring Data R2DBC与Spring Data JDBC的对比表明,R2DBC更适合现代云原生和微服务架构,能够在高并发场景下提供更好的性能和可扩展性。
6.2 与MyBatis-Plus的对比
MyBatis-Plus是MyBatis的增强工具,提供了更简洁的SQL操作方式。与MyBatis-Plus相比,Spring Data R2DBC的主要优势在于:
- 响应式支持:Spring Data R2DBC原生支持响应式编程模型,而MyBatis-Plus需要额外的异步处理。
- 类型安全:Spring Data R2DBC通过
RowMapper和@Query注解提供类型安全的查询结果映射,而MyBatis-Plus需要手动编写映射器。 - 事务管理:Spring Data R2DBC提供声明式和编程式事务支持,而MyBatis-Plus需要额外的事务管理器。
MyBatis-Plus更适合传统同步应用,而Spring Data R2DBC更适合需要高并发、低延迟的响应式应用。 开发者可以根据项目需求选择合适的工具。
6.3 与Reactive MongoDB的对比
Reactive MongoDB是Spring Data家族中用于MongoDB等NoSQL数据库的模块。与Reactive MongoDB相比,Spring Data R2DBC的主要优势在于:
- 关系型数据库支持:Spring Data R2DBC支持主流关系型数据库,如PostgreSQL、MySQL等,而Reactive MongoDB专为MongoDB设计。
- SQL查询能力:Spring Data R2DBC允许开发者直接编写和执行SQL查询,而Reactive MongoDB使用MongoDB特定的查询语言。
- 事务管理:Spring Data R2DBC支持ACID事务,而Reactive MongoDB主要支持最终一致性。
Reactive MongoDB和Spring Data R2DBC都是Spring Data家族的重要成员,但它们针对不同的数据库类型和使用场景。 在实际项目中,开发者可以根据数据模型和业务需求选择合适的工具,或结合使用以构建混合数据访问层。
七、使用方法与最佳实践
7.1 项目搭建与依赖引入
要使用Spring Data R2DBC,首先需要在项目中引入相关依赖。对于Spring Boot项目,可以通过以下方式添加:
<dependencies><!-- Spring WebFlux --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency><!-- Spring Data R2DBC --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-r2dbc</artifactId></dependency><!-- 数据库驱动 --><dependency><groupId>io.r2dbc</groupId><artifactId>r2dbc postgreSQL</artifactId><version>1.0.0.RELEASE</version><scope>runtime</scope></dependency>
</dependencies>引入依赖后,Spring Boot会自动配置ConnectionFactory和DatabaseClient,开发者无需手动创建这些对象。 这大大简化了Spring Data R2DBC的使用流程。
7.2 数据库连接配置
在application.properties或application.yml中配置数据库连接:
spring:r2dbc:url: r2dbc:pool:postgresql://localhost:5432/testdbusername: springpassword: passwordpool:max-size: 20 # 最大连接数max-idle-time: 30m # 最大空闲时间validation-query: SELECT 1 # 心跳检测查询连接池配置是Spring Data R2DBC性能优化的关键环节。 合理的连接池参数(如max-size、max-idle-time)可以显著提升系统吞吐量和响应速度。
7.3 实体定义与Repository
定义实体类:
@Data
public class User {@Idprivate Long id;private String name;private Integer age;private String email;
}创建Repository接口:
public interface UserRepository extends ReactiveCrudRepository<User, Long> {Mono<User> findByEmail(String email);Flux<User> findByNameStartingWith(String prefix);
}实体定义与Repository创建是Spring Data R2DBC的基础步骤,通过简单的接口定义,开发者可以快速获得基本的CRUD能力。 这使得数据访问层的开发变得异常简单。
7.4 数据操作示例
使用Repository进行数据操作:
@Service
public class UserService {private final UserRepository userRepository;public UserService(UserRepository userRepository) {this.userRepository = userRepository;}public Mono<User> createUser(User user) {return userRepository.save(user);}public Flux<User>全体用户() {return userRepository.findAll();}public Mono<User> findUserById(Long id) {return userRepository.findById(id);}public Mono<Integer>全体用户数() {return userRepository.count();}
}使用DatabaseClient进行复杂查询:
@Service
public class UserService {private final DatabaseClient databaseClient;public UserService(DatabaseClient databaseClient) {this.databaseClient = databaseClient;}public Flux<User> findUsersByAgeAndStatus(Integer age, String status) {return databaseClient.execute().sql("SELECT * FROM users WHERE age > $1 AND status = $2").bind("$1", age).bind("$2", status).fetch().all().map(row -> new User(row.get("id", Long.class),row.get("name", String.class),row.get("age", Integer.class),row.get("email", String.class)));}
}无论是使用Repository还是DatabaseClient,Spring Data R2DBC都提供了简洁、直观的API,使开发者能够轻松地进行数据库操作。 这大大降低了响应式数据库访问的学习曲线。
7.5 端到端集成示例
将Spring Data R2DBC与Spring WebFlux集成,构建一个简单的REST API:
@RestController
@RequestMapping("/users")
public class UserController {private final UserRepository userRepository;public UserController(UserRepository userRepository) {this.userRepository = userRepository;}@GetMappingpublic Flux<User>全体用户() {return userRepository.findAll();}@GetMapping("/byEmail/{email}")public Mono<User> findUserByEmail(@PathVariable String email) {return userRepository.findByEmail(email);}@PostMappingpublic Mono<User> createUser(@RequestBody User user) {return userRepository.save(user);}@PutMappingpublic Mono<User> updateUser(@RequestBody User user) {return userRepository.save(user);}@DeleteMapping("/{id}")public Mono<Void>.deleteUser(@PathVariable Long id) {return userRepository.deleteById(id);}
}这个简单的示例展示了Spring Data R2DBC与Spring WebFlux的端到端集成,通过返回Flux和Mono,实现了完全响应式的应用架构。 在高并发场景下,这种架构能够提供更好的性能和可扩展性。
7.6 最佳实践与性能优化
以下是使用Spring Data R2DBC的一些最佳实践:
- 合理配置连接池:根据系统负载和并发需求,设置合适的
max-size和max-idle-time参数。 - 避免阻塞操作:在响应式链中,避免使用阻塞方法(如
block()),以免破坏响应式模型。 - 利用背压机制:通过
Flux的背压机制,控制数据流的速率,避免内存溢出。 - 使用异常处理:通过
onErrorResume和retryWhen处理异常,提高系统的健壮性。 - 监控连接池状态:通过Spring Boot Actuator监控连接池的
acquired、allocated和pending指标,及时发现连接池瓶颈。
遵循这些最佳实践,可以充分发挥Spring Data R2DBC的性能优势,构建高效、可扩展的响应式应用。 在实际项目中,开发者需要根据具体需求调整这些实践,以达到最佳效果。
八、常见问题与解决方案
8.1 依赖冲突问题
Spring Data R2DBC的依赖管理是新手常遇到的问题。 为避免依赖冲突,建议:
- 确保使用与Spring Boot版本兼容的Spring Data R2DBC版本。可以通过查阅官方文档或GitHub上的发布说明来确认兼容性。
- 在
pom.xml或build.gradle中明确指定依赖版本,避免使用默认版本导致的冲突。 - 使用Maven或Gradle的依赖管理工具(如
dependencyManagement或dependencyResolutionManagement)统一管理依赖版本。
8.2 连接配置问题
数据库连接配置是Spring Data R2DBC的另一个常见问题。 为确保连接成功,建议:
- 在
application.properties或application.yml中正确配置数据库连接信息,包括URL、用户名、密码等。 - 检查数据库驱动是否正确引入,并确保驱动版本与数据库版本兼容。
- 使用
DatabaseClient进行简单的查询操作,验证连接是否成功。
8.3 响应式编程模型问题
新手在使用响应式编程模型时,可能会对Mono和Flux的概念不熟悉,导致代码编写错误。 为解决这一问题,建议:
- 学习响应式编程的基本概念,理解
Mono和Flux的区别及使用场景。 - 参考官方文档或示例代码,学习如何正确使用
Mono和Flux进行数据操作。 - 使用调试工具或日志输出,逐步验证代码的执行流程,确保响应式编程模型正确应用。
九、应用场景与未来展望
9.1 适用场景
Spring Data R2DBC特别适合以下场景:
- 微服务架构:在分布式系统中,非阻塞和响应式设计可以帮助优化资源分配,减少系统延迟。
- 实时数据分析:对于需要实时更新视图或进行快速数据查询的应用,R2DBC的高性能读写能力非常有用。
- 高并发场景:如电子商务、社交网络等业务,需要处理大量并发请求,R2DBC可以有效提升服务器的并发处理能力。
在这些场景中,Spring Data R2DBC能够充分发挥其性能优势,为应用提供高效的数据库访问能力。
9.2 未来发展趋势
随着云原生和微服务架构的普及,Spring Data R2DBC的未来发展趋势包括:
- 更广泛的应用支持:随着R2DBC生态的成熟,预计将有更多数据库提供R2DBC驱动支持,扩大Spring Data R2DBC的应用范围。
- 更完善的工具链:随着开发者对R2DBC的熟悉,预计将出现更多辅助工具和框架,简化R2DBC的使用流程。
- 与云原生技术的深度整合:随着云原生技术的发展,Spring Data R2DBC预计将与Kubernetes、Serverless等技术深度整合,提供更灵活的部署和扩展能力。
- 更强大的查询能力:随着Fluent API的完善,预计将支持更复杂的查询操作(如JOIN),进一步提升Spring Data R2DBC的查询能力。
Spring Data R2DBC作为响应式数据库访问的代表技术,其未来发展将与云原生和微服务架构的演进紧密相关。 随着这些技术的成熟,Spring Data R2DBC的应用场景和功能也将不断扩展和增强。
十、总结与建议
Spring Data R2DBC是Java响应式编程领域的重大创新,它通过异步非阻塞的编程模型,解决了传统JDBC在高并发场景下的性能瓶颈。 与Spring WebFlux等响应式框架的深度整合,使开发者能够构建端到端的响应式应用,提高系统性能和可扩展性。
对于希望采用响应式编程模型的开发者,建议:
- 评估项目需求:只有在项目需要处理高并发、低延迟的场景时,才考虑使用Spring Data R2DBC。对于低并发场景,传统JDBC可能更为合适。
- 循序渐进学习:从简单的查询和操作开始,逐步掌握Spring Data R2DBC的高级特性和最佳实践。
- 充分测试:在生产环境中使用Spring Data R2DBC前,进行全面的测试和性能评估,确保其能够满足项目需求。
- 持续关注生态发展:Spring Data R2DBC和R2DBC生态仍在快速发展中,持续关注最新版本和功能,以便及时更新和优化应用。
Spring Data R2DBC代表了数据库访问技术的新方向,它不仅是一种技术解决方案,更是一种应对高并发挑战的思维跃迁。 随着云原生和微服务架构的普及,Spring Data R2DBC的应用场景和价值将进一步扩大。对于Java开发者来说,掌握Spring Data R2DBC不仅是技术能力的提升,更是适应现代应用架构的必然选择。
参考资料:
- Spring Data R2DBC 文档
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊“技术内外的那些事”,让你的代码之外,更有“技术眼光”。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!关于愚者Turbo:
🌟博主GitHub
🌞博主知识星球