如何利用简单的浏览器插件Web Scraper爬取知乎评论数据
一、简单介绍:
Web Scraper 的优点就是对新手友好,在最初抓取数据时,把底层的编程知识和网页知识都屏蔽了,可以非常快的入门,只需要鼠标点选几下,几分钟就可以搭建一个自定义的爬虫。
我在过去的半年里,写了很多篇关于 Web Scraper 的教程,本文类似于一篇导航文章,把爬虫的注意要点和我的教程连接起来。最快一个小时,最多一个下午,就可以掌握 Web Scraper 的使用,轻松应对日常生活中的数据爬取需求。
像这样的网页数据,想要通过网页爬虫的方式获取数据,可以下载web scraper进行爬虫
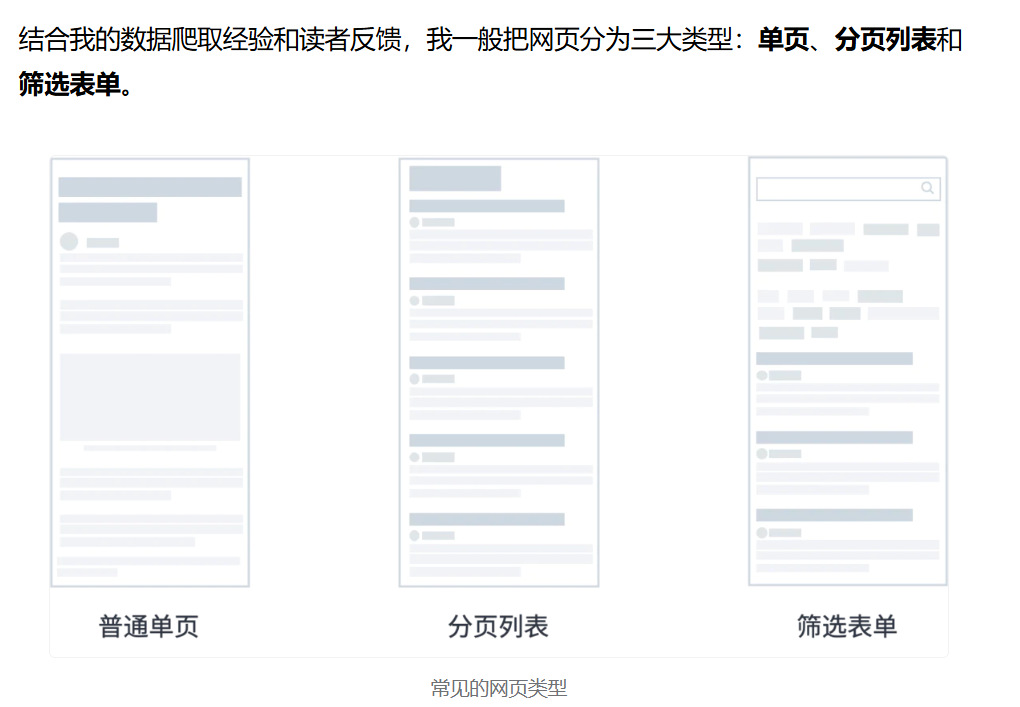
这是常见的网页类型:
1.单页
单页是最常见的网页类型。
我们日常阅读的文章,推文的详情页都可以归于这种类型。作为网页里最简单最常见的类型,Web Scraper 教程里就拿豆瓣电影作为案例,入门 Web Scraper 的基础使用。
2.分页列表
分页列表也是非常常见的网页类型。
互联网的资源可以说是无限的,当我们访问一个网站时,不可能一次性把所有的资源都加载到浏览器里。现在的主流做法是先加载一部分数据,随着用户的交互操作(滚动、筛选、分页)才会加载下一部分数据。
教程里我费了较大的笔墨去讲解 Web Scraper 如何爬取不同分页类型网站的数据,因为内容较多,我放在本文的下一节详细介绍。
3.筛选表单
表单类型的网页在 PC 网站上比较常见。
这种网页的最大特点就是有很多筛选项,不同的选择会加载不同的数据,组合多变,交互较为复杂。比如说淘宝的购物筛选页。
知乎就是属于第二种的网页滚动加载分页
官方支持Fierfox浏览器和Chrome浏览器,用edge浏览器也可以,以下演示我用edge浏览器来做:
二、安装教程
点进插件里获取更多扩展:
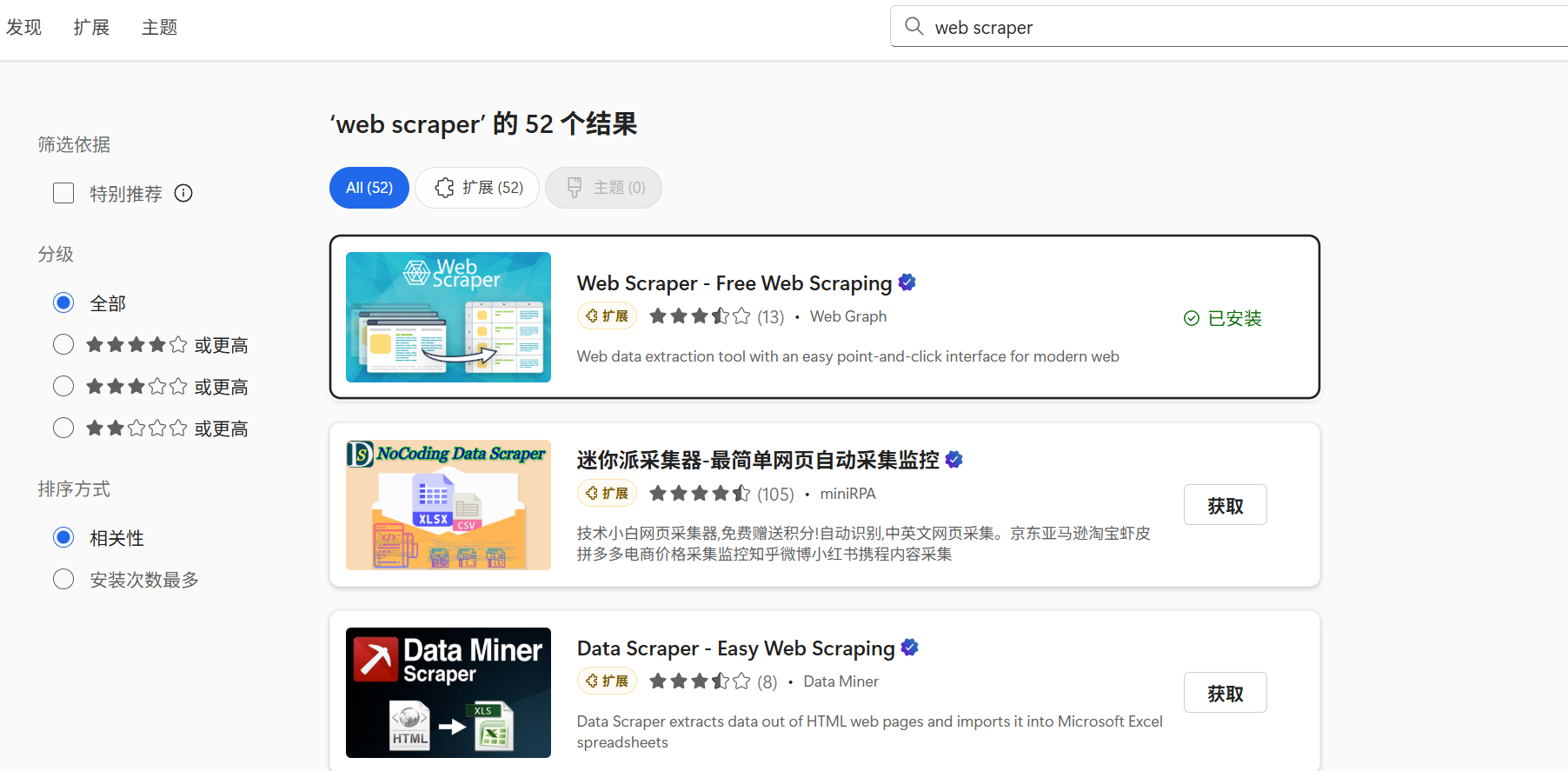
搜索web scraper进行安装
大家在自己使用的时候是不是只能爬5条信息?那是因为你没有点scroll设置延迟,下面我来教学:
三、使用教程
1.第一步:选择一个帖子
按F12进入开发者模式:
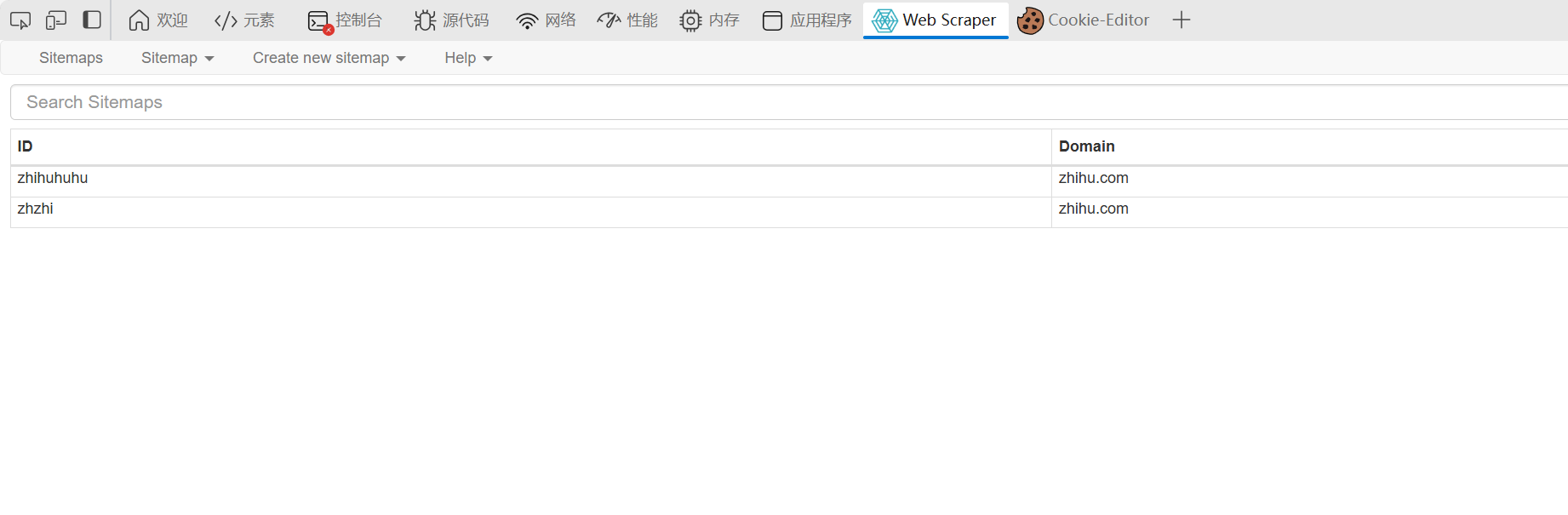
接下来点create sitemap: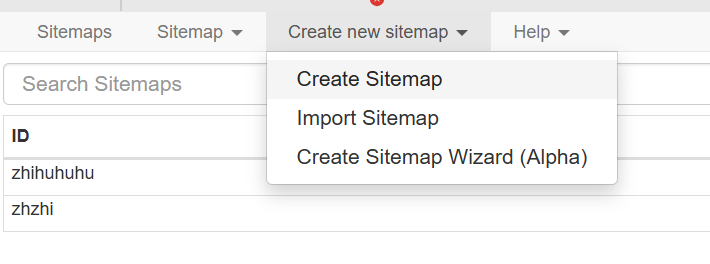
然后名字随便取,url填上面的网页链接:
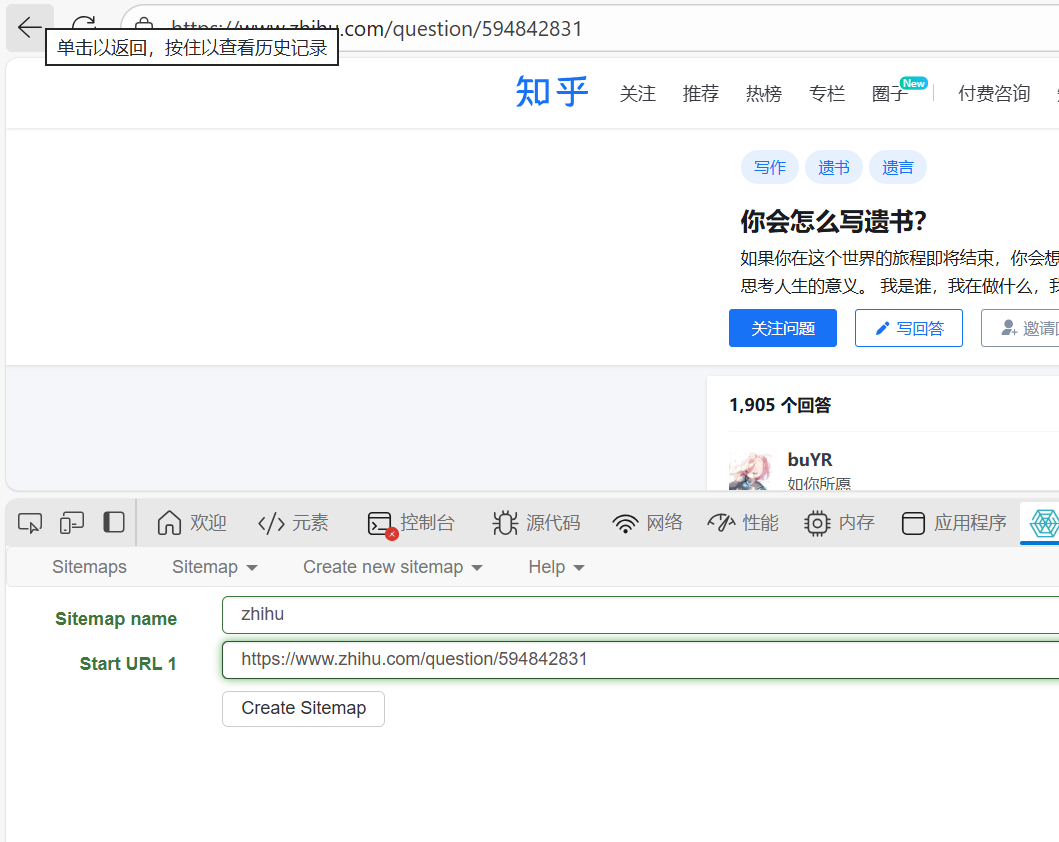
然后点create sitemap
接下来创建新的选择器:
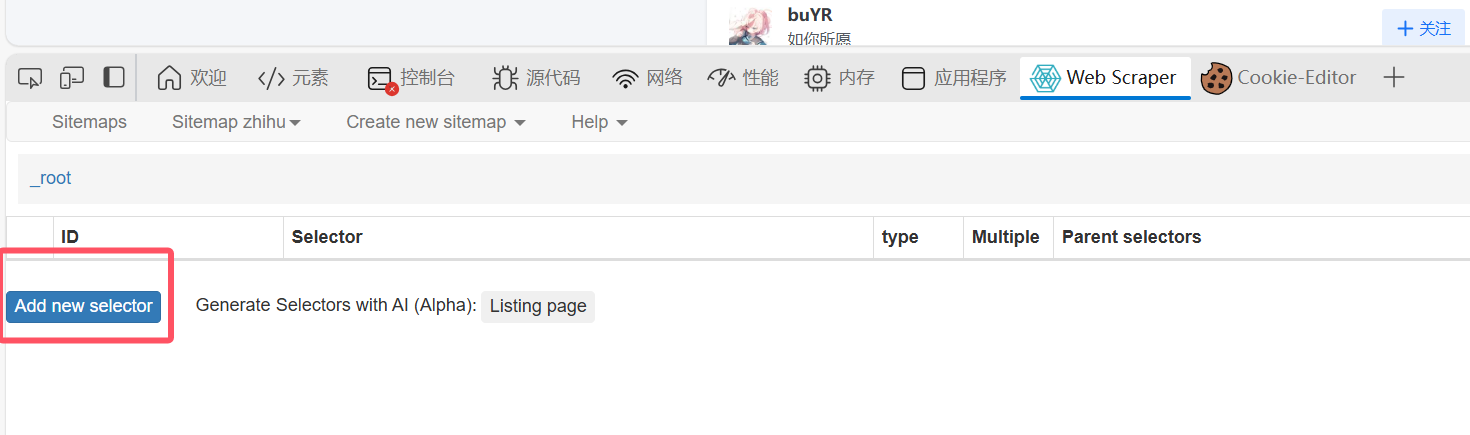
id随便取,type按照我图片上的来,元素滚动:
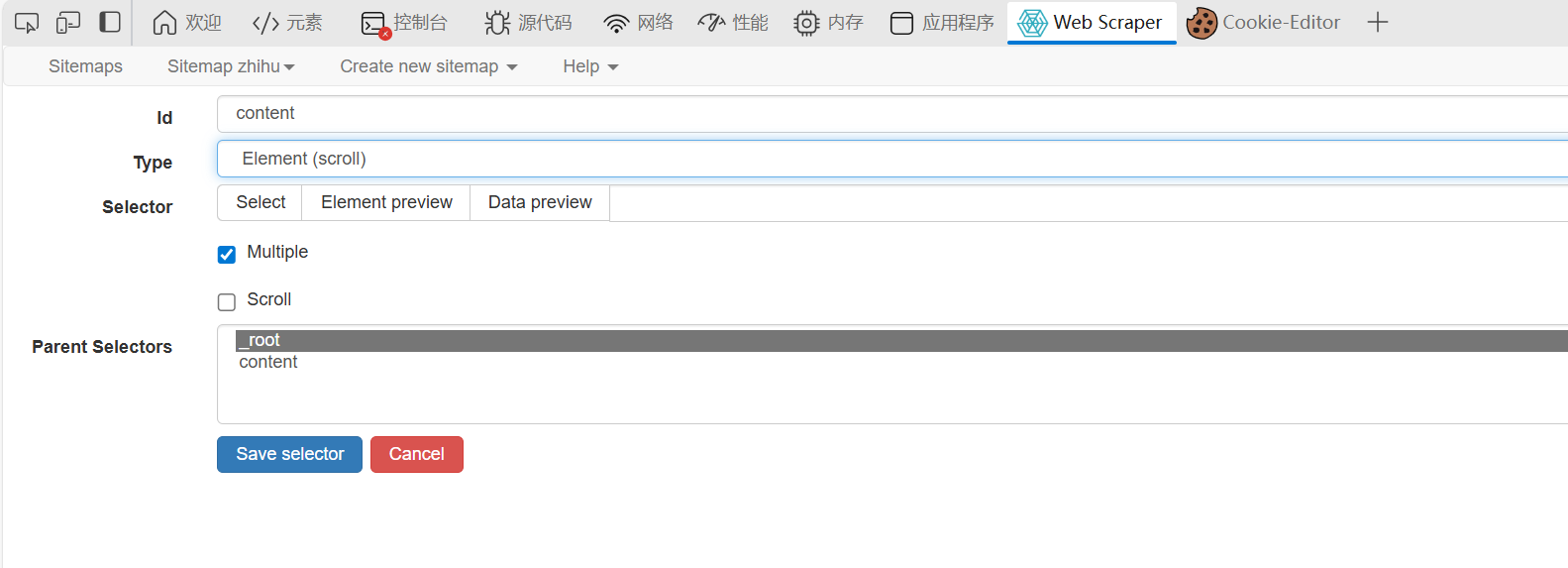
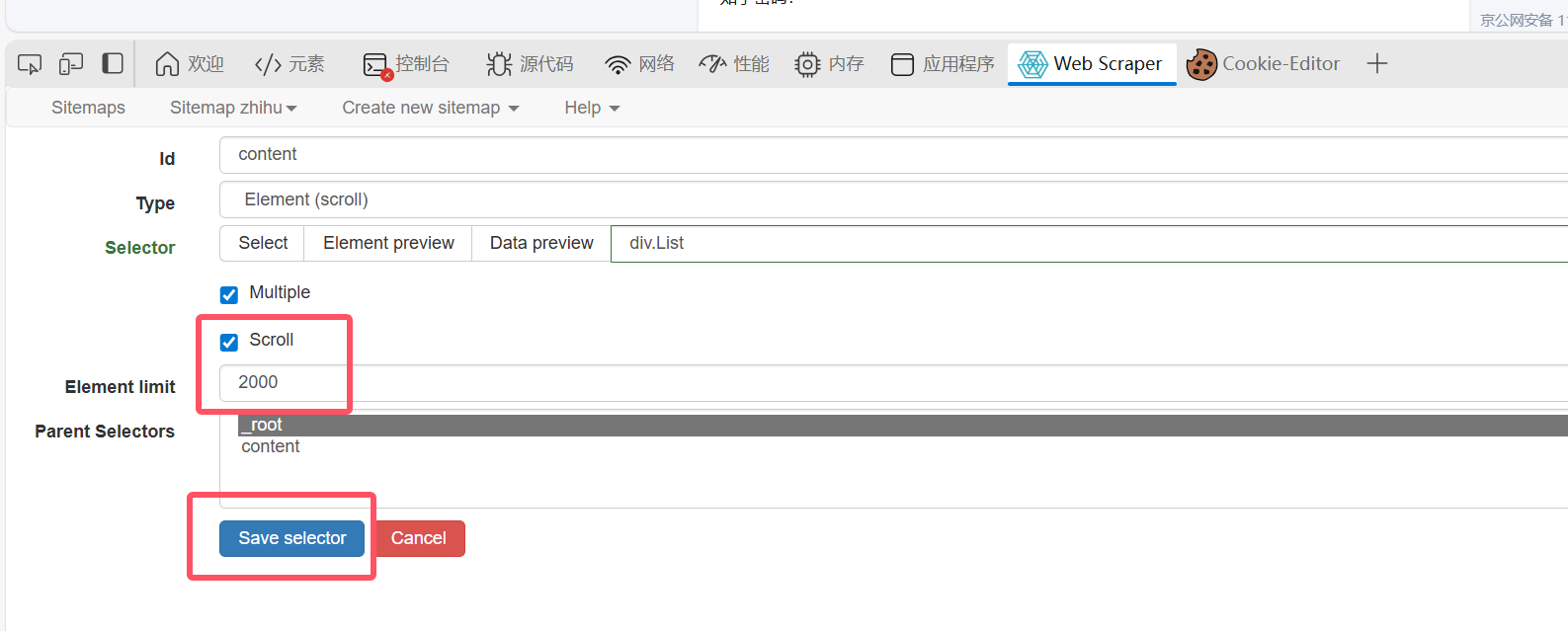
然后点击select选择全部的下滑框,像我图里的这样,然后点保存(我红框标注的):
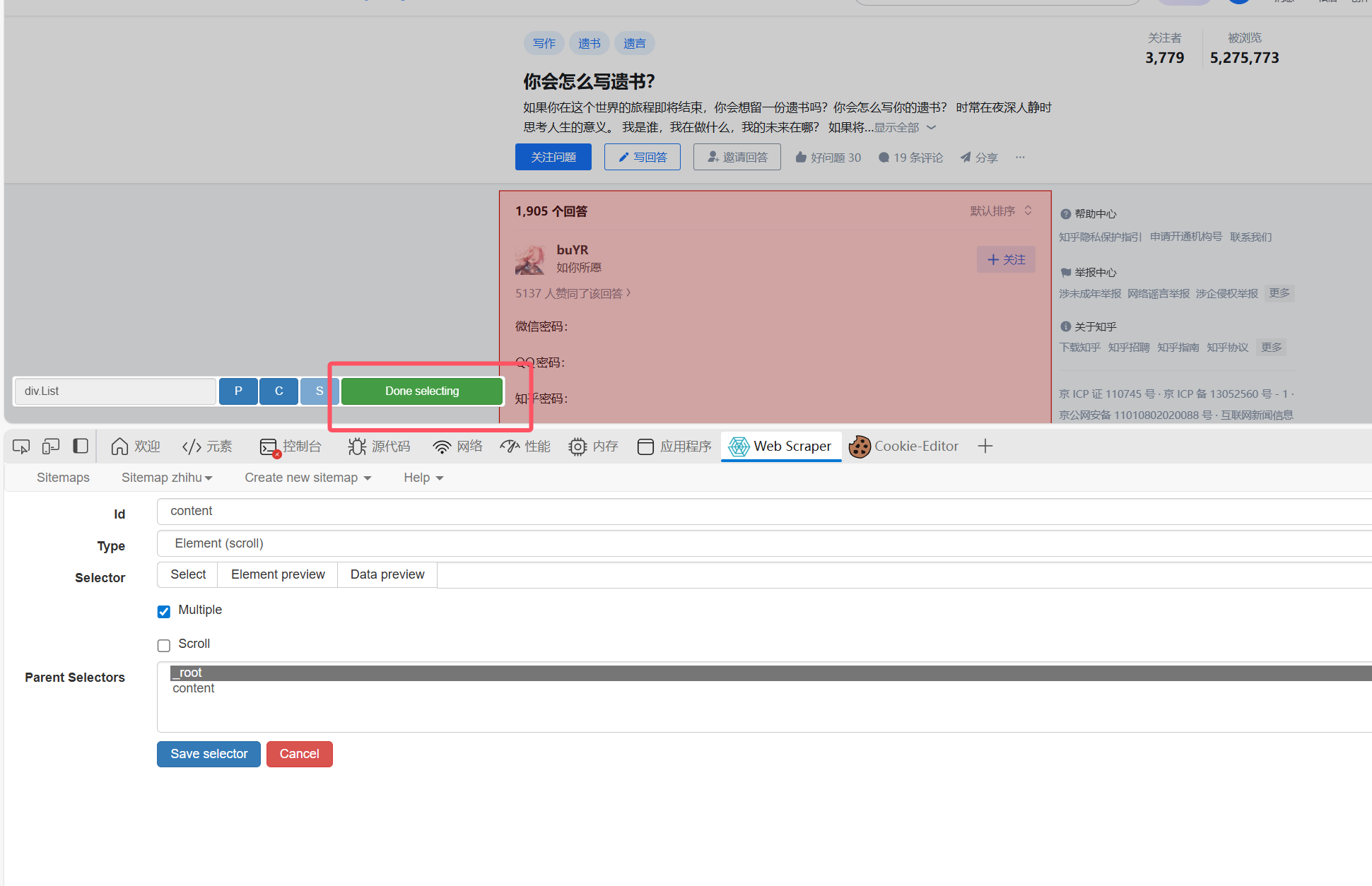 然后记得scroll记得也要选上,延迟选2000,最后save:
然后记得scroll记得也要选上,延迟选2000,最后save:
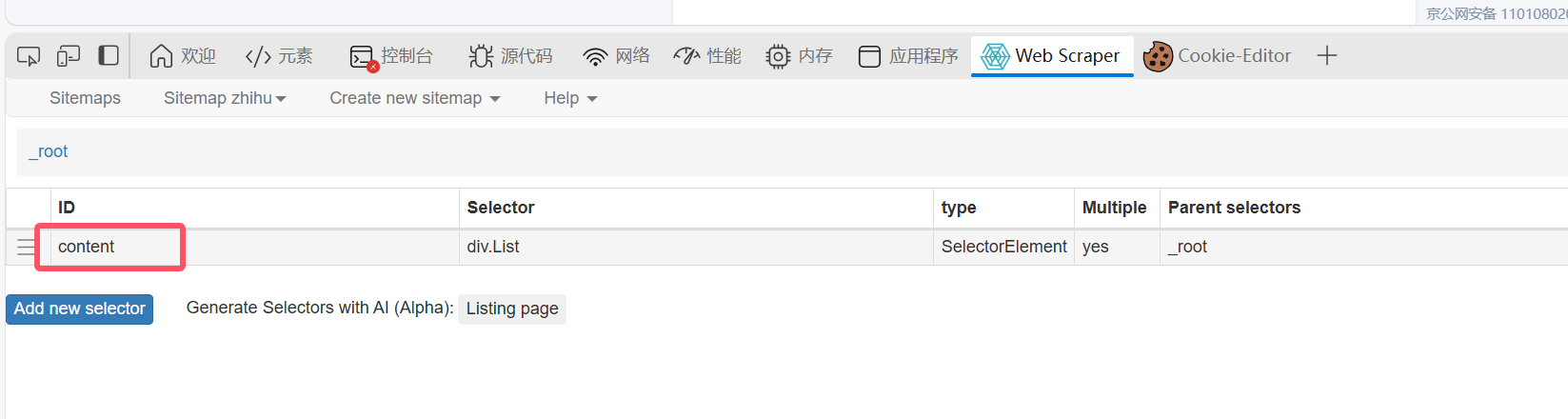
然后再点进content里面:
继续add: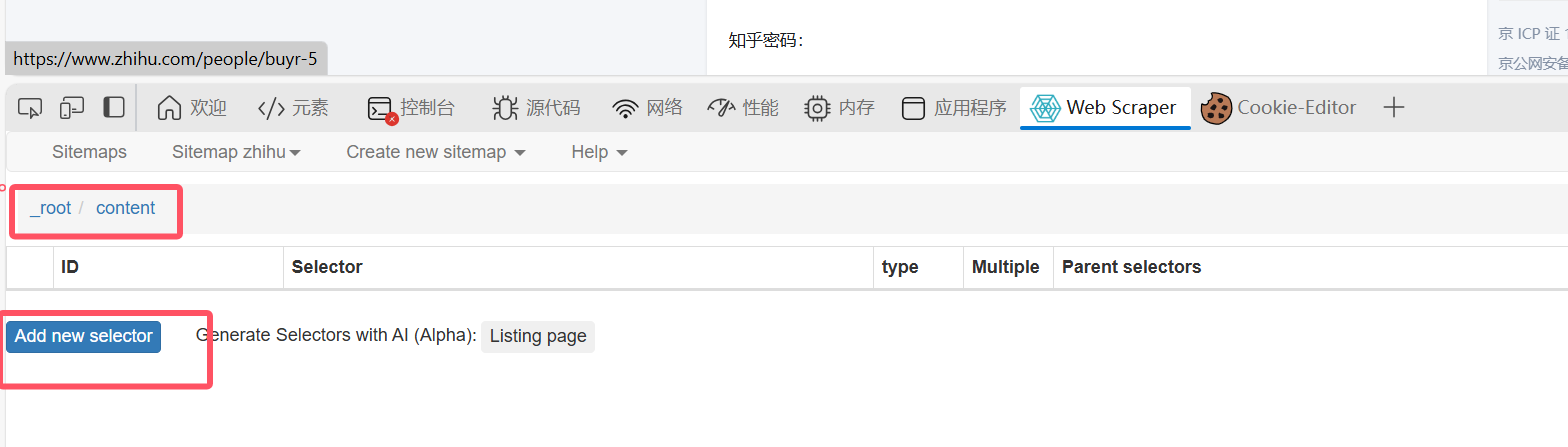
然后直接一步到位吧,把最重要的data内容爬下来,id随便取,类型是text:
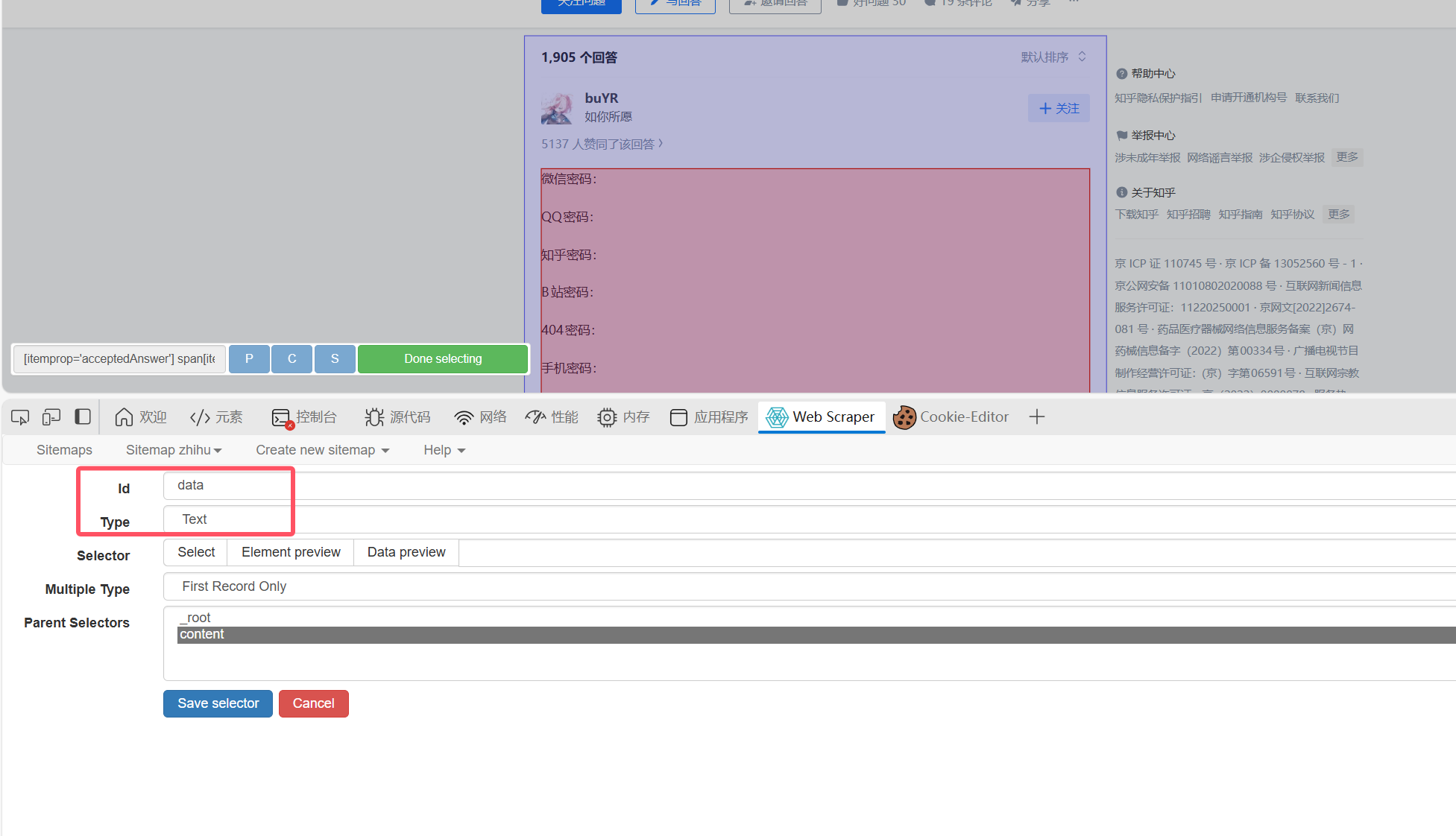
其它的像名字,点赞量评论量什么的你们自己可以设置同级别的add点击需要爬取的框,把信息都爬下来
接下来点select点击内容框,此时最重要的来了!!!!!按住shift点击下一个帖子的data内容,这时候往下翻会发现都自动选中了:
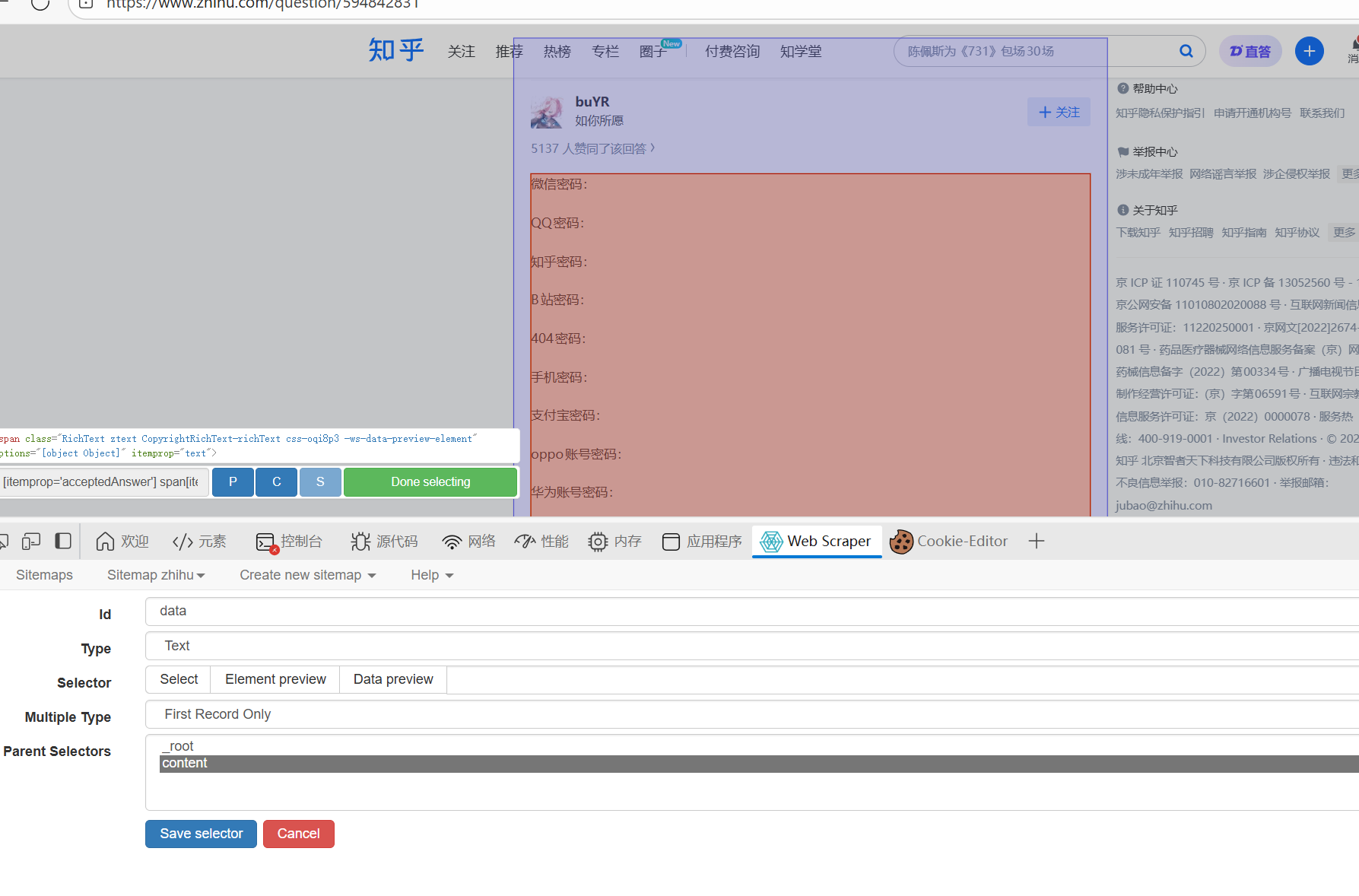
done后save
其实在爬之前也可以data preview一下:
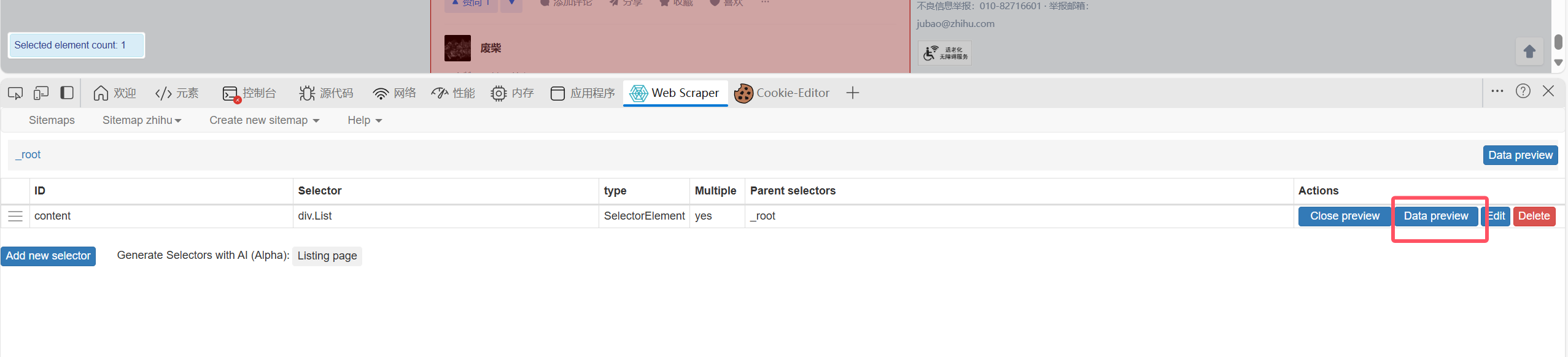
然后他会自动向下翻页
最后点击抓取:
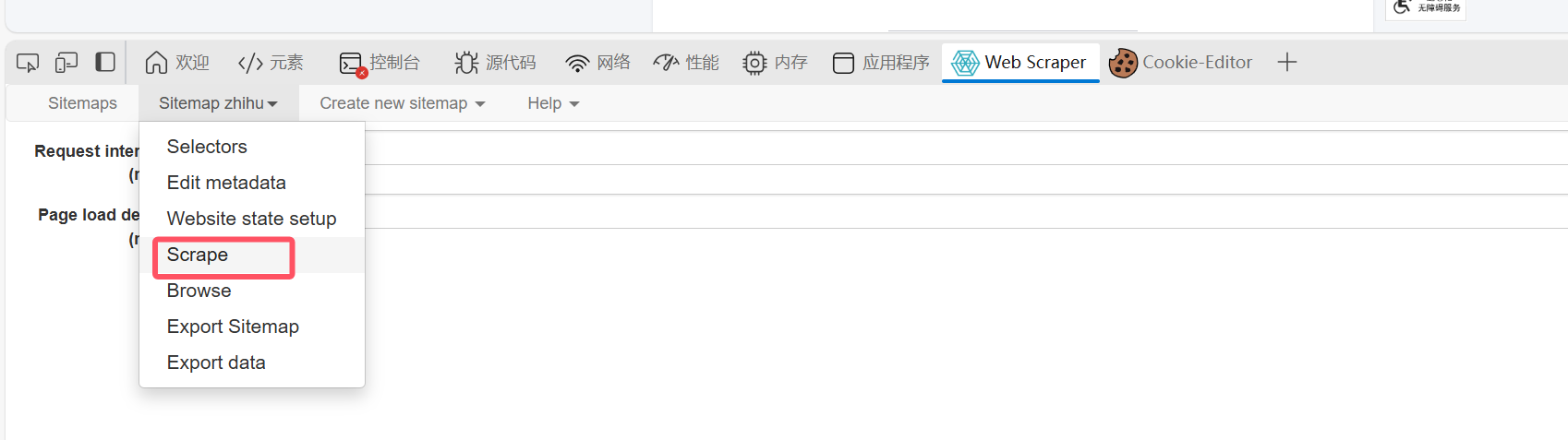
不用管直接start:
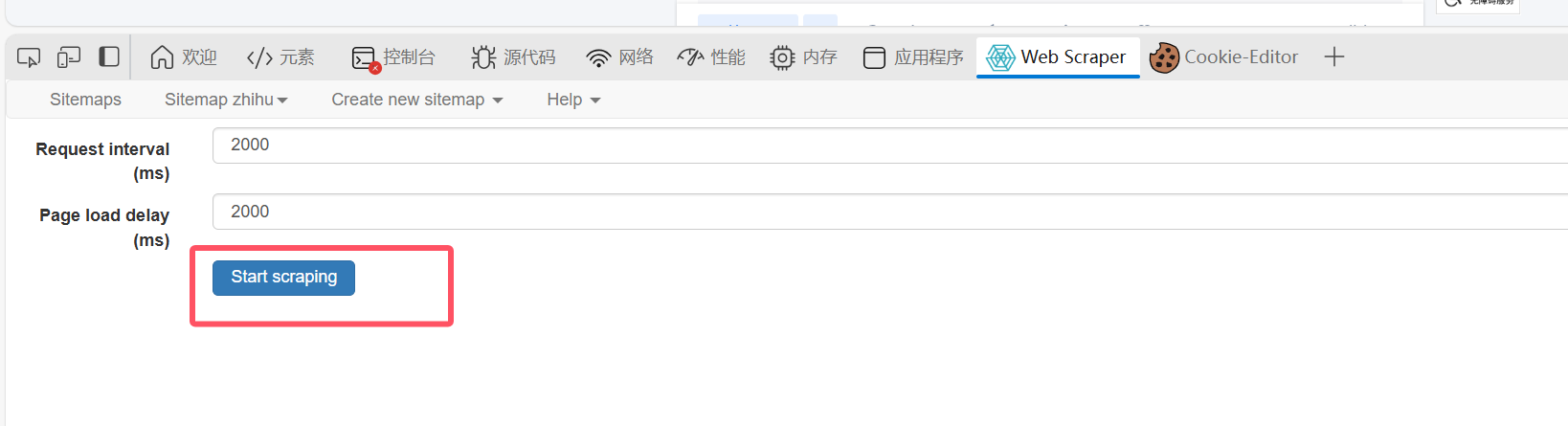
然后他会自己往下翻,等他结束关闭了:
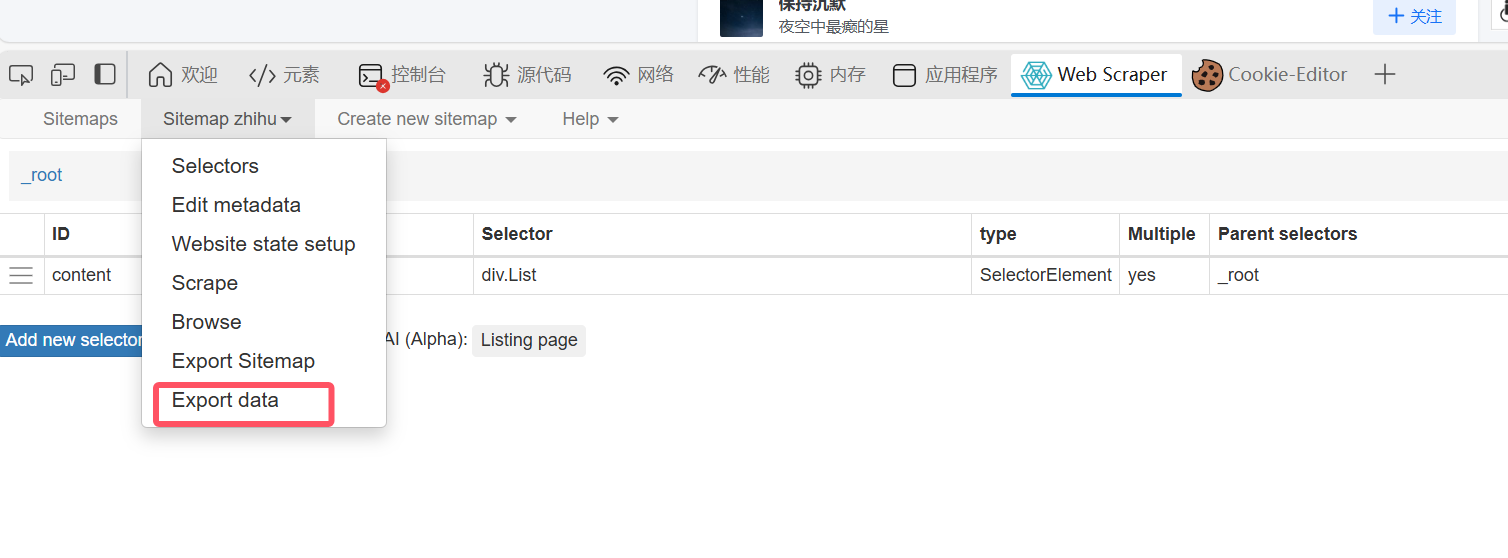
最后数据会弹出来,然后点导出数据:
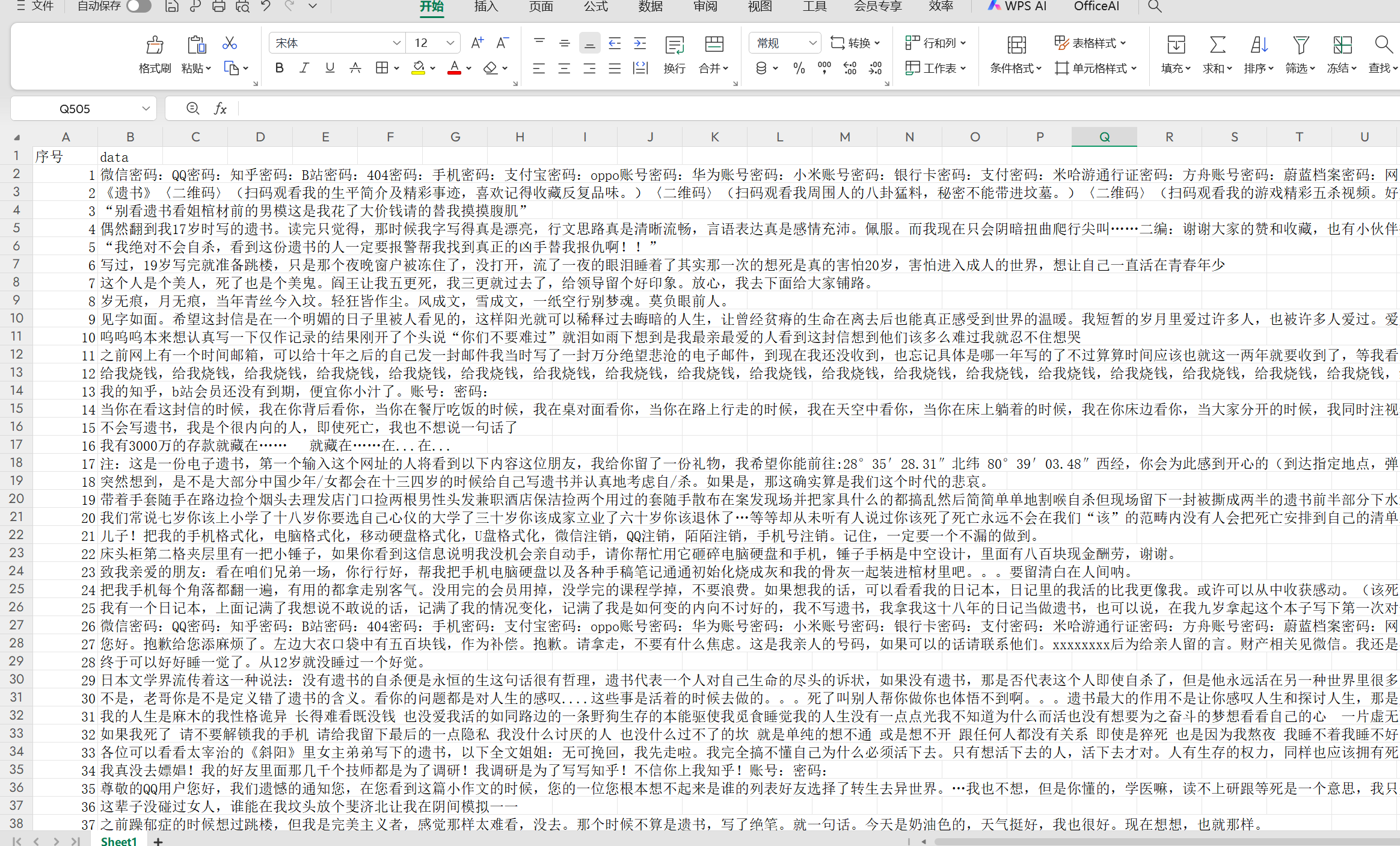
最后结果:
四、总结:
掌握了 Web Scraper 的使用,基本上可以应付学习工作中 90% 的数据爬取需求。相对于 python 爬虫,虽然灵活度上受到了限制,但是低廉的学习成本可以大大节省学习时间,快速解决手头的工作,提高整体的工作效率。综合来看,Web Scraper 还是非常值得去学习的。
希望大家多多点赞收藏支持~